

Missed Nvidia? Don't miss Crypto AI again
TechFlow Selected TechFlow Selected
Missed Nvidia? Don't miss Crypto AI again
We are standing on the edge of an innovation explosion.
Author: Teng Yan
Translation: TechFlow

Good morning! It’s finally here.
Our full thesis is quite comprehensive. To make it easier to digest (and avoid hitting email size limits), I’ve decided to break it into several parts and share them gradually over the next month. Let’s dive in!
There's one massive miss I still can't get over.
It haunts me to this day because it was an obvious opportunity that anyone paying attention could have seen — yet I missed it completely and didn’t invest a single dollar.
No, it wasn’t the next Solana killer or a memecoin of a dog wearing a funny hat.
It was… NVIDIA.
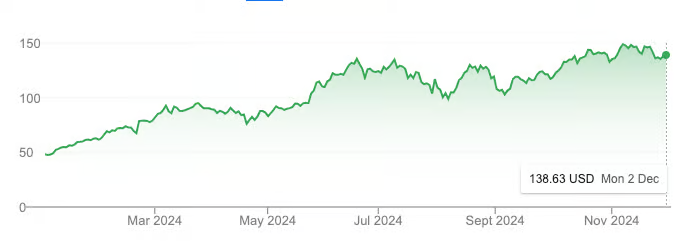
NVDA year-to-date stock performance. Source: Google
In just one year, NVIDIA’s market cap surged from $1 trillion to $3 trillion, tripling its stock price and outperforming even Bitcoin during the same period.
Sure, some of this was fueled by the AI boom. But more importantly, this growth had solid real-world fundamentals. NVIDIA generated $60 billion in revenue for fiscal 2024, a 126% increase from 2023. Behind this staggering growth is a global race among tech giants to buy GPUs and gain an edge in the AGI arms race.
Why did I miss it?
For the past two years, my focus has been entirely on crypto, and I neglected developments in AI. That was a huge mistake — one I deeply regret.
But not this time.
Crypto AI today feels eerily familiar.
We’re standing at the edge of an innovation explosion — one reminiscent of the California Gold Rush in the mid-19th century, where industries and cities rose overnight, infrastructure rapidly expanded, and risk-takers made fortunes.
Just like early NVIDIA, Crypto AI will look obvious in hindsight.
Crypto AI: A Massive Investment Opportunity
In Part I of my thesis, I explained why Crypto AI is the most exciting potential opportunity today — both for investors and developers. Key takeaways:
- Many still see it as “pie in the sky.”
- Crypto AI is still early, likely 1–2 years away from peak hype.
- This space has at least $230 billion in growth potential.
The core of Crypto AI lies in merging artificial intelligence with crypto infrastructure. This makes it far more likely to follow AI’s exponential growth trajectory than the broader crypto market. To stay ahead, you need to track the latest AI research on Arxiv and talk to founders who believe they’re building the next big thing.
The Four Core Areas of Crypto AI
In Part II of my thesis, I’ll focus on the four most promising sub-sectors within Crypto AI:
- Decentralized Compute: Model Training, Inference & GPU Marketplaces
- Data Networks
- Verifiable AI
- AI Agents Running On-chain
This article is the result of weeks of deep research and conversations with founders and teams across the Crypto AI space. It’s not an exhaustive analysis of each area, but rather a high-level roadmap designed to spark your curiosity, refine your research focus, and guide your investment decisions.
