

FLock.io CEOとの対話:なぜGoogleは本物のフェデレーテッドラーニングができないのか、そしてブロックチェーンならできる理由
TechFlow厳選深潮セレクト
FLock.io CEOとの対話:なぜGoogleは本物のフェデレーテッドラーニングができないのか、そしてブロックチェーンならできる理由
世界は功利主義的であり、アルゴリズムも確かにこのブラックボックスアルゴリズムから出されたものだが、結果として本当に大きな奇跡が生まれた。
執筆:Sunny,TechFlow
ゲスト:Jiahao Sun、FLock
「非中央集権型の機械学習は、もはや単なるスローガンではなく、現実的な工学的ソリューションになりつつある。」
– Jiahao Sun、FLock.io CEO
非中央集権型AIは新しい概念ではないが、暗号資産の台頭により復活の兆しを見せ、AIの民主化に可能性を提供している。しかし、この分野に不慣れな人にとっては、「AIの民主化」という概念は曖昧に感じられるかもしれない。
ブロックチェーンは現代ネットワークのバックエンドとして、労働力とリソースの調整・クラウドソーシングを可能にする。
AIは予測を行うためのトレーニングと推論を広く包含しており、計算能力、モデル、データに依存している。現在、これらは主に数社の大手テック企業が支配している。一般的には悪用されないとされているが、それを検証する保証はなく、より多くの人々がAI開発に参加できる新たなアプローチが必要とされている。
かつてGoogleはフェデレーテッドラーニング(連合学習)を試みた。ユーザーの端末がローカルでデータと計算能力を提供し、それらを集約してグローバルモデルを構築する方式だ。しかし、このモデルでも依然として中央集権的な管理が維持されていた。
ブロックチェーンは、トークノミクスと暗号資産を通じて、誰もがデータ、計算能力、モデルの提供に参加できるプライベート経済システムを可能にすることで、解決策を提供する。
FLock(ブロックチェーンベースの連合学習)は、スマートコントラクトとトークノミクスによって真の連合学習を実現し、より広範な参加を保証する。本日はFLockのCEOを迎え、民主的AIの概念や、医療衛生などの分野における関連性について議論する。去中心化の議論を超えて、連合学習自体の意義についても触れたい。
伝統的金融AIディレクターから、スマートコントラクト化された連合学習へ
TechFlow:まず簡単な自己紹介をお願いします。また、FLockとは何か、つまり非中央集権型連合学習とは何なのか教えてください。
Jiahao:
私は従来のWeb2系フィンテック業界で10年間働いてきました。卒業直後、Entrepreneur Firstのインキュベーターに入り、そこでAIを活用した与信評価(Credit Scoring)に取り組む初の起業をしました。その後すぐにヘッドハンティングされ、トップクラスの金融機関でInnovation Leadとして働き、8年かけてグローバルAIディレクターまでになりました。つまり、ずっとAIの研究と応用の現場に身を置いてきたわけです。
Web3業界に興味を持ったのは、2017年のICOバブルの時期でした。「適当なアイデアでもプロジェクトが立ち上がる」という状況に驚きを感じました。ただ、当時の市場は明らかに未熟で、今で言う「土狗(劣悪プロジェクト)」が多く、あまり格好良い印象ではなかったため、本格的に参入するつもりはありませんでした。ただ「面白い業界があるものだ」と傍観していました。
パンデミック中、時間の流れが緩慢に感じられ、欧米では皆が在宅勤務になり、急に自由な時間が増えました。その時間をゲームに費やすこともできたし、何か意味のあることに使うこともできました。私は一年ほどゲームに明け暮れた後、人生を無駄にしていると感じ、何か有意義なことに取り組むことを決めました。2021年末を見渡すと、暗号市場は深い熊相場にありましたが、注目すべきプロジェクトがいくつも登場していました。特に、豊富なWeb2経験を持つチームがWeb3で優れた成果を上げているのを見て、大きなインスピレーションを受け、Web3の発展と真正面から向き合うべき技術・ナラティブに魅了されるようになりました。
