Discours intégral de Jensen Huang à la conférence GTC : « L’ère de l’inférence est arrivée ; le chiffre d’affaires atteindra au moins un millier de milliards de dollars en 2027 ; la langouste est le nouvel système d’exploitation. »
TechFlow SélectionTechFlow Sélection
Discours intégral de Jensen Huang à la conférence GTC : « L’ère de l’inférence est arrivée ; le chiffre d’affaires atteindra au moins un millier de milliards de dollars en 2027 ; la langouste est le nouvel système d’exploitation. »
Nvidia développe un ordinateur de centre de données spatial baptisé « Vera Rubin Space-1 », ouvrant ainsi totalement la voie à l’extension de la puissance de calcul de l’IA au-delà de la Terre.
Source : Wall Street Insights
Le 16 mars 2026, la conférence GTC 2026 de NVIDIA a officiellement ouvert ses portes, et Jensen Huang, fondateur et PDG de NVIDIA, y a prononcé un discours liminaire.
Lors de ce rassemblement considéré comme le « pèlerinage annuel de l’industrie IA », Huang a décrit la transformation de NVIDIA, passant d’une « entreprise de puces » à une « entreprise d’infrastructures et d’usines IA ». Face aux questions les plus pressantes du marché concernant la pérennité des résultats et les perspectives de croissance, Huang a détaillé la logique commerciale fondamentale qui sous-tend cette croissance future : l’« économie de l’usine de tokens ».

Prévisions de résultats extrêmement optimistes : « Une demande d’au moins 1 000 milliards de dollars d’ici 2027 »
Au cours des deux dernières années, la demande mondiale en calcul IA a explosé de façon exponentielle. À mesure que les grands modèles évoluent de la « perception » et de la « génération » vers le « raisonnement » et l’« action (exécution de tâches) », la consommation de puissance de calcul augmente fortement. Concernant le plafond des commandes et des revenus — sujet hautement scruté par le marché — Huang a formulé des attentes particulièrement robustes.
Huang a déclaré explicitement lors de son discours :
« Il y a un an, j’avais indiqué que nous observions une demande hautement fiable de 500 milliards de dollars, couvrant les architectures Blackwell et Rubin jusqu’en 2026. Aujourd’hui, en cet instant précis, je constate une demande d’au moins 1 000 milliards de dollars (at least $1 trillion) d’ici 2027. »

L’annonce de cette estimation de mille milliards de dollars a fait bondir le cours de l’action NVIDIA de plus de 4,3 %.
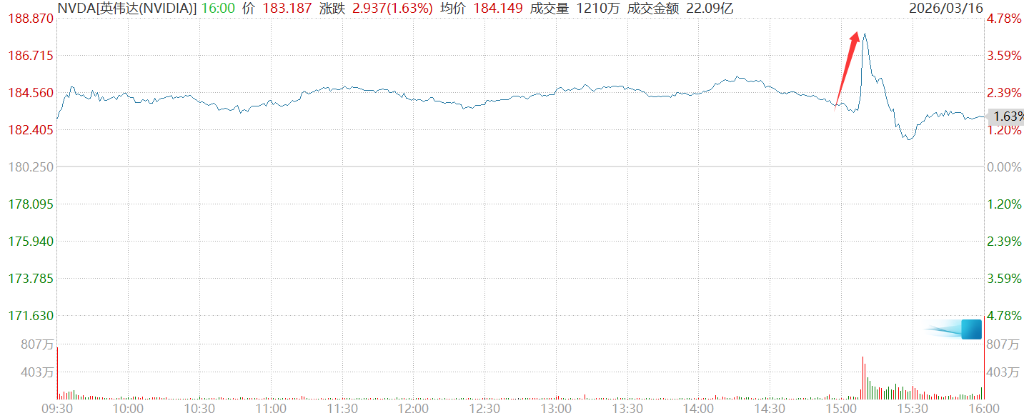
Mais il n’en est pas resté là et a complété ce chiffre ainsi :
« Cela semble-t-il raisonnable ? C’est précisément ce que je vais vous expliquer maintenant. En réalité, nous serons même confrontés à une pénurie d’offre. Je suis convaincu que la demande réelle en calcul dépassera largement ce montant. »
Huang a souligné que les systèmes NVIDIA actuels se sont déjà imposés comme « l’infrastructure la moins coûteuse au monde ». Grâce à leur capacité à exécuter pratiquement tous les modèles IA dans tous les domaines, leur universalité permet aux clients d’exploiter pleinement leurs investissements de 1 000 milliards de dollars sur une longue période.
Actuellement, 60 % des activités de NVIDIA proviennent des cinq principaux fournisseurs mondiaux de services cloud hyperscalaires, tandis que les 40 % restants sont répartis largement entre les clouds souverains, les entreprises, les secteurs industriel, robotique et de calcul périphérique (edge computing).
L’économie de l’usine de tokens : la performance par watt détermine la survie commerciale
Pour justifier la rationalité de cette demande de 1 000 milliards de dollars, Huang a présenté aux PDG mondiaux une nouvelle approche commerciale. Il a précisé que les centres de données futurs ne seront plus de simples entrepôts de fichiers, mais bien des « usines » produisant des tokens (l’unité fondamentale générée par l’IA).

Huang a insisté :
« Chaque centre de données, chaque usine, est par définition limité par sa consommation électrique. Une usine de 1 GW (gigawatt) ne deviendra jamais une usine de 2 GW : c’est une loi physique et atomique. À puissance fixe, celui qui obtient le débit de tokens par watt le plus élevé possède le coût de production le plus bas. »
Huang a classé les futurs services IA en quatre niveaux commerciaux :
- Niveau gratuit (débit élevé, vitesse faible)
- Niveau intermédiaire (~3 dollars par million de tokens)
- Niveau avancé (~6 dollars par million de tokens)
- Niveau haute vitesse (~45 dollars par million de tokens)
- Niveau ultra-haute vitesse (~150 dollars par million de tokens)
Il a ajouté que, à mesure que les modèles grandissent et que leurs contextes s’allongent, les IA deviendront plus intelligentes, mais le taux de génération de tokens diminuera. Huang a déclaré :
« Dans cette usine de tokens, votre débit et votre vitesse de génération de tokens se transformeront directement en revenus précis pour l’année prochaine. »
Huang a souligné que l’architecture NVIDIA permet à ses clients d’atteindre un débit extrêmement élevé au niveau gratuit, tout en augmentant les performances de manière spectaculaire — jusqu’à 35 fois — dans le niveau d’inférence à plus forte valeur ajoutée.

