

a16zによる万字に及ぶ長文:AIの次のフロンティアは言語ではなく、物理世界——ロボット工学、自律的科学、ブレイン・マシン・インターフェースという3つのスパイラル
TechFlow厳選深潮セレクト
a16zによる万字に及ぶ長文:AIの次のフロンティアは言語ではなく、物理世界——ロボット工学、自律的科学、ブレイン・マシン・インターフェースという3つのスパイラル
真正次世代の破壊的技術を実現できるのは、汎用ロボット、自律型科学(AI科学者)、脳機インターフェースなどの新しい人間-機械インタフェースである。
著者:Oliver Hsu(a16z)
翻訳・編集:TechFlow
TechFlow解説: 本稿は、a16zの研究員Oliver Hsuによるもので、2026年以降で最も体系的な「物理AI(Physical AI)」投資マップです。著者の見解によれば、言語/コードを軸とする技術路線は依然としてスケーリングを続けており、しかし、次世代の破壊的機能を生み出す真の可能性は、この主流路線に隣接する3つの分野——汎用ロボティクス、自律的科学(AIサイエンティスト)、脳機インターフェースなどの新世代ヒューマン・マシン・インタフェース——にあります。著者は、これらを支える5つの基盤技術能力を詳細に分解し、さらに、この3つの戦線が互いに補完・強化し合う「構造的フィードバック・フライホイール(structural flywheel)」を形成することを論じています。物理AIへの投資ロジックを明確に理解したい方にとって、現時点で最も包括的なフレームワークです。
現在のAIを主導するパラダイムは、言語およびコードを中心に構築されています。大規模言語モデル(LLM)のスケーリング則(scaling law)はすでに十分に解明されており、データ・計算リソース・アルゴリズムの改善がもたらすビジネス上のフィードバック・ループは着実に回っており、各ステージにおける能力向上がもたらすリターンは依然として非常に大きく、しかもその大部分は目に見える形で現れています。このパラダイムは、注がれる資本と注目度に十分に見合った成果を上げているのです。
一方で、これに隣接する領域では、すでに実質的な進展が生まれ始めています。ここには、VLA(Vision-Language-Actionモデル)、WAM(World Action Model)といった汎用ロボティクスのアプローチ、いわゆる「AIサイエンティスト」を軸とした物理・科学的推論、そしてAIの進展を活かして人間と機械のインタラクションを再定義する新世代インタフェース(脳機インターフェースや神経テクノロジーを含む)などが含まれます。これらの分野は単なる技術的進歩にとどまらず、既に優秀な人材、資金、起業家を惹きつけ始めています。先端AIを物理世界へと延長するための技術的プリミティブ(基本要素)が、同時に成熟しつつあるのです。過去18カ月間の進展は、これらの領域がそれぞれ独自のスケーリング段階へと急速に移行しつつあることを示唆しています。
あらゆる技術パラダイムにおいて、「現在の能力」と「中期的な潜在能力」のギャップが最も大きい領域には、通常以下の2つの特徴が見られます。第一に、現在の最先端を牽引するスケーリング恩恵をそのまま享受できること。第二に、主流パラダイムからわずかに離れていること——近すぎてインフラや研究の勢いを継承できるが、遠すぎて実際の追加作業を不可避に要する距離にあることです。この「距離」自体が二重の役割を果たします。すなわち、単純な追随者に対する自然な参入障壁(モアット)となり、かつ、情報が希薄で競合が少ない問題空間を定義することで、新しい能力の創出を促進します——まさに、まだ誰も踏み込んでいない「近道」が存在するからこそです。

図解:現在のAIパラダイム(言語/コード)と隣接する先端システムとの関係
現在、このような特徴を備える領域は3つあります。すなわち、ロボット学習、自律的科学(特に材料科学および生命科学の分野)、そして新世代ヒューマン・マシン・インタフェース(脳機インターフェース、無音スピーチ、神経系ウェアラブル、さらにはデジタル嗅覚といった新たな感覚チャネルを含む)です。これらは決して独立した研究テーマではなく、共に「物理世界における先端システム」という大きなカテゴリーに属しています。それらは以下の5つの共通基盤プリミティブを共有しています:物理力学の学習表現、具身的行動を指向したアーキテクチャ、シミュレーションおよび合成データ基盤、拡張される感覚チャネル、そしてクローズドループ型エージェントのオーケストレーション。これらは相互にフィードバックしながら強化され合い、また、モデル規模・物理世界への実装・新たなデータ形態という3つの要素が交差する場所であり、まさに「質的飛躍」が最も起こりやすい領域なのです。
