

ポッドキャストノート|Gensyn創業者との対談:分散型ネットワークを活用して遊休コンピューティングリソースを最大限に活用し、機械学習を支援
TechFlow厳選深潮セレクト
ポッドキャストノート|Gensyn創業者との対談:分散型ネットワークを活用して遊休コンピューティングリソースを最大限に活用し、機械学習を支援
ブロックチェーンは、多数の参加者間で合意を形成できるため、単一の意思決定者や仲裁者を必要としない仕組みを提供する。
整理 & 編集:Sunny、TechFlow
ブロックチェーンAI計算プロトコルGensynは6月12日、a16z主導による4300万ドルのシリーズA資金調達を実施したことを発表しました。
Gensynの使命は、ユーザーが独自のコンピューティングクラスターを持つことと同等のスケールで計算リソースにアクセスできるようにすることであり、特に中央集権的な主体による管理や停止から自由な公平なアクセスを実現することです。同時にGensynは、機械学習モデルのトレーニングに特化した分散型コンピューティングプロトコルです。
昨年末にGensyn創業者Harry氏とBen氏がEpicenterのポッドキャストで語った内容を振り返ると、AWS、オンプレミスインフラ、クラウドインフラなど、さまざまな計算リソースについて詳細に調査し、AIアプリケーションの発展を支えるための最適なリソース活用方法について議論しています。
また、Gensynの設計思想、目標、市場ポジショニング、および設計プロセスにおける制約条件、前提仮定、実行戦略についても詳しく説明しています。
ポッドキャストでは、Gensynのオフチェーンネットワークに存在する4つの主要な役割、オンチェーンネットワークの特徴、ならびにGensynのトークンとガバナンスの重要性について紹介されています。
さらにBen氏とHarry氏は、人工知能の基礎原理と応用に関する興味深い知識も共有しており、AIへの理解を深めるのに役立ちます。

司会:Dr. Friederike Ernst、Epicenter ポッドキャスト
ゲスト:Ben Fielding & Harry Grieve、Gensyn 共同創業者
元タイトル:『Ben Fielding & Harry Grieve: Gensyn – The Deep Learning Compute Protocol』
放送日:2022年11月24日
ブロックチェーンを分散型AIインフラの信頼層として
司会者は、Ben氏とHarry氏がAIおよびディープラーニングの豊富な経験をどうしてブロックチェーンと組み合わせたのか尋ねました。
Ben氏は、この決定は一朝一夕のものではなく、比較的長い時間をかけて導き出されたものだと述べています。Gensynの目標は大規模なAIインフラを構築することであり、最大限の拡張性を実現する方法を探る中で、信頼不要なレイヤーが必要であることに気づいたのです。
新たなプロバイダーの集中接続に依存せずに計算能力を統合できる仕組みが必要でしたが、その場合、行政的な拡張の制限に直面します。この問題を解決するために彼らは検証可能計算(verifiable computation)研究を探索しましたが、そこには常に信頼された第三者または審査官が必要でした。
この制限により、彼らはブロックチェーンへと向かいました。ブロックチェーンは単一の意思決定者や仲裁者を必要としない仕組みを提供し、大人数間での合意形成を可能にします。
