

Bittensor est l’espoir de toute la communauté crypto.
TechFlow SélectionTechFlow Sélection
Bittensor est l’espoir de toute la communauté crypto.
Dans le débat général « La crypto a-t-elle encore un sens ? », Bittensor fournit actuellement la réponse la plus convaincante de toute l’industrie.
Auteur : 0xai
Un remerciement spécial à @DistStateAndMe et à son équipe pour leurs contributions au domaine des modèles d’IA open source, ainsi que pour leurs précieux conseils et leur soutien apportés à ce rapport.
Pourquoi vous devriez lire ce rapport
Si l’entraînement décentralisé de modèles d’IA est passé du « impossible » au « possible », à quel point Bittensor est-il sous-évalué ?
Au début de l’année 2026, une certaine lassitude régnait dans l’ensemble de la communauté crypto.
La vague haussière précédente s’était depuis longtemps dissipée, et les talents migraient rapidement vers le secteur de l’IA. Ceux qui, autrefois, parlaient du « prochain 100x », discutent désormais de Claude CodeOpenclaw. « La crypto, c’est perdre son temps » — vous avez probablement entendu cette phrase plus d’une fois.
Mais le 10 mars 2026, un sous-réseau Bittensor nommé Templar a discrètement annoncé une nouvelle.
Plus de 70 participants indépendants, venus du monde entier, sans serveur central ni coordination par une grande entreprise, ont, uniquement grâce à des mécanismes d’incitation cryptographiques, collaboré pour entraîner un modèle d’IA géant comportant 72 milliards de paramètres.
Le modèle et l’article scientifique correspondant ont été publiés sur HuggingFace et arXiv, et les données sont publiques et vérifiables.
Encore plus crucial : dans plusieurs tests clés, ce modèle a surpassé des modèles de niveau équivalent entraînés à grands frais par Meta.
Après l’annonce, le prix du jeton TAO est resté quasiment inchangé pendant près de deux jours. Ce n’est qu’au troisième jour que le cours a commencé à grimper fortement, sans toutefois s’arrêter six jours plus tard, avec une hausse totale d’environ +40 %. Pourquoi ce délai de deux jours ?
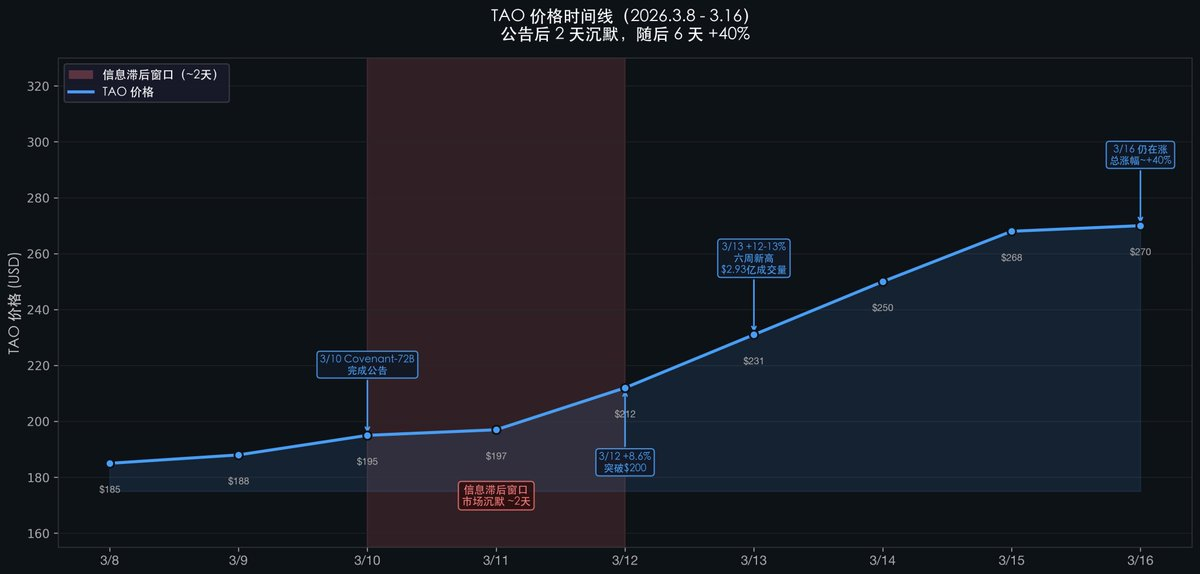
L’argument central de ce rapport est le suivant : les investisseurs crypto perçoivent cela comme « un autre modèle open source », jugé inférieur aux modèles quotidiennement utilisés tels que GPT ou Claude ; quant aux chercheurs en IA, ils ne prêtent pas attention à la crypto. Ce fossé entre les deux communautés crée actuellement une fenêtre d’arbitrage cognitif.
Cadre de lecture
Ce rapport se divise en deux parties logiques :
Partie I — Avancée technique : expliquer précisément ce qu’a accompli SN3 Templar, et pourquoi cet exploit revêt une importance historique majeure tant pour le domaine de l’IA que pour celui de la crypto.
Partie II — Impact sectoriel : expliquer pourquoi cet événement signifie que l’écosystème Bittensor est systématiquement sous-évalué, et pourquoi Bittensor représente l’espoir de toute la communauté crypto.
Partie I : La percée de l’entraînement décentralisé de modèles d’IA
1. À quoi sert SN3 ?
Quels éléments sont nécessaires pour entraîner un grand modèle de langage ?
Réponse traditionnelle : construire un centre de données géant, acheter des dizaines de milliers de GPU haut de gamme, dépenser des centaines de millions de dollars, et faire appel à une équipe d’ingénieurs appartenant à une seule entreprise. C’est exactement ce qu’ont fait Meta, Google et OpenAI.
L’approche de SN3 Templar : permettre à des personnes dispersées aux quatre coins du globe de mettre chacune à disposition un ou plusieurs serveurs équipés de GPU, puis d’assembler collectivement ces ressources de calcul comme des pièces d’un puzzle afin d’entraîner conjointement un grand modèle complet.
Mais un problème fondamental se pose ici : comment garantir la validité des résultats d’entraînement si les participants sont dispersés mondialement, ne se font pas confiance mutuellement, et subissent des latences réseau instables ? Comment empêcher les tricheurs ou les participants négligents ? Et surtout, comment inciter durablement chacun à contribuer activement ?
