IOSG:あなたのブラウザがエージェントになるとき
TechFlow厳選深潮セレクト
IOSG:あなたのブラウザがエージェントになるとき
AIの未来は、ウェブページを自律的にナビゲートできるエージェントにあります。
執筆:Mario Chow & Figo @IOSG
はじめに
過去12か月間、ウェブブラウザと自動化の関係は劇的に変化した。ほぼすべての大手テック企業が、自律型ブラウザエージェント(browser agent)の構築にしのぎを削っている。このトレンドは2024年末から顕著になり、OpenAIは1月にAgentモードをリリースし、AnthropicはClaudeモデルに「コンピューター操作」機能を追加、Google DeepMindはProject Marinerを発表、Operaはエージェント型ブラウザNeonを宣言、Perplexity AIはCometブラウザを投入した。信号は明確だ:AIの未来は、ウェブページを自律的にナビゲートできるエージェントにある。
この流れは単にブラウザに賢いチャットボットを搭載するだけではなく、機械とデジタル環境とのインタラクションの根本的転換である。ブラウザエージェントとは、「画面を見る」ことができ、リンクをクリックし、フォームに入力し、ページをスクロールし、文字を入力する――まるで人間ユーザーのように振る舞うAIシステムである。このアプローチは、現状では人間の操作が必要な、あるいは従来のスクリプトでは複雑すぎて自動化できないタスクを処理することで、大きな生産性と経済的価値を解放する可能性を秘めている。
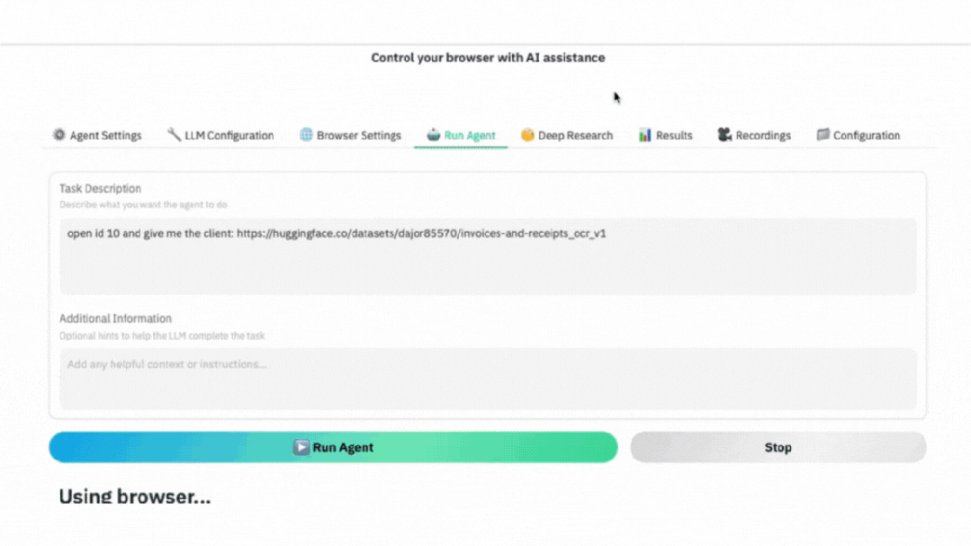
▲ GIFデモ:AIブラウザエージェントの実際の動作。指示に従って目的のデータセットページへ移動し、自動でスクリーンショットを撮影して必要なデータを抽出。
誰がAIブラウザ戦争に勝つのか?