Harry氏も自身の考えを共有し、彼とBen氏は言論の自由を強く支持しており、検閲制度に対して懸念を抱いていると述べました。
ブロックチェーンに注目する前、彼らはフェデレーテッドラーニングという分野を研究していました。これは、複数の分散データソース上で複数のモデルを訓練し、それらを統合することで、すべてのデータソースから学習できるメタモデルを構築するディープラーニング技術です。銀行との共同プロジェクトでもこのアプローチを試みました。しかしすぐに、これらのモデルを訓練可能な計算リソース(処理装置)を確保することがより大きな課題であることに気づきました。
計算リソースを最大化して統合するには、分散型の調整手段が必要であり、そこにブロックチェーンの出番があります。
市場の計算リソース調査:AWS、オンプレミス、クラウドインフラ
Harry氏は、AIモデルを実行する際の異なる計算リソース選択肢について、モデルの規模によって変わると説明しました。
学生はAWSやローカルマシンを使用するかもしれません。スタートアップ企業は、オンデマンドのAWSまたは予約型の安価なプランを選ぶでしょう。
しかし、大規模なGPU需要においては、AWSはコストと拡張性の制限に直面しやすく、多くの場合は自社内にインフラを構築する選択になります。
調査によると、多くの組織がスケールアップに苦労しており、一部はGPUを購入し自ら管理するまでになっています。長期的には、AWSで運用するよりもGPUを購入する方が費用対効果が高いのです。
機械学習の計算リソースには、クラウドコンピューティング、ローカルでのAIモデル実行、または自前のコンピューティングクラスターの構築があります。Gensynの目標は、自社クラスターを持つのと同等の計算規模へのアクセスを提供し、重要なのはそれが中央集権的な主体によって制御されたり遮断されたりしない公平なアクセスであること。

表一:現在市場にあるすべての計算リソース選択肢
Gensynの設計理念、目標、市場ポジショニングについて
司会者は、GensynとGolem Networkのような過去のブロックチェーンコンピューティングプロジェクトとの違いについて質問しました。
Harry氏は、Gensynの設計理念は主に以下の2つの軸に基づいていると説明しました:
-
プロトコルの細分化:Golemのような汎用計算プロトコルとは異なり、Gensynは機械学習モデルのトレーニングに特化した細分化されたプロトコルです。
-
検証の拡張性:初期のプロジェクトは評判システムやビザンチン障害に弱い複製方式に依存しており、機械学習の結果に対する信頼性が十分ではありませんでした。Gensynは、暗号世界の計算プロトコルの知見を活かし、それを機械学習に特化して適用することで、速度とコストの最適化を図りつつ、満足できるレベルの検証を実現することを目指しています。
Harry氏はさらに補足し、ネットワークが備えるべき性質について強調しました。それは機械学習エンジニアや研究者向けであること。検証機能が必要ですが、最も重要なのは誰でも参加できる点であり、検閲耐性を持ち、ハードウェアに対して中立的である必要があります。
設計プロセスにおける制約、前提、実行
Gensynのプラットフォーム設計において、Ben氏はシステムの制約と前提の重要性を強調しました。目標は世界全体をAIスーパーコンピューターに変えるネットワークを創ることであり、そのためには製品上の仮定、研究上の仮定、技術上の仮定のバランスを取る必要があります。
