

Web3分散型データベースストレージの現状と未来
TechFlow厳選深潮セレクト
Web3分散型データベースストレージの現状と未来
なぜ中央集権型データベースが必要とされるのか?分散型データベースの良し悪しはどのように評価すればよいのか?
執筆:Maggie
なぜ分散型データベースが必要なのか?
Web2アプリケーションのデータストレージには、ファイルシステム(File System)とデータベース(Database)という2つの基本的な方法がある。Web3にはデータベース製品が不足しているため、DAppのほとんどは、わずかに重要なデータを高価なスマートコントラクトに保存する以外は、依然として構造化データの保存に中心化されたデータベースを使用している。しかし近年、IPFSなどの分散型ファイルシステムがWeb3アプリケーションのNFTデータ保存に徐々に利用されるようになり、分散型ファイルシステムはWeb3によって認められ受け入れられるようになった。これに伴い、分散型データベース技術も一回り進化し、さまざまな新製品が登場している。
分散型データベースは、従来の中心化データベースとは異なり独自の利点を持つ。これにより、Web3プロジェクトにおける単一障害点(SPOF)のリスクを低減し、DAppを完全に非中央集権化できる。
分散型データベースは、アクセス頻度の高いホットデータの保存に適しており、DAppの財務関連ではないデータ、例えば以下のデータの保存に最適である。
-
NFTメタデータ
-
DAOの投票データ
-
DEXの注文ブック
-
分散型ソーシャルデータ、ブログデータ、メール
-
DAppが必要とする複雑なリレーショナルデータベースのデータ
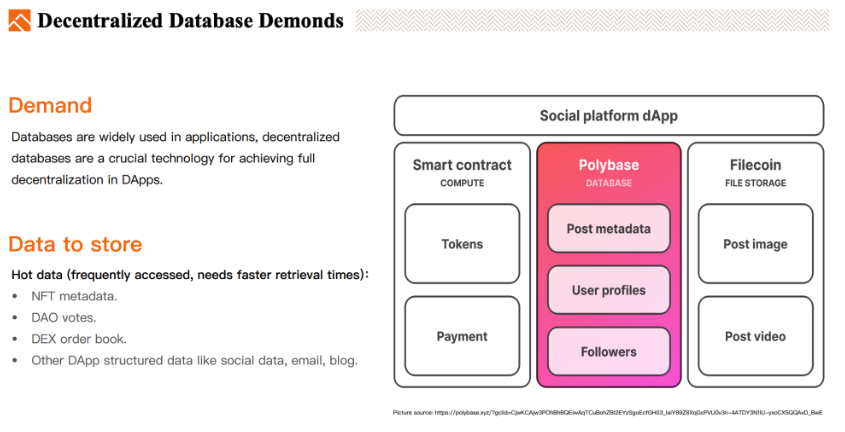
どのような種類の分散型データベースストレージシステムがあるのか?
ここ2年ほどで多くの分散型データベースプロジェクトが登場し、その中には革新的なプロジェクトも多く、注目を集めている。
-
Ceramic:Ceramic は2019年から始まったプロジェクト。データは「ストリーム」という形で保存・管理され、フォーマットされたイベントログがストリームに追加される。このログはファイル化され、IPFSへアップロードされる。GraphQL APIによるクエリを提供。Ceramic は IPFS のようなインセンティブモデルを持っておらず、データの作成・読み取り・更新(CRU)をサポートしている。
-
OrbitDB:OrbitDB は Ceramic よりも早い時期に登場したプロジェクトで、IPFSファイルシステムを用いてファイルを保存する。NoSQLデータベースおよびファイルの保存をサポートしている。
-
Tableland:2022年に開始されたプロジェクトで、現在パブリックテスト段階にある。本番版は2023年にリリース予定。データの保存にはスマートコントラクトを使用し、SQL文を定義して使用権限を設定する。データの読み取りはオンチェーンではなくオフチェーンで行われるため、手数料は不要。現在、このコントラクトはETHやOPなどのL2上にデプロイされている。
-
Polybase:現在テストネット上で動作中。CRUD操作をサポートするNoSQLデータベースで、各操作に対して手数料が発生する。また、Polybase はローカルディスク、IPFS、Filecoin、Polystore、さらにはAWS S3など、さまざまなファイルシステムを使ってデータベースファイルを保存できる。また、支払いチャネルを利用してデータクエリの支払いを行い、オンチェーン取引の頻度を減らし、支払いによるクエリ遅延を回避している。
-