ほぼすべての大手テック企業(およびいくつかのスタートアップ)が、独自のブラウザAIエージェントソリューションを開発している。以下は代表的なプロジェクトである:
OpenAI – Agentモード
OpenAIのAgentモード(旧称Operator、2025年1月リリース)は、内蔵ブラウザを持つAIエージェントである。Operatorは、ウェブフォームの記入、食料品の注文、会議のスケジューリングなど、さまざまな繰り返し作業を、人間が普段使う標準的なウェブインターフェースを通じて処理できる。
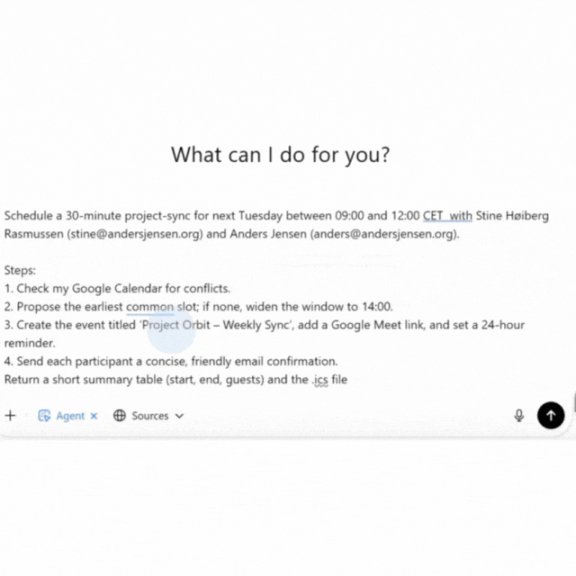
▲ AIエージェントが専門アシスタントのように会議を調整:カレンダーを確認し、空き時間を検索してイベントを作成、確認メールを送信し、.icsファイルを生成。
Anthropic – Claudeの「Computer Use(コンピューター操作)」
2024年末、AnthropicはClaude 3.5に新たな「Computer Use(コンピューター操作)」機能を導入し、人間のようにPCやブラウザを操作できる能力を与えた。Claudeは画面を読み取り、カーソルを動かし、ボタンをクリックし、文字を入力できる。これは同種の大規模言語モデルベースのエージェントとして初めて一般公開されたベータ版であり、開発者はClaudeを使ってウェブサイトやアプリケーションを自動ナビゲートできる。Anthropicはこれを実験的機能として位置づけ、主にウェブ上の多段階ワークフローの自動化を目指している。
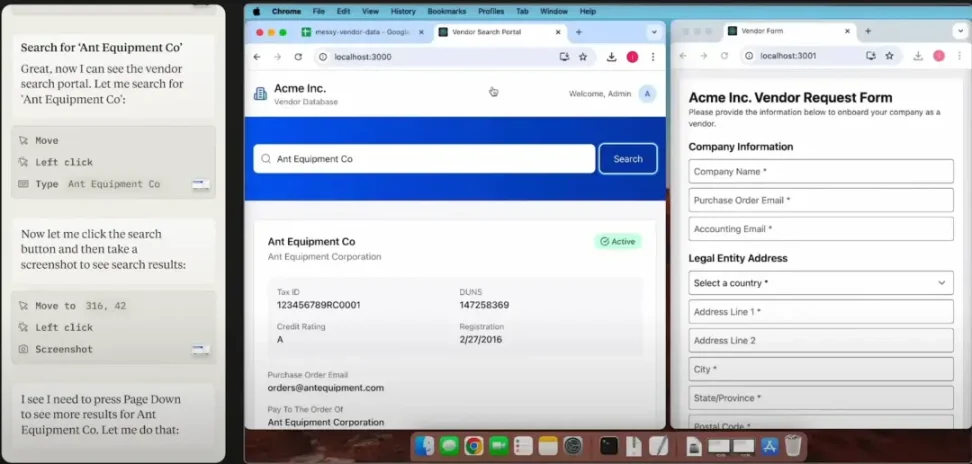
Perplexity – Comet
AIスタートアップのPerplexity(質問応答エンジンで知られる)は、2025年半ばにChrome向けAI駆動の代替ブラウザ「Comet」をリリースした。Cometの核となるのは、アドレスバー(omnibox)に内蔵された対話型AI検索エンジンであり、従来の検索リンクではなく、即時回答と要約を提供する。
さらにCometには、サイドバーに常駐するComet Assistantというエージェントも内蔵されており、複数のサイトにまたがって日常業務を自動実行できる。たとえば、開いているメールを要約したり、会議を設定したり、ブラウザタブを管理したり、ユーザーに代わってウェブ情報を閲覧・収集できる。
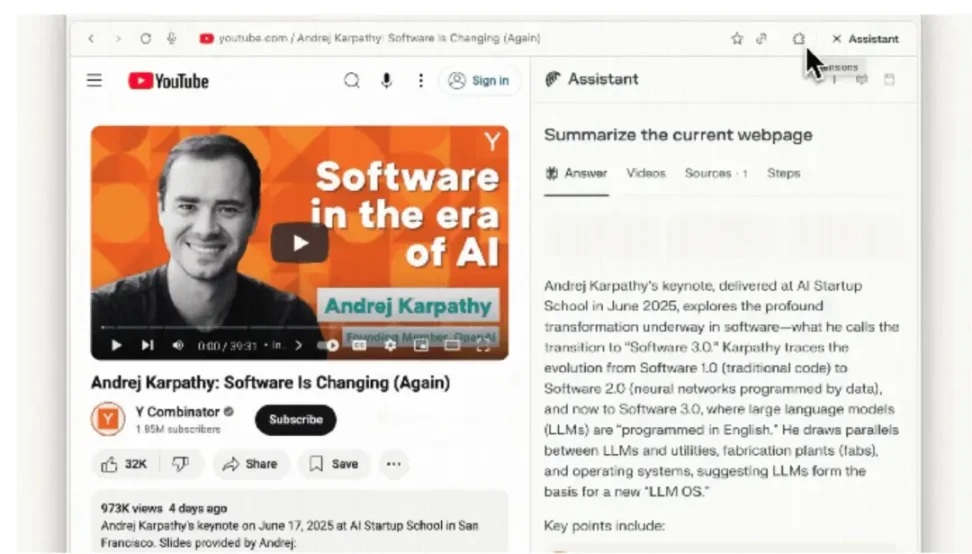