なぜGensynを独自の第1層ブロックチェーンとして構築するのかという問いに対し、彼らはコンセンサス機構などのキーテクノロジー分野において柔軟性と意思決定の自由度を保つためだと答えました。将来プロトコルを証明できるようにしたいと考えており、早期段階で不必要な制限を課すつもりはありません。また、将来的には異なるチェーンが広く受け入れられる通信プロトコルを通じて相互作用すると信じており、そのビジョンにも合致しています。
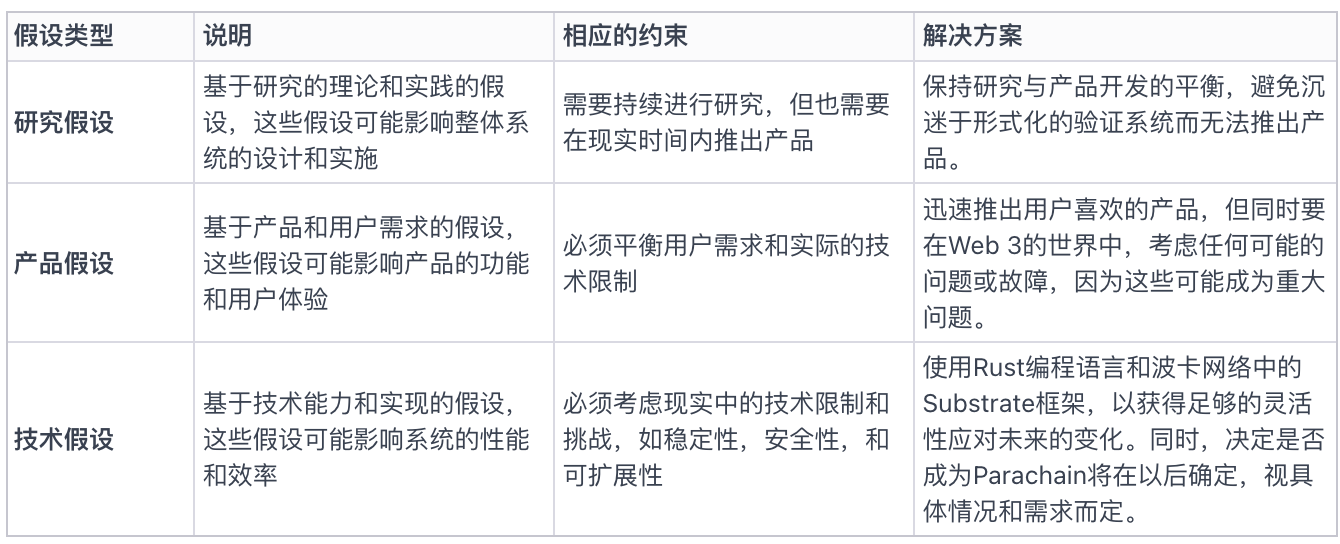
図二:製品仮定、研究仮定、技術仮定、制約と実行
Gensynオフチェーンネットワークの4つの主要な役割
今回のGensyn経済構造の議論では、提出者(Submitter)、作業者(Worker)、検証者(Verifier)、通報者(Whistleblower)という4つの主要な役割が紹介されました。提出者は、特定の画像生成や自動運転車両用AIモデル開発といったさまざまなタスクをGensynネットワークに提出できます。
提出者(Submitter)によるタスクの提出
Harry氏は、Gensynを使ってモデルを訓練する方法を説明しました。まずユーザーは期待される成果を定義します。例えば、テキストプロンプトに基づいて画像を生成する場合、テキストを入力として画像を出力するモデルを構築します。訓練データはモデルの学習と改善にとって極めて重要です。モデルアーキテクチャと訓練データの準備が終わったら、学習率スケジュールや訓練期間などのハイパーパラメータとともにGensynネットワークに提出します。この訓練プロセスの結果として得られるのが訓練済みモデルであり、ユーザーはこれをホスティングし利用できます。
未訓練モデルの選択方法について尋ねられたHarry氏は、2つのアプローチを提示しました。
-
1つ目は、現在主流のベースモデル概念に基づくもので、OpenAIやMidjourneyのような大手企業がベースモデルを構築し、ユーザーがそのベースモデルを特定データで再訓練する方法です。
-
2つ目は、ベースモデルを使わずゼロからモデルを構築する方法です。
Gensynでは、開発者が進化的最適化手法に類似した方法でさまざまなアーキテクチャを提出し、訓練・テストを行いながら理想的なモデルを継続的に最適化できます。
Ben氏は、ベースモデルこそがこの分野の未来だと考えると述べました。
Gensynというプロトコルは、進化的最適化や類似技術を使うDAppsが利用できるようにすることを目指しています。こうしたDAppsは個別のアーキテクチャをGensynプロトコルに提出し、訓練・テストを繰り返して理想のモデルを精錬できます。
Gensynの目標は純粋な機械学習計算基盤を提供し、その周辺にエコシステムを育成することです。
ただし事前訓練済みモデルは、特定組織が専有データセットを使ったり訓練プロセスを隠蔽したりすることで偏りを生む可能性があります。Gensynの解決策は訓練プロセスをオープンにすることであり、ブラックボックスを完全に排除するか全確定性に依存するわけではありません。集団で設計・訓練されたベースモデルにより、特定企業のデータセットによる偏りのないグローバルモデルを構築できます。
作業者(Solver)
-
タスクの割り当てでは、1つのタスクに対して1台のサーバーが対応します。ただし1つのモデルが複数のタスクに分割されることがあります。
-
大規模言語モデルは設計時に当時の最大限のハードウェア容量を活用するようになっています。この概念はネットワークに拡張でき、デバイスの異種混合性を考慮できます。
