

Vers les supercalculateurs mondiaux : un nouveau paradigme de l'exécution décentralisée à très grande échelle
TechFlow SélectionTechFlow Sélection
Vers les supercalculateurs mondiaux : un nouveau paradigme de l'exécution décentralisée à très grande échelle
Pour parvenir à la décentralisation, en tirant parti de l'absence de confiance intrinsèque de la cryptographie, des incitations économiques naturelles liées au MEV, en favorisant une adoption massive, en exploitant le potentiel de la technologie ZK et en répondant à la demande croissante de calcul généralisé décentralisé incluant l'apprentissage automatique, l'émergence d'un superordinateur mondial est devenue une nécessité.
Rédaction : msfew, Kartin, Xiaohang Yu, Qi Zhou
Traduction : TechFlow
*Note : Cet article provient de la Stanford Blockchain Review. TechFlow est partenaire exclusif de la Stanford Blockchain Review et dispose d'une autorisation exclusive pour traduire et republier cet article.

Introduction
À quelle distance l’Ethereum se trouve-t-il d’atteindre finalement ce superordinateur mondial ?
Du consensus pair-à-pair du Bitcoin à la machine virtuelle Ethereum (EVM), jusqu’au concept d’État-Network, l’un des objectifs historiques de la communauté blockchain a toujours été de construire un superordinateur mondial : plus précisément, une machine à état unique, décentralisée, incensurable, sans confiance et évolutif.
Bien qu’il ait été clair depuis longtemps que cela était théoriquement très plausible, jusqu’à présent, les efforts en cours ont été largement fragmentés, comportant de graves compromis et limitations.
Dans cet article, nous examinerons certains des compromis et limites rencontrés par les tentatives actuelles de construction d’un ordinateur mondial, analyserons ensuite les composants essentiels à une telle machine, et proposerons enfin une architecture novatrice pour un superordinateur mondial.
Une nouvelle possibilité, qui mérite que nous y prêtions attention.
1. Limites des approches actuelles
a) Ethereum et les Rollups de niveau 2
Ethereum constitue la première tentative sérieuse — et probablement la plus réussie — de construire un superordinateur mondial. Toutefois, au fil de son développement, Ethereum a fortement privilégié la décentralisation et la sécurité au détriment de l’évolutivité et des performances. Ainsi, bien qu’il soit fiable, Ethereum standard est loin d’être un superordinateur mondial — il n’est tout simplement pas évolutif.
La solution actuelle consiste en les rollups de niveau 2 (L2), devenus la méthode d’évolutivité la plus répandue pour améliorer les performances de l’ordinateur mondial Ethereum. En tant que couche supplémentaire construite au-dessus d’Ethereum, les rollups L2 offrent des avantages significatifs et bénéficient du soutien de la communauté.
Bien que plusieurs définitions existent pour les rollups L2, on considère généralement qu’un rollup L2 est un réseau possédant deux caractéristiques clés : la disponibilité des données sur chaîne (sur Ethereum ou une autre blockchain de base) et l’exécution hors chaîne des transactions. Fondamentalement, les données historiques ou les entrées transactionnelles sont publiquement accessibles et vérifiées via des engagements sur Ethereum, tandis que chaque transaction individuelle et chaque transition d’état sont déplacées hors de la chaîne principale.
Bien que les rollups L2 améliorent effectivement grandement les performances de ces « ordinateurs globaux », beaucoup souffrent de risques systémiques de centralisation, qui sapent fondamentalement le principe des blockchains comme réseaux décentralisés. En effet, l’exécution hors chaîne implique non seulement les transitions d’état individuelles, mais aussi l’ordonnancement ou le groupage des transactions. Dans la plupart des cas, c’est un séquenceur L2 qui effectue cet ordonnancement, tandis qu’un validateur L2 calcule le nouvel état. Or, confier cette capacité d’ordonnancement à un séquenceur L2 crée un risque de centralisation, où un séquenceur centralisé peut abuser de son pouvoir, censurer arbitrairement des transactions, nuire à la vitalité du réseau et profiter du capture de MEV.
Bien que de nombreuses discussions aient eu lieu sur la manière de réduire ces risques de centralisation dans les L2 — par exemple via des solutions mutualisées, externalisées ou basées sur des séquenceurs, ou encore des solutions de séquenceurs décentralisés (comme PoA, sélection de leader PoS, enchères de MEV ou PoE) — bon nombre de ces tentatives restent à l’étape conceptuelle et sont loin d’être des remèdes universels. De plus, de nombreux projets L2 semblent réticents à implémenter des solutions de séquenceurs décentralisés. Par exemple, Arbitrum propose un séquenceur décentralisé comme fonctionnalité optionnelle. Outre le problème du séquenceur centralisé, les rollups L2 peuvent présenter des risques de centralisation liés aux exigences matérielles des nœuds complets, aux risques de gouvernance et à la tendance croissante des applications à leur propre rollup.
