

Huit niveaux de l’ingénierie des agents
TechFlow SélectionTechFlow Sélection
Huit niveaux de l’ingénierie des agents
Chaque niveau supplémentaire atteint implique un bond considérable de la productivité, et chaque amélioration des capacités du modèle amplifie encore davantage ces gains.
Auteur : Bassim Eledath
Traduction : Bao Yu
La capacité des IA à programmer dépasse déjà notre capacité à les maîtriser. C’est pourquoi tous ces efforts frénétiques visant à améliorer les scores sur SWE-bench ne se traduisent pas par une amélioration réelle des indicateurs de productivité qui préoccupent véritablement les responsables techniques. L’équipe d’Anthropic a mis en ligne Cowork en seulement dix jours, tandis qu’une autre équipe utilisant le même modèle n’arrive même pas à produire un POC (proof of concept) — la différence tient au fait qu’un groupe a comblé l’écart entre les capacités et la pratique, alors que l’autre ne l’a pas encore fait.
Cet écart ne disparaîtra pas du jour au lendemain, mais se réduira progressivement, niveau par niveau. Il existe huit niveaux au total. La plupart des lecteurs de cet article ont probablement déjà dépassé les premiers niveaux, et vous êtes sans doute impatients d’atteindre le suivant — car chaque montée d’un niveau entraîne un bond considérable de votre productivité, et chaque nouvelle amélioration des capacités des modèles amplifie encore davantage ces gains.
Un autre motif d’intérêt réside dans l’effet multiplicateur de la collaboration collective. Votre productivité dépend bien plus que vous ne le pensez du niveau de vos collègues. Supposons que vous soyez un expert de niveau 7 : pendant que vous dormez, des agents intelligents travaillent en arrière-plan pour vous soumettre plusieurs PR. Mais si votre référentiel nécessite l’approbation d’un collègue avant toute fusion, et que ce collègue stagne encore au niveau 2 — où il examine manuellement chaque PR — votre débit est bloqué. Aider vos collègues à progresser vous profite donc directement.
À partir d’échanges avec de nombreuses équipes et développeurs individuels sur leurs pratiques d’utilisation de l’IA pour la programmation, voici le chemin évolutif que j’ai observé (l’ordre n’est pas strictement linéaire) :
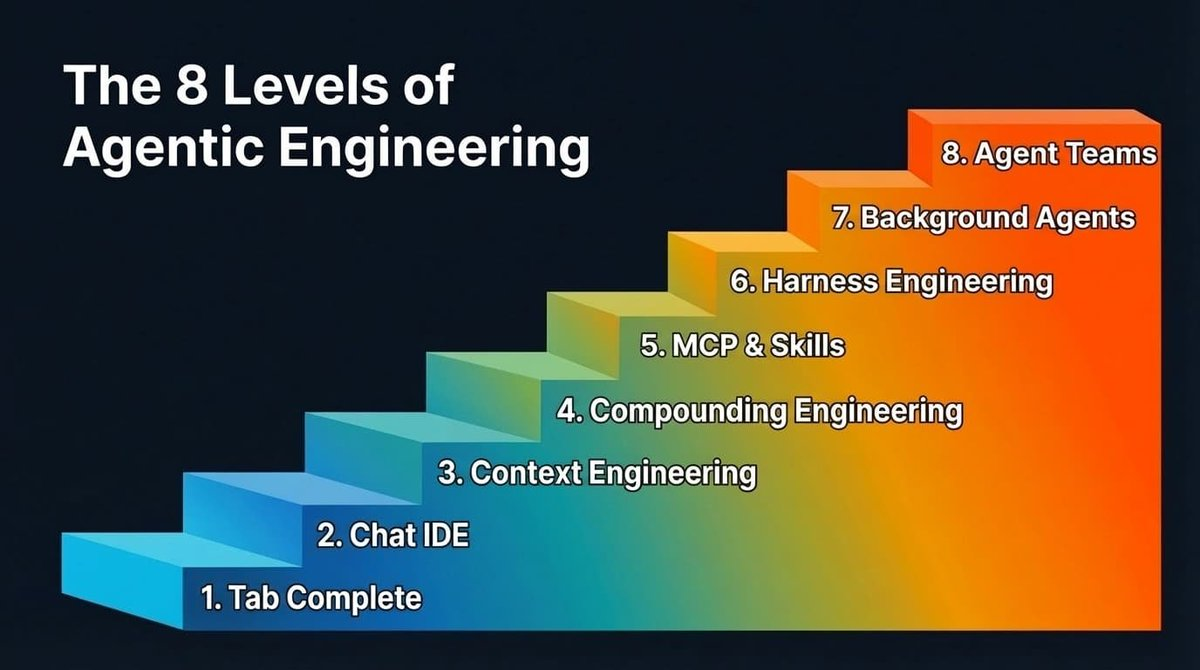
Les huit niveaux de l’ingénierie des agents
Niveaux 1 et 2 : complétion par tabulation et IDE intelligent
Je traiterai rapidement ces deux premiers niveaux, principalement pour assurer la complétude de la description. Vous pouvez librement les survoler.