-
検証者や作業者のような特定タスクについては、Mempoolから引き受けることも可能です。タスクを引き受けたいと表明した人の中からランダムに1人の作業者が選ばれます。モデルやデータが特定デバイスに適合しなくても所有者が対応可能と主張すれば、ネットワーク混雑によりペナルティが科される可能性があります。
-
あるタスクが特定マシンで実行可能かどうかは、利用可能な作業者サブセットから1人を選択する検証可能な乱数関数によって決まります。
-
作業者の能力検証に関しては、もし作業者が主張する計算能力を持っていなければ、計算タスクを完了できず、証明提出時に検出されます。
-
しかしタスクサイズは問題です。大きすぎるとDoS攻撃(サービス拒否攻撃)のようなシステム問題を引き起こす可能性があり、作業者がタスク完了を宣言しても永遠に完了させず、時間とリソースを浪費するリスクがあります。
-
したがってタスクサイズの決定は極めて重要であり、並列化やタスク構造の最適化などを考慮する必要があります。研究者たちはさまざまな制約下での最適な方法を積極的に研究しています。
-
テストネットが開始されれば、実際の状況も考慮し、システムが現実世界でどのように動作するかを観察します。
-
完璧なタスクサイズを定義するのは困難であり、Gensynは現実のフィードバックと経験に基づき調整・改善する準備ができています。
オンチェーンでの大規模計算の検証メカニズムとチェックポイント (Checkpoints)
Harry氏とBen氏は、計算の正しさを検証することが大きな課題であると指摘しています。ハッシュ関数のように決定的ではないため、ハッシュ検証だけで計算が行われたかどうかを判断できません。この問題を解決する理想の方法は、計算全体の過程にゼロ知識証明を応用することです。現在、Gensynはこの能力の実現に向けて努力しています。
現時点では、Gensynはチェックポイントを用いたハイブリッド方式を採用し、確率的手法とチェックポイントで機械学習計算を検証しています。ランダム監査スキームと勾配空間パスを組み合わせることで、比較的堅牢なチェックを構築できます。さらに、検証プロセスの強化のためにゼロ知識証明も導入されており、モデルのグローバル損失にも応用されています。
検証者(Verifier)と通報者(Whistleblower)
司会者とHarry氏は、検証プロセスに関与する2つの追加の役割、すなわち検証者(Verifier)と通報者(whistleblower)について議論しました。それぞれの具体的な責任と役割について詳しく説明しています。
検証者の任務はチェックポイントの正確性を保証すること、通報者の任務は検証者が正確に職務を果たしているかを確認することです。通報者は検証者のジレンマ問題を解決し、検証者の作業が正確かつ信頼できることを保証します。検証者は意図的に誤りを挿入し、通報者がそれを見つけ出すことで、検証プロセスの完全性を維持します。
検証者は通報者の警戒心を試し、システムの有効性を確保するために意図的に誤りを挿入します。作業に誤りがあれば、検証者はそれを検出し通報者に通知します。誤りはその後ブロックチェーン上に記録され、オンチェーンで検証されます。定期的かつシステムの安全性に関連した頻度で、検証者は意図的に誤りを挿入し、通報者の参加を促します。通報者が問題を発見した場合、「pinpoint protocol」と呼ばれるゲームに参加し、計算をニューラルネットワークの特定領域のMerkleツリー内の具体的なポイントまで絞り込むことができます。この情報はオンチェーンの裁定に提出されます。これは検証者と通報者のプロセスの簡易版であり、シードラウンド終了後にさらなる開発と研究が行われる予定です。
