

a16z 1만 자 장문: AI의 다음 최전선은 언어가 아닌 물리 세계에 있다—로봇, 자율 과학, 뇌-기계 인터페이스의 삼중 비틀림
저자: Oliver Hsu(a16z)
번역 및 편집: TechFlow
TechFlow 리더스 다이제스트: 본 기사는 a16z 연구원 Oliver Hsu가 작성한 글로, 2026년 이후 가장 체계적인 ‘물리 인공지능(Physical AI)’ 투자 지도이다. 저자의 판단에 따르면, 언어/코드를 축으로 한 주류 경로는 여전히 확장(scaling) 중이지만, 진정한 차세대 파괴적 역량을 창출할 수 있는 분야는 이 주류 경로와 인접한 세 영역이다—즉, 범용 로봇, 자율 과학(AI 과학자), 뇌-기계 인터페이스(BMI) 등 새로운 형태의 인간-기계 인터페이스이다. 저자는 이를 뒷받침하는 다섯 가지 근간 역량을 분석하고, 이 세 전선이 서로를 강화하는 구조적 피드백 고리(structural flywheel)를 형성함을 입증한다. 물리 인공지능 투자 논리를 명확히 이해하려는 독자에게, 이는 현재까지 가장 완전한 프레임워크이다.
오늘날 인공지능을 주도하는 패러다임은 언어와 코드를 중심으로 조직된다. 대규모 언어 모델(LLM)의 스케일링 법칙은 이미 명확히 규명되었고, 데이터·연산력·알고리즘 개선이라는 상업적 피드백 고리가 가동 중이며, 능력 향상 단계마다 얻는 수익은 여전히 크고 대부분 가시적이다. 이 패러다임은 자신이 흡수한 자본과 주목도에 걸맞은 성과를 내고 있다.
그러나 이 주류 패러다임과 인접한 또 다른 분야들에서는 이미 실질적인 진전이 이루어지고 있다. 여기에는 VLA(비전-언어-행동 모델), WAM(월드 액션 모델) 등 범용 로봇 기술, ‘AI 과학자’ 개념을 중심으로 한 물리 및 과학 추론, 그리고 AI 발전을 바탕으로 인간-기계 상호작용을 재구성하는 새로운 인터페이스(뇌-기계 인터페이스 및 신경기술 포함)가 포함된다. 기술 자체뿐 아니라, 이러한 분야들은 이미 인재, 자본, 창업가들을 끌어들이기 시작했다. 최첨단 인공지능을 물리 세계로 확장하기 위한 기술 원시어(primitive)들이 동시에 성숙해가고 있으며, 지난 18개월간의 진전은 이 분야들이 각각의 스케일링 단계에 빠르게 진입할 것임을 시사한다.
어떤 기술 패러다임에서든, 현재 역량과 중기 잠재력 사이의 격차(delta)가 가장 큰 영역은 일반적으로 두 가지 특징을 갖는다. 첫째, 현재 최첨단 기술을 이끄는 동일한 스케일링 혜택을 누릴 수 있어야 하며, 둘째, 주류 패러다임에서 ‘한 발짝 떨어져 있어야 한다’—즉, 그 인프라와 연구 에너지를 계승할 만큼 가까우면서도, 실질적인 추가 작업이 반드시 요구되는 정도로 충분히 멀어야 한다. 이 거리 자체는 이중의 역할을 한다. 즉, 후발 주자들에게 자연스럽게 진입 장벽을 형성하며, 동시에 정보가 희소하고 경쟁이 덜 치열한 문제 공간을 정의함으로써, 오히려 새로운 역량이 등장할 가능성을 높인다—왜냐하면 아직 누구도 ‘쉬운 길’을 걷지 않았기 때문이다.

그림 설명: 현재 인공지능 패러다임(언어/코드)과 인접한 선도적 시스템 간 관계 개요
현재 이 설명에 부합하는 세 분야가 있다: 로봇 학습, 자율 과학(특히 재료과학 및 생명과학 분야), 그리고 새로운 형태의 인간-기계 인터페이스(뇌-기계 인터페이스, 무음 음성, 신경 착용형 기기, 디지털 후각 등 새로운 감각 채널 포함). 이들은 완전히 독립된 연구가 아니며, 주제적으로 동일한 ‘물리 세계의 선도적 시스템’ 집단에 속한다. 이들은 공통의 근간 원시어를 공유한다: 물리 역학의 학습 표현, 구체화된 행동(embodied action)을 위한 아키텍처, 시뮬레이션 및 합성 데이터 인프라, 지속적으로 확장되는 감각 채널, 그리고 폐쇄 루프(closed-loop) 에이전트 오케스트레이션. 이들은 교차 분야 피드백 관계를 통해 서로를 강화한다. 또한 이곳이 질적 도약(qualitative leap) 역량이 가장 가능성이 높은 영역이다—모델 규모, 물리적 실현, 새로운 형태의 데이터라는 세 요소가 상호 작용하는 결과이다.
본 고에서는 이러한 시스템을 뒷받침하는 기술 원시어를 정리하고, 왜 이 세 분야가 선도적 기회를 대표하는지를 설명하며, 이들 간의 상호 강화 관계가 물리 세계로의 인공지능 확장을 이끄는 구조적 피드백 고리(structural flywheel)를 구성함을 제시한다.
다섯 가지 근간 원시어
구체적인 응용 분야를 살펴보기 전에, 먼저 이 선도적 시스템들이 공유하는 기술 기반을 이해해야 한다. 최첨단 인공지능을 물리 세계로 확장시키는 것은 다섯 가지 주요 원시어에 의존한다. 이 기술들은 어느 특정 응용 분야에만 국한되지 않으며, ‘인공지능을 물리 세계로 확장’하는 시스템을 구성할 수 있게 해주는 구성 요소이다. 이 원시어들의 동시 성숙이 바로 지금 이 순간을 특별하게 만드는 이유이다.

그림 설명: 물리 인공지능을 뒷받침하는 다섯 가지 근간 원시어
원시어 1: 물리 역학의 학습 표현
가장 근본적인 원시어는, 물체의 움직임, 변형, 충돌, 힘에 대한 반응 방식 등 물리 세계의 행동을 압축적이고 보편적으로 표현하는 것을 학습하는 능력이다. 이 계층이 없으면, 각 물리 인공지능 시스템은 자기 분야의 물리 법칙을 처음부터 다시 배워야 하며, 그 비용은 아무도 감당할 수 없다.
여러 아키텍처 흐름이 서로 다른 방향에서 이 목표에 접근하고 있다. VLA 모델은 상위 계층에서 접근한다: 사전 훈련된 비전-언어 모델(VLM)—이는 이미 물체, 공간 관계, 언어 의미를 이해하는 능력을 갖춘 모델—에 동작 디코더를 추가하여 운동 제어 명령을 출력한다. 핵심은 ‘보기’와 ‘세상을 이해하기’를 학습하는 막대한 비용이 인터넷 규모의 이미지-텍스트 사전 훈련을 통해 분산될 수 있다는 점이다. Physical Intelligence의 π₀, Google DeepMind의 Gemini Robotics, 엔비디아의 GR00T N1은 모두 점점 더 큰 규모에서 이러한 아키텍처의 타당성을 검증하고 있다.