Bittensor fournit la réponse : utiliser le jeton TAO comme mécanisme d’incitation. Plus la contribution d’un participant (exprimée sous forme de « gradients », soit sa contribution effective à l’amélioration du modèle) est efficace, plus il reçoit de jetons TAO. Le système attribue automatiquement les scores et procède aux paiements sans aucune intervention d’une autorité centrale.
C’est précisément ce qu’est le sous-réseau n°3 (SN3) de Bittensor, codé Templar.
Si Bitcoin a prouvé la faisabilité d’une monnaie décentralisée, SN3 démontre aujourd’hui que l’entraînement décentralisé de modèles d’IA est également possible.
2. Quels résultats SN3 a-t-il obtenus ?
Le 10 mars 2026, SN3 Templar a annoncé avoir achevé l’entraînement du modèle de langage Covenant-72B.
Que signifie « 72B » ? : 72 milliards de paramètres. Les paramètres constituent les « unités de stockage des connaissances » d’un modèle d’IA ; plus leur nombre est élevé, plus le modèle est généralement performant. GPT-3 comporte 175 milliards de paramètres, tandis que LLaMA-2 (le modèle phare open source de Meta) en compte 70 milliards. Covenant-72B appartient donc à la même catégorie que LLaMA-2.
Quelle est l’échelle de l’entraînement ? : environ 1,1 billion de tokens (mots), soit l’équivalent de 5,5 millions de livres (en supposant une moyenne de 200 000 mots par livre).
Qui a participé à l’entraînement ? : plus de 70 participants indépendants (« mineurs ») ont successivement mis à disposition de la puissance de calcul (avec une limite de synchronisation de ~20 nœuds par cycle). L’entraînement a débuté le 12 septembre 2025 et s’est étalé sur environ six mois, sans serveur central ni coordination par une institution unique.
Quelles performances le modèle affiche-t-il ? : pour mieux les appréhender, comparons-les aux résultats obtenus par les modèles d’IA sur des épreuves standard :
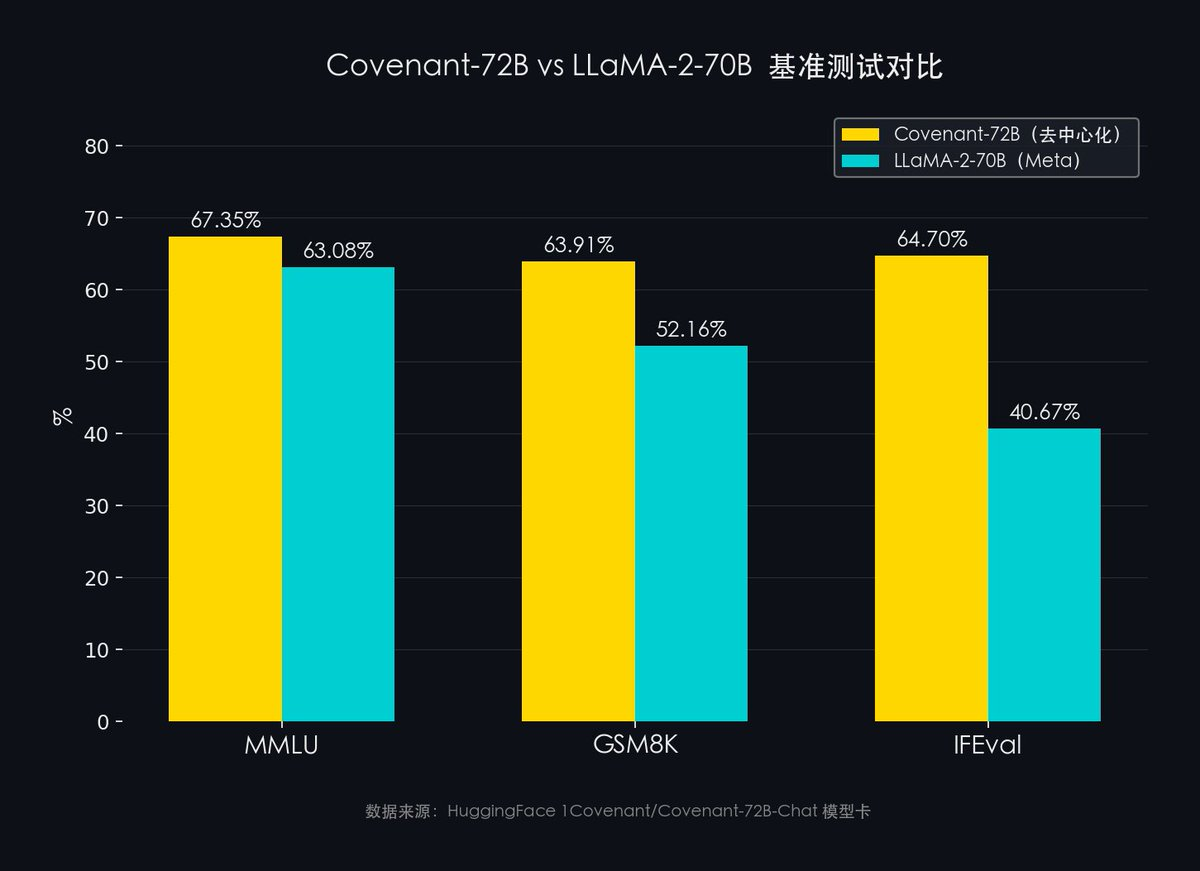
Source des données : fiche du modèle HuggingFace 1Covenant/Covenant-72B-Chat
- MMLU (connaissances intégrées sur 57 disciplines) : Covenant-72B (67,35 %) contre LLaMA-2 de Meta (63,08 %)
- GSM8K (raisonnement mathématique) : Covenant-72B (63,91 %) contre LLaMA-2 de Meta (52,16 %)
- IFEval (capacité à suivre des instructions) : Covenant-72B (64,70 %) contre LLaMA-2 de Meta (40,67 %)
Entièrement open source : licence Apache 2.0. Téléchargement, utilisation et exploitation commerciale gratuits et sans restriction.
Appui académique : article soumis à [arXiv 2603.08163] ; les technologies clés (l’optimiseur SparseLoCo et le mécanisme anti-triche Gauntlet) ont été présentées lors du NeurIPS Optimization Workshop.
