
Vitalik: The future of different types of ZK-EVM
TechFlow Selected TechFlow Selected
Vitalik: The future of different types of ZK-EVM
would rather see improvements to ZK-EVM and Ethereum itself to make it more suitable for ZK-SNARKs, and there's no need for Ethereum to standardize around a single ZK-EVM implementation for L1 use.
Author: Vitalik
Translation: Block unicorn, Foresight News
Recently, there have been many high-profile announcements about "ZK-EVM" projects. Polygon opened up their ZK-EVM project, ZKSync released their ZKSync 2.0 plans, and the relatively new Scroll recently launched its ZK-EVM as well. There are also ongoing efforts from teams like Privacy and Scaling Explorations, Nicolas Liochon and others, including an alpha compiler from EVM to Starkware's zk-friendly language Cairo, and of course some projects I will miss.
The core goal shared by all these projects is the same: using ZK-SNARK technology to cryptographically prove execution of Ethereum-like transactions—either to make verifying the Ethereum chain itself easier, or to build zk rollups that provide nearly the same functionality as Ethereum but with greater scalability. However, there are subtle differences between these projects, and trade-offs they make between practicality and speed. This article will attempt to describe a taxonomy of different "types" of EVM equivalence, along with the benefits and costs of trying to achieve each type.
Overview (in chart form)
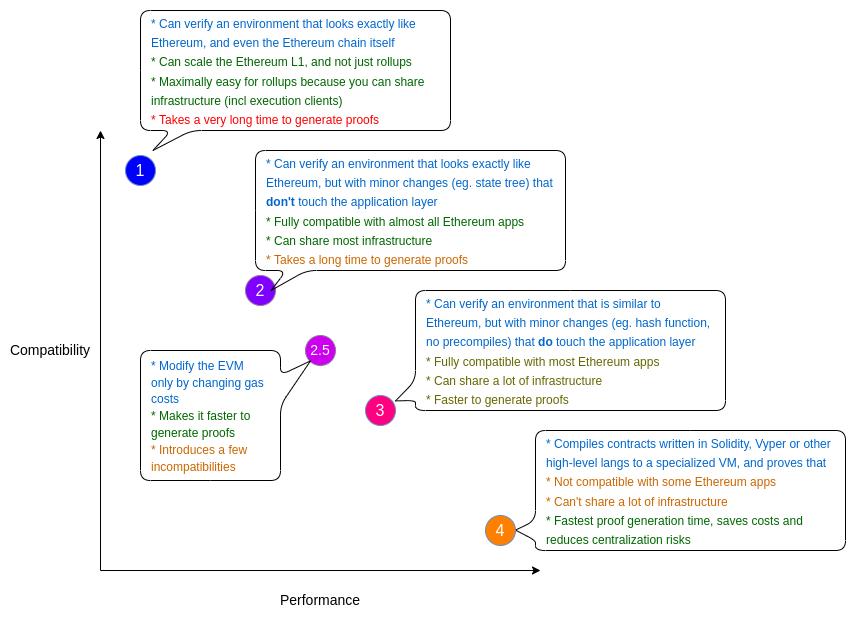
Type 1 (Fully Equivalent to Ethereum)
Type 1 ZK-EVMs aim for complete and uncompromising equivalence to Ethereum. They do not change any part of the Ethereum system to make proof generation easier. They do not replace hashes, state trees, transaction trees, precompiles, or any other consensus logic, no matter how peripheral it may seem.
Advantage: Perfect Compatibility
The goal is to be able to verify Ethereum blocks exactly as they are today—or at least verify the execution layer (so Beacon Chain consensus logic is excluded, but all transaction execution, smart contract, and account logic are included).
Type 1 ZK-EVMs are what we ultimately need to make Ethereum Layer 1 itself more scalable. In the long run, modifications tested out in Type 2 or Type 3 ZK-EVMs might be introduced into Ethereum itself, but such redesigns come with their own complexities.
Type 1 ZK-EVMs are also ideal for rollups because they allow reuse of large amounts of existing infrastructure. For example, Ethereum Execution clients can be used unchanged to generate and process rollup blocks (or at least, once withdrawals are implemented, they can be reused, and this functionality could support ETH deposited into rollups). Thus, block explorers, block production tools, and more become very easy to reuse.
Disadvantage: Proving Time
Ethereum was not originally designed around zk-friendliness, so many parts of the Ethereum protocol require significant computation to verify under zk proofs. The goal of Type 1 is to fully replicate Ethereum, so it cannot alleviate these inefficiencies. Currently, proving an Ethereum block takes many hours. This situation could be improved through clever engineering to massively parallelize provers, or in the long term via ASICs specialized for ZK-SNARKs.
