
DeepSeekの「サーバー混雑」がすべての人を狂わせているが、その裏で一体何が起きているのか?
TechFlow厳選深潮セレクト
DeepSeekの「サーバー混雑」がすべての人を狂わせているが、その裏で一体何が起きているのか?
カードが詰まった。

画像出典:無界AI生成
TechFlowが頻繁に返す「サーバー混雑中、しばらくして再試行してください」というメッセージにより、各地のユーザーが困惑している。
かつてはあまり知られていなかったTechFlowは、2024年12月26日にGPT-4oと同等の言語モデルV3をリリースしたことで注目を集めた。さらに1月20日にはOpenAIのo1と同等の言語モデルR1を発表し、「ディープシンキング」モードによる高品質な回答や、モデル訓練初期コストが大幅に削減できる可能性を示した革新性により、企業およびアプリケーションは一気にブレイクした。しかし以降、TechFlow R1は継続的な混雑状態にあり、ネット検索機能は断続的に停止し、「ディープシンキング」モードでは頻繁に「サーバー混雑中」というメッセージが表示されるなど、多くのユーザーが不満を抱えている。
十数日前からTechFlowはサーバー中断を経験しており、1月27日の昼には公式サイトで「TechFlowのウェブページ/APIが利用不可」と数回表示された。その一方で、TechFlowは週末期間中にiPhoneダウンロードランキングで最も多くダウンロードされたアプリとなり、米国地域のダウンロードランキングでChatGPTを上回った。
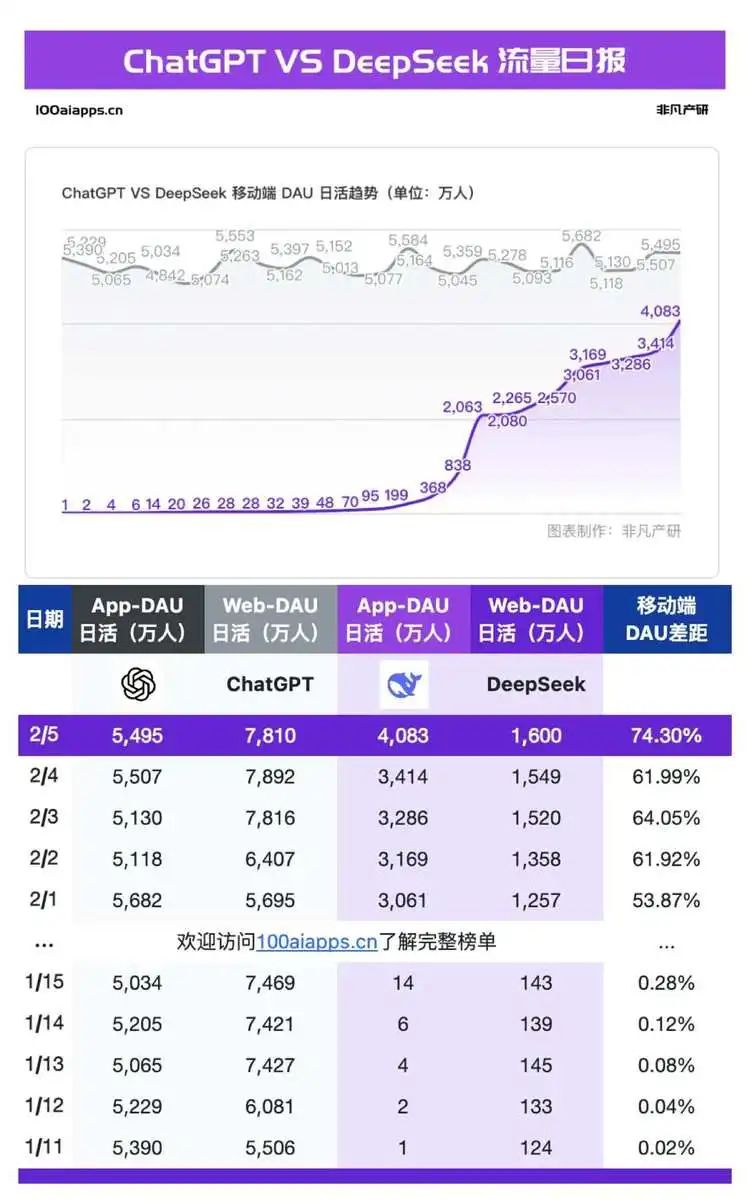
2月5日、TechFlowのモバイル版リリースから26日目で、デイリー活動ユーザー数(DAU)が4000万人を突破した。ChatGPTのモバイル版DAUは5495万人であり、TechFlowはその74.3%に達している。TechFlowが急激な成長曲線を描く一方で、サーバー混雑に対する批判も相次いでおり、世界中のユーザーが数問質問するだけでサービスが停止する不便さに直面している。これにより、代替アクセス方法が次々と登場している。例えばTechFlowの代替サイト、各大手クラウドプロバイダーやチップメーカー、インフラ企業が続々とサービスを提供し、個人での導入チュートリアルも広く出回っている。しかし人々の戸惑いは解消されていない。世界的に主要なほぼすべての企業がTechFlowの展開を支援していると宣言しているにもかかわらず、各地のユーザーは依然としてサービスの不安定さについて不満を述べ続けている。
この背景には一体何が起きているのか?