b) Les rollups L2 et le dilemme du triple ordinateur mondial
Tous ces problèmes de centralisation découlant de l’utilisation des rollups L2 pour étendre Ethereum révèlent un problème fondamental : le « dilemme du triple ordinateur mondial », dérivé du classique « dilemme du triple blockchain » :
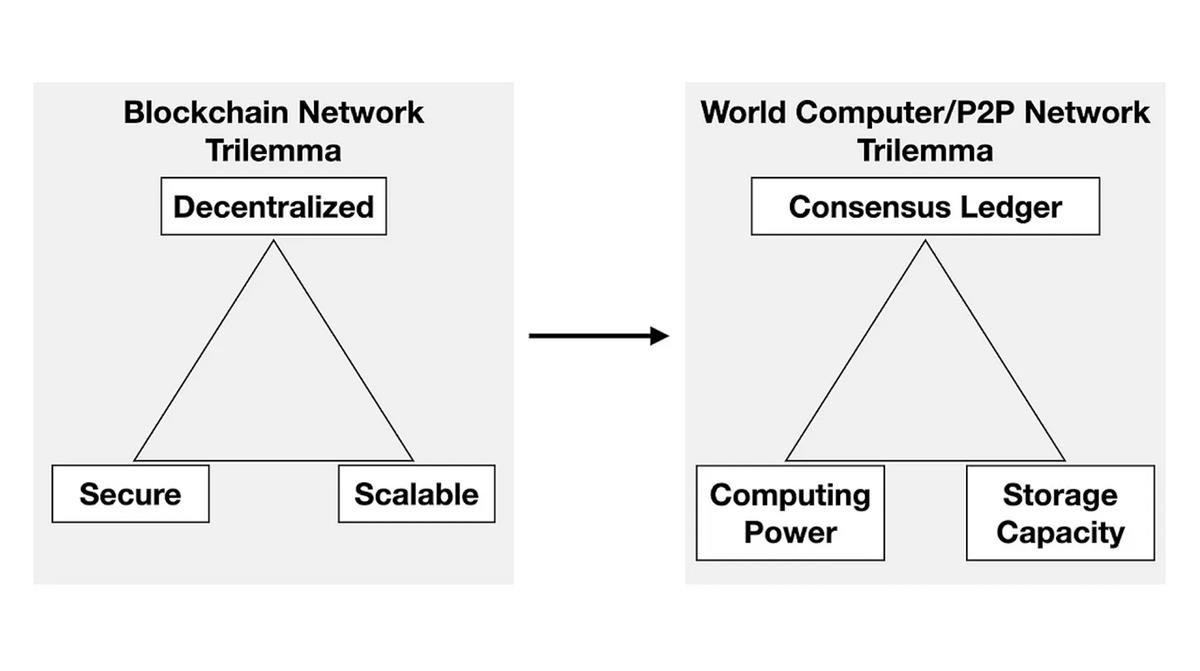
Les différentes priorités dans ce dilemme entraînent des compromis distincts :
-
Ledger de consensus fort : nécessite fondamentalement un stockage et un calcul redondants, donc mal adapté à l’évolutivité du stockage et du calcul.
-
Capacité de calcul forte : nécessite de réutiliser fréquemment le consensus lors de l’exécution de calculs ou de preuves intensifs, donc mal adapté au stockage à grande échelle.
-
Capacité de stockage forte : nécessite de réutiliser fréquemment le consensus pour des preuves d’espace par échantillonnage aléatoire, donc mal adapté au calcul.
Les solutions traditionnelles de type L2 construisent en réalité l’ordinateur mondial de façon modulaire. Toutefois, comme elles ne partitionnent pas les différentes fonctions selon les priorités ci-dessus, même après extension, l’ordinateur mondial conserve l’architecture hôte initiale d’Ethereum. Cette architecture ne satisfait ni les exigences de décentralisation ni celles de performance, et ne résout pas le dilemme du triple ordinateur mondial.
Autrement dit, les rollups L2 réalisent effectivement les éléments suivants :
-
La modularité de l’ordinateur mondial (permettant davantage d’expérimentations au niveau de la couche de consensus, avec une certaine confiance externe sur les séquenceurs centralisés) ;
-
L’amélioration du débit de l’ordinateur mondial (bien que pas strictement une « évolutivité ») ;
-
L’innovation ouverte pour l’ordinateur mondial.
Cependant, les rollups L2 ne fournissent pas :
-
La décentralisation de l’ordinateur mondial ;
-
L’amélioration des performances de l’ordinateur mondial (la somme maximale des TPS des rollups est en réalité insuffisante, et un L2 ne peut jamais avoir une finalité plus rapide que celle d’un L1) ;
-
Le calcul de l’ordinateur mondial (ce qui inclut des opérations allant au-delà du traitement des transactions, comme le machine learning ou les oracles).
Bien qu’une architecture d’ordinateur mondial puisse intégrer des L2 et des blockchains modulaires, elle ne résout pas le problème fondamental. Les L2 peuvent résoudre le dilemme du triple blockchain, mais pas celui de l’ordinateur mondial lui-même. Ainsi, comme nous le voyons, les méthodes actuelles sont insuffisantes pour réaliser pleinement l’ordinateur mondial décentralisé tel qu’initialement imaginé par Ethereum. Nous avons besoin d’une évolutivité des performances accompagnée de décentralisation, et non d’une évolutivité des performances associée à une décentralisation progressive.
2. Objectifs de conception du superordinateur mondial
Pour y parvenir, nous avons besoin d’un réseau capable de gérer efficacement des calculs intensifs généralistes (notamment le machine learning et les oracles), tout en conservant la décentralisation totale de la couche de base. En outre, nous devons garantir que ce réseau puisse supporter des calculs exigeants, tels que le machine learning (ML), pouvant s’exécuter directement sur le réseau et être finalement vérifiés sur la blockchain. Enfin, nous devons fournir une capacité de stockage et de calcul suffisante au-dessus des implémentations actuelles d’ordinateur mondial, selon les objectifs et approches suivants :
a) Exigences en matière de calcul
Pour répondre aux besoins et objectifs de l’ordinateur mondial, nous étendons le concept d’ordinateur mondial tel qu’énoncé par Ethereum, visant désormais à atteindre un superordinateur mondial.
Un superordinateur mondial doit d’abord accomplir, de manière décentralisée, toutes les tâches que les ordinateurs peuvent effectuer aujourd’hui et demain. Pour préparer une adoption massive, les développeurs ont besoin d’un superordinateur mondial afin d’accélérer le développement et l’adoption du machine learning décentralisé, notamment pour exécuter et valider des inférences de modèles.
Pour des tâches intensives en ressources comme le machine learning, atteindre cet objectif requiert non seulement des technologies de calcul à confiance minimale comme les preuves à connaissance nulle (ZK), mais également une plus grande capacité de données sur un réseau décentralisé. Ces conditions ne peuvent être remplies sur un simple réseau pair-à-pair (comme une blockchain traditionnelle).
b) Solutions aux goulets d’étranglement de performance
Au début du développement des ordinateurs, nos prédécesseurs ont fait face à des goulets d’étranglement similaires, dus aux compromis entre puissance de calcul et capacité de stockage. Prenons comme exemple le composant le plus élémentaire d’un circuit.
Nous pouvons comparer la quantité de calcul à une ampoule/transistor, et la capacité de stockage à un condensateur. Dans un circuit, l’ampoule a besoin de courant pour produire de la lumière, tout comme une tâche de calcul a besoin de puissance pour s’exécuter. En revanche, le condensateur stocke la charge électrique, tout comme le stockage conserve les données.
Pour une tension et un courant donnés, il existe un compromis dans la répartition de l’énergie entre l’ampoule et le condensateur. Généralement, un calcul plus intense nécessite plus de courant, ce qui laisse moins d’énergie disponible pour le stockage. Un condensateur plus grand peut stocker plus d’énergie, mais peut entraîner des performances de calcul réduites sous forte charge. Ce compromis rend difficile, voire impossible, la combinaison de calcul et de stockage dans certains cas.
