

DeepSeek新モデルの核心に迫る――なぜAI業界を震撼させたのか?
TechFlow厳選深潮セレクト
DeepSeek新モデルの核心に迫る――なぜAI業界を震撼させたのか?
DeepSeek-R1は純粋な強化学習手法を採用し、GPT-4oやClaude Sonnet 3.5といった最先端モデルと同等の性能を達成した。
腾讯科技『AI未来指北』特別執筆者:郝博陽
わずか一か月も経たないうちに、DeepSeekは再び世界中のAI業界を震撼させた。
昨年12月、DeepSeekが発表したDeepSeek-V3は、世界的なAI分野で大きな波紋を広げた。極めて低い訓練コストでありながら、GPT-4oやClaude Sonnet 3.5といったトップクラスのモデルと同等の性能を実現し、業界に衝撃を与えた。当時、腾讯科技ではこのモデルについて詳細に分析し、低コストかつ高効率を両立させる技術的背景を、最もシンプルな方法で解説した。
前回とは異なり、今回リリースされた新モデル「DeepSeek-R1」はコストが低いだけでなく、技術的にも大幅な進化を遂げており、さらにオープンソースという点でも注目される。
この新モデルは高いコストパフォーマンスという強みを継承し、わずか1/10のコストでGPT-o1レベルの性能を達成している。
そのため、多くの関係者は「DeepSeekがOpenAIの後継になる」とまで声を上げており、特にその学習手法におけるブレークスルーに注目が集まっている。
たとえば、元Meta AIスタッフで有名なAI論文紹介アカウントのElvis氏は、本論文は「至宝」だと評価。大規模言語モデルの推論能力を向上させる複数のアプローチを探求し、より明確な「湧出特性(emergent properties)」を発見したとしている。

また、AI業界の大物Yuchen Jin氏は、DeepSeek-R1論文の中で提示された「純粋な強化学習(RL)によりモデルが自ら学習・自己反省的推論を行うようになった」という発見の意義は非常に大きいと指摘する。
英偉達GEAR LabプロジェクトリーダーのJim Fan氏もツイッターで言及。DeepSeek-R1は、容易に騙されがちな学習用報酬モデルではなく、「ハードコーディングされたルールによって計算された真の報酬」を利用したことで、モデルに自己反省と探索行動の「湧出(emergence)」を促したと述べている。
こうした極めて重要な発見がすべてDeepSeek-R1によって完全にオープンソース化されたため、Jim Fan氏は「これは本来OpenAIがやるべきことだった」とまで評した。

ここで問題となるのは、彼らが言う「純粋なRLによる学習」とは一体何か?また、モデルに現れた「Aha moment(ひらめきの瞬間)」がなぜAIの「湧出能力」を証明するのか?そして私たちが最も知りたいのは、DeepSeek-R1のこの画期的な革新が、AI分野の将来にどのような意味を持つのか、ということだ。
最もシンプルなレシピで、最も純粋な強化学習へ回帰する
o1リリース以降、「推論の強化」は業界で最も注目される手法となった。
一般的に、モデルの訓練過程では、推論能力を高めるために固定された訓練法を採用することが多い。
しかしDeepSeekチームは、R1の訓練において、まったく異なる3つの技術的アプローチ――直接的な強化学習訓練(R1-Zero)、多段階の漸進的訓練(R1)、およびモデル蒸留――を同時に試み、すべて成功させた。特に多段階漸進的訓練とモデル蒸留には多くの革新的要素が含まれており、業界への影響は大きい。
