

Vitalik Buterinの最新記事:TwitterのCommunity Notesは極めて暗号的精神にあふれており、新しいソーシャルメディア実験の未来が期待される
TechFlow厳選深潮セレクト
Vitalik Buterinの最新記事:TwitterのCommunity Notesは極めて暗号的精神にあふれており、新しいソーシャルメディア実験の未来が期待される
Community Notes は暗号化プロジェクトではないが、主流の世界で「暗号的価値観」に最も近い実例かもしれない。
執筆:vitalik
編集:TechFlow
ここ2年間、Twitter(X)は紛れもなく混乱の時代を過ごしてきた。昨年、Elon Muskが440億ドルでこのプラットフォームを買収し、その後、会社の人員構成、コンテンツモデレーション、ビジネスモデル、さらにはサイト文化に至るまで全面的な改革を断行した。こうした変化の多くは、特定の政策決定というよりも、むしろElon Musk自身のソフトパワーによるものだったかもしれない。しかし、これらの物議を醸す行動の中でも、Twitter上で新しい機能が急速に注目を集め、さまざまな政治的立場から支持されている:Community Notesである。
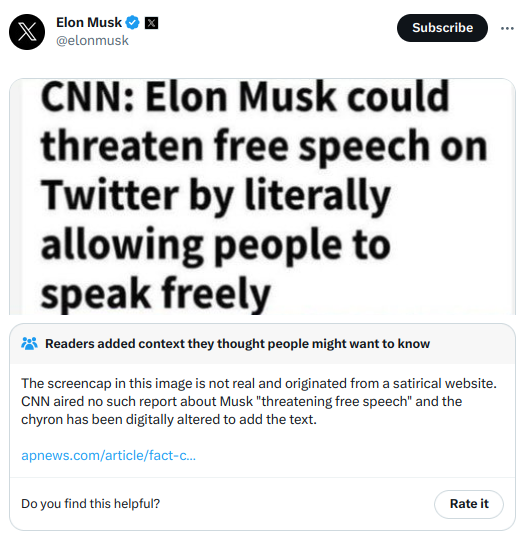
Community Notesはファクトチェックツールであり、時にツイートに背景情報を提供する注釈として表示される。上のElon Muskのツイートにもその一例があるように、誤情報への対抗策として機能している。もともとはBirdwatchと呼ばれ、2021年1月にパイロットプロジェクトとして開始された。それ以来徐々に拡大され、特にMuskがTwitterを引き継いだ昨年の時期に最も急速な成長を見せた。現在では、注目度の高いツイート、特に論争的な政治的トピックに関連するものに対して、頻繁にCommunity Notesが添付されるようになっている。私自身の見解およびさまざまな政治的立場の人々との対話を通じて得られた結論として、これらの注釈は実際に表示された際、情報量があり、価値あるものだと感じている。
しかし、私が特に興味深いと感じるのは、Community Notesが「暗号プロジェクト」ではないにもかかわらず、主流社会において「暗号的価値観」に最も近い実例の一つとなっている点だ。Community Notesは、中央集権的に選ばれた専門家によって作成・管理されるわけではない。誰もが注釈を作成・投票でき、どの注釈が表示されるかは完全にオープンソースのアルゴリズムによって決まる。Twitterには、このアルゴリズムの動作原理を詳細に説明するガイドが存在し、公開されている注釈や投票データをダウンロードして、自らアルゴリズムをローカルで実行し、Twitter上での出力結果と一致するかを検証することも可能だ。完璧ではないものの、極めて論争的な状況下でも驚くほど「信頼できる中立性」という理想に近く、かつ非常に実用的である。
Community Notesのアルゴリズムはどのように機能するのか?