サイドバーインターフェースを通じてエージェントが現在のページ内容を認識できるようにすることで、CometはブラウジングとAIアシスタントをシームレスに統合することを目指している。
ブラウザエージェントの実用的なユースケース
前項では、大手テック企業(OpenAI、Anthropic、Perplexityなど)が、異なる製品形態を通じてブラウザエージェント(browser agents)に機能を付与しようとしているかを見てきた。その価値をより直感的に理解するために、これらの能力が日常生活や企業の業務プロセスにおいてどのように活用されるかを具体的に見てみよう。
日常的なウェブ自動化
#ECと個人ショッピング
非常に実用的なユースケースの一つは、買い物や予約タスクをエージェントに委任することだ。エージェントは固定リストに基づいてオンラインのショッピングカートを自動で埋めて注文でき、複数の小売店間で最安値を検索し、チェックアウトプロセスを代行できる。
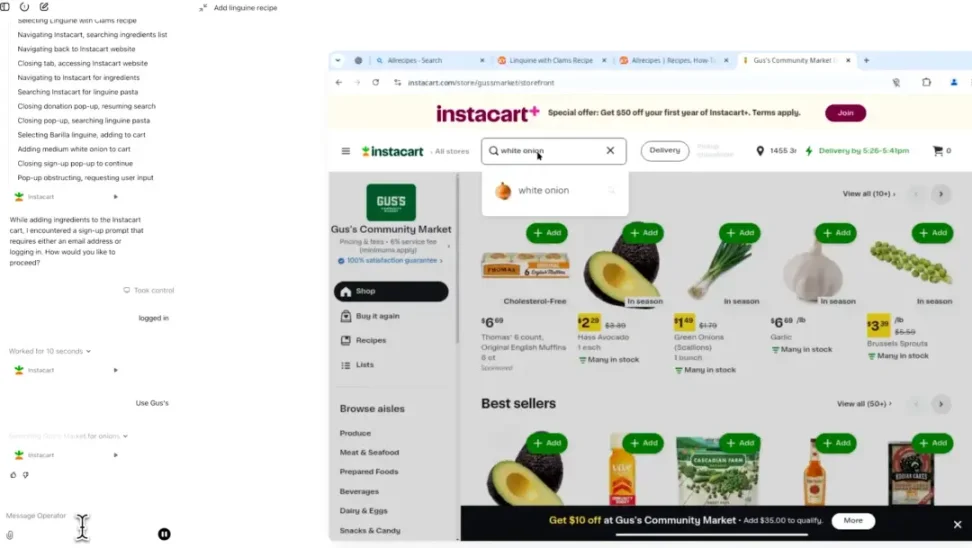
旅行に関しては、次のようなタスクをAIに依頼できる。「来月東京へのフライトを800ドル以下で予約し、無料Wi-Fi付きのホテルも探して」。エージェントは航空会社やホテルのウェブサイトを通じて、フライト検索、オプション比較、乗客情報入力、ホテル予約の全プロセスを処理する。このような自動化レベルは、既存の旅行ロボットを大きく超えるものであり、単なる提案ではなく、購入自体を直接実行する点が特徴だ。
#業務効率の向上
エージェントは、人々がブラウザ内で行う多くの繰り返し作業を自動化できる。たとえば、メールを整理してToDoを抽出したり、複数のカレンダーで空き時間を確認して会議を自動設定したりする。PerplexityのCometアシスタントはすでに、受信トレイの内容を要約したり、スケジュールを追加したりできる。承認を得れば、SaaSツールにログインして定期レポートを生成したり、スプレッドシートを更新したり、フォームを送信したりも可能だ。HR担当者が複数の求人サイトにポジションを自動投稿するHRエージェント、あるいはCRMシステムのリード情報を更新する営業エージェントを想像してほしい。こうした日々の細々とした作業は従来、多くの労働時間を消費していたが、AIはウェブフォームやページ操作の自動化によりこれらを処理できる。
