

DeepSeek のコストはどのように計算されるのか?
TechFlow厳選深潮セレクト
DeepSeek のコストはどのように計算されるのか?
大規模モデルの競争が激化しており、能力を巡っても競争が繰り広げられ、「コスト」を巡っても競争が行われている。
著者:王璐、定焦One(dingjiaoone)オリジナル
DeepSeekは世界中を完全に動揺させた。
昨日、マスク氏は「地球上で最も賢いAI」であるGrok 3をライブ配信で披露し、「推論能力は現存するすべての既知モデルを上回る」と自称した。推論テスト時間スコアにおいても、DeepSeek R1やOpenAI o1よりも優れていると述べた。最近では国民的アプリ微信がDeepSeek R1の導入を発表し、段階的なテストを開始している。この最強コンビは、AI検索分野の大きな変化を予感させるものとして注目されている。
現在、マイクロソフト、NVIDIA、ファーウェイクラウド、テンセントクラウドなど、世界中の多くの大手テック企業がすでにDeepSeekを採用している。ネットユーザーは占い、宝くじ予測などユニークな使い方を開発しており、その人気は直接的に収益に転換され、DeepSeekの評価額は急騰し、最高で100億ドルに達した。
DeepSeekが注目を集めた理由は、無料かつ使いやすいという点だけでなく、わずか557.6万ドルのGPUコストで、OpenAI o1と同等の性能を持つDeepSeek R1モデルを訓練できたことにある。過去数年の「百モデル戦争」において、国内外のAI大規模モデル企業は数十億から数百億ドルもの資金を投入してきた。一方、Grok 3が「世界で最も賢いAI」となるために要したコストも膨大であり、マスク氏によれば20万枚のNVIDIA GPU(単価約3万ドル)が累計で使用されたが、業界関係者の推定ではDeepSeekは1万枚台のGPUで済んでいる。
しかし、コスト面でDeepSeekに挑戦する動きもある。最近、李飛飛チームは、クラウド計算費用50ドル未満で推論モデルS1を訓練したと発表した。S1は数学およびコーディング能力テストにおいて、OpenAIのo1やDeepSeekのR1と同等のパフォーマンスを示した。ただし注意すべきは、S1は中規模モデルであり、DeepSeek R1のような数千億パラメータ級とは差があることだ。
それでも、50ドルから数百億ドルという巨大な訓練コストの差異により、人々は深く疑問を持つようになっている。すなわち、DeepSeekの能力はどこまで高く、なぜ各社がそれを追い越そうとしているのか。また、大規模モデルの訓練には一体いくらかかるのか? どの工程に関わるのか? 将来的にさらにコストを下げることは可能なのか?
「以偏概全」されがちなDeepSeek
業界関係者によると、これらの疑問に答える前に、いくつかの概念を明確にする必要がある。
まず第一にDeepSeekに対する「以偏概全」的理解がある。人々が驚嘆しているのは多数ある大規模モデルの中の一つ――推論専用モデルDeepSeek-R1であるが、DeepSeekには他にもさまざまな大規模モデルがあり、それぞれ機能が異なる。そして557.6万ドルという金額は、汎用大規模モデルDeepSeek-V3の訓練におけるGPU利用コストであり、純粋な計算リソースコストと理解できる。
簡単な比較:
-
汎用大規模モデル:
明確な指示を受け取り、ステップを分解する。ユーザーはタスク内容を詳細に説明する必要があり、回答順序(例:最初に要約してからタイトルを出すか、逆か)も指定する。
