

ChatGPTが医療分野に参入して6日後、OpenAIは自社の医療ヘルスケアベンチマークで逆転を許した
TechFlow厳選深潮セレクト
ChatGPTが医療分野に参入して6日後、OpenAIは自社の医療ヘルスケアベンチマークで逆転を許した
百川智能は今年上半期中に、C向けの医療製品を順次2種類リリースする予定であると表明した。
著者:Li Yuan
AIアシスタントに自分の健康に関する質問をしたことがありますか?
もし私がそうであるように、あなたもAIのヘビーユーザーなら、おそらく試したことがあるでしょう。
OpenAI自身が公表したデータによると、ヘルスケアはすでにChatGPTで最も一般的な利用シナリオの一つとなっており、世界中で毎週2.3億人以上が健康や保健に関連する質問を行っています。
そのため、2026年に向けて、ヘルスケア分野はAI企業の激戦区となる兆しを見せています。
1月7日、OpenAIは「ChatGPT Health」を発表し、ユーザーが電子カルテや各種ヘルスケアアプリと連携することで、より的確な医療回答を受けられるようにしました。そして1月12日には、Anthropicも直ちに「Claude for Healthcare」をリリースし、新モデルの医療シーンにおける能力を強調しました。
しかし興味深いことに、今回は中国企業が遅れを取らず、むしろリードしている可能性さえあります。
1月13日、百川智能はM3モデルのリリースを発表し、OpenAIが公開した医療・ヘルスケア分野の評価ベンチマーク「HealthBench」において、GPT-5.2 Highを上回りSOTA(最新最良)を達成しました。
「All-in メディカル」として多くの疑問を呈された後、百川智能はようやくその実力を証明したようです。今回のM3モデルの能力およびAI医療の最終的な展望について、極客公園は王小川氏に直接インタビューしました。
01 初めて健康分野のテストでOpenAIを上回る
今回発表されたM3モデルの中で最も目立つ成果は、OpenAIが発表した医療・ヘルスケア分野の評価テストセット「HealthBench」で、初めてOpenAIのGPT-5.2 Highを上回り、SOTAを獲得したことだ。
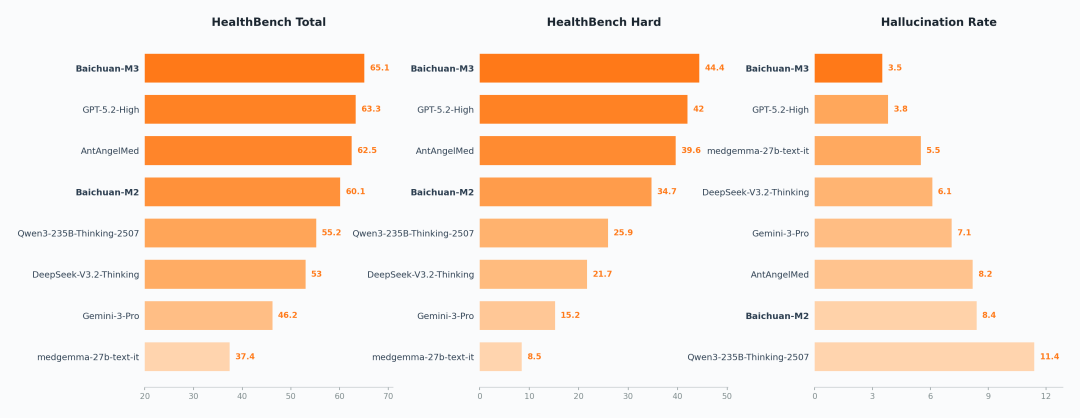
Healthbench、Healthbench Hardおよびハルシネーション評価でのSOTA
Healthbenchは、2025年5月にOpenAIが発表した医療・ヘルスケア分野の評価用テストセットであり、60カ国から262人の医師が共同で構築したもので、5000組の極めてリアルなマルチターン医療対話が収録されており、現時点では世界的に最も権威があり、臨床現場に最も近い医療評価データセットの一つです。
このテストセット発表以降、OpenAIのモデルが常にトップを維持していました。
今回、百川智能の次世代オープンソース医療大規模モデル「Baichuan-M3」は総合得点65.1を記録し、世界第1位となりました。特に複雑な意思決定能力を試す「HealthBench Hard」でも優勝し、最高得点を更新しました。
また、百川は同時にハルシネーション率のテスト結果も公表しています。M3モデルのハルシネーション率は3.5%と、世界最低レベルです。
なお、このハルシネーション率は外部検索ツールを用いない、純粋なモデル設定下での医療ハルシネーション率である点に注目が必要です。
百川智能によれば、これら二つの成果を得た鍵は、医療分野に適した強化学習アルゴリズムを導入したことにあるとしています。
百川はM3モデルで初めて「Fact Aware RL(事実認識型強化学習)」技術を採用し、「決まり文句ばかり言わず」「でたらめを言わない」効果を実現しました。
これは医療分野において極めて重要なことです。