Vera Rubin : un accélérateur 350 fois plus rapide en deux ans ; Groq comble le besoin d’inférence ultra-rapide
Dans le cadre de ces contraintes physiques, NVIDIA a présenté son système de calcul IA le plus complexe jamais conçu : Vera Rubin. Huang a commenté :
« Par le passé, lorsque je parlais de Hopper, je brandissais une puce — c’était charmant. Mais quand on évoque Vera Rubin, on pense à l’ensemble du système. Dans ce système entièrement refroidi à liquide, qui supprime totalement les câbles traditionnels, l’installation d’un rack, qui prenait deux jours auparavant, ne prend désormais que deux heures. »
Huang a précisé qu’avec une conception matérielle et logicielle intégrée extrême, Vera Rubin a permis, au sein d’un seul centre de données de 1 GW, une progression remarquable :
« En seulement deux ans, nous avons fait passer le taux de génération de tokens de 22 millions à 700 millions, soit une augmentation de 350 fois. La loi de Moore n’aurait permis, sur la même période, qu’une amélioration d’environ 1,5 fois. »
Pour résoudre le goulot d’étranglement de bande passante rencontré dans les scénarios d’inférence ultra-rapide (par exemple, 1 000 tokens/seconde), NVIDIA a dévoilé sa solution finale intégrant Groq, société qu’elle a rachetée : une inférence séparée asymétrique. Huang a expliqué :
« Les caractéristiques de ces deux processeurs sont radicalement différentes. La puce Groq intègre 500 Mo de SRAM, tandis qu’une puce Rubin dispose de 288 Go de mémoire. »

Huang a indiqué que NVIDIA, via son système logiciel Dynamo, affecte la phase de « pré-remplissage (Pre-fill) », nécessitant d’importantes ressources de calcul et de mémoire vidéo, à Vera Rubin, tandis que la phase de « décodage », extrêmement sensible à la latence, est traitée par Groq. Il a également donné aux entreprises des recommandations sur la configuration de leur puissance de calcul :
« Si votre travail consiste principalement en un débit élevé, utilisez exclusivement Vera Rubin. Si vous avez de nombreux besoins élevés en génération de tokens de haute valeur (par exemple, au niveau de la programmation), allouez 25 % de la capacité de votre centre de données à Groq. »
Selon les informations divulguées, la puce Groq LP30, fabriquée par Samsung, est désormais en production de masse et devrait être livrée au troisième trimestre. Le premier rack Vera Rubin est déjà opérationnel sur le cloud Microsoft Azure.
En outre, concernant la technologie d’interconnexion optique, Huang a présenté le premier commutateur optique embarqué (CPO) commercialisé au monde, Spectrum X, et mis fin au débat sur la substitution du cuivre par la fibre optique :
« Nous avons besoin de davantage de capacités de production de câbles en cuivre, de puces photoniques et de modules CPO. »
Les agents mettent fin aux SaaS traditionnels ; « salaire annuel + tokens » devient la norme dans la Silicon Valley
Outre les barrières matérielles, Huang a consacré une large part de son intervention à la révolution logicielle et écosystémique de l’IA, notamment à l’explosion des agents (agents intelligents).
Il a qualifié le projet open source OpenClaw de « projet open source le plus populaire de l’histoire humaine », affirmant qu’il avait dépassé, en quelques semaines seulement, les réalisations accumulées par Linux au cours de ses trente dernières années. Huang a clairement déclaré qu’OpenClaw constitue, en substance, le « système d’exploitation » de l’ordinateur agent.
Huang a affirmé :
« Chaque entreprise de SaaS (Software-as-a-Service) deviendra une entreprise de AaaS (Agent-as-a-Service). Sans aucun doute, afin de garantir le déploiement sécurisé de ces agents capables d’accéder à des données sensibles et d’exécuter du code, NVIDIA a lancé la référence NeMo Claw destinée aux entreprises, intégrant un moteur de politiques et un routeur de confidentialité. »
Pour les professionnels ordinaires, cette révolution est tout aussi proche. Huang a esquissé la nouvelle forme du lieu de travail :
« À l’avenir, chaque ingénieur de notre entreprise disposera d’un budget annuel en tokens. Leur salaire de base pourrait s’élever à plusieurs centaines de milliers de dollars ; j’y ajouterai environ la moitié de ce montant sous forme de quota de tokens, afin de multiplier leur efficacience par 10. Ce nouveau critère est déjà devenu un argument décisif dans les recrutements de la Silicon Valley : combien de tokens contient votre offre ? »
En conclusion de son discours, Huang a « dévoilé » l’architecture de calcul suivante, Feynman, qui marquera la première mise en œuvre d’une extension horizontale commune entre les connexions en cuivre et les CPO. Encore plus fascinant, NVIDIA développe actuellement un ordinateur pour centre de données spatial baptisé « Vera Rubin Space-1 », ouvrant pleinement la voie à l’extension de la puissance de calcul IA au-delà de la Terre.
Discours intégral de Jensen Huang à la conférence GTC 2026, traduction complète ci-dessous (assistée par des outils IA) :
Animateur : Bienvenue sur scène, Jensen Huang, fondateur et directeur général de NVIDIA.
Jensen Huang, fondateur et directeur général :
Bienvenue à la conférence GTC. Je tiens à rappeler à tous que celle-ci est une conférence technologique. Je suis très heureux de voir tant de personnes faire la queue dès le matin pour entrer, et de vous avoir tous parmi nous aujourd’hui.
