

黄仁勲氏の最新CES基調講演:AIエージェントは次なるロボット産業となり、規模は数兆ドルに達する可能性
TechFlow厳選深潮セレクト
黄仁勲氏の最新CES基調講演:AIエージェントは次なるロボット産業となり、規模は数兆ドルに達する可能性
NVIDIAは、AIをクラウドから個人端末および企業内にまで拡大し、開発者から一般ユーザーまでのあらゆるコンピューティングニーズに対応しようとしている。
編集:有新

CES 2025の本日開幕に際し、NVIDIA創業者兼CEOのジェンスン・フアン(黄仁勳)がAIとコンピューティングの未来を示す画期的な基調講演を行った。生成AIの中心概念であるトークンから、新たなBlackwellアーキテクチャGPUの発表、そしてAI駆動型デジタル未来に至るまで、この講演は多角的視点で業界全体に深い影響を与えるものとなった。
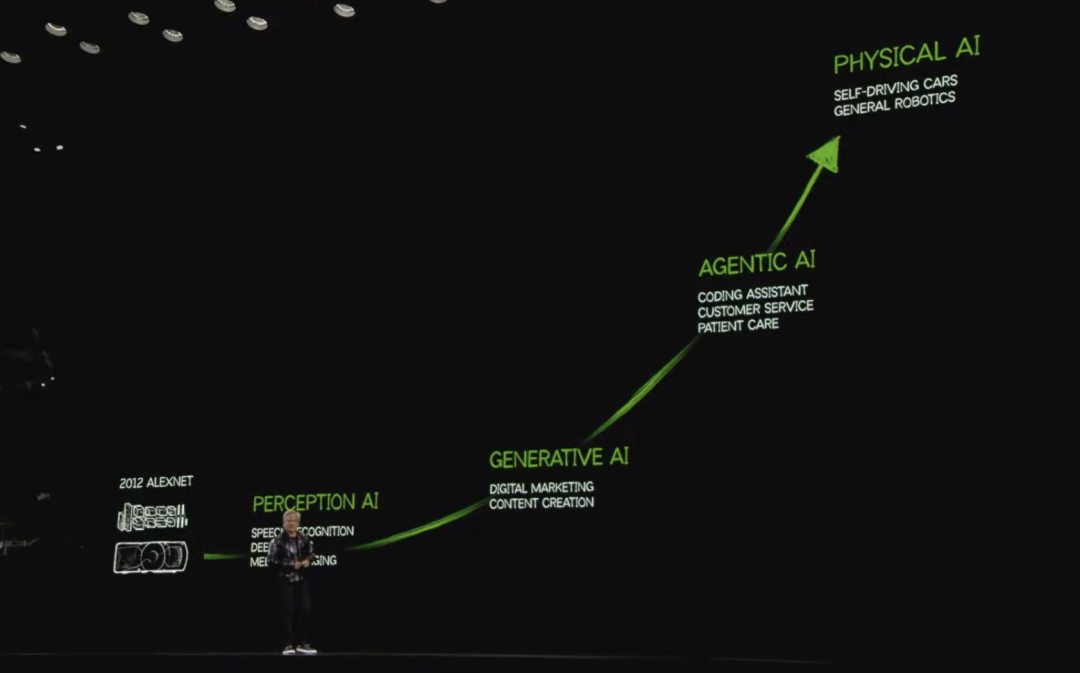
1)生成AIからエージェントAIへ:全新时代の幕開け
-
トークンの誕生:生成AIの核となるトークンは、文字を知識に変換し、画像に生命を吹き込む。これにより、全く新しいデジタル表現の時代が開かれた。
-
AIの進化の道筋:知覚AI、生成AIから、推論・計画・行動が可能なエージェントAIへと、AI技術は絶えず新たな高みへと到達している。
-
Transformerの革命:2018年の登場以来、この技術は計算方法を再定義し、従来の技術スタックを完全に覆した。
2)Blackwell GPU:性能限界の突破
-
次世代GeForce RTX 50シリーズ:Blackwellアーキテクチャを採用し、920億個のトランジスタ、4000 TOPSのAI性能、4 PetaFLOPSの演算能力を備え、前世代比で3倍の性能を実現。
-
AIとグラフィックスの融合:初のプログラマブルシェーダーとニューラルネットワークの統合により、ニューラルテクスチャ圧縮やマテリアルシェーディング技術を導入し、驚異的なレンダリング効果を実現。
-
高性能の普及:RTX 5070ノートPCは$1299という価格でRTX 4090と同等の性能を実現し、高性能コンピューティングの一般化を推進。
3)AI応用の多領域展開
-
企業向けAIエージェント:NVIDIAはNeMoやLlama Nemotronなどのツールを提供し、企業が自律的に推論を行う「デジタル従業員」を構築できるよう支援し、インテリジェントな管理とサービスを実現。
-
フィジカルAI:OmniverseおよびCosmosプラットフォームを通じて、AIを産業、自動運転、ロボティクス分野に統合し、世界の製造および物流を再定義。
-
将来のコンピューティングシナリオ:NVIDIAはAIをクラウドから個人端末や企業内部へと拡大し、開発者から一般ユーザーに至るまでのあらゆるコンピューティングニーズに対応。
以下はジェンスン・フアン氏による基調講演の主な内容である:
ここは知性が生まれる場所であり、トークンを生み出す発電機のような、まったく新しい工場である。トークンはAIの構成要素であり、未知なる領域への扉を開き、驚異的な世界へ踏み出す第一歩となる。トークンは文字を知識に変え、画像に命を吹き込み、創造を映像に変え、あらゆる環境での安全なナビゲーションを可能にする。また、ロボットに名人のように動くことを教え、新たな形で勝利を祝う力を与える。必要としているときにこそ、心の平安さえも届けることができる。デジタルに意味を与え、世界をより深く理解し、潜在的な危険を予測し、内なる脅威に対処する方法を見つける手助けをする。私たちのビジョンを現実にし、失われたものを修復する力を持つ。