3. Quelle est la portée de ce résultat ?
Pour la communauté open source de l’IA : jusqu’à présent, l’entraînement de modèles de grande taille (70 milliards de paramètres) était réservé à quelques grandes entreprises, en raison des barrières financières et de puissance de calcul. Covenant-72B démontre pour la première fois que la communauté, sans aucun financement centralisé, peut elle aussi entraîner un modèle de taille comparable. Cela redéfinit radicalement les conditions d’accès au développement des modèles fondamentaux d’IA.
Pour la structure du pouvoir dans le domaine de l’IA : l’actuel paysage des modèles fondamentaux d’IA est fortement centralisé — OpenAI, Google, Meta et Anthropic contrôlent les modèles les plus performants. La réussite de l’entraînement décentralisé remet donc en cause cette « zone de sécurité ». L’hypothèse selon laquelle « seules les grandes entreprises peuvent développer des modèles fondamentaux » est pour la première fois sérieusement ébranlée.
Pour le secteur crypto : c’est la première fois qu’un projet crypto produit une contribution technologique concrète dans le domaine de l’IA, et non plus simplement une opération de « surf sur la vague ». Covenant-72B dispose d’un modèle publié sur HuggingFace, d’un article sur arXiv et de données publiques de benchmark. Cela établit un précédent important : les mécanismes d’incitation crypto peuvent constituer une infrastructure crédible pour la recherche sérieuse en IA.
Pour Bittensor lui-même : le succès de SN3 transforme Bittensor d’un « protocole théoriquement viable d’IA décentralisée » en une « infrastructure pratique et éprouvée pour l’IA décentralisée ». Il s’agit là d’une transition qualitative, passant du stade « zéro à un ».
4. Place historique de SN3
Le chemin vers l’entraînement décentralisé de modèles d’IA n’a pas été emprunté pour la première fois par SN3. Toutefois, SN3 y a progressé bien plus loin que ses prédécesseurs.
Histoire de l’évolution de l’entraînement décentralisé :
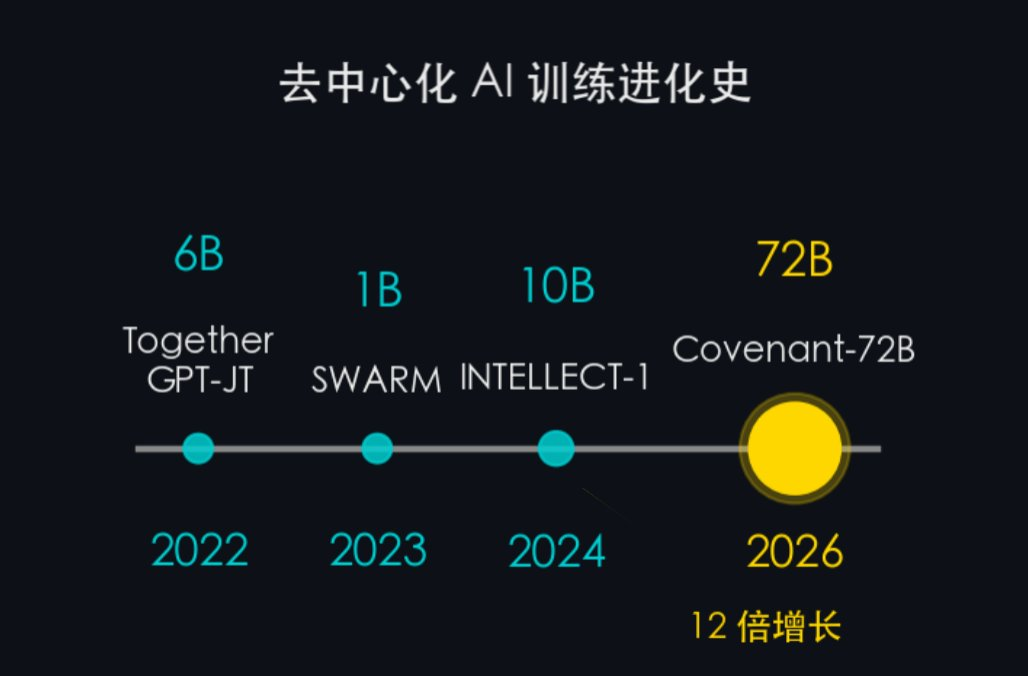
- 2022 — Together GPT-JT (6 milliards de paramètres) : exploration précoce, démontrant la faisabilité de la collaboration multi-machine
- 2023 — SWARM Intelligence (~1 milliard de paramètres) : proposition d’un cadre d’entraînement collaboratif impliquant des nœuds hétérogènes
- 2024 — INTELLECT-1 (10 milliards de paramètres) : entraînement décentralisé transinstitutionnel
- 2026 — Covenant-72B / SN3 (72 milliards de paramètres) : premier grand modèle décentralisé de 72 milliards de paramètres à surpasser, sur les benchmarks standards, les modèles entraînés de façon centralisée
En quatre ans, on passe de 6 à 72 milliards de paramètres, soit une multiplication par douze. Mais ce qui compte davantage que la simple augmentation du nombre de paramètres, c’est la qualité : les projets antérieurs visaient essentiellement à « faire fonctionner le système », tandis que Covenant-72B est le premier modèle décentralisé à dépasser, sur les benchmarks courants, les performances des modèles entraînés de façon centralisée.