WAM 모델은 하위 계층에서 접근한다: 인터넷 규모의 동영상에서 사전 훈련된 비디오 확산 트랜스포머(video diffusion Transformer)를 기반으로 하여, 물리 역학에 대한 풍부한 사전 지식(물체가 어떻게 떨어지는지, 어떻게 가려지는지, 힘을 받았을 때 어떻게 상호작용하는지 등)을 계승한 다음, 이를 동작 생성과 결합한다. 엔비디아의 DreamZero는 완전히 새로운 과제와 환경에 대한 제로샷 일반화(zero-shot generalization)를 보여주었으며, 소량의 적응 데이터만으로 인간의 동영상 시범을 기반으로 본체 간 이식(cross-body transfer)을 수행할 수 있고, 실제 세계 일반화 능력이 유의미하게 향상되었다.
세 번째 경로는 미래 방향성을 판단하는 데 가장 통찰력을 줄 수 있는데, 이는 사전 훈련된 VLM과 비디오 확산 백본 전체를 건너뛰는 것이다. Generalist의 GEN-1은 실제 물리적 상호작용 데이터 50만 시간 이상을 사용해 처음부터 훈련된 원생 구체화 기초 모델(native embodied foundation model)이다. 이 데이터는 주로 저비용 착용형 기기를 통해 일상 작업을 수행하는 사람으로부터 수집된다. 이 모델은 표준적인 VLA(마이크로튜닝되는 비전-언어 백본이 없음)도 아니고, WAM도 아니다. 이는 물리적 상호작용을 위해 특별히 설계된 기초 모델로서, 인터넷 이미지, 텍스트 또는 동영상의 통계적 규칙이 아니라, 인간과 물체 간 접촉의 통계적 규칙을 처음부터 학습한다.
World Labs와 같은 기업이 추진하는 공간 지능(spatial intelligence)은 이 원시어에 가치를 더한다. 왜냐하면 이는 VLA, WAM, 원생 구체화 모델이 공통으로 겪는 한계—즉, 모두가 존재하는 환경의 3차원 구조를 명시적으로 모델링하지 못한다는 점—를 보완하기 때문이다. VLA는 이미지-텍스트 사전 훈련에서 유래한 2D 시각 특징을 계승한다. WAM은 동영상을 통해 역학을 학습하는데, 동영상 자체는 3D 세계의 2D 투영이다. 착용형 센서 데이터를 기반으로 학습하는 모델은 힘과 운동학을 포착할 수 있지만, 장면의 기하학적 구조는 포착하지 못한다. 공간 지능 모델은 이 공백을 메우는 데 도움을 준다—즉, 물리적 환경의 완전한 3D 구조를 재구성하고 생성하며, 이를 기반으로 기하학, 조명, 가림, 물체 간 관계, 공간 배치 등을 추론하는 능력을 갖춘다.
각 경로의 수렴 자체가 핵심이다. 표현이 VLM에서 계승되든, 동영상 공동 훈련에서 학습되든, 혹은 원생 물리적 상호작용 데이터에서 직접 구축되든, 근간 원시어는 동일하다: 압축적이며 이식 가능한 물리 세계 행동 모델이다. 이러한 표현이 활용할 수 있는 데이터 피드백 고리는 매우 방대하며, 대부분 아직 미활용 상태이다—인터넷 동영상 및 로봇 궤적뿐 아니라, 착용형 기기가 이제 막 대규모로 수집하기 시작한 방대한 인간 신체 경험 코퍼스도 포함된다. 동일한 표현은 수건을 접는 로봇을 위한 것이 될 수도 있고, 반응 결과를 예측하는 자율 실험실을 위한 것이 될 수도 있으며, 운동 피질의 쥐기 의도를 해독하는 신경 해독기(neural decoder)를 위한 것이 될 수도 있다.
원시어 2: 구체화된 행동을 위한 아키텍처
물리적 표현만으로는 부족하다. ‘이해’를 신뢰할 수 있는 물리적 행동으로 번역하기 위해서는, 상위 수준의 의도를 연속적인 운동 명령으로 매핑하고, 긴 동작 시퀀스에서 일관성을 유지하며, 실시간 지연 제약 조건 하에서 실행하고, 경험에 따라 지속적으로 향상시키는 등 여러 관련된 문제를 해결하는 아키텍처가 필요하다.
복잡한 구체화 작업을 위한 이중 시스템 계층형 아키텍처(dual-system hierarchical architecture)가 표준 설계가 되었다: 느리지만 강력한 비전-언어 모델이 장면 이해 및 과제 추론(System 2)을 담당하고, 빠르고 경량화된 비전-운동 전략이 실시간 제어(System 1)를 담당한다. GR00T N1, Gemini Robotics, Figure의 Helix는 모두 이 경로의 변형을 채택하여, ‘대규모 모델이 풍부한 추론을 제공한다’는 점과 ‘물리적 과제가 밀리초 단위 제어 주파수를 요구한다’는 점 사이의 근본적인 긴장을 해결하였다. Generalist는 ‘공진 추론(resonant reasoning)’을 통해 사고와 행동을 동시에 발생시키는 또 다른 경로를 선택하였다.
동작 생성 메커니즘 자체도 빠르게 진화하고 있다. π₀가 개척한 흐름 매칭(flow matching) 및 확산 기반의 동작 헤드는 부드럽고 고주파 연속 동작을 생성하는 주류 방법이 되었으며, 언어 모델링에서 차용한 이산 토큰화(discrete tokenization)를 대체하였다. 이러한 방법은 동작 생성을 이미지 합성과 유사한 노이즈 제거 과정으로 간주하여, 산출된 궤적은 물리적으로 더 부드럽고 오차 누적에 대해 더 강인하며, 오토리그레시브 토큰 예측보다 우수하다.
그러나 아키텍처 차원에서 가장 중요한 진전은 강화 학습(RL)을 사전 훈련된 VLA에 확장하는 것이다—즉, 시범 데이터에서 훈련된 기초 모델이 자율적인 연습을 통해 계속해서 향상될 수 있도록 하는 것인데, 이는 사람이 반복적인 연습과 자기 수정을 통해 기술을 다듬는 것과 유사하다. Physical Intelligence의 π*₀.₆ 연구는 이 원칙을 가장 명확하게 대규모로 시연한 사례이다. 그들의 방법은 RECAP(우세성 기반 조건 정책의 경험 및 수정 강화 학습, Reinforcement learning with Experience and Correction based on Advantage-conditioned Policies)이라 불리며, 순수한 모방 학습(imitation learning)으로는 해결할 수 없는 긴 시퀀스 신용 할당(long-sequence credit assignment) 문제를 해결한다. 로봇이 이탈리아식 커피 머신의 손잡이를 약간 기울어진 각도로 잡았을 경우, 실패는 즉각 나타나지 않고 몇 단계 후에 삽입 시점에서야 드러날 수 있다. 모방 학습은 이번 실패를 훨씬 이전의 잡기 동작으로 귀인시키는 메커니즘이 없지만, 강화 학습은 이를 가능하게 한다. RECAP는 임의의 중간 상태에서 성공 확률을 추정하는 가치 함수(value function)를 훈련하고, VLA가 높은 우세성(advantage)을 갖는 동작을 선택하도록 한다. 핵심은 시범 데이터, 온폴리시(on-policy) 자율 경험, 실행 중 전문가가 원격 조작으로 제공한 수정 데이터 등 다양한 이질적 데이터를 하나의 훈련 파이프라인에 통합한다는 점이다.