単一タスクだけでなく、複数のネットワークシステムにまたがる完全なワークフローを連携させることも可能だ。こうした各ステップはすべて異なるウェブインターフェースでの操作を必要とするが、まさにこれがbrowser agentの強みである。エージェントはさまざまなダッシュボードにログインして障害対応を行い、新入社員のオンボーディング(複数のSaaSサイトでアカウント作成)などのプロセスを編成することさえできる。本質的に、現在複数のサイトを開いて完了している多段階操作は、すべてエージェントに委ねられる。
現時点での課題と制限
潜在能力は大きいものの、今日のブラウザエージェントは完璧からほど遠い。現行の実装は、長年存在する技術的・インフラ的課題を浮き彫りにしている:
アーキテクチャの不一致
現代のウェブは人間が操作するブラウザ用に設計されており、時間の経過とともに自動化を積極的に阻止する方向に進化してきた。データはしばしば視覚表示用に最適化されたHTML/CSSの中に埋もれ、ホバーやスワイプといったジェスチャーに制限されたり、非公開API経由でのみアクセス可能だったりする。
これに加えて、アンチクローラーや詐欺防止システムがさらに人工的な障壁を設ける。これらのツールはIP評判、ブラウザフィンガープリント、JavaScriptチャレンジ応答、行動分析(マウス移動のランダム性、タイピングリズム、滞在時間など)を組み合わせる。皮肉なことに、AIエージェントが「完璧」に近いほど、すなわち瞬時にフォームを埋め、決してミスをしないほど、悪意ある自動化と見なされやすくなる。これにより、ハードな失敗につながる可能性がある。たとえば、OpenAIやGoogleのエージェントがチェックアウト前のすべてのステップを正常に完了しても、最終的にCAPTCHAや二次セキュリティフィルターでブロックされることがある。
人間向けに最適化されたインターフェースと、ロボットには敵対的な防御層が重なり合うことで、エージェントは脆弱な「人間模倣」戦略を採用せざるを得なくなる。この方法は極めて不安定で成功率が低く(人的介入なしでは完全取引の成功確率は依然として3分の1未満)、容易に失敗する。
信頼とセキュリティ上の懸念
エージェントに完全な制御権を与えるには、通常、ログイン資格情報、Cookie、二要素認証トークン、さらには支払い情報へのアクセスが必要になる。これにより、ユーザーと企業双方が抱く懸念が生じる:
-
エージェントが誤動作したり、悪意のあるサイトに騙されたりしたらどうなるのか?
-
エージェントが何らかの利用規約に同意したり、取引を実行した場合、誰が責任を負うのか?