AIの物語は1993年に始まる。当時、NVIDIAは初の製品NV1を発表した。我々は普通のコンピュータでは不可能なことを実現するマシンを作りたいと考えており、PCにゲーム機の機能を持たせることを目指した。その後1999年、NVIDIAはプログラマブルGPUを発明し、20年以上にわたる技術革新の時代の幕を開け、現代のコンピュータグラフィックスの可能性を切り拓いた。さらに5年後、CUDAを発表し、豊かなアルゴリズムによってGPUのプログラマブル性を表現した。当初は説明が難しい技術だったが、2012年にAlexNetの成功がCUDAの可能性を証明し、AIの飛躍的発展を促した。
それ以来、AIは驚異的なスピードで進化してきた。知覚AIから生成AI、さらには知覚・推論・計画・行動が可能なエージェントAIへと、その能力は継続的に向上している。2018年、GoogleがTransformerを発表したことで、AIの世界は真に加速した。TransformerはAIの枠組みを根本から変えただけでなく、コンピューティング全体のあり方を再定義した。機械学習は単なる新しいアプリケーションやビジネスチャンスではなく、コンピューティング自体の根本的革新であることに我々は気づいた。手動で命令を書くことから、機械学習によってニューラルネットワークを最適化する手法へと、技術スタックのすべての層が大きく変化したのである。
今日、AIの応用はあらゆる場面に広がっている。テキスト、画像、音声の理解から、アミノ酸や物理学の翻訳に至るまで、ほぼすべてのAIアプリケーションは次の3つの問いに帰着する:何のモダリティ(模態)の情報を学習したのか?何のモダリティの情報に翻訳されたのか?何のモダリティの情報を生成したのか?この基本的な概念が、すべてのAI駆動型アプリケーションを推進している。
こうした成果の裏には、GeForceの貢献がある。GeForceはAIの民主化を推進し、今やAIはGeForceに逆戻りしてそれを革新している。リアルタイムレイトレーシング技術により、驚異的なグラフィックスが可能になった。DLSSを通じて、AIはフレーム生成を超え、未来の画面を予測することさえ可能になる。3300万ピクセルのうちわずか200万ピクセルしか計算されず、残りはすべてAIが予測して生成している。この奇跡のような技術は、AIの強大な力を示しており、計算をより効率的にするとともに、無限の未来の可能性を見せてくれる。
だからこそ、今このような数々の驚異的な出来事が起きているのだ。我々はGeForceを通じてAIの発展を推進してきたが、今やAIがGeForceを完全に革新しようとしている。本日、次世代製品であるRTX Blackwellファミリーを発表する。さあ、ご覧いただこう。
これはBlackwellアーキテクチャをベースとした全新GeForce RTX 50シリーズである。このGPUは性能モンスターであり、920億個のトランジスタ、4000 TOPSのAI性能、4 PetaFLOPSのAI演算能力を備え、前世代のAdaアーキテクチャに対して3倍の性能を発揮する。これらすべては、私が先ほど紹介した驚異的なピクセルを生み出すためのものだ。また、380レイトレーシングTeraflopsを備え、計算が必要なピクセルに最高品質の画質を提供する。さらに125シェーディングTeraflopsを有し、MicronのG7メモリを搭載。速度は秒間1.8TBに達し、前世代の2倍の性能を実現している。
現在、AIワークロードとコンピュータグラフィックスワークロードを統合することが可能になった。本世代の特筆すべき特徴の一つは、プログラマブルシェーダーがニューラルネットワークを処理できることである。これにより、「ニューラルテクスチャ圧縮」と「ニューラルマテリアルシェーディング」を発明できた。これらの技術はAIがテクスチャや圧縮アルゴリズムを学習することで、AIにしか実現できない驚くべき画像効果を生み出す。