最適化されていないモデルで医療質問を行うと、よくある問題が二つあります。一つはモデルが症状を完全に捏造し、病名をでっち上げること。もう一つは曖昧な表現で結局「医師の診察を受けてください」とだけ答えることであり、どちらも医師や患者にとってあまり役立ちません。
多くのモデルが単純なハルシネーション率を最適化目標としており、正しい事実をひたすら並べて全体のハルシネーション率を低下させようとするためです。これに対し百川は意味クラスタリングと重要性重み付けメカニズムを導入しました。クラスタリングによって冗長な表現の干渉を排除し、重み付けにより主要な医学的判断に高い重みを与えることで精度を高めています。
また、単にハルシネーションに対する重みを高くすると、「何も言わなければ間違えない」という保守的な戦略に陥りやすくなります。そのためFact Aware RLアルゴリズムには、モデルの現在の能力に応じて動的に両目標を調整するメカニズムが設計されています。能力構築段階では医療知識の学習と表現に重点(高いTask Weight)を置き、能力が成熟したら徐々に事実性制約を厳しくしていきます(ハルシネーションWeightを上昇)。
ネット接続可能な場合、百川はマルチラウンド検索に基づくオンライン検証モジュールを追加し、効率的なキャッシュシステムを導入して膨大な医療知識との整合性を確保しています。
02 診断能力が人間の医師を超え、実用段階へ
ただし、HealthbenchでOpenAIを上回ったこと自体が唯一のハイライトではありません。
より興味深いのは、百川が独自に「SCAN-benche」という評価セットを創造的に構築した点です。OpenAIのベンチマークで順位を上げることよりも、百川が独自に構築したこの評価セットこそが、同社が医療分野で本当に改善したい方向性を示しているかもしれません。
百川が今回構築した評価セットの核心は、「エンドツーエンドの診察能力」の最適化にあります。これは同社が行った実験から得られた洞察に由来します。つまり、「問診の正確度が2%向上すると、治療結果の正確度が1%向上する」というものです。
つまり、OpenAIのHealthBenchが主に「AIが質問に答えられるか」に焦点を当てているのに対し、百川のSCAN-bencheは「AIが一問一答の中で有効な情報を取得し、正しい診断結果と医療アドバイスを提供できるか」を評価しようとしています。
通常、AIアシスタントに「経験豊富な医師として振る舞ってください」と指示しても、十分な効果は得られません。なぜなら、実際の医師の問診プロセスは非常に規範的だからです。これを百川は四象限のSCAN原則にまとめました。Safety Stratification(安全分層)、Clarity Matters(情報の明確化)、Association & Inquiry(関連追及)、Normative Protocol(標準化された出力)です。
このSCAN原則に基づき、百川は医学教育で長年使われてきたOSCE方式を参考に、150人以上の現役医師と協力してSCAN-bench評価体系を構築しました。診療プロセスを「病歴聴取」「補助検査」「精密診断」の三段階に分解し、動的かつマルチターンで評価することで、医師が初診から確定診断までの一連のプロセスを完全に模倣し、各ステップでより良い結果を得られるようにモデルを最適化しています。
百川は今回、M3モデルのSCAN-bencheでの評価結果も公表しました。
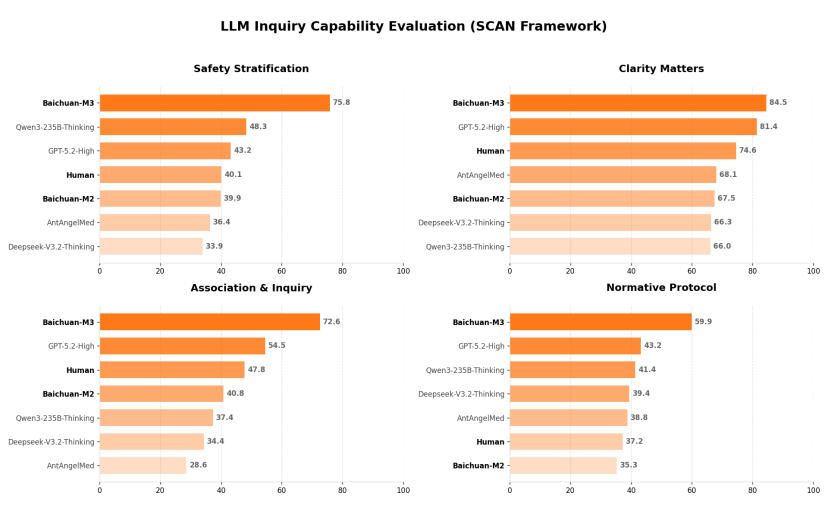
結果は非常に興味深いものでした。百川はモデル同士の比較だけでなく、実際に人間の医師とも比較を行いました。その結果、四つの象限すべてで、人間の医師はモデルが到達した水準にすでに及ばなくなっていました。