本稿では、こうしたシステムを支える技術的プリミティブを整理し、なぜこの3つの領域が今後の最前線の機会であるのかを説明するとともに、それらが互いに強化し合う構造的フィードバック・フライホイールによって、AIが物理世界へと向かう流れを加速させることを提言します。
5つの基盤プリミティブ
具体的な応用事例を見る前に、まずこれらの先端システムが共有する技術的基盤を理解しましょう。先端AIを物理世界へと押し進めるために必要なのは、主に5つのプリミティブです。これらは特定の応用分野に限定されたものではなく、むしろ「AIを物理世界へと延長する」システムを構築するための基本部品です。それらが同時に成熟していることが、今日という時代が特別である所以なのです。

図解:物理AIを支える5つの基盤プリミティブ
プリミティブ①:物理力学の学習表現
最も根本的なプリミティブは、物体の運動・変形・衝突・外力への応答といった、物理世界における挙動を圧縮的かつ汎用的に学習する表現です。これがなければ、各物理AIシステムはそれぞれの専門分野における物理法則をゼロから学ぶ必要があり、そのコストは誰にも負担できません。
複数のアーキテクチャ流派が、異なる方向からこの目標に迫っています。VLAモデルは上位層からアプローチします。すなわち、事前に学習済みの視覚・言語モデル(物体・空間関係・言語の意味的理解を既に獲得済み)に、動作制御指令を出力するアクション・デコーダを付加するという手法です。鍵となるのは、「見る」「世界を理解する」という莫大な学習コストが、インターネット規模の画像・テキスト対の事前学習によって均等に分散されることです。Physical Intelligence社のπ₀、Google DeepMindのGemini Robotics、NVIDIAのGR00T N1などは、このアーキテクチャの大規模検証を繰り返しています。
WAMモデルは下位層からアプローチします。インターネット規模の動画を用いた事前学習済みのビデオ拡散トランスフォーマーをベースに、物体の落下・遮蔽・外力による相互作用といった物理力学に関する豊かな事前知識を継承し、それをアクション生成と統合します。NVIDIAのDreamZeroは、全く新しいタスクおよび環境へのゼロショット一般化を実証しており、少量の適応データを用いて人間の動画デモンストレーションから本体間の転移学習を可能にしています。実世界における一般化性能は、有意義なレベルで向上しました。
第3のアプローチは、将来の方向性を判断する上で最も示唆に富むかもしれません。それは、事前学習済みのVLMやビデオ拡散バックボーンを一切経由せず、ゼロから構築された「具身型基盤モデル」です。Generalist社のGEN-1は、50万時間以上に及ぶリアルな物理的相互作用データを用いてトレーニングされたモデルであり、主に低コストのウェアラブルデバイスを用いて日常的な操作タスクを遂行する人間から収集されたデータを用いています。これは標準的なVLAではありません(微調整される視覚・言語バックボーンが存在しない)。またWAMでもありません。これは、物理的相互作用を目的として設計された純粋な基盤モデルであり、インターネット上の画像・テキスト・動画の統計的規則ではなく、人間と物体との接触に関する統計的規則をゼロから学習しています。
World Labsなどが取り組む「空間知能(spatial intelligence)」は、このプリミティブにとって極めて価値があります。なぜなら、それはVLA・WAM・ネイティブ具身モデルのいずれにも共通する弱点——つまり、シーンの三次元構造を明示的にモデリングしていない点——を補完するからです。VLAは画像・テキスト事前学習から得られた2次元視覚特徴を継承し、WAMは動画から力学を学びますが、動画自体は3次元世界の2次元投影です。ウェアラブルセンサデータから学習するモデルは力と運動学を捉えられても、シーンの幾何学的構造は捉えられません。空間知能モデルは、物理環境の完全な3次元構造を再構成・生成し、それに基づいて幾何学・照明・遮蔽・物体関係・空間レイアウトなどを推論することを可能にします。
各アプローチの収束自体が重要です。表現がVLMから継承されようが、動画共同学習から得られようが、あるいは物理的相互作用データからゼロから構築されようが、根底にあるプリミティブは同一です:圧縮的かつ転移可能な物理世界挙動モデル。この表現が利用可能なデータ・フィードバック・ループは極めて巨大であり、まだほとんど手つかずです——インターネット動画やロボットの軌跡だけではなく、ウェアラブルデバイスが今まさに大規模に収集し始めている膨大な人間の身体的経験のコーパスも含まれます。同一の表現は、タオルを畳むことを学ぶロボットにも、反応結果を予測する自律実験室にも、運動皮質の握り込み意図を解読するニューロン・デコーダにもサービスを提供できます。
プリミティブ②:具身的行動を指向したアーキテクチャ