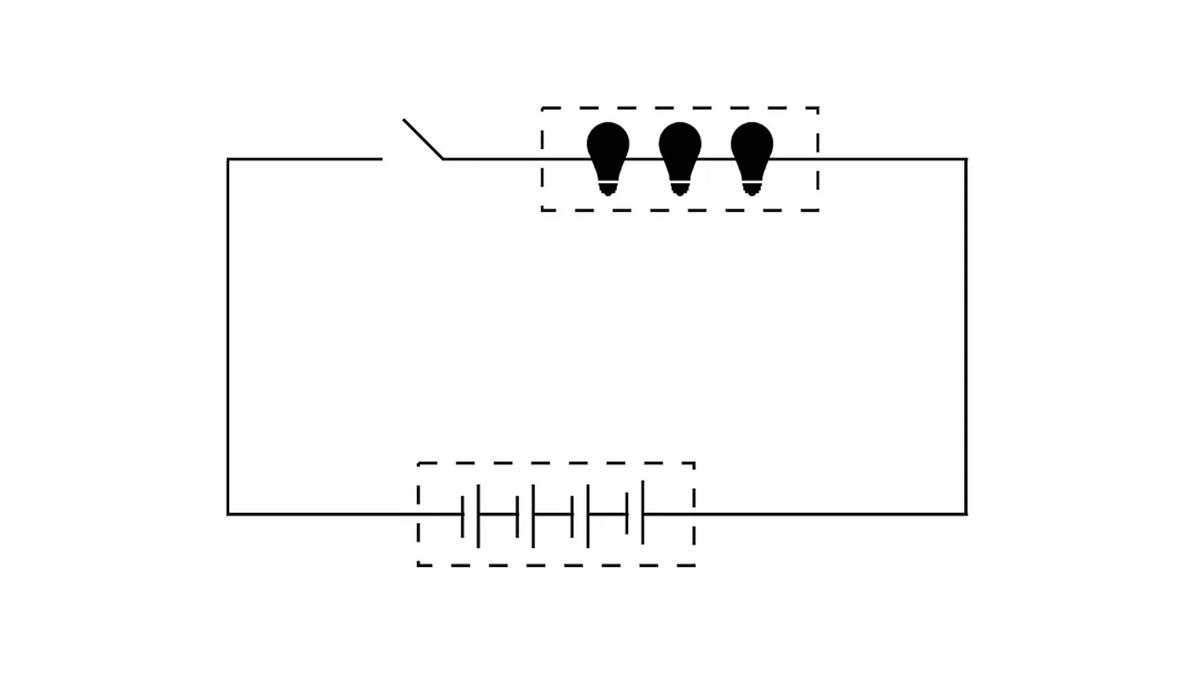
Dans l’architecture informatique de von Neumann, on adopte justement le principe de séparation entre le processeur central et les dispositifs de stockage. Comme séparer l’ampoule du condensateur, cela permet de résoudre les goulets d’étranglement de performance dans notre système de superordinateur mondial.
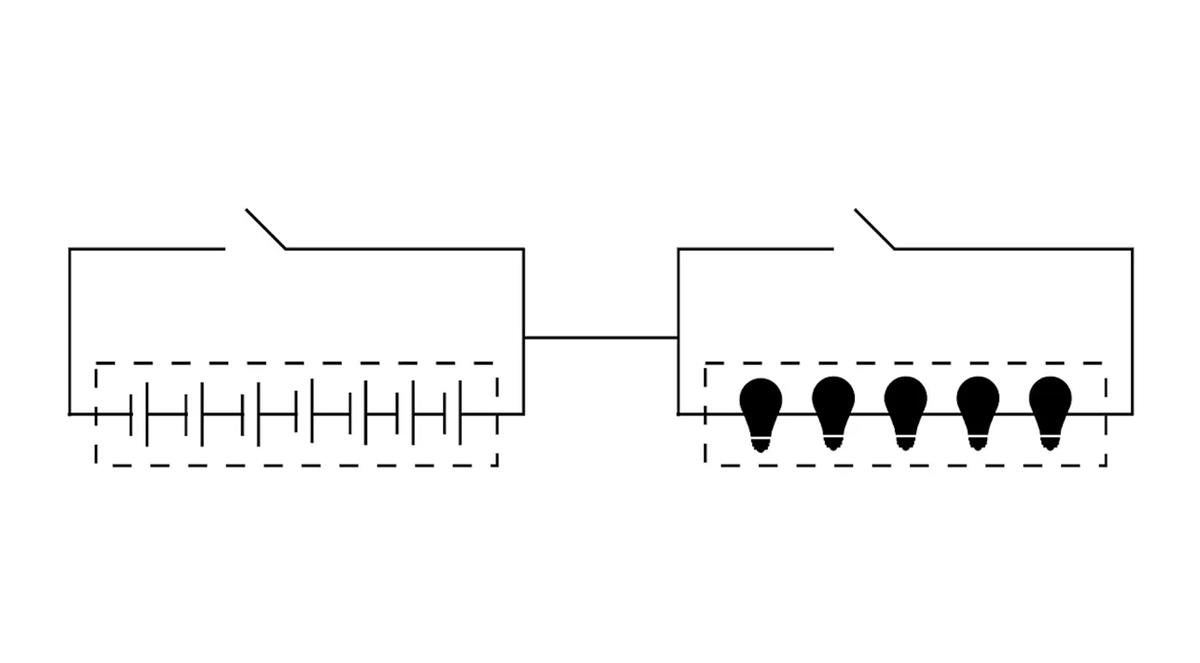
Par ailleurs, les bases de données distribuées hautes performances traditionnelles adoptent une conception séparant stockage et calcul. Cette approche est utilisée car elle est parfaitement compatible avec les caractéristiques du superordinateur mondial.
c) Une topologie d’architecture novatrice
La différence principale entre les blockchains modulaires (y compris les rollups L2) et l’architecture d’ordinateur mondial réside dans leurs objectifs :
-
Blockchain modulaire : vise à créer de nouvelles blockchains en combinant des modules (consensus, couche de disponibilité des données DA, règlement et exécution).
-
Superordinateur mondial : vise à construire un ordinateur/réseau global décentralisé en combinant différents réseaux (blockchain de base, réseau de stockage, réseau de calcul).
