

Un article de 10 000 mots d’a16z : La prochaine frontière de l’IA ne réside pas dans le langage, mais dans le monde physique — un triple cercle vertueux composé de robots, de science autonome et d’interfaces cerveau-machine
TechFlow SélectionTechFlow Sélection
Un article de 10 000 mots d’a16z : La prochaine frontière de l’IA ne réside pas dans le langage, mais dans le monde physique — un triple cercle vertueux composé de robots, de science autonome et d’interfaces cerveau-machine
Ce sont les robots généraux, la science autonome (« scientifiques IA ») et les interfaces cerveau-machine — de nouvelles interfaces homme-machine — qui pourront véritablement déployer les capacités révolutionnaires de la prochaine génération.
Auteur : Oliver Hsu (a16z)
Traduction et adaptation : TechFlow
Introduction de TechFlow : Cet article, rédigé par Oliver Hsu, chercheur chez a16z, constitue à ce jour la cartographie d’investissement la plus systématique jamais publiée sur l’intelligence artificielle physique (« Physical AI »), depuis 2026. Selon l’auteur, la voie fondamentale centrée sur le langage et le code continue de progresser selon ses lois d’échelle, mais les véritables capacités disruptives de la prochaine génération émergeront dans trois domaines adjacents à cette voie principale : les robots généralistes, la science autonome (les « scientifiques IA ») et les nouvelles interfaces homme-machine, notamment les interfaces cerveau-machine. L’auteur décompose les cinq capacités fondamentales qui soutiennent ces domaines, et démontre comment ces trois fronts stratégiques s’alimentent mutuellement au sein d’un cercle vertueux structurel. Pour quiconque souhaite comprendre la logique d’investissement sous-jacente à la Physical AI, ce cadre constitue actuellement la vision la plus complète disponible.
Le paradigme dominant de l’IA aujourd’hui s’organise autour du langage et du code. Les lois d’échelle des grands modèles linguistiques (LLM) sont désormais bien établies ; la boucle commerciale vertueuse alimentée par les données, la puissance de calcul et les améliorations algorithmiques est en pleine action ; chaque saut de capacité génère encore des retours substantiels — et la plupart de ces retours sont tangibles. Ce paradigme mérite pleinement le capital et l’attention qu’il attire.
Mais un autre ensemble de domaines adjacents, déjà en phase de gestation, réalise des progrès concrets. Il inclut notamment les modèles VLA (vision-langage-action), les modèles WAM (World Action Models), qui constituent des pistes prometteuses pour la robotique généraliste, les approches de raisonnement physique et scientifique centrées sur le concept de « scientifique IA », ainsi que les nouvelles interfaces homme-machine redéfinies grâce aux avancées de l’IA (y compris les interfaces cerveau-machine et les neurotechnologies). Au-delà des progrès technologiques eux-mêmes, ces orientations commencent à attirer talents, capitaux et fondateurs. Les primitives techniques permettant d’étendre l’IA de pointe au monde physique maturent simultanément : les progrès accomplis au cours des dix-huit derniers mois indiquent clairement que ces domaines vont bientôt entrer chacun dans leur propre phase d’échelle.
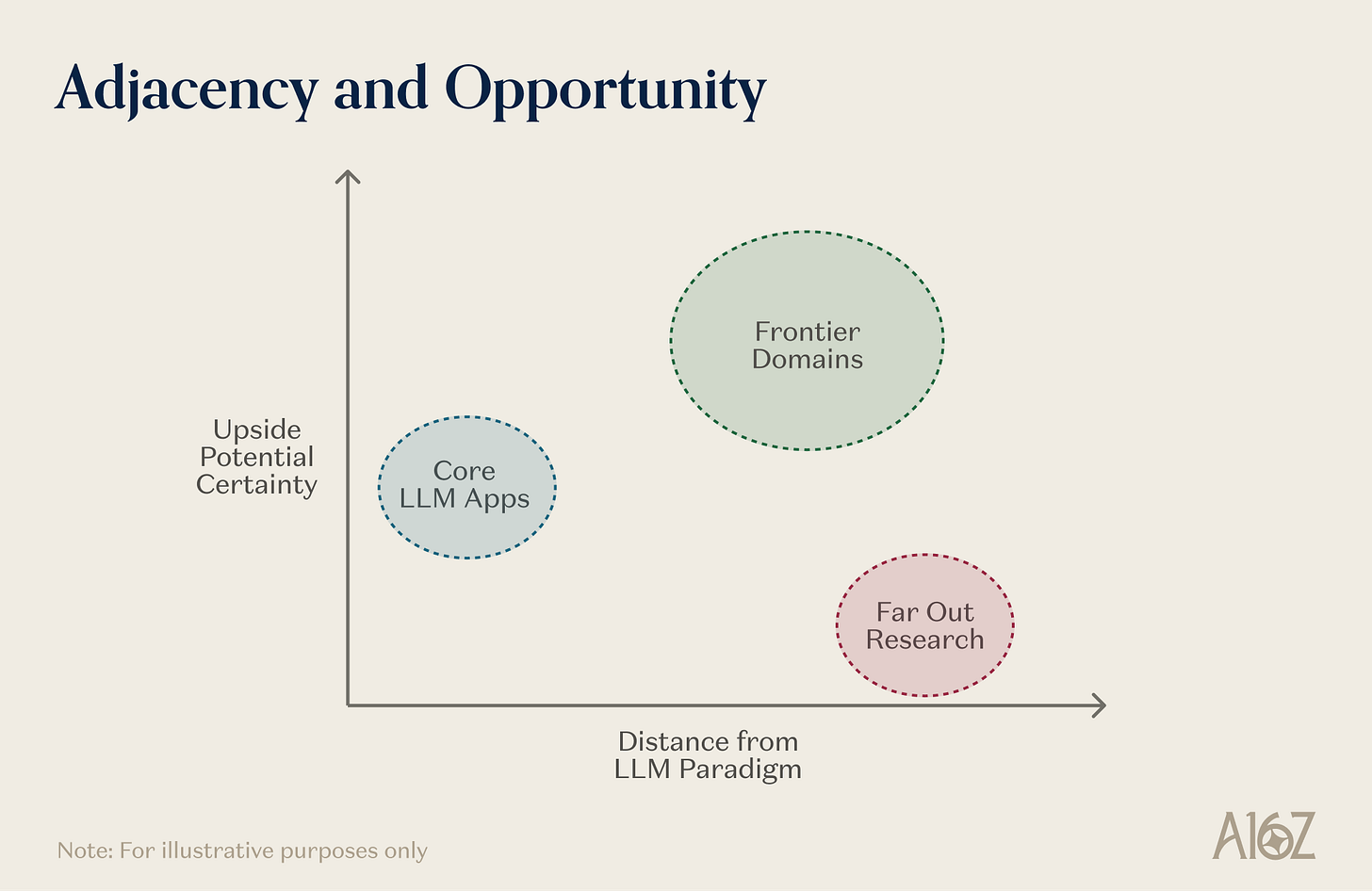
Dans tout paradigme technologique, les domaines où l’écart entre les capacités actuelles et le potentiel à moyen terme est le plus important présentent généralement deux caractéristiques : premièrement, ils peuvent tirer profit des mêmes avantages d’échelle qui propulsent actuellement les frontières de la recherche ; deuxièmement, ils se trouvent à une distance stratégique du paradigme dominant — suffisamment proche pour hériter de ses infrastructures et de son élan de recherche, mais suffisamment éloignés pour exiger un travail concret et spécifique. Cette distance joue un double rôle : elle constitue naturellement une barrière protectrice contre les suiveurs rapides, tout en définissant un espace de problèmes plus rare, moins encombré, donc plus propice à l’émergence de nouvelles capacités — précisément parce que les raccourcis n’ont pas encore été empruntés.