物理的表現だけでは不十分です。「理解」を信頼性の高い物理的行動へと変換するには、以下の相互に関連する課題を解決するアーキテクチャが必要です:高レベルの意図を連続的な運動指令へとマッピングすること、長時間の動作シーケンスにおいて一貫性を保つこと、リアルタイム遅延制約下で動作すること、そして経験とともに継続的に向上すること。
複雑な具身タスクにおいては、二重システムの階層型アーキテクチャが標準となっています:ゆっくりだが強力な視覚・言語モデル(System 2)がシーン理解とタスク推論を担当し、素早く軽量な視覚・運動ポリシー(System 1)がリアルタイム制御を担当します。GR00T N1、Gemini Robotics、Figure社のHelixなどは、このアプローチのバリエーションを採用しており、「大規模モデルによる豊かな推論」と「物理タスクに求められるミリ秒単位の制御周波数」という根本的な緊張関係を解消しています。一方、Generalist社は「共鳴的推論(resonant reasoning)」という別のアプローチを採用し、思考と動作を同時に行うことを可能にしています。
アクション生成メカニズム自体も急速に進化しています。π₀が開発したフローマッチングおよび拡散に基づくアクションヘッドは、滑らかで高周波数の連続的動作を生成するための主流手法となっており、言語モデリングから借用された離散トークン化を置き換えました。この手法では、アクション生成を画像合成に類似したノイズ除去プロセスとして扱い、物理的により滑らかで誤差累積に対してよりロバストな軌跡を生成します。自己回帰型トークン予測よりも優れています。
しかし、アーキテクチャ面での最も重要な進展は、事前学習済みVLAへの強化学習(RL)の拡張かもしれません——デモンストレーションデータで訓練された基盤モデルが、自律的な練習を通じてさらに向上することが可能になります。これは、人が反復練習と自己修正によって技能を磨くのと同様です。Physical Intelligence社のπ*₀.₆の研究は、この原則を最も明確にスケールアップした実証です。彼らの手法「RECAP(Advantage-Conditioned Policy Experience and Correction Reinforcement Learning)」は、純粋な模倣学習では解決できない長時間系列における信用配分問題に対処します。例えば、ロボットがわずかに傾いた角度でエスプレッソマシンのハンドルを掴んだ場合、失敗は直後に現れず、数ステップ後の挿入時に初めて露呈するかもしれません。模倣学習には、この失敗をより早い段階の掴み動作に帰属させる仕組みがなく、RLにはそれが備わっています。RECAPは任意の中間状態から成功する確率を推定する価値関数を訓練し、VLAが高アドバンテージのアクションを選択するようにします。肝心なのは、デモンストレーションデータ・オンポリシーな自律的経験・実行中のエキスパートによるリモート操作による修正といった、多様な異種データを単一の訓練パイプラインに統合している点です。
この手法の成果は、RLがアクション領域において有望であることを示す好材料です。π*₀.₆は、実際の家庭環境で見たことのない50種類の衣類を畳むこと、紙箱を確実に組み立てること、専門機器でエスプレッソを製作することを、数時間にわたって人間の介入なしに連続実行しました。最も困難なタスクにおいて、RECAPは純粋な模倣学習ベースラインと比較してスループットを2倍以上に増加させ、失敗率を半減以下に削減しました。このシステムはまた、RLによる後学習が模倣学習では得られない質的飛躍をもたらすことも実証しています:より滑らかな回復動作、より効率的な掴み戦略、そしてデモンストレーションデータに存在しない適応的エラー修正などです。
こうしたメリットが示すのは、GPT-2からGPT-4へと大規模言語モデルを進化させた計算資源のスケーリング原動力が、具身領域でも始まっているということです。ただ、現在は曲線のより初期の位置にあり、アクション空間は連続的かつ高次元であり、さらに物理世界の厳格な制約に直面しているのです。
プリミティブ③:スケーリング基盤としてのシミュレーションと合成データ
言語領域では、インターネットがデータ問題を解決しました:自然に発生し、無料で利用可能な兆単位のトークン規模のテキストです。物理世界では、この問題は桁違いに難しくなります——これは既に広く認識された共通理解であり、最も直接的な兆候は、物理世界向けデータ供給企業のスタートアップが急増していることです。実世界のロボット軌跡の収集はコストが高く、スケーリングにはリスクがあり、多様性にも限界があります。言語モデルは10億回の会話から学べますが、ロボット(当面は)10億回の物理的相互作用を行うことはできません。
シミュレーションおよび合成データ生成は、この制約を解消するための基盤層であり、その成熟は、物理AIが「今日」(5年前ではなく)加速している理由の一つです。
