

AI+DePIN+Solanaエコの三重の注目を集めるIO.NET:発行間近のトークンを概観
TechFlow厳選深潮セレクト
AI+DePIN+Solanaエコの三重の注目を集めるIO.NET:発行間近のトークンを概観
AIの計算需要が供給を上回る市場環境において、分散型AI計算ネットワークにとって最も重要な要素はGPU供給側の規模である。
著者:Alex Xu、Mint Ventures
序論
私の前回の記事では、今回の暗号資産市場の好況サイクルが過去2回と比べて、十分なインパクトを持つ新たなビジネスやアセットストーリーに欠けていると述べました。AIは今回のWeb3分野において数少ない新ストーリーの一つであり、本稿では今年話題となったAIプロジェクトIO.NETを絡めながら、以下の2つの問いに対する考察を整理します。
-
AI+Web3の商業的必要性
-
分散型コンピューティングサービスの必要性と課題
さらに、代表的なAI分散コンピューティングプロジェクトであるIO.NETについて、その製品ロジック、競合状況、プロジェクト背景などの主要情報を整理し、評価額の推計も試みます。
本稿におけるAIとWeb3の統合に関する一部の考察は、Delphi DigitalのリサーチャーMichael Rinkoによる『The Real Merge』からの示唆を受けています。本稿の一部の見解は同レポートの内容を消化・引用したものであり、読者の皆様には原文の閲覧をおすすめします。
本稿は筆者が公開時点で持つ暫定的な考察であり、今後変更される可能性があります。また、意見には極めて強い主観性があり、事実、データ、推論の誤りが含まれる可能性もあります。投資判断の参考としては絶対に使用しないでください。業界関係者の批判や議論を歓迎いたします。
以下本文です。
1. ビジネスロジック:AIとWeb3の接点
1.1 2023年:AIが生んだ新たな「奇跡の年」
人類の発展史を振り返ると、科学技術が画期的な進展を遂げれば、個人の日常生活から産業構造、さらには人類文明全体に至るまで、劇的な変化がもたらされます。
人類史上には2つの重要な年があります。それは1666年と1905年であり、これらは現在「科学史における二大奇跡の年」と呼ばれています。
1666年が奇跡の年と呼ばれるのは、ニュートンがこの年に集中して科学的成果を上げたためです。彼は光学という物理学の一分野を開拓し、微積分という数学の一分野を創設し、現代自然科学の基礎法則となる万有引力の公式を導きました。これらの成果はいずれも未来百年の科学発展の礎となり、科学全体の発展を大きく加速させました。
二つ目の奇跡の年は1905年です。当時わずか26歳だったアインシュタインが、同年『Annalen der Physik(物理学年報)』に連続して4編の論文を発表しました。それぞれ光電効果(量子力学の基礎)、ブラウン運動(確率過程分析の重要基盤)、特殊相対性理論、そして質能方程式(有名な式E=MC^2)に関するものです。後世の評価では、これらの論文はいずれもノーベル物理学賞の平均水準を超えています(アインシュタイン自身も光電効果の論文によりノーベル賞を受賞)。これにより、人類文明の歴史的プロセスが再び大きく前進しました。