The Crypto AI Ecosystem Blueprint
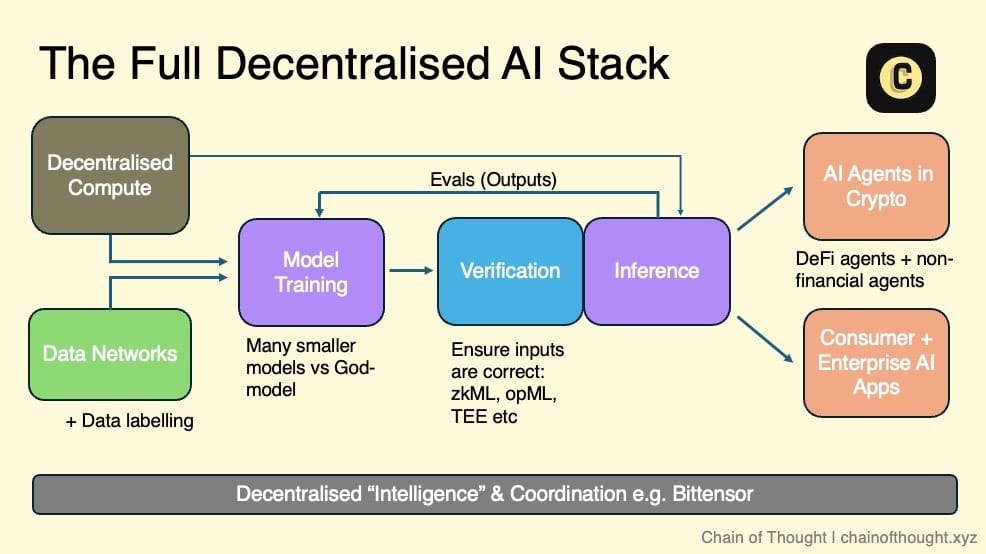
I envision the decentralized AI ecosystem as a layered stack: starting with decentralized compute and open data networks at one end, forming the foundation for training decentralized AI models.
All inputs and outputs of inference are cryptographically verified through cryptographic economic incentives and evaluation networks. These verified results flow to autonomous AI agents running on-chain, and to consumer and enterprise AI applications users can trust.
Coordination networks connect the entire ecosystem, enabling seamless communication and collaboration.
In this vision, any team working on AI development can plug into one or more layers of the ecosystem based on their needs — whether leveraging decentralized compute for model training or using evaluation networks to ensure high-quality output. The ecosystem offers diverse options.
Thanks to blockchain composability, I believe we’re moving toward a modular future. Each layer will become highly specialized, with protocols optimized for specific functions rather than all-in-one solutions.
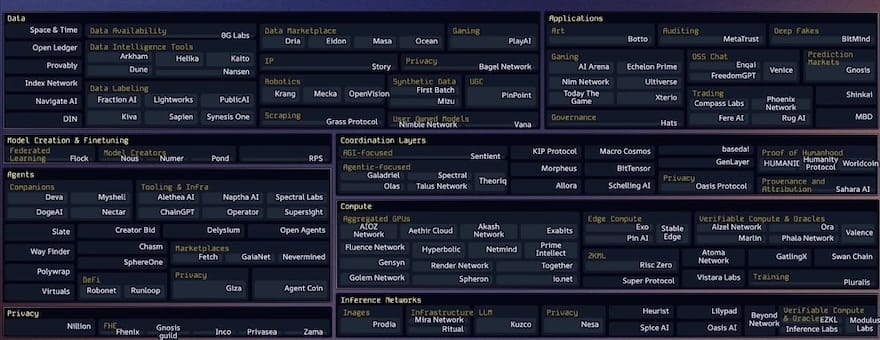
In recent years, there has been a Cambrian explosion of startups across every layer of the decentralized AI tech stack — most founded just 1–3 years ago. This shows we’re still very early in this industry.
Among the many Crypto AI startup landscape maps I’ve seen, the most comprehensive and up-to-date version is maintained by Casey and her team at topology.vc. It’s an essential resource for anyone tracking this space.
As I dig deeper into each sub-sector of Crypto AI, I keep asking: How big is the opportunity here? I’m not interested in niche markets — I’m looking for massive opportunities that can scale into hundreds of billions of dollars.
- Market Size
When assessing market size, I ask: Is this sub-sector creating a new market or disrupting an existing one?