Légende de l’illustration : Relation schématique entre le paradigme actuel de l’IA (langage/code) et les systèmes de pointe adjacents
Aujourd’hui, trois domaines correspondent précisément à cette description : l’apprentissage robotique, la science autonome (en particulier dans les domaines des matériaux et des sciences de la vie), et les nouvelles interfaces homme-machine (incluant les interfaces cerveau-machine, la parole silencieuse, les dispositifs neuroportables, ainsi que de nouveaux canaux sensoriels tels que l’olfaction numérique). Ces domaines ne constituent pas des travaux entièrement indépendants ; ils appartiennent tous à la même catégorie de « systèmes de pointe dans le monde physique ». Ils partagent un ensemble de primitives fondamentales : les représentations apprises de la dynamique physique, les architectures orientées vers l’action incarnée, les infrastructures de simulation et de données synthétiques, l’élargissement continu des canaux sensoriels, et l’orchestration d’agents intelligents en boucle fermée. Ils se renforcent mutuellement via des relations de rétroaction transversales. Ce sont également les domaines les plus susceptibles de voir émerger des capacités qualitativement nouvelles — fruit de l’interaction entre la taille des modèles, la mise en œuvre physique et de nouvelles formes de données.
Cet article présente les primitives techniques qui soutiennent ces systèmes, explique pourquoi ces trois domaines représentent les opportunités les plus prometteuses à la pointe de la recherche, et propose que leurs interactions mutuelles forment un cercle vertueux structurel capable de propulser l’IA vers le monde physique.
Cinq primitives fondamentales
Avant d’examiner les applications concrètes, il convient de comprendre la base technique commune à ces systèmes de pointe. L’extension de l’IA de pointe au monde physique repose sur cinq primitives principales. Ces technologies ne sont pas spécifiques à un domaine d’application unique : elles constituent des composants essentiels — des briques capables de construire des systèmes capables d’étendre l’IA au monde physique. Leur maturation simultanée est précisément ce qui rend ce moment historique si particulier.

Légende de l’illustration : Les cinq primitives fondamentales qui soutiennent la Physical AI
Primaire n°1 : Représentations apprises de la dynamique physique
La primitive la plus fondamentale consiste à apprendre une représentation compacte et universelle des comportements du monde physique — comment les objets se déplacent, se déforment, entrent en collision, ou réagissent aux forces appliquées. En l’absence de cette couche, chaque système de Physical AI devrait réapprendre à zéro les lois physiques propres à son domaine — un coût prohibitif pour toute entreprise.
Plusieurs écoles architecturales s’approchent de cet objectif sous des angles différents. Les modèles VLA adoptent une approche descendante : ils prennent des modèles pré-entraînés de vision-langage — déjà dotés d’une compréhension sémantique des objets, des relations spatiales et du langage — et y ajoutent un décodeur d’action pour produire des commandes de contrôle moteur. Le point clé réside dans le fait que le coût considérable d’apprendre à « voir » et à « comprendre le monde » peut être amorti grâce à un pré-entraînement à l’échelle d’internet sur des paires image-texte. Les modèles π₀ de Physical Intelligence, Gemini Robotics de Google DeepMind, et GR00T N1 de NVIDIA valident de manière croissante cette architecture à des échelles toujours plus grandes.