現代のシミュレーションスタックは、物理ベースのシミュレーションエンジン、レイトレーシングによる写実的レンダリング、プログラム生成による環境構築、およびシミュレーション入力を用いて写実的動画を生成するワールド基盤モデルを統合しています——最後のものは、シミュレーションと実世界(sim-to-real)のギャップを埋めることを目的としています。このパイプライン全体は、スマートフォン一台のみで可能な実環境のニューラル再構成から始まり、物理的に正確な3Dアセットを充填し、自動アノテーション付きの大規模合成データ生成へと至ります。
シミュレーションスタックの改良の意義は、物理AIを支える経済的仮定を変えることにあります。もし物理AIのボトルネックが「実データの収集」から「多様な仮想環境の設計」へと移ったならば、コスト曲線は急激に低下します。シミュレーションは計算リソースの拡張に依存し、人的リソースや物理ハードウェアには依存しません。これは、インターネットテキストデータが言語モデルの訓練に与えた変革と同種のものであり、つまり、シミュレーション基盤への投資は、エコシステム全体に対して極めて大きなレバレッジ効果を持つということです。
ただし、シミュレーションはロボティクスのプリミティブにとどまりません。同じ基盤インフラは、自律的科学(実験装置のデジタルツイン、仮説の事前スクリーニングに用いるシミュレーション反応環境)、新世代インタフェース(BCIデコーダ訓練のためのシミュレーション神経環境、新規センサの校正に用いる合成感覚データ)など、AIと物理世界の相互作用を伴う他のすべての領域にもサービスを提供します。シミュレーションは、物理世界におけるAIのための汎用データエンジンなのです。
プリミティブ④:感覚チャネルの拡張
物理世界が伝達する情報信号は、視覚および言語よりもはるかに豊かです。触覚は、カメラでは捉えられない素材特性・握りの安定性・接触幾何学などの情報を伝達します。神経信号は、現存するいかなるヒューマン・マシン・インタフェースとも比較にならない帯域幅で、運動意図・認知状態・知覚体験を符号化します。副声帯筋活動は、音声が発生する以前にすでに言語意図を符号化します。第4のプリミティブとは、AIがこれまでアクセス困難であったこれらの感覚チャネルを、急速に拡張することです——研究のみならず、消費財向けデバイス・ソフトウェア・インフラを構築するエコシステム全体からも推進されています。
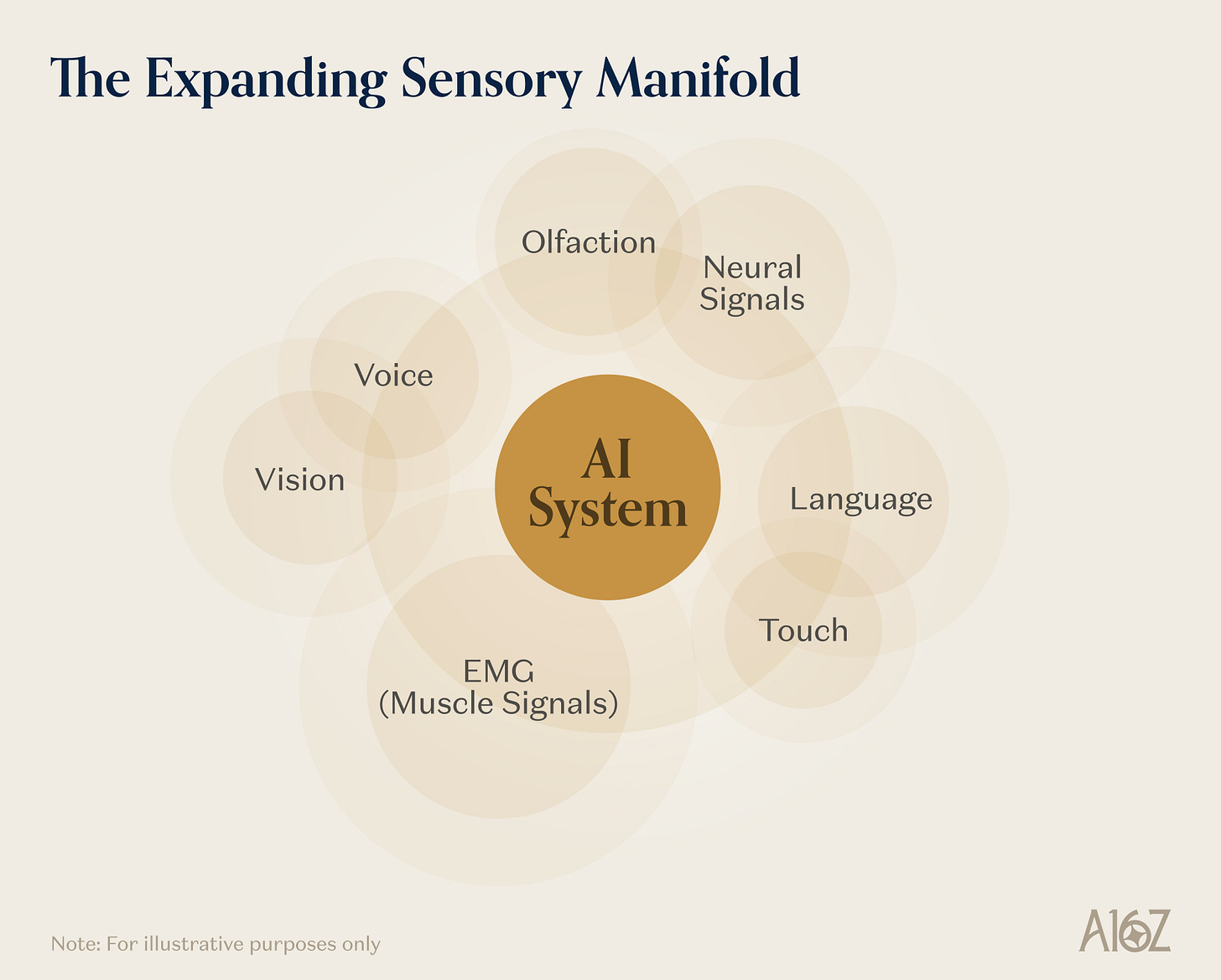
図解:AR、EMG、脳機インターフェースに至るまで、拡張中のAI感覚チャネル
最も直感的な指標は、新規デバイスカテゴリの登場です。ARデバイスは近年、体験および形状面で大幅に改善しており(既にこのプラットフォーム上で消費者・産業用途のアプリケーションを開発する企業が存在します);音声中心のAIウェアラブルは、言語AIに物理世界におけるより完全な文脈を提供しています——ユーザーと共に実際に物理環境へと入り込むのです。長期的には、神経インターフェースがさらに完全なインタラクションモダリティを開く可能性があります。AIがもたらすコンピューティング方式の変化は、ヒューマン・マシン・インタラクションを大幅に高度化する機会を創出し、Sesameのような企業がそのための新たなモダリティおよびデバイスを構築しています。
音声というより主流のモダリティも、新興インタラクション方式に追い風を送っています。Wispr Flowのような製品は、情報密度が高いという天然の優位性から、音声を主要な入力手段として推進しており、無音スピーチインタフェースの市場条件も同時に改善しています。無音スピーチデバイスは、舌および声帯の動きを捉える複数のセンサを用いて、音を立てずに言語を識別します——これは、音声よりも情報密度の高いヒューマン・マシン・インタラクションモダリティを代表しています。
脳機インターフェース(侵襲型および非侵襲型)は、さらに深遠なフロンティアを表します。これを取り巻く商業エコシステムは着実に前進しています。信号は臨床検証・規制承認・プラットフォーム統合・機関投資の4つの要素が交差する地点に現れます——これは、数年前までは純粋な学術領域に留まっていた技術カテゴリーでした。
触覚感知は、具身AIアーキテクチャへと入り込みつつあり、ロボット学習の一部のモデルでは、触覚が「第一級市民」として明示的に組み込まれ始めています。嗅覚インタフェースは、実際の工学的製品へと変わりつつあります:マイクロ香料発生器とミリ秒単位の応答を備えたウェアラブル嗅覚ディスプレイが、ミックスドリアリティ応用で既に実証されています。また、嗅覚モデルは視覚AIシステムとペアリングされ、化学プロセス監視に用いられ始めています。