Take decentralized compute as a classic example of disruption. We can estimate its potential by looking at the existing cloud computing market, currently valued at ~$680 billion, projected to reach $2.5 trillion by 2032.
In contrast, entirely new markets like AI agents are harder to quantify. Without historical data, we rely on intuition about problem-solving capabilities and reasonable extrapolation. But beware — sometimes products that appear to create new markets are actually “solutions in search of problems.”
- Timing
Timing is everything. While technology generally improves and becomes cheaper over time, progress happens at vastly different speeds across domains.
How mature is the technology in a given sub-sector? Is it ready for mass adoption, or still in research phase, years away from practical use? Timing determines whether a field deserves immediate attention or should be watched from afar.
Take Fully Homomorphic Encryption (FHE): Its potential is undeniable, but current performance is too slow for widespread use. We may need several more years before it goes mainstream. Therefore, I prioritize areas where technology is nearing mass adoption, focusing my time and energy on opportunities gaining momentum.
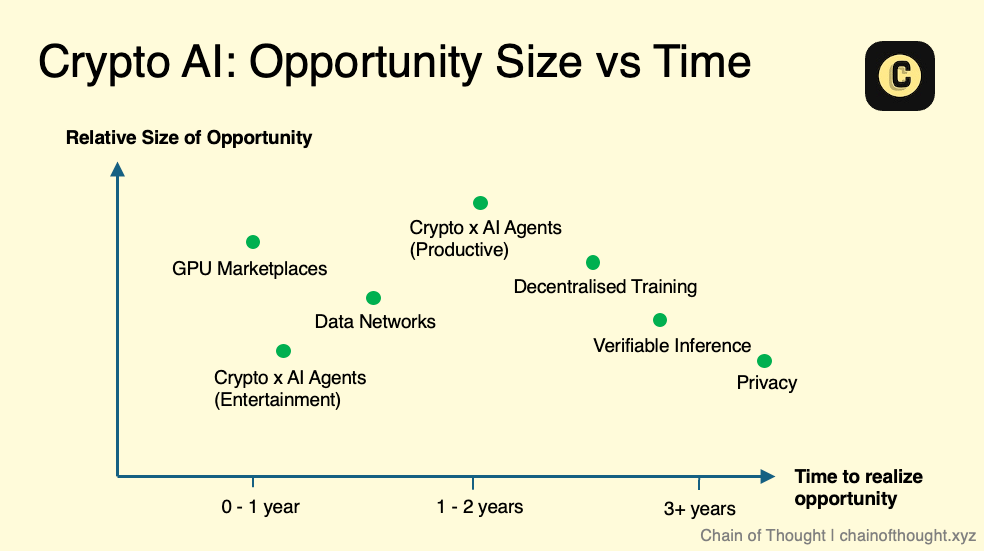
If we plot these sub-sectors on a “market size vs. timing” chart, it might look something like this. Note: this is a conceptual sketch, not a strict guide. Complexity exists within each area — e.g., in verifiable inference, different approaches (zkML vs. opML) are at varying stages of technical maturity.
Still, I firmly believe AI’s future scale will be enormous. Even areas that seem “niche” today could evolve into major markets tomorrow.
At the same time, we must recognize technological progress isn’t always linear — it often advances in leaps. When breakthroughs occur, my views on market timing and size will shift accordingly.
With this framework in mind, let’s now unpack each Crypto AI sub-sector to explore their growth potential and investment opportunities.
Area 1: Decentralized Compute
Summary
- Decentralized compute is the foundational pillar of decentralized AI.
- GPU markets, decentralized training, and decentralized inference are tightly linked and co-evolve.
- Supply primarily comes from small-to-medium data centers and consumer-grade GPU devices.
- Demand is currently small but growing, mainly consisting of price-sensitive, low-latency-tolerant users and smaller AI startups.
- The biggest challenge facing Web3 GPU markets today is making these networks truly efficient.
- Coordinating GPU usage in decentralized networks requires advanced engineering and robust network architecture.
