

GitHub Copilot passe à un modèle payant, révélant le plus grand mensonge de l’industrie de l’IA
TechFlow SélectionTechFlow Sélection
GitHub Copilot passe à un modèle payant, révélant le plus grand mensonge de l’industrie de l’IA
OpenAI, Anthropic et Microsoft subventionnent tous simultanément votre utilisation, mais ce jeu est sur le point de devenir insoutenable.
Auteur : Ed Zitron
Traduction : TechFlow
Introduction de TechFlow : Microsoft a finalement cédé. GitHub Copilot passe d’un modèle d’abonnement mensuel à une facturation à l’usage (par token). Ce n’est pas une mise à niveau produit, mais l’effondrement collectif de la « supercherie subventionnée » qui sous-tend toute l’industrie de l’IA : OpenAI, Anthropic et d’autres masquent leurs coûts réels derrière des abonnements mensuels, incitant les utilisateurs à dépenser 1 dollar tout en brûlant 8 à 13 dollars de puissance de calcul — ce qui façonne des habitudes d’utilisation impossibles à pérenniser sur le long terme. Lorsque les prix reviendront à la réalité, vous découvrirez que ces outils d’IA « révolutionnaires » ne sont peut-être qu’un jouet coûteux.
Je viens de publier un article sur la façon dont OpenAI a éliminé Oracle ; celui-ci reprend certains éléments de ce texte. C’est l’un des meilleurs articles que j’aie jamais écrits, et j’en suis très fier.
S’abonner à la version payante est non seulement excellent rapport qualité-prix, mais cela me permet aussi de publier chaque semaine ces grandes études approfondies, gratuites pour tous.
Hier matin, les utilisateurs de GitHub Copilot ont reçu la confirmation d’une annonce que j’avais déjà signalée il y a une semaine : tous les forfaits GitHub Copilot passeront à une facturation à l’usage à compter du 1er juin 2026.
Microsoft ne fournit plus aux utilisateurs un nombre fixe de « requêtes », mais facture désormais selon le coût réel d’inférence du modèle utilisé — ce que Microsoft qualifie de « … étape importante vers une activité Copilot durable et fiable, ainsi qu’une expérience utilisateur optimale ». La quantité d’usage désormais disponible dépend directement de la valeur des tokens achetés avec l’abonnement (par exemple, un forfait mensuel de 19 dollars permet d’utiliser pour 19 dollars de tokens).
Traduction libre : « Nous ne pouvons plus subventionner les utilisateurs de GitHub Copilot — sinon Amy Hood, la directrice financière de Microsoft, va nous assommer à coups de batte de baseball. »
Cette annonce elle-même constitue déjà un aperçu fascinant de la manière dont ces changements tarifaires seront présentés :
Copilot n’est plus le même produit qu’il y a un an. Il s’est transformé d’un simple assistant intégré à l’éditeur en une plateforme d’agents intelligents capables de mener des sessions de codage longues et multi-étapes, en exploitant les modèles les plus récents pour itérer sur l’ensemble d’un codebase. L’utilisation d’agents devient le mode par défaut, ce qui entraîne une augmentation significative des besoins en calcul et en inférence. Aujourd’hui, une simple question en chat rapide peut coûter autant qu’une session autonome de codage de plusieurs heures. GitHub a absorbé jusqu’ici cette hausse continue des coûts d’inférence, mais le modèle actuel basé sur un quota de requêtes n’est plus viable à long terme. La facturation à l’usage résout ce problème : elle aligne mieux les tarifs sur l’usage réel, garantit la fiabilité du service sur le long terme, et réduit la nécessité de limiter les utilisateurs intensifs.
Vous voyez, ce n’est pas Microsoft qui subventionne la puissance de calcul de près de deux millions d’utilisateurs — c’est que l’IA est devenue si puissante et complexe qu’elle est fondamentalement devenue un produit différent !
Bien que Copilot « ne soit plus le même produit qu’il y a un an », la déconnexion économique sous-jacente n’a guère changé : depuis trois ans, Microsoft autorise ses utilisateurs à consommer chaque mois bien plus de tokens que leur abonnement ne le justifie. Selon un article du Wall Street Journal daté d’octobre 2023 :
Les utilisateurs particuliers paient 10 dollars par mois pour cet assistant IA. D’après des données fournies par une source bien informée, au cours des premiers mois de l’année, l’entreprise perdait en moyenne plus de 20 dollars par utilisateur et par mois, certains arrivant même à coûter 80 dollars mensuels à l’entreprise.
Naturellement, les utilisateurs de GitHub Copilot se soulèvent aujourd’hui, déclarant que le produit est « mort » ou « complètement ruiné ».
J’avais prédit ce jour-là dès mon article de il y a deux ans, « La crise des subprimes de l’IA » :
Ce jour est enfin arrivé, car chaque service IA que vous utilisez subventionne sa puissance de calcul — et chaque service perd donc de l’argent :
Lorsque vous payez un service fourni par une startup IA — y compris OpenAI et Anthropic — vous payez un abonnement mensuel : par exemple, Claude d’Anthropic coûte 20, 100 ou 200 dollars par mois ; Perplexity, 20 ou 200 dollars par mois ; OpenAI, 8, 20 ou 200 dollars par mois. Dans certains scénarios professionnels, on vous accorde un certain « quota » d’unités de travail — par exemple, Lovable inclut « 100 quotas mensuels » dans son abonnement à 25 dollars/mois, ainsi que 25 dollars d’hébergement cloud (jusqu’au premier trimestre 2026), les quotas pouvant être reportés d’un mois sur l’autre. Lorsque vous utilisez ces services, la société concernée paie soit un tarif au laboratoire IA par million de tokens, soit (dans le cas d’Anthropic et d’OpenAI) des frais à un fournisseur de services cloud pour louer des GPU afin d’exécuter ses modèles. Un token représente approximativement trois quarts de mot. En tant qu’utilisateur, vous ne percevez pas la consommation de tokens — vous ne faites que saisir une entrée et recevoir une sortie. Les laboratoires IA masquent les coûts réels du service à l’aide de termes comme « tokens », « messages » ou « limites de débit à 5 heures avec pourcentage », si bien que vous, utilisateur, ignorez totalement combien tout cela coûte réellement. En arrière-plan, les startups IA brûlent de l’argent à un rythme effréné : jusqu’à récemment, Anthropic permettait à ses utilisateurs de brûler jusqu’à 8 dollars de puissance de calcul pour chaque dollar d’abonnement. OpenAI faisait de même, bien que le montant exact soit difficile à mesurer.