Who Is Building It?
The Privacy and Scaling Explorations team’s ZK-EVM is building a Type 1 ZK-EVM.
Type 2 (Fully Equivalent to EVM)
Type 2 ZK-EVMs aim for full equivalence to the EVM, but not full equivalence to Ethereum. That is, they look exactly like Ethereum “from the inside,” but have some differences externally, particularly in data structures such as block format and state tree.
Their goal is full compatibility with existing applications, while making small modifications to Ethereum to ease development and enable faster proof generation.
Advantage: Full Equivalence at the Virtual Machine Level
Type 2 ZK-EVMs change data structures that store Ethereum state. Fortunately, these structures are not directly accessible by the EVM itself, so applications working on Ethereum almost always work on a Type 2 ZK-EVM rollup. You won’t be able to use Ethereum Execution clients out-of-the-box, but you can use them with minor modifications, and you can still use EVM debuggers and most other developer infrastructure.
However, there are a few exceptions. Incompatibility arises for applications that verify Merkle proofs of historical Ethereum blocks to confirm claims about past transactions, receipts, or state (e.g., bridges sometimes do this). A ZK-EVM replacing Keccak with a different hash function would break these proofs. Still, I generally advise against building apps this way, since future changes to Ethereum (e.g., Verkle Trees) would even break such apps on Ethereum itself. A better alternative for Ethereum would be adding reliable historical access precompiles that remain future-proof.
Disadvantage: Improved Proving Time, But Still Slow
Type 2 ZK-EVMs offer faster proving times than Type 1, primarily by removing parts of the Ethereum stack that rely on unnecessarily complex and zk-unfriendly cryptography. In particular, they may change Ethereum’s Keccak-based and RLP-encoded Merkle Patricia Tree, and possibly also block and receipt structures. Type 2 ZK-EVMs might use different hash functions, such as Poseidon. Another natural modification is altering the state tree to store code hashes and keccak values explicitly, eliminating the need to recompute hashes when handling EXTCODEHASH and EXTCODECOPY opcodes.
These changes significantly improve proving time, but they don’t solve everything. Due to inherent inefficiencies and zk-hostility in the EVM, proving the EVM exactly as-is remains slow. A simple example is memory: because MLOAD can read any 32-byte chunk, including “unaligned” ones (where start and end are not multiples of 32), MLOAD cannot simply be interpreted as reading one block; instead, it may need to read two consecutive blocks and perform bit operations to merge results.
Who Is Building It?
Scroll’s ZK-EVM project is moving toward a Type 2 ZK-EVM, as is Polygon Hermez. That said, neither project is complete yet (neither has finished ZK-EVM work); in particular, many more complex precompiles have not yet been implemented. Therefore, currently both projects are best considered Type 3.
Type 2.5 (Equivalent to EVM Except Gas Costs)
One way to significantly improve worst-case proving time is to greatly increase the gas cost of specific operations in the EVM that are particularly hard to prove. This could involve precompiles, KECCAK opcodes, or potentially certain calling conventions or patterns of accessing memory, storage, or calldata.
Changing gas costs may reduce compatibility with developer tools and break some applications, but it’s generally seen as less risky than deeper changes to the EVM. Developers should take care not to exceed block capacity in gas required per transaction, and avoid using hardcoded gas amounts in calls (which has long been standard advice for developers).
Type 3 (Almost Equivalent to EVM)
Type 3 ZK-EVMs are almost equivalent to the EVM, but make some sacrifices to further improve proving time and simplify EVM implementation.
Advantage: Easier to Build, Faster Proving Time
Type 3 ZK-EVMs may drop some features that are especially difficult to implement in a ZK-EVM. Here, precompiles often top the list; additionally, Type 3 ZK-EVMs sometimes have subtle differences in how they handle contract code, memory, or the stack.
Disadvantage: More Incompatibilities
The goal of Type 3 ZK-EVMs is compatibility with most applications, requiring minimal rewriting for the rest. However, some applications will need to be rewritten either because they use precompiles removed in Type 3 ZK-EVMs, or due to subtle dependencies on edge cases handled differently by the EVM.
Who Is Building It?
Scroll and Polygon in their current forms are both Type 3, though they hope to improve compatibility over time. Polygon has a unique design where they use ZK to verify their internal language zkASM, and implement ZK-EVM code interpretation via zkASM. Despite this implementation detail, I still consider it a true Type 3 ZK-EVM—it still verifies EVM code, just using different internal logic.