応答速度が速く、確率予測(迅速反応)に基づき、大量データから答えを予測する。
-
推論大規模モデル:
シンプルで目的明確なタスクを受け取る。ユーザーが必要なことを直接言えば、モデル自身で計画を立てる。
応答速度が遅く、連鎖的思考(ゆっくり考える)に基づき、問題を段階的に推論して答えを導く。
両者の主な技術的違いは訓練データにあり、汎用モデルは「問題+答え」、推論モデルは「問題+思考プロセス+答え」である。
第二に、DeepSeekの推論モデルDeepSeek-R1の注目度が高いことから、多くの人が誤って「推論モデルは必ず汎用モデルより高度だ」と考えている。
確かに、推論モデルは先端的なモデルタイプであり、大規模モデルの事前学習パラダイムが限界に達した後、OpenAIが推論フェーズで計算量を増やす新しいアプローチとして提唱したものである。汎用モデルと比べて、推論モデルはより高コストで、訓練期間も長くなる。
しかし、それが推論モデルが常に汎用モデルより優れているとは限らない。特定の種類の問題に対しては、むしろ推論モデルが不必要になる場合もある。
大規模モデル分野の著名な専門家である劉聡氏は「定焦One」に対し、ある国の首都や地方の省都を尋ねるような質問では、推論モデルよりも汎用モデルの方が適していると説明した。

DeepSeek-R1が単純な質問に対して過剰に思考している様子
彼は、このような単純な質問に対して、推論モデルは回答効率が汎用モデルより低く、計算リソースコストも高くつくだけでなく、過剰思考が起こり、最終的に誤った答えを出す可能性さえあると指摘した。
彼の提案では、数学の難問やチャレンジングなコーディングなどの複雑なタスクには推論モデルを使用し、要約、翻訳、基本的なQAなどの簡単なタスクには汎用モデルの使用がより効果的である。
第三にDeepSeekの真の実力はどこまでなのかという点がある。
権威あるランキングと業界関係者の意見を総合すると、「定焦One」は推論モデルと汎用モデルの二つの領域で、DeepSeekの位置づけを行った。
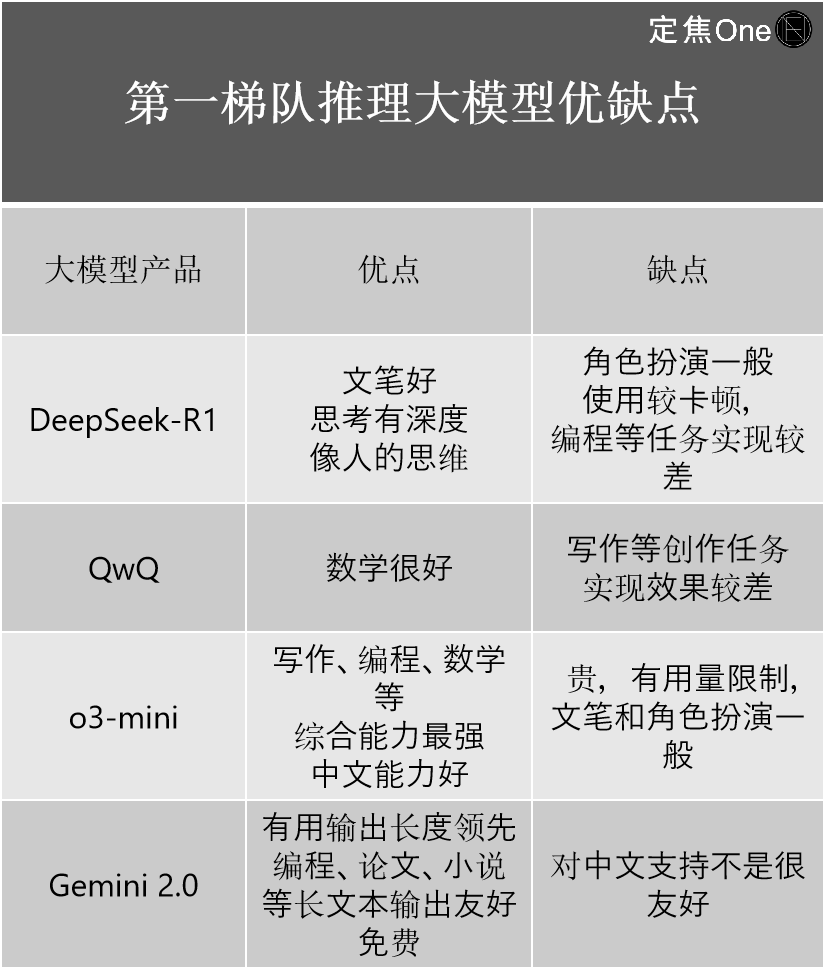
推論モデルの第一陣営には主に4社:海外のOpenAIのoシリーズ(例:o3-mini)、GoogleのGemini 2.0;国内のDeepSeek-R1、アリババのQwQ。
複数の関係者が指摘するように、外部ではDeepSeek-R1が中国国内トップレベルのモデルとしてOpenAIを追い抜いたように議論されているが、技術的には最新のOpenAI o3と比べるとまだ一定の差がある。
重要な意義は、国内外のトップレベル間の差を大幅に縮めたことにある。「以前の差は2〜3世代だったが、DeepSeek-R1の登場で0.5世代まで縮まった」とAI業界のベテラン江樹氏は語った。
彼は自身の使用経験に基づき、4社の長所と短所を紹介した。
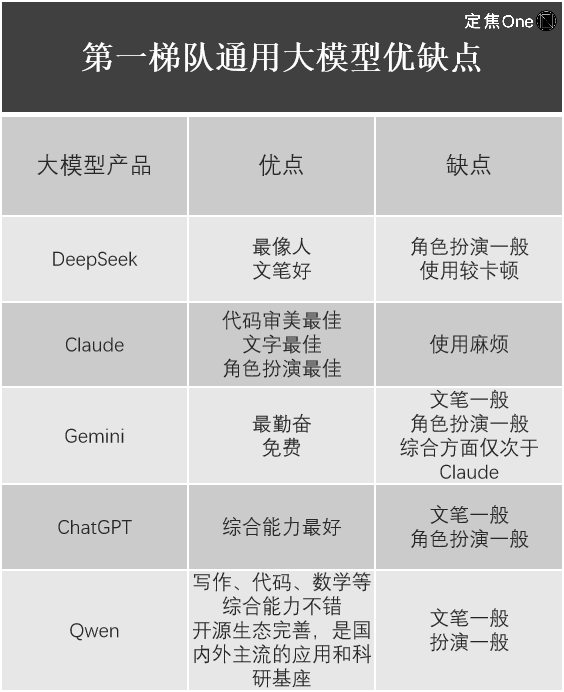
汎用モデル分野では、LM Arena(大規模言語モデル(LLM)のパフォーマンスを評価・比較するためのオープンソースプラットフォーム)のランキングによると、第一陣営には5社:海外のGoogle Gemini(クローズドソース)、OpenAI ChatGPT、Anthropic Claude;国内のDeepSeek、アリババ Qwen。
江樹氏は、これらを使用した体験についても列挙した。