中でも最も注目すべきは、やはり「直接的な強化学習」のアプローチである。DeepSeek-R1は、この手法の有効性を初めて証明したモデルなのだ。
まず、従来のAI推論能力の訓練手法を振り返ってみよう。通常はSFT(監視付きファインチューニング)において大量の「思考の連鎖(Chain of Thought: CoT)」の例を追加し、例示やプロセス報酬モデル(PRM)のような複雑なニューラルネットワーク報酬モデルを使って、モデルにCoT方式での思考を学ばせる。
場合によってはモンテカルロ木探索(MCTS)を導入し、複数の可能性の中から最適な選択肢を探索させるケースもある。
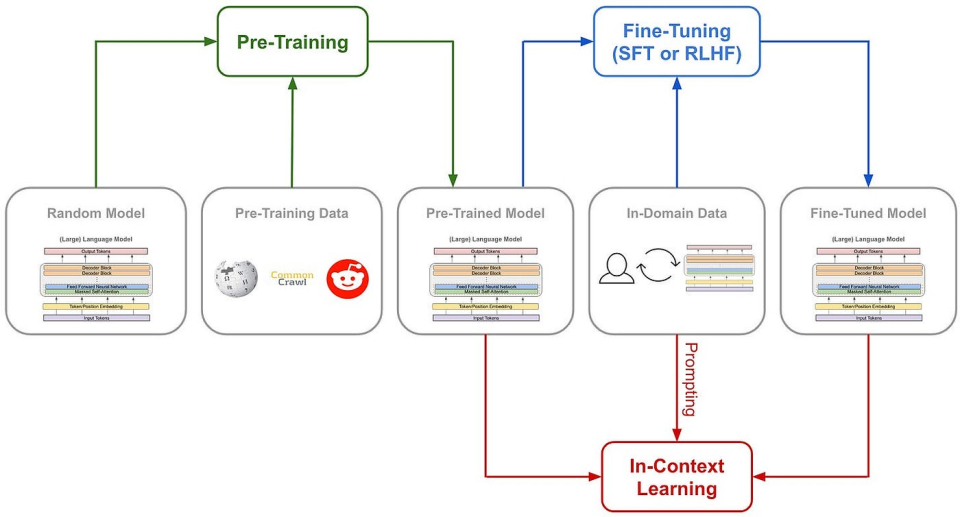
(従来のモデル訓練フロー)
しかし、DeepSeek-R1 Zeroは前例のない道――「純粋な」強化学習の道を選んだ。事前に設定されたCoTテンプレートや監視付き微調整(SFT)を完全に捨て去り、単純な報酬・ペナルティ信号のみでモデルの行動を最適化する。
これは、あらゆる例や指導を与えられず、ただ繰り返す試行錯誤とフィードバックを通じて解法を学ぶ天才児童を育てるようなものだ。
DeepSeek-R1 Zeroが持つのは、AIの推論能力を引き出すための、ごくシンプルな報酬システムだけである。
そのルールはたった2つ:
1. 正確性報酬:応答が正しいかどうかを評価し、正解なら加点、誤答なら減点。評価方法もシンプル。たとえば、確定的な答えを持つ数学問題では、モデルは指定された形式(例:<answer> と </answer> の間)で最終解答を提出しなければならない。プログラミング問題では、コンパイラが予め定義されたテストケースに基づいてフィードバックを生成できる。
2. フォーマット報酬:モデルが思考プロセスを<think>と</think>のタグ間に記述することを強制する。守らなければ減点、守れば加点。
強化学習(RL)過程におけるモデルの自然な進展を正確に観察するため、DeepSeekは意図的にシステムプロンプトをこのような構造的フォーマットに限定し、特定の内容に偏るバイアス(たとえば、自己反省的推論を強制したり、特定の問題解決戦略を推奨したり)を避けた。

(R1 Zeroのシステムプロンプト)
このシンプルなルールのもと、AIはGRPO(Group Relative Policy Optimization)の枠組み内で自己サンプリング+比較を行い、自己改善を遂げる。
GRPOの仕組み自体は単純で、グループ内のサンプル同士を相対的に比較して方針勾配(policy gradient)を計算することで、訓練の不安定性を低減しつつ学習効率を高める。
簡単に言えば、教師が出した問題に対してモデルが複数の回答を生成し、上記の報酬・ペナルティルールでそれぞれに採点を行った後、「高得点を目指し、低得点を避ける」という原則に基づいてモデルを更新する。
このプロセスの流れは次の通り:
入力問題 → モデルが複数の回答を生成 → ルールシステムが採点 → GRPOが相対的優位性を計算 → モデルを更新
この直接的な訓練法にはいくつかの顕著な利点がある。第一に、訓練効率が向上し、短時間での完了が可能になる。第二に、SFTや複雑な報酬モデルが不要となるため、計算リソースの消費が大幅に削減される。
もっと重要なのは、この方法が本当にモデルに「考える」ことを教えた点であり、しかもそれは「ひらめき(Aha moment)」という形で学ばれたのだ。
自分の言葉で、「頓悟」の中で学ぶ
この極めて「原始的」な方法によって、モデルが本当に「考えること」を学んだとどうやってわかるのか?