À la GTC, nous concentrons nos efforts sur trois thèmes principaux : la technologie, les plateformes et l’écosystème. NVIDIA propose actuellement trois plateformes : la plateforme CUDA-X, la plateforme système, et notre toute dernière plateforme, l’usine IA.
Avant de commencer officiellement, je souhaite remercier nos présentateurs d’ouverture — Sarah Guo de Conviction, Alfred Lin de Sequoia Capital (le premier investisseur en capital-risque de NVIDIA), ainsi que Gavin Baker, le premier investisseur institutionnel majeur de NVIDIA. Ces trois personnalités possèdent une compréhension profonde de la technologie et exercent une influence considérable sur l’ensemble de l’écosystème technologique. Bien entendu, je remercie également tous les invités prestigieux que j’ai personnellement conviés à participer à cet événement. Merci à cette équipe exceptionnelle.
Je remercie également toutes les entreprises présentes aujourd’hui. NVIDIA est une entreprise de plateforme, dotée de technologies, de plateformes et d’un écosystème riche. Les entreprises représentées ici couvrent presque l’intégralité des acteurs d’un secteur estimé à 100 000 milliards de dollars. Quatre-cent-cinquante entreprises ont parrainé cet événement — merci sincèrement à chacune d’elles.
Cette conférence comprend 1 000 forums techniques et accueillera 2 000 intervenants, couvrant chaque niveau de l’architecture « gâteau à cinq couches » de l’IA — depuis les infrastructures fondamentales (terres, alimentation électrique, salles informatiques), jusqu’aux puces, aux plateformes, aux modèles, et enfin aux applications qui propulsent l’ensemble de l’industrie.
CUDA : vingt ans de progrès technologiques
Tout commence ici. Cette année marque le vingtième anniversaire de CUDA.
Pendant vingt ans, nous nous sommes consacrés sans relâche au développement de cette architecture. CUDA représente une invention révolutionnaire — la technologie SIMT (Single Instruction, Multiple Threads) permet aux développeurs d’écrire des programmes en code scalaire, puis de les étendre facilement à des applications multithreads, avec une complexité de programmation bien inférieure à celle des architectures SIMD antérieures. Nous venons récemment d’introduire la fonction Tiles, facilitant la programmation des cœurs tensoriels (Tensor Core) et des diverses structures mathématiques essentielles à l’IA moderne. CUDA compte aujourd’hui des milliers d’outils, de compilateurs, de frameworks et de bibliothèques ; des centaines de milliers de projets publics existent sur les communautés open source, et CUDA est profondément intégré dans tous les écosystèmes technologiques.
Ce graphique illustre la logique stratégique totale de NVIDIA — je présente régulièrement cette diapositive depuis mes débuts. L’élément le plus difficile à réaliser — et le plus central — est la « base installée », située au bas du graphique. Après vingt ans, nous avons accumulé, à l’échelle mondiale, des centaines de millions de GPU et de systèmes de calcul exécutant CUDA.
Nos GPU sont compatibles avec toutes les plateformes cloud et desservent presque tous les fabricants d’ordinateurs et tous les secteurs industriels. Cette base installée colossale constitue précisément le moteur principal de ce cercle vertueux. Elle attire les développeurs, qui créent de nouveaux algorithmes et réalisent des percées, ouvrant ainsi de nouveaux marchés. Ces marchés naissants forment de nouveaux écosystèmes qui attirent davantage d’entreprises, renforçant encore la base installée — ce cercle vertueux s’accélère continuellement.
Le nombre de téléchargements des bibliothèques NVIDIA augmente à un rythme impressionnant, à la fois massif et en croissance constante. Ce cercle vertueux permet à notre plateforme de calcul de soutenir une multitude d’applications et de nouvelles percées incessantes.
Plus important encore, il confère à ces infrastructures une durée de vie exceptionnellement longue. La raison en est évidente : les applications exécutables sur CUDA sont extrêmement nombreuses, couvrant chaque étape du cycle de vie de l’IA, toutes les plateformes de traitement de données, ainsi que divers solveurs scientifiques. Dès lors qu’un GPU NVIDIA est installé, sa valeur d’utilisation réelle est extrêmement élevée. C’est pourquoi les GPU de l’architecture Ampere, lancés il y a six ans, voient leur prix augmenter sur le cloud.
La raison fondamentale de ce phénomène réside dans la taille colossale de la base installée, la puissance du cercle vertueux et l’étendue de l’écosystème de développeurs. Lorsque ces facteurs agissent conjointement, et que nous continuons à mettre à jour nos logiciels, le coût du calcul diminue continuellement. Le calcul accéléré améliore considérablement les performances des applications, et grâce à notre maintenance et à nos itérations logicielles continues, les utilisateurs bénéficient non seulement d’un bond initial de performance, mais aussi d’une baisse continue du coût de calcul. Nous nous engageons à soutenir chaque GPU dans le monde, car ils sont entièrement compatibles sur le plan architectural.
Nous pouvons nous permettre cela parce que la base installée est si vaste — chaque nouvelle optimisation bénéficie à des millions d’utilisateurs. Cette combinaison dynamique permet à l’architecture NVIDIA d’élargir continuellement sa portée, d’accélérer sa croissance propre, tout en réduisant constamment le coût du calcul, stimulant ainsi de nouvelles croissances. CUDA est au cœur de tout cela.
De GeForce à CUDA : un parcours de vingt-cinq ans
Notre voyage avec CUDA remonte en réalité à vingt-cinq ans.
GeForce — beaucoup d’entre vous ont grandi avec GeForce. GeForce est le projet marketing le plus réussi de NVIDIA. Nous avons commencé à former nos futurs clients alors qu’ils ne pouvaient pas encore acheter nos produits — ce sont vos parents qui sont devenus les premiers utilisateurs de NVIDIA, achetant année après année nos produits, jusqu’au jour où vous êtes devenus d’excellents informaticiens, nos véritables clients et développeurs.