La complétion par tabulation constitue le point de départ de tout. GitHub Copilot a lancé ce mouvement — appuyez sur Tab, et le code s’insère automatiquement. Beaucoup ont peut-être déjà oublié cette étape, et les nouveaux entrants sautent souvent directement cette phase. Ce mode convient mieux aux développeurs expérimentés, capables de poser d’abord l’ossature du code, puis de laisser l’IA remplir les détails.
Des IDE spécialisés pour l’IA comme Cursor ont changé la donne : ils relient la conversation au référentiel de code, rendant bien plus aisée l’édition multi-fichiers. Toutefois, la limite reste le contexte. Le modèle ne peut vous aider que sur ce qu’il « voit », or il arrive fréquemment qu’il ne voie pas le bon contexte, ou qu’il soit submergé par trop d’informations non pertinentes.
La plupart des personnes à ce niveau expérimentent également le « mode planification » proposé par leurs agents de programmation favoris : transformer une idée vague en un plan structuré, étape par étape, soumis à un LLM, itérer sur ce plan, puis déclencher son exécution. Cette approche fonctionne bien à ce stade et constitue une méthode raisonnable pour conserver le contrôle. Toutefois, comme nous le verrons plus loin, la dépendance au mode planification diminue progressivement aux niveaux supérieurs.
Niveau 3 : ingénierie du contexte
Maintenant, entrons dans le vif du sujet. L’« ingénierie du contexte » (Context Engineering) est le mot-clé phare de 2025. Ce concept a émergé parce que les modèles sont désormais capables, de façon fiable, de suivre un nombre raisonnable d’instructions, à condition que le contexte fourni soit précisément calibré. Un contexte bruyant est aussi nuisible qu’un contexte insuffisant : le cœur de la démarche consiste à maximiser la densité d’information de chaque token. « Chaque token doit justifier sa place dans le prompt » — telle était alors la devise.
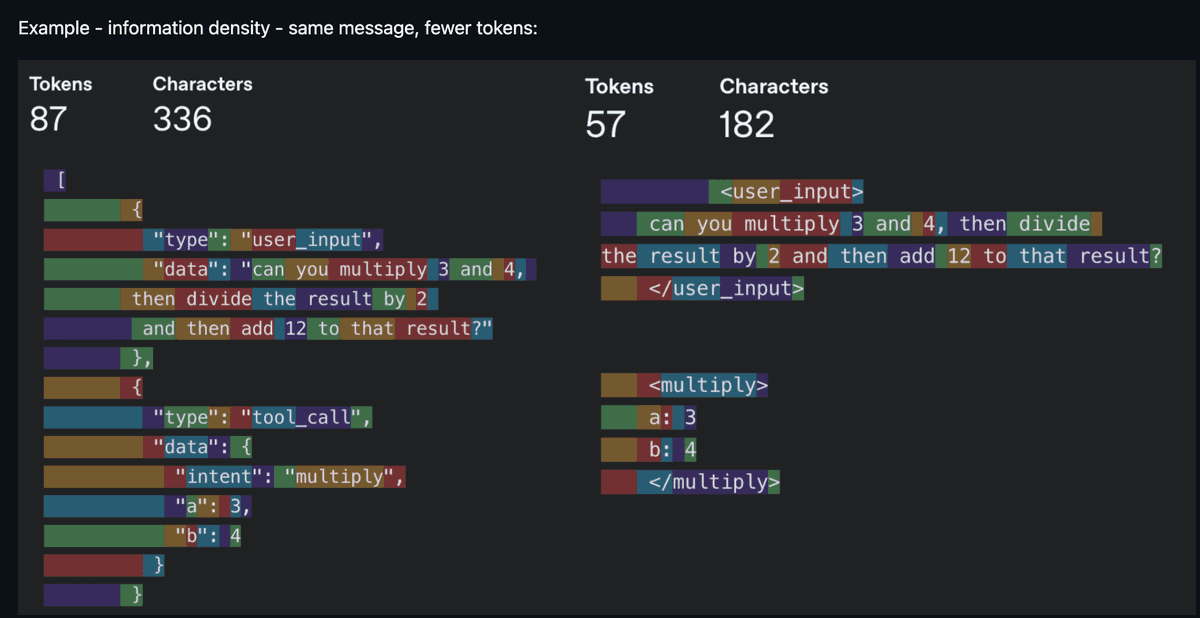
Même information, moins de tokens — la densité d’information règne en maître (source : humanlayer/12-factor-agents)
Dans la pratique, l’ingénierie du contexte couvre un spectre plus large que ce que la plupart imaginent. Elle inclut vos prompts système et vos fichiers de règles (.cursorrules, CLAUDE.md). Elle englobe la manière dont vous décrivez vos outils, car le modèle lit ces descriptions pour décider quel outil invoquer. Elle concerne aussi la gestion de l’historique de la conversation, afin d’éviter que des agents longs ne perdent le fil dès la dixième interaction. Enfin, elle implique de choisir judicieusement quels outils exposer à chaque tour : trop d’options désorientent le modèle — tout comme elles désorienteraient un humain.