Les modèles WAM adoptent quant à eux une approche ascendante : ils reposent sur des transformateurs de diffusion vidéo pré-entraînés à l’échelle d’internet, héritant ainsi d’aprioris riches sur la dynamique physique (comment les objets tombent, sont masqués, ou interagissent sous l’effet de forces), puis couplent ces aprioris à la génération d’actions. DreamZero de NVIDIA démontre une généralisation à zéro échantillon sur des tâches et environnements entièrement nouveaux, et une capacité de transfert interspécifique à partir de démonstrations vidéo humaines avec seulement quelques données d’adaptation, obtenant ainsi une amélioration significative de la généralisation dans le monde réel.
Une troisième voie, peut-être la plus instructive pour anticiper les directions futures, contourne entièrement le pré-entraînement de modèles VLM et de transformateurs de diffusion vidéo. GEN-1 de Generalist est un modèle fondamental nativement incarné, entraîné dès l’origine sur plus de 500 000 heures de données d’interactions physiques réelles, collectées principalement à l’aide de dispositifs portables peu coûteux auprès de personnes effectuant des tâches opérationnelles quotidiennes. Ce n’est pas un modèle VLA au sens classique (aucun socle vision-langage n’y est affiné), ni un modèle WAM. C’est un modèle fondamental spécifiquement conçu pour l’interaction physique, apprenant dès le départ non pas les régularités statistiques des images, textes ou vidéos d’internet, mais les régularités statistiques des contacts entre le corps humain et les objets.
L’intelligence spatiale développée par des entreprises telles que World Labs apporte une contribution précieuse à cette primitive, car elle comble une lacune commune aux modèles VLA, WAM et aux modèles nativement incarnés : aucun d’eux ne modélise explicitement la structure tridimensionnelle de l’environnement dans lequel ils évoluent. Les modèles VLA héritent de caractéristiques visuelles 2D issues du pré-entraînement sur paires image-texte ; les modèles WAM apprennent la dynamique à partir de vidéos, qui sont elles-mêmes des projections 2D d’un monde 3D ; les modèles apprenant à partir de données de capteurs portables capturent les forces et la cinématique, mais non la géométrie de l’environnement. Les modèles d’intelligence spatiale viennent combler ce vide — ils apprennent à reconstruire et à générer la structure 3D complète de l’environnement physique, et à raisonner sur celle-ci : géométrie, éclairage, occultation, relations entre objets, agencement spatial.
La convergence même de ces différentes voies est cruciale. Que la représentation soit héritée d’un modèle VLM, apprise conjointement à partir de vidéos, ou construite directement à partir de données d’interaction physique, la primitive sous-jacente reste identique : un modèle compact et transférable du comportement du monde physique. Le cercle vertueux de données qu’elles peuvent exploiter est extrêmement vaste — et largement inexploré jusqu’à présent : non seulement les vidéos d’internet et les trajectoires robotiques, mais aussi le gigantesque corpus d’expériences corporelles humaines, désormais collecté à grande échelle par des dispositifs portables. La même représentation peut servir à la fois à un robot apprenant à plier une serviette, à un laboratoire autonome prédisant les résultats d’une réaction chimique, et à un décodeur neuronal interprétant les intentions de préhension provenant du cortex moteur.
Primaire n°2 : Architectures orientées vers l’action incarnée
Disposer d’une représentation physique ne suffit pas. Traduire la « compréhension » en actions physiques fiables nécessite des architectures capables de résoudre plusieurs problèmes interconnectés : mapper une intention de haut niveau vers des instructions de mouvement continues, maintenir la cohérence sur de longues séquences d’actions, fonctionner sous contrainte de latence en temps réel, et s’améliorer continuellement avec l’expérience.
L’architecture hiérarchique à double système est devenue la conception standard pour les tâches incarnées complexes : un modèle lent mais puissant de vision-langage gère la compréhension de la scène et le raisonnement sur la tâche (Système 2), tandis qu’une stratégie rapide et légère de vision-mouvement assure le contrôle en temps réel (Système 1). GR00T N1, Gemini Robotics et Helix de Figure adoptent toutes des variantes de cette approche, résolvant ainsi la tension fondamentale entre la richesse du raisonnement offerte par les grands modèles et la fréquence de contrôle milliseconde exigée par les tâches physiques. Generalist, quant à lui, emprunte une voie différente, utilisant un « raisonnement résonant » permettant pensée et action de se produire simultanément.
Les mécanismes de génération d’actions évoluent rapidement. La tête d’action basée sur le matching de flux et la diffusion, introduite par π₀, est devenue la méthode dominante pour générer des trajectoires continues et fluides, supplantant la tokenisation discrète empruntée au domaine de la modélisation linguistique. Ces méthodes traitent la génération d’actions comme un processus de débruitage similaire à la synthèse d’images, produisant des trajectoires plus physiquement fluides et plus robustes face à l’accumulation d’erreurs, surpassant la prédiction autorgressive de tokens.
Mais la progression la plus décisive au niveau architectural pourrait bien être l’extension de l’apprentissage par renforcement (RL) aux modèles VLA pré-entraînés — un modèle fondamental entraîné sur des données de démonstration peut continuer à s’améliorer par pratique autonome, tout comme un humain affine une compétence par répétition et auto-correction. Le travail π*₀.₆ de Physical Intelligence constitue la démonstration la plus claire et la plus échelonnée de ce principe. Leur méthode, appelée RECAP (Reinforcement Learning with Advantage-Conditioned Policies), résout le problème de l’attribution de crédit sur de longues séquences, impossible à traiter uniquement par apprentissage par imitation. Si un robot saisit la poignée d’une machine à expresso sous un angle légèrement décalé, l’échec ne se manifestera pas immédiatement, mais seulement plusieurs étapes plus tard, lors de l’insertion. L’apprentissage par imitation ne dispose d’aucun mécanisme pour attribuer cet échec à la prise initiale ; le RL, lui, en dispose. RECAP entraîne une fonction de valeur estimant la probabilité de succès à partir de n’importe quel état intermédiaire, puis guide le modèle VLA vers les actions présentant un avantage élevé. L’élément clé réside dans l’intégration, au sein d’un même pipeline d’entraînement, de plusieurs types de données hétérogènes : données de démonstration, expériences autonomes « on-policy », et corrections fournies par des experts à distance durant l’exécution.