C’est sur cette base posée il y a vingt-cinq ans par GeForce que tout repose. Il y a vingt-cinq ans, nous avons inventé les shaders programmables — une invention évidente mais profondément significative qui a rendu les accélérateurs programmables, et qui constitue le tout premier accélérateur programmable au monde, à savoir le shader de pixels. Cinq ans plus tard, nous avons créé CUDA — l’un de nos investissements les plus importants à ce jour. À l’époque, nos ressources financières étaient limitées, mais nous avons engagé la quasi-totalité de nos bénéfices dans ce projet, visant à étendre CUDA de GeForce à chaque ordinateur. Nous avons été si déterminés parce que nous croyions profondément en son potentiel. Malgré les difficultés initiales, l’entreprise a maintenu cette conviction pendant treize générations, soit vingt ans entiers — aujourd’hui, CUDA est omniprésent.
Ce sont les shaders de pixels qui ont déclenché la révolution GeForce. Et il y a environ huit ans, nous avons lancé RTX — une refonte complète de l’architecture pour l’ère moderne de l’informatique graphique. GeForce a diffusé CUDA dans le monde entier, permettant ainsi à des chercheurs tels qu’Alex Krizhevsky, Ilya Sutskever, Geoffrey Hinton et Andrew Ng de découvrir que le GPU pouvait servir d’accélérateur puissant pour l’apprentissage profond, déclenchant ainsi l’explosion de l’IA il y a dix ans.
Il y a dix ans, nous avons décidé d’intégrer le shader programmable à deux nouvelles idées : premièrement, le traçage de rayons matériel (Ray Tracing), technologie extrêmement exigeante ; deuxièmement, une idée visionnaire à l’époque — il y a environ dix ans, nous avions prédit que l’IA transformerait radicalement l’informatique graphique. Tout comme GeForce a apporté l’IA au monde entier, l’IA va désormais redéfinir entièrement la manière dont l’informatique graphique est implémentée.
Aujourd’hui, je vous présente l’avenir. Il s’agit de notre prochaine technologie graphique, que nous appelons le rendu neuronal (Neural Rendering) — une fusion profonde entre les graphismes 3D et l’IA. Voici DLSS 5, regardez.
Rendu neuronal : la fusion entre données structurées et IA générative
N’est-ce pas époustouflant ? L’informatique graphique retrouve ainsi une nouvelle jeunesse.
Que faisons-nous ? Nous combinons les graphismes 3D contrôlables (la base réelle du monde virtuel) avec leurs données structurées, puis intégrons l’IA générative et le calcul probabiliste. L’un est entièrement déterministe, l’autre probabiliste mais extrêmement réaliste — nous fusionnons ces deux concepts, permettant une maîtrise précise grâce aux données structurées, tout en générant en temps réel. Le résultat final est à la fois magnifique et entièrement contrôlable.
Cette idée de fusion entre données structurées et IA générative se reproduira dans un secteur après l’autre. Les données structurées constituent la pierre angulaire de l’IA fiable.
Une plateforme d’accélération pour données structurées et non structurées
Passons maintenant à un schéma d’architecture technique.
Données structurées — SQL, Spark, Pandas, Velox, ainsi que des plateformes majeures telles que Snowflake, Databricks, Amazon EMR, Azure Fabric et Google BigQuery, manipulent toutes des « Data Frames » (cadres de données). Ces cadres de données ressemblent à des tableaux électroniques géants, porteurs de l’intégralité des informations du monde des affaires, et constituent la « vérité fondamentale » (Ground Truth) du calcul d’entreprise.
À l’ère de l’IA, nous devons permettre à l’IA d’utiliser les données structurées et d’en accélérer le traitement de façon extrême. Par le passé, l’accélération du traitement des données structurées visait simplement à rendre les entreprises plus efficaces. À l’avenir, l’IA utilisera ces structures de données à une vitesse bien supérieure à celle de l’humain, et les agents intelligents feront massivement appel aux bases de données structurées.
Concernant les données non structurées, les bases de données vectorielles, les fichiers PDF, les vidéos et les fichiers audio constituent la grande majorité des données dans le monde — environ 90 % des données générées chaque année sont non structurées. Par le passé, ces données étaient presque entièrement inexploitées : nous les lisions, les stockions dans des systèmes de fichiers, et c’était tout. Nous ne pouvions ni les interroger ni les rechercher facilement, car les données non structurées manquent d’index simples et exigent de comprendre leur signification et leur contexte. Or, l’IA peut désormais accomplir cela — grâce aux technologies multimodales de perception et de compréhension, l’IA est capable de lire des documents PDF, d’en saisir le sens et de les intégrer dans une structure plus large, consultable.
Pour répondre à ce besoin, NVIDIA a créé deux bibliothèques fondamentales :
- cuDF : pour l’accélération du traitement des cadres de données et des données structurées
- cuVS : pour le stockage vectoriel, les données sémantiques et les données IA non structurées
Ces deux plateformes deviendront parmi les plus importantes plateformes fondamentales de l’avenir.
Aujourd’hui, nous annonçons des partenariats avec plusieurs entreprises. IBM — inventeur du langage SQL — utilisera cuDF pour accélérer sa plateforme WatsonX Data. Dell et NVIDIA ont conjointement développé la plateforme AI Data de Dell, intégrant cuDF et cuVS, avec des gains de performance notables dans des projets réels menés avec NTT Data. Chez Google Cloud, nous accélérons non seulement Vertex AI, mais aussi BigQuery, et collaborons avec Snapchat pour réduire ses coûts de calcul de près de 80 %.
Les avantages du calcul accéléré sont triples : vitesse, échelle et coût. Cette logique suit directement celle de la loi de Moore — obtenir des bonds de performance grâce au calcul accéléré, tout en optimisant continuellement les algorithmes, afin que tout le monde bénéficie d’une baisse continue du coût de calcul.
NVIDIA construit une plateforme de calcul accéléré, sur laquelle reposent de nombreuses bibliothèques : RTX, cuDF, cuVS, etc. Ces bibliothèques sont intégrées dans les services cloud mondiaux et les systèmes OEM, atteignant ainsi les utilisateurs du monde entier.