これらの発展の共通法則は、極限に達した際に互いに収束していくことです。AR眼鏡は、ユーザーと物理環境との相互作用に関する視覚および空間データを継続的に生成します。EMG腕帯は、人間の運動意図の統計的規則を捉えます。無音スピーチインタフェースは、副声帯発音から言語出力までのマッピングを捉えます。BCIは、現時点での最高解像度で神経活動を捉えます。触覚センサは、物理的操作における接触力学を捉えます。各新規デバイスカテゴリは、同時にデータ生成プラットフォームでもあり、複数の応用分野の基盤モデルを養います。EMGから運動意図データを学習したロボットと、リモート操作データのみで学習したロボットでは、掴み戦略が異なります。副声帯指令に応答する実験室AIとキーボード制御の実験室では、科学者と機械のインタラクション方法がまったく異なります。高密度BCIデータで訓練された神経デコーダは、他のいかなるチャネルでも得られない運動計画表現を生成できます。
こうしたデバイスの普及は、最先端の物理AIシステムの訓練に利用可能なデータ多様体の有効次元を拡張しています——しかも、この拡張の多くは、学術研究所ではなく、資金に余裕のある消費財企業によって駆動されているため、データ・フィードバック・ループは市場採用率とともに拡大していくのです。
プリミティブ⑤:クローズドループ型エージェントシステム
最後のプリミティブは、よりアーキテクチャ寄りのものです。それは、知覚・推論・アクションを、持続的・自律的・クローズドループで稼働するシステムとして統合し、長い時間軸において人間の介入なしに動作させることを意味します。
言語モデルにおいては、これに対応する発展が「エージェントシステム」の台頭です——多段階推論チェーン・ツール利用・自己修正プロセスにより、モデルは単一ラウンドの質問応答ツールから、自律的な問題解決者へと進化しました。物理世界では、同様の変化が起こっていますが、要求ははるかに厳しいものです。言語エージェントが間違えても、コストゼロでやり直しが可能です。しかし、物理エージェントが試薬瓶をこぼしたら、もう元には戻せません。
物理世界のエージェントシステムには、デジタル版と区別する3つの特徴があります。第一に、実験または運用のクローズドループに埋め込まれる必要があります:原始的な機器データストリーム・物理状態センサ・実行プリミティブに直接接続し、推論が物理現実の文字通りの記述ではなく、物理現実そのものに根ざすようにします。第二に、長時間系列における永続性が必要です:記憶・トレーサビリティ追跡・安全監視・回復動作などにより、複数の実行サイクルを連結し、各タスクを独立したエピソードとして扱わないようにします。第三に、クローズドループによる適応が必要です:文字によるフィードバックではなく、物理的な結果に基づいて戦略を修正します。
このプリミティブは、個々の独立した能力(優れたワールドモデル・信頼性の高いアクションアーキテクチャ・豊富なセンサセット)を、物理世界で自律的に稼働する完全なシステムへと融合させます。これは統合層であり、その成熟こそが、後述の3つの応用分野が単なる研究デモではなく、現実世界への実装として成立する前提条件です。
3つの応用分野
上記のプリミティブは、汎用的なイネーブラー層であり、それ自体が最も重要な応用分野を指定するわけではありません。多くの分野が物理的動作・物理的測定・物理的知覚を含みます。「先端システム」と「単なる既存システムの改良版」とを区別するのは、モデル能力の向上とスケーリング基盤が複利的に発揮される程度——単に性能が向上するだけでなく、以前には不可能だった新機能が「湧出(emerge)」するかどうかです。
ロボティクス、AI主導の科学、新世代ヒューマン・マシン・インタフェースは、この複利効果が最も強い3つの分野です。それぞれが独特の方法でプリミティブを組み合わせ、それぞれが現在のプリミティブが解除しつつある制約に阻まれており、それぞれが運用中に副産物として一種の構造化された物理データを生成します——このデータは逆にプリミティブ自体をさらに良くし、フィードバックループを形成して、システム全体を加速させます。これらは唯一の注目すべき物理AI分野ではありませんが、先端AI能力と物理現実との相互作用が最も濃密な場所であり、また、現在の言語/コードパラダイムから最も離れており、そのため新機能の湧出可能性が最大——同時に、そのパラダイムと強く補完し合い、その恩恵を享受できる場所でもあります。
ロボティクス
ロボティクスは、文字通り最も物理的なAIの体現です:AIシステムがリアルタイムで知覚・推論し、物質世界に対して物理的動作を施す必要があります。また、同時に、すべてのプリミティブに対して「ストレステスト」を課します。