極客公園はこの点について百川チームに質問しました。回答によると、今回の評価はすべて専門医が専門症例でモデルと比較したものであり、モデルが勝利できた理由は第一に「モデルの方が忍耐強く、より多くの質問ができる」こと、そして何より「モデルがより優れた跨学科的知識統合能力を持っている」ことだと述べています。
例えば、10歳の子供が繰り返し発熱するというケースがあります。発熱は非常に複合的な医療現象であり、咳などの肺の状態だけを尋ねると、関節や泌尿器系の深刻な問題を見逃し、単なる感染症と誤診してしまう可能性があります。
人間の医師は通常、自分の専門分野の病気にしか精通しておらず、これが複雑な症状に対してしばしば専門家会議が必要になる理由であり、難病の専門家ですら資料を調べたり本を引いたりすることが多いのです。
一方、特別な訓練を受けておらず、ただ医師を「演じる」だけの普通のモデルでは、こうした問題に正しく答えるのは難しいのが現状です。
03 次のステップ:C向け製品の開発を始め、より真剣な医療へ
百川智能にとって、人間の医師を上回るというこの節目は極めて大きな意味を持ちます。これはAIが「使える」段階に達したことを意味し、実際の使用シナリオへの展開が可能になったということです。
1月13日から、ユーザーはすでに百小応のウェブサイトおよびアプリで、M3モデルによる回答を体験できます。
現在のサイトデザインは非常にユニークです。M3モデルを使用して回答していますが、「医師版」と「一般患者版」に分かれています。医師版では回答が簡潔で、多くの参考文献が引用され、「人間っぽくない」表現になります。一方、一般患者版では、モデルは一度に回答せず、さらに多くの追加質問を行い、より明確な診断を行います。

百川智能によると、モデルのバックエンドでの思考プロセスは非常に興味深いものです。「モデルの思考チェーンの中に『この患者は私の質問に答えていませんが、この質問は必ずしなければならない』と書いていることがよくあります。極端なケースでは、『すでに患者に20ラウンド質問しました。これは最大ラウンド数を超えていますが、それでもこの質問はしなければなりません』と書いています。なぜなら、訓練中に巧みな言い方をして報酬を得ることはできず、本当に十分なキーワードを得て、正しい診断を出した場合にのみ報酬が与えられるからです。これは私たちと他社のモデル訓練方法の明らかな違いです」と述べています。
最近、多くのAI企業が医療分野に参入しています。しかし百川智能が自分たちの最大の違いだと考えるのは、「より真剣な医療」を追求することです。
「これは、百川がシナリオを選ぶ際に、『どの分野がやりやすいか』ではなく、技術能力を絶えず高め、より難しい問題に挑戦し続けることを堅持しているということです」と王小川氏は語ります。
典型的な例として、今後百川は優先的に腫瘍専門の解決シナリオに取り組み、一方で心理療法は比較的低い優先順位に置いています。
一般的な見方では、AIによる心理療法は比較的簡単で、早期に実用化できる分野と考えられています。しかし百川の判断は異なります。彼らは腫瘍領域の方がより厳密な科学的根拠があると考えており、ここではAIが真剣な医療効果を出し、人間の医師の水準に達する、あるいは超える可能性が高いと見ています。一方、心理学の分野にはこのような確実な科学的アンカーが欠けています。
別の例として、ある企業が医師の「分身」を作ることを選択する中、王小川氏はその方向性は百川が目指すものではないと述べます。医師の分身は医師の能力を完全に再現できず、ましてやそれを超えることはできません。このようなAIは最終的に看板倒しや顧客獲得ツールに過ぎず、真剣な医療の推進にはつながりません。
この「真剣さ」へのこだわりは、百川の多くのビジネス選択に深く影響を与えています。