Avancées techniques clés :
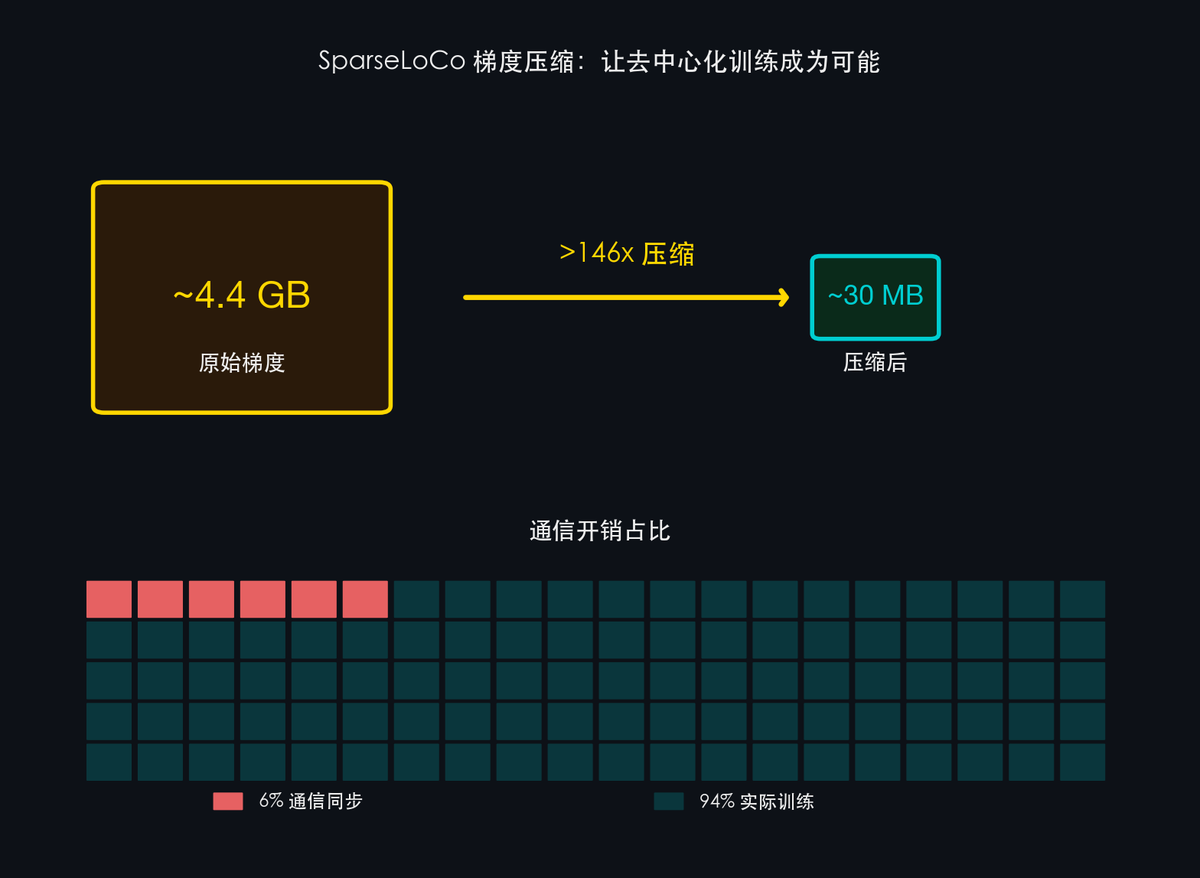
- Taux de compression >99 % (>146×) : chaque fois qu’un participant transmet ses résultats d’entraînement (gradients), le processus SparseLoCo compresse intégralement les données — initialement de plusieurs gigaoctets — de plus de 146 fois. Cela revient à compresser une saison entière d’une série télévisée en une seule image, avec une perte d’information quasi négligeable.
- Surcharge de communication limitée à seulement 6 % : lorsque 100 personnes collaborent, seuls 6 % de leur temps sont consacrés à la « communication et à la coordination », les 94 % restants étant consacrés à l’entraînement effectif. Ce progrès résout l’un des principaux goulots d’étranglement de l’entraînement décentralisé.
5. L’entraînement décentralisé est-il sous-évalué ?
Examinons d’abord les données, puis tirons nos conclusions.
Preuves d’une sous-évaluation
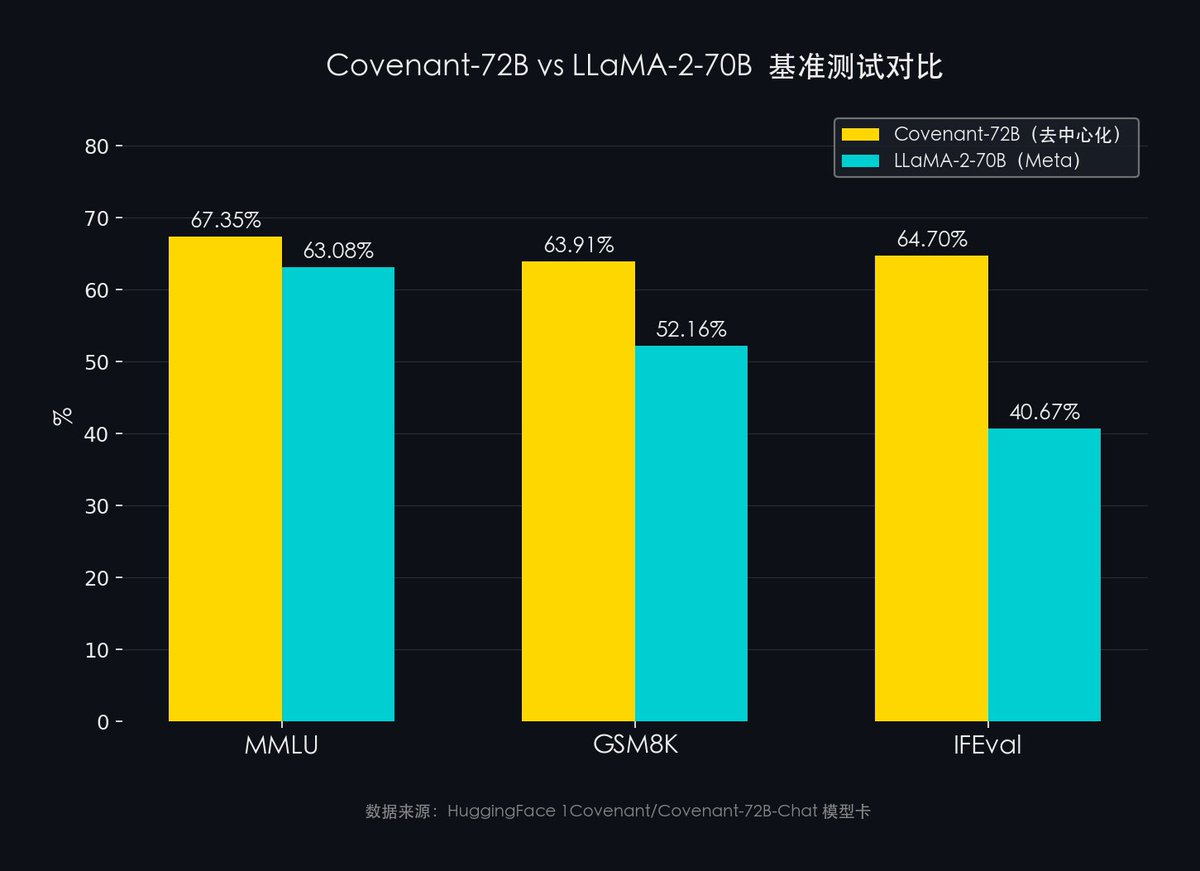
- MMLU : Covenant-72B (67,35 %) contre LLaMA-2 (63,08 %)
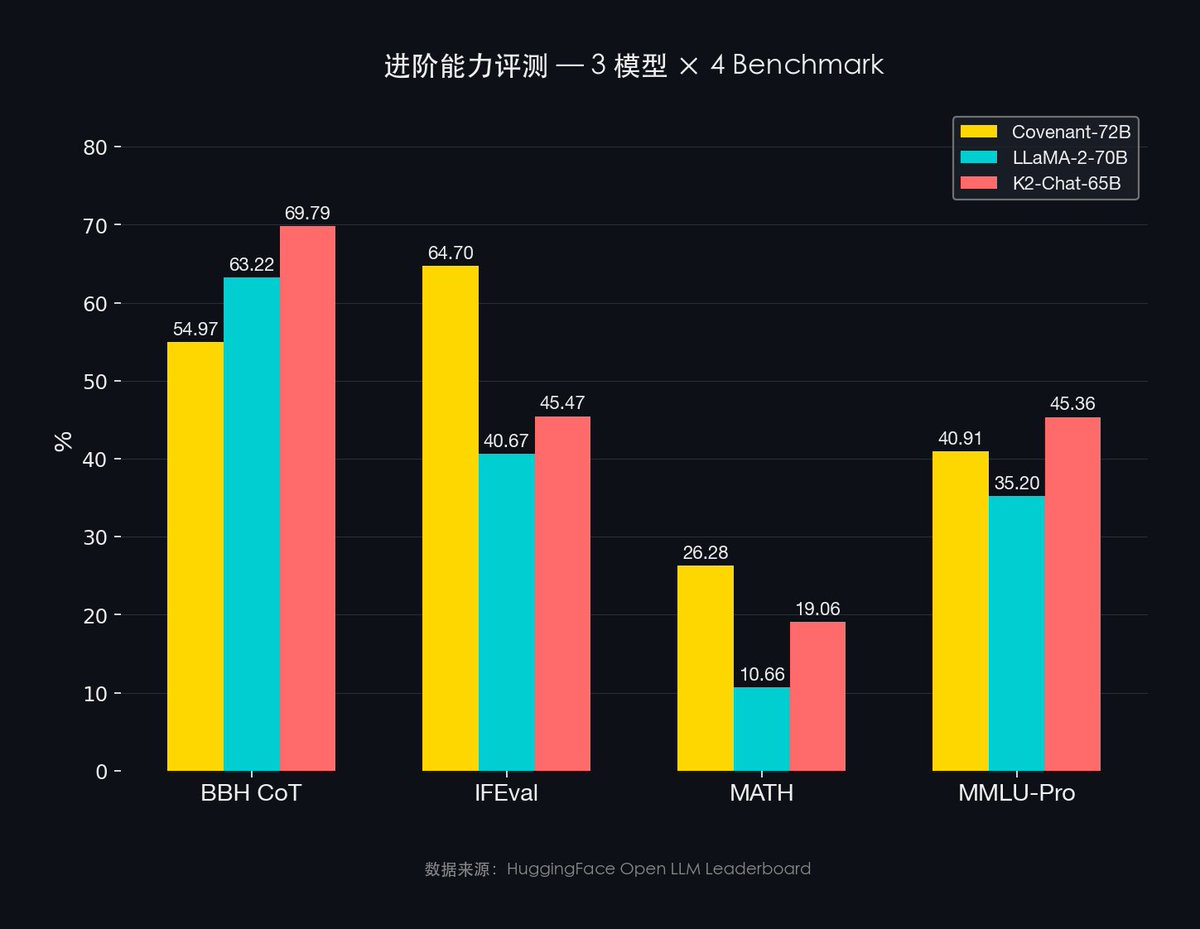
- MMLU-Pro : Covenant-72B (40,91 %) contre LLaMA-2 (35,20 %)
- IFEval : Covenant-72B (64,70 %) contre LLaMA-2 (40,67 %)
Le modèle décentralisé dépasse LLaMA-2-70B, entraîné à grands frais par Meta.
Écart avec les modèles open source leaders actuels (à reconnaître honnêtement) :
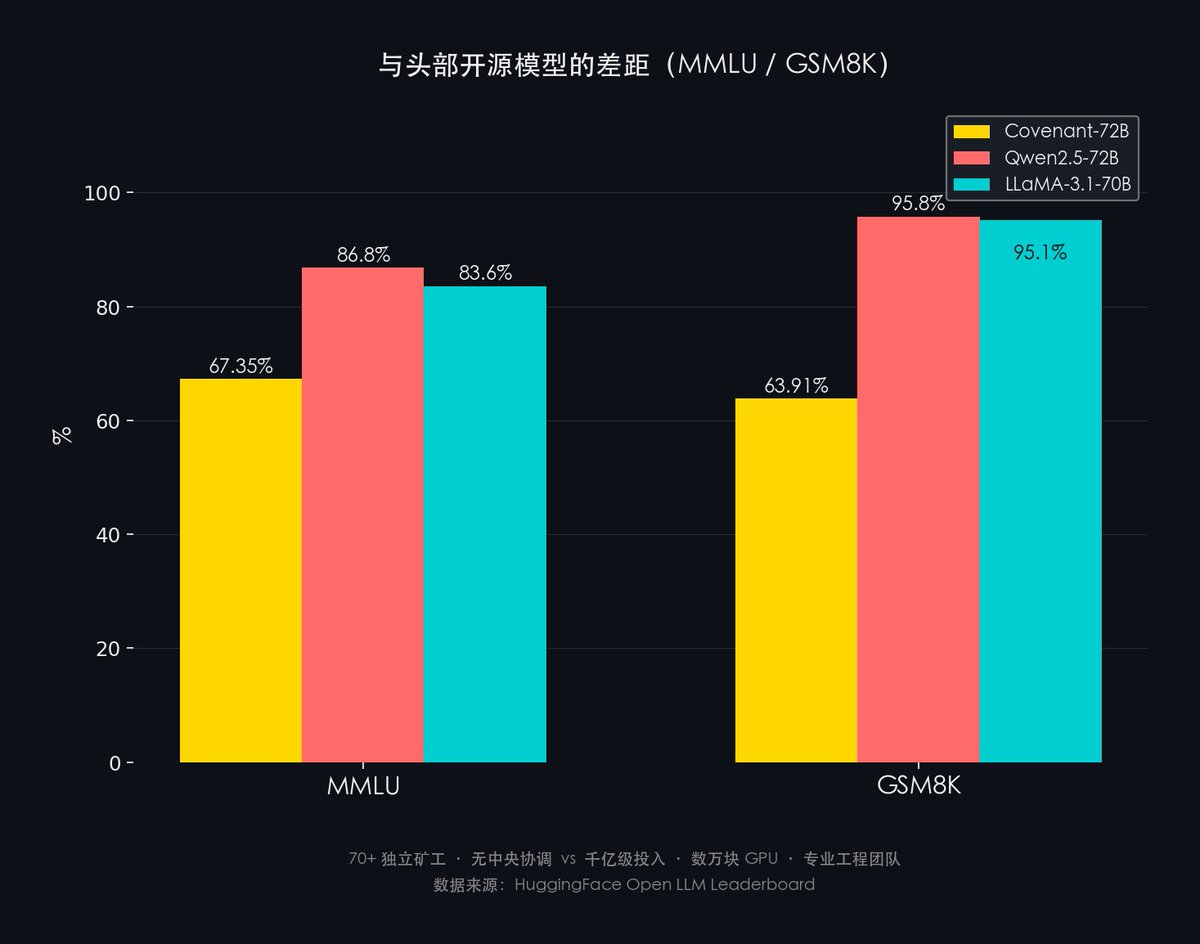