Les startups IA et les géants du cloud pensaient pouvoir attirer suffisamment d’utilisateurs grâce à des produits subventionnés et déficitaires, créant une forme de dépendance telle qu’aucun client ne voudrait changer de fournisseur même face à une hausse tarifaire. Ils pensaient également que le coût des tokens diminuerait avec le temps — or ce qui s’est produit, c’est que si certains modèles ont effectivement baissé en prix, les modèles d’inférence les plus récents consomment davantage de tokens, ce qui fait que les coûts d’inférence augmentent globalement avec le temps.
Les deux hypothèses se sont révélées fausses, car le modèle d’abonnement mensuel ne tient pas logiquement pour aucun service connecté à un grand modèle linguistique (LLM).
Le modèle économique central de l’IA générative s’est effondré
Considérez-le ainsi. Lorsque Uber (non, ce n’est pas du tout comparable à Uber) augmente ses tarifs, la logique économique sous-jacente ne change pas, ni ce que voient conducteurs et passagers : le client paie pour un trajet, le conducteur est rémunéré pour un trajet. Le conducteur doit toujours payer l’essence, l’assurance automobile, les licences exigées par les autorités locales, et potentiellement les coûts de financement liés à son véhicule — rien de tout cela n’est subventionné par Uber. Les pertes colossales d’Uber proviennent des subventions, des dépenses marketing incessantes, et des efforts de R&D voués à l’échec, comme les voitures autonomes.
L’abonnement IA n’a strictement rien à voir avec Uber
Pour illustrer l’ampleur de cette déconnexion tarifaire, je vous demande d’imaginer une histoire parallèle dans laquelle Uber adopterait un modèle économique très différent.
L’abonnement IA générative ressemble à ce qui se produirait si Uber facturait 20 dollars par mois pour 100 trajets de moins de 100 miles, alors que l’essence coûterait 150 dollars le gallon — et qu’Uber paierait lui-même l’essence, parce que quelqu’un affirme que le pétrole deviendra un jour si bon marché qu’il ne vaudra même plus la peine d’être compté.
Uber déciderait finalement de commencer à facturer aux utilisateurs un abonnement mensuel pour accéder au service, puis de les faire payer séparément selon la quantité d’essence consommée. Du jour au lendemain, les utilisateurs passeraient de 20 dollars par mois pour 100 trajets à 20 dollars pour l’accès au service + 26 dollars pour 10 miles parcourus. Naturellement, ils seraient quelque peu mécontents.
Bien que cela semble exagéré, c’est en réalité une métaphore remarquablement précise de ce qui se produit actuellement dans l’industrie de l’IA générative — en particulier avec GitHub Copilot.
La tarification antérieure de GitHub Copilot permettait 300 requêtes avancées par mois, ainsi que des « requêtes illimitées en chat » utilisant des modèles comme GPT-5 mini. Chaque « requête » (selon les propres termes de Microsoft) correspond à « … toute interaction où vous demandez à Copilot de faire quelque chose pour vous ». Dans les systèmes basés sur les requêtes, les modèles plus coûteux consomment davantage de requêtes — par exemple, Claude Opus 4.6 utilise trois requêtes avancées. Une fois vos requêtes avancées épuisées, Copilot vous permet d’utiliser librement pendant le reste du mois les modèles moins chers.
Cela n’a pas toujours été le cas. Jusqu’en mai 2025, Microsoft offrait encore une utilisation illimitée des modèles — et même ainsi, les utilisateurs s’indignaient de toute restriction imposée au produit.
Microsoft — comme toutes les entreprises IA — a trompé ses clients en vendant un service non viable, car la commercialisation de services pilotés par des LLM sur un modèle d’abonnement mensuel n’a jamais eu de sens, et n’en aura jamais.
Si vous souhaitez estimer le coût d’un service facturé par token, un utilisateur du sous-forum GitHub Copilot a découvert que le coût moyen d’une requête avancée était d’environ 11 dollars, car une « requête » implique l’utilisation de 60 000 tokens dans la fenêtre de contexte, plusieurs outils, et de nombreux « tours » internes (les opérations effectuées par le modèle) pour générer une sortie.
Il y a aussi l’instabilité fondamentale des grands modèles linguistiques, sujets aux hallucinations. Bien qu’il soit frustrant qu’une requête avancée entre dans une boucle infinie et génère un code partiellement corrompu, ce même dysfonctionnement devient bien moins excusable lorsque vous payez personnellement pour chaque erreur.
Les utilisateurs ont également été formés à utiliser le produit d’une manière radicalement différente de celle qui serait adaptée à une facturation par token. Je pense que beaucoup ne réalisent même pas combien de « tokens » ils consomment, ni combien une tâche donnée en nécessite — ce chiffre variant selon le modèle utilisé.
Cela n’a strictement rien à voir avec Uber. Toute personne vous disant le contraire cherche simplement à justifier une conduite répréhensible. Uber a certes augmenté ses prix, mais il n’a pas dû modifier dramatiquement la logique économique sous-jacente de sa plateforme, ni obliger ses utilisateurs à changer radicalement leur façon d’utiliser le service — comme si Uber venait soudain à facturer au gallon d’essence.
Tous les abonnements mensuels IA font partie intégrante de la supercherie subventionnée de l’IA — une tentative délibérée de dissocier l’IA générative de ses coûts réels
Il n’y a jamais eu — et il n’y aura jamais — de modèle économiquement viable pour fournir un service piloté par LLM, sauf en facturant chaque utilisateur selon sa consommation réelle de tokens. Et, en trompant ces utilisateurs, ces entreprises ont créé des produits dotés d’avantages illusoires et de rendements sur investissement douteux.
Cela était évident depuis des années.
D’un point de vue économique, un abonnement mensuel n’est justifié que lorsque les coûts sont relativement stables. Une salle de sport peut vendre des abonnements, car elle connaît approximativement l’usure du matériel, les coûts des cours, et les dépenses d’électricité, de personnel et d’eau sur une période donnée.
Pour les clients de Google Workspace — du moins avant l’ère de l’IA — les coûts consistent principalement en l’accès ou le stockage de documents, ainsi que les coûts permanents associés à Google Docs et autres services. Le coût du stockage numérique étant relativement faible (et contrairement aux LLM, Google Workspace n’a pas besoin d’une puissance de calcul élevée), un utilisateur très intensif de Google Drive ne grève pas significativement la rentabilité de son abonnement mensuel.