汎用ロボットがタオルを畳むために何をしなければならないかを考えてみてください。それは、力を受けた際に可変形材料がどのように振る舞うかを学習した表現——言語事前学習では得られない物理的先験知識——を必要とします。それは、高レベルの指示を20Hz以上の制御周波数で連続する運動指令列に変換するアクションアーキテクチャを必要とします。それは、誰も数百万回の実際のタオル畳みデモンストレーションを収集していないため、シミュレーションによって生成された訓練データを必要とします。それは、視覚では安定した掴みと失敗寸前の掴みを区別できないため、滑りを検出し握り力を調整するための触覚フィードバックを必要とします。また、畳み間違いを認識し、記憶した軌跡を盲目的に実行するのではなく回復するためのクローズドループコントローラーを必要とします。
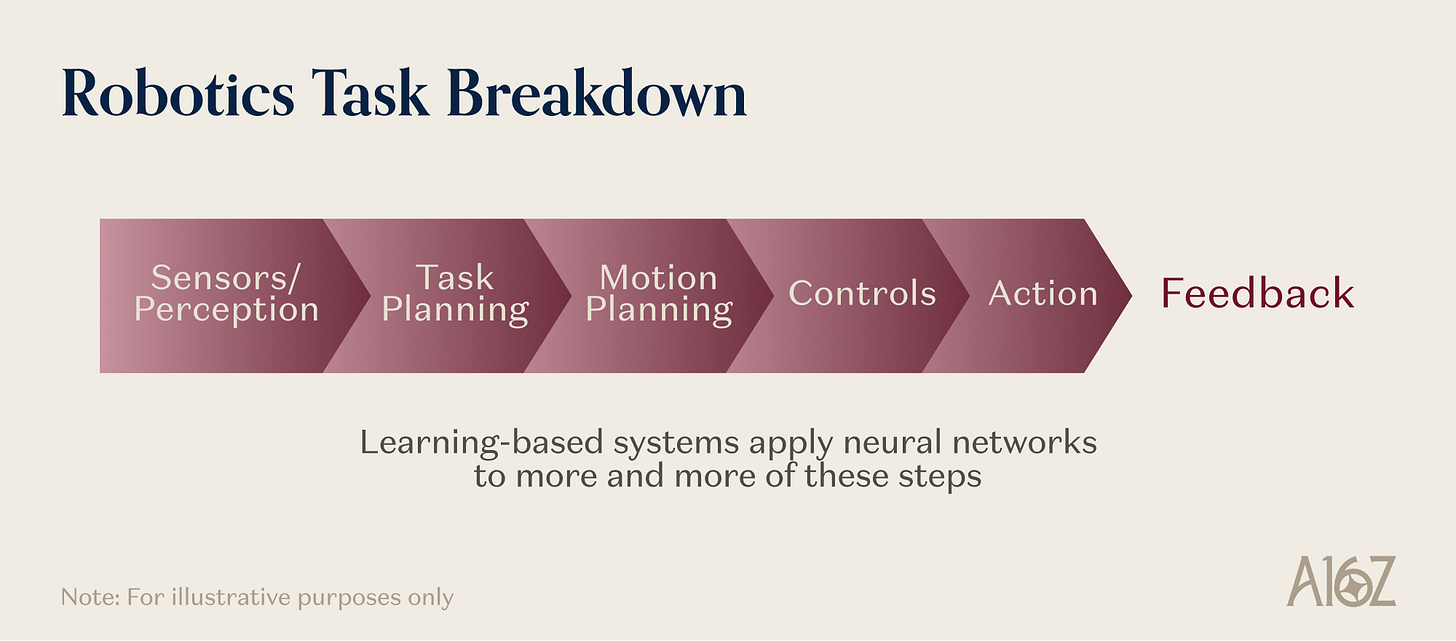
図解:ロボットタスクにおける5つの基盤プリミティブの同時活用
だからこそ、ロボティクスは先端システムであって、単に道具が良くなった成熟した工学分野ではないのです。これらのプリミティブは、既存のロボット能力を改良するものではなく、狭く制御された産業環境以外ではこれまで不可能だった操作・運動・インタラクションのカテゴリーを「解放」するものです。
過去数年の先端的進展は顕著です——我々は以前にもこの点について述べました。第1世代のVLAは、基盤モデルが多様なタスクを実行するためにロボットを制御できることを実証しました。アーキテクチャの進展は、ロボットシステムの高レベル推論と低レベル制御をつなぐ橋渡しを進めています。エッジ側での推論が実現可能になり、本体間の転移学習は、限られたデータで全く新しいロボットプラットフォームへとモデルを適応させることを可能にしています。残された核心的課題はスケーリングされた信頼性であり、これが依然として実装のボトルネックです。各ステップで95%の成功率を達成しても、10ステップのタスク連鎖では60%にまで落ち込み、実務環境ではこれより遥かに高い水準が求められます。この分野において、RLによる後学習は大きな可能性を秘めており、スケーリング段階へと到達するために必要な能力とロバスト性の閾値を越える助けとなります。
こうした進展は、市場構造にも影響を与えます。ロボティクス業界は数十年にわたり、価値の大部分が機械システム自体に凝縮されてきました。機械は依然として技術スタックの鍵となる部分ですが、学習戦略が標準化されるにつれ、価値はモデル・訓練インフラ・データ・フィードバック・ループへと移行します。ロボティクスはまた、上記のプリミティブを逆に支援します:各実世界の軌跡はワールドモデルを改善する訓練データとなり、各デプロイメント失敗はシミュレーションの網羅性のギャップを露呈させ、各新規本体のテストは事前学習に利用可能な物理的経験の多様性を拡大します。ロボティクスは、プリミティブにとって最も厳しい消費者であると同時に、それらを改善するための最も重要なフィードバック信号源の一つでもあります。
自律的科学
ロボティクスが「リアルタイム物理動作」によってプリミティブをテストするのに対し、自律的科学は、やや異なる課題——因果関係が複雑な物理システムに対する、時間スケールが数時間から数日に及ぶ継続的・多段階推論——をテストします。実験結果は解釈・文脈化され、戦略の修正に使われなければなりません。
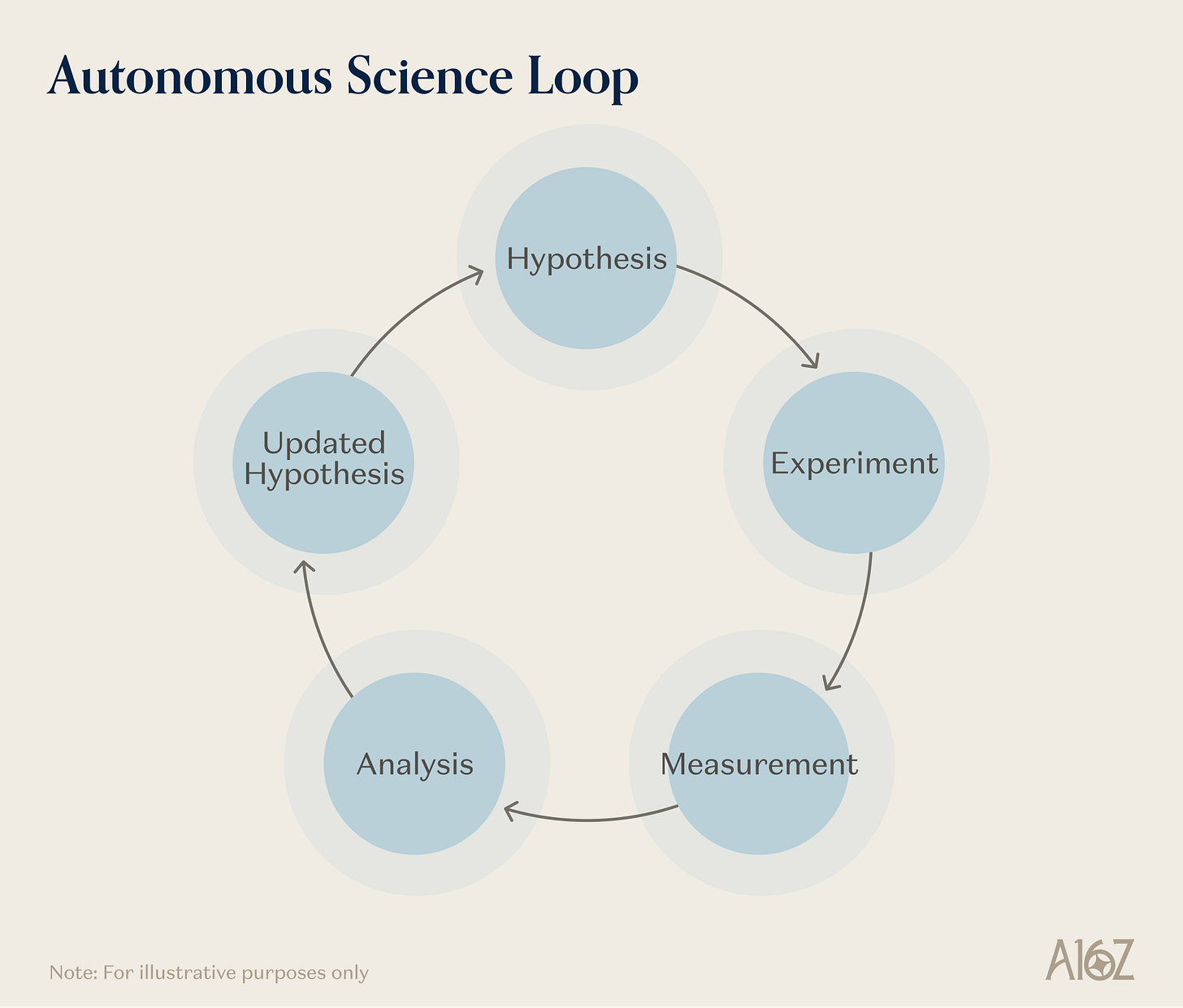
図解:自律的科学(AIサイエンティスト)における5つの基盤プリミティブの統合方法
AI主導の科学は、プリミティブを最も徹底的に組み合わせる分野です。自律走行型実験室(self-driving lab, SDL)は、実験の結果を予測するための物理・化学的力学の学習表現を必要とします。サンプルのピペット操作・配置・分析機器の操作のための具身的アクションを必要とします。候補実験の事前スクリーニングや希少な機器使用時間の割り当てのためのシミュレーションを必要とします。結果の特徴付けのための拡張されたセンシング能力——スペクトル・クロマトグラフィー・質量分析、そして日進月歩の化学・生物センサ——を必要とします。そして、他のいかなる分野よりも、クローズドループ型エージェントオーケストレーションプリミティブを必要とします:「仮説-実験-分析-修正」というワークフローを、人間の介入なしに複数ラウンド維持し、トレーサビリティを保持・安全を監視・各ラウンドで明らかになる情報を基に戦略を調整できるようにする必要があります。
他のどの分野も、これほど深くこれらのプリミティブを活用していません。だからこそ、自律的科学は、単に「ソフトウェアが優れた実験室自動化」ではなく、先端の「システム」なのです。Periodic LabsやMedraといった企業は、それぞれ材料科学および生命科学の分野で、科学的推論能力と物理的検証能力を統合し、科学的イテレーションを実現し、同時に実験訓練データを継続的に生成しています。