機構設計においても、このGPUは奇跡といえる。デュアルファン設計を採用し、カード全体が巨大なファンのような構造になっている。内部の電圧調整モジュールは最先端のものであり、このような卓越した設計はエンジニアチームの努力の賜物である。
次にパフォーマンス比較について説明しよう。皆様ご存知のRTX 4090は$1599で、家庭用PCエンターテインメントの中心的存在である。一方、RTX 50シリーズは、開始価格$549ながら、RTX 5070からRTX 5090まで、RTX 4090の2倍の性能を提供する。
さらに驚くべきことに、この高性能GPUをノートPCに搭載した。RTX 5070搭載ノートPCは$1299という価格でありながら、RTX 4090と同等の性能を発揮する。この設計はAIとコンピュータグラフィックス技術を融合させ、高エネルギー効率と高性能を両立している。

将来のコンピュータグラフィックスは「ニューラルレンダリング」、つまりAIとコンピュータグラフィックスの融合となる。Blackwellシリーズは厚さわずか14.9mmのノートPCにも搭載可能であり、RTX 5070からRTX 5090までの全ラインナップが超薄型ノートPCに適応できる。
GeForceがAIの普及を推進し、今やAIがGeForceを根本から変革している。これは技術と知性の相互促進であり、我々はより高い次元へ向かっている。
AIの3つのスケーリング則
次に、AIの進化方向について話そう。
1)事前学習スケーリング則(Pre-training Scaling Law)
AI業界は急速に拡大しており、その原動力となっているのが「スケーリング則」と呼ばれる強力なモデルである。この経験則は研究者や産業界によって繰り返し検証されており、訓練データの規模、モデルの規模、投入される計算能力が大きければ大きいほど、モデルの能力も高くなることを示している。
データの増加スピードは指数関数的に加速している。今後数年間で、人類が年間に生み出すデータ量は、それ以前の歴史全体を超えると予測されている。これらのデータはマルチモーダル化しており、動画、画像、音声など多様な形式を含む。膨大なデータはAIの基礎知識体系を訓練するために利用され、堅固な知識基盤を築く。
2)事後学習スケーリング則(Post-training Scaling Law)
加えて、新たに注目されているのが他の2つのスケーリング則である。
第2のスケーリング則は「事後学習スケーリング則」であり、強化学習や人間からのフィードバックといった技術に関連している。この方式では、AIは人間の問い合わせに対して回答を生成し、人間からのフィードバックに基づいて継続的に改善される。高品質なプロンプトを通じて、AIは特定分野のスキルを磨くことができ、例えば数学問題の解決や複雑な推論に長けるようになる。
AIの未来とは、知覚や生成に留まらず、自己改善を続け、境界を越えていくプロセスである。それはまるでコーチや指導者が、タスク完了後にフィードバックを与えるようなものだ。テスト、フィードバック、自己改善を通じて、AIも同様の強化学習とフィードバックメカニズムで進化できる。この事後学習段階における強化学習と合成データ生成技術の組み合わせは、自己練習に似ている。AIは定理の証明や幾何学的問題といった複雑かつ検証可能な難問に直面し、強化学習を通じて自らの解答を最適化していく。この事後学習には膨大な計算能力が必要だが、最終的には非凡なモデルを生み出すことができる。
3)テスト時スケーリング則(Test-time Scaling Law)
テスト時スケーリング則も徐々に姿を現している。この法則はAIが実際に使用される際に独自のポテンシャルを発揮する。AIは推論時に動的にリソースを割り当てることができ、パラメータ最適化に限定されず、必要な高品質な回答を得るために計算リソースの配分に焦点を当てる。