이 방법의 결과는 강화 학습이 동작 분야에서의 전망에 대해 낙관적인 신호를 준다. π*₀.₆는 실제 가정 환경에서 50종류의 처음 보는 의류를 접는 작업, 종이 상자를 신뢰성 있게 조립하는 작업, 전문 기기에서 이탈리아식 커피를 제조하는 작업을 수 시간 동안 인간의 개입 없이 연속적으로 수행하였다. 가장 어려운 과제에서, RECAP은 순수 모방 기준선 대비 처리량을 두 배 이상 증가시키고, 실패율을 절반 이하로 감소시켰다. 이 시스템은 또한 RL 사후 훈련(post-training)이 모방 학습으로는 얻을 수 없는 질적 도약 행동을 창출함을 입증하였다: 더 부드러운 복구 동작, 더 효율적인 쥐기 전략, 시범 데이터에 전혀 존재하지 않는 적응적 오류 수정 등이다.
이러한 수익이 시사하는 바는 다음과 같다: GPT-2에서 GPT-4로의 대규모 언어 모델 확장을 이끈 연산력 스케일링 동력이, 이제 구체화된 분야에서도 작동하기 시작하고 있다는 것이다—단지 이는 곡선상 더 초기 단계에 위치해 있을 뿐이며, 동작 공간은 연속적이고 고차원적이며, 물리 세계의 냉혹한 제약 조건을 직면해야 한다는 점에서 다르다.
원시어 3: 스케일링 인프라로서의 시뮬레이션 및 합성 데이터
언어 분야에서는 인터넷이 데이터 문제를 해결하였다: 자연스럽게 생성되고 무료로 이용 가능한 수 조 토큰 규모의 텍스트 데이터. 그러나 물리 세계에서는 이 문제가 수 차례 더 어렵다—이 사실은 이제 공론화된 합의이며, 가장 직접적인 신호는 물리 세계를 위한 데이터 공급업체 스타트업이 급속도로 증가하고 있다는 점이다. 실제 로봇 궤적을 수집하는 비용은 높고, 대규모 확장에는 위험이 따르며, 다양성은 제한적이다. 언어 모델은 십억 차례의 대화에서 학습할 수 있지만, 로봇은(지금 당장은) 십억 차례의 물리적 상호작용을 할 수 없다.
시뮬레이션 및 합성 데이터 생성은 이러한 제약을 해결하는 인프라 계층이며, 이 인프라의 성숙은 물리 인공지능이 오늘날, 즉 5년 전이 아니라 가속화되는 주요 원인 중 하나이다.
현대 시뮬레이션 스택은 물리 기반 시뮬레이션 엔진, 광선 추적 기반의 사진급 렌더링, 절차적 환경 생성, 시뮬레이션 입력을 사용하여 사진급 동영상을 생성하는 월드 기초 모델(world foundation model)을 결합한다—후자는 시뮬레이션-현실(sim-to-real) 간 격차를 해소하는 역할을 한다. 전체 파이프라인은 실제 환경의 신경 재구성(스마트폰 한 대만으로도 가능)에서 시작하여, 물리적으로 정확한 3D 자산을 채우고, 자동 주석 처리된 대규모 합성 데이터 생성으로 이어진다.
시뮬레이션 스택의 개선은 물리 인공지능을 뒷받침하는 경제적 가정을 변화시키는 데 의미가 있다. 만약 물리 인공지능의 병목이 ‘실제 데이터 수집’에서 ‘다양한 가상 환경 설계’로 전환된다면, 비용 곡선은 급격히 하락할 것이다. 시뮬레이션은 연산력에 따라 확장되며, 인력이나 물리적 하드웨어에 의존하지 않는다. 이는 물리 인공지능 시스템 훈련의 경제 구조를 언어 모델 훈련에 대한 인터넷 텍스트 데이터의 변화와 동일한 방식으로 개혁하는 것이다—즉, 시뮬레이션 인프라에 대한 투자는 전체 생태계에 대해 매우 높은 레버리지 효과를 갖는다는 의미이다.
그러나 시뮬레이션은 단순히 로봇 원시어가 아니다. 동일한 인프라는 자율 과학(실험실 장비의 디지털 트윈, 가설 사전 선별을 위한 시뮬레이션 반응 환경), 새로운 인터페이스(BCI 해독기 훈련을 위한 시뮬레이션 신경 환경, 새로운 센서 교정을 위한 합성 감각 데이터) 및 기타 인공지능과 물리 세계 간 상호작용 분야에도 서비스된다. 시뮬레이션은 물리 세계 인공지능을 위한 범용 데이터 엔진이다.
원시어 4: 감각 채널의 확장
물리 세계가 전달하는 정보 신호는 시각과 언어보다 훨씬 풍부하다. 촉각은 카메라가 볼 수 없는 재료 속성, 쥐기 안정성, 접촉 기하학 등의 정보를 전달한다. 신경 신호는 기존의 어떤 인간-기계 인터페이스보다 훨씬 높은 대역폭으로 운동 의도, 인지 상태, 지각 경험을 인코딩한다. 아성대(subglottal) 근육 활동은 소리 생성 이전에 이미 언어 의도를 인코딩한다. 네 번째 원시어는, 이러한 기존에는 접근하기 어려웠던 감각 모달리티에 대한 인공지능의 빠른 확장이다—단순한 연구를 넘어서, 소비자용 기기, 소프트웨어 및 인프라를 구축하는 전체 생태계로부터 비롯된 것이다.
그림 설명: AR, EMG에서 뇌-기계 인터페이스까지 확장 중인 인공지능 감각 채널
가장 직관적인 지표는 신규 기기 범주의 등장이다. AR 기기는 최근 몇 년간 사용성과 형태 면에서 크게 개선되었으며(이 플랫폼에서 소비자 및 산업용 애플리케이션을 개발하는 기업이 이미 존재함), 음성 중심 인공지능 착용형 기기는 언어 기반 인공지능에 더 완전한 물리 세계 맥락을 제공한다—즉, 사용자가 실제로 물리적 환경으로 들어가는 것을 따라간다. 장기적으로는 신경 인터페이스가 더 완전한 상호작용 모달리티를 열 수 있다. 인공지능이 가져온 컴퓨팅 방식의 변화는 인간-기계 상호작용을 획기적으로 업그레이드할 기회를 창출하였으며, Sesame과 같은 기업이 이를 위해 새로운 모달리티와 기기를 개발하고 있다.