一定の条件を満たすTwitterアカウント(基本的には:6ヶ月以上活動しており、規約違反歴がなく、電話番号を認証済み)であれば、誰でもCommunity Notesに参加登録できる。現時点では、参加者はゆっくりとランダムに受け入れられているが、将来的には条件を満たすすべてのユーザーが参加可能になる予定だ。一度承認されると、まず既存の注釈に対して評価を行うことができ、その評価が十分に適切であることが確認された時点で(つまり、その評価が最終的な注釈判定とどれだけ一致していたかで測定)、自分で注釈を作成できるようになる。
自分が作成した注釈は、他のCommunity Notesメンバーによるレビューによってスコアを得る。これらのレビューは、「役に立つ」「やや役に立つ」「役に立たない」という3段階の投票と見なせるが、さらにアルゴリズム内で役割を果たす追加のラベルも含まれる。これらレビューに基づき、注釈にはスコアが与えられる。スコアが0.40を超えると、その注釈は表示される。そうでなければ表示されない。
このアルゴリズムの特徴は、スコアの計算方法にある。単純な合計や平均を取るような素朴なアルゴリズムではなく、Community Notesのスコリングアルゴリズムは、異なる意見を持つ人々の間で**共通の肯定的評価**を得た注釈を優先しようとする。つまり、普段は評価で意見が分かれるユーザーたちが、特定の注釈について一致した場合、その注釈は高スコアを得る。
その仕組みを詳しく見てみよう。ユーザーの集合と注釈の集合があり、行列Mを考える。ここで、要素Mijはi番目のユーザーがj番目の注釈に与えた評価を表す。
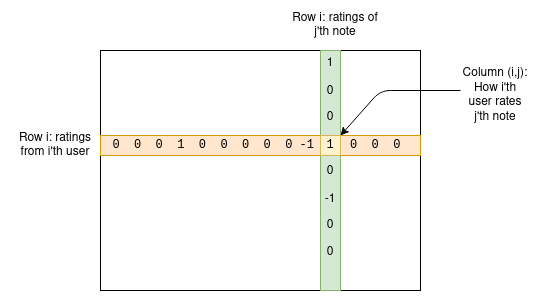
特定の注釈に対して、ほとんどのユーザーは評価を行っていないため、行列の大部分はゼロだが、問題はない。アルゴリズムの目的は、各ユーザーと各注釈に対してそれぞれ2つの統計量を割り当てる四次元モデルを作ることだ。ユーザーには「親しみやすさ(friendliness)」と「極性(polarity)」、注釈には「有用性(usefulness)」と「極性(polarity)」を割り当てる。そして以下の式を使って、行列の値をこれらの変数の関数として予測しようとする。
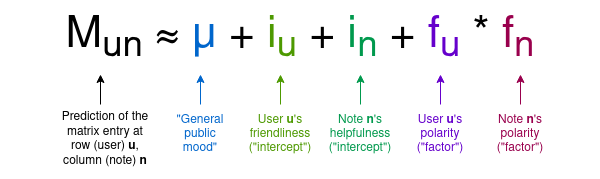