このプロセスは即答や一回限りの推論ではなく、推論的思考に近い。AIは問題を複数のステップに分解し、複数の解決策を生成して評価し、最終的に最良の選択肢を選ぶことができる。このような長期的推論は、モデル能力の向上に極めて効果的である。
すでにこの技術の進化は見られ、ChatGPTからGPT-4、そして現在のGemini Proに至るまで、これらすべてのシステムは事前学習、事後学習、テスト時拡張の段階を経て発展している。これらのブレークスルーを実現するには莫大な計算能力が必要であり、まさにそれがNVIDIAのBlackwellアーキテクチャの核心的価値なのである。
Blackwellアーキテクチャ最新紹介
Blackwellシステムは現在全面的に量産中であり、その性能は驚異的である。現在、すべての主要クラウドプロバイダーがこれらのシステムを導入しており、世界中の45工場で製造され、液冷・風冷、x86アーキテクチャ、NVIDIA Grace CPU版などを含む200種類以上の構成がサポートされている。
その中核部品であるNVLinkシステム自体の重量は1.5トンに達し、60万個の部品からなり、20台の自動車と同等の複雑さを持つ。背後には2マイルの銅線と5000本のケーブルが接続されている。この極めて複雑な製造プロセスの目的は、増大し続ける計算需要に対応することにある。
前世代アーキテクチャと比較して、Blackwellはワット当たりの性能が4倍、ドル当たりの性能が3倍向上している。つまり、同じコストでモデルの規模を3倍に拡大できることを意味する。こうした進歩の鍵は、生成AIのトークンにある。これらのトークンはChatGPT、Gemini、各種AIサービスで広く活用されており、将来のコンピューティングの基盤となっている。
この基盤の上に、NVIDIAは「ニューラルレンダリング」という新たな計算モデルを推進している。これはAIとコンピュータグラフィックスを完璧に融合したものである。Blackwellアーキテクチャ下では、72枚のGPUが地球上最大の単一チップシステムを形成し、1.4 ExaFLOPSのAI浮動小数点性能を提供する。メモリ帯域幅は驚異の1.2 PB/sに達し、これは全世界のインターネットトラフィックの合計に匹敵する。このスーパーコンピューティング能力により、AIはより複雑な推論タスクを処理でき、コストを大幅に削減し、より効率的な計算の基盤を築く。
AIエージェントシステムとエコシステム
将来、AIの推論プロセスは単純な一回回答ではなく、「内的対話」に近づいていく。将来的なAIは答えを生成するだけでなく、省察・推論・継続的最適化を行うようになる。AIトークンの生成速度の向上とコスト低下により、AIサービスの品質は著しく向上し、より広範な応用ニーズに対応できる。
企業が自律的推論能力を持つAIシステムを構築できるよう、NVIDIAは3つの重要なツールを提供している:NVIDIA NeMo、AIマイクロサービス、およびアクセラレーションライブラリ。複雑なCUDAソフトウェアとディープラーニングモデルをコンテナ化されたサービスとしてパッケージ化することで、企業は任意のクラウドプラットフォーム上でこれらのAIモデルを展開し、特定分野向けのAIエージェント(例:企業管理支援ツールやユーザインタラクション用デジタル従業員)を迅速に開発できる。
これらのモデルは企業に新たな可能性を切り開き、AIアプリケーションの開発ハードルを下げると同時に、Agentic AI(自律AI)の方向性において業界全体を確実に前進させる。将来的なAIはデジタル従業員となり、SAP、ServiceNowなどの企業ツールに容易に統合され、さまざまな環境で顧客にインテリジェントなサービスを提供する。これはAI拡張の次のマイルストーンであり、NVIDIA技術エコシステムの中心的ビジョンでもある。