最終的にWeb3に参入することを決めたのは、私たちの研究チームが国際会議で受賞した論文がきっかけです。これは創業メンバーたちによる非中央集権型機械学習の本質に関する考察であり、FLockという技術用語(Federated Learning on the Blockchain)が初めて市場に提示された瞬間でもありました。また、学術界最高レベルのピアレビューによる支持を得たことで、FLockプロジェクトを本格的に立ち上げる自信と後押しを得ました。
論文リンク:https://scholar.google.com/citations?user=s0eOtD8AAAAJ&hl=en
なぜなら、連合学習あるいは非中央集権型機械学習は、業界内で常に存在してきたからです。
例えばNVIDIAやAWSも、分散コンピューティングや分散機械学習に多額の投資を行っています。しかしここには常に問題があります。仮にAWSが「すべてのクラウドプラットフォームやリソースは分散されており、あなたが自分のクラウドを持っている」と言ったとしても、誰もそれを信じないでしょう。結局あなたはAWSを通じてクラウドを購入しているのであり、AWSが中間的な管理権を持ち、最終的な支配者だからです。つまり、あなたが所有しているのはあくまでレンタルであり、データの所有権もユーザーにはありません。
プライバシーの問題を解決するという点では、Googleが2017年に連合学習(Federated Learning)という概念を提唱しました。
連合学習とは、マシンラーニングのフレームワークの一種で、すべての計算処理を各ノードに分散させることで、データを外部に出さずに済むようにするものです。各ユーザーが自分のノード内でローカル計算を行い、その結果を集約して最終的な総合モデルを構築します。この大規模モデルはすべてのデータで訓練された結果を反映しつつ、データを第三者のサーバーに送信する必要がなくなるのです。
このような仕組み全体を連合学習と呼びます。Googleが最初にこれを提唱した後、入力予測に応用しました。そのため、多くのPixel Phoneユーザーはすでに連合学習の恩恵を受けています。Googleのスマホで文字を打つと、次の単語を予測してくれる機能です。これが連合学習の最初の実用例でした。
しかし、先ほど挙げた例のように、Googleがトレーニング全体を管理しており、悪意を持って行動する可能性があります。ソースコードや元データすべてを見ることができ、「見ていない」と主張しても検証できないのです。実際に面白い事件がありました。ある中国語入力ソフトが「連合学習でユーザーのプライバシーを保護している」と宣伝していましたが、後に調査で、すべてのユーザー入力データがそのまま中央サーバーに送られていたことが判明し、実際には連合学習など行われていませんでした。
こういった出来事もあり、最近の技術コミュニティでは「もし一人がすべてのリソースを管理したら、本当に悪意を持たないと言い切れるのか?」という疑問が持ち上がっています。もし保証しても、果たして信じられるのか? 明らかに他社は信じていないのでしょう。そうでなければ、AppleとGoogleが協力して一つの入力予測モデルを共同開発しているはずです。
だからこそ、我々はブロックチェーンのスマートコントラクトメカニズムを、従来の連合学習フレームワークに導入しました。これにより、Googleのような中央管理者が不要になります。 各人は独立した個体として、自分自身のノードを持ち、自分の部分だけを計算します。そして、スマートコントラクトによって、どのGradient(勾配)が有効か、どのGradientを統合すべきかを決定します。すべてはチェーン上のコンセンサスによって解決されます。これがFLockが最初に抱いた研究アイデアでした。