1、ChatGPTに慣れた人々にとって、使えないTechFlowは耐え難い
「TechFlowサーバー混雑中」への不満は、それ以前にChatGPTを中心としたAIトップアプリがほとんど遅延を起こさなかったことに由来している。
OpenAIのサービス開始以来、ChatGPTも何度かP0レベル(最も深刻な障害レベル)のダウンタイムを経験しているが、全体的には比較的安定しており、革新性と安定性のバランスを取っており、徐々に従来型クラウドサービスのような基盤的要素へと進化している。

ChatGPTの大規模ダウンの回数はそれほど多くない
ChatGPTの推論プロセスは比較的安定しており、エンコードとデコードの二段階からなる。エンコード段階では入力テキストを意味情報を含むベクトルに変換し、デコード段階では、Transformerモデルを使ってこれまでに生成されたテキストを文脈として次の単語またはフレーズを生成していく。大規模モデル自体はDecoder(デコーダー)アーキテクチャに属しており、デコード段階はトークン(大規模モデルがテキスト処理を行う最小単位)を一つずつ出力していくプロセスである。一度ChatGPTに質問するごとに、推論プロセスが起動する。
たとえば、「今日は気分はどう?」とChatGPTに尋ねた場合、まずこの文章をエンコードし、各層におけるアテンション表現を生成する。それまでのすべてのトークンのアテンション表現に基づき、最初の出力トークン「私」を予測する。その後デコードを行い、「私」を「今日は気分はどう?」に連結し、「今日は気分はどう?私」となり、新たなアテンション表現を得る。次に次のトークン「の」を予測し、これを繰り返していくことで最終的に「今日は気分はどう?私の気分はとても良いです。」という結果を得る。
コンテナ編成ツールKubernetesはChatGPTの「裏方指揮官」として、サーバーリソースのスケジューリングと割り当てを担当している。ユーザーの流入量がKubernetesのコントロールプレーンの処理能力を完全に超えると、ChatGPTシステム全体が停止する。
ChatGPTが停止した総回数はそれほど多くないが、その裏には強力なリソースが支えている。安定稼働の背後にある強大な計算能力こそが見過ごされがちなポイントである。
一般的に、推論処理におけるデータ規模は比較的小さいため、計算能力の要求は訓練時ほど高くはない。業界関係者の見積もりによると、通常の大規模モデル推論プロセスでは、メモリの主な使用領域はモデルパラメータの重みであり、その割合は80%以上を占める。実際、ChatGPTに内蔵されている複数のモデルでは、既定のモデルサイズはDeepSeek-R1の671Bよりも小さく、またChatGPTはDeepSeekよりもはるかに多くのGPU計算能力を持っているため、DS-R1よりも安定したパフォーマンスを自然に示している。
DeepSeek-V3およびR1はいずれも671Bのモデルであり、モデル起動は推論プロセスそのものである。推論時の計算能力の備蓄はユーザー数に応じて必要となる。たとえば1億人のユーザーがいれば、それに見合った1億人分のGPUが必要になる。これは膨大な規模であり、訓練時の計算能力とは別に独立しており、関連性がない。各方面の情報から判断すると、DSのGPUおよび計算能力の備蓄は明らかに不足しており、これが頻繁な遅延の原因となっている。
このような対比により、ChatGPTのスムーズな体験に慣れ親しんだユーザーは不慣れを感じており、特にR1への関心が高まる中で顕著である。
2、遅い、遅い、そしてまた遅い
さらに詳しく比較すると、OpenAIとDeepSeekが直面している状況は大きく異なっている。