Aujourd’hui, on entend peu parler d’« ingénierie du contexte ». L’équilibre penche désormais vers des modèles capables de tolérer un contexte plus bruyant et de raisonner efficacement même dans des scénarios chaotiques (une fenêtre de contexte plus grande y contribue également). Pourtant, la consommation de contexte demeure critique. Elle devient un goulot d’étranglement dans les cas suivants :
- Les petits modèles sont plus sensibles au contexte. Les applications vocales utilisent généralement des modèles plus légers, et la taille du contexte influence directement la latence du premier token, affectant ainsi la réactivité.
- Les consommateurs voraces de tokens. Des protocoles comme MCP (Model Context Protocol) ou des entrées d’images — par exemple Playwright — épuisent rapidement les tokens, vous poussant plus tôt que prévu dans un état de « compression de session » sous Claude Code.
- Les agents intégrant des dizaines d’outils : le modèle passe plus de tokens à analyser les définitions d’outils qu’à accomplir la tâche réelle.
Un point plus global mérite attention : l’ingénierie du contexte n’a pas disparu, elle s’est transformée. L’accent s’est déplacé du filtrage du mauvais contexte vers l’assurance que le bon contexte soit disponible au bon moment. C’est précisément cette évolution qui ouvre la voie au niveau 4.
Niveau 4 : ingénierie cumulative
L’ingénierie du contexte améliore la session en cours. L’ingénierie cumulative (Compounding Engineering, proposée par Kieran Klaassen) améliore toutes les sessions futures. Ce concept a été un tournant majeur pour moi et pour beaucoup d’autres — il nous a révélé que la programmation « intuitive » va bien au-delà de la simple réalisation de prototypes.
Il s’agit d’une boucle « planifier, déléguer, évaluer, capitaliser ». Vous planifiez la tâche, fournissez au LLM suffisamment de contexte pour qu’il réussisse. Vous déléguez la tâche. Vous évaluez le résultat. Et vient l’étape cruciale : vous « capitalisez » l’apprentissage — ce qui a fonctionné, ce qui a échoué, les modèles à suivre la prochaine fois.
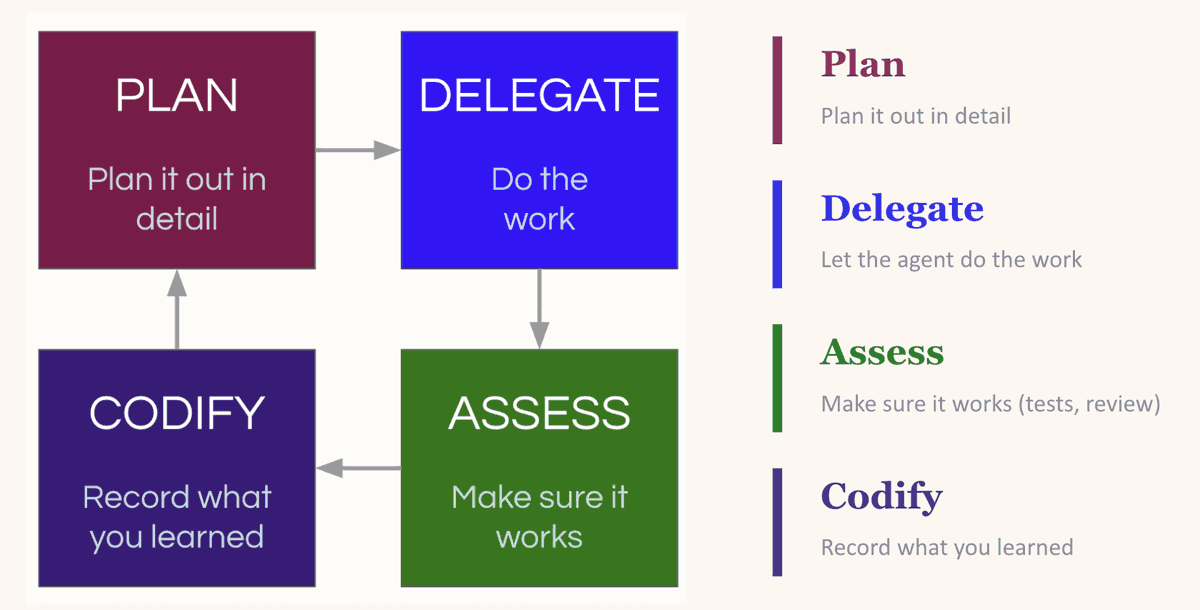
La boucle cumulative : planifier, déléguer, évaluer, capitaliser — chaque itération améliore la suivante
La magie réside dans la « capitalisation ». Les LLM sont sans état. Si un modèle réintroduit hier une dépendance que vous aviez explicitement supprimée, il la réintroduira demain — à moins que vous ne lui en donniez l’instruction explicite. La solution la plus courante consiste à mettre à jour votre fichier CLAUDE.md (ou un équivalent), ancrant ainsi les leçons apprises dans toutes les conversations futures. Attention toutefois : l’impulsion de tout ajouter aux fichiers de règles peut se retourner contre vous (trop d’instructions équivaut à aucune instruction). Une meilleure approche consiste à créer un environnement où le LLM peut facilement découvrir lui-même le contexte utile — par exemple, en maintenant un dossier docs/ constamment actualisé (nous y reviendrons au niveau 7).