論文には印象的な事例が記録されている。複雑な数学式 √a - √(a + x) = x を扱う際、モデルは突然「Wait, wait. Wait. That's an aha moment I can flag here」(待て、待て、これは記録に値する“あっ!”という瞬間だ)と言い出し、その後解法プロセス全体を再検討した。この人間のような「ひらめき」は完全に自発的に生じたもので、事前にプログラムされたものではない。
こうした「頓悟」こそが、モデルの思考能力が飛躍する瞬間なのである。
DeepSeekの研究によれば、モデルの進歩は均等に進行するわけではない。強化学習の過程で、応答の長さが突然大きく伸びることがあり、これらの「ジャンプポイント」はしばしば解法戦略の質的変化と一致する。このパターンは、長期的な思索の後に訪れる人間の「突然のひらめき」に酷似しており、何らかの深い認知的突破を示唆している。
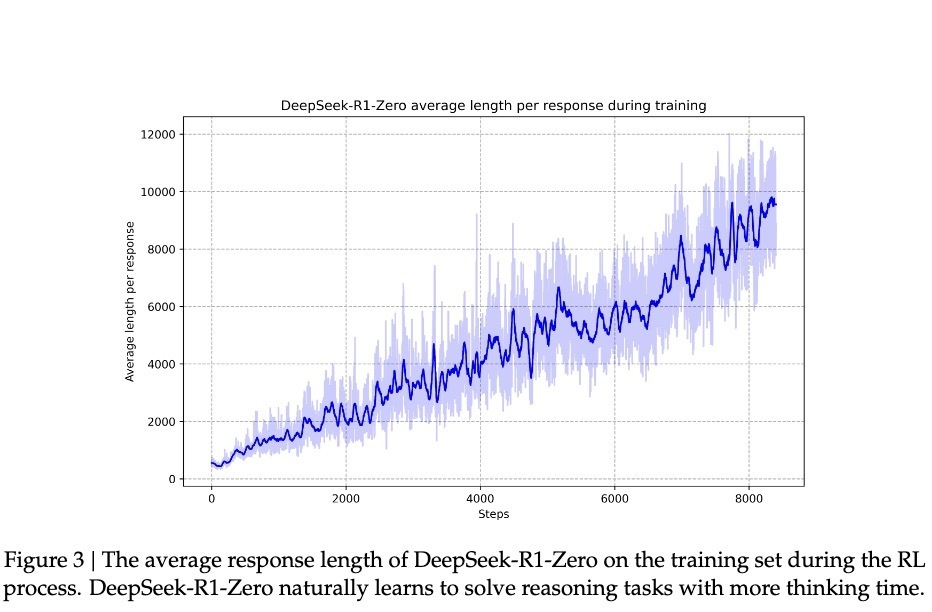
こうした「頓悟」を伴う能力向上により、R1-Zeroは数学界で名高いAIMEコンテストでの正解率を、初期の15.6%から71.0%まで引き上げた。同一問題を複数回試行させた場合、正解率はさらに86.7%に達した。これは単に「見たことがあるから解ける」レベルではない。AIMEの問題は深い数学的直感と創造的思考を必要とし、機械的な公式適用では太刀打ちできない。モデルが真に推論できなければ、このような向上は不可能だ。
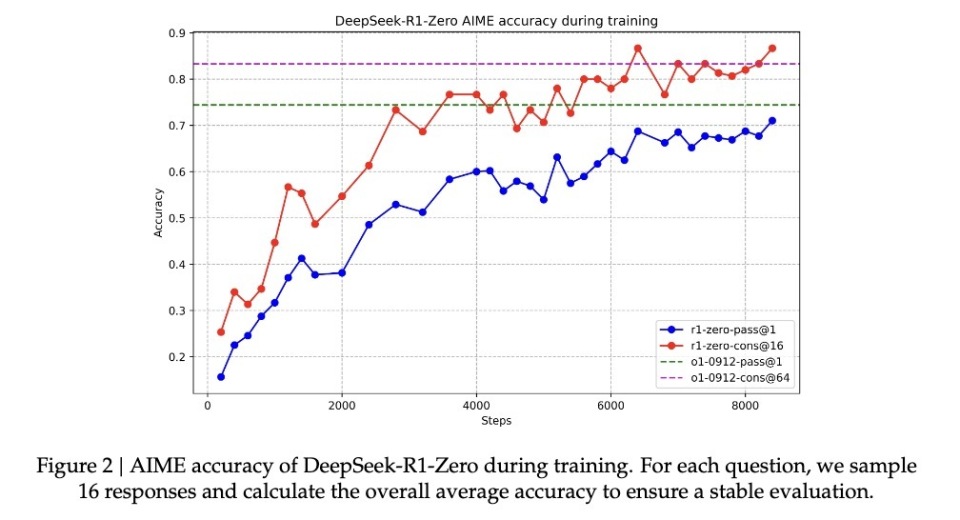
もう一つの決定的証拠は、モデルの応答長が問題の複雑さに応じて自然に調整される点にある。この適応的振る舞いは、単なるテンプレート適用ではなく、問題の難易度を真正に理解し、それに応じてより多くの「思考時間」を投入していることを示している。人間が簡単な足し算と複雑な積分で自然に思考時間を調整するように、R1-Zeroも同様の知性を示している。
最も説得力があるのは、おそらく転移学習能力の存在だろう。全く異なるプログラミングコンテストプラットフォーム「Codeforces」において、R1-Zeroは人類参加者の96.3%以上を上回る実力を発揮した。この他領域への汎化能力は、モデルが特定ドメインの解法テクニックを暗記しているのではなく、普遍的な推論能力を獲得していることを示している。