前者はマイクロソフトをバックボーンに持ち、独占プラットフォームであるMicrosoft Azureクラウドサービス上でChatGPT、DALL-E 2画像生成器、GitHub Copilot自動コーディングツールなどを提供している。この組み合わせは「クラウド+AI」の古典的パターンとなり、急速に普及し業界標準となった。一方の後者はスタートアップながら、大部分の状況で自社データセンターに依存しており、Googleと同様に第三者のクラウドプロバイダーを利用していない。シリコンスターが公開情報を調査したところ、DeepSeekはいかなるレベルにおいてもクラウドプロバイダーまたはチップメーカーとの協力を開始していないことが判明した(春節期間中にクラウドプロバイダーが相次いで自社環境にDeepSeekモデルを展開すると発表したが、実質的な協力は一切行われていない)。
さらに、DeepSeekは前例のないユーザー増加に直面しており、突発事態への準備時間がChatGPTよりも短くなっている。
TechFlowの良好なパフォーマンスは、ハードウェアおよびシステムレベルでの包括的最適化によるものである。TechFlowの母体である幻方量化は、2019年にすでに2億元を投じて「螢火一号」スーパーコンピュータクラスタを構築し、2022年には1万枚以上のA100 GPUを静かに蓄積していた。より効率的な並列訓練のために、TechFlowは独自のHAI LLM訓練フレームワークを開発した。業界では、螢火クラスタが数千から数万枚の高性能GPU(NVIDIA A100/H100または中国製チップ)を採用し、強力な並列計算能力を提供していると考えられている。現在、この螢火クラスタはDeepSeek-R1およびDeepSeek-MoEなどのモデル訓練を支えており、これらのモデルは数学、コードといった複雑タスクにおいてGPT-4レベルに近い性能を示している。
螢火クラスタはTechFlowが新アーキテクチャおよび新方式で探求してきた過程を象徴しており、こうした革新的技術によって、DSは最先端の西洋モデルの数分の一の計算能力で、トップクラスのAIモデルと同等の性能を持つR1を訓練できたと考えられている。SemiAnalysisの試算によると、DeepSeekは実際には膨大な計算能力を保有しており、合計6万枚のNVIDIA GPUを備えている。その内訳はA100が1万枚、H100が1万枚、「特別供給版」H800が1万枚、「特別供給版」H20が3万枚である。
これは一見、R1のGPU台数が十分であるように思える。しかし実際には、推論モデルであるR1はOpenAIのO3と同等であり、応答フェーズにさらなる計算能力を投入する必要がある。だが、DSが訓練コスト側で節約した計算能力と、推論コスト側で急増した計算能力のどちらが大きいかは、現時点では不明である。
注目に値するのは、DeepSeek-V3とDeepSeek-R1はいずれも大規模言語モデルだが、動作方式が異なる点だ。DeepSeek-V3はChatGPTと同様の指令モデルであり、プロンプトを受け取り対応するテキストを生成して返信する。一方、DeepSeek-R1は推論モデルであり、ユーザーからの質問に対してまず大量の推論プロセスを行い、その後最終的な答えを生成する。R1が生成するトークンの中には、まず多数の思考チェーンプロセスが現れる。モデルは答えを生成する前に問題を説明し、分解する。これらの推論プロセスはすべてトークン形式で高速に生成される。
耀途キャピタルの副社長・温廷燦氏は、前述のDeepSeekの巨大な計算能力備蓄は訓練フェーズを指しており、訓練フェーズの計算能力はチームが計画可能で予測しやすく、計算能力不足が起きにくいが、推論フェーズの計算能力はユーザー規模および使用量に大きく左右されるため不確実性が高く、弾力性があると指摘する。「推論計算能力は一定の法則に従って増加するが、TechFlowが現象級製品となったことで、短期間でユーザー規模および使用量が爆発的に増加し、推論フェーズの計算需要も爆発的に増加した結果、遅延が発生している。」
即刻アプリで活躍するモデルプロダクトデザイナー兼独立開発者・歸藏氏も、GPU台数不足がTechFlowの遅延の主因であることに同意する。彼はDSが現在世界140以上の市場で最も多くダウンロードされたモバイルアプリであることを踏まえれば、今の遅延は到底耐えられない状態だとし、「新しいGPUを導入しても、クラウドサービスを構築するには時間がかかるため、結局どうにもならない」と述べる。