음성처럼 더 주류인 모달리티 역시 신규 상호작용 방식에 긍정적인 영향을 미친다. Wispr Flow와 같은 제품은 음성의 정보 밀도가 높고 천연적 이점이 있기 때문에 주요 입력 방식으로 음성을 채택함으로써, 무음 음성 인터페이스의 시장 조건도 함께 개선시킨다. 무음 음성 기기는 혀와 성대 움직임을 감지하는 여러 센서를 사용하여 소리를 내지 않고 언어를 인식한다—이는 음성보다 정보 밀도가 높은 인간-기계 상호작용 모달리티를 대표한다.
뇌-기계 인터페이스(침습식 및 비침습식)는 더 깊은 선도적 영역을 대표하며, 이에 대한 상업적 생태계는 지속적으로 진전되고 있다. 신호는 임상 검증, 규제 승인, 플랫폼 통합, 기관 자본이라는 네 가지 요소가 만나는 지점에서 나타난다—이는 몇 년 전까지만 해도 순전히 학술 영역에 머물러 있던 기술 범주였다.
촉각 인식은 구체화된 인공지능 아키텍처로 진입하고 있으며, 로봇 학습의 일부 모델은 촉각을 일등 시민으로 명시적으로 포함시키기 시작하였다. 후각 인터페이스는 현실적인 공학 제품으로 자리매김하고 있다: 착용형 후각 디스플레이가 마이크로 향기 발생기와 밀리초 단위 응답 속도를 활용하여 혼합 현실 애플리케이션에서 시연되었으며, 후각 모델은 화학 공정 모니터링을 위해 시각 인공지능 시스템과 결합되기 시작하였다.
이 모든 발전의 공통된 규칙은, 극한 상황에서 서로 수렴한다는 점이다. AR 안경은 사용자와 물리 환경 간 상호작용에 대한 시각 및 공간 데이터를 지속적으로 생성한다. EMG 손목밴드는 인간 운동 의도의 통계적 규칙을 포착한다. 무음 음성 인터페이스는 아성대 발성에서 언어 출력까지의 매핑을 포착한다. BCI는 현재 가능한 가장 높은 해상도로 신경 활동을 포착한다. 촉각 센서는 물리적 조작의 접촉 역학을 포착한다. 각 신규 기기 범주는 동시에 데이터 생성 플랫폼이기도 하며, 여러 응용 분야의 근간 모델을 키워준다. EMG를 이용해 운동 의도 데이터를 훈련한 로봇은 원격 조작 데이터만으로 훈련된 로봇과 다른 쥐기 전략을 학습한다. 아성대 명령에 응답하는 실험실 인터페이스는 키보드로 제어되는 실험실과 비교해 과학자-기계 상호작용 방식이 완전히 다르다. 고밀도 BCI 데이터로 훈련된 신경 해독기는 다른 어떤 채널에서도 얻을 수 없는 운동 계획 표현을 산출한다.
이 기기들의 확산은 최첨단 물리 인공지능 시스템 훈련에 사용 가능한 데이터 다양체(data manifold)의 유효 차원을 확장하고 있으며, 이 확장의 상당 부분은 학술 실험실이 아니라 자본이 풍부한 소비재 기업에 의해 주도되고 있으므로, 데이터 피드백 고리는 시장 채택률과 함께 확장될 수 있다.
원시어 5: 폐쇄 루프 인텔리전트 에이전트 시스템
마지막 원시어는 더 아키텍처 중심적이다. 이는 지각, 추론, 행동을 지속적이고 자율적이며 폐쇄 루프로 작동하는 시스템으로 통합하여, 장기간에 걸쳐 인간의 개입 없이 작동하게 하는 것을 의미한다.
언어 모델에서는 이에 대응하는 발전이 인텔리전트 에이전트 시스템의 등장이다—즉, 다단계 추론 체인, 도구 사용, 자기 교정 프로세스를 통해 모델을 단일 라운드 질문-응답 도구에서 자율적 문제 해결자로 진화시킨다. 물리 세계에서는 동일한 전환이 발생하고 있지만, 훨씬 더 엄격한 요구사항이 따른다. 언어 에이전트가 오류를 범하더라도 비용 없이 되돌릴 수 있지만, 물리 에이전트가 시약병을 쏟으면 되돌릴 수 없다.
물리 세계의 인텔리전트 에이전트 시스템은 디지털 버전과 구분되는 세 가지 특성을 갖는다. 첫째, 실험 또는 운영 폐쇄 루프에 직접 내장되어야 한다: 즉, 원시 기기 데이터 스트림, 물리적 상태 센서, 실행 원시어에 직접 연결되어, 추론이 물리적 현실의 문자적 설명이 아니라 물리적 현실 자체에 뿌리를 두어야 한다. 둘째, 장기 시퀀스 지속성(long-sequence persistence)이 필요하다: 기억, 추적 가능성, 안전 감시, 복구 행동을 통해 여러 실행 주기를 연결해야 하며, 각 과제를 독립적인 삽화로 취급해서는 안 된다. 셋째, 폐쇄 루프 적응(closed-loop adaptation)이 필요하다: 즉, 문자 기반 피드백이 아니라 물리적 결과에 따라 전략을 수정해야 한다.
이 원시어는 개별 역량(우수한 월드 모델, 신뢰성 있는 동작 아키텍처, 풍부한 센서 키트)을 물리 세계에서 자율적으로 작동하는 완전한 시스템으로 통합한다. 이는 통합 계층이며, 이 계층의 성숙은 아래 세 응용 분야가 단순한 연구 시연이 아니라 실제 세계에 배포되는 것으로 존재할 수 있는 전제조건이다.
세 분야
위의 원시어들은 범용 가능화 계층(universal enabling layer)이며, 자체적으로는 가장 중요한 응용 분야가 어디에 위치할지를 규정하지 않는다. 많은 분야가 물리적 동작, 물리적 측정 또는 물리적 지각을 포함한다. ‘선도적 시스템’과 ‘단지 기존 시스템의 개량판’을 구분하는 것은, 해당 분야 내 모델 역량 향상과 스케일링 인프라가 복리 효과를 일으키는 정도—즉, 단순히 성능이 향상되는 것이 아니라 이전에는 불가능했던 새로운 역량이 등장하는지 여부—이다.
로봇, AI 기반 과학, 새로운 형태의 인간-기계 인터페이스는 이러한 복리 효과가 가장 강한 세 분야이다. 각 분야는 고유한 방식으로 원시어를 조합하며, 각 분야는 현재 원시어가 해소하고 있는 제약에 의해 막혀 있고, 각 분야는 운영 과정에서 구조화된 물리 데이터라는 부산물을 생성한다—이 데이터는 다시 원시어 자체를 개선시키는 피드백 루프를 형성하여 전체 시스템을 가속화한다. 이들은 유일한 관심 분야가 아니지만, 최첨단 인공지능 역량과 물리적 현실이 가장 밀접하게 상호작용하는 곳이며, 현재 언어/코드 패러다임에서 가장 멀리 떨어져 있어 새로운 역량이 등장할 가능성이 가장 크고, 동시에 이 패러다임과 높은 보완성을 갖추어 그 혜택을 직접 누릴 수 있는 곳이다.