そして、つい先日の2023年も、ChatGPTの登場によって、もう一つの「奇跡の年」として語られる可能性が高いでしょう。
2023年を人類科学技術史における新たな「奇跡の年」と呼ぶ理由は、GPTが自然言語の理解・生成において大きな進歩を遂げたことだけでなく、GPTの進化を通じて大規模言語モデルの能力成長の法則を人間が把握できた点にあります。つまり、「モデルのパラメータと訓練データを拡大すれば、指数関数的にモデルの能力が向上する」という法則です。このプロセスには短期的にはまだ限界が見えません(計算資源さえあれば)。
この能力は言語の理解や会話生成に留まらず、さまざまな技術分野へ横断的に応用可能です。例えば、大規模言語モデルがバイオテクノロジー分野に応用された例を見てみましょう。
-
2018年、ノーベル化学賞を受賞したフランシス・アーノルド氏は授賞式でこう述べました。「今日、私たちは実用上任意のDNA配列を読み書き編集できるが、それを使って創作することはできない(compose it)」。しかし、この発言からわずか5年後の2023年、スタンフォード大学およびシリコンバレーのAIスタートアップSalesforce Researchの研究者たちが『Nature Biotechnology(ネイチャー・バイオテクノロジー)』に論文を発表。GPT-3をファインチューニングした大規模言語モデルを使い、ゼロから100万種類の全く新しいタンパク質を創造し、その中から構造はまったく異なるがどちらも殺菌能力を持つ2種類のタンパク質を発見しました。これはつまり、AIの助けにより、タンパク質の「創造」の壁が突破されたことを意味します。
-
また以前より、AIアルゴリズムAlphaFoldが18ヶ月間で地球上のほぼすべての2億1400万種のタンパク質構造を予測しており、その成果はこれまでの人間の構造生物学者の全仕事量の数百倍にあたります。
AIベースの各種モデルがあれば、バイオテクノロジー、材料科学、医薬品開発といったハードテックから、法律、芸術など人文分野に至るまで、劇的な変革が到来するのは間違いありません。そして2023年はまさにその元年でした。
近世以降、人類の富の創造能力は指数関数的に増加していますが、AI技術の急速な成熟は、このプロセスをさらに加速させるでしょう。

世界GDP総額推移図、出典:世界銀行
1.2 AIとCryptoの統合
AIとCryptoの統合の本質的な必要性を理解するには、両者の相補的特性から始めることができます。
AIとCryptoの特性の相補性
AIには以下の3つの属性があります。
-
ランダム性:AIはランダム性を持ち、コンテンツ生成の背後にあるメカニズムは再現困難かつ調査不能なブラックボックスであり、結果にもランダム性がある