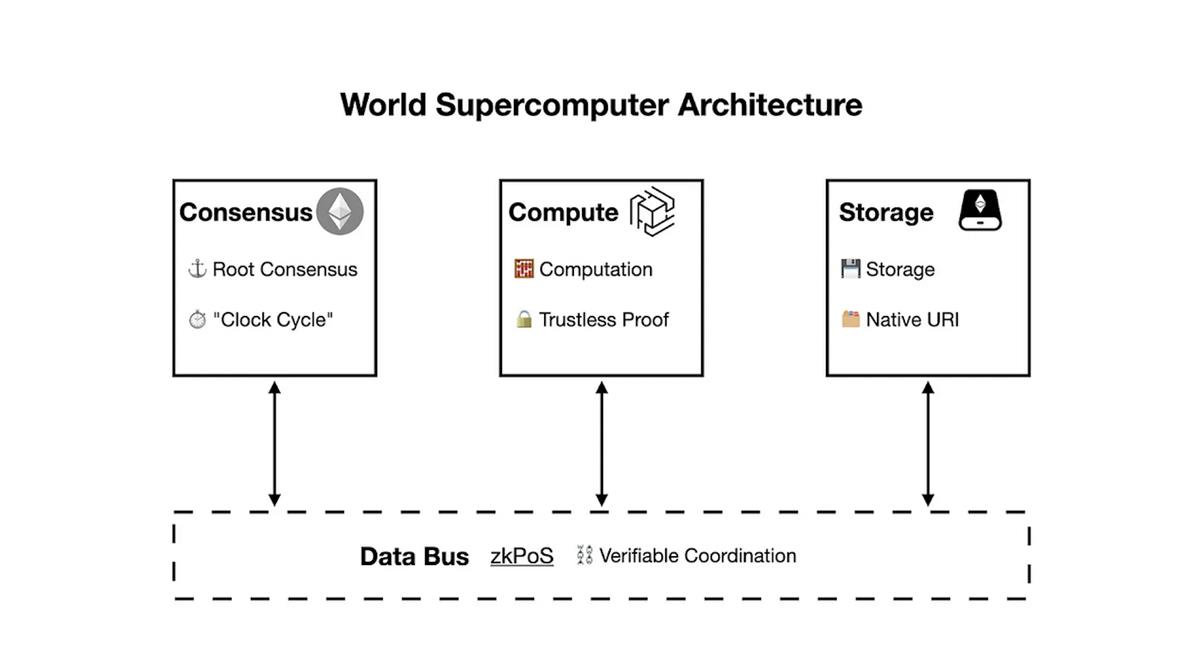
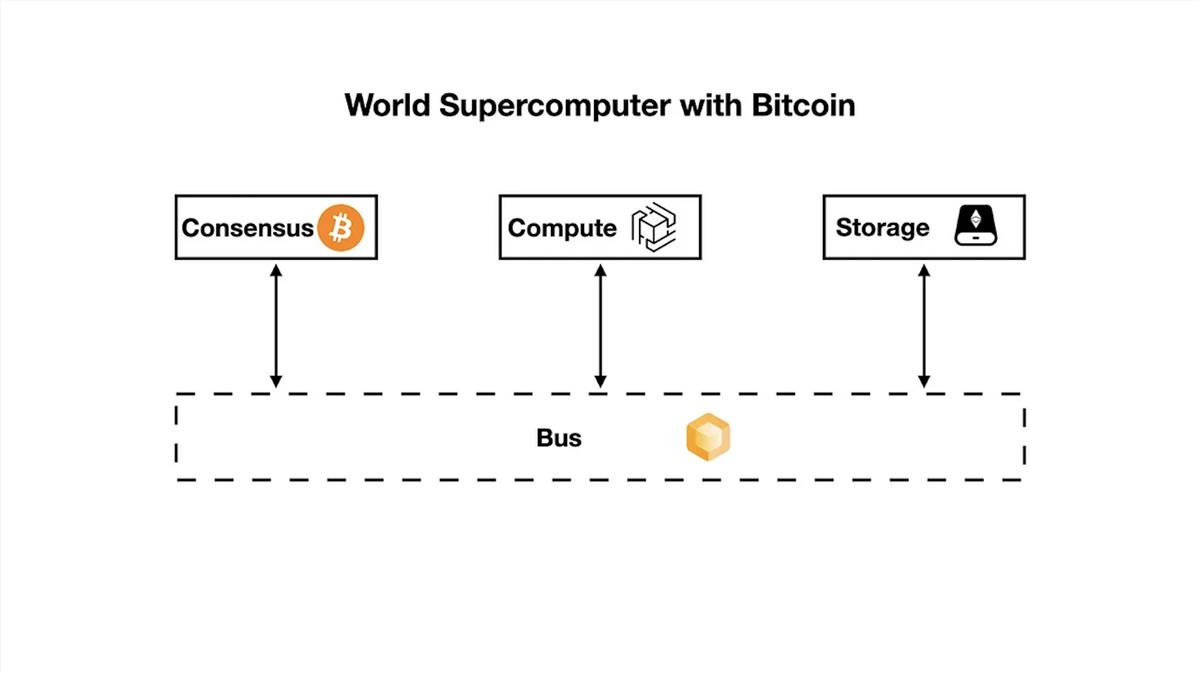
Nous proposons une alternative : le superordinateur mondial final sera constitué de trois réseaux pair-à-pair topologiquement hétérogènes, connectés par des bus sans confiance (connecteurs) basés sur des technologies de preuve à connaissance nulle. Ces trois composants sont : le ledger de consensus, le réseau de calcul et le réseau de stockage. Cette configuration de base permet au superordinateur mondial de résoudre le dilemme du triple, et d’autres composants peuvent être ajoutés selon les besoins applicatifs spécifiques.
Notons que l’hétérogénéité topologique concerne non seulement les différences architecturales et structurelles, mais aussi des divergences fondamentales au niveau de la forme topologique. Par exemple, bien qu’Ethereum et Cosmos soient hétérogènes au niveau de la couche réseau et de l’interconnexion, ils restent équivalents en termes d’hétérogénéité topologique (blockchain).