로봇
로봇은 물리 인공지능을 가장 문자 그대로 구현한 것이다: 인공지능 시스템이 실시간으로 지각하고, 추론하고, 물질 세계에 물리적 동작을 가해야 한다. 또한 이는 각 원시어에 대해 압력 테스트를 동시에 수행한다.
범용 로봇이 수건을 접기 위해 수행해야 할 일을 생각해 보라. 로봇은 힘을 받았을 때 가변형 재료가 어떻게 반응하는지를 학습한 표현—즉, 언어 사전 훈련이 제공할 수 없는 물리적 사전 지식—이 필요하다. 로봇은 고위 수준의 명령을 초당 20회 이상의 제어 주파수로 연속적인 운동 명령 시퀀스로 번역할 수 있는 동작 아키텍처가 필요하다. 로봇은 실제 수건 접기 시범을 수백만 차례 수집한 사람은 없기 때문에, 시뮬레이션을 통해 생성된 훈련 데이터가 필요하다. 로봇은 시각으로는 안정적인 쥐기와 실패 직전의 쥐기를 구분할 수 없기 때문에, 미끄러짐을 감지하고 쥐기 힘을 조정하기 위한 촉각 피드백이 필요하다. 또한 로봇은 잘못 접었을 때 오류를 인식하고 복구할 수 있는 폐쇄 루프 컨트롤러가 필요하며, 단순히 기억된 궤적을 맹목적으로 실행해서는 안 된다.
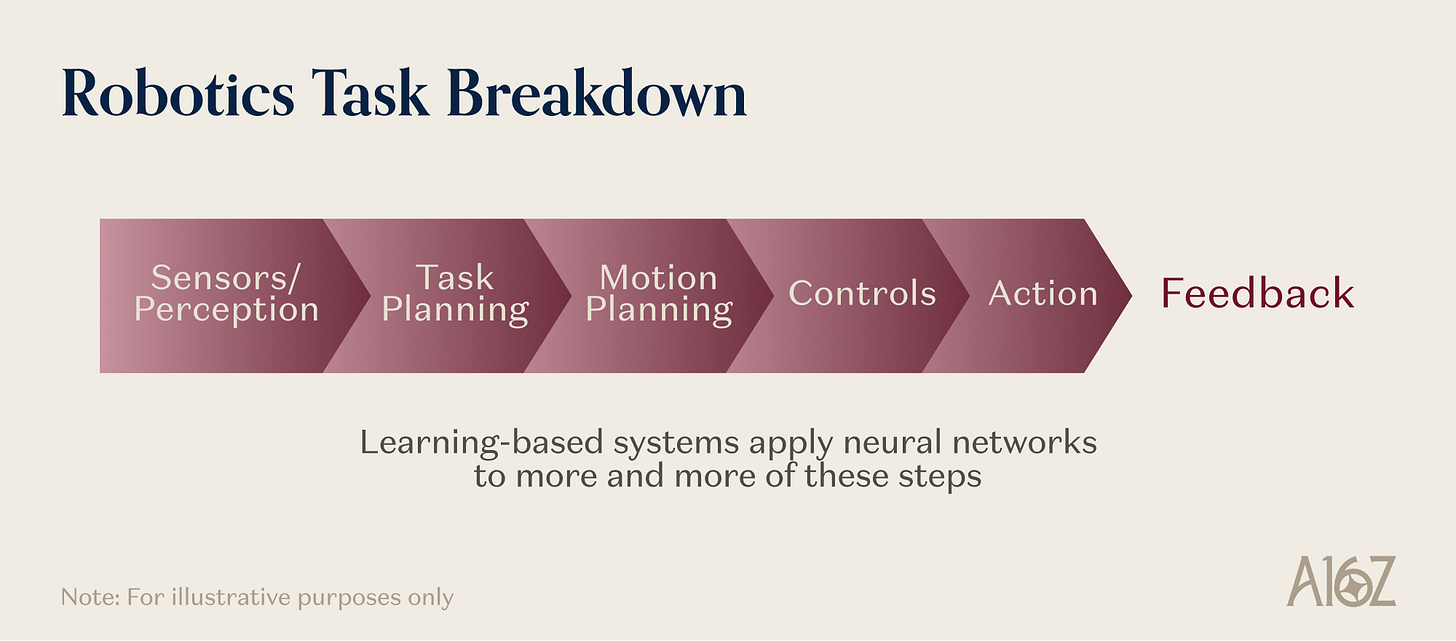
그림 설명: 로봇 과제가 다섯 가지 근간 원시어를 동시에 호출하는 방식
이것이 바로 로봇이 단순한 도구가 개선된 성숙한 공학 분야가 아니라, 선도적 시스템인 이유이다. 이 원시어들은 기존 로봇 역량을 단순히 개량하는 것이 아니라, 좁고 통제된 산업 환경 외부에서는 이전에 불가능했던 조작, 운동, 상호작용 범주를 해방한다.
지난 몇 년간의 선도적 진전은 상당하다—우리는 이전에도 이를 다룬 바 있다. 1세대 VLA는 기초 모델이 다양한 과제를 수행하기 위해 로봇을 제어할 수 있음을 입증하였다. 아키텍처 분야의 진전은 로봇 시스템의 고위 수준 추론과 저위 수준 제어를 연결하고 있다. 엣지 측 추론이 실현 가능해졌으며, 본체 간 이식(cross-body transfer)은 제한된 데이터로 새 로봇 플랫폼에 모델을 적응시키는 것을 가능하게 한다. 남은 핵심 과제는 규모화된 신뢰성이며, 이는 여전히 배포의 병목이다. 각 단계에서 95%의 성공률을 달성하더라도, 10단계 과제 체인에서는 60%에 불과하며, 생산 환경은 이보다 훨씬 높은 수준을 요구한다. 강화 학습 사후 훈련은 이 분야가 스케일링 단계에 진입하기 위해 필요한 역량 및 강건성 임계치를 넘어설 수 있는 잠재력을 지닌다.
이러한 진전은 시장 구조에도 영향을 미친다. 로봇 산업은 수십 년간 기계 시스템 자체에 가치가 축적되어 왔으며, 기계는 여전히 기술 스택의 핵심 부분이지만, 학습 전략이 표준화됨에 따라 가치는 모델, 훈련 인프라, 데이터 피드백 고리로 이동할 것이다. 로봇은 또한 위의 원시어를 되돌려준다: 각 실제 세계 궤적은 월드 모델을 개선하는 훈련 데이터이며, 각 배포 실패는 시뮬레이션의 적용 범위에 대한 공백을 드러내며, 각 새로운 본체의 테스트는 사전 훈련에 사용 가능한 물리적 경험 다양성을 확장한다. 로봇은 원시어에 대해 가장 엄격한 소비자이자, 이들을 개선하기 위한 가장 중요한 신호원 중 하나이다.
자율 과학
로봇이 ‘실시간 물리적 동작’으로 원시어를 테스트한다면, 자율 과학은 약간 다른 것을 테스트한다—즉, 인과관계가 복잡한 물리적 시스템에 대한 지속적이고 다단계적인 추론으로, 시간 범위는 시간 또는 일 단위이며, 실험 결과는 해석되고 맥락화되어 전략을 수정하는 데 사용되어야 한다.
