AIデータ爆発による「石油危機」で、コンテンツ企業は寝たきりで儲けられる時代が来た
TechFlow厳選深潮セレクト
AIデータ爆発による「石油危機」で、コンテンツ企業は寝たきりで儲けられる時代が来た
AI大規模モデルを車に例えるなら、生データは原油である。
執筆:江江
編集:蔓蔓周
ChatGPTの登場とMidjourneyの爆発的な普及により、AIは大規模モデルの普及という形で初めて大規模に応用されるようになった。
いわゆる大規模モデルとは、多数のパラメータと複雑な構造を持つ機械学習モデルであり、膨大なデータを処理し、さまざまな複雑なタスクを遂行できるものである。
01 AIデータ著作権紛争
現在のAI大規模モデルを車に例えるなら、元となるデータは原油に相当する。いずれにせよ、まずAIモデルには十分な「原油」が必要である。
AI企業の「原油」の主な出所は以下の通りだ:
-
インターネット上の無料公開データ源(ウィキペディア、ブログ、フォーラム、ニュースなど);
-
老舗のニュースメディアや出版社;
-
大学などの研究機関;
-
モデルを利用するC端ユーザー。
現実世界では石油の所有権について既に成熟した法的規範があるが、AIというまだ混沌とした分野では、「原油」の採掘権は依然として曖昧であり、そのために生じる紛争は数えきれないほどある。
最近では、複数の大手音楽レーベルがAI音楽制作会社SunoおよびUdioを著作権侵害で提訴した。この訴訟は、昨年12月に『ニューヨーク・タイムズ』がOpenAIに対して起こした訴訟と同様のものである。

画像出典:Billboard
2023年7月、いくつかの作家が同社を訴え、ChatGPTが著作権保護された内容から著者の作品要約を生成したと主張した。
同年12月には、『ニューヨーク・タイムズ』もマイクロソフトとOpenAIに対して類似の著作権侵害訴訟を提起し、両社が同紙のコンテンツを用いてAIチャットボットの訓練を行ったと非難した。
また、カリフォルニア州では集団訴訟が提起され、OpenAIがユーザーの同意を得ずにインターネット上から個人情報を取得してChatGPTの訓練に使ったと告発されている。
最終的にOpenAIはこの訴えに対して支払いをしていない。同社は『ニューヨーク・タイムズ』の主張に同意せず、指摘された問題を再現できないと述べた。さらに重要なのは、『ニューヨーク・タイムズ』が提供したデータ源がOpenAIにとってそれほど重要ではないということだった。

出典:
https://openai.com/index/openai-and-journalism/
OpenAIにとって、この件からの最大の教訓はおそらくデータ供給者との関係を適切に管理し、双方の権利義務を明確にすることだろう。そのため、ここ一年ほどでOpenAIはThe Atlantic、Vox Media、News Corp、Reddit、Financial Times、Le Monde、Prisa Media、Axel Springer、American Journalism Projectなど、多くのデータ供給者とパートナーシップを結んできた。
今後、OpenAIは正式にこれらのメディアのデータを使用できることになり、一方でこれらのメディアもOpenAIの技術を自社製品に統合していくことになる。
02 AIによるコンテンツプラットフォームの収益化