-
リソース集約性:AIはリソース集約型産業であり、大量のエネルギー、チップ、計算資源を必要とする
-
類人知能:AIは(近い将来)チューリングテストを通過でき、人間と機械の区別が難しくなる*
※2023年10月30日、米国カリフォルニア大学サンディエゴ校の研究チームがGPT-3.5およびGPT-4.0のチューリングテスト結果を発表(テスト報告書)。GPT-4.0の得点は41%で、合格ラインの50%まであと9%。同一試験での人間の得点は63%でした。このチューリングテストの意味は、「チャット相手が本物の人間だと認識される割合」です。50%を超えると、半数以上の人が相手を人間だと認識したとみなされ、チューリングテスト通過と見なされます。
AIは人類に新たな飛躍的な生産力をもたらす一方で、これらの3つの属性は社会に大きな課題も提起しています。具体的には:
-
AIのランダム性をどう検証・制御し、これを欠陥ではなく強みとするか
-
AIが必要とする巨額のエネルギーと計算資源の不足をどう満たすか
-
人間と機械をどう区別するか
一方で、Cryptoおよびブロックチェーン経済の特性は、AIがもたらす課題を解決する良薬となる可能性があります。暗号経済には以下の3つの特徴があります。
-
決定性:業務がブロックチェーン、コード、スマートコントラクトに基づいて運営され、ルールと境界が明確。入力に対して出力が確定的で、高い決定性を持つ
-
リソース配分の高効率性:暗号経済は巨大なグローバル自由市場を構築しており、リソースの価格設定、資金調達、流通が非常に迅速。トークンの存在により、インセンティブを通じてマーケットの需要供給のマッチングを加速し、臨界点への到達を促進可能
-
信頼不要性(trustless):台帳が公開され、コードがオープンソース。誰でも簡単に検証可能で、「信頼不要(trustless)」なシステムを提供。ZK技術により、検証時にプライバシーを漏らさない
次に、3つの例を通じてAIと暗号経済の相補性を説明します。
例A:ランダム性の解決、暗号経済に基づくAIエージェント
AIエージェントとは、人間の意志に基づき、人間の代わりに作業を行う人工知能プログラムのことです(代表的プロジェクト:Fetch.AI)。例えば、自分のAIエージェントに「BTCを1000ドル分購入せよ」という金融取引を任せるとします。AIエージェントは以下の2つの状況に直面する可能性があります。
状況一:伝統的金融機関(ベライドなど)と接続し、BTCのETFを購入する場合。大量のAIエージェントと中央集権的機関の適合問題が生じます。KYC、資料審査、ログイン、身分認証などがあり、現時点では非常に煩雑です。