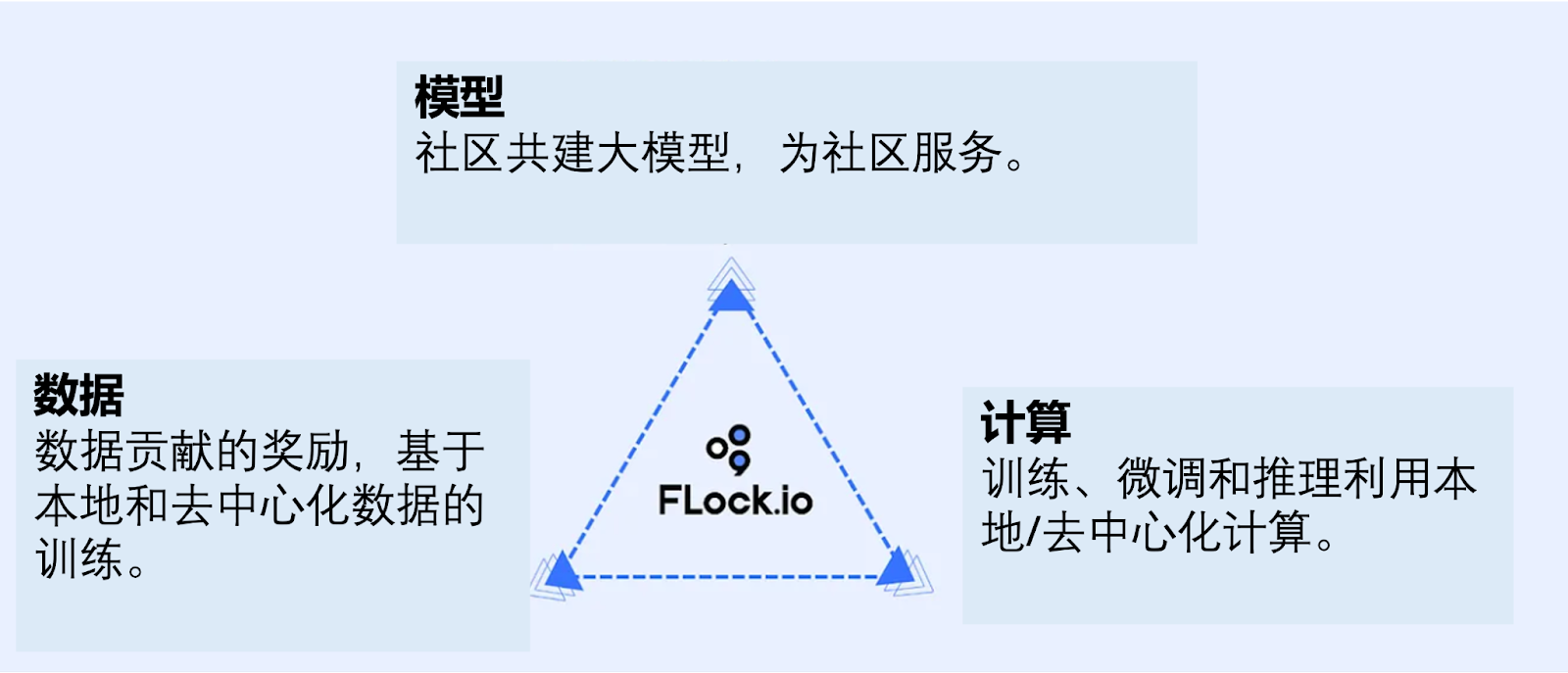
FLockはスマートコントラクトにより、計算・モデル・データのコミュニティ主導の共同構築を実現
まず理解すべきこと:訓練済みのデータは、まだ「あなたのデータ」なのか?
TechFlow:個々のノードにおいて、個人のローカルデータはどのように暗号化され、総合モデルの訓練に参加するのでしょうか? また、訓練結果を得た上で、いかにプライバシーを守るのでしょうか?
Jiahao:
例を挙げましょう。WorldCoinは虹彩写真を撮影し、ニューラルネットワークを通してEmbedding(埋め込み表現)に変換します。このEmbeddingはもはや虹彩写真そのものではありません。人々がこの理論を信じるかどうかがポイントです。
–「これはもはや私の虹彩ではない。新しいEmbeddingだ」
もちろん、この理論を受け入れない人もいます。「これは私のデータの派生物であり、やはり私のデータだ」と考えるのです。
順を追って説明しましょう。まず、この理論を受け入れる人にとって、連合学習では個人データが個々のノードから一切出ることはありません。外部に出るのは、自分のデータでローカルモデルを訓練した後のモデルの変化量、これを勾配(Gradient)と呼びます。
次ノードに送信するのはこの勾配のみであり、個人データに関わる情報は一切送信されず、完全に秘匿されます。理論的には追加の暗号化は不要です。なぜなら、送信内容はもはや個人データではないからです。
ただし、「私のデータの派生物も私のデータだ」と考える場合、たとえ神経ネットワークで処理され、虹彩そのものではなくなり、Embeddingになっても、それが依然として元データに対応すると考えます。そのような場合は、転送チャネルに対してさらに一層の暗号化を施します。
ノードから次のノードへの転送時にも暗号化を施します。複数の方法があり、特に注目すべき技術にDeep Gradient Compressionがあります。これにより、ノード間のデータ転送量を5%以下に圧縮できます。転送速度が向上し、同時にプライバシー保護も実現し、モデル精度にも影響を与えず、一石三鳥です。
理由は二つあります。第一に、機械学習では過学習を防ぐために、毎回の計算時にDropout(一部データの意図的な除外)を行うのが一般的です。たとえば100%の結果が出ても、70~80%程度に減らして転送します。100%のまま進めると、局所最適解に陥ってしまうためです。これは局所最適であって、グローバル最適ではないのです。この手法により、むしろ計算精度が向上します。
第二に、深層学習の分野で、勾配を極限まで圧縮(例:5%以下)すると、もはや元のデータを復元できないレベルまで情報が失われることがわかりました。これは画像に非常に濃いモザイクをかけるのと同じで、最も高性能なAIでも元の画像の詳細を完全に復元することは不可能です。いくら想像や推測をしても、利用可能な情報が少なすぎるため、還元できる内容は極めて限られます。情報理論的に、もはや元のデータに戻すことは不可能であり、これだけで十分な暗号化と言えるのです。
第三に、ペイロードが小さくなることで、転送効率が自然と向上します。数十Bパラメータの大規模モデルでも、私たちの最適化により、一般家庭の複数PCによる非中央集権型チューニングが数時間で完了可能です。
非中央集権型機械学習は、もはや単なるスローガンではなく、現実的な工学的ソリューションになりつつある。
これは本質的にブロックチェーンや連合学習の仕組み自体の問題ではなく、ノード間の暗号化転送の問題です。それが安全である限り問題ありません。私が述べたのは一例にすぎず、ZK(ゼロ知識証明)、FHE(完全準同型暗号)、TEE(信頼できる実行環境)なども暗号化ソリューションとして使用可能です。FLockはこれらすべての技術と良好に互換性があり、自ら「zkFL」という論文も発表しています。