Web3Q:2022年に開始されたプロジェクトで、テストネットはすでに稼働中。データアクセス用の新しいURL形式「Web//access protocol」を提案している。課金モデルが特徴的で、データを削除すると返金される仕組みになっている。
-
Kwil:Kwil はArweaveを基盤としたSQLデータベースシステムであり、スマートコントラクトによる支払いを行う。
-
KYVE:KYVE はArweaveを基盤としたデータベースシステムである。
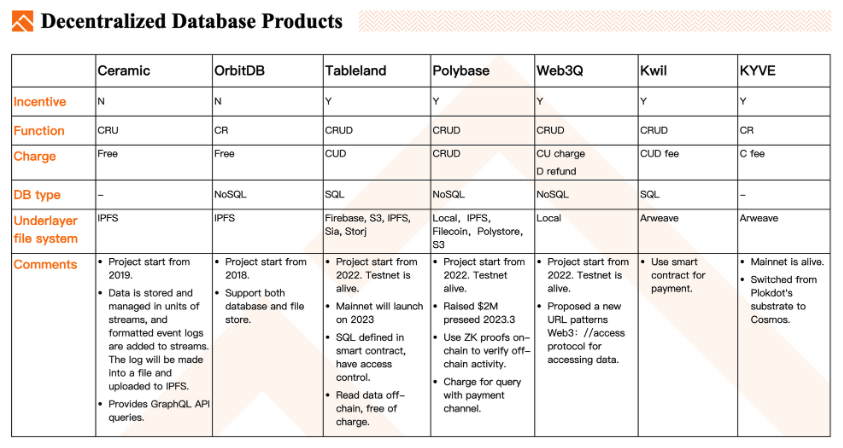
技術面
-
SQLとNoSQLの両方ともデータベースとして使用可能であり、SQLの方が成熟しており効率的だが、NoSQLの方が豊かで柔軟性が高い。SQLはデータ構造の一貫性が高く、結合クエリ機能が強力で、成熟度と効率性に優れる。一方、NoSQLのKV形式はイーサリアムの設計パターンに合致しており、多様なデータ型をサポートでき、柔軟かつ拡張しやすい。
-
機能面では、CRUDをサポートしていることが理想的だが、更新(Update)や削除(Delete)をサポートするとシステムの複雑さが増す。ローカルストレージを採用している場合、履歴値のクエリができない可能性がある。IPFSやArweaveを使用する場合は、データベースをappend-only(追記のみ)にする必要がある。そうでないと、同じデータに複数のバージョンが存在し、ストレージコストが倍増する。
-
基盤となるファイルシステムの選択肢は2つある。
-
ローカルにファイルを保存する方が柔軟性が高く、検索ロジックをカスタマイズでき、効率も上がる。また、Arweaveなどの分散型ファイルシステムを利用することによる信頼性の低下や複雑さを回避できる。たとえば、ユーザーがTokenAでデータベースマイナーに支払いを行い、マイナーがArweaveコインを支払ってデータを保存する場合、二重のネットワーク構造が複雑さを生む。
-
データベースファイルをIPFSやArweaveなどの分散型ファイルシステムに保存する方法;
-
ノードのローカルまたはS3クラウド上に保存する方法。
-
-
分散型ストレージと同様に、データ検索速度の改善、インセンティブモデルとトークン経済、そしてデータ可用性を保証するアルゴリズムは、プロトコルが広く使われるかどうかの鍵となる要素である。
-
優れたインセンティブモデルとトークンモデルは、ノードの参加意欲を高めるだけでなく、ノードが正しい行動を取ることを促進する。例えば、単にデータを保存してストレージ報酬を得るだけでなく、有効な検索機能を提供することを促す。
-
データ可用性保証アルゴリズムは定期的にノードのデータ保存状況をチェックし、ノードにデータ可用性の証明を提出させる。この証明はノードのインセンティブと相まって、データ消失を防ぐ役割を果たす。
-
データ検索の速度はユーザーエクスペリエンスに直結し、DAppの使いやすさとスムーズさにとって極めて重要である。
-
まとめ
-
分散型データベース分野は非常に注目度が高く、緊急性のあるニーズがあるが、現時点では広く受け入れられ、利用されている製品はまだ存在しない。
-
分散型データベース技術の成熟度は、分散型ファイルストレージシステムよりも低い。なぜなら、分散型データベース技術は分散型ファイルシステムに基づいているためである。多くのプロジェクトは2022年に開始されたばかりだ。
-
データ検索速度の改善、インセンティブモデルとトークン経済、データ可用性を保証するアルゴリズムは、プロトコルが広く採用されるかどうかの鍵となる。今後のプロトコルの重点は検索時間の短縮に置かれることだろう。これはDAppの使いやすさとスムーズさにとって極めて重要である。

TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