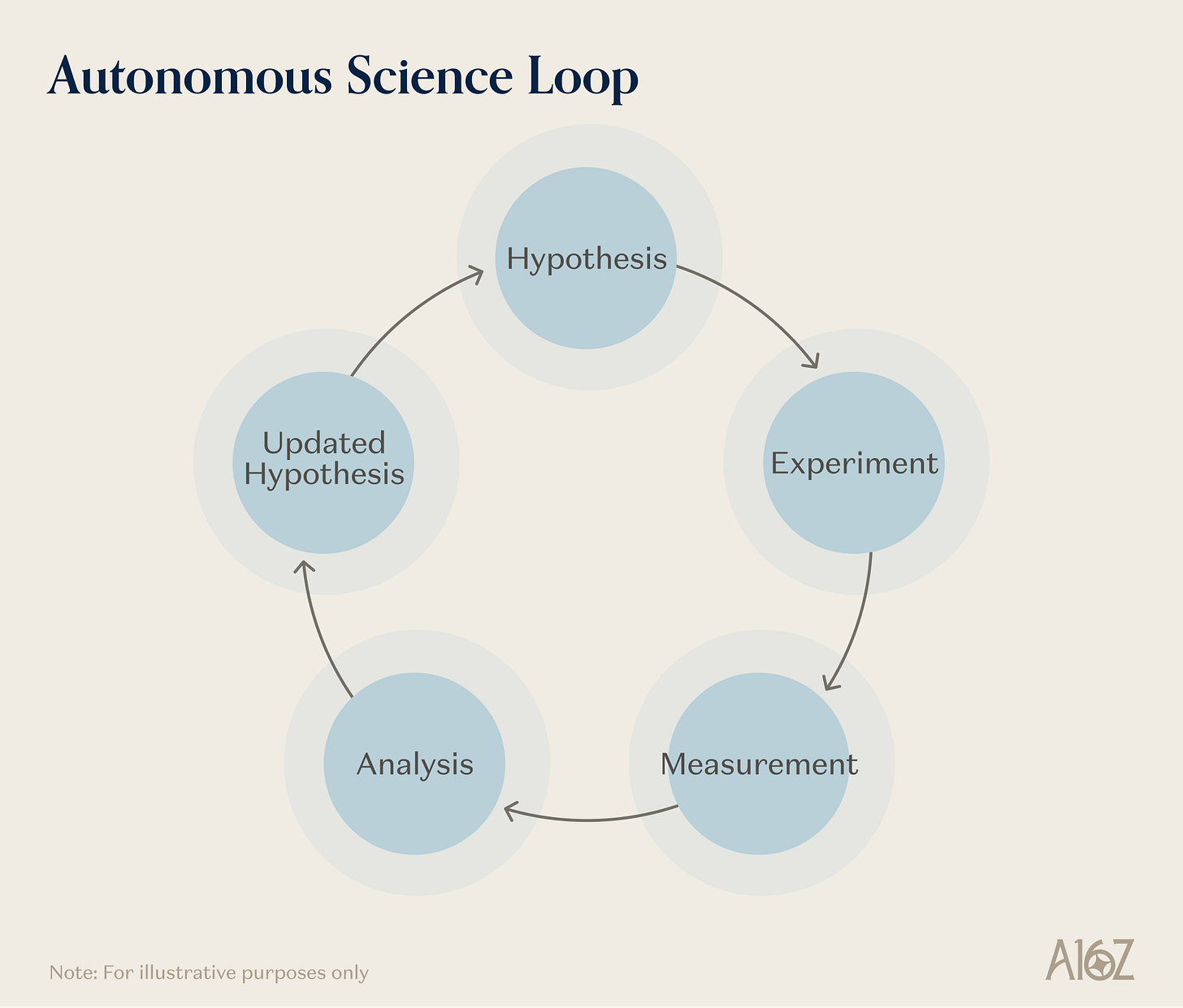
그림 설명: 자율 과학(AI 과학자)이 다섯 가지 근간 원시어를 통합하는 방식
AI 기반 과학은 원시어 조합이 가장 철저한 분야이다. 자율 주행 실험실(self-driving lab, SDL)은 실험이 어떤 결과를 낳을지 예측하기 위해 물리·화학 역학에 대한 학습 표현이 필요하다. 샘플 이동, 샘플 정렬, 분석 장비 조작을 위한 구체화된 동작이 필요하다. 후보 실험 사전 선별 및 희귀 장비 시간 할당을 위한 시뮬레이션이 필요하다. 결과를 특성화하기 위해 광범위한 감지 능력—분광, 크로마토그래피, 질량 분석, 그리고 점점 더 새로운 화학 및 생물 센서—이 필요하다. 이 분야는 어떤 다른 분야보다도 폐쇄 루프 인텔리전트 에이전트 오케스트레이션 원시어를 더 깊이 필요로 한다: 즉, ‘가설-실험-분석-수정’의 다중 라운드 워크플로를 인간 개입 없이 유지하면서, 추적 가능성, 안전 모니터링, 각 라운드에서 드러나는 정보에 따라 전략을 조정할 수 있어야 한다.
이러한 원시어를 이 정도로 깊이 호출하는 분야는 없다. 이것이 자율 과학이 단순히 소프트웨어가 개선된 실험실 자동화가 아니라, 선도적 ‘시스템’인 이유이다. Periodic Labs와 Medra는 각각 재료과학 및 생명과학 분야에서 과학적 추론 능력과 물리적 검증 능력을 통합하여 과학적 반복을 실현하고, 동시에 실험 훈련 데이터를 산출하고 있다.
이러한 시스템의 가치는 직관적으로 명확하다. 전통적인 재료 발견은 개념에서 상용화까지 수 년이 걸리지만, AI가 가속화하는 워크플로는 이 과정을 훨씬 단축시킬 수 있다. 핵심 제약은 가설 생성(기초 모델이 이미 잘 보조함)에서 제조 및 검증(물리적 장비, 로봇 실행, 폐쇄 루프 최적화 필요)으로 이동하고 있다. SDL은 바로 이 병목을 해결하기 위해 설계되었다.
자율 과학의 또 다른 중요한 특성—모든 물리 세계 시스템에서 공통되는 특성—은 그것이 데이터 엔진으로서의 역할이다. SDL이 실행하는 각 실험은 단순한 과학적 결과뿐만 아니라, 물리적 실현을 거쳐 실험적으로 검증된 훈련 신호를 산출한다. 특정 조건에서 중합체가 어떻게 결정화되는지에 대한 측정은 월드 모델의 재료 역학에 대한 이해를 풍부하게 한다. 검증된 합성 경로는 물리적 추론의 훈련 데이터가 된다. 특성화된 실패는 인텔리전트 에이전트 시스템이 자신의 예측이 어디에서 실패했는지를 알려준다. AI 과학자가 실제 실험을 통해 산출한 데이터는 인터넷 텍스트나 시뮬레이션 출력과는 성격이 다르다—즉, 구조화되어 있고, 인과관계가 있으며, 실증적으로 검증된 것이다. 이는 물리적 추론 모델이 가장 필요로 하지만 다른 어떤 출처에서도 얻을 수 없는 데이터이다. 자율 과학은 바로 물리적 현실을 구조화된 지식으로 직접 전환하고, 전체 물리 인공지능 생태계를 개선하는 통로이다.