Les résultats obtenus par cette méthode sont très encourageants pour l’avenir du RL dans le domaine des actions. π*₀.₆ plie avec fiabilité 50 types de vêtements jamais vus auparavant dans des environnements domestiques réels, assemble des boîtes en carton de manière fiable, et prépare des expressos sur des machines professionnelles, fonctionnant sans intervention humaine pendant plusieurs heures d’affilée. Sur les tâches les plus difficiles, RECAP double plus que le taux de débit par rapport à une ligne de base purement imitative, et réduit de plus de moitié le taux d’échec. Ce système démontre également que le post-entraînement par RL produit des comportements qualitativement nouveaux, impossibles à obtenir par apprentissage par imitation seul : des mouvements de récupération plus fluides, des stratégies de préhension plus efficaces, et des mécanismes de correction adaptative absents des données de démonstration.
Ces gains illustrent un fait essentiel : la dynamique d’échelle en termes de puissance de calcul qui a propulsé les modèles linguistiques de GPT-2 à GPT-4 commence maintenant à s’appliquer au domaine incarné — simplement, nous sommes ici à un stade beaucoup plus précoce de la courbe, où l’espace des actions est continu, de haute dimensionnalité, et soumis aux contraintes impitoyables du monde physique.
Primaire n°3 : Simulation et données synthétiques comme infrastructure d’échelle
Dans le domaine du langage, le problème des données a été résolu par internet : des milliards de tokens de texte sont générés naturellement et gratuitement. Dans le monde physique, ce problème est plusieurs ordres de grandeur plus complexe — un consensus désormais établi, dont le signal le plus direct est la multiplication rapide des startups spécialisées dans la fourniture de données pour le monde physique. La collecte de trajectoires robotiques dans le monde réel est coûteuse, risquée à grande échelle, et limitée en diversité. Un modèle linguistique peut apprendre à partir de milliards de dialogues ; un robot (pour l’instant) ne peut pas accumuler des milliards d’interactions physiques.
La simulation et la génération de données synthétiques constituent la couche d’infrastructure permettant de lever cette contrainte. Leur maturité est l’une des raisons clés pour lesquelles la Physical AI accélère aujourd’hui, et non il y a cinq ans.
La pile moderne de simulation intègre un moteur de simulation physique, un rendu photoréaliste basé sur le suivi de rayons, la génération procédurale d’environnements, et des modèles fondamentaux du monde capables de générer des vidéos photoréalistes à partir d’entrées simulées — ce dernier élément étant chargé de combler le fossé « simulation-réalité ». L’ensemble du pipeline commence par la reconstruction neuronale d’environnements réels (réalisable avec un simple smartphone), remplit ensuite des actifs 3D physiquement précis, puis génère massivement des données synthétiques avec annotation automatique.
L’amélioration de la pile de simulation a une signification profonde : elle transforme les hypothèses économiques sous-tendant la Physical AI. Si le goulot d’étranglement passe de la « collecte de données réelles » à la « conception d’environnements virtuels variés », la courbe des coûts s’effondre. La simulation s’étend avec la puissance de calcul, sans dépendre de la main-d’œuvre ou du matériel physique. Cette transformation de la structure économique de l’entraînement des systèmes de Physical AI est analogue à celle que les données textuelles d’internet ont opérée sur l’entraînement des modèles linguistiques — ce qui signifie qu’un investissement dans l’infrastructure de simulation exerce un effet de levier considérable sur l’ensemble de l’écosystème.
Mais la simulation ne concerne pas uniquement la robotique. La même infrastructure sert la science autonome (jumeaux numériques d’équipements de laboratoire, environnements de simulation pour le criblage préliminaire d’hypothèses), les nouvelles interfaces (environnements neuronaux simulés pour l’entraînement des décodeurs BCI, données sensorielles synthétiques pour l’étalonnage de nouveaux capteurs), ainsi que d’autres domaines d’interaction entre l’IA et le monde physique. La simulation est le moteur de données universel de l’IA du monde physique.
Primaire n°4 : Élargissement des canaux sensoriels
Les signaux d’information transmis par le monde physique sont bien plus riches que la vision et le langage. Le toucher transmet des propriétés matérielles, la stabilité de la préhension, la géométrie du contact — des informations invisibles aux caméras. Les signaux neuronaux codent l’intention motrice, l’état cognitif et l’expérience perceptive avec une bande passante dépassant de loin celle de toute interface homme-machine existante. L’activité musculaire sous-glottique encode l’intention verbale avant même la production sonore. La quatrième primaire est l’extension rapide, par l’IA, de ces voies sensorielles auparavant inaccessibles — non seulement grâce à la recherche, mais aussi grâce à un écosystème entier dédié à la construction de dispositifs, de logiciels et d’infrastructures grand public.