Partenariats approfondis avec les fournisseurs de services cloud
Partenariats avec les principaux fournisseurs de services cloud
Google Cloud : nous accélérons Vertex AI et BigQuery, et sommes profondément intégrés à JAX/XLA, tout en offrant des performances exceptionnelles sur PyTorch — NVIDIA est le seul fournisseur d’accélérateurs au monde à performer aussi bien sur PyTorch et JAX/XLA. Nous avons intégré des clients tels que Base10, CrowdStrike, Puma et Salesforce dans l’écosystème Google Cloud.
AWS : nous accélérons EMR, SageMaker et Bedrock, et bénéficions d’une intégration approfondie avec AWS. Ce qui me passionne particulièrement cette année, c’est l’intégration d’OpenAI sur AWS, ce qui stimulera fortement la consommation de services cloud d’AWS et aidera OpenAI à étendre ses déploiements régionaux et sa puissance de calcul.
Microsoft Azure : notre supercalculateur de 100 PFLOPS est le premier supercalculateur construit par NVIDIA, et le premier déployé sur Azure — une base essentielle pour notre collaboration avec OpenAI. Nous accélérons les services cloud Azure et AI Foundry, contribuons à l’expansion des régions Azure, et collaborons étroitement sur la recherche Bing. À noter, notre capacité de « calcul confidentiel (Confidential Computing) » — garantissant que même l’opérateur ne puisse pas consulter les données et les modèles des utilisateurs — fait de nos GPU NVIDIA les premiers GPU au monde à supporter le calcul confidentiel, permettant ainsi le déploiement confidentiel des modèles OpenAI et Anthropic dans les environnements cloud mondiaux. À titre d’exemple, nous accélérons l’intégralité des flux de travail EDA et CAD de Synopsys, déployés sur Microsoft Azure.
Oracle : nous sommes le premier client IA d’Oracle, et je suis fier d’avoir été le premier à lui expliquer le concept de cloud IA. Depuis, Oracle a connu une croissance fulgurante, et nous lui avons introduit de nombreux partenaires tels que Cohere, Fireworks et OpenAI.
CoreWeave : le premier cloud natif IA au monde, spécifiquement conçu pour l’hébergement de GPU et les services cloud IA, avec une clientèle remarquable et une croissance vigoureuse.
Palantir + Dell : les trois parties ont conjointement développé une nouvelle plateforme IA, fondée sur la plateforme ontologique (Ontology Platform) et la plateforme IA de Palantir, pouvant déployer localement, dans n’importe quel pays ou dans des environnements isolés (air-gapped), l’ensemble de la pile d’accélération IA — du traitement des données (vectorisation ou structuration) à l’accélération complète de l’IA.
NVIDIA entretient ce type de partenariat spécifique avec les fournisseurs mondiaux de services cloud — nous aidons nos clients à migrer vers le cloud, un écosystème gagnant-gagnant.
Intégration verticale, ouverture horizontale : la stratégie fondamentale de NVIDIA
NVIDIA est la première entreprise au monde à allier intégration verticale et ouverture horizontale.
La nécessité de ce modèle est simple : le calcul accéléré n’est pas un problème de puces ni un problème de systèmes ; sa formulation complète est « accélération des applications ». Le CPU peut accélérer l’ensemble du fonctionnement d’un ordinateur, mais cette voie a atteint ses limites. À l’avenir, seules l’accélération spécifique aux applications ou aux domaines permettront de générer continuellement des bonds de performance et des baisses de coûts.
C’est précisément pourquoi NVIDIA doit approfondir un domaine après l’autre, une bibliothèque après l’autre, un secteur vertical après l’autre. Nous sommes une entreprise de calcul intégrée verticalement, et n’avons pas d’autre choix. Nous devons comprendre les applications, les domaines, les algorithmes en profondeur, et être capables de les déployer dans n’importe quel scénario — centre de données, cloud, local, edge ou systèmes robotiques.
Parallèlement, NVIDIA reste ouverte horizontalement, prête à intégrer sa technologie dans toute plateforme partenaire, afin que le monde entier puisse bénéficier des avantages du calcul accéléré.
La composition des participants à la GTC illustre parfaitement ce point. Parmi les participants, le secteur des services financiers est le mieux représenté — espérons que ce soient des développeurs, et non des traders, qui soient venus. Notre écosystème couvre toute la chaîne d’approvisionnement, en amont comme en aval. Que des entreprises aient 50, 70 ou 150 ans, elles ont toutes connu leur meilleure année historique l’an dernier. Nous sommes au début de quelque chose de très, très important.
CUDA-X : le moteur d’accélération pour chaque secteur industriel
NVIDIA est profondément implantée dans tous les secteurs verticaux :
- Conduite autonome : couverture étendue, impact profond
- Services financiers : l’investissement quantitatif passe progressivement de l’ingénierie manuelle des caractéristiques à l’apprentissage profond piloté par supercalculateurs, entrant dans son « moment Transformer »
- Santé : vit son propre « moment ChatGPT », couvrant la découverte de médicaments assistée par IA, les agents intelligents pour le diagnostic médical, les services clients médicaux, etc.
- Industrie : la vague de construction la plus importante au monde est en cours, avec la mise en place d’usines IA, d’usines de puces et de centres de données
- Divertissement et jeux vidéo : une plateforme IA en temps réel prend en charge la traduction, la diffusion en direct, les interactions de jeu et les agents intelligents pour le commerce électronique
- Robotique : engagement de plus de dix ans, avec trois architectures informatiques complètes (ordinateur d’entraînement, ordinateur de simulation, ordinateur embarqué), et 110 robots exposés lors de ce salon
- Télécommunications : un secteur de près de 2 000 milliards de dollars, dont les stations de base évoluent d’un simple nœud de communication vers une plateforme d’infrastructures IA, nommée Aerial, en collaboration approfondie avec Nokia, T-Mobile, etc.
Le cœur de tous ces domaines est précisément notre bibliothèque CUDA-X — la raison d’être de NVIDIA en tant qu’entreprise algorithmique. Ces bibliothèques constituent l’actif le plus fondamental de l’entreprise, permettant à la plateforme de calcul de délivrer une valeur concrète dans chaque secteur.