こうしたリスクを踏まえ、現行のシステムは慎重な姿勢を取っている:
-
GoogleのMarinerはクレジットカード情報の入力や利用規約の同意を行わず、ユーザーに引き渡す。
-
OpenAIのOperatorは、ログインやCAPTCHAチャレンジの際にユーザーに引き継ぎを促す。

AnthropicのClaude駆動エージェントは、セキュリティ上の理由からログインそのものを拒否する場合もある。
結果として、AIと人間の間に頻繁な停止と引き継ぎが生じ、シームレスな自動化体験が損なわれる。
こうした障壁があるにもかかわらず、進展は急速に進行している。OpenAI、Google、Anthropicなどの企業は、毎回の反復で失敗を学び続けている。需要が高まるにつれ、「共進化」が起こる可能性が高い:有利な場面ではサイト側がエージェントに対してよりフレンドリーになり、一方でエージェントも人間の行動模倣能力を高め、既存の障壁を回避していくだろう。
アプローチと機会
現在のブラウザエージェントは、二つのまったく異なる現実に直面している。一方はWeb2の敵対的環境――アンチクローラーやセキュリティ防御が至る所に存在する。他方はWeb3のオープンな環境――自動化がむしろ歓迎されることが多い。この差異が、各種ソリューションの方向性を決定づけている。
以下のソリューションはおおむね二つに分けられる:一つはエージェントがWeb2の敵対環境を乗り越えるためのもの、もう一つはWeb3原生のソリューションである。
ブラウザエージェントが直面する課題は依然として大きいが、新しいプロジェクトが次々と登場し、これらの問題に直接取り組もうとしている。暗号通貨および分散型金融(DeFi)エコシステムは、開放的でプログラマブルであり、自動化に対して敵対的ではないことから、自然な実験場となっている。オープンなAPI、スマートコントラクト、チェーン上での透明性により、Web2世界でよく見られる摩擦の多くが解消される。
以下は四つのソリューションカテゴリであり、それぞれが現時点の主要な制限の一つ以上に対処している:
チェーン上操作向けのネイティブエージェント型ブラウザ
こうしたブラウザはゼロから自律エージェント駆動を前提に設計されており、ブロックチェーンプロトコルと深く統合されている。従来のChromeブラウザとは異なり、チェーン上操作の自動化にはSelenium、Playwright、ウォレットプラグインなどの追加依存が必要だが、ネイティブエージェント型ブラウザは、エージェントが直接呼び出せるAPIと信頼できる実行パスを提供する。
分散型金融(DeFi)では、取引の有効性は「人間らしさ」ではなく暗号署名に依存する。そのため、チェーン上環境では、エージェントはWeb2世界で一般的なCAPTCHA、詐欺検出スコア、デバイスフィンガープリント検査を回避できる。ただし、AmazonのようなWeb2サイトに接続する場合、関連する防御メカニズムを回避することはできず、そのようなシナリオでは通常のロボット対策が依然として発動する。
エージェント型ブラウザの価値は、すべてのサイトに魔法のようにアクセスできる点にあるわけではない。その真価は:
-
ネイティブなブロックチェーン統合:MetaMaskのポップアップやdAppフロントエンドのDOM解析を介さず、内蔵ウォレットと署名サポートを備える。
-
自動化優先設計:プロトコル操作に直接マッピング可能な安定した高レベル指令を提供。
-
セキュリティモデル:細かな権限制御とサンドボックスにより、自動化中に秘密鍵を安全に保つ。
-
パフォーマンス最適化:ブラウザレンダリングやUI遅延なしに、複数のチェーン上呼び出しを並列実行可能。
#事例:Donut
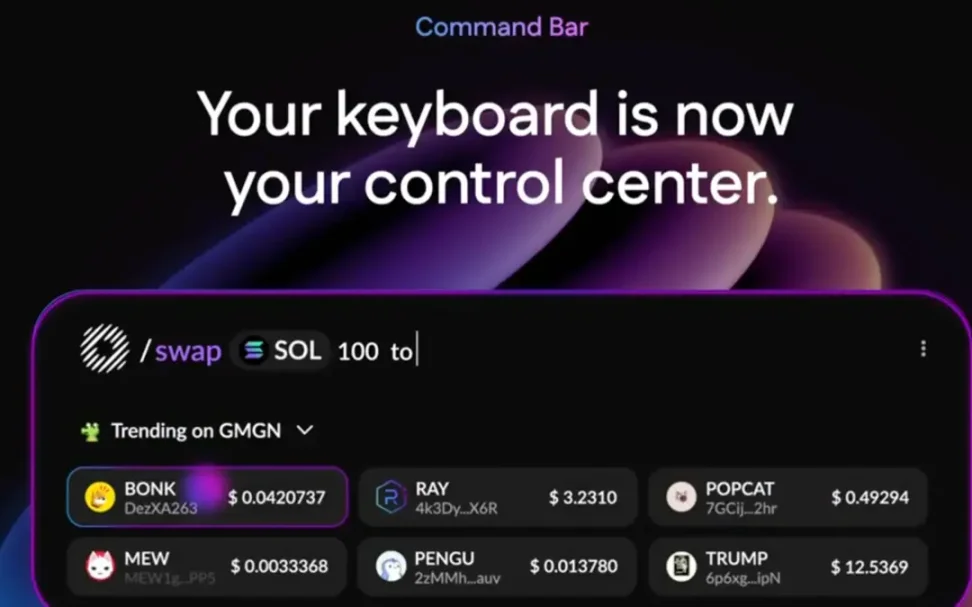