- MMLU : Covenant-72B (67,35 %) contre Qwen2.5-72B (86,8 %) contre LLaMA-3.1-70B (83,6 %)
- GSM8K : Covenant-72B (63,91 %) contre Qwen2.5-72B (95,8 %) contre LLaMA-3.1-70B (95,1 %)
L’écart est d’environ 20 à 30 points de pourcentage.
Mais le cadre de comparaison est essentiel : la valeur de Covenant-72B ne réside pas dans sa capacité à battre les modèles SOTA (State-of-the-Art), mais dans la preuve qu’il apporte de la faisabilité de l’entraînement décentralisé. Qwen2.5 et LLaMA-3.1 reposent sur des investissements à l’échelle des milliards de dollars, des dizaines de milliers de GPU et des équipes d’ingénieurs spécialisées ; Covenant-72B, lui, repose sur plus de 70 mineurs indépendants, sans coordination centrale.
La tendance compte plus qu’un instantané :
- 2022 : le meilleur modèle décentralisé atteignait 6 milliards de paramètres, sans même être évalué sur MMLU.
- 2026 : un modèle de 72 milliards de paramètres obtient un score MMLU de 67,35 %, dépassant les modèles de niveau équivalent de Meta.
En quatre ans, l’entraînement décentralisé est passé d’une « expérience conceptuelle » à une approche dont les performances rivalisent avec celles de l’entraînement centralisé. La pente de cette courbe est plus significative que n’importe quel chiffre isolé issu d’un benchmark.