L’une des bibliothèques les plus importantes est cuDNN (CUDA Deep Neural Network library), qui a révolutionné l’intelligence artificielle et déclenché l’explosion de l’IA moderne.
(Projection de la vidéo de démonstration CUDA-X)
Tout ce que vous venez de voir est une simulation — y compris les solveurs basés sur les lois physiques, les modèles IA d’agents physiques, et les modèles de robots IA physiques. Rien n’est animé manuellement ni articulé à la main. C’est précisément là que réside la compétence fondamentale de NVIDIA : grâce à une compréhension approfondie des algorithmes et à une intégration parfaite avec la plateforme de calcul, nous débloquons ces opportunités.
Entreprises natives IA et nouvelle ère du calcul
Vous venez de voir des géants définissant la société actuelle — Walmart, L’Oréal, JPMorgan Chase, Roche, Toyota — ainsi qu’une foule d’entreprises que vous n’avez probablement jamais entendues nommer — que nous appelons des entreprises natives IA. Cette liste est extrêmement longue : elle inclut OpenAI, Anthropic, ainsi que de nombreuses entreprises émergentes spécialisées dans différents secteurs verticaux.
Au cours des deux dernières années, ce secteur a connu une croissance stupéfiante. Les investissements de capital-risque dans les startups ont atteint 150 milliards de dollars, un record historique. Plus important encore, le montant moyen par investissement est passé pour la première fois de plusieurs millions à plusieurs centaines de millions, voire des milliards de dollars. La raison est unique : c’est la première fois dans l’histoire que chaque entreprise de ce type a besoin de vastes ressources de calcul et de nombreux tokens. Ce secteur crée, génère des tokens, ou valorise les tokens provenant d’institutions telles qu’Anthropic et OpenAI.
Tout comme la révolution PC, la révolution Internet et la révolution mobile/cloud ont chacune vu naître des entreprises révolutionnaires, cette nouvelle ère du calcul donnera naissance à des entreprises influentes, qui deviendront des forces majeures du monde futur.
Trois percées historiques à l’origine de tout cela
Que s’est-il passé au cours des deux dernières années ? Trois événements majeurs.
Premier événement : ChatGPT, ouvrant l’ère de l’IA générative (fin 2022 – 2023)
Il ne se contente pas de percevoir et de comprendre, mais génère également du contenu unique. J’ai montré la fusion entre l’IA générative et l’informatique graphique. L’IA générative transforme fondamentalement le calcul — ce dernier passe d’un mode de recherche à un mode de génération, ce qui influe profondément sur l’architecture informatique, les modes de déploiement et la signification globale du calcul.
Deuxième événement : l’IA de raisonnement (Reasoning AI), incarnée par o1
Le raisonnement permet à l’IA de se réfléchir, de planifier, de décomposer des problèmes — en fragmentant ceux qu’elle ne peut pas comprendre directement en étapes traitables. o1 rend l’IA générative fiable, capable de raisonner à partir d’informations réelles. Pour cela, le volume de tokens d’entrée (contexte) et de tokens de sortie (pour la réflexion) augmente fortement, entraînant une hausse significative de la charge de calcul.
Troisième événement : Claude Code, le premier modèle agent
Il peut lire des fichiers, écrire du code, compiler, tester, évaluer et itérer. Claude Code révolutionne totalement l’ingénierie logicielle — 100 % des ingénieurs de NVIDIA utilisent l’un ou plusieurs des outils Claude Code, Codex ou Cursor ; aucun ingénieur logiciel ne travaille aujourd’hui sans assistance IA.
Voici un nouveau point de basculement — vous ne demandez plus à l’IA « quoi, où, comment », mais lui demandez plutôt de « créer, exécuter, construire », de prendre activement des outils, de lire des fichiers, de décomposer des problèmes et d’agir. L’IA passe de la perception, à la génération, au raisonnement, pour finalement accomplir réellement des tâches.
Au cours des deux dernières années, la puissance de calcul nécessaire au raisonnement a augmenté d’environ 10 000 fois, et son utilisation a augmenté d’environ 100 fois. Je pense personnellement que la demande de calcul a augmenté d’un million de fois au cours des deux dernières années — c’est le sentiment partagé par tous, par OpenAI, par Anthropic. Avec davantage de puissance de calcul, on génère davantage de tokens, les revenus augmentent, et l’IA devient plus intelligente. Le point de basculement du raisonnement est bel et bien arrivé.
L’ère des infrastructures IA d’un millier de milliards de dollars
Il y a un an, j’affirmais ici que nous avions une confiance élevée dans les commandes et la demande pour Blackwell et Rubin jusqu’en 2026, pour un montant d’environ 500 milliards de dollars. Aujourd’hui, un an après la GTC, je vous annonce que, pour 2027, le chiffre que je vois est d’au moins 1 000 milliards de dollars. Et je suis certain que la demande réelle en calcul dépassera largement ce montant.
2025 : l’année de l’inférence pour NVIDIA
2025 est l’année de l’inférence pour NVIDIA. Nous voulons nous assurer que, au-delà de l’entraînement et du post-entraînement, nous restons excellents à chaque étape du cycle de vie de l’IA, afin que les infrastructures déjà investies puissent fonctionner de manière continue et efficace, et que plus leur durée de vie utile est longue, plus leur coût unitaire est bas.
Parallèlement, Anthropic et Meta rejoignent officiellement la plateforme NVIDIA, représentant ensemble un tiers de la demande mondiale en calcul IA. Les modèles open source approchent désormais les performances de pointe, et sont omniprésents.
NVIDIA est actuellement la seule plateforme au monde capable d’exécuter tous les modèles IA — langage, biologie, graphismes informatiques, vision par ordinateur, voix, protéines et chimie, robotique, etc. — qu’ils soient déployés en périphérie ou dans le cloud, dans n’importe quelle langue. L’architecture NVIDIA est universelle pour tous ces scénarios, ce qui fait de nous la plateforme la moins coûteuse et la plus fiable.