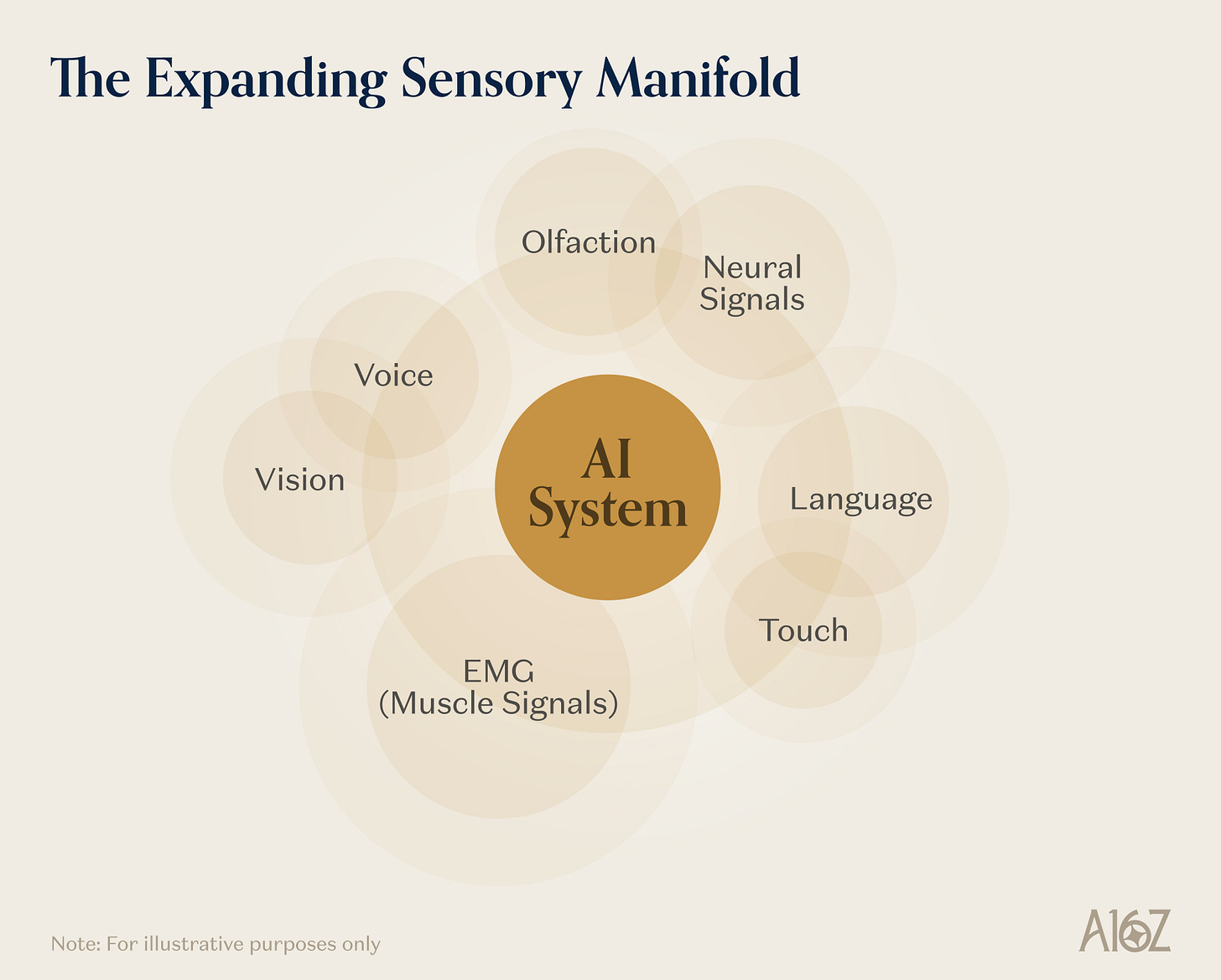
Légende de l’illustration : Élargissement des canaux sensoriels de l’IA, de la réalité augmentée (AR) aux interfaces cerveau-machine (BCI)
L’indicateur le plus direct est l’apparition de catégories de dispositifs entièrement nouvelles. Les appareils de réalité augmentée ont connu ces dernières années des améliorations spectaculaires en termes d’expérience utilisateur et de forme (certaines entreprises développent déjà des applications grand public et industrielles sur cette plateforme) ; les dispositifs portables IA centrés sur la voix donnent aux IA linguistiques un contexte physique plus complet — elles suivent réellement l’utilisateur dans son environnement physique. À long terme, les interfaces neuronales pourraient ouvrir des modes d’interaction encore plus complets. La transformation computationnelle induite par l’IA crée une opportunité sans précédent pour une amélioration radicale de l’interface homme-machine, et des entreprises comme Sesame construisent activement de nouveaux modes et dispositifs à cet effet.
Des modalités plus conventionnelles, comme la voix, profitent également de cette vague. Des produits comme Wispr Flow poussent la voix comme mode d’entrée principal (grâce à sa densité informationnelle élevée et à ses avantages intrinsèques), améliorant ainsi les conditions de marché pour les interfaces de parole silencieuse. Ces dispositifs captent les mouvements de la langue et des cordes vocales à l’aide de multiples capteurs, permettant une reconnaissance silencieuse du langage — représentant ainsi un mode d’interaction homme-machine à densité informationnelle supérieure à la parole elle-même.
Les interfaces cerveau-machine (BCI), invasives ou non, représentent une frontière encore plus profonde, et leur écosystème commercial progresse de manière continue. Les signaux se matérialisent au point de convergence de la validation clinique, de l’approbation réglementaire, de l’intégration aux plateformes, et du financement institutionnel — un domaine qui, il y a quelques années encore, relevait purement de la sphère académique.
La perception tactile entre progressivement dans les architectures d’IA incarnée, et certains modèles d’apprentissage robotique commencent à intégrer explicitement le toucher comme une modalité de premier plan. Les interfaces olfactives deviennent des produits d’ingénierie réels : des afficheurs olfactifs portables utilisant des générateurs de parfums miniatures à réponse milliseconde ont déjà été démontrés dans des applications de réalité mixte ; des modèles olfactifs commencent également à être jumelés avec des systèmes d’IA visuelle pour la surveillance des procédés chimiques.