連合学習 + スマートコントラクト = FLock
TechFlow:連合学習では各ノードが自分のデータを処理し、結果を提出します。その後どうなるのでしょうか? AIに詳しくない人向けに、このコンセンサスをどう説明しますか?
Jiahao:
これらのノード群はある種のグループのようなもので、Ring-all Reduce方式を使用し、あるノードから次へ、さらに次へとデータを回していきます。中央管理者を置かず、あるノードが同じデータを二度受け取った時点で、一周完了となります。これをGradient加算と呼びます。これにより、各ノードが自分のローカルモデルを新しいモデルに更新します。
コンセンサスとは、誰も管理していないシステムの中で成立するものです。 なぜGoogleは中央集権的な連合学習システムを管理する必要があるのでしょうか?
それは、ノードの中に悪意のある行為者がいる可能性があるためです。たとえば、偽のデータで計算を行う、または無意味な乱数データを提出するといったケースです。これが中央管理者が必要な理由です。これが従来のWeb2世界で連合学習を行う際に、必ず契約を交わす必要がある理由です。信用できる相手とのみ連合学習を行うしかないのです。
一方、FLockは非中央集権型のアプローチを取り、悪意のあるノードを防ぐ仕組みを提供します。スマートコントラクトが中央管理者の役割を代替し、バリデータとして検証(Validation)を行います。
機械学習は結果重視です。計算後のモデルの結果が、精度向上の方向に向かっているかを検証すればよいのです。
他の全員が精度向上の方向に進んでいるのに、あるノードだけ精度低下の方向に向かっていた場合、そのノードはSlash(報酬削減)の対象になります。一気に全額削除されるわけではなく、徐々に削減され、継続的に逸脱を続けると最終的にネットワークから除外されます。
これはスマートコントラクトによって管理されるゲーム理論的メカニズムです。
極端なケースは発生しないでしょうか? それがまさにトークノミクスの意義です。
論文では多くの極端なケースを検証しています。簡単な例を挙げましょう。
仮に、データ内のユーザー全員が右利きで、ある一つのノードだけ左利きのユーザーだとします。そのデータは確かに他の人と異なりますが、正しいデータです。計算を行うと、他の右利きユーザーのモデルは右側に偏り、左利きユーザーのモデルは左側に偏ります。最初のラウンドでは、FLockのコンセンサスにより、左利きユーザーのノードは異なるためSlashされます。二巡目でもさらに少しSlashされます。しかし、数ラウンドを経て、左利きユーザーのデータが真実であり、モデルへの貢献も真実であるため、モデルの変化はいずれ左利きユーザーの方向に少しずつシフトし始めます。すると、他の全員のモデルも左利きユーザーの結果に近づいていきます。
トークノミクスによれば、最終的にモデルがどの方向に偏るか(分かりやすく言えば)によって、報酬の分配もその方向に傾きます。つまり、左利きのノードは初期にデータの独自性ゆえに一時的にSlashされるものの、最終的にはモデルへの貢献により報酬が大きく分配され、逆に多くの収益を得ることになります。
これがFLockのメカニズム設計の背景であり、論文から入り、頂級カンファレンスでの発表を経てFLockを立ち上げた理由です。多くの要素を深く検討する必要があり、そのため創業当初は全くマネタイズをせず、論文執筆、コード作成、実験、シミュレーションに集中しました。NeurIPS、TAI、Scienceなどのピアレビューからの肯定的な評価を得ることで、基盤が堅固であることを確認した後、SDKやtestnetの構築を開始しました。
TechFlow:このトークノミクス、あるいはネットワーク内にいるプレイヤーについて簡単に説明できますか?