状況二:ネイティブな暗号経済上で動作する場合。状況ははるかに簡単になります。Uniswapや他の集約取引所を通じ、ユーザーのアカウントで署名・注文を行い取引を完了し、WBTC(または他のラップ形式のBTC)を受け取ります。このプロセスは迅速かつシンプルです。実際、これが各種Trading BOTが行っていることであり、すでに初級のAIエージェントとして機能しています(ただし取引専門に限られます)。将来的には、AIの統合と進化により、より複雑な取引意図を実行できるようになるでしょう。例えば、「100個のチェーン上の賢いお金アドレスを追跡し、それらの取引戦略と成功率を分析し、自分のアドレスの10%の資金を1週間以内に同様の取引を実行し、効果が悪ければ停止し、失敗の原因を要約する」などです。
AIがブロックチェーンシステム上でよりうまく動作するのは、暗号経済のルールが明確であり、システムアクセスが無許可だからです。限定されたルール内でタスクを実行する場合、AIのランダム性がもたらす潜在的リスクは小さくなります。例えば、AIは将棋やビデオゲームで人間を圧倒していますが、これは将棋やゲームがルールが明確な閉鎖的サンドボックスだからです。一方、AIの自動運転の進展は比較的遅れています。これは開放的な外部環境の挑戦が大きく、AIのランダム性を処理することに対する私たちの許容度が低いからです。
例B:リソースの形成、トークンインセンティブによるリソースの集積
BTCの背後にあるグローバルな計算ネットワークの現在の総算力(ハッシュレート:576.70 EH/s)は、どの国のスーパーコンピュータの総合算力をも超えています。その発展原動力は、シンプルで公平なネットワークインセンティブにあります。
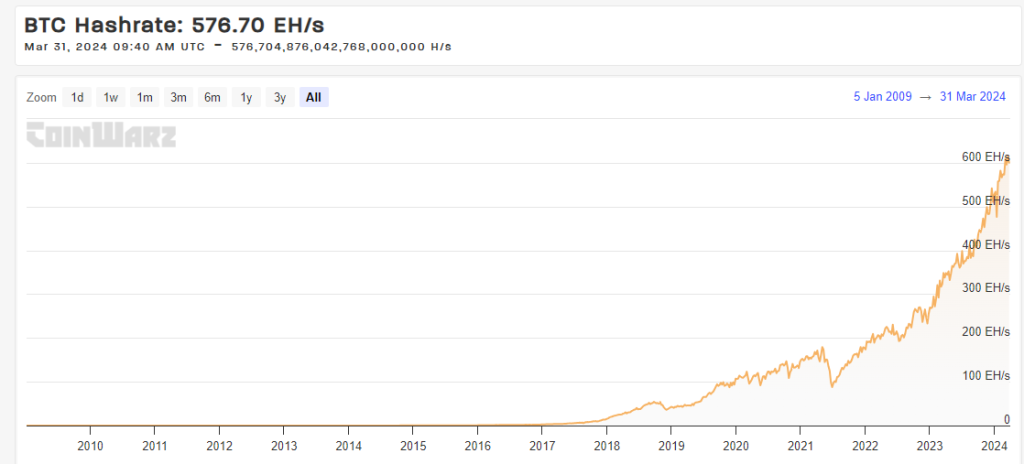
BTCネットワーク算力推移、出典:https://www.coinwarz.com/
その他、Mobileなどを含むDePINプロジェクトも、トークンインセンティブを通じて需給両側のバイラテラルマーケットを形成し、ネットワーク効果を実現しようとしています。本稿で重点的に紹介するIO.NETは、AI算力を集積するプラットフォームであり、トークンモデルを通じてさらなるAI算力のポテンシャルを引き出そうとしています。
例C:オープンソースコード、ZKの導入、プライバシー保護下での人機識別
OpenAIの創設者Sam Altmanが参加するWeb3プロジェクトWorldcoinは、ハードウェアデバイスOrbを使用し、虹彩の生体情報に基づきZK技術で固有かつ匿名のハッシュ値を生成することで、身分を検証し、人間と機械を区別します。今年3月初め、Web3アートプロジェクトDripはWorldcoinのIDを使用して、本物のユーザーを検証し報酬を配布しました。

また、Worldcoinは最近、虹彩ハードウェアOrbのプログラムコードをオープンソース化し、ユーザーの生体情報の安全とプライバシーを保証しています。
総じて、暗号経済はコードと暗号学の決定性、無許可性、トークンメカニズムによるリソース流動と調達の利点、オープンソースコードと公開台帳による信頼不要性を持つため、AIがもたらす課題に直面する人類社会にとって重要な潜在的解決策となっています。
