
Rédaction : IOSG Ventures
Remerciements aux contributeurs Zhenyang@Upshot, Fran@Giza, Ashely@Neuronets, Matt@Valence, Dylan@Pond pour leurs retours.
Cette étude vise à explorer quels domaines de l'intelligence artificielle sont les plus importants pour les développeurs, ainsi que les opportunités émergentes potentielles dans la convergence entre Web3 et l'IA.
Avant de partager nos nouvelles analyses, nous sommes heureux d’annoncer notre participation au premier tour de financement de RedPill, s’élevant à 5 millions de dollars. Nous sommes enthousiastes et impatients de grandir aux côtés de RedPill !

TL;DR
Alors que la convergence entre Web3 et l’IA devient un sujet central dans l’univers cryptographique, le développement des infrastructures IA dans ce domaine est en plein essor. Toutefois, peu d’applications exploitent réellement l’IA ou sont construites pour elle, et une forte homogénéisation des infrastructures IA commence à apparaître. Notre récente participation au financement de RedPill a permis d’approfondir ces observations.
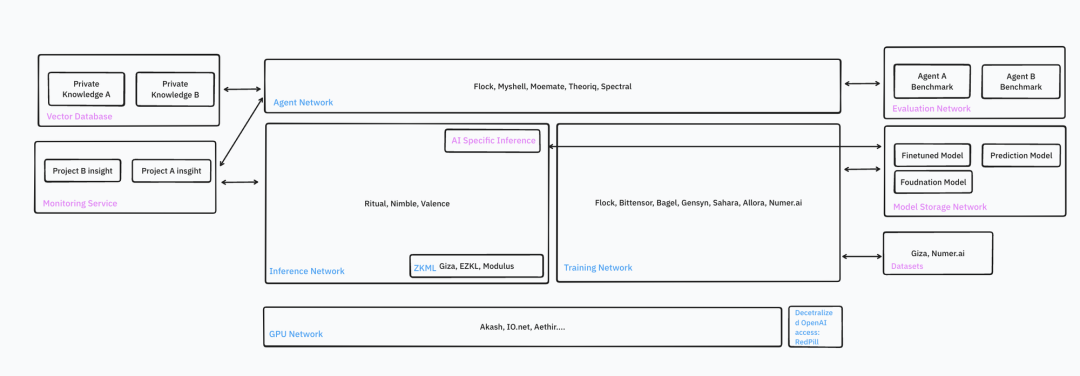
Les principaux outils pour construire des applications IA décentralisées (AI Dapp) incluent l’accès décentralisé à OpenAI, les réseaux GPU, les réseaux d’inférence et les réseaux d’agents.
Les réseaux GPU suscitent un engouement encore plus fort que durant l’ère du minage de Bitcoin, car : le marché IA est plus vaste, en croissance rapide et stable ; des millions d’applications dépendent quotidiennement de l’IA ; des besoins variés en modèles GPU et en localisations serveur existent ; les technologies sont désormais matures ; et la clientèle ciblée est bien plus large.
Les réseaux d’inférence et les réseaux d’agents reposent sur des infrastructures similaires mais ont des objectifs distincts. Les réseaux d’inférence ciblent principalement les développeurs expérimentés souhaitant déployer leurs propres modèles, y compris non basés sur LLM, qui n’exigent pas toujours un GPU. En revanche, les réseaux d’agents se concentrent sur les LLM : les développeurs n’ont pas besoin d’héberger leur propre modèle, mais peuvent se concentrer sur l’ingénierie des prompts et la composition d’agents. Ces réseaux nécessitent systématiquement des GPU performants.
Les projets d’infrastructure IA affichent des ambitions considérables et continuent d’introduire régulièrement de nouvelles fonctionnalités.
La plupart des projets natifs de la crypto restent en phase testnet, avec des problèmes de stabilité, des configurations complexes, des fonctionnalités limitées, et doivent encore prouver leur sécurité et confidentialité.
Si les AI Dapps devenaient dominantes, de nombreux domaines resteraient inexploités : surveillance, infrastructures liées au RAG, modèles natifs Web3, agents décentralisés intégrant des API et données natives crypto, réseaux d’évaluation, etc.
L’intégration verticale constitue une tendance marquée : les infrastructures visent à offrir des solutions clés en main, simplifiant le développement des AI Dapps.
L’avenir sera hybride : certaines inférences seront exécutées côté client (frontend), d’autres sur chaîne (on-chain), afin d’optimiser coût et vérifiabilité.
Source : IOSG
Introduction
La fusion entre Web3 et IA est aujourd’hui l’un des sujets les plus discutés dans l’écosystème crypto. Des développeurs talentueux construisent activement des infrastructures IA pour le monde crypto, cherchant à insuffler de l’intelligence aux contrats intelligents. Développer des AI Dapps est extrêmement complexe : les développeurs doivent gérer données, modèles, puissance de calcul, opérations, déploiement et intégration blockchain. Face à ces besoins, les fondateurs du Web3 ont proposé des solutions préliminaires telles que les réseaux GPU, l’annotation communautaire de données, les modèles entraînés collectivement, l’inférence et l’entraînement IA vérifiables, ou encore les boutiques d’agents.