Cependant, ces services cachent délibérément le nombre de tokens ou le coût réel d’une activité donnée, ce qui signifie que les utilisateurs ne comprennent pas vraiment ce que représentent les limites de débit — et que chaque changement soudain de ces limites plonge les clients dans une course frénétique pour déterminer combien de travail réel ils peuvent encore accomplir avec le service.
C’est une pratique commerciale abusive, manipulatrice et trompeuse, dont le seul objectif est d’élargir la base d’utilisateurs pour Anthropic, OpenAI et d’autres entreprises IA — car la plupart des utilisateurs d’IA perçoivent leurs avantages réels ou imaginaires exclusivement à travers le prisme de leur capacité à brûler 8 à 13,5 dollars de tokens pour chaque dollar d’abonnement.
Cette tromperie délibérée poursuit un seul objectif : empêcher la grande majorité des utilisateurs de jamais prendre conscience des coûts réels de l’IA générative. Lorsque The Atlantic publie un article passionné sur Claude Code comme « le moment ChatGPT » d’Anthropic, cet article repose sur un abonnement mensuel de 20 dollars, et non sur la consommation réelle de tokens qui coûte à Anthropic de fournir ce service — ce qui conduit l’auteur à excuser les « petites erreurs » du modèle ou ses blocages lors de « tâches de programmation plus complexes ».
Si l’auteur devait payer directement pour sa consommation réelle de tokens — et si chaque blocage lui coûtait 15 dollars de tokens — je doute fort qu’elle soit aussi indulgente face à ces défaillances.
Mais tout cela fait partie intégrante de la supercherie.
Il est extrêmement, extrêmement important de noter que les journalistes couvrant l’IA dans les médias grand public ne comprennent pas réellement combien ces services coûtent — et que presque tous les articles grand public sur ChatGPT, Claude Code ou d’autres services sont rédigés par des personnes qui ignorent presque totalement combien une tâche donnée pourrait coûter à un utilisateur.
Rappelez-vous : les services d’IA générative sont essentiellement des produits expérimentaux, dont les fonctionnalités ne ressemblent à aucune autre application logicielle ou matérielle moderne. Les gens ne peuvent pas simplement s’asseoir devant ChatGPT ou Claude et attendre qu’ils se mettent au travail.
Techniquement, vous pouvez le faire — mais si votre prompt est mal formulé, si vous ne comprenez pas comment le système fonctionne, si vous commettez une erreur dans les données que vous lui fournissez, ou si le modèle se trompe simplement, il vous renverra un résultat que vous n’aimez pas — ce qui vous oblige à reformuler votre demande. Les LLM sont, par nature, imprévisibles.
Vous ne pouvez pas garantir qu’un LLM exécutera une action spécifique, ni qu’il vous fournira un résultat fondé sur la réalité. Vous ne pouvez pas déterminer avec certitude combien coûtera une tâche donnée — même si vous l’avez déjà accomplie maintes fois avec un LLM — ni prévoir quand le modèle risque de supprimer quelque chose de manière erronée, ou de ne rien faire tout en prétendant l’avoir fait.
Si les utilisateurs étaient contraints de payer les tarifs réels, je pense que beaucoup abandonneraient immédiatement le produit — car explorer aveuglément les capacités d’un LLM peut facilement vous coûter 5 dollars de tokens.
Remarque en passant : en effet, vous pouvez dépenser d’importantes sommes sans jamais obtenir le résultat souhaité, car les LLM ne sont pas véritablement de l’intelligence artificielle ! Une personne consciente de leurs limites peut facilement dépenser 30, 50, voire 100 dollars pour tenter de convaincre un LLM de faire ce qu’il affirme pouvoir faire. Il existe un terme pour désigner ce phénomène : la flagornerie. Les LLM sont généralement conçus pour approuver l’utilisateur, même lorsqu’il profère des absurdités dangereuses — ce qui s’étend à des affirmations telles que « Vous souhaitez réaliser cette entreprise techniquement ou économiquement impossible ? Bien sûr que oui ! » Voilà pourquoi l’industrie s’efforce tant de masquer ces coûts — c’est tout simplement du racket !
Je crois que la transition inévitable de la plupart des abonnements IA vers une facturation par token est désormais inéluctable — surtout qu’Anthropic et OpenAI appliquent déjà ce modèle à leurs clients professionnels.
Les entreprises ordinaires peuvent-elles supporter la transition vers une facturation par token ? Anthropic estime que les utilisateurs dépensent 13 à 30 dollars par jour sur Claude Code (soit plus de 7 000 dollars par an), tandis que les grandes organisations dépensent des centaines de milliers ou des millions de dollars annuellement
Comme je l’ai discuté la semaine dernière, le CTO d’Uber a déclaré lors d’une conférence que l’entreprise avait épuisé l’intégralité de son budget IA pour 2026 en quelques mois seulement. Goldman Sachs conseille certaines entreprises de consacrer jusqu’à 10 % de leurs salaires à l’achat de tokens IA — une proportion susceptible d’augmenter jusqu’à 100 % au cours des prochains trimestres.
C’est le résultat direct de la stratégie consistant à encourager chaque utilisateur IA à exploiter ces services au maximum tout en camouflant leurs coûts réels. Chaque grande entreprise qui demande à chacun de ses employés « d’utiliser l’IA autant que possible » agit fondamentalement sans tenir compte de la consommation réelle de tokens — et, à mesure que ces entreprises devront payer les coûts réels, je me demande sérieusement comment justifier économiquement un investissement quelconque dans cette technologie.
Bien sûr, vous allez dire que les ingénieurs « livrent du code plus rapidement », etc. Je comprends. Mais combien plus vite ? Combien d’argent cela vous rapporte-t-il ou vous fait-il économiser ? Si vous consacrez 10 % de vos coûts salariaux à l’achat de tokens IA, cette dépense supplémentaire est-elle compensée ailleurs ? Je ne pense pas. Je ne pense pas qu’aucune entreprise ayant englouti d’importants montants en tokens ait réellement observé un retour sur investissement — c’est pourquoi toutes les études sur le ROI de l’IA ne trouvent pratiquement aucune preuve tangible de son existence.