Donutはブロックチェーンデータと操作をファーストクラスのものとして統合する。ユーザー(またはそのエージェント)はトークンのリアルタイムリスク指標をホバーで確認でき、自然言語で「/swap 100 USDC to SOL」といった命令を直接入力できる。Web2の敵対的摩擦ポイントをスキップすることで、DonutはDeFi内でのエージェントのフルスピード稼働を可能にし、流動性、裁定取引、市場効率を高める。
検証可能かつ信頼できるエージェント実行
エージェントに機密権限を与えることはリスクが伴う。これに対するソリューションとして、信頼できる実行環境(TEEs)やゼロ知識証明(ZKPs)を使用し、実行前にエージェントの予期される挙動を暗号的に確認することで、秘密鍵や資格情報を露出せずに対象者と第三者がエージェントの動作を検証できるようにする。
#事例:Phala Network
PhalaはTEE(Intel SGXなど)を用いて実行環境を隔離・保護し、運営者や攻撃者がエージェントのロジックやデータを盗み見たり改ざんしたりするのを防ぐ。TEEはハードウェア支援の「セキュアルーム」のようなもので、機密性(外部からは見えない)と完全性(外部からは変更できない)を保証する。
ブラウザエージェントにとって、これはログイン、セッショントークンの保持、支払い情報の処理ができても、こうした機密データがセキュアルームから漏れ出ることがないことを意味する。使用端末、OS、ネットワークが侵害されても、情報が漏洩することはない。これはエージェントの実用化における最大の障壁の一つ――機密資格情報と操作への信頼問題――を直接緩和する。
分散型構造化データネットワーク
現代のアンチロボット検出システムは、要求が「速すぎる」「自動化されている」かどうかを調べるだけでなく、IP評判、ブラウザフィンガープリント、JavaScriptチャレンジ応答、行動分析(カーソル移動、タイプリズム、セッション履歴など)を総合的に判断する。データセンターIPや完全に再現可能なブラウジング環境からのエージェントは簡単に識別されてしまう。
この問題を解決するために、こうしたネットワークは人間向けに最適化されたウェブページをスクレイピングするのではなく、機械可読なデータを直接収集・提供する、あるいは実際の人間のブラウジング環境を通じてトラフィックをプロキシする。これにより、従来のクローラーが抱える解析・アンチクロールの脆弱性を回避し、エージェントにクリーンで信頼できる入力を提供できる。
エージェントのトラフィックをこうした現実世界のセッションにプロキシすることで、分散ネットワーク(distribution network)はAIエージェントが人間のようにウェブコンテンツにアクセスできるようにし、即座にブロックされることを防ぐ。
#事例
-
Grass:分散型データ/DePINネットワーク。ユーザーが余剰の住宅ブロードバンドを共有し、公共のウェブデータ収集やモデル学習に、エージェントフレンドリーで地理的に多様なアクセス経路を提供。
-
WootzApp:暗号通貨支払いに対応するオープンソースモバイルブラウザ。バックグラウンドエージェントとゼロ知識IDを備え、AI/データタスクを消費者向けに「ゲーム化」する。
-
Sixpence:分散型ブラウザネットワーク。グローバルな貢献者のブラウジングを通じて、AIエージェントのトラフィックをルーティング。
しかし、これは完全な解決策ではない。行動検出(マウス/スクロール軌跡)、アカウントレベルの制限(KYC、アカウント年齢)、フィンガープリントの一貫性チェックは依然としてブロックを引き起こす可能性がある。したがって、分散ネットワークはあくまで基礎的な隠蔽層として捉え、人間模倣型の実行戦略と併用することで最大の効果を発揮する。
エージェント向けウェブ標準(展望)
現在、ますます多くの技術コミュニティや組織が次の問いを探求している:将来のネットユーザーが人間だけでなく自動化エージェント(agent)も含むなら、サイトはそれらと安全かつ準拠した形でどう関わるべきか?