こうしたシステムの価値は直感的に明白です。従来の材料発見は概念から商用化まで数年を要しますが、AIによるワークフロー加速は、理論的にはこれをはるかに短縮できます。キーとなる制約は、仮説生成(基礎モデルが十分に支援可能)から、製造および検証(物理的機器・ロボット実行・クローズドループ最適化を必要とする)へと移行しています。SDLはまさにこのボトルネックを狙って設計されています。
自律的科学のもう一つの重要な特徴——これはすべての物理世界システムに共通します——は、それが「データエンジン」としての役割を果たすことです。SDLが実行する各実験は、単なる科学的結果だけでなく、物理的実装・実験的検証を経た訓練信号という副産物も生み出します。ある条件下でポリマーがどのように結晶化するかの測定は、ワールドモデルの材料力学への理解を豊かにします。検証済みの合成経路は、物理的推論の訓練データとなります。特徴付けられた失敗は、インテリジェント・エージェント・システムがどこで予測を誤ったかを教えます。AIサイエンティストが実験から生み出すデータは、インターネットテキストやシミュレーション出力とは性質が異なります——それは構造化されており、因果的であり、実証的に検証されています。これは、物理的推論モデルが最も必要とし、他のいかなるソースからも得られないデータです。自律的科学は、物理的現実を直接構造化された知識へと変換し、物理AIエコシステム全体を改善するための通路そのものです。
新世代インタフェース
ロボティクスはAIを物理的動作へと延長し、自律的科学はAIを物理的研究へと延長します。新世代インタフェースは、AIを人間の知能・感覚体験・身体信号との直接的な結合へと延長します——そのデバイスはAR眼鏡・EMG腕帯から、埋め込み型脳機インターフェースにまで及びます。このカテゴリを結びつけるのは単一の技術ではなく、共通の機能です:人間の知能とAIシステムの間のチャネルの帯域幅およびモダリティを拡張し、その過程で物理AIの構築に直接使える人間-世界相互作用データを生成することです。

図解:AR眼鏡から脳機インターフェースに至る新世代インタフェースのスペクトラム
主流パラダイムからの距離は、この分野の課題であると同時に、その可能性でもあります。言語モデルは概念レベルでこれらのモダリティを知っていますが、無音スピーチの運動パターン・嗅覚受容体結合の幾何学構造・EMG信号の時系列力学を天然に熟知しているわけではありません。これらの信号をデコードするための表現は、拡張中の感覚チャネルから学ばねばなりません。多くのモダリティにはインターネット規模の事前学習コーパスが存在せず、データはインタフェース自体からしか得られないことが多い——つまり、システムとその訓練データが協調進化しているのです。これは、言語AIには存在しない現象です。
この分野の最近の成果は、AIウェアラブルという消費財カテゴリの急速な台頭です。AR眼鏡はおそらくこのカテゴリの中で最も目立つ例ですが、音声または視覚を主入力とする他のウェアラブルも並行して出現しています。
この消費財デバイスエコシステムは、AIを物理世界へと延長するための新たなハードウェアプラットフォームを提供するだけでなく、物理世界データのインフラにもなっています。AI眼鏡を装着した人は、物理環境でのナビゲーション・物体操作・世界との相互作用に関する、第一人称視点の動画ストリームを継続的に生成します。他のウェアラブルは、生体認証および運動データを継続的にキャプチャします。AIウェアラブルの設置台数は、分散型の物理世界データ収集ネットワークへと変わり、これまで不可能だった規模で人間の物理的経験を記録しています。スマートフォンという消費財の規模を思い浮かべてみてください——同等の規模で、新たなモダリティで世界を知覚するコンピュータを提供する新たな消費財デバイスカテゴリは、AIと物理世界の相互作用に対して、途方もなく大きな新たなチャンネルを開きます。
脳機インターフェースは、さらに深遠なフロンティアを表します。Neuralinkは既に複数の患者に埋め込みを行い、手術ロボットおよびデコードソフトウェアの反復開発を進めています。Synchron社の血管内Stentrodeは、麻痺患者がデジタルおよび物理的環境を制御するために既に使用されています。Echo Neurotechnologiesは、高解像度皮質音声デコードの研究成果に基づく言語回復用BCIシステムを開発中です。Nudgeのような新規企業も、新たな神経インターフェースおよび脳インタラクションプラットフォームの構築のために、人材と資本を集めて設立されています。研究レベルの技術的マイルストーンも注目に値します:BISCチップは単一チップ上で65,536電極の無線神経記録を実証しました。BrainGateチームは、運動皮質から内部言語を直接デコードすることに成功しています。