特に切実で、商業的需要が最も高い課題は、AI製品が計算資源に対して極めて飢えた状態にあること、つまりチップと計算資源に対する巨大な需要です。
これが今回の好況サイクルで、分散型計算プロジェクトがAI分野全体の中で最も顕著な上昇を示した主な理由です。
分散型コンピューティング(Decentralized Compute)の商業的必要性
AIは膨大な計算リソースを必要とします。モデルのトレーニングにも推論にも同様です。
大規模言語モデルのトレーニング実践において、確認された事実は次の通りです。データパラメータの規模が十分に大きければ、大規模言語モデルは以前にはなかった能力を発現するのです。各世代のGPTの能力が前世代を指数関数的に飛び越える背景には、モデルトレーニングの計算量が指数関数的に増加していることが挙げられます。
DeepMindとスタンフォード大学の研究によると、異なる大規模言語モデルが異なるタスク(演算、ペルシャ語質疑応答、自然言語理解など)に直面するとき、モデルのパラメータ規模を拡大すれば(それに伴い、トレーニングの計算量も増加)10^22 FLOPs(FLOPs:毎秒浮動小数点演算回数、計算性能を測る指標)に達するまでは、どのタスクのパフォーマンスもランダムに答えを与えるのとほぼ同じです。しかし、ある規模の臨界値を超えると、タスクのパフォーマンスは急激に向上し、どの言語モデルでも同様です。
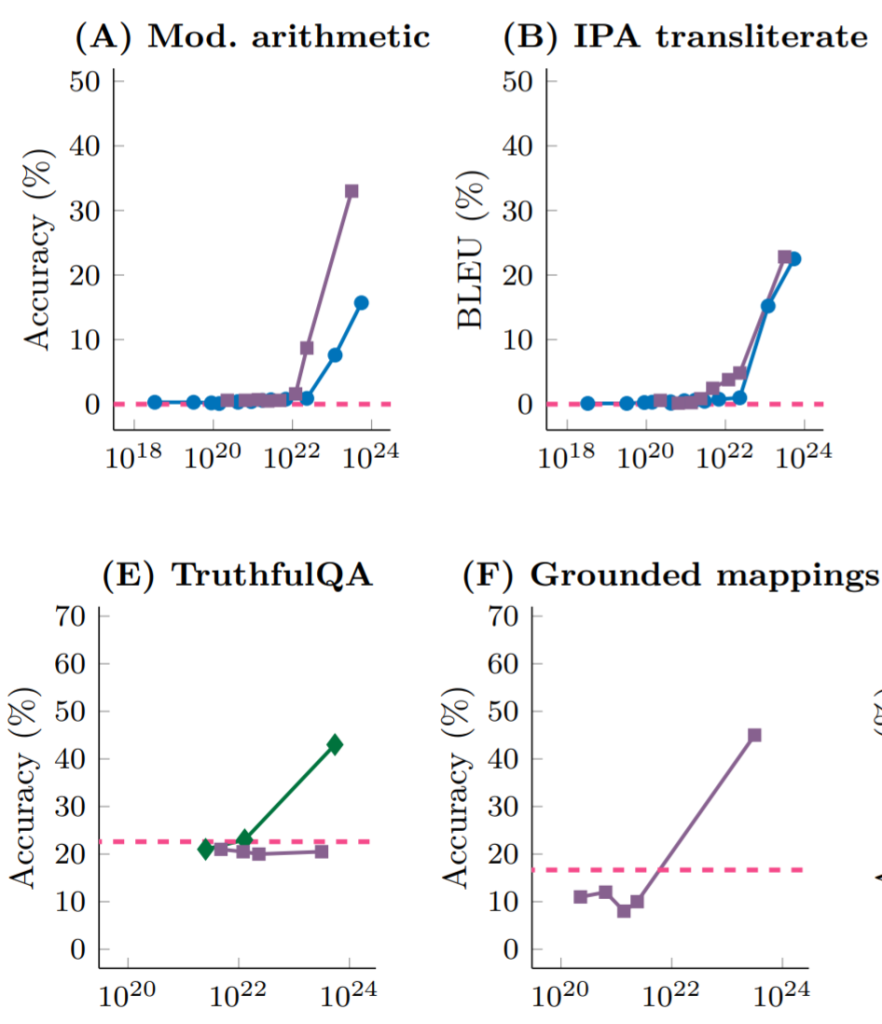
出典:Emergent Abilities of Large Language Models
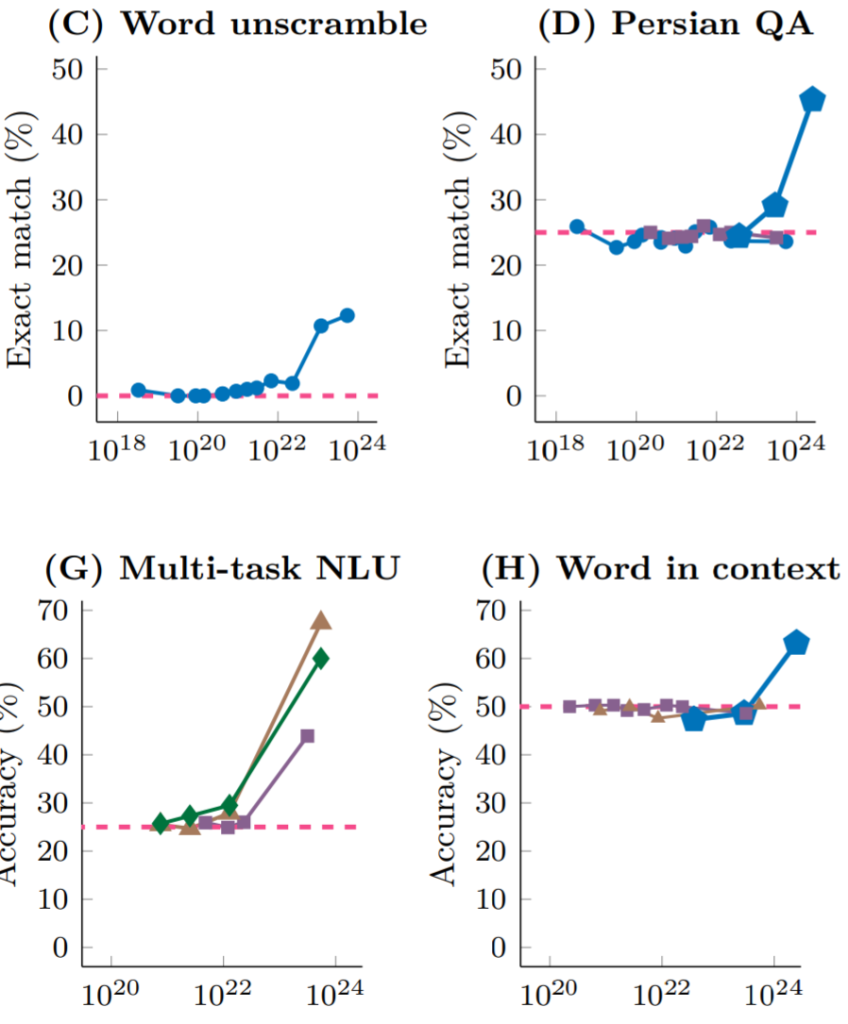
出典:Emergent Abilities of Large Language Models
まさに「計算力で奇跡を起こす」という法則と実践の検証が、OpenAIの創設者Sam Altmanをして「7兆ドルを調達し、現存のTSMCの10倍規模の先端チップ工場(予想費用1.5兆ドル)を建設し、残りの資金をチップ生産とモデルトレーニングに充てる」と言わしめたのです。
AIモデルのトレーニングに計算力が必要なだけでなく、モデルの推論プロセス自体も大きな計算力を必要とします(トレーニング量に比べれば小さいですが)。そのため、チップと計算力への渇望はAI分野の参加者の常態となっています。
Amazon Web Services、Google Cloud Platform、Microsoft Azureなどの中央集権的AI計算提供者と比較して、分散型AI計算の主な価値提案は以下の通りです。
-
アクセシビリティ:AWS、GCP、Azureなどのクラウドサービスで計算チップにアクセスするには通常数週間かかり、人気のGPUモデルは頻繁に在庫切れです。また、計算力を得るために、消費者はしばしば長期的で柔軟性に欠ける契約を大企業と結ぶ必要があります。一方、分散型計算プラットフォームは柔軟なハードウェア選択を提供し、アクセシビリティが高くなります。