評価訓練システム。将来的にこれらのAIエージェントは、実際の従業員と共に働き、業務を遂行するデジタル労働力となる。そのため、会社にこうした専門的なエージェントを導入することは、新入社員の入社手続きのようなものだ。我々はさまざまなツールキットを提供し、これらのAIエージェントが企業独自の言語、用語、ビジネスプロセス、仕事のやり方を学ぶのを支援する。成果物のサンプルを提示し、彼らが生成を試みた後、フィードバックや評価を行う。同時に、どのような操作や発言を禁止するか、アクセスできる情報を制御するといった制限も設定できる。この一連のデジタル従業員プロセスを「NeMo」と呼ぶ。ある意味、各社のIT部門はAIエージェントのHR部門となるのだ。
現在、IT部門は多数のソフトウェアを管理・維持しているが、将来は多数のデジタルエージェントを管理・育成・入社・改善し、企業にサービスを提供する。このように、IT部門は次第にAIエージェントのHR部門へと進化していく。
さらに、エコシステム向けに多くのオープンソースのブループリントを提供している。ユーザーは自由にこれらのブループリントを修正できる。我々はさまざまなタイプのエージェント向けにブループリントを用意している。本日、非常にクールで賢い発表もある:Llamaをベースにした全く新しいモデルファミリー、「NVIDIA Llama Nemotron」言語基盤モデルシリーズを発表する。
Llama 3.1は現象的なモデルである。MetaのLlama 3.1は約3億5065万回ダウンロードされ、およそ6万種の派生モデルを生み出した。これはほぼすべての企業や業界がAI研究を始めたきっかけの一つである。我々はLlamaモデルを企業ユースケース向けにさらに微調整できることに気づいた。自社の専門知識と能力を活かし、それをLlama Nemotronオープンモデルキットとして微調整した。
これらのモデルはサイズ別に分かれている:小型モデルはレスポンスが高速;主流のスーパーモデル「Super Llama Nemotron」は汎用用途;超大型モデル「Ultra Model」は教師モデルとして、他のモデルの評価、解答生成、品質判断、あるいは知識蒸留モデルとして使用できる。これらすべてのモデルが既に公開されている。
これらのモデルは対話、指示、情報検索などの分野でランキング上位を占め、世界的なAIエージェント機能に非常に適している。
我々はServiceNow、SAP、Siemensとの産業AI分野での協力も密接に行っている。CadenceやPerplexityなども優れたプロジェクトを進めている。Perplexityは検索分野を革新し、Codiumは世界中の3000万人のソフトウェアエンジニアにサービスを提供している。AIアシスタントはソフトウェア開発者の生産性を劇的に向上させ、これはAIサービスの次の巨大な応用分野となるだろう。世界には10億人の知識労働者がおり、AIエージェントは次のロボット産業となり、数兆ドル規模のポテンシャルを持つ。
AIエージェントのブループリント
次に、パートナーと共同で完成したAIエージェントのブループリントをいくつか紹介する。
AIエージェントは新しいデジタル労働力であり、人間の作業を支援または代替できる。NVIDIAのAgentic AI構築モジュール、NEM事前学習モデル、Nemoフレームワークにより、組織は容易にAIエージェントを開発・展開できる。これらのエージェントは特定分野のタスク専門家として訓練可能である。
以下の4つの例を挙げる:
-
研究アシスタントエージェント:講義、学術誌、財務報告書などの複雑な文書を読み、インタラクティブなポッドキャストを生成し、学習を容易にする。
-
ソフトウェアセキュリティAIエージェント:開発者が継続的にソフトウェアの脆弱性をスキャンし、対応策を提案する。
-
バーチャルラボAIエージェント:化合物設計とスクリーニングを加速し、潜在的な創薬候補を迅速に発見する。
-