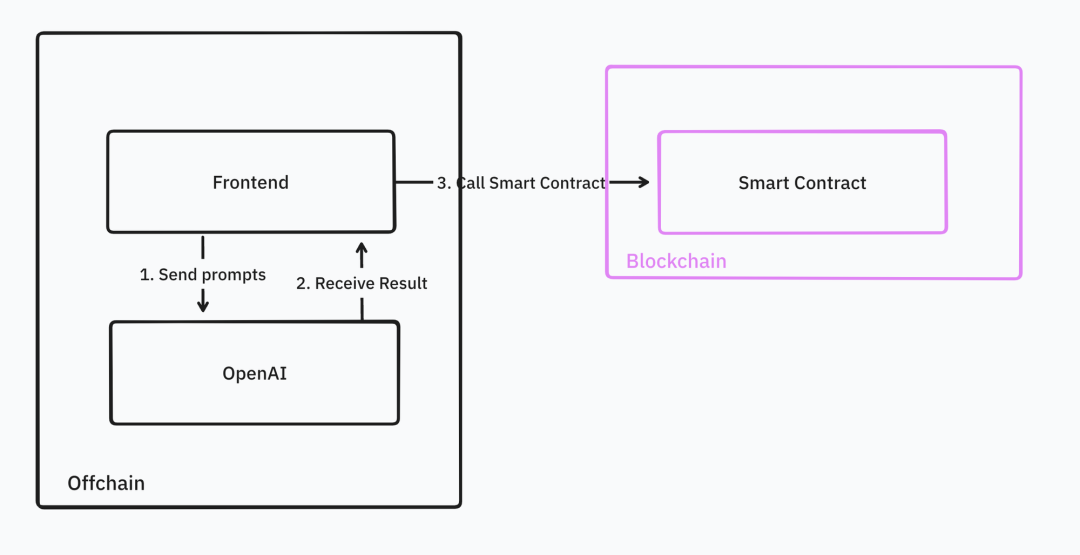
Malgré cet essor des infrastructures, peu d’applications exploitent réellement l’IA ou sont conçues pour elle. Les développeurs cherchant des tutoriels pour créer des AI Dapps constatent que ceux-ci sont rares, et que la majorité se contentent d’appeler l’API OpenAI côté frontend.
Source : IOSG Ventures
Les applications actuelles ne tirent pas pleinement parti des caractéristiques fondamentales de la blockchain — décentralisation et vérifiabilité. Cependant, cette situation devrait rapidement évoluer. La majorité des infrastructures IA crypto ont déjà lancé leurs réseaux tests et prévoient de passer en production dans les six mois à venir.
Cette étude présente en détail les principaux outils disponibles dans l’infrastructure IA du secteur crypto. Préparons-nous à vivre le moment « GPT-3.5 » du monde crypto !
1. RedPill : accès décentralisé à OpenAI
Le projet RedPill, dans lequel nous avons investi, constitue un excellent point d’entrée.
OpenAI propose plusieurs modèles parmi les plus puissants au monde — GPT-4-vision, GPT-4-turbo et GPT-4o — idéaux pour construire des AI Dapps avancés.
Les développeurs peuvent intégrer l’API OpenAI dans leurs dApps via des oracles ou des interfaces frontend.
RedPill agrège les clés API OpenAI de divers développeurs sous une seule interface, offrant aux utilisateurs mondiaux un service d’intelligence artificielle rapide, économique et vérifiable. Ainsi, RedPill démocratise l’accès aux meilleurs modèles IA. Son algorithme de routage dirige chaque requête vers un contributeur spécifique. Les demandes passent par son réseau de distribution, contournant ainsi les restrictions potentielles imposées par OpenAI, et résolvant plusieurs problèmes courants rencontrés par les développeurs crypto :
Limites TPM (tokens par minute) : les nouveaux comptes ont un quota limité, insuffisant pour les dApps populaires fortement dépendantes de l’IA.
Restrictions d’accès : certains modèles restreignent l’accès aux nouveaux comptes ou à certains pays.
En conservant le même code de requête tout en changeant simplement l’hôte, les développeurs peuvent accéder aux modèles OpenAI à faible coût, avec une grande évolutivité et sans restriction.

2. Réseaux GPU
Outre l’utilisation de l’API OpenAI, de nombreux développeurs choisissent d’héberger eux-mêmes leurs modèles. Ils peuvent alors recourir à des réseaux GPU décentralisés comme io.net, Aethir ou Akash, pour créer des clusters GPU et déployer divers modèles internes ou open source.