Actuellement, 60 % des activités de NVIDIA proviennent des cinq principaux fournisseurs mondiaux de services cloud hyperscalaires, tandis que les 40 % restants sont répartis entre les clouds régionaux, les clouds souverains, les entreprises, les secteurs industriel, robotique et de calcul périphérique. L’étendue de la couverture de l’IA est précisément sa résilience — il s’agit sans aucun doute d’une nouvelle révolution de la plateforme de calcul.
Grace Blackwell et NVLink 72 : une révolution architecturale audacieuse
Alors que l’architecture Hopper était encore à son apogée, nous avons décidé de reconcevoir entièrement le système, étendant NVLink de 8 voies à NVLink 72, et procédant à une déconstruction complète du système de calcul. Grace Blackwell NVLink 72 constitue un pari technologique majeur, difficile pour tous nos partenaires — je tiens à exprimer ici mes sincères remerciements à chacun d’eux.
Parallèlement, nous avons lancé NVFP4 — non pas un simple FP4 classique, mais un tout nouveau type de cœur tensoriel et d’unité de calcul. Nous avons démontré que NVFP4 permet une inférence sans aucune perte de précision, tout en offrant des gains de performance et d’efficacité énergétique considérables, et qu’il est également adapté à l’entraînement. En outre, de nouveaux algorithmes tels que Dynamo et TensorRT-LLM ont vu le jour, et nous avons même consacré plusieurs milliards de dollars à la construction d’un supercalculateur dédié à l’optimisation des noyaux, baptisé DGX Cloud.
Les résultats prouvent que nos performances en inférence sont remarquables. Selon les données de Semi Analysis — la plus complète évaluation des performances en inférence IA à ce jour — NVIDIA domine largement sur les deux dimensions : nombre de tokens par watt et coût par token. Alors que la loi de Moore aurait pu apporter un gain de performance de 1,5 fois au H200, nous avons atteint un gain de 35 fois. Dylan Patel, de Semi Analysis, a même déclaré : « Jensen Huang a été trop prudent — c’est en réalité un gain de 50 fois. » Il a raison.
Je cite ici ses propos : « Jensen sandbagged. »
Le coût par token de NVIDIA est le plus bas au monde, inégalé à ce jour. La raison en est la conception collaborative extrême (Extreme Co-design).
Prenons l’exemple de Fireworks : avant la mise à jour complète des logiciels et algorithmes de NVIDIA, sa vitesse moyenne de tokens était d’environ 700 tokens/seconde ; après la mise à jour, elle approche les 5 000 tokens/seconde, soit une amélioration d’environ 7 fois. Voilà la puissance de la conception collaborative extrême.
L’usine IA : du centre de données à l’usine de tokens
Le centre de données n’est plus un lieu de stockage de fichiers, mais une usine produisant des tokens. Chaque fournisseur de services cloud, chaque entreprise IA, évaluera à l’avenir son efficacité selon le critère de « l’efficacité de l’usine de tokens ».
Voici mon argument central :
- Axe vertical : débit (Throughput) — nombre de tokens générés par seconde à puissance fixe
- Axe horizontal : vitesse de token (Token Speed) — vitesse de réponse par inférence ; plus elle est élevée, plus le modèle utilisé peut être volumineux, plus le contexte peut être long, et plus l’IA est intelligente
Le token est une nouvelle matière première ; une fois mature, il sera segmenté selon des niveaux de prix :
- Niveau gratuit (débit élevé, vitesse faible)
- Niveau intermédiaire (~3 dollars par million de tokens)
- Niveau avancé (~6 dollars par million de tokens)
- Niveau haute vitesse (~45 dollars par million de tokens)
- Niveau ultra-haute vitesse (~150 dollars par million de tokens)
Par rapport à Hopper, Grace Blackwell améliore le débit de 35 fois dans le niveau à plus forte valeur ajoutée, et introduit un nouveau niveau. En simplifiant le modèle, si 25 % de la puissance sont alloués à chacun des quatre niveaux, Grace Blackwell génère 5 fois plus de revenus que Hopper.
Vera Rubin : le système de calcul IA de nouvelle génération
(Projection de la vidéo de présentation du système Vera Rubin)
Vera Rubin est un système complet, entièrement optimisé de bout en bout, conçu spécifiquement pour les charges de travail agent (Agentic) :
- Cœur de calcul pour les grands modèles linguistiques : cluster de GPU NVLink 72, traitant le pré-remplissage (Prefill) et le cache KV
- Nouveau CPU Vera : conçu spécifiquement pour des performances monothread exceptionnelles, équipé de mémoire LPDDR5, offrant une excellente efficacité énergétique, et étant le seul CPU pour centre de données au monde utilisant LPDDR5, adapté aux appels d’outils par les agents IA
- Système de stockage : BlueField 4 + CX 9, une nouvelle plateforme de stockage conçue pour l’ère IA, adoptée à 100 % par l’ensemble de l’industrie mondiale du stockage
- Commutateur CPO Spectrum X : le premier commutateur Ethernet optique embarqué (CPO) au monde, désormais en production de masse
- Rack Kyber : un nouveau système de racks supportant jusqu’à 144 GPU formant un seul domaine NVLink, avec calcul frontal et commutation NVLink arrière, constituant un ordinateur géant
- Rubin Ultra : le prochain nœud de supercalculateur, conçu avec une insertion verticale, compatible avec le rack Kyber, permettant une interconnexion NVLink à plus grande échelle
Vera Rubin est entièrement refroidi à liquide, réduisant le temps d’installation de deux jours à deux heures, avec un refroidissement à eau chaude à 45 °C, allégeant fortement la charge de refroidissement des centres de données. Satya (Nadella) a déjà confirmé publiquement que le premier rack Vera Rubin est opérationnel sur Microsoft Azure — je suis profondément enthousiaste à ce sujet.
Intégration de Groq : l’extension ultime des performances d’inférence
Nous avons acquis l’équipe Groq et obtenu une licence sur sa technologie. Groq est un processeur de flux de données déterministe (Deterministic Dataflow Processor), utilisant une compilation statique et une planification par le compilateur, doté d’une grande quantité de SRAM, spécifiquement optimisé pour une seule charge de travail d’inférence, offrant une latence extrêmement faible et une vitesse de génération de tokens très élevée.