Jiahao:
プレイヤーは3種類:Planner(企画者)、Trainer(訓練者)、Validator(検証者)です。これをタスクプラットフォームに例えると、伝統的なAI界隈のHuggingFaceのようなイメージです。Plannerはタスク発行者で、タスクを掲載し、参加者にインセンティブを提供します。TrainerはAI開発者やデータ所有者で、モデルやデータを提供し、報酬を得ることを期待します。Validatorは計算リソースを提供し、AIモデルの精度を検証することで、システムが常に公正かつ効率的に運営されることを保証します。
Go-to-Market
TechFlow:FLockのスマートコントラクトはフロントエンドでどのように表示されるのでしょうか? 先ほど話した画像認識の場合、具体的な手順はどうなりますか?
Jiahao:
各ユーザーはウェブサイトまたはクライアントを開き、ローカルデータを指定して「Training」ボタンを押すだけで、トレーニングプロセスに入ることができます。一般ユーザーに対しては、シームレスなユーザーエクスペリエンスを実現しています。
TechFlow:異なるタスクのマッチングはどのように行われますか?
Jiahao:
私は訓練者として、自分のデータをさまざまなタスクにマッチさせることができます。たとえば、病院が睡眠データのプロジェクトを立ち上げ、毎日の睡眠データセットを利用したい場合、私はそれに参加する選択ができます。まるでマーケットプレイスのようであり、データ所有者として、どのプロジェクトに参加するかを選ぶ権利があります。このマーケットプレイスのインセンティブは企業側が提供します。病院、銀行、DeFiなどが報酬(Bounty)を設定し、たとえば20万ドルを提供して、FLock上に構築されたサブネット(subnet)への参加を促進します。
TechFlow:つまり、マーケティングではまずビジネスサイドから着手するのでしょうか?
Jiahao:
はい、現在の有料ユーザーはすべて企業契約です。すでに数回の納品を終えており、次はマーケットプレイスを公開し、より多くの企業が直接タスクを投稿できるようにして、より2C寄りの形にしたいと考えています。B2Bのオンボーディングプロセスを経る必要がなくなるようにするのです。
TechFlow:従来のデータ提供企業は、Web3に対してどれくらいの受け入れ姿勢ですか?
Jiahao:
コストが下がるため、彼らにとってメリットがあります。オンチェーン以外で同様のプロセスを行うと、数ヶ月かかり、多くの審査を通過する必要があります。また、国際共同臨床試験(Clinical Trial)を行う場合、問題はさらに深刻です。ほぼすべての国が医療データの国外流出を禁止しているため、多くの場合、そもそも実施できません。
そのため、FLockの出現は彼らにとって大きな突破口です。
第一に、本人のデータはすべてローカルに留まり、多くの規制を回避できます。
第二に、これまで考えられなかったことが可能になります。たとえば、中日韓が協力して、東アジア人の体質に特化した血糖値予測・監視のための連合学習を行うことができます。
さらに大きな可能性もあります。以前提携した病院側との話し合いでも出たアイデアですが、遠隔医療です。以前はほとんど不可能でした。データが国境を越えられないからです。しかし連合学習を使えば、「こちらで監視を行い、あちらで診断結果を出す」ことが可能になります。双方がお互いのデータを見ることなく、患者にとっては飛行機に乗って海外まで健診に行く手間が省けるのです。少なくとも私の知る限り、医療業界は連合学習を最も理解している業界であり、次に理解しているのは金融業界です。彼らは無数のテック企業に何度もプレゼンされてきたからです。
ただし、伝統的金融業界には手を出しておらず、DeFiと直接連携しています。彼らはWeb3を完全に理解しており、相互の理解コストが最も低いからです。
マーケットプレイス公開時には、個人ニーズに近いAIスタートアップに注力する予定です。たとえば音声模倣を行う企業です。以前、AIで写真を生成するアプリが流行りましたが、すぐに廃れました。その理由は、利用規約に「アップロードしたすべての写真の著作権は当社に帰属する」という恐ろしい条項があったためです。顔写真を10枚もアップロードするのに抵抗を感じる人が多かったのです。しかし、音声模倣を行うスタートアップがFLockを利用したい理由は、製品に「プライバシー保護の保証」としてFLockを貼り付け、ユーザーに安心感を与えるためです。「私の声はローカルに残り、ブロックチェーン上で第三者に送信されていないことが確認できる。その上で、趙本山の話し方を真似るなど楽しめる」というわけです。
最終的なビジョンとして、FLockがプライバシー業界のCertiKのような存在になることを望んでいます。プライバシー保護と非中央集権型モデル訓練の標準を定める存在となるのです。
TechFlow:P2Pネットワークをどれくらい研究して、実現可能だと判断しましたか?