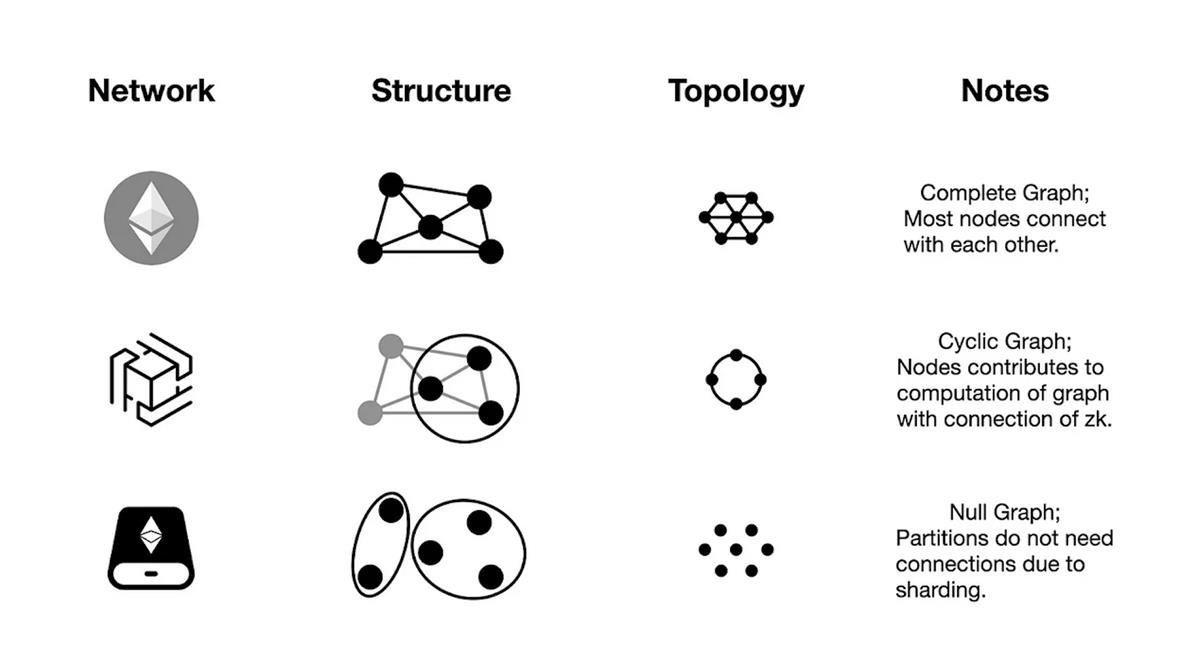
Dans le superordinateur mondial, la blockchain du ledger de consensus adopte une forme de blockchain, les nœuds formant un graphe complet, alors que le réseau zkOracle de Hyper Oracle est un réseau sans ledger, dont les nœuds forment un graphe cyclique, et le réseau de storage rollup constitue une autre variante, avec des partitions formant des sous-réseaux.
En utilisant les preuves à connaissance nulle comme bus de données, nous pouvons connecter ces trois réseaux pair-à-pair topologiquement hétérogènes pour obtenir un superordinateur mondial entièrement décentralisé, incensurable, sans permission et évolutif.
3. Architecture du superordinateur mondial
Comme pour la construction d’un ordinateur physique, nous devons assembler les réseaux de consensus, de calcul et de stockage mentionnés précédemment en un seul superordinateur mondial.
Le choix et la connexion appropriés de chaque composant nous aideront à trouver un équilibre entre le ledger de consensus, la capacité de calcul et la capacité de stockage, assurant ainsi décentralisation, hautes performances et sécurité du superordinateur mondial.
L’architecture du superordinateur mondial, décrite selon ses fonctions, est la suivante :
La structure des nœuds du réseau du superordinateur mondial, comprenant les réseaux de consensus, de calcul et de stockage, est similaire à ce qui suit :
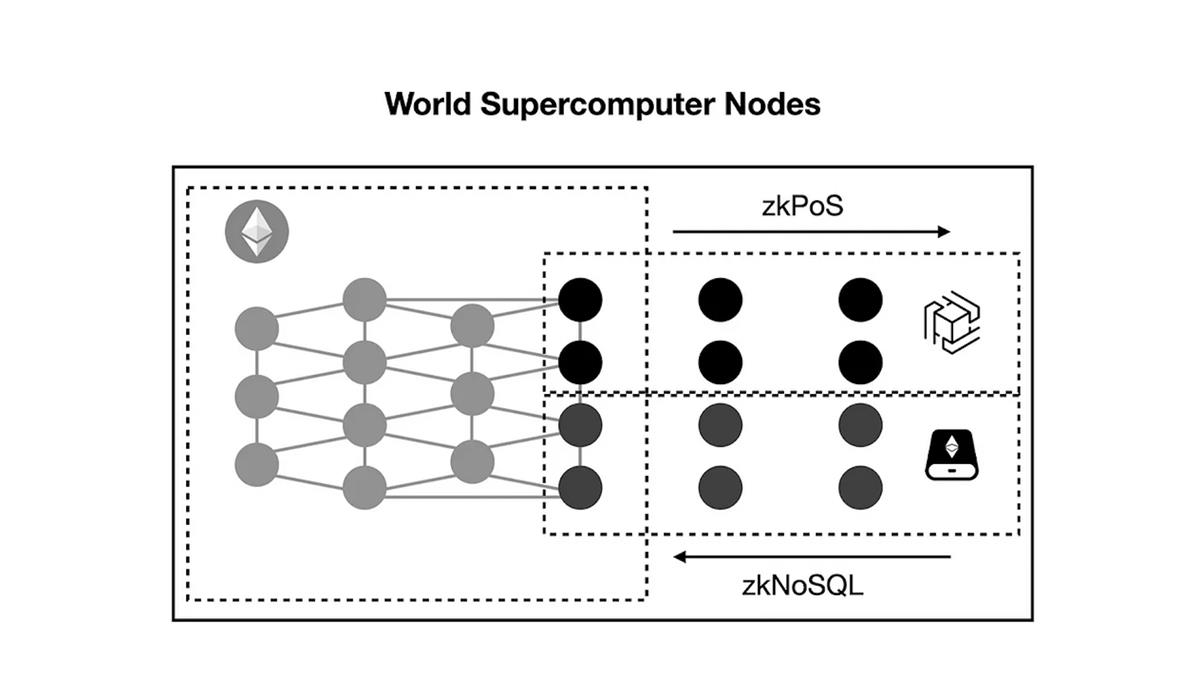
Pour lancer le réseau, les nœuds du superordinateur mondial s’appuieront sur l’infrastructure décentralisée d’Ethereum. Les nœuds dotés de hautes performances de calcul pourront rejoindre le réseau de calcul zkOracle pour générer des preuves destinées à des calculs généralistes ou au machine learning, tandis que les nœuds ayant une grande capacité de stockage pourront rejoindre le réseau de stockage d’EthStorage.