Cependant, la capacité mémoire de Groq est limitée (500 Mo de SRAM embarquée), ce qui rend difficile son autonomie pour héberger les paramètres et le cache KV des grands modèles, limitant ainsi son application à grande échelle.
La solution est précisément Dynamo — un logiciel d’ordonnancement d’inférence. Via Dynamo, nous décomposons la chaîne d’inférence (Disaggregate) :
- **Le pré-remplissage (Prefill) et le décodage de l’attention (Decode)** sont effectués sur Vera Rubin (nécessitant une puissance de calcul importante et un stockage du cache KV)
- **Le décodage du réseau de rétropropagation (Feed-Forward Network Decode)**, c’est-à-dire la génération de tokens, est effectué sur Groq (nécessitant une bande passante très élevée et une latence extrêmement faible)
Les deux composants sont étroitement couplés via Ethernet, et un mode spécial permet de réduire la latence d’environ moitié. Sous la gestion unifiée de Dynamo — le « système d’exploitation de l’usine IA » — les performances globales sont améliorées de 35 fois, ouvrant un nouveau niveau de performances d’inférence inaccessible auparavant avec NVLink 72.
Recommandations pour la combinaison Groq et Vera Rubin :
- Si la charge de travail est principalement axée sur un débit élevé, utilisez 100 % Vera Rubin
- Si une grande partie de la charge de travail concerne la génération de tokens de haute valeur (par exemple, la génération de code), intégrez Groq, avec une proportion recommandée d’environ 25 % Groq + 75 % Vera Rubin
La puce Groq LP30, fabriquée par Samsung, est désormais en production de masse et devrait être livrée au troisième trimestre. Merci à Samsung pour son soutien total.
Un bond historique des performances d’inférence
Quantifions les progrès technologiques précédents : en deux ans, le taux de génération de tokens d’une usine IA de 1 gigawatt passera de 22 millions à 700 millions de tokens/seconde, soit une augmentation de 350 fois. Voilà la puissance de la conception collaborative extrême.
Feuille de route technologique
- Blackwell : actuellement en production, système standard de racks Oberon, extension cuivre jusqu’à NVLink 72, option d’extension optique jusqu’à NVLink 576
- Vera Rubin (actuel) : rack Kyber, NVLink 144 (cuivre) ; rack Oberon, NVLink 72 + optique, extension jusqu’à NVLink 576 ; Spectrum 6, le premier commutateur CPO au monde
- Vera Rubin Ultra (prochainement) : nouvelle génération de GPU Rubin Ultra, puce LP35 (première intégration de NVFP4), améliorant encore les performances de plusieurs fois
- Feynman (génération suivante) : nouveau GPU, puce LP40 (co-développée par NVIDIA et l’équipe Groq, intégrant NVFP4) ; nouveau CPU — Rosa (Rosalyn) ; BlueField 5 ; CX 10 ; rack Kyber prenant en charge à la fois les extensions cuivre et CPO
La feuille de route est claire : les trois voies — extension cuivre, extension optique (Scale-Up), extension optique (Scale-Out) — progressent simultanément. Nous avons besoin que tous nos partenaires augmentent continuellement leurs capacités de production de câbles en cuivre, de fibres optiques et de modules CPO.
NVIDIA DSX : la plateforme de jumeau numérique pour l’usine IA
Les usines IA deviennent de plus en plus complexes, mais leurs fournisseurs technologiques, qui les composent, n’ont jamais collaboré durant la phase de conception — ils ne « se rencontrent » que dans le centre de données — ce qui est clairement insuffisant.
Pour y remédier, nous avons créé Omniverse, ainsi que la plateforme NVIDIA DSX, bâtie dessus — une plateforme où tous les partenaires peuvent concevoir et exploiter virtuellement des usines IA de plusieurs gigawatts. DSX fournit :
- Un système de simulation mécanique, thermique, électrique et réseau au niveau des racks
- Une connexion au réseau électrique, permettant une planification énergétique coopérative
- Une optimisation dynamique de la puissance et du refroidissement dans le centre de données, basée sur Max-Q
Une estimation prudente indique que ce système peut améliorer l’efficacité énergétique d’environ deux fois — un gain très substantiel à l’échelle dont nous parlons. Omniverse commence par la Terre numérique, et hébergera des jumeaux numériques de toutes tailles ; nous construisons avec nos partenaires mondiaux l’ordinateur le plus grand de l’histoire humaine.
En outre, NVIDIA s’engage dans l’espace. La puce Thor a déjà obtenu sa certification contre les radiations et est déjà opérationnelle dans des satellites. Nous développons conjointement avec des partenaires Vera Rubin Space-1, destiné à la construction de centres de données spatiaux. Dans l’espace, le refroidissement ne peut se faire que par rayonnement ; la gestion thermique est donc le défi central, et nous mobilisons nos meilleurs ingénieurs pour y répondre.
OpenClaw : le système d’exploitation de l’ère des agents
Peter Steinberger a développé un logiciel nommé OpenClaw. Il s’agit du projet open source le plus populaire de l’histoire humaine, ayant dépassé, en quelques semaines seulement, les réalisations accumulées par Linux au cours de ses trente dernières années.
OpenClaw est fondamentalement un système agent (Agentic System), capable de :
- Gérer les ressources, accéder aux outils, aux systèmes de fichiers et aux grands modèles linguistiques
- Exécuter des planifications et des tâches programmées
- Décomposer progressivement les problèmes et appeler des sous-agents
- Prendre en charge des entrées/sorties de n’importe quel mode (voix, vidéo, texte, courrier électronique, etc.)
En utilisant la syntaxe des systèmes d’exploitation, il est effectivement un système d’exploitation — le système d’exploitation de l’ordinateur agent. Windows a rendu possible l’ordinateur personnel ; OpenClaw rend possible l’agent personnel.
Chaque entreprise devra élaborer sa propre stratégie OpenClaw, tout comme nous avons besoin d’une stratégie Linux, d’une stratégie HTML, d’une stratégie Kubernetes.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News