-
低価格:アイドリングチップを利用し、ネットワークプロトコル側がチップおよび計算供給者にトークン補助を行うことで、分散型計算ネットワークはより安価な計算力を提供できる可能性があります。
-
検閲耐性:現在、最先端の計算チップと供給は大手テック企業に独占されており、アメリカ政府をはじめとする各国政府がAI計算サービスへの監視を強化しています。AI計算を分散的、弾力的、自由に取得できることが、徐々に明示的なニーズとなっています。これがWeb3ベースの計算サービスプラットフォームの核心的価値提案です。
化石燃料が工業時代の血液なら、計算力はAIによって始まる新しいデジタル時代の血液となるかもしれません。計算力の供給はAI時代のインフラストラクチャとなるでしょう。安定通貨が法定通貨のWeb3時代における繁栄する傍系のように、分散型計算市場は急速に成長するAI計算市場の傍系となるでしょうか?
これはまだ非常に初期の市場であり、すべては様子見です。しかし、以下の要因が分散型計算のストーリーまたは市場採用を刺激する可能性があります。
-
GPUの継続的な需給緊張。GPUの継続的な供給不足は、一部の開発者が分散型計算プラットフォームへの移行を試みるきっかけとなるかもしれません。
-
規制の拡大。大手クラウド計算プラットフォームからAI計算サービスを得るには、KYCおよび多重の審査を経る必要があります。これは逆に分散型計算プラットフォームの採用を促進する可能性があり、特に制限や制裁を受けている地域においてそうです。
-
トークン価格の刺激。好況サイクルでのトークン価格上昇は、プラットフォームがGPU供給側に与える補助の価値を高め、より多くの供給者を市場に惹きつけ、市場規模を拡大し、消費者の実際の購入価格を低下させます。
しかし同時に、分散型計算プラットフォームの課題も明らかです。
-
技術的・工学的課題
-
計算検証の問題:深層学習モデルの計算は階層構造のため、各層の出力が次の層の入力となるため、計算の妥当性を検証するには以前のすべての作業を実行する必要があります。簡単かつ効果的に検証できません。この問題を解決するため、分散型計算プラットフォームは新しいアルゴリズムを開発したり、近似検証技術を使用したりする必要があります。これらの技術は結果の正しさに対する確率的保証を提供できますが、絶対的な確定性ではありません。
-
並列化の難題:分散型計算プラットフォームはロングテールのチップ供給を集積するため、単一デバイスが提供できる計算力は限られます。個々のチップ供給者は、短時間で独立してAIモデルのトレーニングや推論タスクを完了することはほぼ不可能です。そのため、タスクを分解し並列化して全体の完了時間を短縮する必要があります。しかし並列化には、タスクの分解方法(特に複雑な深層学習タスク)、データ依存性、デバイス間の通信コストの増加といった問題が伴います。
-
プライバシー保護の問題:購入者のデータやモデルがタスク受領者に漏れないようにするには?