これは、王小川氏が医療AIの次の段階において根本的に考えるべき問題にも直結しています。彼は、現段階で最も重要な任務は、AIの能力を強化しつつ、徐々に医療供給を増やしていくことだと考えています。
中国は長年、階層診療制度と家庭医制度の導入を試みてきました。その狙いは、国民がまず一次医療機関で診察を受け、大病院の予約難、長時間の待ち行列、混雑といった現状を解消することにあります。
しかし、この制度がうまくいかない根本的な原因は、医療資源の供給不足にあります。一次医療機関には高度なスキルを持つ医師が不足しています。風邪程度でも、人々は安心感から三次病院に並ぶことを選びます。
まさにここが、医療AIが力を発揮できるポイントです。大規模モデルはトップレベルの医学知識を規模的に普及させることが可能です。これにより一次医療の供給ギャップが埋まり、すべてのコミュニティ、すべての家庭が三次病院の専門医と同等の診断能力を持つことができるようになります。
長期的には、これによりさらに広範な影響が生まれる可能性があります。医療における意思決定権が、徐々に医師から患者へと移行するかもしれません。従来の医療シナリオでは、患者は利益の受益者ですが、意思決定権を持っていません。この権力の不均衡は、コミュニケーションコストや治療中の苦痛を生む要因となります。
百川はAIを通じて、患者がより簡単に高品質な医療資源を利用できるようにすることを目指しています。「多くの人は医療はあまりに複雑で、患者には理解できないと考えます。しかし私は米国の司法制度にある陪審員制度を思い浮かべます。法律も非常に専門的な分野ですが、陪審員の一般人は専門知識がなくても、裁判官や弁護士、検察官が十分に議論し、わかりやすく説明することで、有罪か無罪かを一般人が判断できるレベルまで落とし込むことができます。つまり、論理的に正常に判断できるようにするのです」と王小川氏は語ります。
これもまた、百川智能が簡単なシナリオに留まらず、常に高度な真剣な診療に挑戦し続けたいと考える理由の一つです。
困難な問題を解決することは商業的に最も高いリターンをもたらすのかと問われたとき、王小川氏は深い答えを返しました。
彼は、風邪や発熱のような軽微な問題を解決しても、ユーザーの心に十分な信頼を築くのは難しいと述べます。医療は極めて信頼に依存する業界です。AIが重病など高度な難題を解決できるようになって初めて、真の信頼基盤を築けるのです。
ビジネスロジックの観点から見ても、患者は深刻な健康問題に直面しているときに、高品質なAIサービスに支払う意欲が高まります。この信頼は、商業的リターンの前提であるだけでなく、AI医療が規模的に普及するための核となる要素です。
さらに根本的な意味において、医療は百川智能や王小川個人にとって、汎用人工知能(AGI)に近づく道でもあります。
王小川氏は、AIは現在、文学・理学・工学・芸術などの分野ですでに実用的な解法を見つけているが、医療は極めて特異な分野だと考えています。人類の医学探求はまだ尽きておらず、AIもこの分野では模索の段階にあります。
百川のロードマップは非常に明確です。まずAIで診断効率を向上させ、現在の医療供給不足を解決します。その上で、患者との間に深い信頼関係を築いていきます。患者がAIツールを使い、継続的に医療相談を行うようになれば、AIは長期の伴走を通じて、実際の高品質な医療データを蓄積できます。
これらのデータの究極の目標は、「生命の数学モデル」を構築することです。これは人間の医師がまだ完全に歩み終えていない道であり、将来、AIが最初に達成する可能性があります。もし生命の本質をモデル化できれば、それは汎用人工知能(AGI)のさらなる進化を推進する重要な一歩となるでしょう。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News