頭脳明晰だが、話しぶりが乱雑な天才
R1-Zeroが驚異的な推論能力を示しているにもかかわらず、研究者たちはすぐに深刻な問題に気づいた:その思考プロセスは往々にして人間には理解しがたい。
論文は率直に、この純粋な強化学習で訓練されたモデルには「poor readability(可読性の低さ)」と「language mixing(言語混在)」の問題があると指摘している。
この現象はよく理解できる。R1-Zeroは報酬・ペナルティ信号のみで行動を最適化しており、「模範解答」となる人間の示範が一切存在しない。まるで天才児が独自の解法を編み出し、常に成功するものの、それを他人に説明するときは支離滅裂になってしまうようなものだ。解法中に複数の言語を使い分けたり、特殊な表現法を開発したりすることで、その推論過程は追跡不能になりやすい。
この問題を解決するために、研究チームは改良版「DeepSeek-R1」を開発した。より伝統的な「コールドスタートデータ(cold-start data)」と多段階訓練プロセスを導入することで、R1は強力な推論能力を維持しつつ、人間にとって理解しやすい形で思考過程を表現する方法を学んだ。これは、あの天才児にコミュニケーションコーチをつけ、自分の考えを明確に伝える術を教えるようなものだ。
この調整後、DeepSeek-R1はOpenAI o1と同等、あるいは一部でそれ以上の性能を発揮した。MATHベンチマークでは77.5%の正解率を記録し、o1の77.3%とほぼ同じ。さらに難易度の高いAIME 2024では71.3%の正解率を達成し、o1の71.0%を上回った。コード分野では、Codeforces評価で2441ポイントを記録し、96.3%の人間参加者を凌駕した。
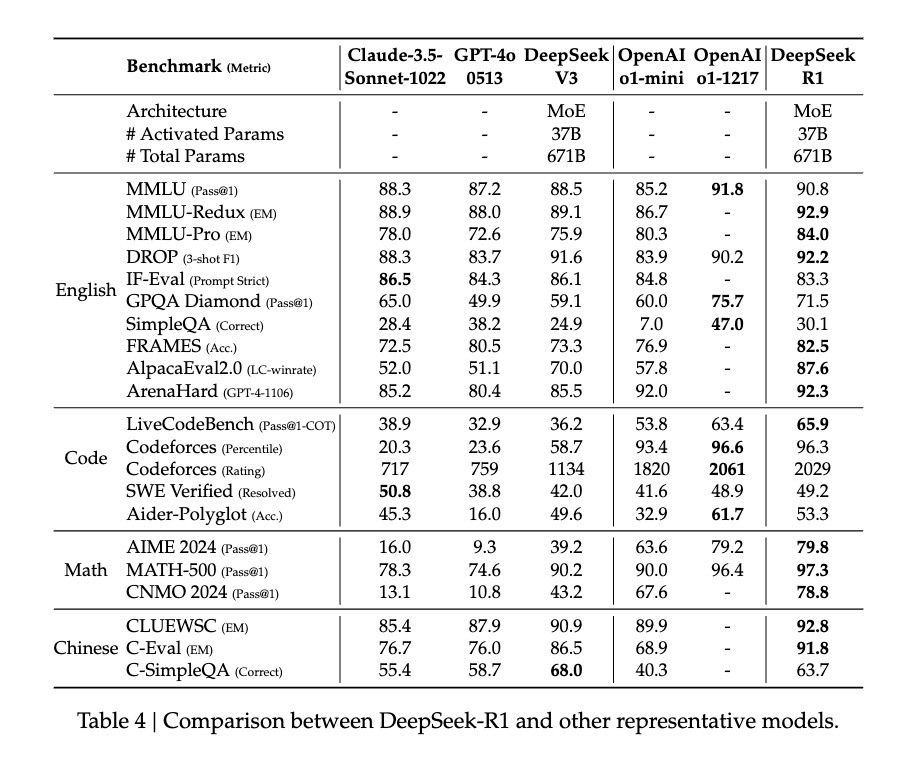