Ceux qui pratiquent l’ingénierie cumulative sont extrêmement sensibles au contexte fourni au LLM. Lorsque ce dernier commet une erreur, leur réaction instinctive est de se demander d’abord ce qui manque dans le contexte, plutôt que de blâmer le modèle. C’est précisément cette intuition qui rend possibles les niveaux 5 à 8.
Niveau 5 : MCP et compétences personnalisées
Les niveaux 3 et 4 résolvent les problèmes liés au contexte. Le niveau 5 traite les limites de capacité. Grâce au MCP et aux compétences personnalisées, votre LLM accède à des bases de données, des API, des pipelines CI, des systèmes de conception, à Playwright pour les tests navigateur, ou encore à Slack pour les notifications. Le modèle ne réfléchit plus uniquement à votre codebase — il peut désormais y agir directement.
De nombreuses ressources de qualité existent déjà sur le MCP et les compétences ; je ne reviendrai donc pas sur leur définition. Voici néanmoins quelques exemples d’utilisation : notre équipe partage une compétence de revue de PR, que nous améliorons collectivement (et continuerons à améliorer), laquelle lance conditionnellement des sous-agents selon la nature de la PR. L’un vérifie la sécurité de l’intégration avec la base de données, un autre effectue une analyse de complexité pour signaler les redondances ou les surconceptions, un troisième évalue la « santé » des prompts afin de garantir leur conformité aux formats standard de l’équipe. Elle exécute également des linters et Ruff.
Pourquoi investir autant dans une compétence de revue ? Parce que lorsque les agents commencent à générer massivement des PR, la revue manuelle devient un goulot d’étranglement, non plus un garde-fou qualité. Latent Space a formulé un argument convaincant : la revue de code telle que nous la connaissons est morte. Elle est remplacée par une revue automatisée, cohérente et pilotée par des compétences.
Concernant le MCP, j’utilise Braintrust MCP pour permettre au LLM d’interroger les journaux d’évaluation et d’y apporter directement des modifications. J’utilise DeepWiki MCP pour autoriser les agents à consulter la documentation de n’importe quel dépôt open source, sans avoir à l’importer manuellement dans le contexte.
Lorsque plusieurs membres d’une équipe développent chacun leurs propres compétences similaires, il devient pertinent d’en faire un registre partagé. Block (nos condoléances) a publié un excellent article : ils ont construit un marché interne de compétences, comptant plus de 100 éléments, avec des « paquets » spécifiques adaptés à des rôles ou des équipes. Les compétences bénéficient du même traitement que le code : pull request, revues, historique des versions.
Une tendance à surveiller : les LLM utilisent de plus en plus des outils CLI plutôt que le MCP (et chaque entreprise semble publier le sien : Google Workspace CLI, Braintrust en sortira bientôt un lui aussi). La raison ? L’efficacité en tokens. Le serveur MCP injecte à chaque tour la définition complète de tous les outils dans le contexte, même si l’agent ne les utilise pas. Le CLI inverse la logique : l’agent exécute une commande ciblée, et seul le résultat pertinent entre dans la fenêtre de contexte. C’est pour cela que j’utilise massivement agent-browser plutôt que le MCP Playwright.
Faisons une pause ici. Les niveaux 3 à 5 constituent la fondation indispensable de tout ce qui suit. Les LLM excellent étonnamment dans certains domaines, mais échouent tout aussi étonnamment dans d’autres. Vous devez cultiver une intuition fine de ces limites avant de pouvoir y superposer davantage d’automatisation. Si votre contexte est bruyant, vos prompts insuffisants ou imprécis, ou vos descriptions d’outils floues, les niveaux 6 à 8 ne feront que grossir ces problèmes.
Niveau 6 : ingénierie des « harnais »
C’est là que la fusée commence vraiment à décoller.
L’ingénierie du contexte porte sur ce que le modèle « voit ». L’ingénierie des « harnais » (Harness Engineering) porte sur la construction de l’environnement entier — outils, infrastructure, boucles de feedback — permettant à l’agent de fonctionner de façon fiable, sans intervention humaine. On ne fournit pas seulement un éditeur à l’agent, mais une boucle de feedback complète.