しかし、OpenAIがデータ供給者と協力関係を築いた根本的な理由は訴訟への恐れではなく、機械学習が直面しようとしているデータ枯渇にある。MITなどの研究者は、機械学習データセットが2026年までにすべての「高品質言語データ」を使い果たす可能性があると推定している。
「高品質データ」は、OpenAIやGoogleのようなモデルメーカーにとっては極めて貴重な存在となっている。コンテンツ企業とAIモデルメーカーの間での協力が繰り返され、収益化のための“楽ちん”モードが開かれたのである。
伝統的なメディアプラットフォームShutterstockは、Meta、Alphabet、Amazon、Apple、OpenAI、RekaといったAI企業と次々に提携し、2023年にAIモデルへのコンテンツライセンスによって年間収入を1億400万ドルに引き上げた。2027年には2億5000万ドルの収益を見込んでいる。Redditはグーグルにコンテンツ著作権を許諾し、年間6000万ドルの収入を得ている。アップルも主要なニュースメディアと協力し、年間最低5000万ドルの著作権料を提示している。コンテンツ企業がAI企業から得る著作権料は、年率450%という驚異的なスピードで増加している。

画像出典:CX Scoop
過去数年間、ストリーミング以外のコンテンツの収益化は困難であり、これがコンテンツ業界の大きな課題であった。インターネット起業時代と比べ、AIの登場はコンテンツ業界にさらなる可能性と強い収益期待をもたらしている。
03 高品質データは依然として希少
もちろん、すべてのコンテンツがAIのニーズに合うわけではない。
前述のOpenAIと『ニューヨーク・タイムズ』の論争においてもう一つの注目点はデータの質である。原油から石油を精製するには、原料そのものの質が高くなければならないし、精製技術も優れている必要がある。
OpenAIは特に強調しているが、『ニューヨーク・タイムズ』のコンテンツは自社モデルの訓練において重大な貢献をしていない。毎年数千万ドルをShutterstockに支払っているOpenAIにとって、『ニューヨーク・タイムズ』のようなタイムリーな情報に依存するメディアはAI時代の寵児ではない。AIはむしろ深く独自性のあるデータを必要としている。
高品質データはあまりにも希少であるため、AI企業は「精製技術」と「ワンストップアプリケーション」の開発にも力を入れ始めている。
6月25日、OpenAIはリアルタイム分析データベース企業Rocksetを買収した。同社は主にリアルタイムのデータインデックスと照会機能を提供しており、OpenAIは自社製品にRocksetの技術を統合し、データのリアルタイム利用価値を高める予定だ。

画像出典:DePIN Scan
Rocksetの買収により、OpenAIはAIがリアルタイムデータをより適切に活用・アクセスできるようにする計画だ。これにより、OpenAIの製品はリアルタイム推薦システム、動的データ駆動型チャットボット、リアルタイム監視・警報システムなど、より複雑なアプリケーションをサポートできるようになる。
Rocketは、OpenAI内蔵の「石油精製部門」であり、通常のデータを直接、アプリケーションに必要な高品質データへと変換する。
04 創作者のデータ所有権の確立は空想か?
インターネットメディアプラットフォーム(Facebook、Redditなど)のデータは大きくUGC、つまりユーザーが提供するコンテンツに依存している。多くのプラットフォームがAI企業に高額のデータ使用料を受け取る一方で、ユーザーコンディションに「当該プラットフォームはユーザーのデータをAIモデルの訓練に使用する権利を持つ」という条項をこっそり追加している。