1.1 GPU Markets / Compute Networks
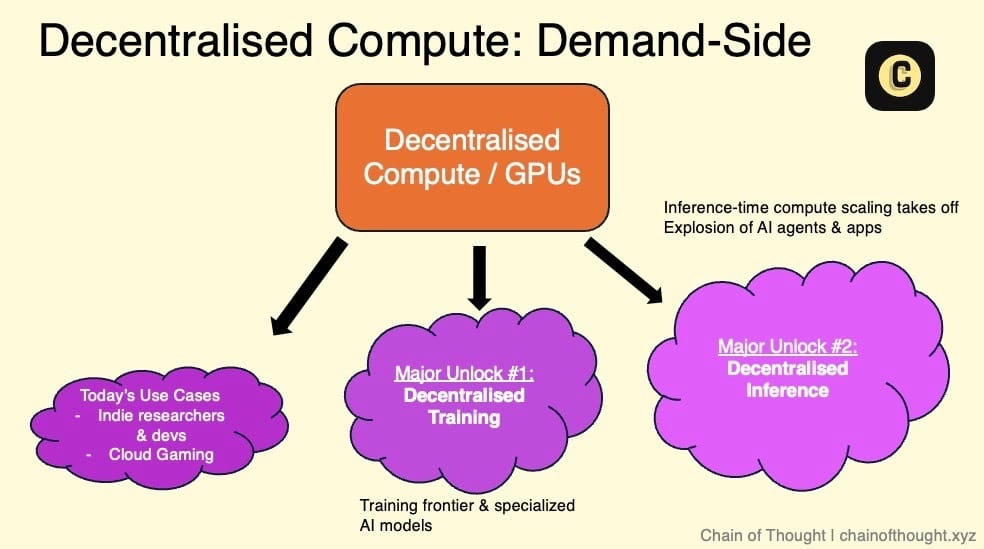
Currently, some Crypto AI teams are building decentralized GPU networks to tap into the vast pool of underutilized global compute resources, addressing the reality that demand for GPUs far exceeds supply.
The core value proposition of these GPU markets can be summarized in three points:
- Compute costs can be up to 90% lower than AWS. This cost advantage stems from eliminating intermediaries and opening up supply. These markets give users access to the lowest marginal-cost compute globally.
- No long-term contracts, no KYC, no approval delays.
- Censorship resistance.
To solve for supply, these markets source compute from the following:
- Enterprise GPUs: High-performance GPUs like A100s and H100s, typically from small-to-medium data centers (which struggle to find enough customers independently), or from Bitcoin miners diversifying income. Some teams are also leveraging government-funded large-scale infrastructure projects that build massive data centers as part of tech development. Suppliers are incentivized to keep GPUs connected to offset depreciation.
- Consumer GPUs: Millions of gamers and home users connect their PCs to the network and earn tokens.
Current demand in decentralized compute includes:
- Price-sensitive, latency-tolerant users: Researchers or independent AI developers on tight budgets who prioritize cost over real-time processing. They often can’t afford traditional cloud providers like AWS or Azure. Targeted marketing to this group is crucial.
- Small AI startups: Need flexible, scalable compute without long-term contracts. Attracting them requires strong business development, as they actively seek alternatives to traditional cloud.
- Crypto AI startups: Building decentralized AI products but lack their own compute, so they rely on these networks.
- Cloud gaming: Less directly related to AI, but demand for GPU resources is rising fast.
One key takeaway: Developers always prioritize cost and reliability.
The Real Challenge: Demand, Not Supply
Many startups treat GPU supply network size as a success metric, but this is merely a vanity metric.
The real bottleneck is demand, not supply. Success should be measured not by how many GPUs are in the network, but by GPU utilization and actual rentals.
Token incentives are effective at bootstrapping supply and quickly attracting resources. But they don’t directly solve weak demand. The real test is whether the product is good enough to unlock latent demand.
As Haseeb Qureshi (Dragonfly) put it, that’s the crux.