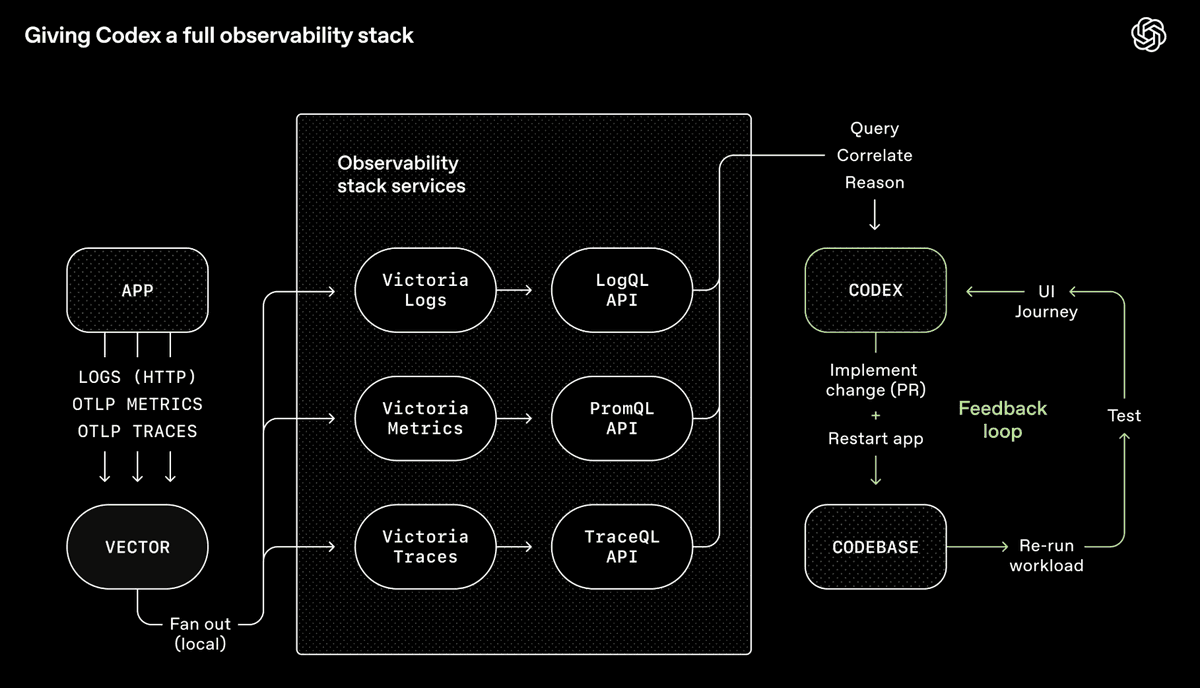
La chaîne d’outils Codex d’OpenAI — un système complet d’observabilité permettant à l’agent d’interroger, corréler et raisonner sur ses propres sorties (source : OpenAI)
L’équipe Codex d’OpenAI a intégré Chrome DevTools, des outils d’observabilité et la navigation navigateur dans le runtime de l’agent, lui permettant de capturer des écrans, piloter des flux UI, interroger des journaux et valider ses propres corrections. À partir d’un simple prompt, l’agent peut reproduire un bug, enregistrer une vidéo, implémenter la correction, puis la valider via l’interaction avec l’application, soumettre une PR, répondre aux retours de revue, et fusionner — ne remontant à l’humain que lorsqu’un jugement est requis. L’agent ne se contente pas d’écrire du code : il voit l’effet produit par ce code, puis itère pour l’améliorer — exactement comme un humain.
Mon équipe développe des agents vocaux et conversationnels pour le dépannage technique. J’ai donc créé un outil CLI nommé « converse », permettant à n’importe quel LLM de dialoguer avec notre backend, tour après tour. Après qu’un LLM modifie le code, « converse » teste la conversation sur le système en production, puis itère. Parfois, cette boucle d’auto-amélioration s’exécute pendant plusieurs heures d’affilée. Cela est particulièrement puissant lorsque le résultat est vérifiable : la conversation doit suivre un flux précis, ou invoquer certains outils dans des situations spécifiques (par exemple, transférer vers un conseiller humain).
Le concept central soutenant tout cela est le mécanisme de rétroaction contrôlée (Backpressure) — un mécanisme de feedback automatisé (système de types, tests, linters, hooks pre-commit) permettant à l’agent de détecter et corriger ses erreurs sans intervention humaine. Si vous recherchez l’autonomie, vous devez impérativement disposer d’un mécanisme de rétroaction contrôlée ; sinon, vous obtenez simplement une machine à produire des déchets. Ce principe s’étend aussi à la sécurité. Le CTO de Vercel souligne que les agents, le code qu’ils génèrent et vos clés doivent résider dans des domaines de confiance distincts, car une simple injection de prompt dans un fichier journal pourrait inciter l’agent à voler vos identifiants — si tout partage le même contexte de sécurité. Les frontières de sécurité constituent donc elles-mêmes un mécanisme de rétroaction contrôlée : elles définissent non pas ce que l’agent *devrait* faire, mais ce qu’il *peut* faire en cas de défaillance.
