

LLM trao quyền cho blockchain, mở ra kỷ nguyên mới cho trải nghiệm trên chuỗi
Tuyển chọn TechFlowTuyển chọn TechFlow
LLM trao quyền cho blockchain, mở ra kỷ nguyên mới cho trải nghiệm trên chuỗi
Ưu điểm của LLM bao gồm khả năng hiểu lượng dữ liệu lớn, thực hiện nhiều nhiệm vụ liên quan đến ngôn ngữ và tiềm năng tùy chỉnh kết quả theo nhu cầu người dùng.
Tác giả: Yiping, IOSG Ventures
Viết trước
-
Khi mô hình ngôn ngữ lớn (LLM) ngày càng phát triển mạnh mẽ, chúng ta đang chứng kiến nhiều dự án tích hợp trí tuệ nhân tạo (AI) với blockchain. Việc kết hợp AI và blockchain ngày càng phổ biến, và chúng tôi cũng nhận thấy cơ hội tái kết nối giữa AI và blockchain. Một trong những điểm đáng chú ý nhất chính là ZKML (Zero-Knowledge Machine Learning - Học máy bằng chứng không kiến thức).
-
AI và blockchain là hai công nghệ đột phá mang những đặc điểm khác biệt về bản chất. AI đòi hỏi năng lực tính toán mạnh mẽ, thường được cung cấp bởi các trung tâm dữ liệu tập trung. Trong khi đó, blockchain cung cấp khả năng tính toán phi tập trung và bảo vệ quyền riêng tư, nhưng lại không hiệu quả trong các nhiệm vụ tính toán và lưu trữ quy mô lớn. Chúng ta vẫn đang khám phá và nghiên cứu các phương pháp tốt nhất để tích hợp AI và blockchain, sau này sẽ giới thiệu tới mọi người một số ví dụ thực tiễn hiện tại về sự kết hợp "AI + Blockchain".
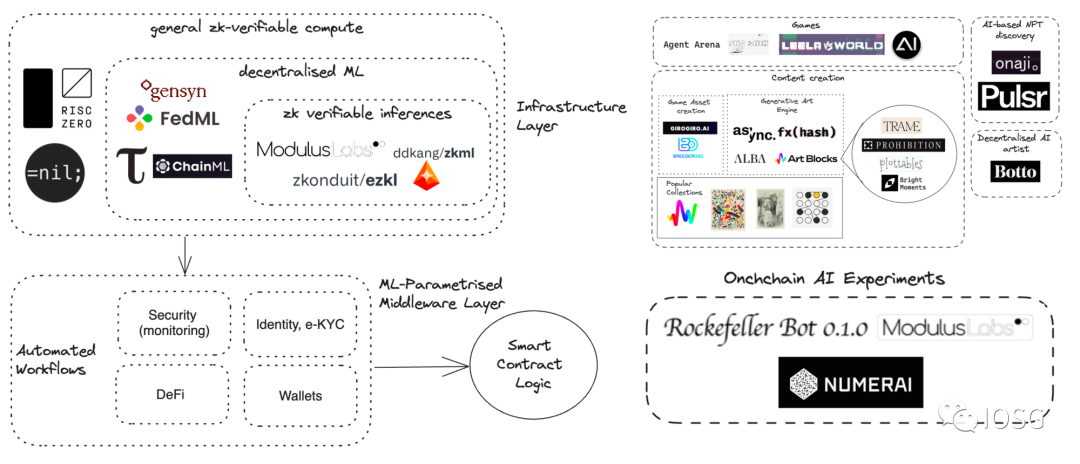
Nguồn: IOSG Ventures
Báo cáo nghiên cứu này được chia thành hai phần, bài viết này là phần đầu tiên, trong đó chúng tôi sẽ tập trung vào ứng dụng của LLM trong lĩnh vực mã hóa và thảo luận về các chiến lược triển khai.
LLM là gì?
LLM (mô hình ngôn ngữ lớn) là một mô hình ngôn ngữ do máy tính hóa, gồm một mạng nơ-ron nhân tạo có số lượng tham số rất lớn (thường là hàng tỷ). Những mô hình này được huấn luyện trên lượng lớn văn bản chưa được gắn nhãn.