Making Compute Networks Actually Work
The biggest challenge for Web3 distributed GPU markets today is making these networks truly efficient.
This is no simple task.
Coordinating GPUs in a distributed network is extremely complex, involving multiple technical hurdles: resource allocation, dynamic workload scaling, node and GPU load balancing, latency management, data transfer, fault tolerance, and handling diverse hardware spread globally. These challenges compound, creating massive engineering barriers.
Solving this requires exceptional engineering talent and a robust, well-designed network architecture.
To understand this better, consider Google’s Kubernetes system. Widely seen as the gold standard in container orchestration, Kubernetes automates tasks like load balancing and scaling in distributed environments — challenges very similar to those faced by distributed GPU networks. Notably, Kubernetes was built on over a decade of Google’s distributed computing experience and took years of iteration to perfect.
Today, some live GPU compute markets handle small workloads, but struggle when scaling up — possibly due to fundamental architectural flaws.
Trustworthiness: Challenges and Opportunities
Another critical issue for decentralized compute networks is ensuring node trustworthiness — i.e., verifying that each node delivers the compute it claims. Currently, this relies mostly on reputation systems, with providers ranked by scores. Blockchain has a natural advantage here, enabling trustless verification. Startups like Gensyn and Spheron are exploring trustless solutions.
Many Web3 teams are still grappling with these challenges — meaning the opportunity space remains wide open.
Market Size of Decentralized Compute
So how big is the decentralized compute market?
Currently, it’s likely just a tiny fraction of the global cloud computing market (~$680B–$2.5T). Yet, as long as decentralized compute is cheaper than traditional providers, demand will exist — even with added UX friction.
I believe decentralized compute will remain cost-advantaged in the short-to-medium term, thanks to token subsidies and unlocked supply from non-price-sensitive users. For example, if I can rent out my gaming laptop for $20–$50/month, I’d be happy.
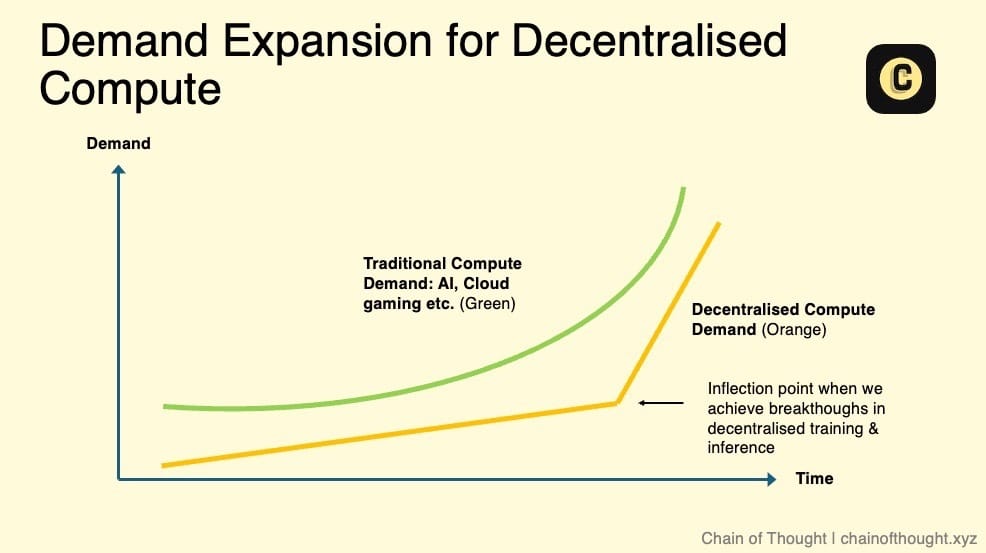
The true growth potential and significant expansion of decentralized compute depend on several key factors:
- Feasibility of decentralized AI model training: Massive demand will emerge when decentralized networks can support AI model training.