Gensynオンチェーンネットワーク
Ben氏とHarry氏は、Gensyn協調プロトコルがオンチェーンでどのように機能し実装されるかについて詳細に説明しました。まず、ネットワークブロックを構築するプロセスについて触れ、その一部としてステーキングトークンが関与していることを述べました。そして、これらの構成要素がGensynプロトコルとどのように関係しているかを説明しました。
Ben氏は、Gensynプロトコルは基本的にvanilla substrateポルカドットネットワークプロトコルに基づいていると説明しました。彼らは权益証明(PoS)に基づくGrandpa Babeコンセンサスメカニズムを採用しており、検証者は通常通り動作します。しかし、前述したすべての機械学習コンポーネントはオフチェーンで行われており、さまざまなオフチェーン参加者が各自のタスクを実行しています。
これらの参加者はステーキングによってインセンティブを得ており、Substrateのステーキングモジュールを通じて、あるいはスマートコントラクト内で一定量のトークンを預けることでステーキングできます。作業が最終的に検証されると報酬を受け取ります。
Ben氏とHarry氏が言及した課題は、ステーキング額、潜在的な罰則額、報酬額のバランスを保ち、怠惰または悪意のある行動を促さないようにすることです。
さらに、通報者の増加がもたらす複雑さについても議論しましたが、スケーリング計算の必要性から、彼らの存在は検証者の誠実性を保証するために不可欠です。ゼロ知識証明技術によって通報者を排除できる可能性を常に模索しています。現在のシステムはlite paperに記述されている内容と一致していますが、各側面を簡素化するための努力を続けています。
司会者がデータ可用性の解決策を持っているか尋ねたところ、Henry氏はsubstrate上にavailability proof(POA)と呼ばれるレイヤーを導入したと説明しました。このレイヤーは消散符号(erasure coding)などの技術を利用して、広範なストレージ市場で遭遇する制限を解決しています。すでにこのような解決策を実装している開発者には非常に興味があると述べました。
Ben氏は補足し、要件は訓練データの保存だけでなく、短期間だけ保持する中間証明データの保存も含まれると述べました。例えば、特定数のブロックをリリースした後は約20秒間保持すればよい場合もあります。しかし、Arweaveでは数百年前までの保存費用を支払っているため、こうした短期ニーズには不適切です。Arweaveと同じ保証と機能を持ちつつ、短期ストレージニーズに低コストで対応できる解決策を探しています。
Gensynトークンとガバナンス
Ben氏は、Gensynトークンがエコシステム内でステーキング、ペナルティ、報酬提供、コンセンサス維持などにおいて重要な役割を果たすと説明しました。主な目的は、システムの財務的合理性と完全性を確保することです。Ben氏は、検証者への支払いにインフレ率を慎重に使い、ゲーム理論的メカニズムを活用しているとも述べました。
彼はGensynトークンの純粋な技術的用途を強調し、技術的にトークン導入のタイミングと必要性を確保すると述べました。