Jiahao:
一年も満たないくらいですね。論文を数本出したところ、すぐに採択され、これは面白いと感じました。
審査員の反応は我々にとって重要な指標です。もし発表内容が「つまらない」「新しくない」と思われたら、マネタイズも難しいでしょう。しかし、我々が発表した際には非常に良いフィードバックが得られ、こうした前向きな反応は非常に助けになりました。
ただし、学術界の評価からマネタイズ段階へ移行するには、まだまだ努力が必要です。つまり、「資本にこの事業が意味があると思わせるには?」「将来性があると思わせるには?」というのが次の課題です。
第一段階はR&Dフェーズでした。その後、テスト版とオープンソースコードベースをリリースし、第二段階に入りました。2023年の深刻な熊相場の中、600万ドルのシードラウンドをクローズしました。Lightspeed Faction(光速アメリカ)が主導し、市場が最悪の時期に、AI専門のトップクラスのファンドから投資を受けたことは、大きな自信となり、長期的な発展に対する期待を高めました。
現在は第三段階、つまり市場からの全面的承認を得るフェーズです。私たちはFLockの非中央集権型トレーニングプラットフォームをリリースし、マーケットプレイスとして、すべてのユーザーが自分たちのコミュニティ向けAIモデルを構築できるようにします。すでに、世界最大のバリデータたちからサポートの予約が入っています。
TechFlow:現在、Web3の可能性に気づいた多くのプロジェクトが、ブロックチェーン技術を現実生活に応用しています。貴社もその一つですが、どのように市場露出を高めますか?
Jiahao:
いわゆる「ヒットアプリ」、または強いニーズ(剛需)を持つアプリの出現を目指しています。DeFiコミュニティと密接に連携するのも、このためです。DeFi領域には、強烈なニーズがあるが満たされていない要望がたくさんあるからです。
たとえば個人融資を行う際、信用情報と実際の銀行カードを紐づけることはできません。FLockなら、ユーザーのノード内で計算を行い、信用スコアを生成し、それを信用証明として提供できます。現時点では低担保ローンは難しいでしょう。当然、超過担保が必要です。しかし、他人が150%の超過担保を要求する場合、あなたは105%で済むかもしれません。これにより、貸借市場の効率が向上します。多くのユーザーにとって、これは剛需です。
もう一つの爆発的ヒットのポイントは、先ほど話した音声模倣アプリのようなものです。再び流行し、人々が共有し、インフルエンサーたちがこぞって紹介すれば、私もそのアプリをダウンロードしようと思うでしょう。
この二つの戦略が、私たちのユーザー獲得の主なチャネルです。
TechFlow:FLockはDePINの一カテゴリとも言えますが、現在のDecentralized ComputeやDecentralized Storageとの関係はどうなっていますか?