Ces réseaux GPU décentralisés mobilisent la puissance de calcul individuelle ou de petits centres de données, offrant flexibilité de configuration, choix étendu de localisations serveur et coûts réduits, permettant aux développeurs de tester facilement des projets IA même avec un budget limité. Toutefois, en raison de leur nature décentralisée, ils présentent encore certaines limitations en termes de fonctionnalité, d’utilisabilité et de confidentialité des données.
Depuis plusieurs mois, la demande pour les GPU dépasse même celle observée lors du pic du minage Bitcoin. Cette flambée s’explique notamment par :
Un élargissement de la clientèle : les réseaux GPU servent désormais des développeurs IA, en nombre croissant et plus fidèles, moins sensibles aux fluctuations des prix des cryptomonnaies.
Contrairement aux équipements spécialisés pour le minage, les GPU décentralisés offrent une plus grande diversité de modèles et de spécifications, adaptés à différents besoins. Par exemple, les grands modèles exigent davantage de VRAM, tandis que les tâches mineures peuvent utiliser des GPU plus légers. De plus, la proximité géographique des serveurs réduit la latence.
Une technologie de plus en plus mature : les réseaux GPU s’appuient sur des blockchains rapides comme Solana pour le règlement, sur Docker pour la virtualisation, et sur Ray pour les clusters de calcul.
Des perspectives de retour sur investissement attractives : le marché IA est en expansion, offrant de nombreuses opportunités de nouveaux usages. Le rendement attendu pour un GPU H100 est de 60 à 70 %, contre un minage Bitcoin plus incertain, où la concurrence est féroce et la production limitée.
Des entreprises traditionnelles du minage Bitcoin comme Iris Energy, Core Scientific et Bitdeer se tournent désormais vers les réseaux GPU, proposent des services IA et achètent massivement des GPU dédiés à l’IA, comme le H100.
Recommandation : Pour les développeurs Web2 peu exigeants sur les SLA, io.net offre une expérience simple et intuitive, et constitue un excellent rapport qualité-prix.
3. Réseaux d’inférence
Il s’agit du cœur des infrastructures IA natives de la crypto. À l’avenir, ces réseaux prendront en charge des milliards d’opérations d’inférence IA. De nombreux projets IA Layer1 ou Layer2 permettent aux développeurs d’appeler nativement des inférences IA directement depuis la chaîne. Les leaders du marché incluent Ritual, Valence et Fetch.ai.
Ces réseaux diffèrent selon plusieurs critères :
Performance (latence, temps de calcul)
Modèles supportés
Vérifiabilité
Prix (coût on-chain, coût d’inférence)
Expérience développeur
3.1 Objectif
Dans un scénario idéal, les développeurs pourraient accéder facilement, depuis n’importe où et sous n’importe quelle forme de preuve, à des services d’inférence IA personnalisés, avec une intégration quasi transparente.
Les réseaux d’inférence fournissent tous les outils de base nécessaires : génération et vérification à la demande de preuves, calcul d’inférence, relais et validation des données, interfaces Web2 et Web3, déploiement unifié de modèles, surveillance système, opérations inter-chaînes, intégration synchrone et exécution planifiée.
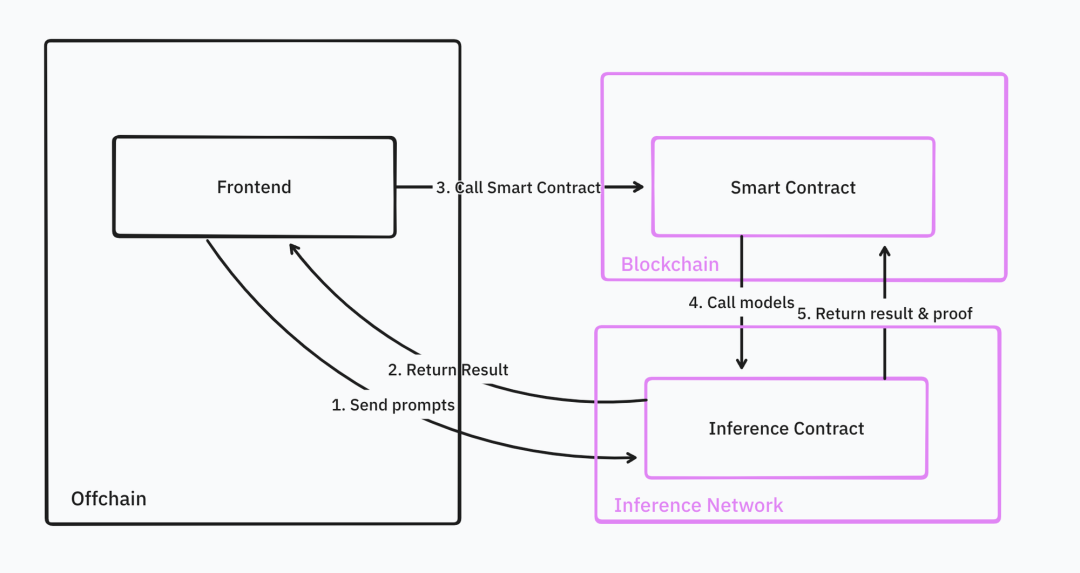
Source : IOSG Ventures
Grâce à ces fonctionnalités, les développeurs peuvent intégrer sans friction les services d’inférence à leurs contrats intelligents existants. Par exemple, en construisant un robot de trading DeFi, celui-ci pourrait utiliser un modèle de machine learning pour identifier les moments optimaux d’achat/vente sur une paire donnée, puis exécuter automatiquement la stratégie sur la plateforme de base.