Harry氏は、深層学習コミュニティの中でも少数派であり、特にAI学者の多くが暗号資産に対して広く疑念を抱いていると述べました。それでも、暗号資産の技術的・イデオロギー的価値を認識しています。
しかし、ネットワーク開始時には、大多数の深層学習ユーザーが取引に主に法定通貨を使用すると予想され、代金のトークン換算は裏でシームレスに行われます。
供給面では、作業者と提出者が積極的にトークン取引に参加するでしょう。また、大量のGPUリソースを持ち新たな機会を求めるイーサリアムマイナーからの関心も既に得ています。
ここで重要なのは、深層学習および機械学習の実務家が暗号資産用語(トークンなど)に対して抱く恐怖心を取り除き、それをユーザーエクスペリエンスのインターフェースから切り離すことです。Gensynは、Web 2とWeb 3の世界を結ぶ魅力的なユースケースだと考えており、経済的合理性とその存在を支える技術的基盤を兼ね備えています。
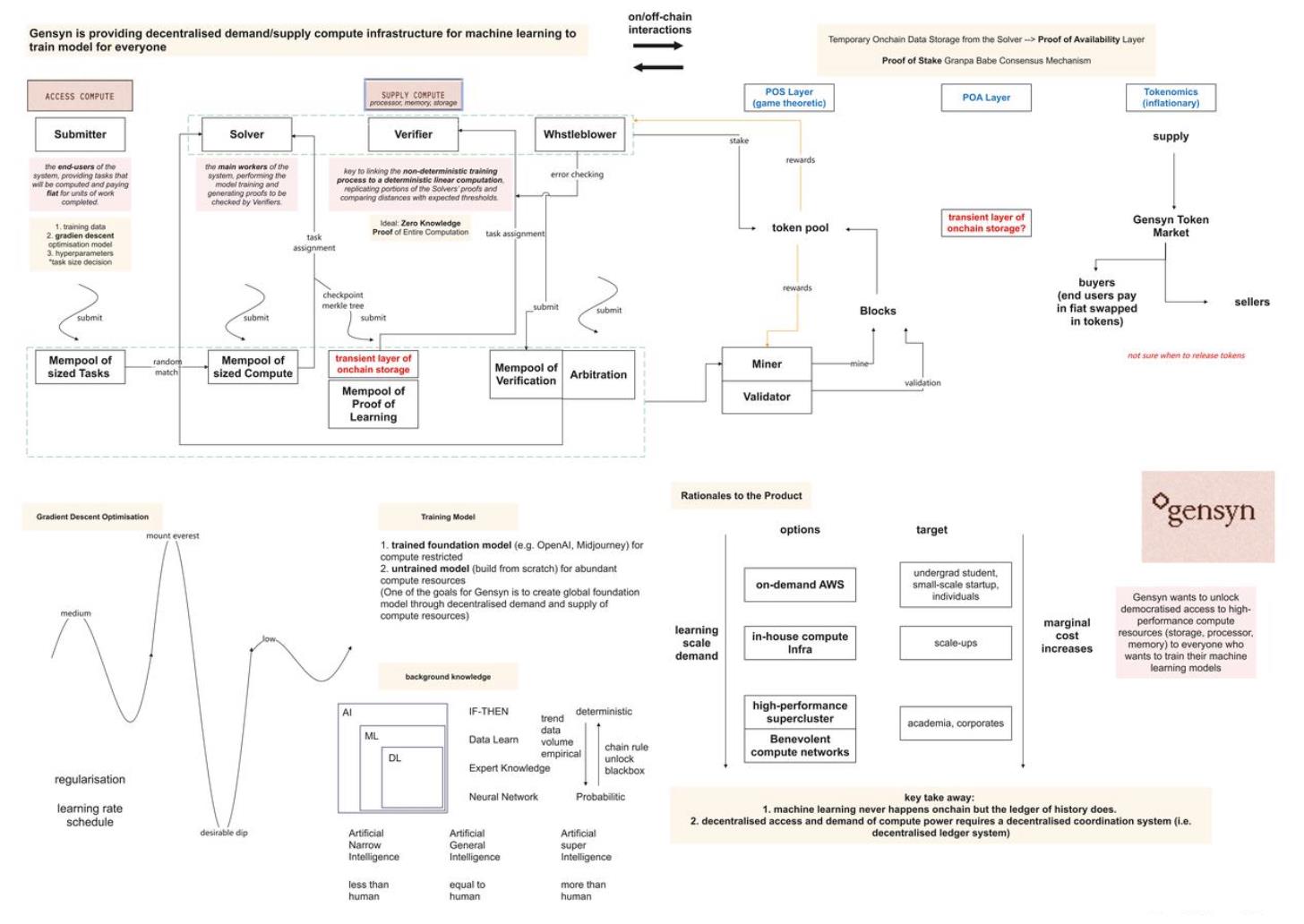
図一:ポッドキャスト内容から整理したGensynのオンチェーン・オフチェーンネットワークの運営モード(画像提供:TechFlow)。運営メカニズムに誤りがあれば、読者の皆様からご指摘をお願いいたします。
人工知能の基礎知識
AI、深層学習、機械学習
Ben氏は近年のAI分野の発展についての見解を述べました。AIおよび機械学習分野は過去7年間でいくつかの小さなブームを経験しましたが、現在の進歩は本当に影響を与え、価値あるアプリケーションを生み出し、より広い聴衆と共鳴できるようになっています。こうした変化の原動力となっているのが深層学習です。ディープニューラルネットワークは、従来のコンピュータービジョン手法が設定したベンチマークを越える能力を示しています。さらに、GPT-3などのモデルもこの進歩を加速させました。
Harry氏は、AI、機械学習、深層学習の違いについてさらに詳しく説明しました。これら3つの用語はよく混同されますが、明確な差があります。彼はこれをマトリョーシカに例え、AIが最も外側の層だと表現しました。
-
広義には、AIとは機械にタスクを実行させるようプログラミングすることです。
-
機械学習は1990年代から2000年代初頭に流行し始め、if-thenルールに依存するエキスパートシステムではなく、データを使って意思決定の確率を決定します。
-
深層学習は機械学習を基盤としつつ、より複雑なモデルを可能にします。

図三:人工知能、機械学習、深層学習の違い
狭義人工知能、汎用人工知能、超人工知能
このセクションでは、司会者とゲストが人工知能の3つの主要分野について深く議論しました:狭義人工知能(ANI)、汎用人工知能(AGI)、超人工知能(ASI)です。
-
狭義人工知能(Artificial Narrow Intelligence、ANI):現在のAIは主にこの段階にあり、特定のタスクを非常に得意としています。例えば、パターン認識を使って医学的スキャンから特定のがんタイプを検出するなどが該当します。
-
汎用人工知能(Artificial General Intelligence、AGI):AGIとは、人間にとっては簡単だが計算システムでは難しいタスクをこなせるようになることです。例えば、混雑した環境を安全にナビゲートしながら、周囲のすべての入力に対して独立した仮定を行う能力などです。AGIとは、日常的なタスクを人間のように遂行できるモデルまたはシステムを指します。
-