L’exemple ci-dessus décrit des nœuds exécutant simultanément Ethereum et les réseaux de calcul ou de stockage. Pour les nœuds exécutant uniquement les réseaux de calcul ou de stockage, ils pourront accéder au dernier bloc d’Ethereum ou prouver la disponibilité des données stockées via des bus technologiques à connaissance nulle (tels que zkPoS et zkNoSQL), sans aucune confiance requise.
a) Consensus Ethereum
Actuellement, le réseau de consensus du superordinateur mondial utilise exclusivement Ethereum. Ce dernier bénéficie d’un fort consensus social et d’une sécurité au niveau du réseau, garantissant un consensus décentralisé.

Le superordinateur mondial repose sur une architecture centrée sur un ledger de consensus. Ce ledger a deux rôles principaux :
-
Fournir un consensus à l’ensemble du système ;
-
Définir les cycles d’horloge du CPU via les intervalles de blocs.
Contrairement au réseau de calcul ou de stockage, Ethereum ne peut ni traiter simultanément de grandes quantités de tâches de calcul, ni stocker de grandes quantités de données généralistes.
Dans le superordinateur mondial, Ethereum joue le rôle de réseau de consensus, stockant des données comme les rollups L2, servant de consensus aux réseaux de calcul et de stockage, et chargeant des données critiques pour permettre au réseau de calcul d’effectuer des calculs hors chaîne supplémentaires.
b) Storage Rollup
Le Proto-danksharding et le Danksharding d’Ethereum sont essentiellement des moyens d’étendre le réseau de consensus. Pour atteindre la capacité de stockage nécessaire au superordinateur mondial, nous avons besoin d’une solution à la fois native d’Ethereum et supportant le stockage permanent de grandes quantités de données.

Les storage rollups, comme EthStorage, étendent fondamentalement Ethereum pour un stockage à grande échelle. De plus, étant donné que les applications intensives en ressources (telles que le machine learning) ont besoin de grandes quantités de mémoire pour s’exécuter sur un ordinateur physique, il est important de noter que la « mémoire » d’Ethereum ne peut pas être excessivement étendue. Les storage rollups sont donc nécessaires pour permettre au superordinateur mondial d’exécuter des tâches intensives en calcul, en agissant comme une « mémoire virtuelle ».
En outre, EthStorage fournit un protocole d’accès web3:// (ERC-4804), similaire à une URI native ou à une adresse de ressource de stockage pour le superordinateur mondial.
c) Réseau de calcul zkOracle
Le réseau de calcul est l’élément le plus crucial du superordinateur mondial, car il détermine les performances globales. Il doit être capable de gérer des calculs complexes tels que les oracles ou le machine learning, et doit être plus rapide que le réseau de consensus ou de stockage en matière d’accès et de traitement des données.
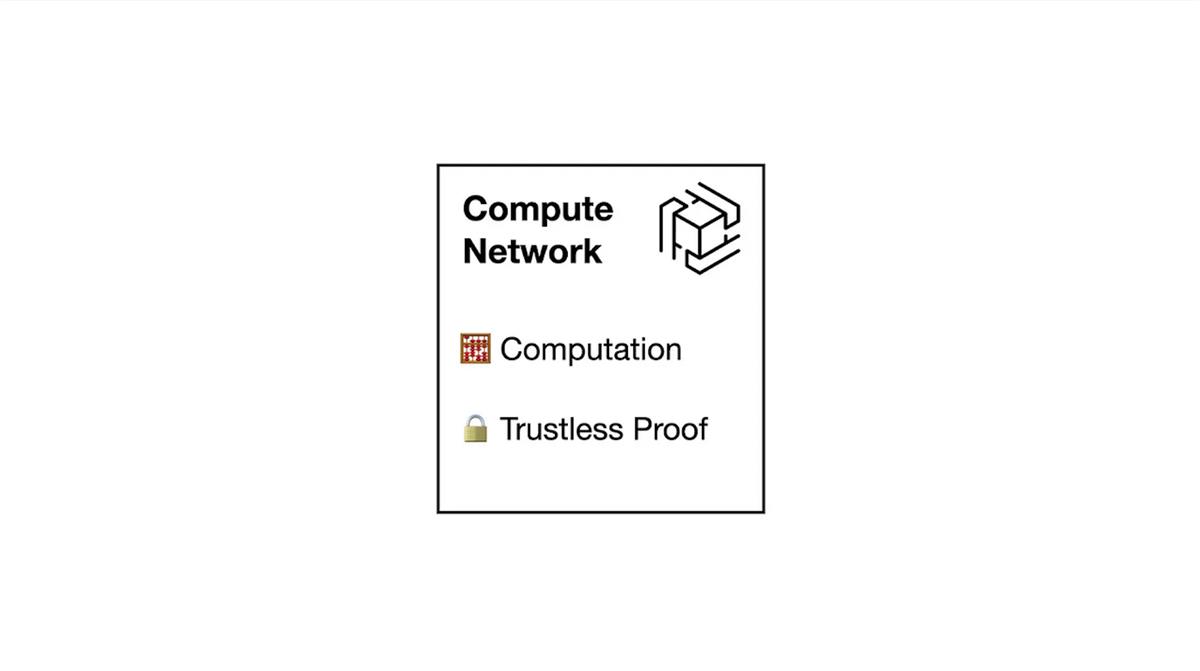
Le réseau zkOracle est un réseau de calcul décentralisé et à confiance minimale, capable de traiter des calculs arbitraires. Tout programme exécuté génère une preuve ZK, facilement vérifiable par le consensus (Ethereum) ou d’autres composants.
Hyper Oracle est un réseau zkOracle, alimenté par zkWASM et EZKL, capable d’exécuter n’importe quel calcul grâce à des preuves de traçabilité d’exécution.
Le réseau zkOracle est une blockchain sans ledger (sans état global), suivant la structure en chaîne de la blockchain d’origine (Ethereum), mais fonctionnant comme un réseau de calcul sans ledger. Contrairement aux blockchains traditionnelles, il ne garantit pas la validité des calculs par réexécution, mais par la génération de preuves assurant la vérifiabilité des calculs. Grâce à sa conception sans ledger et à des nœuds spécialisés, le réseau zkOracle (comme Hyper Oracle) peut se concentrer sur un calcul haute performance et à confiance minimale. Les résultats des calculs sont directement transmis au réseau de consensus, sans créer de nouveau consensus.