새로운 인터페이스
로봇은 인공지능을 물리적 동작으로 확장하고, 자율 과학은 인공지능을 물리적 연구로 확장한다. 새로운 인터페이스는 인공지능을 인간의 지각, 감각 경험, 신체 신호와의 직접적 결합으로 확장한다—AR 안경, EMG 손목밴드에서 이식형 뇌-기계 인터페이스에 이르기까지 다양한 기기를 포함한다. 이 범주를 묶는 것은 단일 기술이 아니라 공통 기능이다: 인간 지능과 인공지능 시스템 간 채널의 대역폭 및 모달리티를 확장하고, 이 과정에서 물리 인공지능 구축에 직접 사용 가능한 인간-세계 상호작용 데이터를 생성하는 것이다.

그림 설명: AR 안경에서 뇌-기계 인터페이스까지 새로운 인터페이스의 스펙트럼
주류 패러다임과의 거리는 이 분야의 도전이자 잠재력의 근원이다. 언어 모델은 개념 수준에서 이러한 모달리티를 알고 있지만, 무음 음성의 운동 패턴, 후각 수용체 결합의 기하학적 구조, EMG 신호의 시계열 역학을 천연적으로 익숙하게 다루지 못한다. 이러한 신호를 해독하는 표현은 확장 중인 감각 채널에서 직접 학습되어야 한다. 많은 모달리티는 인터넷 규모의 사전 훈련 코퍼스가 없으며, 데이터는 인터페이스 자체에서만 생성될 수 있다—즉, 시스템과 그 훈련 데이터가 공동 진화(co-evolution)하고 있으며, 이는 언어 인공지능에서는 대응되는 사례가 없다.
이 분야의 최근 성과는 AI 착용형 기기가 소비재 범주로서 급속히 부상하고 있다는 점이다. AR 안경은 아마도 이 범주에서 가장 눈에 띄는 예일 것이며, 음성 또는 시각을 주요 입력으로 삼는 다른 착용형 기기도 동시에 등장하고 있다.
이 소비재 기기 생태계는 인공지능을 물리 세계로 확장하기 위한 새로운 하드웨어 플랫폼을 제공할 뿐 아니라, 물리 세계 데이터 인프라가 되고 있다. AI 안경을 착용한 사람은 물리 환경에서 인간이 어떻게 항해하고, 물체를 조작하며, 세상과 상호작용하는지를 지속적으로 기록하는 1인칭 비디오 스트림을 산출한다. 다른 착용형 기기들은 생체 인식 및 운동 데이터를 지속적으로 캡처한다. AI 착용형 기기의 설치 수량은 분산된 물리 세계 데이터 수집 네트워크가 되어, 이전에는 불가능했던 규모로 인간의 물리적 경험을 기록하고 있다. 스마트폰이 소비재 기기로서 갖는 규모를 생각해 보라—동일한 규모의 신규 소비재 기기가 새로운 모달리티로 컴퓨터가 세상을 인식하게 만들고, 인공지능과 물리 세계 간 상호작용을 위한 거대한 새로운 채널을 열어준다.
뇌-기계 인터페이스는 더 깊은 선도적 영역을 대표한다. Neuralink는 이미 여러 환자에게 이식을 완료하였으며, 수술 로봇 및 해독 소프트웨어가 반복적으로 개선되고 있다. Synchron의 혈관 내 스텐트로드(Stentrode)는 마비 환자가 디지털 및 물리적 환경을 제어하는 데 이미 사용되고 있다. Echo Neurotechnologies는 고해상도 피질 음성 해독 연구를 기반으로 언어 회복을 위한 BCI 시스템을 개발 중이다. Nudge와 같은 신규 기업들도 새로운 신경 인터페이스 및 뇌 상호작용 플랫폼을 위해 인재와 자본을 모으고 있다. 연구 수준의 기술 이정표도 주목할 만하다: BISC 칩은 단일 칩에서 65,536개 전극의 무선 신경 기록을 시연하였다. BrainGate 팀은 운동 피질에서 직접 내부 언어를 해독하였다.
AR 안경, AI 착용형 기기, 무음 음성 기기, 이식형 BCI를 관통하는 주요 선은 단순히 ‘모두 인터페이스’라는 점이 아니라, 이들이 인간의 물리적 경험과 인공지능 시스템 간 대역폭이 점차 증가하는 스펙트럼을 공동으로 구성한다는 점이다—이 스펙트럼의 각 지점은 본 문서의 세 분야 뒤에 있는 원시어의 지속적 진전을 뒷받침한다. 수백만 명의 AI 안경 사용자로부터 얻은 고품질 1인칭 비디오로 훈련된 로봇은, 선별된 원격 조작 데이터셋으로 훈련된 로봇과는 완전히 다른 조작 사전 지식을 학습한다. 아성대 명령에 응답하는 실험실 AI는 키보드로 제어되는 실험실과 지연 및 유창성 측면에서 완전히 다른 것이다. 고밀도 BCI 데이터로 훈련된 신경 해독기는 다른 어떤 채널에서도 얻을 수 없는 운동 계획 표현을 산출한다.
새로운 인터페이스는 감각 채널 자체를 확장하는 메커니즘이다—즉, 이전에는 존재하지 않았던 물리 세계와 인공지능 간 데이터 채널을 열어준다. 이러한 확장은 대규모 배포를 추구하는 소비재 기업에 의해 주도되므로, 데이터 피드백 고리는 소비자 채택률과 함께 가속화될 것이다.
물리 세계의 시스템
로봇, 자율 과학, 새로운 인터페이스를 동일한 원시어 조합으로 만들어진 선도적 시스템의 서로 다른 사례로 보는 이유는, 이들이 서로를 가능하게 하며 복리 효과를 창출하기 때문이다.