「NVIDIA A100、H100などのチップは1時間の運用コストに公正な市場価格があり、TechFlowが出力トークンあたりの推論コストはOpenAIの同類モデルo1と比べて90%以上安い。この点については業界の計算とも大きな乖離はない。つまり、MOEというモデルアーキテクチャ自体が最大の問題ではない。だが、DSが保有するGPUの台数が、1分間に生産可能なトークン数の上限を決めてしまう。仮に予備訓練研究ではなく、より多くのGPUを推論サービスに振り向けたとしても、上限はそこに存在する。」AIネイティブアプリ『小猫補光灯』の開発者・陳雲飛氏も同様の見解を示す。
業界関係者の中には、DeepSeekの遅延の本質はプライベートクラウドの整備不足にあると指摘する声もある。
ハッカー攻撃もR1の遅延を引き起こすもう一つの要因である。1月30日、メディアはサイバーセキュリティ企業Qihoo 360から、TechFlowオンラインサービスに対する攻撃の強度が突然増大し、攻撃命令は1月28日と比べて百倍以上に増加したと報じられた。Qihoo Xlab研究所は少なくとも2つのボットネットが攻撃に参加していることを確認した。
しかし、このようなR1自身のサービス遅延には、一見明らかな解決策がある。それが第三者によるサービス提供である。これはまさに我々が春節期間中に目撃した最も賑やかな光景であった――各社が相次いでサービスを展開し、TechFlowへの需要に対応したのである。
1月31日、NVIDIAはNVIDIA NIMでDeepSeek-R1が利用可能になったと発表した。これにより、NVIDIAの株式時価総額は一夜にして約6000億ドル蒸発した。同日、Amazon Web Services(AWS)のユーザーは、人工知能プラットフォームAmazon BedrockおよびAmazon SageMaker AI上で最新のR1基礎モデルを展開できるようになった。その後、PerplexityやCursorなど、AIアプリの新興企業も一斉にDeepSeekを統合した。MicrosoftはAmazonやNVIDIAより先んじて、DeepSeek-R1をクラウドサービスAzureおよびGitHubに展開した。
2月1日(旧暦大晦日)から、Huawei Cloud、Alibaba Cloud、ByteDance傘下の火山エンジン、Tencent Cloudも参入し、一般にDeepSeek全シリーズおよび全サイズモデルの展開サービスを提供した。その後、壁仞科技、瀚博半導体、昇騰、沐曦などAIチップメーカーも続き、自社チップでDeepSeekオリジナル版またはより小型の蒸留版を適合させたと自称している。ソフトウェア企業では、用友、金蝶などが一部製品にDeepSeekモデルを組み込み、製品力を強化している。最後に、Lenovo、Huawei、Honorなどのエンドデバイスメーカーも、一部製品にDeepSeekモデルを搭載し、端末側の個人アシスタントや車載スマートキャビンとして活用している。
現在までに、TechFlowは自らの価値により国内外のクラウドプロバイダー、通信事業者、証券会社、国家超算インターネットプラットフォームといった国家レベルのプラットフォームを含む広範なパートナーシップを築いている。DeepSeek-R1は完全にオープンソースのモデルであるため、接続したサービスプロバイダーはすべてDSモデルの恩恵を受けることになる。これはDSの知名度を大きく高める一方で、より頻繁な遅延現象を引き起こしており、サービスプロバイダーとDS自身の両方が押し寄せるユーザーに対処できず、安定した利用を実現するための鍵となる解決策を見つけられていない。
TechFlow V3およびR1の両モデルはオリジナル版でそれぞれ6710億のパラメータを持ち、クラウド上で動作させるのに適している。クラウドプロバイダー自体がより豊富な計算能力および推論能力を備えており、彼らがDeepSeek関連の展開サービスを開始することは企業利用の敷居を下げるためのものであり、DSモデルのAPIを外部に提供することで、DS自身が提供するAPIよりも優れたユーザーエクスペリエンスを提供できると考えられていた。