超人工知能(Artificial Super Intelligence、ASI):汎用人工知能を達成した後、機械はさらに進化して超人工知能になる可能性があります。これは、モデルの複雑性、計算能力の増加、無限の寿命、完璧な記憶により、人間の能力を超越する状態を意味します。この概念はSFやホラー映画でよく探求されています。
さらにゲストは、脳-機械インターフェースのような人間の脳と機械の融合がAGI達成の道の一つかもしれないが、これには倫理的・道徳的問題が伴うとも述べました。
深層学習のブラックボックスを解く:決定性と確率性
Ben氏は、深層学習モデルのブラックボックス性はその絶対的な大きさに起因すると説明しました。ネットワーク内の多数の意思決定ポイントを追跡することはできますが、そのパスが非常に巨大で、モデル内の重みやパラメータを特定の値に関連付けるのは困難です。なぜなら、これらの値は数百万のサンプルを入力した後に導き出されるからです。決定的に追跡することは可能で、すべての更新を追うことができますが、最終的に生成されるデータ量は非常に膨大になります。
彼は2つの傾向があると見ています:
-
構築中のモデルに対する理解が深まるにつれ、ブラックボックス性は徐々に薄れていく。深層学習は研究分野であり、基礎理論ではなく、「何ができるか」を試す大量の実験が行われるという興味深い急速な時期を経てきました。より多くのデータを投入し、新しいアーキテクチャを試して「どうなるか」を見るのであって、基本原理から設計し、正確に動作原理を把握するわけではないのです。そのため、すべてがブラックボックスだったワクワクする時代がありました。しかし、彼はこの急速な成長が落ち着き始め、人々がこれらのアーキテクチャを再検討し、「なぜこれがうまくいくのか?掘り下げて証明しよう」と言い始めており、ある意味でそのカーテンが開かれつつあると考えています。
-
もう一つの出来事はより議論を呼ぶかもしれませんが、計算システムが完全に決定的である必要があるのか、それとも我々は確率的な世界に生きることができるのかという見方の変化です。人間は確率的な世界に生きています。自動運転車の例が最も明確です。運転中、偶発的な出来事や小事故、システムの不具合が起こることを受け入れています。しかし、自動運転車については「完全に決定的でなければならない」と完全に否定します。自動運転車業界の課題の一つは、確率的メカニズムを自動運転車に適用すれば社会が受け入れると仮定したことですが、実際には人々は受け入れていません。彼はこの状況は変わるだろうと考えており、議論の余地があるのは、社会として確率的計算システムと共存することを許容するかどうかです。この道が順調に進むかは不明ですが、そうなるだろうと信じています。
勾配最適化法:深層学習の核心的最適化手法
勾配最適化は深層学習の中心的手法の一つであり、ニューラルネットワークの訓練において極めて重要な役割を果たします。ニューラルネットワークでは、一連の層のパラメータは実質的に実数です。ネットワークの訓練とは、これらのパラメータをデータが正しく伝播し、ネットワークの最終段階で望ましい出力を引き起こすような実際の値に設定することです。
勾配に基づく最適化手法は、ニューラルネットワークおよび深層学習分野で大きな変革をもたらしました。この手法では、ネットワーク各層のパラメータに対する誤差の微分である勾配を利用します。連鎖律を適用することで、勾配を全層にわたって逆方向に伝播できます。このプロセスにより、誤差曲面上での位置を特定できます。誤差はユークリッド空間内の曲面としてモデル化でき、高低が入り混じった地形のように見えます。最適化の目的は、誤差を最小化する領域を見つけることです。