AR眼鏡・AIウェアラブル・無音スピーチデバイス・埋め込み型BCIを貫く主線は、「それらがすべてインタフェースである」という単一の事実ではなく、それらが共に、人間の物理的経験とAIシステムの間の帯域幅が増大するスペクトラムを構成しているという点です——このスペクトラム上の各ポイントが、本稿で取り上げる3大分野を支えるプリミティブの継続的進展を支えています。数百万のAI眼鏡ユーザーから得られる高品質な第一人称動画で訓練されたロボットは、精選されたリモート操作データセットで訓練されたロボットとはまったく異なる操作の先験知識を学習します。副声帯指令に応答する実験室AIとキーボード制御の実験室では、遅延と流暢性という点で全く異なるものになります。高密度BCIデータで訓練された神経デコーダは、他のいかなるチャネルでも得られない運動計画表現を生成します。
新世代インタフェースは、感覚チャネルそのものを拡大するメカニズムです——それは、物理世界とAIの間に、かつて存在しなかったデータチャネルを開くのです。そして、この拡大は、スケーリングされたデプロイメントを追求する消費財企業によって推進されているため、データ・フィードバック・ループは消費者の採用率とともに加速します。
物理世界のシステム
ロボティクス・自律的科学・新世代インタフェースを、同一のプリミティブから構成される先端システムの異なる実例として捉える理由は、それらが互いにイネーブルし合い、複利効果を生むからです。
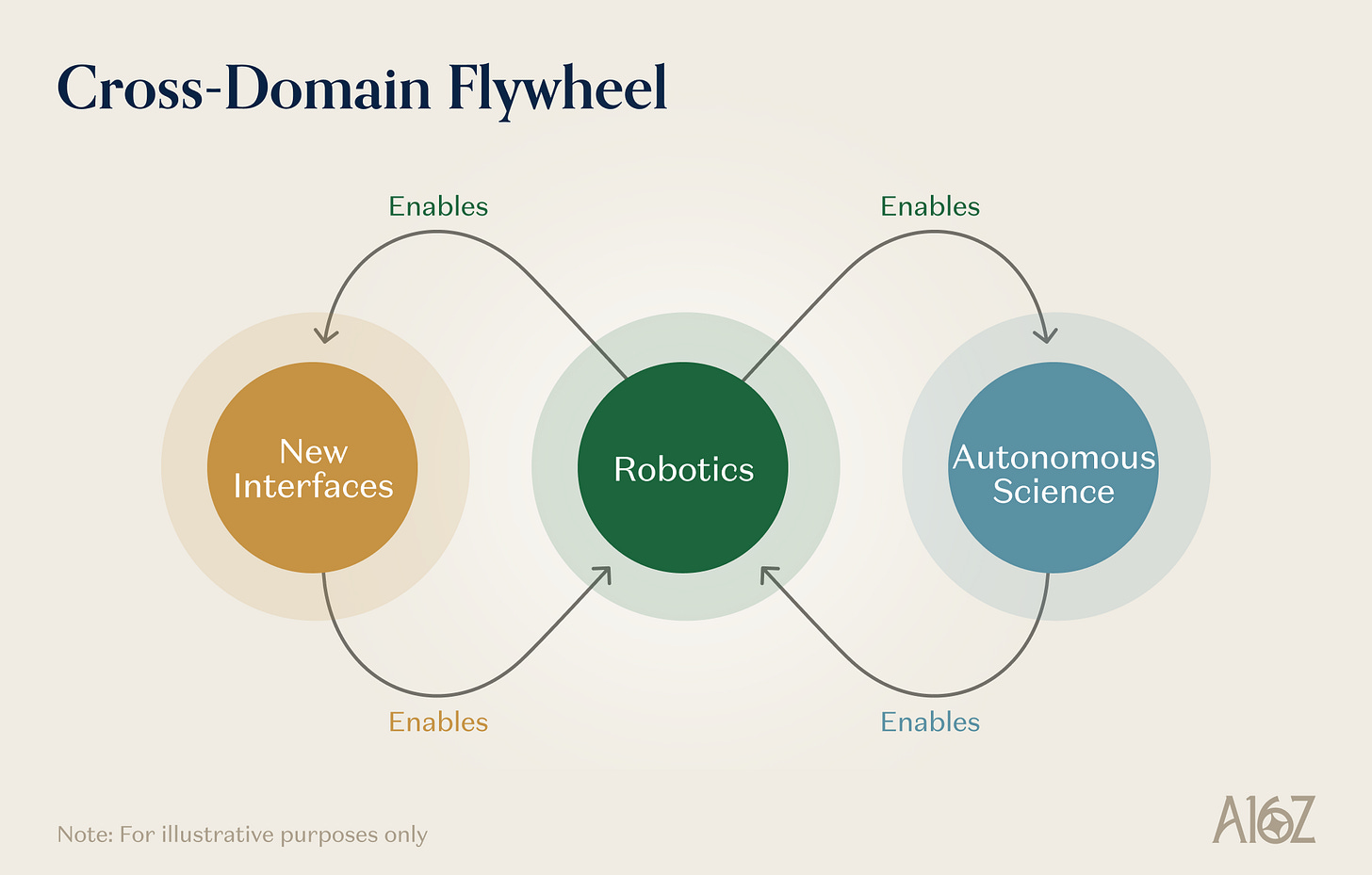
図解:ロボティクス・自律的科学・新世代インタフェース間の相互フィードバック・フライホイール
ロボティクスは自律的科学をイネーブルする。 自律走行型実験室(SDL)は本質的にロボットシステムです。汎用ロボットの開発に向けられた操作能力——器用な掴み・液体処理・精密な位置決め・多段階タスク実行——は、実験室自動化へと直接転移可能です。ロボットモデルの汎用性およびロバスト性が一歩前進するごとに、SDLが自律的に実行可能な実験プロトコルの範囲は広がります。ロボット学習の進展は、自律実験のコストを下げ、スループットを引き上げます。
自律的科学はロボティクスをイネーブルする。 自律走行型実験室が生み出す科学データ——検証済みの物理測定・因果的実験結果・材料特性データベース——は、ワールドモデルおよび物理推論エンジンが最も必要とする、構造化され、物理的に実装された訓練データを提供します。さらに、次世代ロボットに必要な材料およびデバイス(より優れたアクチュエータ・より敏感な触覚センサ・より高密度のバッテリーなど)自体が、材料科学の産物です。材料革新を加速する自律的発見プラットフォームは、ロボット学習が動作するハードウェア基盤そのものを直接改善します。
新世代インタフェースはロボティクスをイネーブルする。 ARデバイスは、「人間が物理環境をどのように知覚・相互作用するか」というデータをスケーラブルに収集する手段です。神経インターフェースは、人間の運動意図・認知計画・感覚処理に関するデータを生成します。これらのデータは、ロボット学習システム、特に人間とロボットの協調作業やリモート操作を含むタスクにおいて極めて貴重です。
ここには、先端AIの進展そのものの性質に関する、さらに深い観察があります。言語/コードパラダイムはすでに非凡な成果を生み出し、スケーリング時代においても勢いを増しています。しかし、物理世界が提供する新たな問題・新たなデータタイプ・新たなフィードバック信号・新たな評価基準は、ほぼ無限です。AIシステムを物理的現実に「落とし込む」——物体を操作するロボット・材料を合成する実験室・生物学および物理学的世界と接続するインタフェース——という行為は、既存のデジタルフロンティアと補完的かつ相互に改善しあう新たなスケーリング軸を開くのです。
図解:物理AIにおける各種スケーリング軸の相互作用と湧出
これらのシステムがどのような挙動を「湧出」させるかは、正確に予測することは困難です——「湧出」とは、個別には理解可能だが、組み合わさると前例のない能力が現れるという定義です。しかし、歴史的な傾向は楽観的です。AIシステムが世界と相互作用する新たなモダリティ——見る(コンピュータビジョン)、話す(音声認識)、読み書きする(言語モデル)——を獲得するたびに、その能力の飛躍は、個々の改良の単純な和をはるかに超えていました。物理世界システムへの移行は、次なるこのような相転移を意味します。この意味で、本稿で議論されるこれらのプリミティブは、まさに今構築されつつあり、先端AIシステムが物理世界を知覚・推論・作用するための基盤となり、物理世界において膨大な価値と進展を解放する可能性を秘めています。
免責事項:本稿は情報共有を目的としており、いかなる投資勧誘・法的・商業的・投資的・税務的助言を構成するものではありません。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