Dans un cas idéal, toute l’infrastructure serait hébergée dans le cloud. Le développeur n’aurait qu’à téléverser son modèle de stratégie (au format standard comme Torch), que le réseau d’inférence stockerait et mettrait à disposition pour des requêtes Web2 et Web3.
Une fois le modèle déployé, le développeur pourrait appeler directement l’inférence via une API Web3 ou un contrat intelligent. Le réseau exécuterait alors continuellement la stratégie et renverrait les résultats au contrat principal. Si le montant géré par la communauté est important, une vérification des résultats d’inférence peut être nécessaire. Une fois reçus, le contrat intelligent agirait en conséquence.
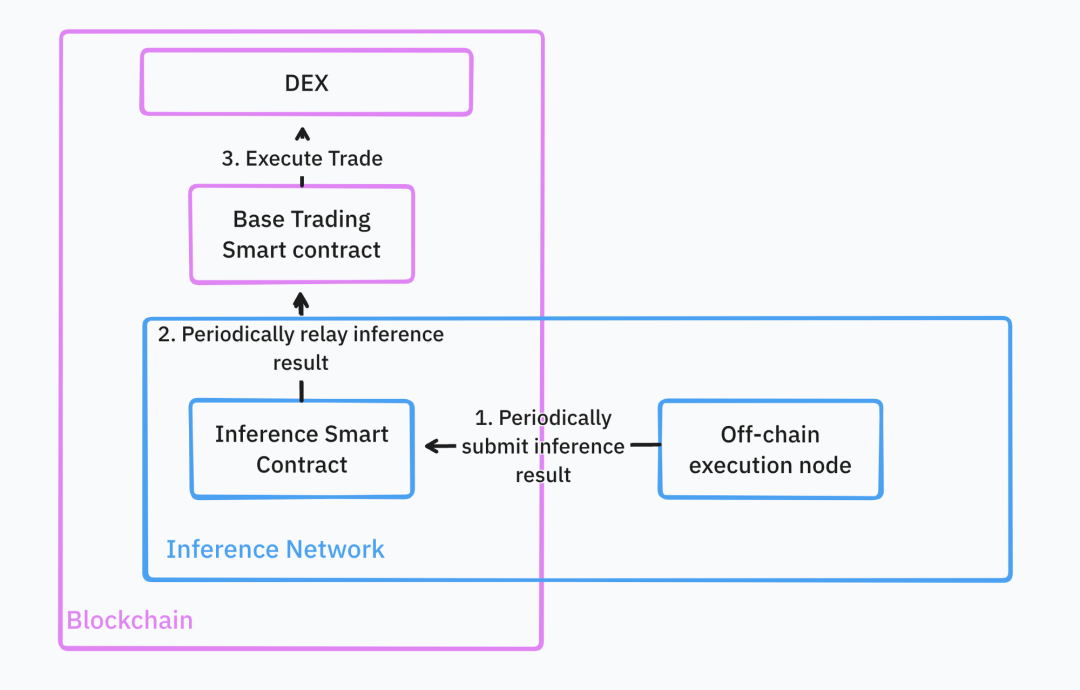
Source : IOSG Ventures
3.1.1 Asynchrone vs Synchrone
Théoriquement, l’exécution asynchrone permet de meilleures performances, mais nuit à l’expérience développeur.
Dans un modèle asynchrone, le développeur doit d’abord soumettre sa tâche au contrat intelligent du réseau d’inférence. Une fois terminée, le résultat est renvoyé. Ce modèle sépare logiquement l’appel d’inférence et le traitement du résultat.