明らかに、DeepSeek-R1がグローバルテック界を震撼させたことは間違いないが、各社の大規模モデル製品にはそれぞれの長所と短所があり、DeepSeekもすべてのモデルで完璧ではない。例えば劉聡氏は、DeepSeekが新たにリリースした画像理解・生成に特化したマルチモーダルモデルJanus-Proの使用感は普通だと感じている。
大規模モデルの訓練には、一体いくらかかるのか?
再び大規模モデルの訓練コストの問題に戻ろう。大規模モデルとは、どのようにして生まれるのか?
劉聡氏によると、大規模モデルの誕生は主に事前学習-後続学習の2段階に分けられる。これを子供に例えるなら、生まれたばかりで泣くだけの状態から、大人の言うことを理解できるようになり、自ら大人に話しかけるようになる過程である。
事前学習とは主に訓練データの処理を指す。例えば大量のテキストデータをモデルに入力し、知識の吸収を促すが、この時点では知識はあるものの活用方法はまだ知らない。
後続学習では、獲得した知識をどう使うかを教える。これにはモデルの微調整(SFT)と強化学習(RLHF)の2つの手法がある。
劉聡氏は、汎用モデルでも推論モデルでも、国内でも国外でも、すべての企業がこのプロセスに従っていると述べた。江樹氏も「定焦One」に、全社がTransformerモデルを使用しており、最も基礎的なモデル構成と訓練ステップには本質的な違いがないと語った。
複数の関係者が指摘するように、各社の訓練コストは大きく異なり、主にハードウェア、データ、人件費の三つの部分に集中している。それぞれの部分でも異なる方式を採用でき、対応するコストも異なる。
例えば劉聡氏は、ハードウェアを購入するかリースするかによって価格差は大きく、購入の場合初期投資が大きいが、その後は大幅にコストが下がり、基本的に電気代のみとなる。リースの場合は初期投資は小さいが、このコストは常に発生する。使用する訓練データについても、既存データを購入するか、自社で人手で収集するかでコストは大きく異なる。また、訓練ごとのコストも異なる。初回はクローラーを作成しデータをフィルタリングする必要があるが、次バージョンでは前バージョンの操作を再利用できるためコストが低下する。さらに、最終的なモデル公開までのバージョン反復回数もコストに影響するが、大規模モデル企業はこの点について極めて慎重である。
つまり、各工程には多くの高額な隠れたコストが含まれている。
外部ではGPUの数から推定され、最先端モデルではGPT-4の訓練コストが約7800万ドル、Llama3.1が6000万ドル以上、Claude3.5が約1億ドルとされていた。しかし、これらの最先端モデルはすべてクローズドソースであり、各社に計算資源の無駄遣いがあるかどうかは外部からは不明だった。同クラスのDeepSeekが557.6万ドルという数字を提示するまで。

画像出典 / Unsplash
注意すべきは、557.6万ドルはDeepSeekの技術報告書に記載された基盤モデルDeepSeek-V3の訓練コストであるということだ。「V3の訓練コストは、最後の成功した訓練のコストを示すに過ぎず、それ以前の研究、アーキテクチャやアルゴリズムの試行錯誤などのコストは含まれていない。またR1の具体的な訓練コストについては論文に記載されていない」と劉聡氏は述べた。つまり、557.6万ドルはモデルの総コストのごく一部にすぎない。
半導体市場分析・予測会社SemiAnalysisによると、サーバー設備投資、運用コストなどを考慮すると、DeepSeekの総コストは4年間で25.73億ドルに達する可能性がある。