ビデオ分析AIエージェント:NVIDIA Metropolisブループリントに基づき、数十億台のカメラからのデータを分析し、インタラクティブな検索、要約、レポートを生成。交通量、施設プロセスの監視、改善提案の提供などに利用可能。
フィジカルAI時代の到来
我々はAIをクラウドから企業内部、個人PCに至るまで隅々に届けたいと考えている。NVIDIAはWindows WSL2(Windows Subsystem for Linux)をAI対応の主要プラットフォームに変える努力をしている。これにより、開発者やエンジニアがNVIDIAのAI技術スタック(言語モデル、画像モデル、アニメーションモデルなど)をより簡単に利用できるようになる。
さらに、NVIDIAはCosmosを発表する。これは物理世界の基礎モデル開発のための初のプラットフォームであり、重力、摩擦、慣性、空間関係、因果関係といった物理世界の動的特性の理解に焦点を当てる。物理法則に準拠した動画やシーンを生成でき、ロボット、産業AI、マルチモーダル言語モデルの訓練・検証に広く応用される。
CosmosはNVIDIA Omniverseと連携し、物理シミュレーションを通じて信頼性の高いシミュレーション結果を生成する。この統合はロボットおよび産業応用開発のコア技術である。
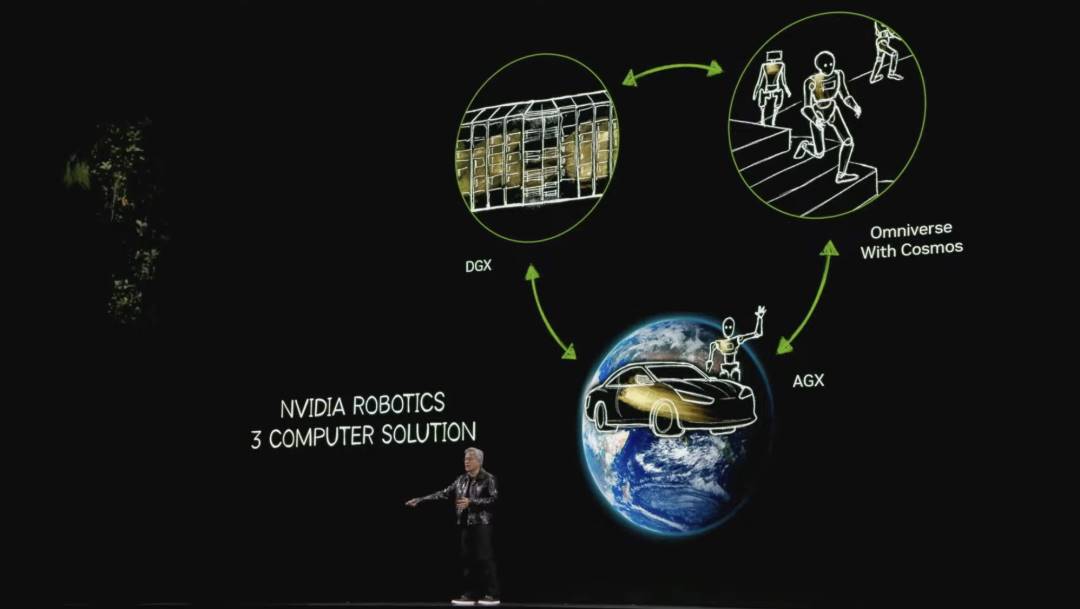
NVIDIAの産業戦略は3つのコンピューティングシステムに基づいている:
-
AI訓練用DGXシステム;
-
AI展開用AGXシステム;
-
強化学習とAI最適化のためのデジタルツインシステム;
この3システムの連携により、NVIDIAはロボットおよび産業AIの発展を推進し、将来のデジタル世界を構築している。「三体問題」と言うよりも、我々は「三コンピュータ」ソリューションを持っている。
NVIDIAのロボットビジョンを3つの例で紹介しよう。
1)産業可視化の応用
現在、世界には数百万の工場と数十万の倉庫があり、これらは50兆ドル規模の製造業の骨格を成している。将来、これらすべてがソフトウェア定義と自動化を実現し、ロボット技術を取り入れる必要がある。我々は世界トップの倉庫自動化ソリューションプロバイダーKeon、および世界最大のプロフェッショナルサービスプロバイダーAccentureと協力し、デジタル製造に取り組み、特別なソリューションを共に創出している。市場展開は他のソフトウェア・テクノロジープラットフォームと同様に、開発者やエコシステムパートナーを通じて行われており、ますます多くのパートナーがOmniverseプラットフォームに接続している。誰もが産業の未来を可視化したいと考えているからだ。この50兆ドルの世界GDPには、多くの無駄と、多くの自動化のチャンスがある。
KeonとAccentureが我々と共同で行ったこの事例を見てみよう:
サプライチェーンソリューション企業Keon、グローバルプロフェッショナルサービスリーダーAccenture、NVIDIAは、物理AIを兆ドル規模の倉庫・配送センター市場に導入している。効率的な倉庫物流の管理には、日々および季節的な需要変動、空間制約、労働力供給、多様なロボットおよび自動化システムの統合など、常に変化する変数に影響される複雑な意思決定ネットワークに対処する必要がある。現在、物理的倉庫の運用KPI(重要業績評価指標)を予測することはほとんど不可能である。
これらの課題を解決するため、KeonはMega(NVIDIA Omniverseのブループリント)を採用し、工業用デジタルツインを構築し、ロボットフリートのテストと最適化を行う。まず、Keonの倉庫管理ソリューションがタスクをデジタルツイン内の産業AIブレインに割り当てる。例えば、緩衝エリアからシャトルストレージソリューションへの物品移動などである。ロボットフリートはOmniverse内の物理的倉庫シミュレーション環境で、知覚と推論によりタスクを実行し、次の行動を計画・実行する。デジタルツイン環境はセンサーを模擬し、ロボットブレインがタスク実行後の状態を把握し、次の行動を決定できる。Megaによる正確な追跡により、このサイクルは継続され、スループット、効率、利用率などの運用KPIが、実際の倉庫を変更する前にすべて測定される。