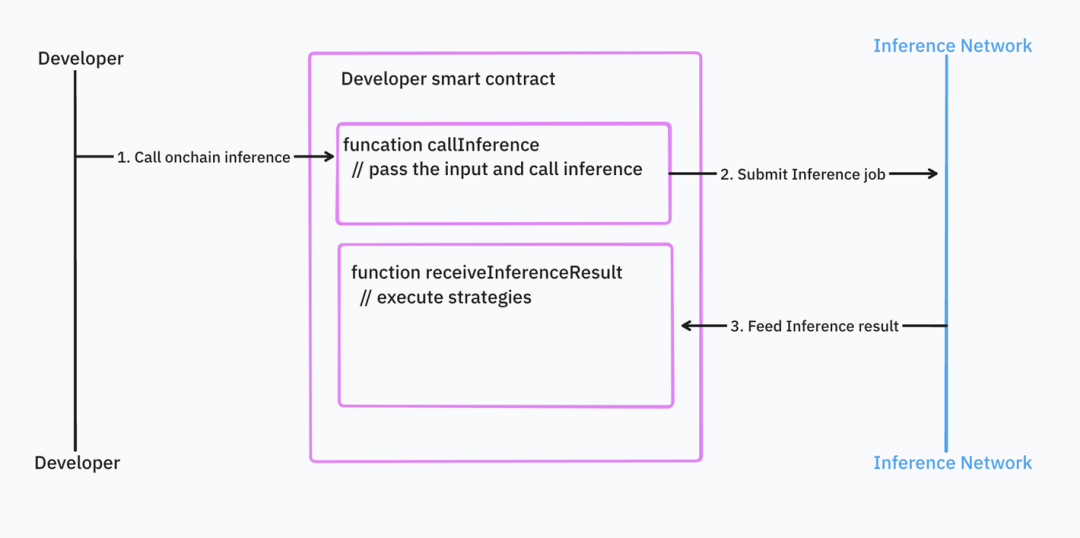
Source : IOSG Ventures
Si le développeur utilise des appels imbriqués ou de nombreuses logiques de contrôle, la situation se complique.
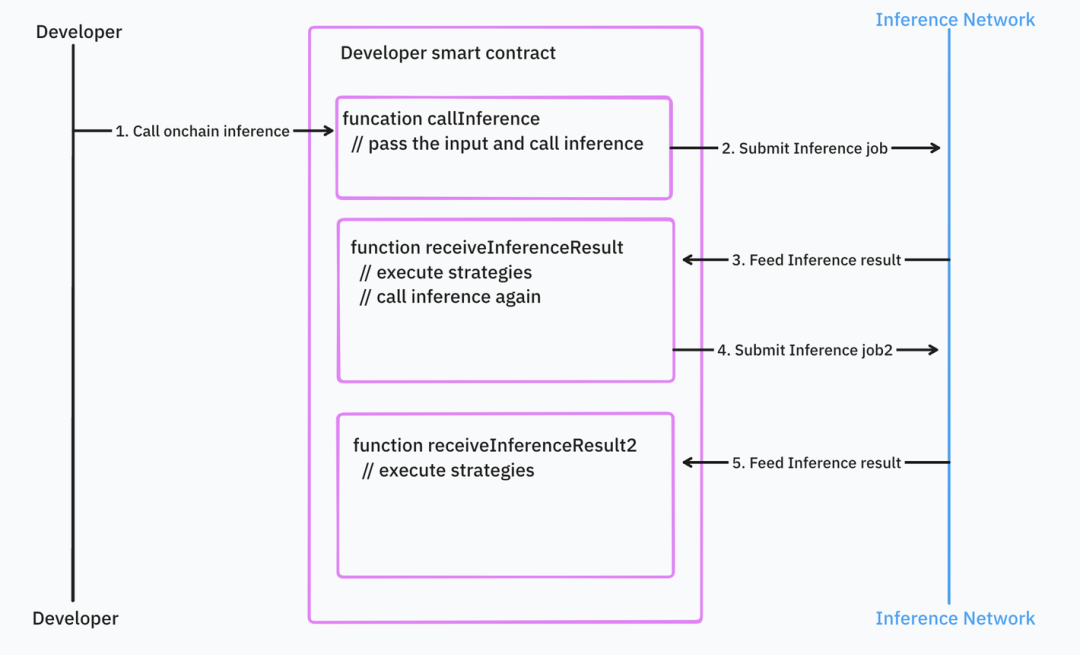
Source : IOSG Ventures
Ce modèle rend difficile l’intégration avec les contrats intelligents existants, obligeant à écrire beaucoup de code supplémentaire, gérer les erreurs et les dépendances.
À l’inverse, la programmation synchrone est plus intuitive, mais pose des défis en termes de temps de réponse et de conception blockchain. Par exemple, si les données d’entrée sont volatiles (prix, horodatage bloc), elles peuvent devenir obsolètes dès la fin de l’inférence, conduisant à des erreurs d’exécution nécessitant un rollback. Imaginez effectuer une transaction avec un prix périmé.