Dans la plupart des cas, ceux qui parlent avec enthousiasme des possibilités infinies de l’IA générative le font sans en supporter les coûts réels. Chaque fou sur Twitter qui raconte sans fin comment toute son équipe d’ingénieurs utilise frénétiquement Claude Code le fait avec un abonnement Teams à 125 dollars par utilisateur et par mois — un abonnement dont les limites d’usage sont comparables à celles de l’abonnement grand public d’Anthropic à 100 dollars par mois. Chaque monstre sur LinkedIn qui affirme avoir « accompli en quelques minutes ce qui prenait des heures » avec un produit Perplexity paie tout au plus 200 dollars par mois pour l’abonnement Max de Perplexity.
En réalité, cet abonnement Teams pour 10 personnes, à 1 250 dollars par mois, coûtera probablement entre 5 000 et 10 000 dollars (ou plus) par mois en frais d’appels API. Amol Avasare, responsable de la croissance chez Anthropic, a déclaré la semaine dernière que l’abonnement Max était conçu pour une utilisation intensive de chat — et non pour les usages intensifs de Claude Code et Cowork. Il a clairement indiqué qu’Anthropic envisageait désormais « différentes options pour continuer à offrir une excellente expérience utilisateur », autrement dit : « Nous ajusterons les prix à un moment donné. »
Je ne suis pas sûr que les gens réalisent à quel point les tokens peuvent être coûteux — surtout dans les projets de programmation impliquant de grands codebases et des appels fréquents à des outils de codage et d’infrastructure. Une personne dépensant 200 dollars par mois peut-elle réellement supporter 350, 400 ou 500 dollars ? Peut-elle supporter un mois où ses dépenses dépassent ce seuil ? Que se passe-t-il si elle dépasse son budget ? Ou pire, si elle ne peut tout simplement pas se permettre de payer ce qu’il faut pour accomplir son travail ?
Voici un exemple plus concret : jusqu’au début d’avril, la documentation officielle des développeurs de Claude Code d’Anthropic (archivée) indiquait encore : « [Les utilisateurs de Claude Code] ont un coût moyen de 6 dollars par développeur et par jour, 90 % des utilisateurs restant en dessous de 12 dollars par jour. » À la date de cette semaine, la documentation indique désormais :
Claude Code est facturé selon la consommation d’API tokens. Les tarifs des abonnements (Pro, Max, Team, Enterprise) sont disponibles sur claude.com/pricing. Le coût par développeur varie fortement selon le modèle choisi, la taille du codebase et le mode d’utilisation (exécution de plusieurs instances ou automatisation). Dans les déploiements professionnels, le coût moyen s’élève à environ 13 dollars par développeur et par jour actif, soit 150 à 250 dollars par mois, 90 % des utilisateurs restant en dessous de 30 dollars par jour actif. Pour estimer les dépenses de votre équipe, commencez par un petit groupe pilote, utilisez l’outil de suivi ci-dessous pour établir une ligne de base, puis étendez progressivement.
Si nous supposons un mois moyen de 21 jours ouvrables, le coût moyen par utilisateur de Claude Code est d’environ 273 dollars par mois, soit 3 276 dollars par an. À raison de 30 dollars par jour ouvrable, cela atteint 630 dollars par mois, soit 7 560 dollars par an.
Ces chiffres sont stupéfiants — et encore plus stupéfiant est le fait que, si vous utilisez l’un des modèles les plus récents d’Anthropic, vous ne pourrez pas vous contenter de 30 dollars par jour. Claude Opus 4.7 coûte 5 dollars par million de tokens d’entrée et 25 dollars par million de tokens de sortie. Un million de tokens équivaut à environ 50 000 lignes de code. En supposant que vous utilisiez le modèle le plus avancé disponible, vous consommerez très probablement au moins un million de tokens — et ce chiffre grimpera vertigineusement si vous ne savez pas quel modèle choisir pour une tâche donnée.
Jouons un peu avec ce chiffre de 30 dollars.
Pour une équipe de 10 développeurs, cela fait 75 600 dollars par an — uniquement sur les jours ouvrables.
Si vous passez à une moyenne de 50 dollars par jour ouvrable pendant trois mois, cela atteint 88 200 dollars.
Si vous ajoutez un mois à plus de 100 dollars par jour, cela fait 102 900 dollars par an.
Si vous dépensez 300 dollars par jour, 10 personnes vous coûteront 756 000 dollars par an.
Bien que cela puisse sembler faisable dans une startup bien financée ou dans l’esprit de réserve budgétaire d’une « république bananière » comme Meta, toute entreprise véritablement soucieuse de ses coûts aura du mal à justifier une dépense supplémentaire à cinq ou six chiffres pour un service censé « améliorer la productivité », alors que cette amélioration semble impossible à mesurer.
Maintenant, je pense que la plupart des entreprises se répartissent en trois catégories :
— Des déploiements professionnels au sein de grandes organisations comme Spotify ou Uber, dirigées par des PDG obsédés par l’IA et autorisant des budgets incontrôlés. Je dirais également que cela s’applique aux grandes startups bien financées.
— Des petites startups utilisant des abonnements « Teams » subventionnés.
— Des utilisateurs individuels payant un abonnement mensuel pour accéder à Claude ou à d’autres services IA.
Les grandes organisations continuent de pouvoir affirmer qu’elles brûlent des millions de dollars en tokens IA pour leurs ingénieurs logiciels, invoquant l’avantage douteux que « les meilleurs ingénieurs » n’écrivent plus aucun code.
Une seule mauvaise conférence téléphonique sur les résultats financiers pourrait suffire à renverser cette narration. À un moment donné, les investisseurs — même les imbéciles bornés qui ont gonflé la bulle IA — commenceront à remettre en question les coûts de recherche et développement en constante augmentation (où la consommation de tokens IA est généralement cachée), dès que la croissance des revenus ne suivra plus. Cela conduira probablement à davantage de licenciements pour maîtriser les coûts, comme chez Meta, puis à un retrait progressif une fois que quelqu’un posera la question : « Est-ce que ces outils nous aident vraiment à travailler plus vite et mieux ? »
Je pense également que, dans les six mois à venir, les startups qui dépensent 10 % ou plus de leurs coûts salariaux en tokens IA auront du mal à convaincre leurs investisseurs que cette dépense est nécessaire.
Une fois que tout le monde aura basculé vers la facturation par token, je ne suis pas sûr que nous verrons encore autant de battage médiatique autour de l’IA générative.
L’économie des centres de données IA et de la puissance de calcul est insensée
La façon dont les gens parlent des centres de données IA est totalement déconnectée de la réalité — et je pense que beaucoup ne réalisent pas à quel point toute cette ère est devenue absurde.