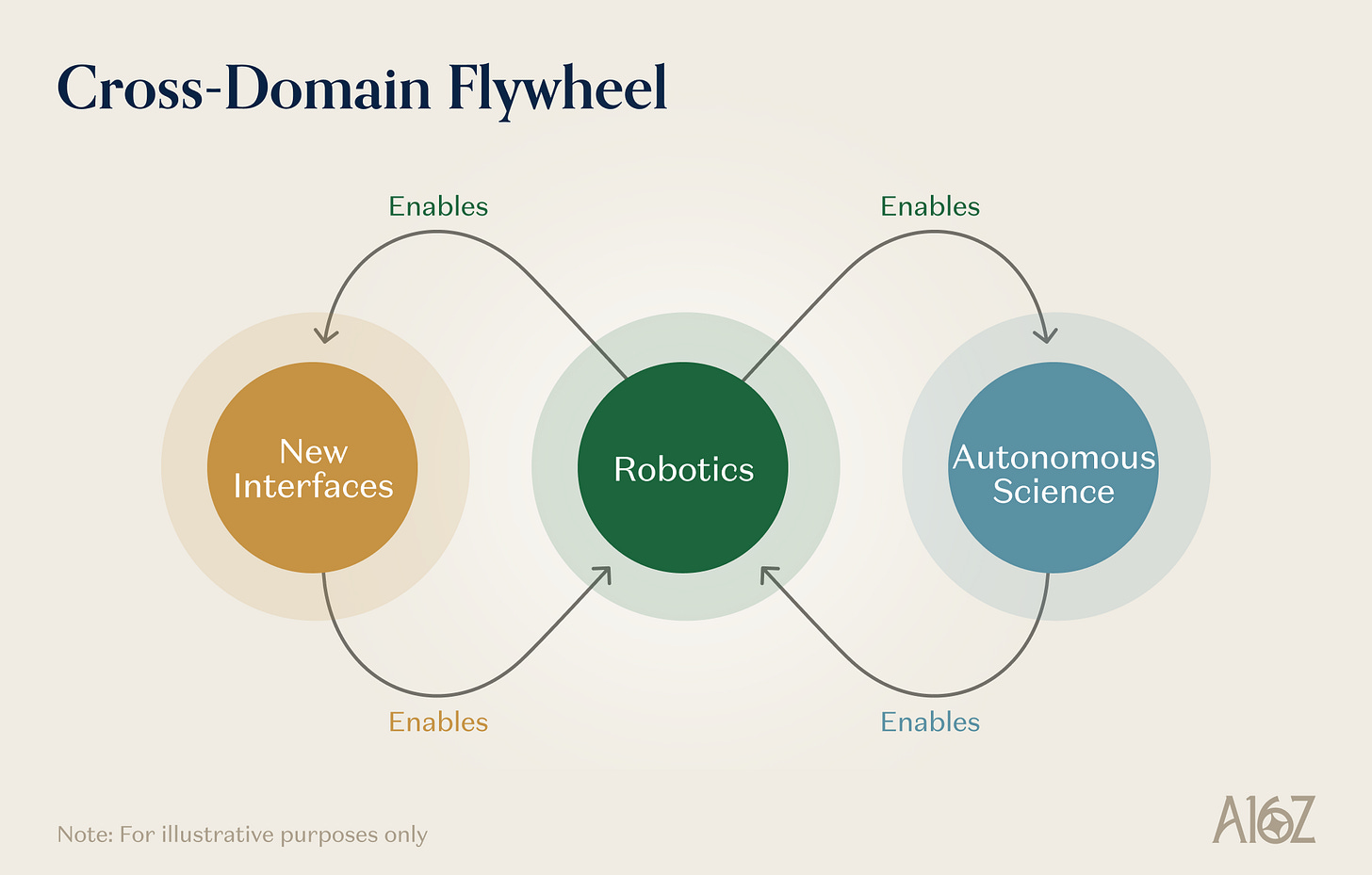
그림 설명: 로봇, 자율 과학, 새로운 인터페이스 간 상호 피드백 고리
로봇은 자율 과학을 가능하게 한다. 자율 주행 실험실은 본질적으로 로봇 시스템이다. 범용 로봇 개발을 위해 구축된 조작 능력—정교한 쥐기, 액체 처리, 정밀 위치 지정, 다단계 과제 실행—은 실험실 자동화에 직접 이식될 수 있다. 로봇 모델이 범용성과 강건성 면에서 한 단계 진전할 때마다, SDL이 자율적으로 실행할 수 있는 실험 프로토콜의 범위는 확대된다. 로봇 학습의 매 진전은 자율 실험의 비용을 낮추고 처리량을 높인다.
자율 과학은 로봇을 가능하게 한다. 자율 주행 실험실이 산출하는 과학적 데이터—검증된 물리적 측정, 인과관계 기반 실험 결과, 재료 특성 데이터베이스—는 월드 모델과 물리적 추론 엔진이 가장 필요로 하는 구조화되고 실현 가능한 훈련 데이터를 제공한다. 더 나아가, 차세대 로봇이 필요로 하는 재료 및 부품(더 우수한 액추에이터, 더 민감한 촉각 센서, 더 높은 에너지 밀도 배터리 등)은 재료과학의 산물 그 자체이다. 재료 혁신을 가속화하는 자율 발견 플랫폼은 바로 로봇 학습이 작동하는 하드웨어 기반을 직접 개선한다.
새로운 인터페이스는 로봇을 가능하게 한다. AR 기기는 ‘사람이 물리 환경을 어떻게 인식하고 상호작용하는가’에 대한 데이터를 규모 있게 수집하는 방식이다. 신경 인터페이스는 인간의 운동 의도, 인지 계획, 감각 처리에 관한 데이터를 산출한다. 이러한 데이터는 특히 인간-로봇 협업 또는 원격 조작 과제를 포함하는 로봇 학습 시스템 훈련에 매우 소중하다.
여기에 최첨단 인공지능 진전 자체의 성격에 대한 더 깊은 관찰이 있다. 언어/코드 패러다임은 놀라운 성과를 산출하였으며, 스케일링 시대에도 여전히 강력한 상승세를 유지하고 있다. 그러나 물리 세계는 거의 무한한 새로운 문제, 새로운 데이터 유형, 새로운 피드백 신호, 새로운 평가 기준을 제공한다. 인공지능 시스템을 물리적 현실에 뿌리내리기—즉, 물체를 조작하는 로봇, 재료를 합성하는 실험실, 생물 및 물리 세계와 연결되는 인터페이스를 통해—우리는 기존 디지털 선도 분야와 보완적인 새로운 스케일링 축을 열었으며, 이는 상호 개선 가능성도 매우 높다.
그림 설명: 물리 인공지능의 다양한 스케일링 축 간 상호작용 및 등장 현상
이러한 시스템이 어떤 행동을 등장시킬지는 정확히 예측하기 어렵다—‘등장(emergence)’의 정의 자체가 독립적으로 이해 가능한 능력들이 결합되었을 때 이전에 본 적 없는 새로운 능력을 창출하는 것이다. 그러나 역사적 패턴은 낙관적이다. 인공지능 시스템이 세상과 상호작용하는 새로운 모달리티—보기(컴퓨터 비전), 말하기(음성 인식), 읽기/쓰기(언어 모델)—를 얻을 때마다, 그 능력의 도약은 각각의 개선 효과를 단순히 더한 것 이상이었다. 물리 세계 시스템으로의 전환은 바로 다음 차례의 이러한 상전이(phase transition)를 의미한다. 이 의미에서, 본 문서에서 논의된 이러한 원시어들은 현재 구축되고 있으며, 최첨단 인공지능 시스템이 물리 세계를 인식하고, 추론하고, 작용할 수 있게 하여, 물리 세계에서 방대한 가치와 진전을 해방할 수 있을 것이다.
면책 조항: 본 문서는 정보 교류 목적으로만 제공되며, 어떠한 투자 조언도 구성하지 않으며, 법률·사업·투자 또는 세무 자문의 근거로 사용되어서는 안 된다.
TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News