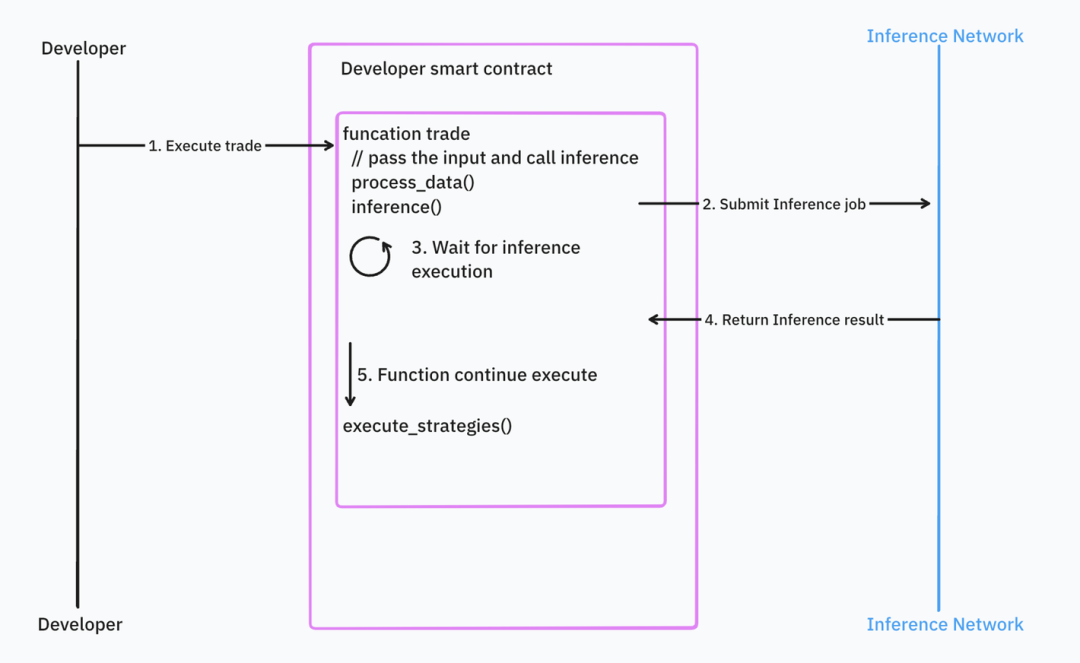
Source : IOSG Ventures
La plupart des infrastructures IA adoptent le traitement asynchrone, mais Valence cherche à résoudre ces problèmes.
3.2 Situation actuelle
En réalité, de nombreux réseaux d’inférence sont encore en phase test, comme Ritual. Selon leurs documents publics, leurs fonctionnalités sont actuellement limitées (vérification, preuves, etc. non encore disponibles). Ils n’offrent pas encore une infrastructure cloud complète pour le calcul IA on-chain, mais plutôt un cadre pour auto-héberger le calcul IA et transmettre les résultats à la chaîne.
Voici un exemple d’architecture pour des NFT AIGC : un modèle de diffusion génère un NFT, stocké sur Arweave, puis le réseau d’inférence frappe le NFT sur chaîne en utilisant cette adresse Arweave.
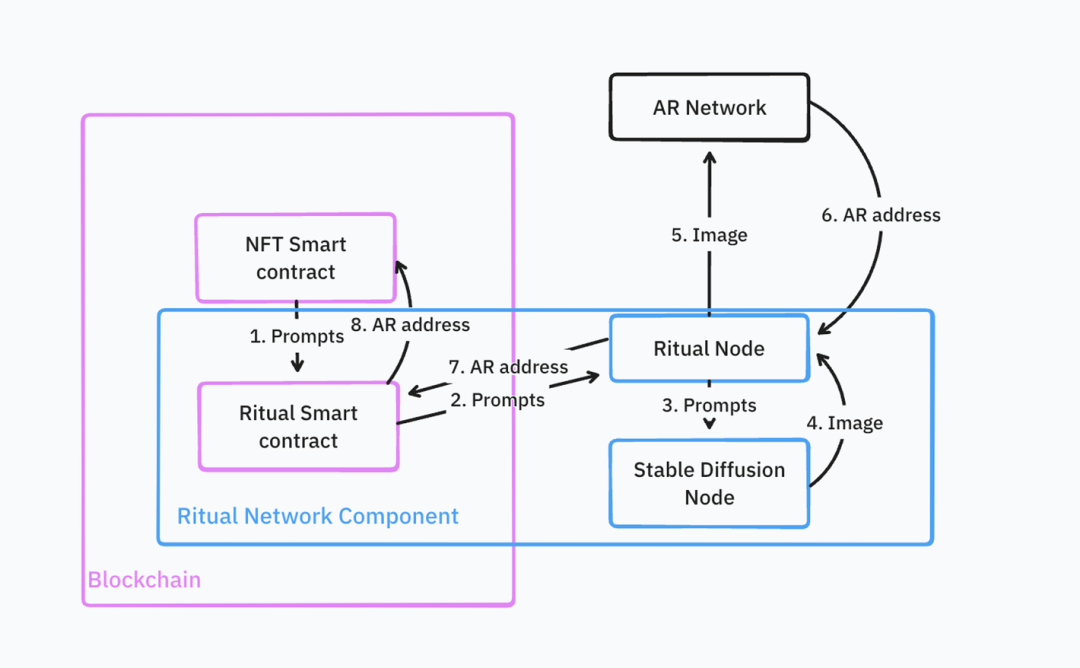
Source : IOSG Ventures
Ce processus reste complexe : le développeur doit déployer et maintenir lui-même la majorité de l’infrastructure (nœud Ritual personnalisé, nœud Stable Diffusion, contrat NFT).