Dans le réseau de calcul zkOracle, chaque unité de calcul ou fichier exécutable est représenté par un zkGraph. Ces zkGraph définissent le comportement de calcul et de génération de preuve, tout comme les contrats intelligents définissent le calcul dans un réseau de consensus.
I. Calcul hors chaîne généraliste
Les programmes zkGraph dans le calcul zkOracle peuvent être utilisés sans pile externe pour deux cas d’usage principaux :
-
Indexation (accès aux données blockchain) ;
-
Automatisation (appels automatisés de contrats intelligents) ;
-
Tout autre calcul hors chaîne.
Ces deux cas couvrent les besoins en middleware et infrastructure de tout développeur de contrat intelligent. Cela signifie que, en tant que développeur du superordinateur mondial, vous pouvez vivre un processus de développement entièrement décentralisé de bout en bout, incluant à la fois les contrats intelligents sur chaîne dans le réseau de consensus et les calculs hors chaîne dans le réseau de calcul.
II. Calcul ML / IA
Pour permettre une adoption à l’échelle d’Internet et supporter tous types d’applications, le superordinateur mondial doit prendre en charge le calcul de machine learning de manière décentralisée.
Grâce aux technologies de preuve à connaissance nulle, le machine learning et l’intelligence artificielle peuvent être intégrés au superordinateur mondial et vérifiés sur le réseau de consensus d’Ethereum, permettant un véritable calcul sur chaîne.
Dans ce scénario, les zkGraph peuvent se connecter à des piles technologiques externes, intégrant ainsi le zkML directement au réseau de calcul du superordinateur mondial. Cela rend possible tous les types d’applications zkML :
-
ML / IA avec protection de la vie privée utilisateur ;
-
ML / IA avec protection de la vie privée du modèle ;
-
ML / IA avec validité de calcul.
Pour doter le superordinateur mondial de capacités de calcul ML et IA, les zkGraph seront intégrés aux technologies avancées suivantes de zkML, assurant leur intégration directe avec le réseau de consensus et le réseau de stockage.
-
EZKL : exécute des inférences de modèles de deep learning et d’autres graphes de calcul dans des zk-snarks.
-
Remainder : opérations rapides de machine learning dans le prover Halo2.
-
circomlib-ml : bibliothèque de circuits circom pour le machine learning.
e) Le ZK comme bus de données
Maintenant que nous disposons de tous les composants fondamentaux du superordinateur mondial, il nous faut un dernier élément pour les relier : un bus vérifiable et à confiance minimale, permettant la communication et la coordination entre les composants.
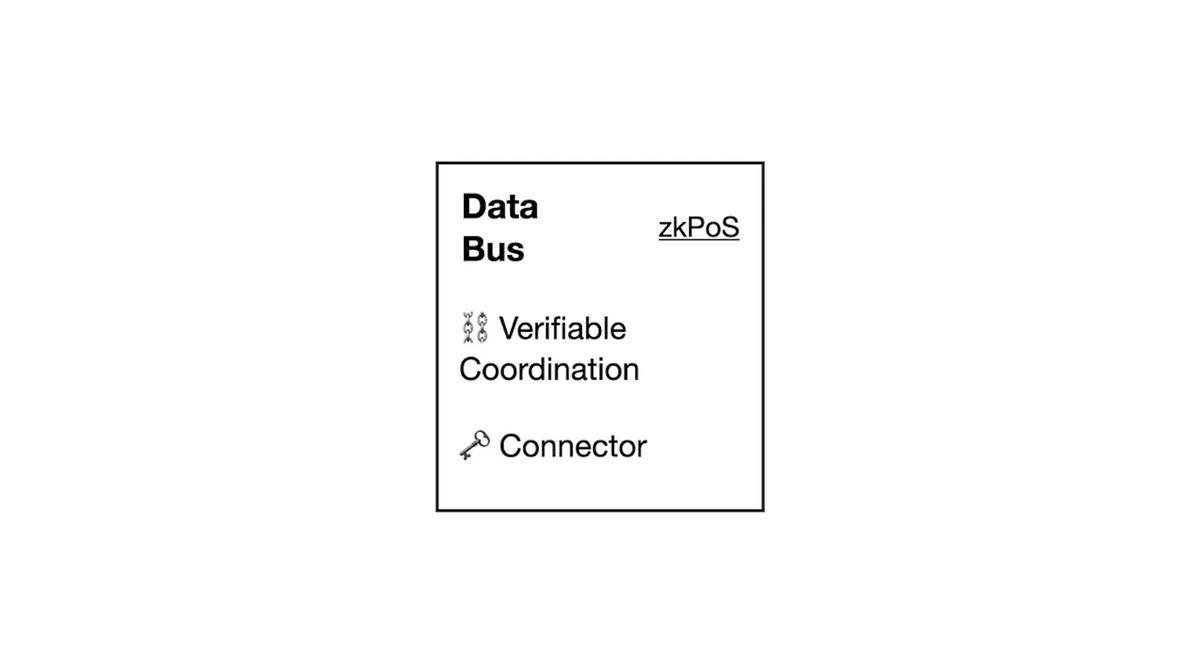
Pour un superordinateur mondial utilisant Ethereum comme réseau de consensus, zkPoS d’Hyper Oracle est un candidat idéal pour le bus ZK. zkPoS est un composant clé de zkOracle, qui valide le consensus d’Ethereum via ZK, permettant ainsi au consensus d’Ethereum d’être propagé et vérifié dans n’importe quel environnement.
En tant que bus décentralisé et à confiance minimale, zkPoS peut connecter tous les composants du superordinateur mondial via ZK, avec presque aucun coût de vérification computationnel. Dès lors qu’un tel bus existe, les données peuvent circuler librement au sein du superordinateur mondial.
Lorsque le consensus d’Ethereum peut être transféré depuis la couche de consensus vers le bus comme donnée initiale de consensus pour le superordinateur mondial, zkPoS peut le prouver via des preuves d’état, d’événements ou de transactions. Les données générées peuvent alors être transmises au réseau de calcul zkOracle.
De plus, concernant le bus du réseau de stockage, EthStorage développe zkNoSQL pour fournir des preuves de disponibilité des données, permettant aux autres réseaux de vérifier rapidement si les BLOB disposent de suffisamment de répliques.
f) Un autre cas : Bitcoin comme réseau de consensus
Comme de nombreux rollups souverains de niveau 2, des réseaux décentralisés comme Bitcoin peuvent également servir de réseau de consensus pour un superordinateur mondial.