Jiahao:
上下流との協力関係は非常に良好です。私たちはTraining Layerに位置し、レイヤーの一つに過ぎません。伝統業界で言えばTensorFlowやPyTorchのような立ち位置であり、中間層のトレーニングフレームワークに相当します。モデルは依然としてAWSに配置する必要があり、データ保存にはAWSのS3を使うかもしれません。私たちはそれらをつなぐ仲介者にすぎず、計算資源の供給元やストレージソリューションも他に多数存在します。
データの非中央集権的ストレージ技術には、あまり革新的な余地がないと考えます。すでに成熟しています。私たちの第一版TestNetもIPFSと良好に連携しており、Decentralized Computeと連携することで、一般ユーザーがFLockの仕組みを難なく体験できるようになっています。
原理主義的に言えば、ビットコインはどう使うべきでしょうか? 自宅のパソコンを起動し、全世界の帳簿(Ledger)をダウンロードしてから、別のPCに送金するべきです。同様に、FLockの原理主義的な使い方も、自宅のPCを開き、すべてのデータを自宅に保管し、第三者に預けることなく、FLockネットワークに接続すべきです。それが最も安全だからです。しかし、誰もが高性能なPCを持ち、常にオンラインにしておくことを求めるのは現実的ではありません。そのため、Decentralized ComputeおよびDataストレージとの協力の最大の意義は、ユーザーがFLockにログインし、データをDecentralized Storageに置き、非中央集権的な計算リソースを使って結果を算出し、公正かつ透明な報酬分配を受けることができる点にあります。ユーザーはMetamaskのようにログインしてクリックするだけで済み、自らPCをホストする必要はありません。
私たちにとって、上下流との協力は、ユーザーエクスペリエンスを向上させるためのものです。
AIに関する余談:GPT、GNN、その他大規模モデル
TechFlow:銀行時代に連合学習をやっていましたか?
Jiahao:
実はしていません。銀行では主にNLP、特にGraph Neural Network(グラフニューラルネットワーク)やKnowledge Graph(知識グラフ)を扱っていましたので、この分野にはある程度精通しています。GPTが流行った後、知識グラフとニューラルネットワークの分野が完全に冷え込んでしまいました。帝国大学で指導している博士課程の学生二人の卒業論文も書き直しを迫られました。そうでなければ、「なぜGPTを使わないのか?」と簡単に突っ込まれてしまうからです。
TechFlow:GPTは意味的データ(Semantic Data)であり、Graphは非意味的データ(non-Semantic Data)が多い?
Jiahao:
そう言えます。しかし、「力技で奇跡を起こせる」のであれば、なぜGPTの背後にGraphを提案する必要があるのでしょうか? 2022年のNeurIPSで、私はパネリストとして参加し、華為研究のBoxing Chen氏、マイクロソフトのYu Cheng氏、MetaのMarjan氏と共にNLPの未来について議論しました。そのとき、私は必死に自分のKnowledge Graphに少しでも注目を集めようとしました。
しかし、主流の意見は「最高の計算能力、最高のアルゴリズム、最高のデータがあれば、エンドツーエンドで結果が得られる。なぜ内部の関係ネットワークを深く分析する必要があるのか?」というものでした。世界は功利主義的であり、ブラックボックスアルゴリズムでも、結果が良ければそれで十分なのだ。
判断分析を行うにはコストがかかりすぎ、効果も遅いのです。非常に直感的な例を挙げましょう。ニューラルネットワークが登場した当初、多くの保守的な学者は反対しました。「統計学的手法を使い、因果関係を理解すべきだ。aがbになる理由を数式で示すべきだ。それが機械学習だ」と。
しかし、ニューラルネットワーク派は「なぜそこまでするのか? aからbに変換できればいい。できなければネットワークを大きくすればいい。もっと大きくして、bになればいい」と主張しました。今や、誰がニューラルネットワークの不透明性を問題視していますか? むしろ、かつて因果分析を強く求めた業界(例:高频取引ファンド)でさえ、内部監査プロセスを変え、エンドツーエンドのテストで戦略を説明し、すべての因果分析レポートを捨て去っています。
消費主義市場の視点から見ると、Graphの未来も同様かもしれません。大規模モデルがここまで到達した後、次のサイクルでは、Graphの存在意義を忘れ去ってしまうかもしれません。次世代の人々からは、これは古い世代の学者が統計学アルゴリズムを研究していた時代遺物と見なされるかもしれません。
ただし、基礎科学の研究は常に必要不可欠であり、私は可能な限り支援し続けます。Graph研究分野には、依然として長く有望な道が続いています。これは私自身が10年間捧げてきた研究分野でもあるからです。はは。
参考資料
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