Recommandation : Actuellement, les réseaux d’inférence sont complexes à intégrer et à déployer pour des modèles personnalisés, et la plupart ne supportent pas encore la vérification. Utiliser l’IA côté frontend reste une option plus simple. Pour la vérification, le fournisseur ZKML Giza est un bon choix.
4. Réseaux d’agents
Les réseaux d’agents permettent aux utilisateurs de personnaliser facilement des agents autonomes. Composés d’entités ou de contrats intelligents capables d’exécuter des tâches, de collaborer entre eux et d’interagir avec la blockchain sans intervention humaine, ils ciblent principalement les technologies LLM. Par exemple, ils peuvent offrir un chatbot GPT spécialisé sur Ethereum. Pour l’instant, leurs outils restent limités, empêchant le développement d’applications complexes.
Source : IOSG Ventures
À l’avenir, ces réseaux doteront les agents de capacités accrues : accès à des connaissances, appel d’API externes, exécution de tâches spécifiques. Les développeurs pourront combiner plusieurs agents en flux de travail. Par exemple, écrire un contrat Solidity pourrait impliquer plusieurs agents spécialisés : design du protocole, développement Solidity, audit de sécurité, déploiement.
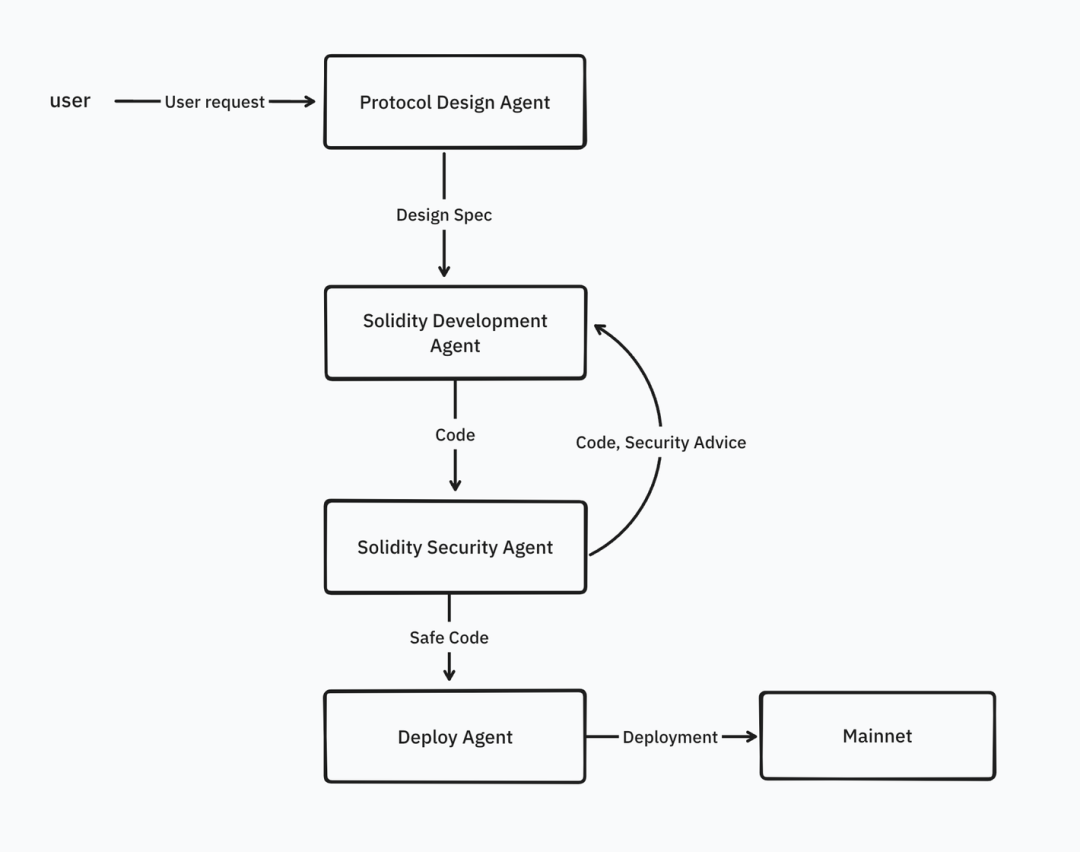
Source : IOSG Ventures
Nous coordonnons ces agents grâce à des prompts et des scénarios.