Today, no ZK-EVM team wants to stay Type 3; Type 3 is merely a transitional phase until the complex work of adding precompiles is completed and projects can move to Type 2.5. However, in the future, Type 1 or Type 2 ZK-EVMs might voluntarily become Type 3 by adding new ZK-SNARK-friendly precompiles that give developers access to low-proving-time and low-gas-cost functionalities.
Type 4 (High-Level Language Equivalent)
Type 4 systems work by taking smart contract source code written in a high-level language (e.g., Solidity, Vyper, or some intermediate language both compile to) and compiling it into a language explicitly designed to be ZK-snark friendly.
Advantage: Very Fast Proving Time
By avoiding the overhead of proving every component of each EVM execution step via ZK, and starting directly from higher-level code, much overhead can be eliminated.
I only described this advantage in a single sentence in this article (compared to the long bullet-point list of compatibility-related disadvantages below), but this should not be interpreted as a value judgment! Compiling directly from high-level languages indeed greatly reduces costs and helps decentralization by making it easier to become a prover.
Disadvantage: More Incompatibilities
A "normal" application written in Vyper or Solidity can be compiled down and will "work normally," but there are important aspects where many applications do not "just work":
- Contract addresses in Type 4 systems may differ from those in the EVM, because CREATE2 deterministic addresses depend on exact bytecode. This breaks applications relying on "counterfactual contracts" not yet deployed, ERC-4337 wallets, EIP-2470 singletons, and many other applications.
- Hand-written EVM bytecode becomes harder to use. For efficiency, many applications use hand-written EVM bytecode in certain sections. Type 4 systems may not support this, although limited EVM bytecode support could be added for these use cases without becoming a full Type 3 ZK-EVM.
- Much debugging infrastructure does not carry over, as it operates on EVM bytecode. That said, this disadvantage is mitigated by accessing debugging tools more from "traditional" high-level or intermediate languages (e.g., LLVM).
Developers should be aware of these issues.
Who Is Building It?
ZKSync is a Type 4 system, though over time it may add compatibility with EVM bytecode. NetherMind’s Warp project is building a compiler from Solidity to Starkware’s Cairo, which would make StarkNet a de facto Type 4 system.
The Future of These ZK-EVM Types
These types are not clearly "better" or "worse" than others. Rather, they represent different points in the trade-off space: lower-development-effort types are more compatible with existing infrastructure but slower; higher-development-effort types are less compatible but faster. Overall, it's healthy for the field that people are exploring all these types.
- A ZK-EVM could start as Type 3, choosing not to include some particularly hard-to-ZK-prove features, then gradually add them over time and transition to Type 2.
- A ZK-EVM could start as Type 2, then evolve into a hybrid Type 2/Type 1 ZK-EVM by offering the option to run in fully Ethereum-compatible mode or use a modified state tree that enables faster proving. Scroll is considering moving in this direction.
- Systems starting as Type 4 might become Type 3 over time by later adding the ability to handle EVM code (though developers would still be encouraged to compile directly from high-level languages to reduce fees and proving time).
- If Ethereum itself adopts modifications to become more ZK-friendly, then Type 2 or Type 3 ZK-EVMs could become Type 1 ZK-EVMs.
- Type 1 or Type 2 ZK-EVMs could become Type 3 ZK-EVMs by adding precompiles that verify code written in ZK-SNARK-friendly languages. This would let developers choose between Ethereum compatibility and speed, making it Type 3 (since it breaks perfect EVM equivalence), but practically speaking, it would retain many benefits of Type 1 and Type 2. The main drawback might be that some developer tools don't understand the ZK-EVM's custom precompiles—but this is fixable: developer tools could add generic precompile support by allowing configuration formats that include equivalent EVM implementations of precompiles.
Personally, I hope that over time everything converges toward Type 1, through improvements in ZK-EVMs and changes to Ethereum itself to make it more ZK-SNARK-friendly. In such a future, we’d have multiple ZK-EVM implementations usable both for ZK rollups and for verifying Ethereum itself. In theory, Ethereum wouldn’t need to standardize on a single ZK-EVM implementation for L1; different clients could use different proofs, so we continue benefiting from code diversity.
However, it will take quite some time to reach such a future. In the meantime, we’ll see much innovation across different paths for scaling Ethereum and Ethereum-based ZK rollups.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News