ここで紹介するのは、Birdwatch論文で使われている用語と、数学的概念を使わずに直感的に理解しやすい私の独自用語:
-
μは「世論パラメータ」で、ユーザー全体がどれだけ高い評価を与える傾向にあるかを示す。
-
iuはユーザーの「親しみやすさ」。つまり、そのユーザーが高評価をつける可能性の高さ。
-
inは注釈の「有用性」。つまり、その注釈が高評価を得る可能性の高さ。これが私たちが知りたい変数だ。
-
fuまたはfnはユーザーまたは注釈の「極性」。つまり、政治的スペクトルにおける位置。負の極性はおおむね「左寄り」、正の極性は「右寄り」を意味するが、重要なのは、この軸はデータ分析によって自動的に導出されており、「左派」「右派」という概念はハードコードされていないことだ。
このアルゴリズムは、標準的な勾配降下法というごく基本的な機械学習モデルを用いて、行列の値を最もよく予測する変数の最適値を求めている。特定の注釈に割り当てられた「有用性」がその注釈の最終スコアとなる。有用性が+0.4以上なら、注釈は表示される。
ここで巧妙なのは、「極性」が、ある注釈が一部のユーザーに好まれて他には嫌われる特性を吸収し、「有用性」はすべてのユーザーに好まれる特性のみを測る点だ。これにより、「有用性」の高い注釈は、異なった立場のグループ間で広く認められたものとなり、一方で特定のグループ内でのみ称賛され他からは反感を買うような注釈は排除される。
上記はあくまでアルゴリズムの核心部分の説明だ。実際には、さらに多くの追加メカニズムが導入されている。幸運にも、これらは公開ドキュメントで説明されている。主なものは以下:
-
アルゴリズムは複数回実行され、毎回ランダムに生成された極端な「擬似投票」が投票データに追加される。つまり、各注釈に対する真の出力は範囲として表され、最終結果はその範囲内の「下限信頼区間」が0.32の閾値を超えているかどうかで決まる。
-
多くのユーザー(特にその注釈の極性と近いユーザー)が注釈を「無用」と評価し、かつ同じ「ラベル」(例:「議論を呼ぶ・偏った表現」「情報源が注釈を裏付けていない」)を理由としている場合、注釈掲載に必要な有用性閾値は0.4から0.5に引き上げられる(数値的には小さいが、実際には非常に大きな違い)。
-
注釈が一旦承認された後でも、その有用性スコアが掲載に必要な閾値より0.01ポイント下回ると、表示が解除される。
-