-
-
規制遵守の難題
-
分散型計算プラットフォームは、供給と購入の両側市場が無許可であるため、一方で販売ポイントとして一部の顧客を惹きつけます。他方で、AI規制の整備とともに、政府の取り締まり対象となる可能性があります。また、一部のGPU供給者は、自分が貸し出した計算リソースが制裁対象の企業や個人に提供されているかどうかを懸念します。
-
総じて、分散型計算プラットフォームの利用者は主に専門的な開発者や中小規模の機関であり、暗号通貨やNFTを購入する暗号投資家とは異なり、プロトコルが提供するサービスの安定性・継続性に対する要求が高くなります。価格が必ずしも彼らの意思決定の主な動機とは限りません。現時点では、分散型計算プラットフォームがこのようなユーザーの承認を得るには、まだ長い道のりがあります。
次に、今回のサイクルの新しい分散型計算プロジェクトIO.NETについて、プロジェクト情報の整理と分析を行い、現在市場にある同分野のAIプロジェクトおよび分散型計算プロジェクトを基に、上場後の可能な評価額を推計します。
2. 分散型AI計算プラットフォーム:IO.NET
2.1 プロジェクトの位置付け
IO.NETは非中央集権型計算ネットワークであり、チップを中心としたバイラテラルマーケットを構築しています。供給側はグローバルに分散したチップ(主にGPU、CPU、AppleのiGPUなど)の計算力、需要側はAIモデルのトレーニングや推論タスクを完了したいAIエンジニアです。
IO.NETの公式サイトでは、次のように述べています。
Our Mission
百万台のGPUをDePIN(分散物理インフラネットワーク)に統合すること。
その使命は、百万規模のGPUをDePINネットワークに統合することです。
既存のクラウドAI計算サービスプロバイダーと比較して、主に以下の販売ポイントを強調しています。
-
柔軟な組み合わせ:AIエンジニアは必要なチップを自由に選び、組み合わせて「クラスタ」を構成し、自分の計算タスクを完了できます
-
迅速な展開:数週間の承認と待機(現在のAWSなどの中央集権型ベンダーの状況)を必要とせず、数十秒で展開しタスクを開始できます
-
低価格サービス:主流ベンダーに比べて90%安いコスト
また、IO.NETは将来、AIモデルストアなどのサービスも計画しています。
2.2 製品メカニズムと事業データ
製品メカニズムと展開体験
Amazon Cloud、Google Cloud、Alibaba Cloudと同じく、IO.NETが提供する計算サービスはIO Cloudと呼ばれます。IO Cloudは分散的・非中央集権型のチップネットワークであり、Pythonベースの機械学習コードを実行し、AIおよび機械学習プログラムを稼働できます。
IO Cloudの基本的な業務モジュールは「クラスタ(Clusters)」と呼ばれます。クラスタとは、計算タスクを自己調整して完了できるGPUグループであり、AIエンジニアは自分のニーズに応じてカスタマイズ可能なクラスタを設計できます。