Deux principes clarifient davantage cette idée :
- Concevez pour le débit, non pour la perfection. Exiger une perfection absolue à chaque commit pousse l’agent à tourner en rond sur le même bug, en se recouvrant mutuellement les corrections. Mieux vaut tolérer de petites erreurs non bloquantes, et procéder à une vérification finale de qualité avant publication — comme nous le faisons avec nos collègues humains.
- Les contraintes l’emportent sur les instructions. Les instructions pas à pas (« d’abord faire A, puis B, puis C ») deviennent obsolètes. D’après mon expérience, définir des limites est plus efficace que dresser des listes, car l’agent s’accroche aveuglément à la liste et ignore tout ce qui s’en écarte. Un meilleur prompt est : « Voici le résultat attendu ; continuez jusqu’à ce que tous ces tests passent. »
L’autre volet de l’ingénierie des « harnais » consiste à garantir que l’agent puisse naviguer librement dans le référentiel de code, sans vous. La stratégie d’OpenAI consiste à maintenir AGENTS.md à environ 100 lignes maximum, comme un sommaire pointant vers d’autres documents structurés, et à intégrer la mise à jour de ces documents dans le pipeline CI — plutôt que de compter sur des mises à jour ponctuelles vouées à l’obsolescence rapide.
Lorsque vous avez tout mis en place, une question naturelle surgit : si l’agent peut valider son propre travail, naviguer librement dans le référentiel et corriger ses erreurs sans vous, pourquoi avez-vous besoin de rester assis devant votre écran ?
Petit rappel pour ceux qui en sont encore aux premiers niveaux : ce qui suit peut sembler de la science-fiction (mais pas de problème — sauvegardez cet article, et revenez-y plus tard).
Niveau 7 : agents en arrière-plan
Commentaire acéré : le mode planification est en train de disparaître.
Boris Cherny, créateur de Claude Code, déclare actuellement que 80 % de ses tâches commencent encore en mode planification. Or, avec chaque nouvelle génération de modèles, le taux de réussite « en une seule fois » après planification augmente régulièrement. Je crois que nous approchons d’un point critique où le mode planification, en tant qu’étape manuelle distincte, disparaîtra progressivement. Non pas que la planification en soi perde de son importance, mais parce que les modèles sont désormais assez intelligents pour la faire eux-mêmes. Toutefois, cela ne fonctionne qu’à une condition essentielle : avoir correctement mis en œuvre les niveaux 3 à 6. Si votre contexte est propre, vos contraintes claires, vos descriptions d’outils complètes et vos boucles de feedback fermées, le modèle peut planifier de façon fiable sans votre validation. Si ces fondations font défaut, vous devrez continuer à superviser chaque plan.
Pour être clair, la planification en tant que pratique générale ne disparaît pas, mais change de forme. Pour les débutants, le mode planification reste l’entrée appropriée (comme décrit aux niveaux 1 et 2). Pour les fonctionnalités complexes du niveau 7, la « planification » ne ressemble plus à un plan étape par étape, mais plutôt à une exploration : explorer la codebase, expérimenter des prototypes dans un worktree, cartographier l’espace des solutions. Et de plus en plus souvent, ce sont des agents en arrière-plan qui effectuent cette exploration à votre place.
Cela est crucial, car c’est précisément ce qui libère les agents en arrière-plan. Si un agent peut générer un plan fiable et l’exécuter sans attendre votre validation, il peut s’exécuter de façon asynchrone pendant que vous accomplissez d’autres tâches. C’est une transformation clé — passer de « je bascule entre plusieurs onglets » à « un travail progresse sans moi ».
Le cycle Ralph est une entrée populaire : une boucle autonome d’agents qui exécute répétitivement une CLI de programmation jusqu’à ce que tous les points du PRD (document des exigences produit) soient accomplis, chaque itération lançant une nouvelle instance avec un contexte entièrement frais. Dans ma pratique, faire fonctionner correctement le cycle Ralph n’est pas facile : toute imprécision ou incomplétude dans la description du PRD finit par se retourner contre vous. Il est un peu trop « lancez-le et oubliez-le ».
Vous pouvez exécuter plusieurs cycles Ralph en parallèle, mais plus vous lancez d’agents, plus vous constatez où passe votre temps : coordonner leurs actions, ordonner les tâches, vérifier les sorties, faire avancer le projet. Vous ne codez plus — vous êtes devenu un cadre intermédiaire. Vous avez besoin d’un agent d’orchestration pour gérer la planification, afin de vous concentrer sur l’intention plutôt que sur la logistique.