業界関係者は、他の大規模モデル企業の数百億ドル規模の投資と比べても、25.73億ドルであってもDeepSeekのコストは低いと考えている。
さらに、DeepSeek-V3の訓練には2048枚のNVIDIA GPUしか必要とせず、GPU時間も278.8万時間にとどまる。一方、OpenAIは数万枚のGPUを消費し、MetaのLlama-3.1-405Bの訓練には3084万GPU時間がかかっている。
DeepSeekはモデル訓練フェーズでの効率が高いだけでなく、推論呼び出しフェーズでもより効率的でコストが低い。
DeepSeekが公表した各モデルのAPI価格(開発者はAPIを通じて大規模モデルを呼び出し、テキスト生成、対話、コード生成などの機能を実現できる)を見れば、そのコストが「OpenAIたち」よりも低いことがわかる。通常、開発コストが高いAPIは高い価格設定でコスト回収を行う。
DeepSeek-R1のAPI価格は、100万トークンの入力あたり1元(キャッシュヒット時)、100万トークンの出力あたり16元。一方、OpenAIのo3-miniは、100万トークンの入力(キャッシュヒット時)と出力がそれぞれ0.55ドル(4元)、4.4ドル(31元)である。
キャッシュヒットとは、キャッシュからデータを読み取って再計算やモデル呼び出しを回避することを意味し、処理時間を短縮しコストを削減できる。業界ではキャッシュヒットとミスを区別することでAPI価格競争力を高めており、低価格により中小企業の導入も容易になっている。
最近割引期間が終了したDeepSeek-V3は、もともとの100万トークン入力0.1元(キャッシュヒット時)、100万トークン出力2元から、それぞれ0.5元、8元に値上げされたが、依然として他の主要モデルより安い。
大規模モデルの総訓練コストを正確に見積もりにくいが、業界関係者は一致してDeepSeekが現時点で一流大規模モデルの最低コストを代表していると考えており、今後各社はDeepSeekを基準にコスト削減を目指すだろうと見ている。
DeepSeekのコスト削減の示唆
DeepSeekはどこでコストを節約したのか? 業界関係者の意見を総合すると、モデル構造-事前学習-後続学習の各段階で最適化が行われている。
例えば回答の専門性を保つため、多くの大規模モデル企業はMoEモデル(混合専門家モデル)を採用している。複雑な問題に対して、モデルがサブタスクに分解し、それぞれを異なる専門家に割り当てる。多くの企業がこのモデルを言及しているが、DeepSeekは究極の専門家特化レベルに到達している。
その秘訣は、細粒度の専門家分割(同じカテゴリ内の専門家をさらにサブタスクに細分化)と共有専門家の隔離(知識の冗長性を軽減するために一部の専門家を隔離)にある。これにより、MoEのパラメータ効率とパフォーマンスが大幅に向上し、より高速かつ正確な回答が可能になる。
ある関係者の試算では、DeepSeekMoEは約40%の計算量でLLaMA2-7Bとほぼ同等の効果を達成している。
データ処理も大規模モデル訓練の障壁の一つであり、各社は計算効率を高めながらメモリや帯域などのハードウェア要求を下げようと工夫している。DeepSeekが見つけた方法は、データ処理時にFP8低精度訓練(ディープラーニングの訓練を加速する技術)を使用することである。「これは既知のオープンソースモデルの中で比較的リードしている。大多数の大規模モデルはFP16またはBF16混合精度訓練を使用しており、FP8の訓練速度ははるかに速い」と劉聡氏は述べた。