NVIDIAとの協力により、KeonとAccentureは産業自律の未来を再定義している。
将来、すべての工場が実際の工場と完全に同期したデジタルツインを持つようになる。OmniverseとCosmosを使って大量の将来シナリオを生成でき、AIが最適なKPIシナリオを決定し、それを実際の工場の展開における制約条件およびAIプログラミングロジックとして利用できる。
2)自動運転車
自動運転革命はすでに到来している。長年の発展を経て、WaymoやTeslaの成功が自動運転技術の成熟を証明している。我々のソリューションはこの業界に3つのコンピュータシステムを提供している:AI訓練用システム(例:DGX)、シミュレーションテストおよび合成データ生成用システム(例:Omniverse、Cosmos)、車載コンピュータシステム(例:AGX)。世界の主要自動車メーカーのほとんどが我々と協力している。Waymo、Zoox、Teslaに加え、世界最大のEV企業BYDも含まれる。Mercedes、Lucid、Rivian、Xiaomi、Volvoなど、革新的な新型車を間もなく発表する企業も参加している。AuroraはNVIDIA技術を用いて自動運転トラックを開発している。
毎年1億台の自動車が製造され、世界の道路には10億台の自動車が走り、年間走行距離は兆マイルに達する。これらはいずれも高度に自動化または完全自動化されていく。この業界は、最初の兆ドル規模のロボット産業になると予想されている。
本日、次世代車載コンピュータ「Thor」を発表する。これは汎用ロボットコンピュータであり、カメラ、高解像度レーダー、LiDARなどのセンサーからの大量データを処理できる。Thorは業界標準Orinのアップグレード版であり、計算能力は20倍に向上し、すでに全面量産されている。同時に、NVIDIA Drive OSは機能安全の最高レベル(ISO 26262 ASIL D)認証を受けた初のAIコンピュータOSである。
自動運転データファクトリー
NVIDIAはOmniverse AIモデルとCosmosプラットフォームを用いて自動運転データファクトリーを構築し、合成走行情報により訓練データを大幅に拡張している。これには以下が含まれる:
-
OmniMap:地図と地理空間データを統合し、走行可能な3D環境を構築;
-
ニューラルリコンストラクションエンジン:センサーログを用いて高精細な4Dシミュレーション環境を生成し、訓練データ用のシナリオバリエーションを作成;
-
Edify 3DS:アセットライブラリから新しいアセットを検索または生成し、シミュレーション用のシーンを作成。
これらの技術により、数千回の走行情報を数十億マイルのデータに拡張し、より安全で高度な自動運転システムの開発に活用している。
3)汎用ロボット
汎用ロボットの時代が目前に迫っている。この分野のブレークスルーを推進する鍵は訓練にある。ヒューマノイドロボットの場合、模倣データの取得は困難だが、NVIDIAのIsaac Grootがその解決策を提供する。これはシミュレーションによって膨大なデータセットを生成し、OmniverseとCosmosのマルチユニバースシミュレーションエンジンを用いてポリシーの訓練、検証、展開を行う。
例えば、開発者はApple Vision Proを用いてロボットを遠隔操作し、実際のロボットなしにデータを収集し、リスクのない環境でタスク動作を教えることができる。Omniverseのドメインランダム化および3Dから現実世界への拡張機能により、指数関数的に増加するデータセットを生成し、ロボット学習に膨大なリソースを提供する。