Par ailleurs, des solutions sont déjà prévues pour combler l’écart actuel de Covenant-72B en matière de raisonnement profond : le sous-réseau SN81 Grail sera chargé de l’entraînement postérieur par apprentissage par renforcement (RLHF), visant à améliorer l’alignement et les capacités du modèle — étape clé qui distingue GPT-4 de GPT-3.
Heterogeneous SparseLoCo constitue la prochaine étape décisive : actuellement, SN3 exige que tous les mineurs utilisent des GPU identiques. La prochaine avancée majeure sera Heterogeneous SparseLoCo, qui permettra d’intégrer du matériel hétérogène (B200 + A100 + GPU grand public) au sein d’une même tâche d’entraînement. Une fois mise en œuvre, cette innovation élargira considérablement le bassin de puissance de calcul disponible pour la prochaine phase d’entraînement.
L’entraînement décentralisé a désormais franchi le seuil de faisabilité. L’écart observé actuellement dans les benchmarks constitue un défi d’ingénierie à relever, non un obstacle théorique insurmontable.
Partie II : Le marché n’a toujours pas compris l’importance de cet événement
Chronologie du prix du TAO
L’évolution du prix du $TAO après l’annonce de SN3 illustre parfaitement ce retard cognitif :
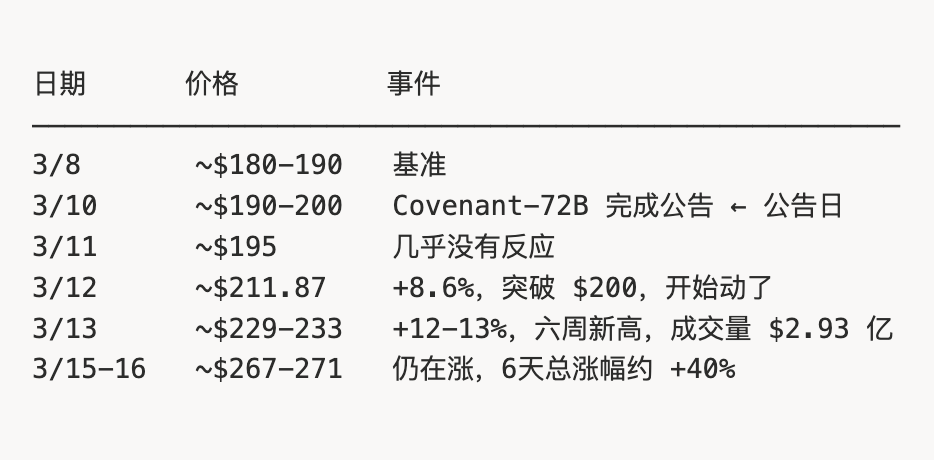
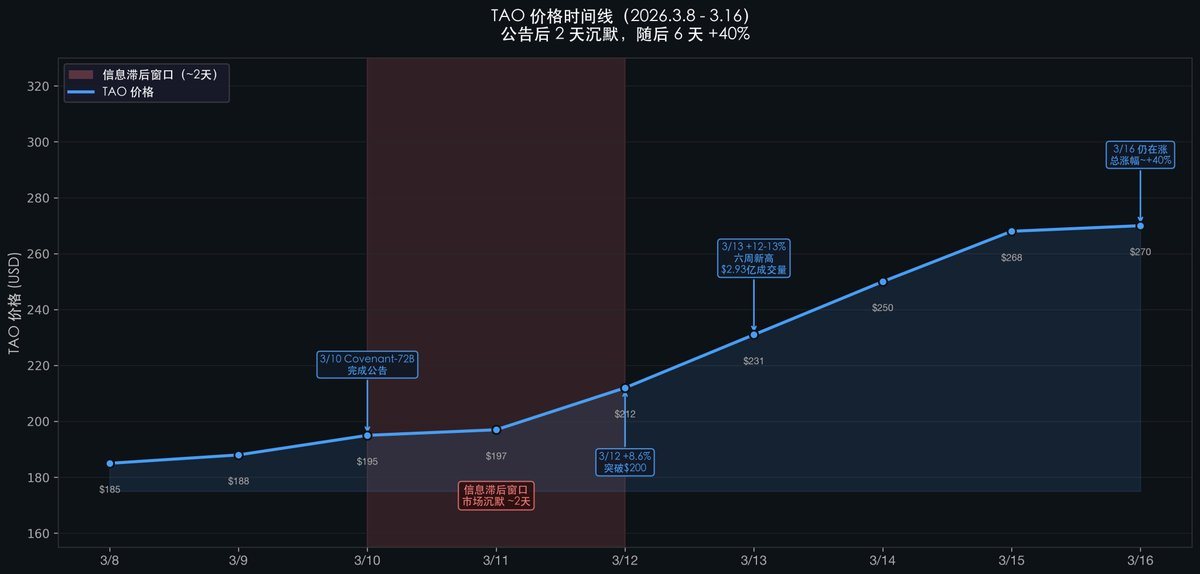
Remarquez ce silence de deux jours (du 10 au 12 mars) : l’annonce est faite, mais le prix reste presque stable.