Vào khoảng năm 2018, sự ra đời của LLM đã hoàn toàn thay đổi nghiên cứu xử lý ngôn ngữ tự nhiên. Khác với cách tiếp cận trước đây là phải huấn luyện các mô hình giám sát riêng cho từng tác vụ cụ thể, LLM hoạt động như một mô hình tổng quát, thể hiện hiệu suất xuất sắc trên nhiều loại nhiệm vụ khác nhau. Các khả năng và ứng dụng của nó bao gồm:
-
Hiểu và tóm tắt văn bản: LLM có thể hiểu và tóm tắt khối lượng lớn dữ liệu ngôn ngữ và văn bản của con người. Chúng có thể trích xuất thông tin chính và tạo ra bản tóm tắt ngắn gọn.
-
Tạo nội dung mới: LLM có khả năng tạo nội dung dựa trên văn bản. Bằng cách cung cấp prompt cho mô hình, nó có thể trả lời câu hỏi, tạo văn bản mới, bản tóm tắt hoặc phân tích cảm xúc.
-
Dịch thuật: LLM có thể dùng để dịch giữa các ngôn ngữ khác nhau. Chúng sử dụng các thuật toán học sâu và mạng nơ-ron để hiểu ngữ cảnh và mối quan hệ giữa từ vựng.
-
Dự đoán và tạo văn bản: LLM có thể dự đoán và tạo văn bản dựa trên ngữ cảnh, tương tự như nội dung do con người tạo ra, bao gồm bài hát, thơ, truyện, tài liệu marketing, v.v.
-
Ứng dụng trong các lĩnh vực khác nhau: Mô hình ngôn ngữ lớn có tính ứng dụng rộng rãi trong các nhiệm vụ xử lý ngôn ngữ tự nhiên. Chúng được sử dụng trong AI đối thoại, chatbot, chăm sóc sức khỏe, phát triển phần mềm, công cụ tìm kiếm, gia sư, công cụ viết lách và nhiều lĩnh vực khác.
Ưu điểm của LLM bao gồm khả năng hiểu lượng dữ liệu khổng lồ, thực hiện nhiều tác vụ liên quan đến ngôn ngữ và tiềm năng tùy chỉnh kết quả theo nhu cầu người dùng.
Các ứng dụng phổ biến của mô hình ngôn ngữ lớn
Do khả năng vượt trội trong việc hiểu ngôn ngữ tự nhiên, LLM sở hữu tiềm năng to lớn, và các nhà phát triển chủ yếu tập trung vào hai khía cạnh sau:
-
Cung cấp câu trả lời chính xác và cập nhật nhất cho người dùng dựa trên lượng lớn dữ liệu ngữ cảnh và nội dung
-
Hoàn thành các nhiệm vụ cụ thể do người dùng giao phó bằng cách sử dụng các tác nhân và công cụ khác nhau
Chính hai khía cạnh này đã khiến các ứng dụng LLM trò chuyện với XX bùng nổ như nấm mọc sau mưa. Ví dụ: trò chuyện với PDF, trò chuyện với tài liệu, trò chuyện với bài báo khoa học.
Sau đó, người ta bắt đầu thử nghiệm tích hợp LLM với các nguồn dữ liệu khác nhau. Các nhà phát triển đã thành công trong việc tích hợp các nền tảng như GitHub, Notion và một số phần mềm ghi chú với LLM.
Để khắc phục những hạn chế vốn có của LLM, các công cụ khác nhau đã được đưa vào hệ thống. Công cụ đầu tiên như vậy là công cụ tìm kiếm, giúp LLM truy cập tri thức cập nhật nhất. Những bước tiến xa hơn sẽ tích hợp các công cụ như WolframAlpha, Google Suites và Etherscan với mô hình ngôn ngữ lớn.