これにより、新興の標準やメカニズムに関する議論が進められており、目標は「信頼できるエージェントのアクセスを許可する」とサイトが明示的に表明し、安全なチャネルを通じてやり取りを行う仕組みを構築することにある。つまり、今日のようにエージェントを「ロボット攻撃」として遮断するのではなく、協調的な関係を築く。
-
「Agent Allowed」タグ:検索エンジンが遵守するrobots.txtのように、将来的にはウェブページコード内に「ここは安全にアクセス可能」とブラウザエージェントに伝えるタグが追加されるかもしれない。たとえば、エージェントで航空券を予約する場合、サイトは多数のCAPTCHAを表示せず、認証済みインターフェースを直接提供する。
-
認証済みエージェント用APIゲートウェイ:サイトは検証済みエージェント専用の入り口を開放できる。「快速レーン」のようなもので、エージェントは人間のクリックや入力を模倣せず、より安定したAPI経路で注文、支払い、データ照会を完了できる。
-
W3Cの議論:ワールド・ワイド・ウェブ・コンソーシアム(W3C)は、「管理された自動化」のための標準化チャネルをどう設計するかをすでに研究している。つまり、将来、信頼できるエージェントがサイトによって識別・受容され、安全性と責任追及可能性を保ったまま運用される、グローバルなルールが誕生する可能性がある。
こうした取り組みはまだ初期段階だが、実現すれば、人間⇔エージェント⇔サイトの関係を大きく改善するだろう。想像してみてほしい:リスク管理を「騙す」ために必死に人間のマウス移動を模倣するのではなく、「公式に許可された」チャネルを通じて堂々とタスクを完了できる未来を。
この道において、暗号原生のインフラが率先して動き出すだろう。なぜなら、チェーン上アプリは初めからオープンAPIとスマートコントラクトに依存しており、自動化に好意的だからだ。一方、広告や詐欺防止体制に依存する従来のWeb2プラットフォームは、依然として慎重な守り姿勢を続けるだろう。しかし、ユーザーと企業が自動化による効率向上を受け入れるにつれ、こうした標準化の試みは、インターネット全体を「エージェント優先アーキテクチャ」へと推し進める重要な触媒となる可能性がある。
結論
ブラウザエージェントは、初期の単純な対話ツールから、複雑なオンラインワークフローを処理できる自律システムへと進化しつつある。この変化は、自動化をユーザーとインターネットのインタラクションの中核インターフェースに直接組み込むという、より広範なトレンドを反映している。生産性向上の可能性は大きいが、根強いアンチロボットメカニズムの突破や、安全性、信頼性、責任ある利用の確保といった課題もまた深刻である。
短期的には、エージェントの推論能力の向上、速度の高速化、既存サービスとの緊密な統合、分散ネットワークの進歩により、信頼性が徐々に高まっていくだろう。長期的には、自動化がサービス提供者とユーザー双方にメリットをもたらすシナリオにおいて、「エージェントフレンドリー」な標準が段階的に普及していくかもしれない。ただし、この変化は均一には進まない:DeFiのような自動化に好意的な環境では採用が早く進む一方、ユーザーのインタラクション制御に強く依存するWeb2プラットフォームでは受け入れが遅れるだろう。
今後、テック企業間の競争はますます、現実世界の制約下でのエージェントのナビゲーション能力、重要なワークフローへの安全な統合能力、多様なオンライン環境で安定した成果を提供できるかどうかに集中していく。そして、これらすべてが最終的に「ブラウザ戦争」を再定義するかどうかは、単なる技術力ではなく、信頼の構築、インセンティブの一致、日常使用における実質的価値の提示にかかっている。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News