ユーザー契約にAIモデル訓練に関する権限が記載されてはいても、多くの創作者は自分が作ったコンテンツが具体的にどのモデルに使われているのか、有償使用されているのかどうか、また自分に属するはずの利益をどうすれば得られるのかを把握していない。
今年2月のMeta四半期決算電話会議で、ザッカーバーグ氏は明確にFacebookおよびInstagram上の画像をAI生成ツールの訓練に使用すると表明した。
報道によると、TumblrもすでにOpenAIおよびMidjourneyと秘密裏にコンテンツ使用許諾契約を結んでおり、ただし具体的な内容は公表されていない。
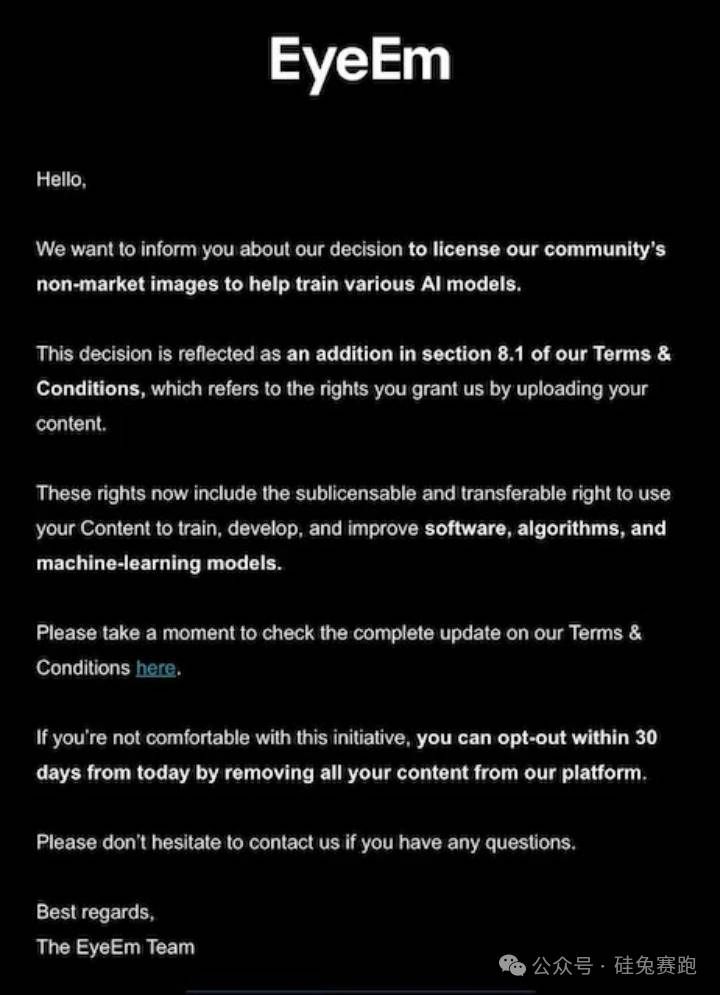
写真共有プラットフォームEyeEmの創作者たちも最近通知を受け取り、自身が投稿した写真がAIモデルの訓練に使われることを知らされた。通知には、ユーザーはこれに反対して製品の使用を中止できるとあるが、補償策についてはまだ触れられていない。EyeEmの親会社Freepikはロイター通信に対し、2億枚の画像の大部分を2社の大手テック企業に1枚あたり約3セントでライセンス供与したと明らかにした。CEOのJoaquin Cuenca Abela氏は、同様の取引が他に5件進行中だと述べたが、買い手の身元は明かさなかった。
Getty Images、Adobe、Photobucket、Flickr、RedditなどUGCを中心とするコンテンツプラットフォームも同様の問題に直面しており、巨大なデータ収益の誘惑の下、プラットフォームはユーザーのコンテンツ所有権を無視し、データを一括してAIモデル企業に売却している。
このプロセスはすべて暗黙のうちに進められ、創作者には何の抵抗の余地もない。多くの創作者にとって、かつての作品がどこかのプラットフォームを通じてAI企業に売られ、モデル訓練に使われていたことに気づくのは、将来あるモデルが自分の作品と酷似した内容を生成したときかもしれない。
創作者のデータ所有権と利益保護の問題を解決する手段として、Web3が有望な選択肢となりうる。AI企業が米国株式市場で連続して最高値を更新する一方で、web3のAI関連コインも同時に急騰している。ブロックチェーンはその非中央集権性と改ざん不可能性という特性により、創作者の権利保護に天然の優位性を持っている。
画像や動画といったメディアコンテンツは2021年のバブル期に大規模なブロックチェーン上での利用が進み、ソーシャルプラットフォームのUGCコンテンツのオンチェーン化も静かに進行している。同時に、多くのweb3 AIモデルプラットフォームは、モデル訓練に貢献する一般ユーザーを報酬で激励しており、データ所有者も訓練者も、それぞれにインセンティブが与えられている。
AIモデルの指数関数的な発展は、データ所有権の確立に対するさらなる需要を突きつけてくる。創作者は考えるべきだ。「なぜ私の作品が私の同意なしに1枚5セントでAIモデル企業に売られたのか?」「なぜこのプロセス全体で私は知らされず、一切の利益も得られないのか?」
メディアプラットフォームが焼け野原を作るようにしてでもAIモデル企業のデータ不安を和らげることはできない。高品質データの大量生産を実現する前提は、データ所有権の確立であり、創作者、プラットフォーム、AIモデル企業の三者が合理的に利益を分配することにある。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News