Les centres de données IA sont coûteux à construire et à exploiter, mais génèrent très peu de revenus
Selon Jerome Darling de TD Cowen, les coûts des équipements informatiques clés (GPU et matériel associé) s’élèvent à environ 30 millions de dollars, et le coût par mégawatt de capacité de centre de données à environ 14 millions de dollars. La construction d’un centre de données prend apparemment de un à trois ans — et encore, à condition que l’alimentation électrique soit disponible.
Sur les 114 GW de centres de données annoncés pour être achevés d’ici la fin 2028, seuls 15,2 GW sont actuellement en construction sous quelque forme que ce soit. Or, « en construction » peut signifier simplement « un trou creusé dans le sol ». Cela ne signifie pas — et ne devrait pas signifier — que la capacité promise sera bientôt disponible.
Commençons par le simple : chaque fois que vous entendez « 100 MW », pensez « 4,4 milliards de dollars », dont une grande partie est consacrée aux GPU NVIDIA.
Ainsi, chaque centre de données IA débute avec des pertes de plusieurs millions de dollars, et même avec un plan d’amortissement sur six ans, il faudra plusieurs années pour l’amortir… et avec le cycle annuel de mises à niveau de NVIDIA, une fois que vous aurez rempli votre premier contrat client, ces GPU ne généreront probablement plus autant de revenus.
Il n’est pas clair que la clientèle de la puissance de calcul IA existe en dehors d’OpenAI et d’Anthropic — dont la demande représente à elle seule 50 % des centres de données IA en construction. Si l’une ou l’autre de ces deux entreprises ne parvenait pas à payer, cela créerait une faiblesse systémique majeure.
Par ailleurs, il n’est pas clair quel tarif continu ces centres de données parviendront à facturer. Bien que le prix spot puisse tourner autour de 4,50 dollars/heure par GPU B200, les prix des contrats à long terme sont généralement bien inférieurs : un fondateur (selon The Information) affirme payer environ 3,70 dollars/heure/GPU pour un engagement d’un an.
Il faut bien distinguer le coût spot — le coût de démarrer aléatoirement un GPU sur les serveurs d’un tiers — du calcul contractuel, qui représente la majeure partie des dépenses en capital des centres de données. La plupart des centres de données sont construits en prévision d’un ou deux gros clients, ce qui signifie que ces clients peuvent négocier des tarifs mixtes plus avantageux.
Ainsi, de nombreux centres de données facturent bien moins de 3,70 dollars/heure, car ils appliquent des tarifs par mégawatt (ou kilowatt).
C’est là que l’économie commence à s’effondrer.
L’économie effondrée d’un centre de données de 100 MW — 2,55 dollars/heure, marge brute de 16 % à taux d’occupation de 100 %, mais sans profit en raison de l’endettement
Voici les coûts initiaux d’un centre de données de 100 mégawatts. Un centre de données de 100 MW peut ne disposer que de 85 MW de capacité facturable réelle, selon les discussions avec des sources familières avec la facturation des infrastructures hyperscales, qui estiment un revenu annuel d’environ 12,5 millions de dollars par mégawatt, soit environ 1,063 milliard de dollars par an.
Je dois préciser que la plupart des sociétés de centres de données que vous connaissez ne construisent pas elles-mêmes ces installations, mais délèguent ce travail à des entreprises comme Applied Digital, également appelées « partenaires gérés ». Par exemple, CoreWeave paie Applied Digital des frais de gestion pour utiliser son centre de données du Dakota du Nord. CoreWeave fournit tous les GPU et autres technologies installés dans le centre de données.
Pour illustrer cette déconnexion économique, j’utiliserai un exemple théorique : un centre de données loué à une entreprise théorique de puissance de calcul IA.
Les GPU de ce centre de données sont très probablement des puces Blackwell de NVIDIA. Il est encore plus probable que ce centre de données utilise des « pods » de 8 GPU B200, dont le prix de vente au détail est d’environ 450 000 dollars chacun, soit 56 250 dollars par GPU. Sur la base d’une charge IT critique de 85 MW, les dépenses totales en capital par mégawatt s’élèvent à environ 36,78 millions de dollars, soit environ 3,126 milliards de dollars au total pour les équipements IT, ou environ 2,67 milliards de dollars pour les GPU seuls.
Supposons que ce centre de données soit situé à Ellendale, dans le Dakota du Nord, ce qui implique un tarif industriel d’électricité d’environ 6,31 cents par kilowattheure, soit environ 55,4 millions de dollars par an en frais d’électricité. Selon mes entretiens avec des sources, j’estime que les coûts récurrents de maintenance, de personnel, de remplacement des alimentations électriques, etc., représentent environ 12 % des revenus, soit environ 128 millions de dollars par an, portant notre total à 183,4 millions de dollars.
Attendez — désolé. Vous devez aussi payer des frais de gestion pour l’équipement IT critique. Selon Brightlio, ces frais s’élèvent généralement à environ 180–200 dollars par kilowatt et par mois, selon l’échelle et l’emplacement du déploiement, bien que j’aie lu des mentions allant jusqu’à 130 dollars — c’est le chiffre que j’adopte ici, soit environ 133 millions de dollars par an. Cela porte notre total à 316,4 millions de dollars.
Bon, cela reste inférieur à 1,06 milliard de dollars, donc tout va bien, n’est-ce pas ?
Faux ! Vous avez 3,126 milliards de dollars d’équipements IT à amortir. Sur six ans, cela fait environ 521 millions de dollars par an. Soit un coût annuel total de 837,4 millions de dollars, vous laissant un bénéfice annuel d’environ 168,6 millions de dollars, soit une marge brute d’environ 16,7 %…
… à condition de maintenir un taux d’occupation de 100 % ! En effet, un centre de données peut nécessiter un ou deux mois pour installer ces GPU et accueillir les clients — durant lesquels vos revenus sont nuls, tandis que vos pertes sont considérables, car vous continuez à payer les frais de gestion, d’électricité et d’exploitation, même à des taux réduits (j’ai modélisé 10 % pour l’électricité et 15 % pour la gestion/exploitation), ce qui signifie que vous perdez environ 3,27 millions de dollars par jour.
Pour cet exemple, supposons que vous ayez besoin d’un mois supplémentaire pour faire fonctionner l’installation — ce qui signifie que vous avez déjà dépensé environ 102 millions de dollars, irrécupérables, portant votre coût annuel total (y compris l’amortissement) à 939,4 millions de dollars, soit une marge brute de 6,6 %.