Pourquoi ce retard ?
Les investisseurs crypto ont lu l’information selon laquelle « Bittensor SN3 a terminé l’entraînement d’un modèle d’IA », mais ils ne saisissent pas nécessairement la portée technique de l’affirmation « entraînement décentralisé de 72 milliards de paramètres dépassant Meta sur MMLU ».
Les chercheurs en IA, eux, comprennent parfaitement cette portée technique, mais ne suivent pas les actualités crypto.
Cette différence de perception entre les deux communautés génère une fenêtre de retard de prix d’environ deux à trois jours.
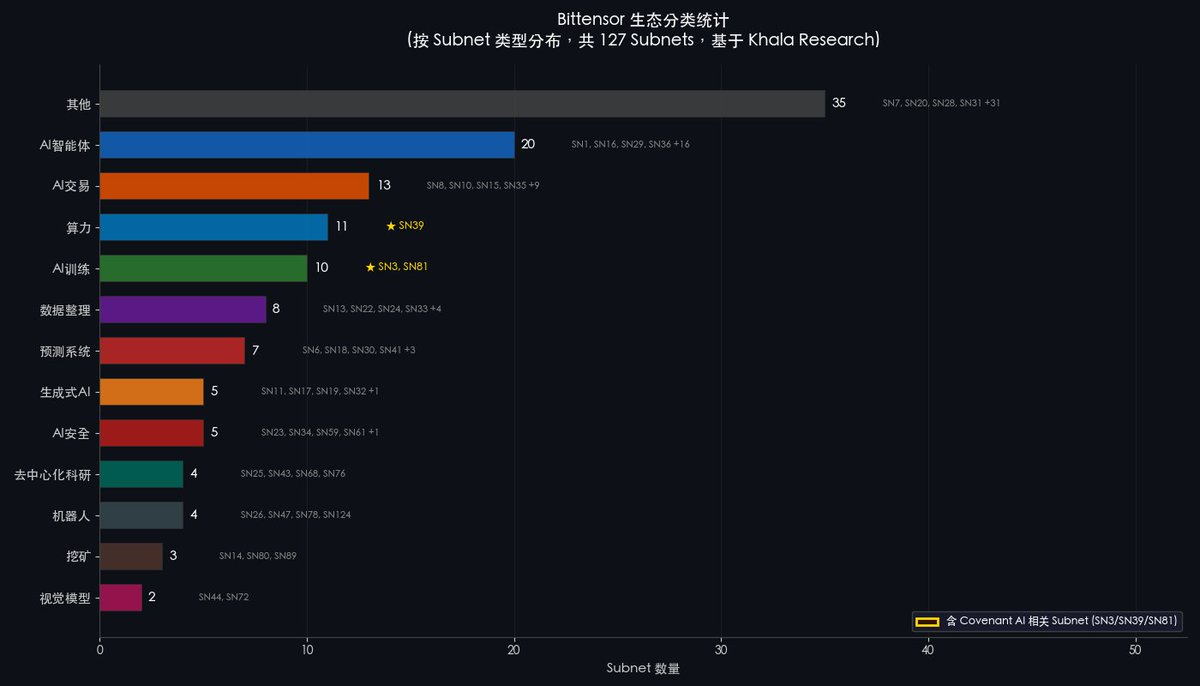
En outre, la plupart des investisseurs crypto perçoivent encore Bittensor à travers le prisme du cycle précédent. Or, le nombre de sous-réseaux actifs sur Bittensor dépasse aujourd’hui 79, couvrant des domaines très variés tels que les agents IA, la puissance de calcul, l’entraînement IA, les transactions IA ou encore la robotique. Lorsque le marché réévaluera la diversité et l’étendue de l’écosystème Bittensor, ce décalage cognitif sera corrigé — et ce processus de correction prend généralement la forme d’une forte hausse des cours.