La loi commune à ces développements est leur convergence progressive aux limites de leurs capacités. Les lunettes AR génèrent continuellement des données visuelles et spatiales sur l’interaction de l’utilisateur avec l’environnement physique ; les bracelets EMG capturent les régularités statistiques de l’intention motrice humaine ; les interfaces de parole silencieuse capturent la correspondance entre l’activité sous-glottique et la sortie linguistique ; les BCI capturent l’activité neuronale à la résolution la plus élevée actuellement disponible ; les capteurs tactiles capturent la dynamique du contact lors des opérations physiques. Chaque nouvelle catégorie de dispositif est simultanément une plateforme de génération de données, nourrissant les modèles sous-jacents de plusieurs domaines applicatifs. Un robot entraîné sur des données d’intention motrice déduites par EMG apprend des stratégies de préhension différentes de celles apprises par un robot entraîné uniquement sur des données de téléopération ; une interface de laboratoire répondant à des commandes sous-glottiques offre aux scientifiques une interaction homme-machine radicalement différente de celle d’un laboratoire contrôlé par clavier ; un décodeur neuronal entraîné sur des données BCI haute densité produit des représentations de la planification motrice inaccessibles par tout autre canal.
La diffusion de ces dispositifs étend la dimension effective de la variété des flux de données disponibles pour l’entraînement des systèmes de Physical AI de pointe — et cette extension est largement pilotée par des entreprises grand public disposant de capitaux abondants, plutôt que par des laboratoires académiques, ce qui signifie que le cercle vertueux des données s’accélère au rythme de l’adoption par les consommateurs.
Primaire n°5 : Systèmes d’agents intelligents en boucle fermée
La dernière primaire est davantage architecturale. Elle désigne l’orchestration de la perception, du raisonnement et de l’action en un système continu, autonome et en boucle fermée, capable de fonctionner sans intervention humaine sur de longues périodes.
Dans le domaine des modèles linguistiques, l’évolution correspondante est l’émergence des systèmes d’agents — chaînes de raisonnement multi-étapes, utilisation d’outils, processus d’autocorrection — qui transforment le modèle d’un simple outil de question-réponse en un résolveur de problèmes autonome. La même transformation est en cours dans le monde physique, mais avec des exigences bien plus strictes. Une erreur d’un agent linguistique peut être annulée sans coût ; une erreur d’un agent physique, comme renverser une bouteille de réactif, est irréversible.
Les systèmes d’agents du monde physique possèdent trois caractéristiques qui les distinguent nettement de leurs homologues numériques. Premièrement, ils doivent s’intégrer directement dans une boucle expérimentale ou opérationnelle : ils doivent se connecter directement aux flux bruts de données des instruments, aux capteurs d’état physique et aux primitives d’exécution, ancrant ainsi le raisonnement dans la réalité physique elle-même, et non dans sa simple description textuelle. Deuxièmement, ils requièrent une persistance sur de longues séquences : mémoire, traçabilité, surveillance de la sécurité, comportements de récupération — reliant plusieurs cycles d’exécution, plutôt que de traiter chaque tâche comme un épisode isolé. Troisièmement, ils nécessitent une adaptation en boucle fermée : réviser leurs stratégies en fonction des résultats physiques obtenus, et non uniquement en fonction de retours textuels.
Cette primaire fusionne des capacités individuelles (bon modèle du monde, architecture d’action fiable, jeu de capteurs riche) en un système complet capable de fonctionner de manière autonome dans le monde physique. Elle constitue la couche d’intégration, et sa maturité est la condition préalable à l’existence de ces trois domaines d’application non plus comme des démonstrations de recherche isolées, mais comme des déploiements réels dans le monde réel.
Trois domaines
Ces primaires constituent des couches d’activation universelles, qui ne déterminent pas à elles seules où les applications les plus importantes émergeront. De nombreux domaines impliquent des actions physiques, des mesures physiques ou des perceptions physiques. Ce qui distingue un « système de pointe » d’une « simple version améliorée d’un système existant » est le degré de rendement composé obtenu par l’amélioration des capacités des modèles et l’infrastructure d’échelle — non seulement une performance accrue, mais l’émergence de capacités totalement nouvelles, auparavant impossibles.
La robotique, la science pilotée par l’IA et les nouvelles interfaces homme-machine sont les trois domaines où cet effet de rendement composé est le plus fort. Chacun assemble les primaires de manière unique, chacun est bloqué par des contraintes que ces primaires sont justement en train de lever, et chacun génère, comme sous-produit de son fonctionnement, un type structuré de données physiques — données qui, en retour, améliorent les primaires elles-mêmes, créant ainsi une boucle de rétroaction qui accélère l’ensemble du système. Ce ne sont pas les seuls domaines de Physical AI dignes d’intérêt, mais ce sont les lieux où l’interaction entre les capacités de pointe de l’IA et la réalité physique est la plus dense, et où la distance par rapport au paradigme actuel du langage/code est la plus grande — ce qui laisse la plus grande marge pour l’émergence de nouvelles capacités, tout en restant hautement complémentaire à ce paradigme et capable d’en tirer parti.
Robotique
La robotique est l’incarnation littérale la plus directe de la Physical AI : un système IA doit percevoir, raisonner et exercer des actions physiques sur le monde matériel, en temps réel. Elle constitue également un test de résistance pour chacune des primaires.