後続学習の強化学習において、戦略最適化は大きな難点であり、大規模モデルがより良い意思決定を行うようにすることに相当する。例えばAlphaGoは戦略最適化により、囲碁で最適な着手を選択する方法を学んだ。
DeepSeekはPPO(近接戦略最適化)ではなくGRPO(グループ相対戦略最適化)を選択している。両者の主な違いは、アルゴリズム最適化時に価値モデルを利用するかどうかであり、前者はグループ内相対報酬で優位性関数を推定し、後者は個別の価値モデルを使用する。モデルが一つ少ないため、計算リソースの要求も自然に小さくなり、コスト削減につながる。
また推論層では、従来の多頭部注意力(MHA)ではなく多頭部潜在注意力(MLA)を使用することで、GPUメモリ使用量と計算複雑さを著しく削減し、直接的なメリットとしてAPI料金の低下が実現している。
ただ、今回のDeepSeekが劉聡氏に与えた最大の示唆は、大規模モデルの推論能力をさまざまな角度から向上できるという点であり、純粋なモデル微調整(SFT)や純粋な強化学習(RLHF)だけで優れた推論モデルが作れることを示した。
画像出典 / Pexels
つまり、現在の推論モデルの作成方法には4通りある:
第一:純粋な強化学習(DeepSeek-R1-zero)
第二:SFT+強化学習(DeepSeek-R1)
第三:純粋なSFT(DeepSeek蒸留モデル)
第四:純粋なプロンプト(低コスト小規模モデル)
「以前は業界内でSFT+強化学習が主流で、誰も純粋なSFTや純粋な強化学習だけで良い結果が得られると考えていなかった」と劉聡氏は述べた。
DeepSeekのコスト削減は、技術的な示唆を与えるだけでなく、AI企業の成長戦略にも影響を与えている。
英諾天使基金パートナーの王晟氏は、AGI方向性を追求するAI産業には一般的に2つの異なる戦略があると紹介した。一つは「計算力軍拡」型で、技術・資金・計算力を集中投入し、まずモデル性能を高水準に引き上げ、その後に産業応用を考えるもの。もう一つは「アルゴリズム効率」型で、初めから産業応用を目標とし、アーキテクチャ革新とエンジニアリング能力によって低コストかつ高性能なモデルを提供する。
「DeepSeekの一連のモデルは、性能の天井が上がらない状況下で、能力向上ではなく効率最適化に重点を置く戦略の実現可能性を証明した」と王晟氏は述べた。
関係者たちは、今後アルゴリズムの進化とともに、大規模モデルの訓練コストはさらに低下すると信じている。
ARKインベストメントマネジメントの創業者兼CEO「ウッド姉妹(Woodie)」は、DeepSeek以前、AI訓練コストは年間75%低下し、推論コストは85〜90%低下していたと指摘した。王晟氏も、年初にリリースされたモデルを年末に再リリースすれば、コストは大幅に下がり、1/10になる可能性もあると述べた。
独立系調査機関SemiAnalysisは最近の分析レポートで、推論コストの低下はAIの進歩を示す重要な指標の一つであると指摘した。かつてスーパーコンピュータや多数のGPUが必要だったGPT-3の性能が、現在ではノートパソコンに搭載された小型モデルでも同等の効果を実現できるようになった。コストも大きく下がっており、AnthropicのCEOダリオ氏は、アルゴリズムによる価格低下でGPT-3レベルの品質がすでに1200倍安くなっていると述べている。
将来、大規模モデルのコスト削減スピードはますます加速していくだろう。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