勾配は各層に対して、その曲面上の位置とパラメータを更新すべき方向を示します。この起伏のある曲面をナビゲートし、誤差を減らす方向を見つけることができます。ステップの大きさは曲面の傾斜度に依存します。急であれば大きく飛び、緩やかであれば小さく飛びます。本質的に、この曲面をナビゲートして谷底を探す作業であり、勾配が位置と方向を教えてくれます。
この手法は大きな飛躍であり、勾配は明確な信号と有用な方向を提供するため、パラメータ空間でランダムにジャンプするよりもはるかに効率的に、自分が曲面のどこにいるか(山頂か谷底か平坦部か)を把握できます。
深層学習には最適解を見つけるための多くの技術がありますが、現実世界の状況は通常さらに複雑です。多くの深層学習訓練で使用される正則化技術により、これは科学というより芸術の領域になっています。そのため、勾配に基づく最適化の現実世界での応用は、正確な科学というより芸術に近いのです。
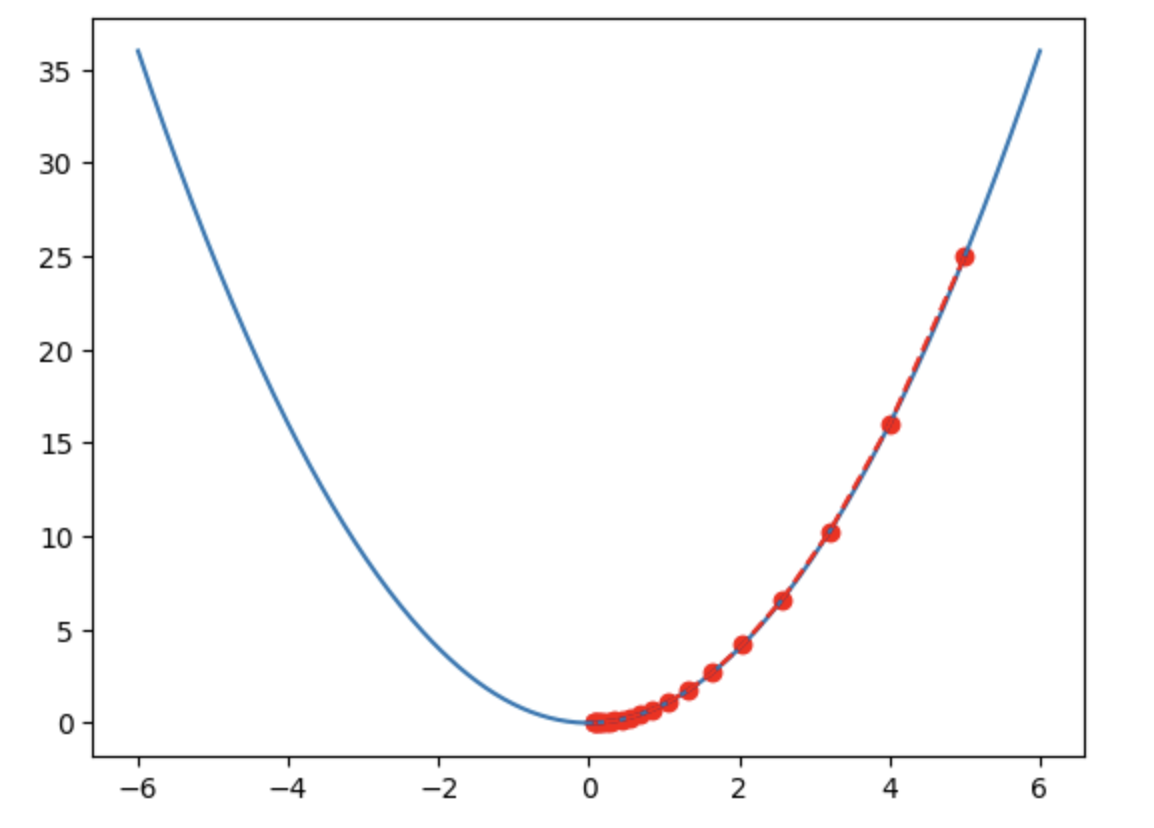
図二:簡単に言えば最適化の目標は谷底を見つけること(画像提供:TechFlow)
まとめ
Gensynの目標は、個人のスマートフォンやパソコンなど、使われていないまたは十分に活用されていない計算リソースを最大限に活用し、世界最大の機械学習計算リソースシステムを構築することです。
機械学習とブロックチェーンの文脈では、帳簿に記録されるのは通常、計算結果、つまり機械学習で処理済みのデータ状態です。この状態は「このデータは機械学習済みで有効、発生日時:X年X月」などとなります。この記録の主な目的は、計算プロセスの詳細を説明するのではなく、結果の状態を表現することです。
この枠組みにおいて、ブロックチェーンは重要な役割を果たします:
-
ブロックチェーンはデータ状態の結果を記録する手段を提供します。その設計により、データの真正性が保証され、改ざんや否認が防止されます。
-
ブロックチェーン内部には経済的インセンティブメカニズムがあり、これにより計算ネットワーク内の異なる役割(前述の4者:提出者、作業者、検証者、通報者)の行動を調整できます。
-
現在のクラウドコンピューティング市場を調査した結果、クラウドコンピューティングが完全に優れているわけではなく、各種計算方法にはそれぞれ固有の問題があることがわかりました。ブロックチェーンの分散型計算方式は特定の場面で役立ちますが、従来のクラウドコンピューティングを全面的に代替できるわけではなく、つまりブロックチェーンは万能の解決策ではありません。
-
最後に、AIは一種の生産力ですが、AIをいかに効果的に組織・訓練するかは生産関係の問題です。これには協働、クラウドソーシング、インセンティブなどが含まれます。この点で、Web 3.0は多くの解決策とシナリオを提供しています。
したがって、ブロックチェーンとAIの結合は、特にデータとモデルの共有、計算リソースの調整、結果の検証といった面で、AIの訓練と利用における課題の解決に新たな可能性を提供していると理解できます。
参考文献
1.https://docs.gensyn.ai/litepaper/
2.https://a16zcrypto.com/posts/announcement/investing-in-gensyn/
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