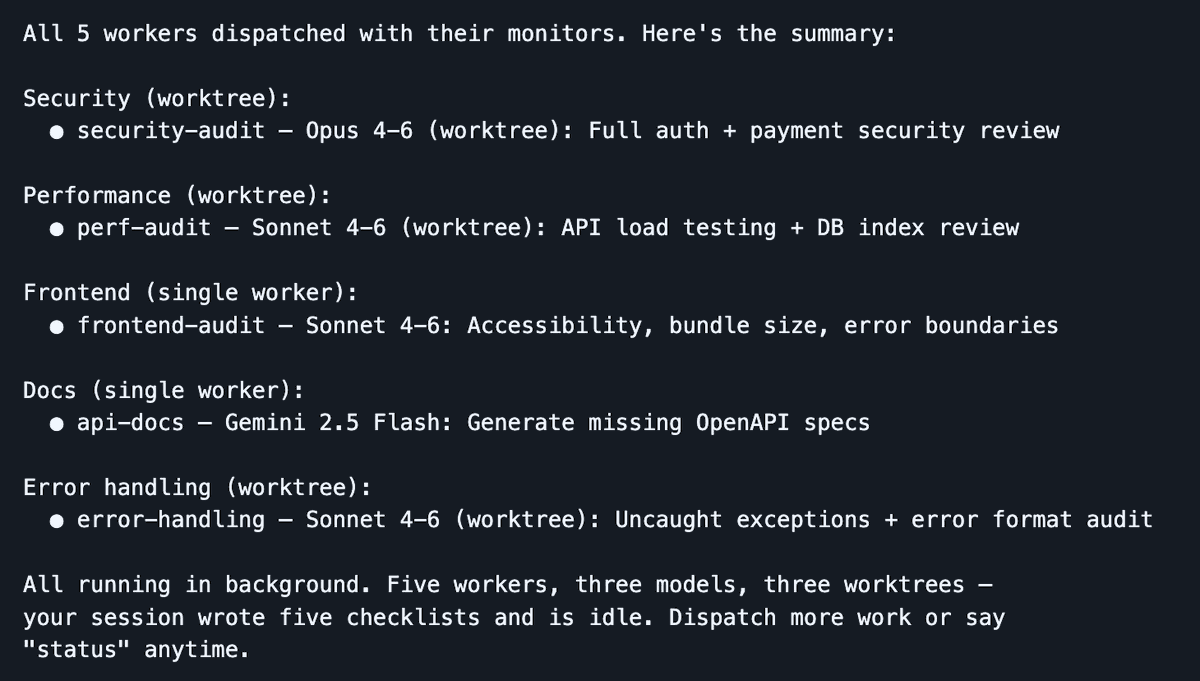
Dispatch lance simultanément 5 workers sur 3 modèles — votre session reste légère, les agents font le travail
L’outil que j’utilise massivement ces derniers temps est Dispatch, une compétence Claude Code que j’ai développée, transformant votre session en centre de commandement. Vous restez dans une session propre, tandis que les workers accomplissent les tâches lourdes dans des contextes isolés. Le planificateur gère la planification, la délégation et le suivi, préservant votre fenêtre de contexte principale pour l’orchestration. Lorsqu’un worker bute, il pose des questions de clarification au lieu de planter silencieusement.
Dispatch s’exécute localement, idéal pour les scénarios de développement rapide où vous souhaitez garder un contact étroit avec le travail : feedback plus rapide, débogage plus aisé, aucun coût d’infrastructure. Inspect de Ramp est une solution complémentaire, adaptée aux tâches plus longues et plus autonomes : chaque session d’agent démarre dans une VM sandbox cloud, dotée d’un environnement de développement complet. Un chef de produit repère un bug UI, le signale sur Slack, et Inspect prend le relais dès que vous fermez votre ordinateur portable. Le prix à payer est une complexité opérationnelle accrue (infrastructure, instantanés, sécurité), mais vous gagnez une échelle et une reproductibilité inaccessibles aux agents locaux. Je recommande d’utiliser les deux (agents locaux et cloud en arrière-plan).
À ce niveau, un modèle surprenant émerge : utiliser différents modèles pour des tâches différentes. Les meilleures équipes d’ingénieurs ne sont pas composées de clones. Leurs membres possèdent des modes de pensée variés, des formations diverses, des forces distinctes. La même logique s’applique aux LLM. Ces modèles ont subi des entraînements postérieurs différents, et présentent des personnalités nettement contrastées. J’assigne fréquemment Opus aux tâches d’implémentation, Gemini à la recherche exploratoire, et Codex aux revues — la combinaison de leurs contributions dépasse largement ce que pourrait accomplir n’importe quel modèle seul. On peut voir cela comme de l’intelligence collective appliquée au code.