複数のモデルを用いた追加実行を行い、初期の有用性スコアが0.3〜0.4の注釈を押し上げる場合もある。
まとめると、22ファイルにわたる計6282行の複雑なPythonコードが出来上がる。しかし、これらすべてはオープンであり、注釈と評価データをダウンロードして自分で実行し、Twitter上の結果と一致するか検証できる。
実際にはどうなっているのか?
このアルゴリズムが単なる評価の平均とは大きく異なる点は、私が「極性」と呼んでいる概念だろう。アルゴリズム文書ではこれをfuとfnと呼び、fはfactor(因子)の略で、これらが互いに乗算されるためである。多様な次元を持つことを将来的に想定しているため、より汎用的な用語が使われている。
極性はユーザーと注釈の両方に割り当てられる。ユーザーIDと実際のTwitterアカウントの紐付けは意図的に非公開だが、注釈自体は公開されている。実際、少なくとも英語データセットでは、アルゴリズムが生成する極性は左右の政治的立場と非常に強く相関している。
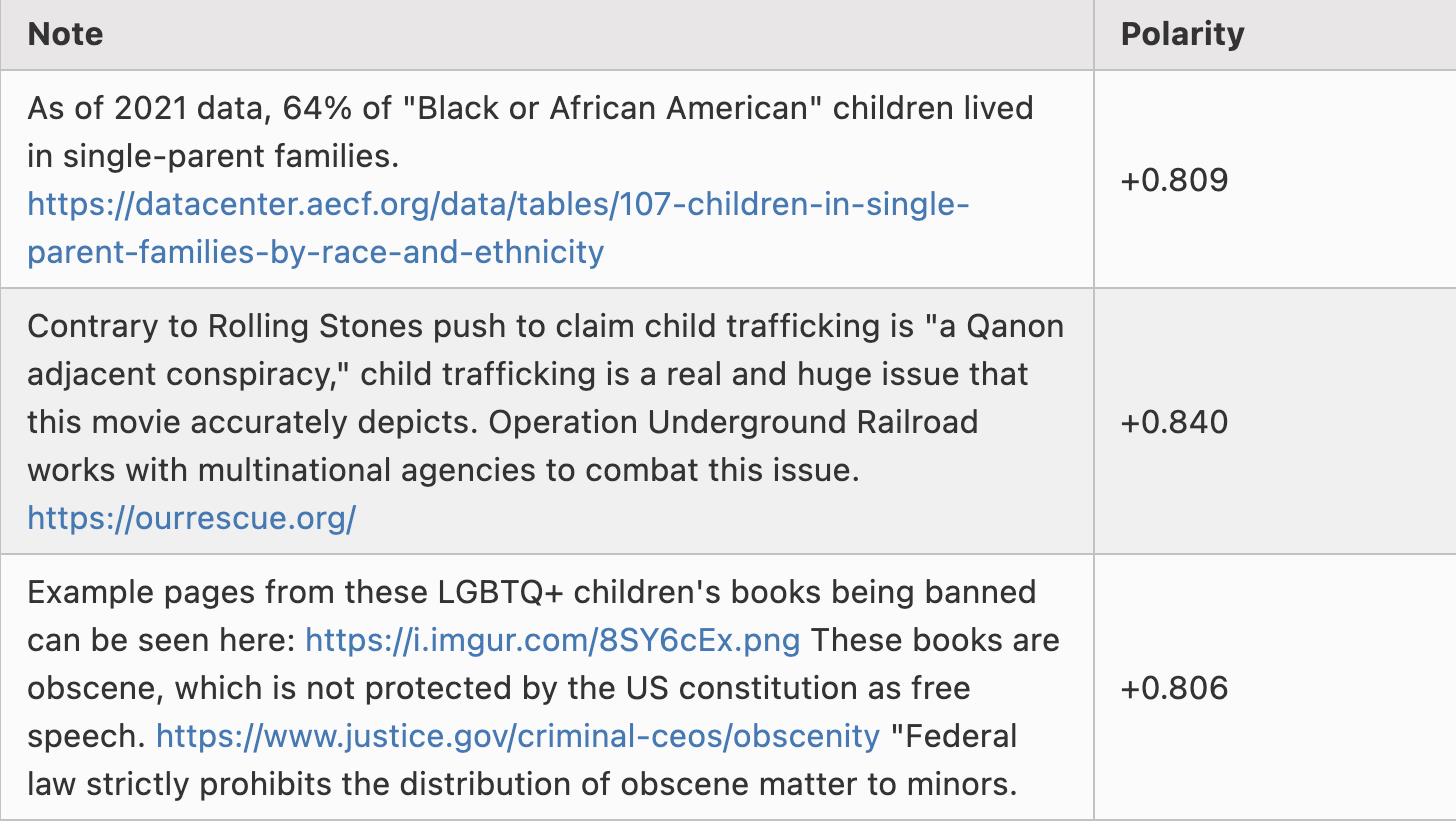
以下は極性が約-0.8の注釈の例だ:
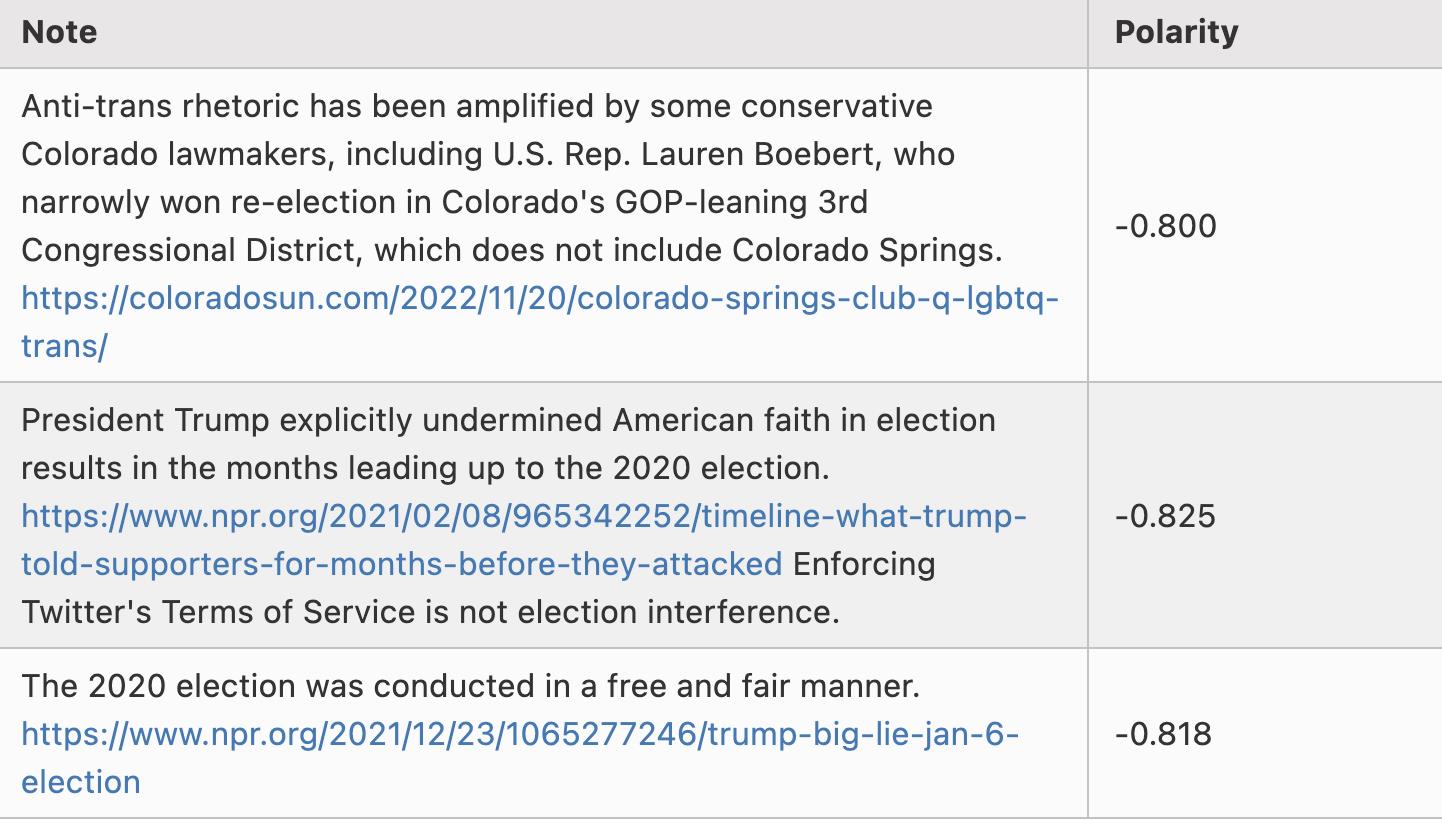
ここで私は意図的に選び抜いたわけではなく、ローカルでアルゴリズムを実行して生成したscored_notes.tsvファイルから、極性スコア(coreNoteFactor1列)が-0.8未満の最初の3行をそのまま示している。
次に、極性が約+0.8の注釈の例を見てみよう。実際には、これらの大半はポルトガル語でブラジル政治について語るもの、あるいはテスラのファンがテスラ批判に反論したものばかりなので、ここではそれら以外のものを少し選んで提示する:
繰り返すが、「左派 vs 右派」という区分はアルゴリズムに一切ハードコードされていない。これは計算によって発見されたものだ。つまり、このアルゴリズムを他の文化的文脈に適用すれば、その社会の主要な政治的分断軸を自動的に検出し、それを橋渡しする可能性があることを示している。
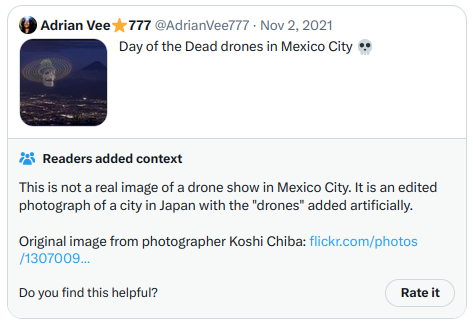
一方で、最も高い「有用性」を得た注釈は次のようになる。今回は実際にTwitterに表示されたものなので、スクリーンショットを直接貼れる:
もう一つ:
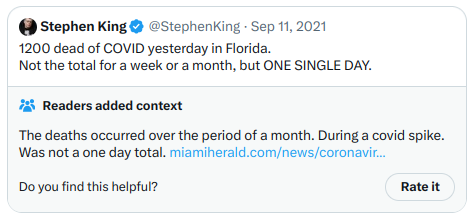
二つ目の注釈は明らかに党派性の高い政治的テーマに直接関わっているが、明確で質が高く、情報豊富な内容のため高評価を得ている。総じて、このアルゴリズムは機能しており、コードを実行して出力を検証することも可能だ。
このアルゴリズムについての私の見解
このアルゴリズムを分析する上で最も印象的なのは、その複雑さだ。「学術論文版」では勾配降下法を使って五つのベクトルと行列方程式の最適フィットを求めているが、実際の実装はさらに複雑で、複数の処理ステップからなり、途中には多くの任意の係数が登場する。
学術論文版ですら、背後にある複雑さを隠している。最適化される方程式は負の4次式である(予測式にfu×fnの2乗項があり、コスト関数は誤差の2乗を測るため)。変数がいくつであっても2次式の最適化は通常一意の解を持ち、基本的な線形代数で計算できるが、多数の変数における4次式の最適化は多くの局所解を持ち、勾配降下法の結果は初期値や微小な入力変化によって大きく変わる可能性がある。わずかな変動が、ある局所最小値から別のものへジャンプさせ、出力を大きく変える。
これは私が関わってきたアルゴリズム(例:二次資金調達)との違いであり、経済学者のアルゴリズムとエンジニアのアルゴリズムの違いのように感じる。経済学者のアルゴリズムは理想的な条件下でシンプルさを重視し、解析が比較的容易で、タスクに対して理論的に最適(あるいは最悪でもましな)であることが数学的に示され、悪用しようとした場合のリスクも定量的に評価できる。一方、エンジニアのアルゴリズムは試行錯誤の反復プロセスを通じて、現実の運用環境で何がうまく働き何が失敗するかに基づいて設計される。エンジニアのアルゴリズムは実用的で「動く」が、想定外の状況で暴走する可能性がある。
あるいは、尊敬されるインターネット哲学者roon(別名tszzl)が関連テーマで述べたように:

もちろん、私は暗号の「理論的美学」が不可欠だと考える。それは、本当に信頼不要なプロトコルと、表面的には良さそうに見えるが実際は中心的な参加者に依存している、あるいはもっと悪いことに完全な詐欺であるようなシステムを正確に区別できるからだ。
深層学習は通常は機能するが、様々な敵対的機械学習攻撃に対して避けられない弱点を持つ。もし可能ならば、技術的トラップや高度に抽象化された枠組みでこうした攻撃に対抗できる。そこで私は疑問を抱く:Community Notes自体を、より「経済学者のアルゴリズム」に近づけることはできないだろうか?