- Explosion in inference demand: As AI inference demand surges, existing data centers may fail to keep up. This trend is already visible. NVIDIA’s Jensen Huang says inference demand could grow by a "billion-fold."
- Introduction of SLAs: Currently, decentralized compute operates on a “best-effort” basis, leaving users uncertain about uptime and service quality. With SLAs, networks can offer standardized reliability and performance, removing a key barrier for enterprise adoption and making decentralized compute a viable alternative to traditional cloud.
Decentralized, permissionless compute is the foundational layer and one of the most critical infrastructures for the decentralized AI ecosystem.
Despite ongoing expansion in GPU and hardware supply chains, I believe we’re still at the dawn of the “human intelligence era.” Future demand for compute will be insatiable.
Watch for key inflection points that could trigger repricing in the GPU market — they may come sooner than expected.
Other Notes:
- Pure GPU markets are highly competitive, not only between decentralized platforms but also against emerging Web2 AI neo-cloud platforms like Vast.ai and Lambda.
- Small nodes (e.g., 4 H100 GPUs) have limited utility and low demand. But finding suppliers of large clusters is nearly impossible due to strong demand.
- Will decentralized protocol compute supply consolidate under a dominant player, or remain fragmented across multiple markets? I lean toward consolidation, expecting a power-law distribution, as integration improves infrastructure efficiency. But this will take time, and fragmentation will persist in the interim.
- Developers want to focus on building apps, not wrestling with deployment and configuration. Compute markets must simplify these complexities and minimize friction for users accessing compute.
1.2 Decentralized Training
Summary
- If Scaling Laws hold, training next-gen frontier AI models in a single data center may soon become physically impossible.
- Training AI models requires heavy GPU-to-GPU data transfer; slow interconnects in distributed GPU networks are the main technical bottleneck.
- Researchers are exploring multiple solutions, achieving breakthroughs (e.g., Open DiLoCo, DisTrO). These innovations will compound, accelerating decentralized training.
- The future of decentralized training may lie more in small, domain-specific models than AGI-frontier models.
- With the rise of models like OpenAI’s o1, inference demand will explode, creating massive opportunities for decentralized inference networks.
Imagine a world-changing AI model not developed in a secret top-tier lab, but collectively trained by millions of ordinary people. Gamers’ GPUs aren’t just rendering flashy scenes in Call of Duty — they’re powering something greater: an open-source, collectively-owned AI model, free from centralized gatekeepers.
In this future, foundational-scale AI models are no longer the exclusive domain of elite labs — they’re a collective achievement.
But back to reality: Most heavyweight AI training still happens in centralized data centers, and this likely won’t change soon.
Companies like OpenAI are expanding their massive GPU clusters. Elon Musk recently revealed that xAI is completing a data center with the equivalent of 200,000 H100 GPUs.
But it’s not just about GPU count. Google’s 2022 PaLM paper introduced a key metric — Model FLOPS Utilization (MFU) — measuring actual GPU compute usage versus theoretical maximum. Surprisingly, MFU is often only 35–40%.
Why so low? While GPU performance races ahead via Moore’s Law, improvements in networking, memory, and storage lag far behind, creating severe bottlenecks. GPUs often sit idle, waiting for data.
The sole reason for AI training centralization is efficiency.
Training large models relies on key techniques:
- Data Parallelism: Splitting datasets across multiple GPUs to speed up training.
- Model Parallelism: Distributing model parts across GPUs to overcome memory limits.
These require frequent GPU-to-GPU data exchange, making interconnect speed (data transfer rate) critical.
When training frontier AI models costs up to $1 billion, every bit of efficiency matters.
Centralized data centers use high-speed interconnects for rapid data transfer, significantly reducing training time and cost — something decentralized networks can’t match… yet.
Overcoming Slow Interconnects
Talk to AI practitioners, and many will say decentralized training simply won’t work.
In decentralized architectures, GPU clusters aren’t co-located, leading to slower data transfer — the main bottleneck. Training requires constant synchronization and data exchange between GPUs. Greater distance means higher latency. Higher latency means slower training and higher costs.