Prenons l’exemple d’un robot généraliste devant plier une serviette. Il doit disposer d’une représentation apprise du comportement des matériaux déformables sous contrainte — un apriori physique que le pré-entraînement linguistique ne peut fournir. Il doit posséder une architecture d’action capable de traduire une instruction de haut niveau en une séquence continue de commandes de contrôle à une fréquence supérieure à 20 Hz. Il a besoin de données d’entraînement générées par simulation, car personne n’a collecté des millions de démonstrations réelles de pliage de serviettes. Il nécessite un retour tactile pour détecter le glissement et ajuster la force de préhension, car la vision seule ne distingue pas une préhension stable d’une préhension sur le point d’échouer. Enfin, il requiert un contrôleur en boucle fermée capable d’identifier une erreur de pliage et de déclencher une récupération, plutôt que d’exécuter aveuglément une trajectoire mémorisée.
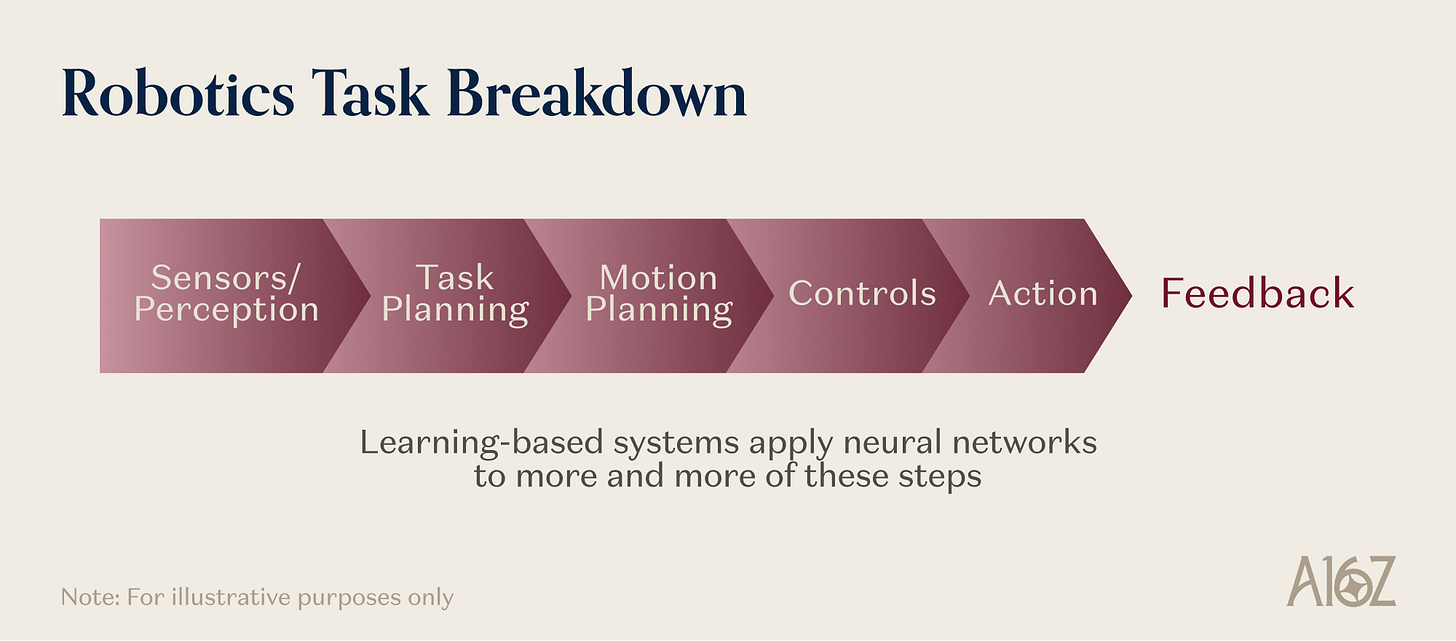
Légende de l’illustration : Appel simultané aux cinq primaires fondamentales dans une tâche robotique
C’est pourquoi la robotique est un système de pointe, et non une discipline d’ingénierie mature dont les capacités seraient simplement améliorées. Ces primaires ne sont pas des améliorations des capacités robotiques existantes ; elles déverrouillent des catégories d’opérations, de mouvements et d’interactions qui étaient auparavant impossibles en dehors d’environnements industriels étroits et rigoureusement contrôlés.
Les progrès récents à la pointe de la recherche sont remarquables — nous en avons déjà parlé précédemment. La première génération de modèles VLA a démontré que les modèles fondamentaux peuvent contrôler des robots pour accomplir des tâches variées. Les avancées architecturales permettent de relier le raisonnement de haut niveau et le contrôle de bas niveau au sein des systèmes robotiques. L’inférence embarquée devient réalisable, et le transfert interspécifique signifie qu’un modèle peut s’adapter à une toute nouvelle plateforme robotique avec un volume de données limité. Le défi central restant est la fiabilité à l’échelle, qui demeure le goulot d’étranglement du déploiement. Une probabilité de réussite de 95 % par étape ne donne que 60 % de chances de réussite sur une chaîne de 10 étapes, alors que les exigences de l’environnement de production sont bien plus élevées. Le post-entraînement par RL possède ici un fort potentiel, capable d’aider ce domaine à franchir le seuil de capacité et de robustesse requis pour entrer pleinement dans sa phase d’échelle.
Ces progrès ont un impact sur la structure du marché. Pendant des décennies, la valeur de l’industrie robotique s’est concentrée sur les systèmes mécaniques eux-mêmes — la mécanique reste une composante clé de la pile technologique — mais à mesure que les stratégies d’apprentissage deviennent plus standardisées, la valeur migrera vers les modèles, les infrastructures d’entraînement et le cercle vertueux des données. La robotique nourrit également en retour les primaires susmentionnées : chaque trajectoire réelle constitue une donnée d’entraînement pour améliorer le modèle du monde, chaque échec de déploiement révèle une lacune dans la couverture de la simulation, et chaque test sur un nouveau corps (« embodiment ») augmente la diversité des expériences physiques disponibles pour le pré-entraînement. La robotique est à la fois le consommateur le plus exigeant des primaires, et l’une de leurs sources de signal d’amélioration les plus importantes.