Une évaluation erronée de Bittensor
Plaçons Bittensor dans un contexte industriel plus large :
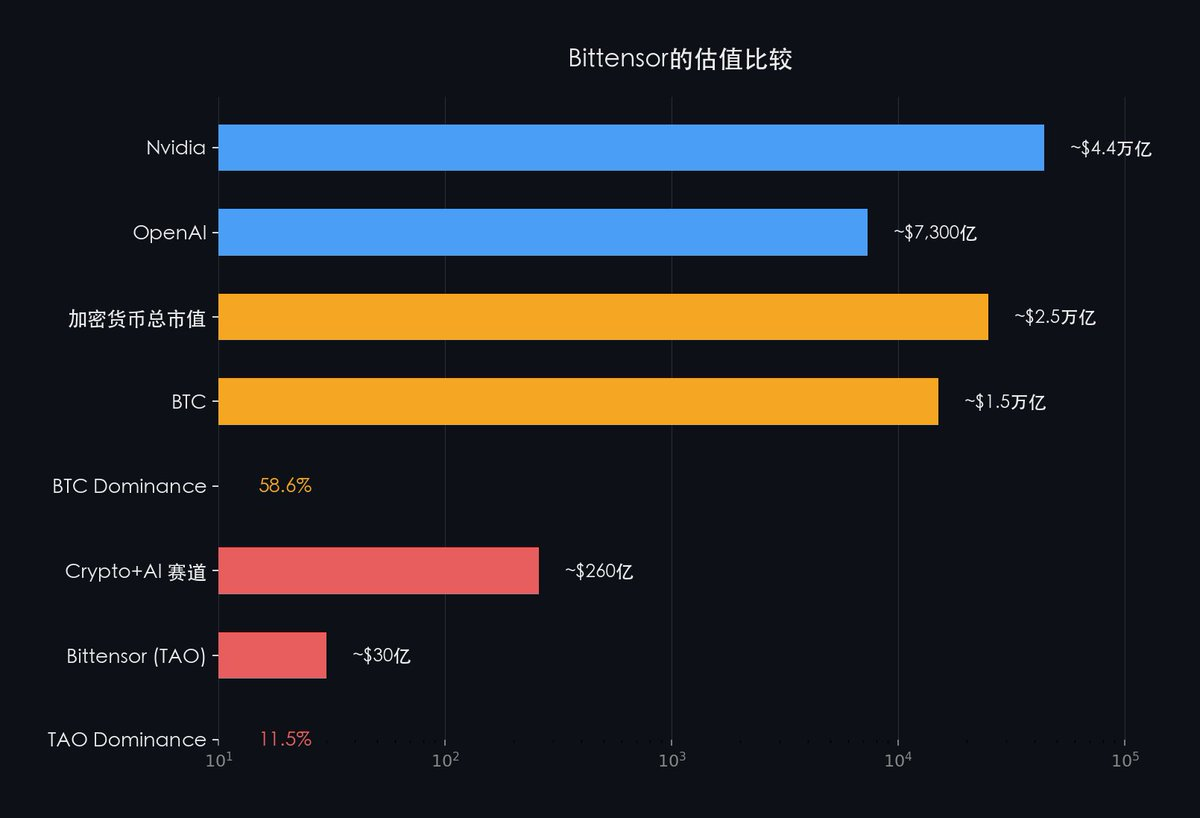
SN3 a déjà démontré que Bittensor est capable d’effectuer l’entraînement décentralisé de grands modèles.
Si, à l’avenir, l’IA a besoin d’un réseau d’entraînement ouvert et sans permission, alors l’infrastructure candidate unique et déjà éprouvée est Bittensor.
Or, le marché évalue actuellement Bittensor selon la logique de valorisation des projets de couche applicative, alors qu’il s’agit d’un réseau d’infrastructure IA.
Même au sein de l’écosystème crypto, la comparaison est éloquente : Bitcoin détient depuis longtemps une part de marché de 50 à 60 % dans l’ensemble du secteur crypto, tandis que Bittensor ne représente que 11,5 % environ de la part de marché de la sous-catégorie « IA crypto ».
Lorsque le marché comprendra pleinement la position stratégique de Bittensor au sein de l’infrastructure IA, ce décalage sera inévitablement corrigé.
Conclusion : Bittensor est l’espoir de toute la communauté crypto
Si Covenant-72B de SN3 Templar prouve une chose, c’est que :
un réseau décentralisé est capable non seulement de coordonner le capital, mais aussi la puissance de calcul et la recherche avancée en IA.
Ces dernières années, la crypto a joué un rôle marginal dans les récits liés à l’IA. De nombreux projets se sont fondés sur des concepts vagues, des effets de mode émotionnels ou des narratifs purement financiers, sans produire de résultats technologiques vérifiables. SN3 constitue un cas nettement différent.
Il ne lance pas un nouveau récit autour d’un jeton, ni ne commercialise un produit de couche applicative fusionnant « IA et Web3 », mais accomplit une tâche plus fondamentale, et plus difficile :
entraîner, sans aucune coordination centralisée, un grand modèle de 72 milliards de paramètres.
Les participants proviennent de toutes les régions du globe et n’ont pas besoin de se faire confiance mutuellement ; le système coordonne automatiquement les contributions à l’entraînement et la distribution des récompenses via des mécanismes d’incitation et de validation sur la chaîne de blocs.
Pour la première fois, les mécanismes crypto organisent une productivité réelle dans le domaine de l’IA.
Beaucoup ne mesurent pas encore l’importance historique de SN3. Tout comme, jadis, beaucoup n’avaient pas saisi que Bitcoin ne démontrait pas seulement un « meilleur moyen de paiement », mais plutôt la possibilité d’un consensus de valeur sans autorité centrale.
Aujourd’hui encore, beaucoup ne voient que les résultats des benchmarks, la publication du modèle ou une simple vague haussière.
Mais le changement véritable est le suivant : Bittensor démontre que :
- la crypto ne se contente pas d’émettre des actifs, elle organise aussi la production
- la crypto ne se contente pas d’échanger de l’attention, elle produit aussi de l’intelligence
Les communautés open source peuvent contribuer du code, le monde universitaire peut produire des articles scientifiques, mais dès lors que les défis touchent à l’entraînement à très grande échelle, à la collaboration à long terme, à l’orchestration transfrontalière, à la lutte contre la fraude ou à la répartition équitable des récompenses, la bonne foi et les systèmes de réputation ne suffisent plus :
- Sans incitation économique, il n’y a pas d’offre stable.
- Sans mécanismes de récompense et de sanction vérifiables, il n’y a pas de collaboration durable.
- Sans mécanisme de coordination basé sur des jetons, il est impossible de créer un réseau mondial, ouvert et sans permission pour la production d’IA.
Alors, Bittensor est-il sous-évalué ? La réponse n’est pas « peut-être », mais bien « de façon manifeste et systématique ».
Dans le grand débat sur « la pertinence continue de la crypto », Bittensor apporte à l’ensemble du secteur la réponse la plus convaincante.
C’est précisément pour cette raison que Bittensor est l’espoir de toute la communauté crypto.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