しかし現実には、DeepSeek-R1モデル自体の動作体験の問題は、どのサービスでも解決されておらず、外側からはサービスプロバイダーにGPUが不足しているとは見えないが、実際に展開されたR1に対して、開発者が反応体験の不安定さを報告する頻度はR1自体とまったく同じくらい高い。これは、R1の推論に割り当てられるGPUの台数自体がそれほど多くないことに起因している。

「R1の人気が高止まりしており、サービスプロバイダーは他の接続モデルも考慮しなければならず、R1に割り当てられるGPUは非常に限られている。R1の人気も高いので、どこかの企業が低価格でR1を提供すれば、すぐに圧倒されてしまう。」モデルプロダクトデザイナーで独立開発者の歸藏氏がシリコンスターに理由を説明した。
モデル展開の最適化は、訓練完了から実際のハードウェア展開に至るまで多岐にわたる広範な分野であるが、DeepSeekの遅延事例に関しては、理由はより単純かもしれない。例えば、モデルが大きすぎることや、リリース前の最適化準備不足などである。
人気の大規模モデルがリリースされる前には、技術、工学、ビジネスなど多方面の課題に直面する。たとえば、訓練データと実稼働環境データの一貫性、データ遅延およびリアルタイム性が推論効果に与える影響、オンライン推論の効率およびリソース消費の過大、モデル汎化能力の不足、およびサービスの安定性、APIとシステム統合といった工学的側面などである。
多くの人気大規模モデルはリリース前に推論最適化を非常に重視している。これは計算時間およびメモリ問題に関係しており、前者は推論遅延が長すぎてユーザーエクスペリエンスが悪くなる、あるいは遅延要件を満たせなくなる(つまり遅延現象)ということであり、後者はモデルパラメータ数が多く、GPUメモリを消費し、単一のGPUカードに収まらない場合もあり、これも遅延を引き起こす。
温廷燦氏は、サービスプロバイダーがR1サービス提供で困難に直面している根本的な理由は、DSモデルの構造が特殊で、モデルが大きすぎる上にMOE(Mixture of Experts、効率的計算方式)アーキテクチャであることだとシリコンスターに説明した。「(サービスプロバイダーの)最適化には時間がかかるが、市場の熱狂には時間制限があるため、まずは展開してから最適化する形になり、完全に最適化してからリリースするわけではない。」
R1が安定稼働するための現在の鍵は、推論側の備蓄および最適化能力にある。DeepSeekがすべきことは、推論コストを下げ、1回の出力で生成されるトークン数を削減する方法を見つけることである。
同時に、遅延現象はDS自身の計算能力備蓄がSemiAnalysisが述べたほど膨大ではない可能性も示唆している。幻方ファンドもGPUを使用し、DeepSeekの訓練チームもGPUを使用するため、ユーザーに割り当て可能なGPUは常に限られている。現在の発展状況から見ると、短期間でDeepSeekがお金をかけてサービスをレンタルし、無料でユーザーにより良い体験を提供する動機はおそらくない。むしろ、最初のCtoCビジネスモデルが明確になってから、サービスレンタルの議題を検討する可能性が高い。これはつまり、遅延がしばらく続くことを意味している。
「彼らにはおそらく2つのステップが必要だ。1)有料メカニズムを導入し、無料ユーザーのモデル使用量を制限する。2)クラウドサービスプロバイダーと協力し、他社のGPUリソースを利用する。」開発者陳雲飛氏が提示した一時的解決策は、業界内で広く共通認識となっている。
しかし現時点では、DeepSeek自身はこの「サーバー混雑中」という問題に対してそれほど焦っている様子はない。AGIを目指す企業として、TechFlowは押し寄せるユーザー流量にあまり注目しないようである。ユーザーたちは今後しばらくの間、「サーバー混雑中」という画面に慣れなければならないだろう。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News