Parmi les exemples de réseaux d’agents : Flock.ai, Myshell, Theoriq.
Recommandation : Aujourd’hui, la plupart des agents restent limités. Pour des cas d’usage précis, les agents Web2 offrent de meilleurs services, avec des outils d’orchestration mûrs comme Langchain ou Llamaindex.
5. Différences entre réseaux d’agents et réseaux d’inférence
Les réseaux d’agents se concentrent surtout sur les LLM, offrant des outils comme Langchain pour connecter plusieurs agents. Généralement, les développeurs n’ont pas à créer leurs propres modèles ML : le réseau simplifie leur développement et déploiement. Il suffit de relier les agents et outils nécessaires. Souvent, l’utilisateur final interagit directement avec ces agents.
Les réseaux d’inférence constituent l’infrastructure sous-jacente des réseaux d’agents. Ils offrent un accès de bas niveau aux développeurs. Normalement, l’utilisateur final n’y accède pas directement. Le développeur doit déployer ses propres modèles (pas uniquement des LLM) et peut y accéder via des points d’entrée on-chain ou off-chain.
Les deux types de réseaux ne sont pas totalement indépendants. On observe déjà des produits intégrés verticalement, combinant les deux fonctions grâce à des infrastructures communes.

6. Nouvelles opportunités
Au-delà de l’inférence, de l’entraînement et des agents, le Web3 offre de nombreux autres terrains d’exploration :
Jeu de données : comment transformer les données blockchain en jeux de données exploitables par le machine learning ? Les développeurs ML ont besoin de données spécifiques et thématiques. Par exemple, Giza propose des jeux de données haute qualité sur le DeFi, dédiés à l’entraînement ML. L’idéal serait d’aller au-delà des tableaux simples vers des données graphiques représentant les interactions dans l’univers blockchain. Ce domaine reste encore immature. Certains projets comme Bagel et Sahara encouragent la création collective de jeux de données, en garantissant la confidentialité des contributeurs.
Stockage de modèles : certains modèles sont très volumineux. Comment les stocker, distribuer et gérer en version ? C’est crucial pour les performances et coûts du ML on-chain. Filecoin, AR et 0g font figure de pionniers.
Entraînement de modèles : l’entraînement distribué et vérifiable reste un défi. Gensyn, Bittensor, Flock et Allora ont fait des progrès notables.
Surveillance : comme l’inférence se produit à la fois on-chain et off-chain, de nouvelles infrastructures sont nécessaires pour suivre l’utilisation des modèles, détecter anomalies et biais. Des outils adaptés permettront aux développeurs ML du Web3 d’ajuster et optimiser continuellement la précision de leurs modèles.
Infrastructure RAG : le RAG distribué exige une nouvelle infrastructure, avec des besoins élevés en stockage, calcul d’embedding et bases de données vectorielles, tout en assurant la confidentialité. Cela diffère fortement des solutions actuelles, largement tributaires de tiers comme Firstbatch ou Bagel.
Modèles spécialisés Web3 : tous les modèles ne conviennent pas au contexte Web3. Souvent, un réentraînement est nécessaire pour des usages précis (prévision de prix, recommandation, etc.). Avec le développement des infrastructures IA, on peut espérer voir émerger davantage de modèles natifs Web3. Par exemple, Pond développe un GNN blockchain pour la prévision de prix, la recommandation, la détection de fraudes et la lutte contre le blanchiment.
Réseaux d’évaluation : évaluer des agents sans feedback humain est difficile. Avec la prolifération des outils de création d’agents, un système sera nécessaire pour mesurer leurs compétences et aider les utilisateurs à choisir le meilleur agent selon le contexte. Neuronets est un acteur dans ce domaine.
Mécanismes de consensus : PoS n’est pas forcément optimal pour les tâches IA. Complexité du calcul, difficulté de vérification et absence de déterminisme sont des obstacles majeurs. Bittensor a inventé un nouveau mécanisme de consensus intelligent, récompensant les nœuds contribuant aux modèles et sorties ML du réseau.
7. Perspectives futures
Nous observons une tendance claire vers l’intégration verticale. En construisant une couche de calcul de base, les réseaux peuvent supporter diverses tâches ML — entraînement, inférence, agents — offrant ainsi une solution complète « tout-en-un » aux développeurs ML du Web3.
Actuellement, l’inférence on-chain reste coûteuse et lente, mais offre une excellente vérifiabilité et une intégration fluide avec les systèmes backend (comme les contrats intelligents). L’avenir sera hybride : une partie des inférences s’exécutera côté frontend ou off-chain, tandis que les décisions critiques seront traitées on-chain. Ce modèle est déjà utilisé sur mobile : les petits modèles s’exécutent localement pour rapidité, tandis que les tâches complexes sont envoyées dans le cloud pour traitement par de grands LLM.