しかし、実はDeepSeek-R1 Zeroの潜在能力はさらに大きいかもしれない。AIME 2024テストで多数決メカニズムを使用した場合、86.7%の正解率を達成した――この成績はOpenAIのo1-0912さえ超えている。この「複数回試行すればより正確になる」という特徴は、R1-Zeroが単なる解法パターンの記憶ではなく、何らかの基本的な推論フレームワークを習得している可能性を示唆している。論文のデータによると、MATH-500からAIME、GSM8Kに至るまで、モデルは安定した他領域への汎化性能を示しており、特に創造的思考を要する複雑な問題で優れている。この広範な性能は、R1-Zeroが本当に基礎的な推論能力を育んできた可能性を示しており、従来のタスク特化型最適化モデルとは明確に対照的である。
したがって、話しぶりは乱雑でも、DeepSeek-R1 Zeroこそが真に「推論を理解した天才」なのかもしれない。
純粋な強化学習――AGIへの意外な近道
DeepSeek-R1の発表が業界の注目を「純粋な強化学習」に集中させた理由は、それがまさにAI進化の新たな道を開いたと言えるほど画期的だからだ。
R1-Zero――完全に強化学習によって訓練されたこのAIモデルは、驚くべき汎用的推論能力を示した。数学コンテストでの驚異的な成績だけでなく、
より重要なのは、R1-Zeroが単に「思考を模倣」しているのではなく、何らかの形の真の「推論能力」を自ら発展させたことだ。
この発見は、我々の機械学習に対する認識を根本から変えかねない。従来のAI訓練法は、根本的な過ちを繰り返してきたのではないか。つまり、AIに人間の思考方法を模倣させすぎてきたのだ。業界は、監視学習がAI発展において果たす役割を改めて問い直す必要がある。純粋な強化学習を通じて、AIシステムは予め決められた解決枠組みに縛られず、より原初的な問題解決能力を発展させることが可能になる。
R1-Zeroは出力の可読性に明らかな欠陥を持つが、この「欠陥」そのものがむしろその思考様式の独自性を裏付けている可能性がある。天才児が独自の解法を編み出したが、それを普通の言語で説明できないのと同じだ。これこそが示唆するのは、真の汎用人工知能(AGI)には、人間とは全く異なる認知様式が必要かもしれない、ということだ。
これがまさに「真の強化学習」なのである。著名な教育学者ピアジェの理論のように――真の理解とは、受動的な受け入れではなく、主体的な構築から生まれるのだ。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