それが具体的にどういうことかを理解するために、私が以前似た目的で設計したアルゴリズムの一例を見てみよう:Pairwise-bounded quadratic funding(新たな二次資金調達方式)。
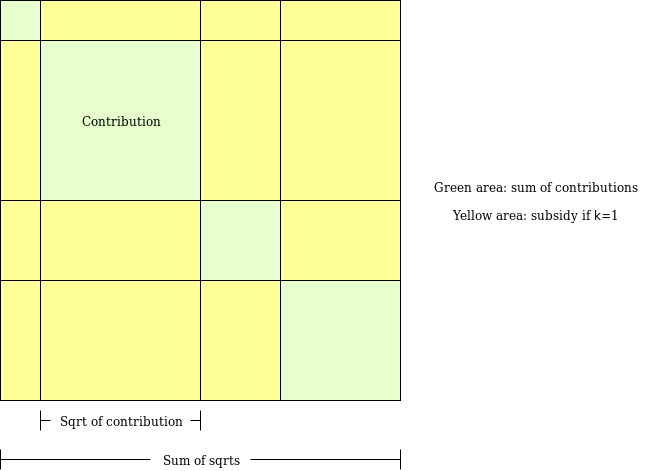
Pairwise-bounded quadratic fundingの目的は、「通常の」二次資金調達に存在する穴を埋めることにある。つまり、2人の参加者が共謀すれば、虚偽のプロジェクトに巨額を拠出し、補助金を自分たちに戻すことで資金プールを枯渇させることが可能になるという問題だ。この方式では、各ペアの参加者に有限の予算Mを割り当てる。アルゴリズムはすべての可能なペアを走査し、参加者AとBがともに支持するプロジェクトPに補助金を出す場合、その分がペア(A,B)の予算から差し引かれる。そのため、k人の共謀者が盗める金額は最大でもk×(k−1)×Mに制限される。
この形式のアルゴリズムはCommunity Notesの文脈には直接適用できない。なぜなら、各ユーザーの投票数は非常に少ないため、任意の2ユーザー間の共通投票数は平均してゼロであり、ペア単位の分析ではユーザーの極性を把握できないからだ。機械学習モデルの目的はまさに、このような非常に疎なデータから行列を「埋める」ことにある。しかし、少数の悪意ある投票に対して結果が極端に不安定にならないよう保つには、追加の工夫が必要となる。
Community Notesは本当に左右の極端から独立しているのか?
Community Notesのアルゴリズムが実際に極端から抵抗性を持っているか、つまり素朴な投票アルゴリズムより優れているかを分析してみよう。素朴な投票アルゴリズムでもある程度の抵抗性はある:「200のいいね」と「100のダメ」がある投稿は、「200のいいね」しかない投稿より劣る。しかし、Community Notesはそれ以上に優れているのだろうか?
抽象的なアルゴリズムだけでは判断が難しい。平均評価が高いが極端に分かれている投稿が、強い極性と高い有用性を同時に持つのはなぜ防げるのか? 理論上は、相反する投票があれば極性が「その特性を吸収」するはずだが、本当にそうなるのか?