A task taking days in a centralized data center might take two weeks in a decentralized setup — at higher cost. Clearly not feasible.
But this is changing.
Excitingly, research in distributed training is heating up. Multiple fronts are being explored simultaneously — evidenced by a surge in papers and studies. These advances will compound, accelerating decentralized training.
Real-world testing in production environments is also crucial to push beyond current limits.
Some decentralized training techniques already work for smaller models in low-bandwidth settings. Frontier research aims to scale these to larger models.
- For instance, Prime Intellect’s Open DiLoCo paper proposes a practical method: grouping GPUs into “archipelagos,” each doing 500 local steps before syncing, reducing bandwidth needs by 500x. Originally a Google DeepMind study on small models, it’s now scaled to train a 10-billion-parameter model — fully open-sourced.
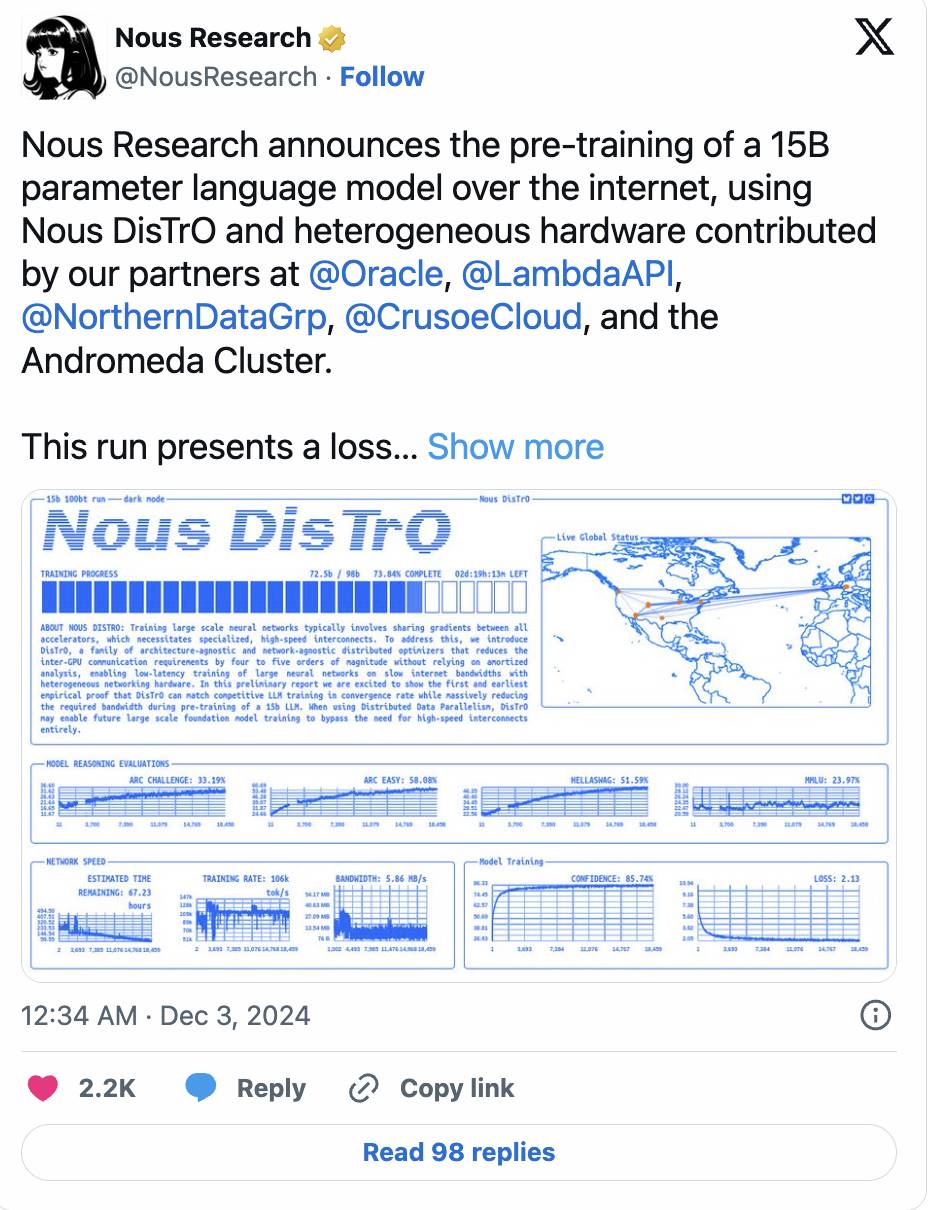
- Nous Research’s DisTrO framework pushes further, reducing GPU communication needs by up to 10,000x via optimizer techniques, successfully training a 1.2-billion-parameter model.