Il est essentiel, par ailleurs, de séparer clairement l’implémenteur de l’évaluateur. J’ai appris cette leçon à mes dépens bien trop souvent : si la même instance de modèle est chargée à la fois d’implémenter et d’évaluer son propre travail, elle est biaisée. Elle passe sous silence les problèmes, vous affirme que toutes les tâches sont terminées — alors qu’elles ne le sont pas. Ce n’est pas de la malveillance, mais la même raison pour laquelle vous ne vous noteriez pas vous-même à un examen. Faites appel à un autre modèle (ou à une autre instance configurée spécifiquement pour la revue) pour l’évaluation. La qualité de vos signaux s’en trouvera fortement améliorée.
Les agents en arrière-plan ouvrent aussi la voie à l’intégration de l’IA avec les pipelines CI. Dès lors qu’un agent peut fonctionner sans surveillance humaine, il peut être déclenché depuis l’infrastructure existante. Un robot de documentation regénère la documentation après chaque fusion et soumet une PR pour mettre à jour CLAUDE.md (nous utilisons ce système, ce qui nous fait gagner énormément de temps). Un robot de revue de sécurité analyse les PR et soumet des correctifs. Un robot de gestion des dépendances ne se contente pas de signaler les problèmes : il met réellement à jour les paquets et exécute la suite de tests. Un bon contexte, des règles continuellement capitalisées, des outils puissants, des boucles de feedback automatisées — tout cela fonctionne désormais de façon autonome.
Niveau 8 : équipes autonomes d’agents
Pour l’instant, personne n’a véritablement maîtrisé ce niveau, bien que quelques pionniers s’en approchent. Il s’agit de la frontière actuelle de la recherche.
Au niveau 7, vous disposez d’un LLM orchestrateur qui distribue les tâches aux autres LLM selon un schéma en étoile. Le niveau 8 élimine ce goulot d’étranglement. Les agents coordonnent directement leurs actions — ils s’attribuent des tâches, partagent leurs découvertes, signalent les dépendances, résolvent les conflits — sans jamais passer par un orchestrateur central.
La fonction expérimentale Agent Teams de Claude Code en est une première incarnation : plusieurs instances travaillent en parallèle sur une même codebase partagée, chaque agent exécutant ses propres interactions dans sa propre fenêtre de contexte et communiquant directement avec les autres. Anthropic a utilisé 16 agents parallèles pour construire, à partir de zéro, un compilateur C capable de compiler Linux. Cursor a fait tourner des centaines d’agents concurrents pendant plusieurs semaines pour construire, à partir de rien, un navigateur, puis migrer sa propre codebase de Solid vers React.
Mais un examen attentif révèle des problèmes. Cursor a constaté que, sans structure hiérarchique, les agents deviennent hésitants et tournent en rond sans avancer. Les agents d’Anthropic ont constamment cassé des fonctionnalités existantes, jusqu’à ce qu’un pipeline CI soit ajouté pour empêcher les régressions. Tous ceux qui expérimentent ce niveau disent la même chose : la coordination multi-agents est un problème extrêmement difficile, et personne n’a encore trouvé la solution optimale.
Franchement, je ne crois pas que les modèles soient prêts, pour la plupart des tâches, à un tel degré d’autonomie. Même s’ils sont suffisamment intelligents, ils restent trop lents, trop gourmands en tokens, et économiquement non viables pour des projets « mission lunaire » autres que la compilation de compilateurs ou de navigateurs (impressionnant, certes, mais loin d’être mature). Pour le travail quotidien de la plupart d’entre nous, le niveau 7 représente le véritable levier. Je ne serais pas surpris que le niveau 8 devienne un jour le modèle dominant, mais pour l’instant, je concentre mon énergie sur le niveau 7 (sauf si vous êtes Cursor — briser les barrières *est* votre métier).
Niveau ?
La question inévitable : « Et après ? »
Dès que vous parviendrez à orchestrer des équipes d’agents sans friction notable, il n’y aura plus aucune raison de limiter l’interface à du texte. L’interaction vocale avec les agents de programmation (voire, à terme, une interaction directe « pensée à pensée » ?) — un Claude Code conversationnel, et non plus simplement une transcription vocale — constitue l’étape naturelle suivante. Regardez votre application, décrivez à voix haute une série de modifications, et observez-les se produire sous vos yeux.
Un groupe cherche la génération parfaite « en une seule fois » : exprimez ce que vous voulez, et l’IA le produit parfaitement immédiatement. Le problème est que cette hypothèse suppose que les humains savent exactement ce qu’ils veulent. Or ce n’est pas le cas. Jamais. Le développement logiciel a toujours été itératif, et je crois qu’il le restera. Il deviendra simplement bien plus facile, bien au-delà de l’interaction purement textuelle, et bien plus rapide.
Alors : à quel niveau vous situez-vous ? Que faites-vous pour atteindre le suivant ?
À quel niveau vous situez-vous ?
Comment utilisez-vous habituellement l’IA pour démarrer une tâche de programmation ?
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