IO.NETの製品インターフェースはユーザーフレンドリーで、AI計算タスクを実行するための独自のチップクラスタを展開する場合、クラスタ製品ページに入れば、必要なチップクラスタを按需で設定できます。
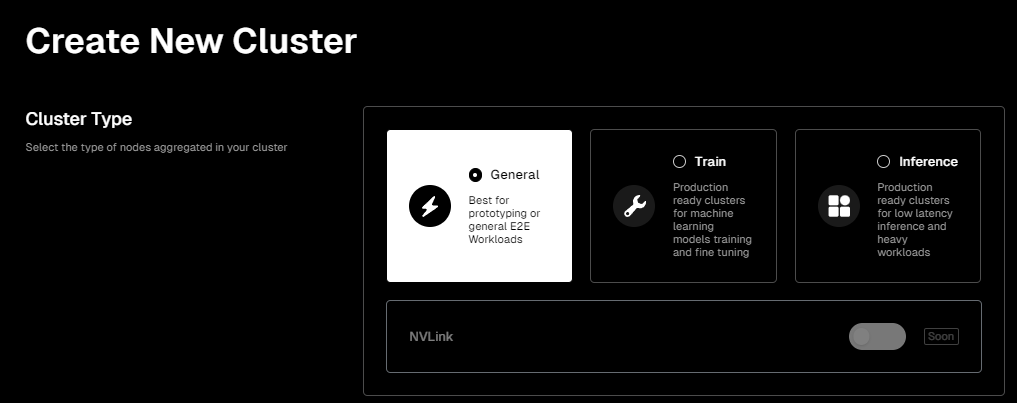
ページ情報:https://cloud.io.net/cloud/clusters/create-cluster、以下同様
まず、タスクのシナリオを選択する必要があります。現在は以下の3種類から選べます。
-
General(汎用型):比較的一般的な環境を提供し、初期段階で具体的なリソース要件が不確かなプロジェクトに適しています。
-
Train(トレーニング型):機械学習モデルのトレーニングおよびファインチューニング専用のクラスタ。このオプションはより多くのGPUリソース、より高いメモリ容量、および/または高速なネットワーク接続を提供し、これらの高負荷計算タスクを処理します。
-
Inference(推論型):低レイテンシ推論および重負荷作業専用のクラスタ。機械学習の文脈では、推論とはトレーニング済みモデルを使用して新データの予測や分析を行い、フィードバックを提供することを指します。したがって、このオプションはレイテンシとスループットの最適化に焦点を当て、リアルタイムまたはニアリアルタイムのデータ処理ニーズをサポートします。
次に、チップクラスタの供給元を選択する必要があります。現在IO.NETはRender NetworkおよびFilecoinのマイナーネットワークと提携しており、ユーザーはIO.NETまたは他の2つのネットワークのチップを計算クラスタの供給元として選択でき、IO.NETがアグリゲーターの役割を果たしています(ただし筆者が執筆時点でFilecoinサービスは一時的に停止中)。なお、ページ表示によると、現在IO.NETでオンライン利用可能なGPU数は20万以上、Render Networkは3700以上です。
その後、クラスタのチップハードウェア選択に進みます。現在IO.NETが選択可能としているハードウェアタイプはGPUのみで、CPUやAppleのiGPU(M1、M2など)は含まれていません。またGPUも主にNVIDIA製品です。
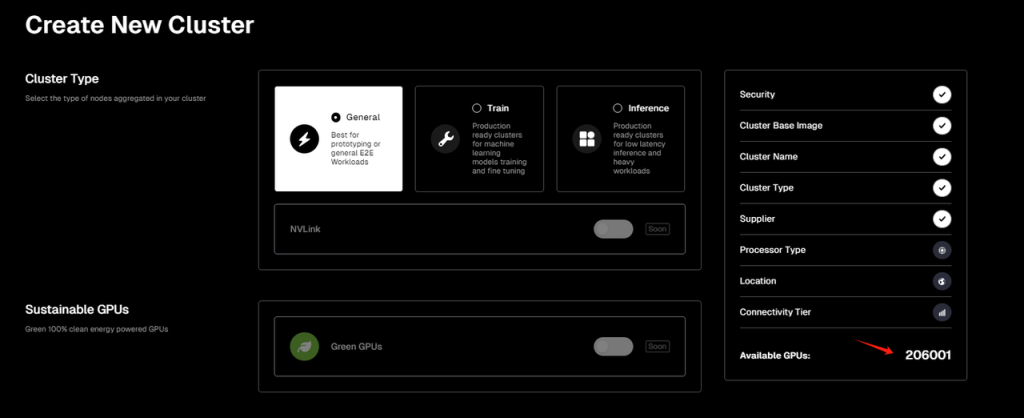
公式サイトでリストアップされ、利用可能なGPUハードウェアオプションの中では、筆者がテストした当日のデータによると、IO.NETネットワークでオンライン利用可能なGPU総数は206,001枚です。最も多く利用可能なのはGeForce RTX 4090(45,250枚)、次いでGeForce RTX 3090 Ti(30,779枚)です。
また、機械学習、深層学習、科学計算などの
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














