

Les LLM révolutionnent la blockchain, inaugurant une nouvelle ère de l'expérience en chaîne
TechFlow SélectionTechFlow Sélection
Les LLM révolutionnent la blockchain, inaugurant une nouvelle ère de l'expérience en chaîne
Les avantages des LLM incluent leur capacité à comprendre de grandes quantités de données, à exécuter diverses tâches liées au langage et à personnaliser les résultats selon les besoins des utilisateurs.
Auteur : Yiping, IOSG Ventures
Premier mot
-
Alors que les grands modèles linguistiques (LLM) se développent de plus en plus, nous observons de nombreux projets combinant l'intelligence artificielle (IA) et la blockchain. La convergence croissante entre LLM et blockchain révèle de nouvelles opportunités où l'IA retrouve un terrain fertile au sein de l'écosystème blockchain. Un domaine particulièrement prometteur est celui du ZKML (Zero-Knowledge Machine Learning).
-
L'intelligence artificielle et la blockchain sont deux technologies transformatrices aux caractéristiques fondamentalement différentes. L’IA nécessite une puissance de calcul élevée, généralement fournie par des centres de données centralisés. En revanche, la blockchain offre un cadre de calcul décentralisé avec une protection accrue de la vie privée, mais elle est moins adaptée aux tâches massives de calcul et de stockage. Nous continuons d’explorer les meilleures pratiques pour intégrer ces deux technologies, et présenterons par la suite plusieurs cas concrets de projets combinant « IA + Blockchain ».
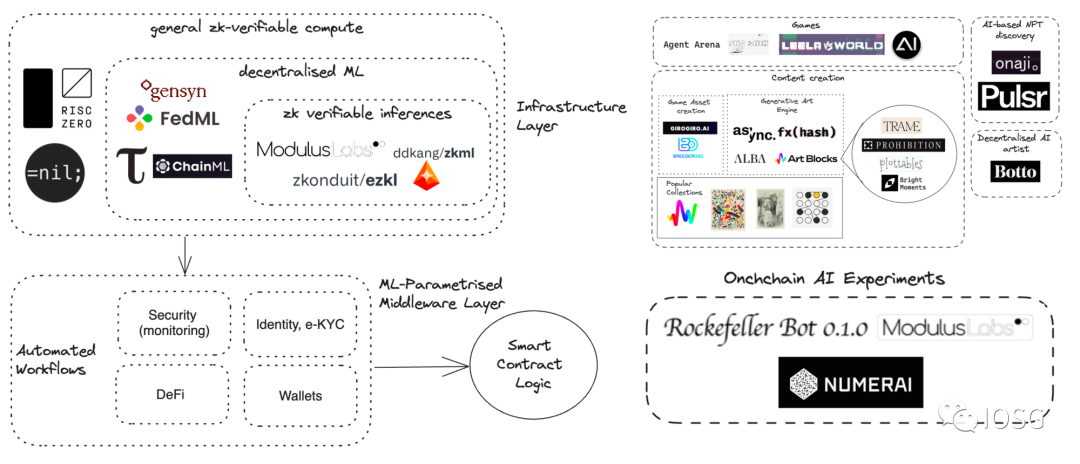
Source : IOSG Ventures
Ce rapport de recherche est publié en deux parties. Le présent article constitue la première partie, dans laquelle nous nous concentrons sur les applications des LLM dans le domaine de la cryptographie, ainsi que sur les stratégies de mise en œuvre concrète.
Qu'est-ce qu'un LLM ?
Un LLM (grand modèle linguistique) est un modèle informatique composé d’un réseau neuronal artificiel doté d’un très grand nombre de paramètres (souvent des milliards). Ces modèles sont entraînés sur de vastes corpus de textes non étiquetés.
Autour de 2018, l’émergence des LLM a radicalement transformé la recherche en traitement du langage naturel. Contrairement aux méthodes antérieures qui nécessitaient l’entraînement de modèles supervisés spécifiques à chaque tâche, les LLM fonctionnent comme des modèles généralistes performants sur une grande variété de tâches. Leurs capacités et usages incluent :
-
Comprendre et résumer du texte : Les LLM peuvent analyser et synthétiser de grandes quantités de données textuelles humaines. Ils extraient les informations clés et génèrent des résumés concis.
-
Générer de nouveaux contenus : Les LLM ont la capacité de produire des contenus textuels originaux. En leur fournissant un prompt, ils peuvent répondre à des questions, générer du texte, résumer ou effectuer une analyse de sentiment.