Kiến trúc của ứng dụng LLM
Hình dưới đây phác họa quy trình làm việc của ứng dụng LLM khi phản hồi truy vấn của người dùng: Trước tiên, các nguồn dữ liệu liên quan được chuyển đổi thành vector nhúng và lưu trữ trong cơ sở dữ liệu vector. Bộ điều hợp LLM sử dụng truy vấn của người dùng và tìm kiếm tương tự để lấy ngữ cảnh liên quan từ cơ sở dữ liệu vector. Ngữ cảnh liên quan này được đưa vào prompt và gửi đến LLM. LLM sẽ thực thi các prompt này và sử dụng các công cụ để tạo ra câu trả lời. Đôi khi, LLM cũng được tinh chỉnh trên bộ dữ liệu cụ thể để tăng độ chính xác và giảm chi phí.
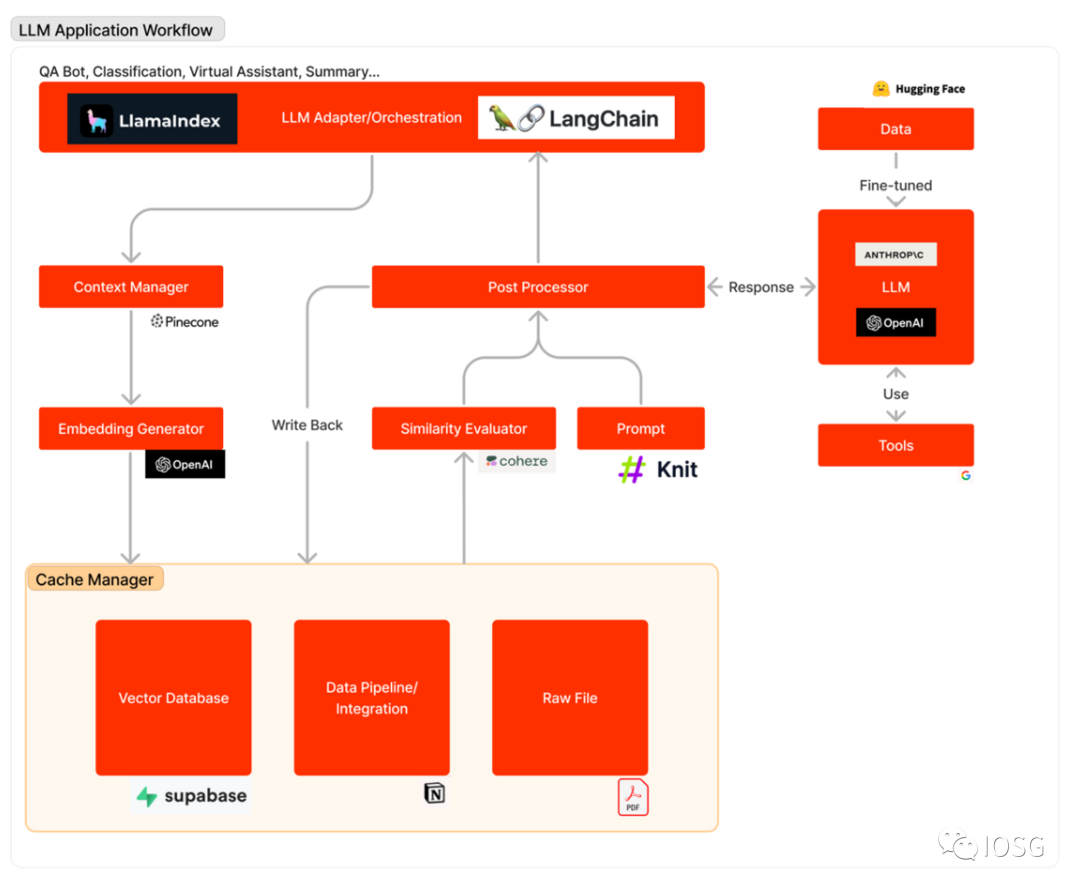
Quy trình làm việc của ứng dụng LLM có thể được chia thành ba giai đoạn chính:
-
Chuẩn bị dữ liệu và nhúng (embedding): Giai đoạn này liên quan đến việc lưu giữ thông tin mật (ví dụ như bản ghi nhớ dự án) để truy cập sau này. Thông thường, các tài liệu sẽ được chia nhỏ và xử lý qua mô hình nhúng, sau đó lưu vào một loại cơ sở dữ liệu đặc biệt gọi là cơ sở dữ liệu vector.