Attendez, nom d’un chien — vous n’avez pas acheté ces GPU à crédit ? Si ? À quel point est-ce grave ? Oh mon Dieu — vous avez obtenu un prêt garanti par actif sur six ans, avec un ratio prêt/valeur de 80 %, ce qui signifie que vous avez emprunté 2,8 milliards de dollars à un taux d’intérêt de 6 %.
Votre banque, dans un geste d’éternelle générosité, vous a accordé un délai de grâce de 12 mois, pendant lequel vous ne remboursez que les intérêts… environ 168 millions de dollars, ce qui porte votre coût total pour la première année (sans inclure le mois de retard, pour plus d’équité) à environ 1,005 milliard de dollars… contre 1,06 milliard de dollars de revenus.
Cela donne une marge brute de 5,19 %, et vous n’avez même pas commencé à rembourser le principal. Lorsque cela arrivera, vous devrez rembourser 54,1 millions de dollars par mois, soit environ 649 millions de dollars par an pendant les cinq prochaines années, soit environ 1,48 milliard de dollars au total, ou une marge brute négative d’environ –40 %.
Je dois être clair : cela suppose un taux d’occupation de 100 %, et des locataires qui paient toujours à temps.
Stargate Abilene est une catastrophe — 2,94 dollars/heure/GPU, revenus annuels de 10 milliards de dollars, retards de plusieurs années, et un seul locataire perdant des milliards de dollars par an
Parlons maintenant du projet qui devrait être le plus économiquement viable de l’histoire des centres de données — un vaste campus de centres de données construit par Oracle pour la plus grande entreprise IA du monde. Oracle est une entreprise quasi-hyperscale vieille de plusieurs décennies, avec une longue expérience dans la vente de bases de données coûteuses et de logiciels de gestion d’entreprise aux entreprises et aux administrations publiques.
Ha, bien sûr, je plaisante — cet endroit est tout simplement un cauchemar.
Stargate Abilene, un campus de huit bâtiments totalisant 1,2 GW de capacité, avec environ 824 MW d’équipements IT critiques, a été annoncé pour la première fois en juillet 2024. Au 27 avril 2026, seuls deux bâtiments sont opérationnels et génèrent des revenus, et le troisième ne contient pratiquement aucun équipement IT. J’estime que le coût total de Stargate Abilene s’élève à environ 52,8 milliards de dollars.
Selon mes propres enquêtes, Oracle prévoit tirer environ 10 milliards de dollars de revenus annuels de Stargate Abilene, et j’estime que la totalité de ses 7,1 GW de capacité de centres de données construits pour un seul client — OpenAI — devrait générer environ 75 milliards de dollars de revenus totaux. Comme je l’ai également rapporté, Oracle estimait en 2024 que Abilene devrait payer chaque année au moins 2,14 milliards de dollars de frais de gestion et d’électricité au promoteur immobilier Crusoe.
Je dois également préciser qu’Oracle semble assumer l’intégralité des coûts de construction d’Abilene.
Selon mes calculs et mes rapports, j’estime que la marge brute brute d’Abilene, une fois pleinement opérationnel, serait d’environ 37,47 % :
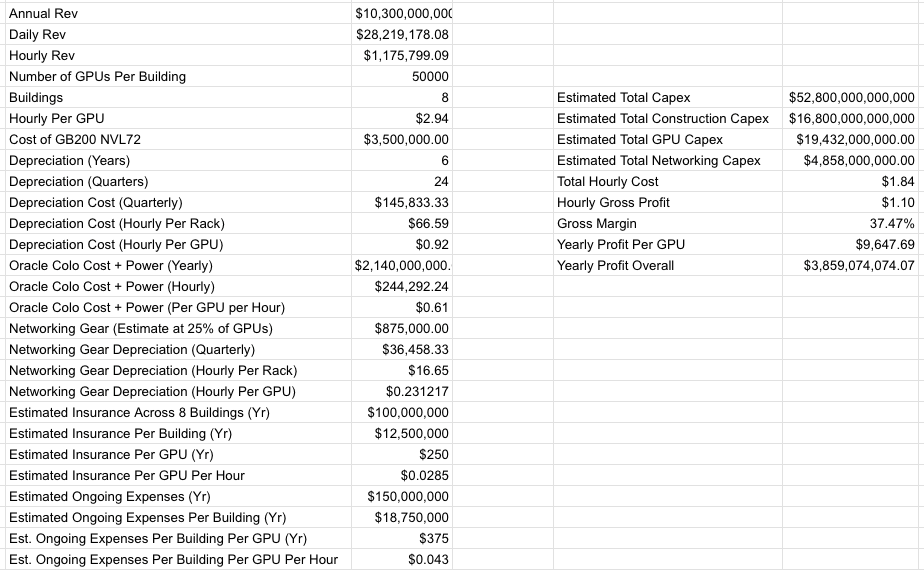
Je dois être clair : une marge brute de 37,47 % pourrait être trop élevée, car je ne connais pas les chiffres réels précis des coûts d’assurance ou de personnel d’Oracle — seulement des estimations basées sur des documents consultés par cette publication. Je dois également préciser qu’Oracle mise littéralement tout son avenir sur des projets comme Stargate Abilene, engageant des milliards de dollars à l’avance, une activité qui ne deviendra rentable que dans plusieurs années — même si OpenAI paie chaque facture à temps.
Malheureusement, je ne peux pas déterminer avec certitude quelle part d’Abilene a été financée par emprunt. Je sais seulement qu’Oracle a levé environ 18 milliards de dollars en septembre 2025, via l’émission d’obligations de tailles variées, à des échéances allant de 7 à 40 ans, et que son dernier rapport financier mentionne un flux de trésorerie négatif de 24,7 milliards de dollars.
Ce que je sais, c’est qu’Oracle a signé avec le promoteur Crusoe un bail de 15 ans, et que l’avenir d’Oracle dépend gravement de la capacité d’OpenAI à continuer à payer — ce qui, à son tour, dépend de la capacité d’Oracle à achever le projet Stargate Abilene.
Je dois également préciser que le bénéfice annuel de 3,85 milliards de dollars n’est réalisable que si OpenAI paie à temps, s’installe à Abilene aussi rapidement que possible, et que tout se déroule conformément au calendrier prévu.