- Momentum continues: Nous recently announced pre-training completion of a 15-billion-parameter model, with loss curves and convergence outperforming traditional centralized training.
- Methods like SWARM Parallelism and DTFMHE are also exploring training ultra-large AI models across diverse devices with varying speeds and connectivity.
Another challenge is managing diverse GPU hardware, especially consumer-grade GPUs common in decentralized networks, which often have limited memory. Model parallelism (splitting model layers across devices) is helping solve this.
The Future of Decentralized Training
Currently, decentralized training methods lag far behind frontier models (GPT-4 reportedly near 1T parameters, 100x Prime Intellect’s 10B). True scalability requires breakthroughs in model architecture, network infrastructure, and task scheduling.
But imagine: decentralized training might one day aggregate more GPU power than the largest centralized data center.
Pluralis Research (a team worth watching in this space) believes this isn’t just possible — it’s inevitable. Centralized data centers face physical limits: space and power supply. Decentralized networks can tap into nearly infinite global resources.
Even NVIDIA’s Jensen Huang suggests asynchronous decentralized training could unlock AI’s scaling potential. Distributed training networks also offer stronger fault tolerance.
Thus, one possible future: the world’s most powerful AI models are trained in a decentralized way.
This vision is exciting, but I remain cautious. We need stronger evidence that decentralized training of ultra-large models is technically and economically viable.
I believe decentralized training’s sweet spot may lie in smaller, specialized open-source models tailored for specific applications — not competing with giant AGI-targeted frontier models. Certain architectures, especially non-Transformer models, are already proving well-suited for decentralized environments.
Token incentives will also play a key role. Once large-scale decentralized training becomes feasible, tokens can effectively reward contributors and drive network growth.
Though the road is long, current progress is encouraging. Breakthroughs in decentralized training will benefit not just decentralized networks, but also Big Tech and top AI labs…
1.3 Decentralized Inference
Currently, most AI compute is focused on training large models. Top AI labs are in an arms race to develop the strongest base models and achieve AGI.
But I believe this compute concentration on training will gradually shift toward inference in the coming years. As AI integrates into everyday apps — from healthcare to entertainment — the compute needed for inference will become enormous.

This isn’t speculative. Inference-time compute scaling is now a hot topic in AI. OpenAI recently previewed its latest model o1 (“Strawberry”), notable for “thinking before answering”: analyzing required steps, then executing them sequentially.
Designed for complex, planning-heavy tasks like solving crosswords, it handles deep-reasoning queries. Though slower, responses are more thoughtful. However, this comes at high cost — inference is 25x more expensive than GPT-4.
This signals that AI’s next leap won’t just come from bigger models, but from scaling compute during inference.
For deeper insights, several studies show:
- Scaling inference compute via repeated sampling yields significant performance gains across many tasks.
- Inference also follows an exponential scaling law.
Once powerful AI models are trained, their inference tasks (real-world use) can be offloaded to decentralized compute networks. This is attractive because:
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News
Add to FavoritesShare to Social Media