-
Traduction : Les LLM peuvent traduire entre différentes langues. Ils utilisent des algorithmes d’apprentissage profond et des réseaux neuronaux pour comprendre le contexte et les relations lexicales.
-
Prédire et générer du texte : Les LLM peuvent prédire et générer du texte en se basant sur le contexte, simulant ainsi la production humaine, y compris des chansons, poèmes, histoires ou supports marketing.
-
Applications dans divers domaines : Les grands modèles linguistiques sont largement applicables aux tâches de traitement du langage naturel. Ils sont utilisés dans l’intelligence conversationnelle, les chatbots, la santé, le développement logiciel, les moteurs de recherche, le tutorat, les outils d’écriture, etc.
Les atouts des LLM incluent leur capacité à comprendre d’immenses volumes de données, à exécuter diverses tâches liées au langage, ainsi que leur potentiel de personnalisation selon les besoins des utilisateurs.
Applications courantes des grands modèles linguistiques
Grâce à leurs performances remarquables en compréhension du langage naturel, les LLM offrent un potentiel considérable. Les développeurs s’intéressent principalement à deux axes :
-
Fournir aux utilisateurs des réponses précises et actualisées à partir de grandes masses de données contextuelles
-
Accomplir des tâches spécifiques confiées par l’utilisateur grâce à l’usage de différents agents et outils
Ces deux aspects ont permis l’essor rapide d’applications LLM centrées sur le dialogue avec des documents. Par exemple, discuter avec un PDF, un document ou encore un article académique.
Par la suite, on a tenté d’intégrer les LLM à diverses sources de données. Des plateformes telles que GitHub, Notion ou certains logiciels de prise de notes ont déjà été connectées avec succès aux LLM.
Pour pallier les limites inhérentes des LLM, différents outils ont été intégrés au système. Le premier fut le moteur de recherche, permettant aux LLM d’accéder à des connaissances actualisées. Des avancées ultérieures ont permis d’intégrer des outils comme WolframAlpha, Google Suites ou encore Etherscan aux grands modèles linguistiques.
Architecture des applications LLM
Le schéma ci-dessous illustre le flux d’une application LLM lorsqu’elle répond à une requête utilisateur : tout d’abord, les sources de données pertinentes sont converties en vecteurs d’incorporation (embeddings) et stockées dans une base de données vectorielle. Un adaptateur LLM utilise la requête de l’utilisateur et une recherche de similarité pour extraire du contexte pertinent depuis cette base. Ce contexte est ensuite inséré dans un prompt envoyé au LLM. Le modèle exécute alors ce prompt et génère une réponse, éventuellement assisté par des outils externes. Parfois, le LLM est affiné (fine-tuned) sur un jeu de données spécifique afin d’améliorer sa précision et réduire ses coûts.
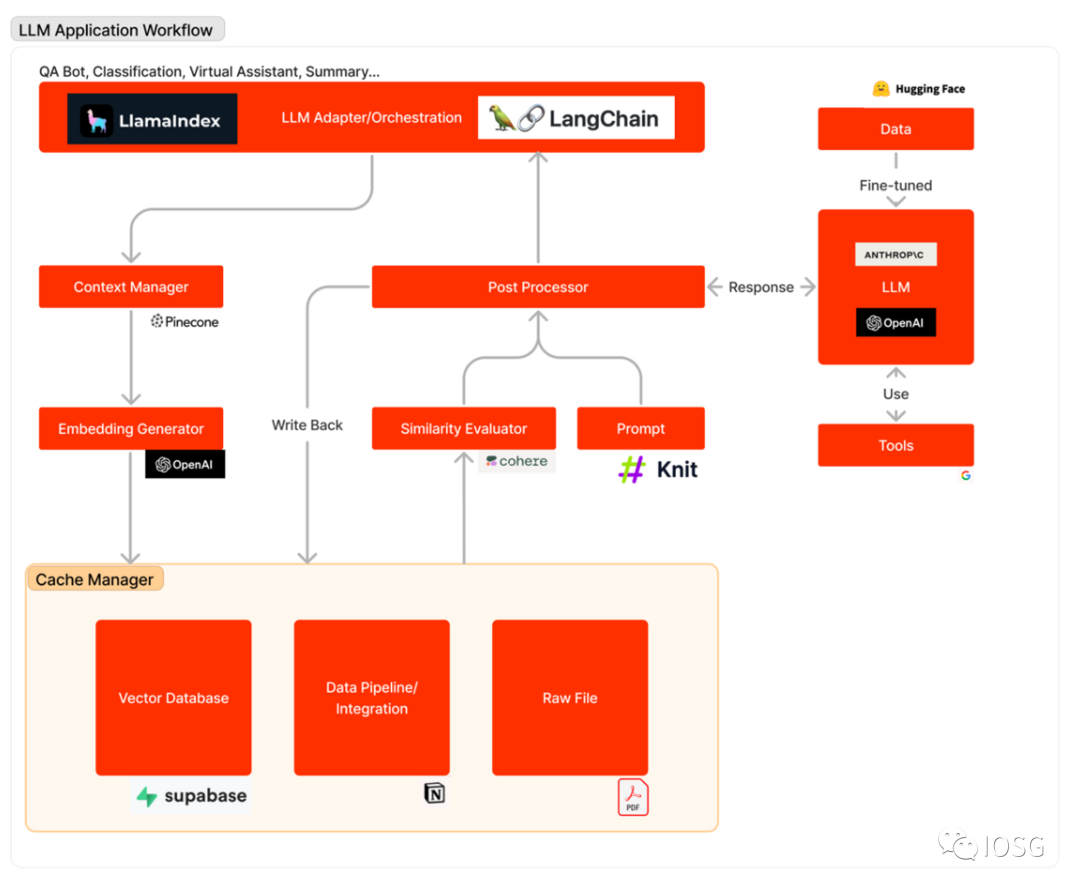
Le workflow d’une application LLM peut être divisé en trois phases principales :
-