Si OpenAI ne parvient pas à lever 852 milliards de dollars de revenus, de financement et d’emprunts d’ici quatre ans, le projet Stargate de centres de données ruinerait Oracle
Malheureusement, la situation exactement inverse s’est produite :
Selon DatacenterDynamics, les premiers 200 MW d’alimentation électrique auraient dû être mis en service « en 2025 ». Avec le temps, l’installation des clients aurait dû commencer au premier semestre 2025, « avec un potentiel d’atteindre 1 GW en 2025 », l’achèvement complet des 1,2 GW de capacité étant prévu pour le milieu de 2026, la mise sous tension pour le milieu de 2026, et le déploiement de 64 000 GPU d’ici la fin 2026. Au 30 septembre 2025, « deux bâtiments étaient en ligne ». Au 12 décembre 2025, Clay Magouyurk, co-PDG d’Oracle, déclara qu’Abilene « progressait selon le calendrier », et qu’« il avait livré plus de 96 000 GPU NVIDIA Grace Blackwell GB200 » — soit le nombre de GPU installés dans les deux bâtiments. Quatre mois plus tard, le 22 avril 2026, Oracle déclara sur X : « … à Abilene, 200 MW sont désormais opérationnels, et la livraison du campus de huit bâtiments suit toujours le calendrier prévu. » Il n’est pas clair si cela fait référence à 200 MW de capacité IT critique ou à la puissance électrique totale disponible dans le campus Abilene. Dans tous les cas, cela ne suffit que pour alimenter deux bâtiments, ce qui signifie qu’Oracle n’est absolument pas « en train de progresser selon le calendrier ».
C’est un problème majeur. OpenAI ne peut payer que pour la puissance de calcul réellement existante — et seule une capacité IT critique de 206 MW génère réellement des revenus, le troisième bâtiment nécessitant encore au moins un mois (voire un trimestre) avant d’entrer en service.
Cependant, le projet global de centres de données Stargate comporte un problème encore plus fondamental et plus grave — tout cela n’a de sens que si OpenAI réussit à concrétiser ses prévisions absurdes, dignes de bandes dessinées.
Comme je l’ai discuté vendredi :
Je répète ces chiffres : une fois achevés, les 7,1 GW de centres de données Stargate en construction généreront environ 75 milliards de dollars de revenus annuels, pour un coût total dépassant les 340 milliards de dollars. Le flux de trésorerie libre d’Oracle est négatif de 24,7 milliards de dollars, ses autres activités stagne, ce qui fait de son activité cloud — actuellement déficitaire ou à faible rentabilité — le seul moteur de croissance. Pour pouvoir honorer ses contrats de puissance de calcul — y compris ceux conclus avec Amazon, Microsoft, CoreWeave, Google, Cerberas et Oracle lui-même — OpenAI doit lever ou générer 852 milliards de dollars de revenus et/ou de financement d’ici quatre ans. Cela exige une croissance annuelle de plus de 250 %, une multiplication par 10 de son activité d’ici la fin 2030, et la mise en place d’un modèle générant un flux de trésorerie positif d’ici là — sans quoi ces chiffres n’ont aucun sens. Pour être clair, les prévisions d’OpenAI prévoient de générer 673 milliards de dollars de revenus d’ici la fin 2030, tout en dépensant 218 milliards de dollars. Il s’agit d’une activité extrêmement déficitaire, et même si elle devenait profitable, elle devrait générer bien plus de revenus qu’actuellement pour continuer à payer Oracle.
J’ai calculé ce chiffre de 75 milliards de dollars en supposant que les GPU Vera Rubin génèrent environ 14 millions de dollars par mégawatt de puissance de calcul sur les 4,64 GW restants de capacité IT critique — un chiffre que j’ai confirmé auprès de sources familières avec le secteur des centres de données, et qui devrait constituer la capacité restante des centres de données Stargate.
Les chiffres d’OpenAI proviennent directement des informations divulguées par The Information sur les prévisions de dépenses et de revenus d’OpenAI, qui prévoit de générer 673 milliards de dollars de revenus d’ici la fin 2030, et d’en dépenser 852 milliards :
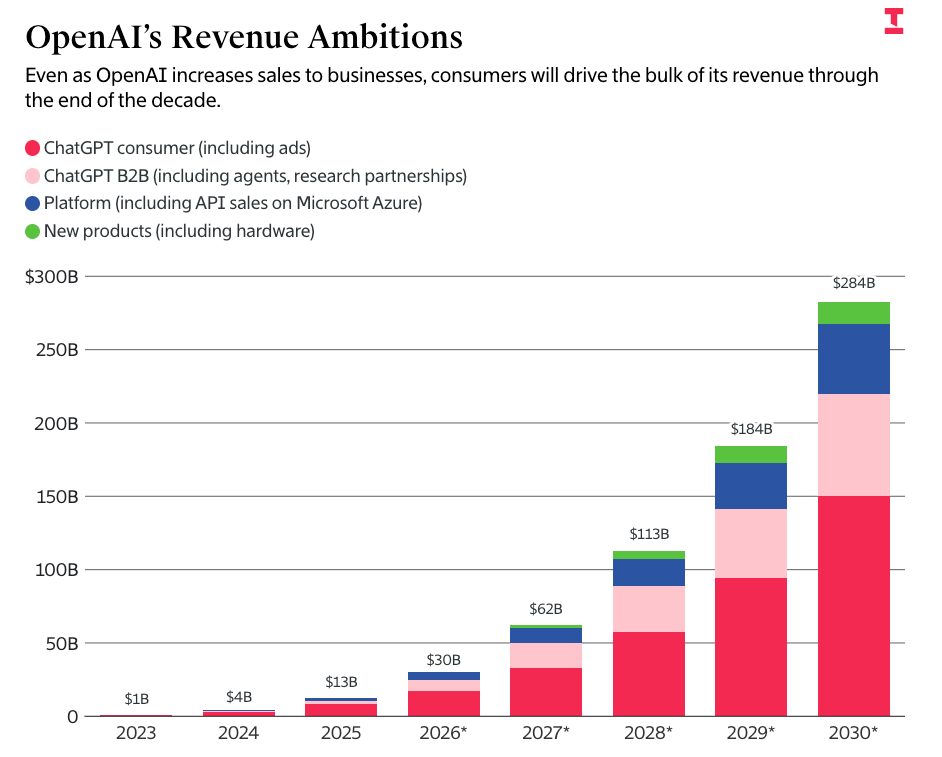