Pour supporter un tel superordinateur mondial, nous devons remplacer le bus zkPoS, car Bitcoin est un réseau blockchain basé sur le mécanisme PoW.
Nous pouvons utiliser ZeroSync pour implémenter le ZK comme bus d’un superordinateur mondial basé sur Bitcoin. ZeroSync est similaire à un « zkPoW », synchronisant le consensus de Bitcoin via des preuves à connaissance nulle, permettant à tout environnement de calcul de vérifier et d’obtenir l’état le plus récent de Bitcoin en quelques millisecondes.
g) Flux de travail
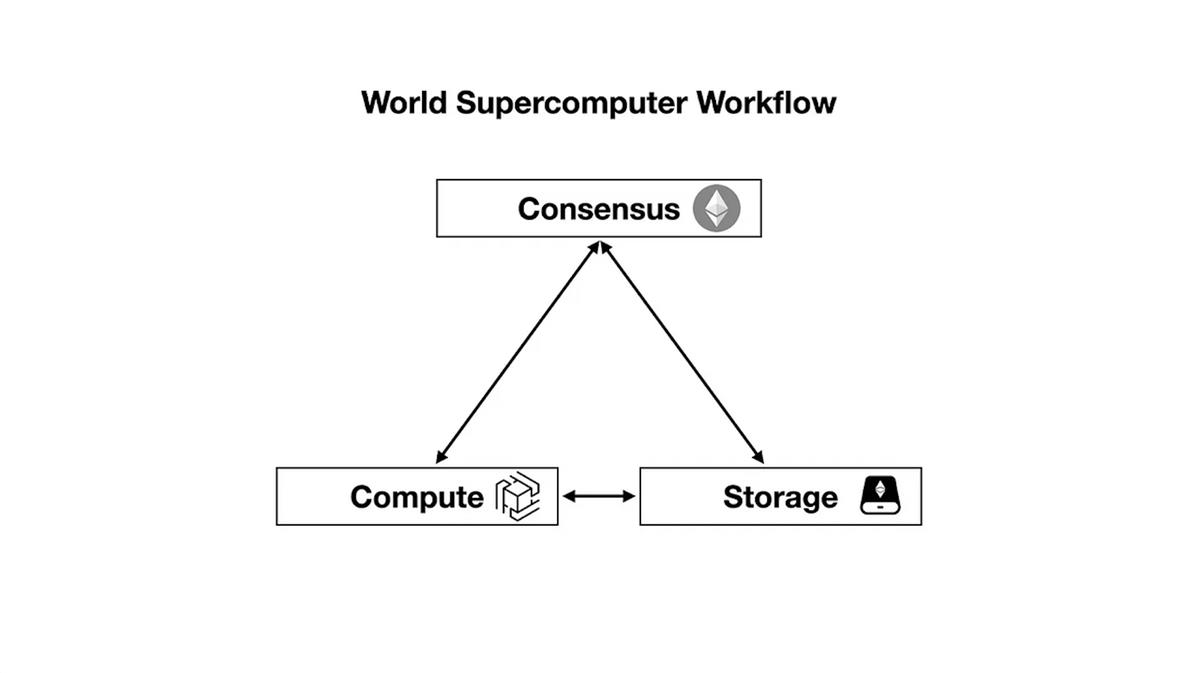
Voici un aperçu du processus transactionnel d’un superordinateur mondial basé sur Ethereum, divisé en plusieurs étapes :
-
Consensus : utilisation d’Ethereum pour traiter et parvenir à un consensus sur la transaction.
-
Calcul : le réseau zkOracle exécute les calculs hors chaîne correspondants (définis par des zkGraph chargés depuis EthStorage), en validant rapidement les preuves et les données de consensus transmises par le bus zkPoS.
-
Consensus : dans certains cas, comme l’automatisation ou le machine learning, le réseau de calcul renvoie des données et des transactions à Ethereum ou à EthStorage via des preuves.
-
Stockage : pour stocker de grandes quantités de données depuis Ethereum (par exemple, les métadonnées de NFT), zkPoS agit comme messager entre le contrat intelligent Ethereum et EthStorage.
Durant tout ce processus, le bus joue un rôle crucial dans la connexion de chaque étape :
-
Lorsque les données de consensus passent d’Ethereum au calcul de zkOracle ou au stockage d’EthStorage, zkPoS et les preuves d’état/événement/transaction génèrent des preuves que le destinataire peut rapidement vérifier pour obtenir les données exactes, par exemple la transaction correspondante.
-
Quand zkOracle a besoin de charger des données depuis le stockage pour calculer, il utilise zkPoS pour accéder à l’adresse des données depuis le réseau de consensus, puis zkNoSQL pour récupérer les données réelles depuis le stockage.
-
Lorsque les données provenant de zkOracle ou d’Ethereum doivent être affichées sous forme finale, zkPoS génère des preuves pour le client (par exemple un navigateur) afin qu’il puisse les vérifier rapidement.
Conclusion
Bitcoin a jeté des bases solides pour créer l’ordinateur mondial v0, réussissant à construire un « grand livre mondial ». Ensuite, Ethereum a efficacement démontré le paradigme de l’« ordinateur mondial » grâce à un mécanisme de contrats intelligents plus programmable. Pour atteindre la décentralisation, exploiter la confiance intrinsèque de la cryptographie, l’incitation économique naturelle du MEV, favoriser une adoption massive, tirer parti du potentiel des technologies ZK, et répondre à la demande croissante de calcul généraliste décentralisé incluant le machine learning, l’émergence du superordinateur mondial est devenue inévitable.
Notre solution proposée consiste à construire un superordinateur mondial en reliant des réseaux pair-à-pair topologiquement hétérogènes via des preuves à connaissance nulle. En tant que ledger de consensus, Ethereum fournira le consensus de base et utilisera les intervalles de blocs comme cycle d’horloge pour l’ensemble du système. En tant que réseau de stockage, le storage rollup stockera de grandes quantités de données et offrira une norme URI pour y accéder. En tant que réseau de calcul, le réseau zkOracle exécutera des calculs intensifs et générera des preuves vérifiables. En tant que bus de données, les technologies à connaissance nulle relieront tous les composants, permettant la liaison et la vérification des données et du consensus.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