Préparation des données et incorporation (embedding) : Cette étape consiste à archiver des informations confidentielles (comme des mémos internes) pour un accès futur. Les fichiers sont généralement découpés puis traités via un modèle d’incorporation, avant d’être stockés dans un type spécial de base de données appelé base de données vectorielle.
-
Construction (formulation) et extraction du prompt : Lorsqu’un utilisateur soumet une requête (par exemple, recherche d’informations sur un projet), le logiciel génère une série de prompts destinés au modèle linguistique. Le prompt final intègre généralement un modèle prédéfini codé en dur par les développeurs, des exemples efficaces (few-shot learning), des données provenant d’API externes, ainsi que des fichiers pertinents extraits de la base vectorielle.
-
Exécution et inférence du prompt : Une fois le prompt construit, il est transmis à un modèle linguistique préexistant pour inférence — il peut s’agir d’une API propriétaire, d’un modèle open source ou d’un modèle affiné individuellement. À ce stade, certains développeurs intègrent également des opérations système comme la journalisation, la mise en cache ou la validation.
Introduire les LLM dans le domaine de la cryptographie
Bien que certaines applications du domaine cryptographique (Web3) soient similaires à celles du Web2, le développement d’excellentes applications LLM dans cet univers requiert une attention particulière.
L’écosystème crypto est unique, doté d’une culture, de données et d’une logique d’intégration propres. Des LLM affinés sur ces jeux de données spécifiques peuvent offrir des résultats supérieurs à coût relativement faible. Bien que les données soient abondantes, il existe un manque criant de jeux de données ouverts sur des plateformes comme HuggingFace. À ce jour, un seul jeu de données lié aux contrats intelligents est disponible, comprenant 113 000 contrats.
Les développeurs rencontrent aussi des difficultés pour intégrer différents outils aux LLM. Ces outils diffèrent de ceux utilisés en Web2 : ils permettent aux LLM d’accéder à des données transactionnelles, d’interagir avec des applications décentralisées (Dapps) et même d’exécuter des transactions. À ce jour, aucune intégration de Dapp n’a encore été trouvée dans Langchain.
Malgré les efforts supplémentaires requis pour développer des applications LLM de haute qualité dans le domaine crypto, les LLM s’y prêtent naturellement bien. Ce domaine fournit en effet des données riches, propres et fortement structurées. De plus, le code Solidity étant généralement concis et clair, il devient plus facile pour les LLM de générer du code fonctionnel.
Dans la partie suivante, nous aborderons huit directions potentielles où les LLM peuvent aider le secteur blockchain, notamment :
-
Intégrer directement des fonctions IA/LLM dans la blockchain
-
Utiliser les LLM pour analyser les historiques de transactions
-
Utiliser les LLM pour identifier des robots potentiels
-
Utiliser les LLM pour écrire du code
-
Utiliser les LLM pour lire et comprendre du code
-
Utiliser les LLM pour aider les communautés
-
Utiliser les LLM pour suivre les marchés
-
Utiliser les LLM pour analyser des projets
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