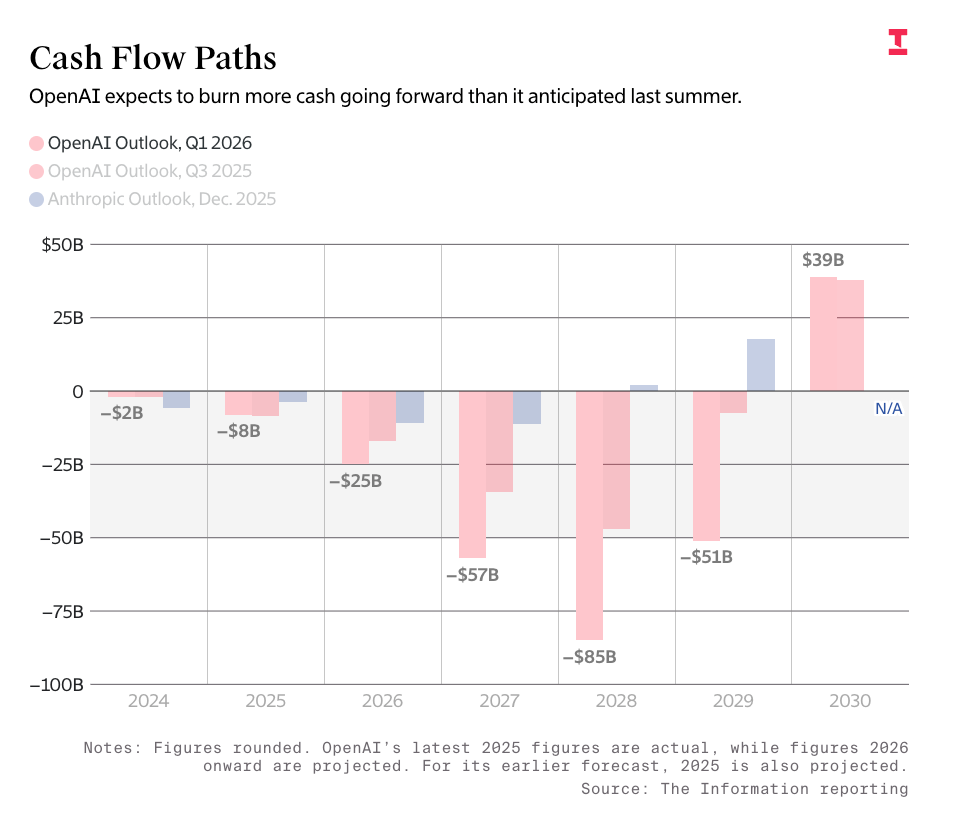
Je dois être clair : tout journaliste répétant ces chiffres sans souligner à quel point ils sont stupides devrait ressentir une certaine honte. Selon mon contenu payant de vendredi :
Autrement dit, OpenAI prévoit que ses revenus dépasseront ceux de TSMC dans deux ans, que ses revenus annuels seront presque équivalents à ceux de Meta dans trois ans, et que ses revenus annuels d’ici la fin 2030 égaleront ceux de Microsoft (environ 300 milliards de dollars au cours des 12 derniers mois).
Si OpenAI ne peut pas payer ces frais de puissance de calcul, Oracle fera faillite, car il a déjà contracté environ 115 milliards de dollars de dette rien que pour la construction des centres de données Stargate, et doit encore en emprunter 150 milliards supplémentaires pour les achever :
Oracle est une entreprise dont le chiffre d’affaires annuel est d’environ 64 milliards de dollars, avec un flux de trésorerie libre négatif de 24,7 milliards de dollars au dernier trimestre. Elle a émis 18 milliards de dollars d’obligations en septembre 2025, 25 milliards de dollars en février 2026, et procédé à une augmentation de capital de 20 milliards de dollars sur le marché en mars — bien que cette opération, qualifiée de « terminée » depuis plusieurs mois, n’ait apparemment été finalisée que récemment, pour un montant total de 38 milliards de dollars destinés aux projets Stargate du Wisconsin et de Shackelford. J’inclus également dans ce calcul la dette de 14 milliards de dollars liée au centre de données Stargate du Michigan. Quoi qu’il en soit, Oracle ne dispose pas des capitaux nécessaires pour achever Stargate Abilene. Il lui en faut encore au moins 150 milliards de dollars pour mener à bien ce projet — et ce, en supposant que d’autres partenaires assument environ 30 milliards de dollars de coûts. Honnêtement, cela pourrait même être plus élevé.
Je dois vraiment être clair : Oracle n’a aucun autre moyen de générer ces revenus sans OpenAI, et ces projets sont entièrement financés et payés à partir des flux de trésorerie prévus des centres de données eux-mêmes.
Je ne suis pas le seul à m’inquiéter de cela. Sarah Friar, d’OpenAI, a exprimé des inquiétudes similaires après que l’entreprise n’ait pas atteint ses objectifs en matière d’utilisateurs et de revenus, selon le Wall Street Journal :
OpenAI n’a récemment pas atteint ses objectifs en matière de nouveaux utilisateurs et de revenus. Ces échecs ont conduit certains dirigeants de l’entreprise à s’interroger sur sa capacité à soutenir ses dépenses massives en centres de données. La directrice financière Sarah Friar a informé les autres dirigeants qu’elle craignait qu’OpenAI ne puisse pas honorer ses futurs contrats de calcul si la croissance des revenus n’était pas suffisamment rapide, selon des sources bien informées. Au cours des derniers mois, les membres du conseil d’administration ont également examiné plus attentivement les transactions de l’entreprise relatives aux centres de données, et ont remis en question la stratégie du PDG Sam Altman visant à acquérir davantage de puissance de calcul, même dans un contexte de ralentissement de l’activité, selon des sources bien informées.
Si cela ne vous inquiète pas, peut-être cela le fera-t-il :
Elle a souligné auprès des cadres dirigeants et des membres du conseil d’administration la nécessité pour OpenAI d’améliorer ses contrôles internes, en avertissant que l’entreprise n’était pas encore prête à répondre aux normes rigoureuses de reporting requises pour les sociétés cotées. Certains interlocuteurs ont indiqué qu’Altman penchait plutôt pour un calendrier d’introduction en bourse plus ambitieux.
Cela ressemble vraiment à une entreprise capable de générer 852 milliards de dollars d’ici la fin de la décennie !
Anthropic est tout aussi défaillant qu’OpenAI, promettant jusqu’à 10 GW (plus de 100 milliards de dollars de revenus annuels) de pu
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News