-
Xây dựng (Formulation) và trích xuất (Extraction) prompt: Khi người dùng gửi yêu cầu tìm kiếm (trong ví dụ này là tìm kiếm thông tin dự án), phần mềm sẽ tạo một loạt prompt để đưa vào mô hình ngôn ngữ. Prompt cuối cùng thường chứa mẫu hướng dẫn được lập trình cứng bởi nhà phát triển, các ví dụ đầu ra hiệu quả dạng few-shot, cũng như bất kỳ dữ liệu cần thiết nào lấy từ API bên ngoài và các tài liệu liên quan trích xuất từ cơ sở dữ liệu vector.
-
Thực thi prompt và suy luận: Sau khi hoàn thiện prompt, chúng được cung cấp cho mô hình ngôn ngữ đã tồn tại để thực hiện suy luận, có thể bao gồm API mô hình riêng quyền, mô hình mã nguồn mở hoặc mô hình đã được tinh chỉnh riêng. Ở giai đoạn này, một số nhà phát triển cũng có thể tích hợp các chức năng vận hành hệ thống (như ghi log, cache và xác thực) vào hệ thống.
Đưa LLM vào lĩnh vực mã hóa
Mặc dù lĩnh vực mã hóa (Web3) có một số ứng dụng tương tự Web2, nhưng việc phát triển các ứng dụng LLM xuất sắc trong lĩnh vực mã hóa đòi hỏi sự thận trọng đặc biệt.
Hệ sinh thái mã hóa mang tính độc đáo, với văn hóa, dữ liệu và tính tích hợp đặc trưng riêng. Các LLM được tinh chỉnh trên các tập dữ liệu giới hạn trong mã hóa có thể cung cấp kết quả vượt trội với chi phí tương đối thấp. Dù dữ liệu dồi dào, nhưng rõ ràng thiếu các tập dữ liệu mở trên các nền tảng như HuggingFace. Hiện tại, chỉ có một tập dữ liệu liên quan đến hợp đồng thông minh, chứa 113.000 hợp đồng thông minh.
Các nhà phát triển còn đối mặt với thách thức tích hợp các công cụ khác nhau vào LLM. Những công cụ này khác với các công cụ dùng trong Web2; chúng trang bị cho LLM khả năng truy cập dữ liệu liên quan đến giao dịch, tương tác với các ứng dụng phi tập trung (DApp) và thực hiện giao dịch. Cho đến nay, chúng tôi chưa tìm thấy bất kỳ tích hợp DApp nào trong Langchain.
Mặc dù phát triển các ứng dụng LLM chất lượng cao trong lĩnh vực mã hóa có thể đòi hỏi thêm nỗ lực, nhưng LLM vốn dĩ rất phù hợp với lĩnh vực này. Lĩnh vực này cung cấp lượng lớn dữ liệu phong phú, sạch và có cấu trúc. Thêm vào đó, mã Solidity thường ngắn gọn và rõ ràng, giúp LLM dễ dàng hơn trong việc tạo mã chức năng.
Trong phần "Phần sau", chúng tôi sẽ thảo luận về 8 hướng tiềm năng mà LLM có thể hỗ trợ lĩnh vực blockchain, ví dụ như:
-
Tích hợp chức năng AI/LLM vào blockchain
-
Sử dụng LLM để phân tích lịch sử giao dịch
-
Sử dụng LLM để nhận diện robot tiềm năng
-
Sử dụng LLM để viết mã
-
Sử dụng LLM để đọc mã
-
Sử dụng LLM để hỗ trợ cộng đồng
-
Sử dụng LLM để theo dõi thị trường
-
Sử dụng LLM để phân tích dự án
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News