結論として、産業可視化、自動運転、汎用ロボットに至るまで、NVIDIAの技術はフィジカルAIおよびロボティクス分野の未来変革をリードしている。
最後に、もう一つ重要な発表がある。これらすべての背景には、10年前に社内で立ち上げた「Project Digits」というプロジェクトがある。正式名称はDeep Learning GPU Intelligence Training System(深層学習GPUインテリジェンス訓練システム)であり、通称Digitsである。
正式発表前に、DGXを社内のRTX、AGX、OVX、その他の製品シリーズと調和させるよう調整した。DGX1の登場はAIの進路を真に変えたものであり、NVIDIAのAI発展におけるマイルストーンでもある。
DGX1の革命性
DGX1の狙いは、研究者やスタートアップ企業に即座に使えるAIスーパーコンピュータを提供することだった。かつてのスーパーコンピュータは、専用施設の建設や複雑なインフラの設計・構築を必要とする存在だった。一方、DGX1はAI開発専用に設計されたスーパーコンピュータであり、複雑な操作不要で、箱を開ければすぐに使用可能である。
2016年、初のDGX1をスタートアップ企業OpenAIに納品したことを覚えている。当時、エロン・マスク氏、イリヤ・サツケアビッチ氏、NVIDIAの多くのエンジニアが集まり、DGX1の到来を共に祝った。この装置はAI計算の発展を大きく加速させた。
今日、AIはあらゆる場所に存在する。研究機関やスタートアップのラボに限らず、私が冒頭で述べたように、AIは新しいコンピューティング方式であり、新しいソフトウェア開発方式でもある。すべてのソフトウェアエンジニア、クリエイティブアーティスト、PCツールを使う一般ユーザーにとって、AIスーパーコンピュータが必要なのである。しかし私は常に、DGX1がもう少し小型になってほしいと願っていた。
最新AIスーパーコンピュータ
以下がNVIDIAの最新AIスーパーコンピュータである。依然としてProject Digitsの一環であり、現在もより良い名称を模索中であり、アイデアを募集している。これは本当に驚異的な装置である。
このスーパーコンピュータはNVIDIAの完全なAIソフトウェアスタック(DGX Cloudを含む)を実行可能である。クラウド上のスーパーコンピュータとしても、高性能ワークステーションとしても、あるいは机の上に置ける分析ワークステーションとしても使用できる。最も重要なのは、秘密裏に開発された新チップ「GB110」を搭載していることである。これは最小のGrace Blackwellである。
このチップを手に取り、内部設計を紹介しよう。このチップは世界トップのSoC企業MediaTekと共同開発したものであり、CPU SoCはNVIDIA専用にカスタマイズされ、NVLinkチップ間接続技術でBlackwell GPUに接続されている。この小型チップはすでに全面量産に入っている。このスーパーコンピュータは5月頃に正式に市場投入予定である。
「2倍の計算能力」構成も提供しており、ConnectXで複数台を接続可能で、GPUダイレクト(GPUDirect)技術をサポートしている。これはAI開発、分析作業、産業応用のあらゆるニーズに対応する完全なスーパーコンピューティングソリューションである。
さらに、3種類の全新Blackwellシステムチップの量産、世界初の物理AI基礎モデル、自律AIエージェントロボット・ヒューマノイドロボット・自動運転車という3つのロボット分野でのブレークスルーも発表された。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