これを確かめるために、簡易実装を100回実行して平均を取った結果が以下だ:

このテストでは、「良い」注釈は同じ政治的立場のユーザーから+2、反対立場のユーザーから+0の評価を得ており、「良いがより極端」な注釈は同派から+4、反対派から-2を得ている。平均評価は同じだが、極性は異なる。実際、「良い」注釈の方が「良いが極端」な注釈より平均有用性が高くなっている。
「経済学者のアルゴリズム」に近いものであれば、極端性に対するペナルティの仕組みがより明確に説明できるだろう。
高リスク状況下での有用性はどの程度か?
具体的な事例を検証することで、その有用性の一端を理解できる。約1ヶ月前、Ian Bremmer氏が、中国政府高官のツイートに非常に批判的なCommunity Noteが付けられたが、その後削除されたと不満を述べていた。
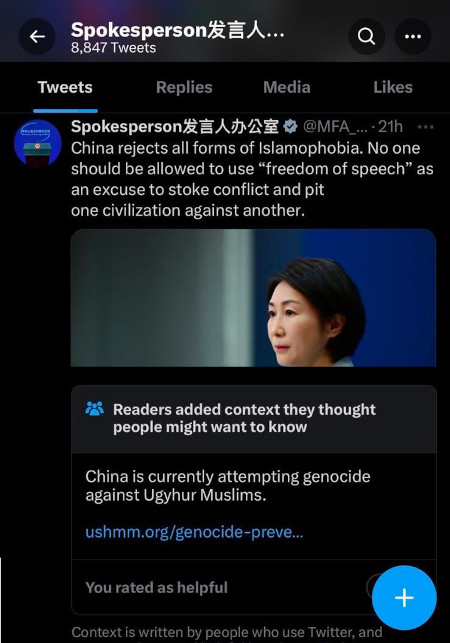
これは難しい課題だ。イーサリアムコミュニティのような環境でメカニズム設計を行うのは、せいぜい2万ドルが極端なインフルエンサーに流れることくらいの問題だが、数百万人の命や政治的地政学的問題がかかっている状況では話が全く違う。誰もが最悪の動機を疑ってしまうのが当然だからだ。しかし、メカニズム設計者が世界に大きな影響を与えたいのなら、こうした高リスク環境に向き合うことは避けられない。
Twitterの場合、中心的な操作の疑いが生じる明白な理由がある:Elon Muskは中国に多くのビジネス利益を持っており、彼がCommunity Notesチームに圧力をかけ、アルゴリズムの出力を操作して特定の注釈を削除させた可能性がある。
幸運にも、このアルゴリズムはオープンソースで検証可能なので、実際に調査できる! やってみよう。元のツイートのURLは https://twitter.com/MFA_China/status/1676157337109946369 だ。末尾の数字1676157337109946369がツイートIDである。このIDでダウンロード可能なデータを検索し、該当する注釈の行を特定する:
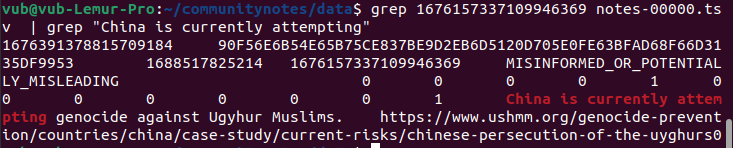
ここで、注釈自体のID、1676391378815709184が得られる。次に、アルゴリズム実行で生成されるscored_notes.tsvおよびnote_status_history.tsvファイルでこのIDを検索する:
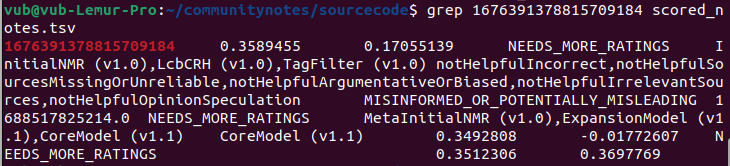

最初の出力の2列目は注釈の現在のスコア。2つ目の出力は履歴で、7列目が現在の状態(NEEDS_MORE_RATINGS)、5列目が直前の非「評価待ち」状態(CURRENTLY_RATED_HELPFUL)。つまり、アルゴリズム自体がまず注釈を表示し、その後スコアが下がって削除されたことがわかる。中心的な介入は見られない。
投票データ自体を調べることでもう一つのアプローチができる。ratings-00000.tsvファイルをスキャンし、この注釈に対するすべての評価を抽出し、「役に立つ」「役に立たない」の数を確認する:

タイムスタンプ順に並べ替えて最初の50票を見ると、40票が「役に立つ」、9票が「役に立たない」だった。つまり、初期の閲覧者には高く評価されていたが、後の閲覧者には低く評価され、スコアが時間とともに低下したことがわかる。
残念ながら、注釈の状態変化の正確なメカニズムは説明が難しい:「0.40以上→以下になったので削除」という単純な話ではない。大量の「役に立たない」評価が異常条件をトリガーし、注釈が維持されるために必要な有用性スコアが引き上げられたのだ。
これは重要な教訓だ:信頼できる中立性を持つアルゴリズムを「本当に信頼できる」ものにするには、シンプルさが不可欠だ。注釈が受容から拒絶に変わった場合、その理由を簡単明瞭に説明できなければならない。
もちろん、別の種類の操作もあり得る:ブリゲーディング(brigading)。ある注釈に反対する人々が、熱心なコミュニティ(あるいはもっと悪いことに、多数の偽アカウント)を動員して「役に立たない」と大量投票すれば、わずかな投票で注釈を「有用」から「極端」に変えてしまう可能性がある。こうした協調攻撃に対する脆弱性を減らすには、さらなる分析と改良が必要だ。一つの改善案は、すべてのユーザーがすべての注釈に投票できるのではなく、推薦アルゴリズムによって注釈をランダムに割り当て、その割り当てられたものだけに評価できるようにすることだ。
Community Notesはあまりに「臆病」なのではないか?
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