Science autonome
Si la robotique teste les primaires à travers l’« action physique en temps réel », la science autonome en teste une autre, légèrement différente : le raisonnement continu et multi-étapes sur des systèmes physiques complexes et causaux, sur des échelles temporelles de plusieurs heures ou jours, où les résultats expérimentaux doivent être interprétés, contextualisés, et utilisés pour réviser les stratégies.
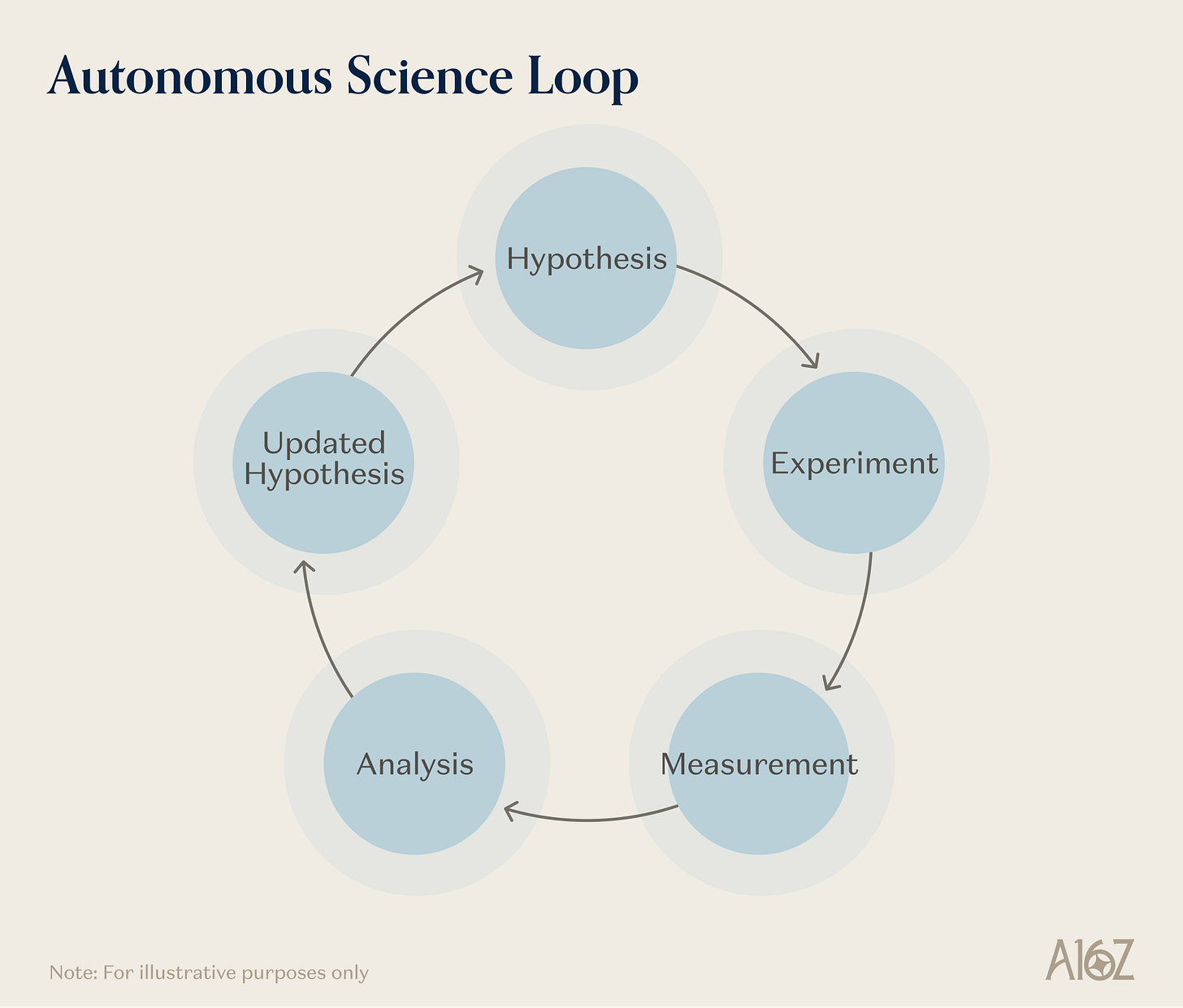
Légende de l’illustration : Mode d’intégration des cinq primaires fondamentales par la science autonome (« scientifique IA »)
La science pilotée par l’IA est le domaine où la combinaison des primaires est la plus complète. Un laboratoire automatisé (« self-driving lab », SDL) a besoin d’une représentation apprise de la dynamique physique et chimique pour prédire les résultats d’une expérience ; d’actions incarnées pour pipeter, positionner des échantillons et manipuler des instruments d’analyse ; de simulations pour le criblage préliminaire des expériences candidates et l’allocation optimale du temps sur des instruments rares ; et de capacités sensorielles étendues — spectroscopie, chromatographie, spectrométrie de masse, ainsi que des capteurs chimiques et biologiques de plus en plus innovants — pour caractériser les résultats. Elle a plus que tout autre domaine besoin de la primaire d’orchestration d’agents intelligents en boucle fermée : pouvoir maintenir sans intervention humaine des cycles répétés « hypothèse-expérience-analyse-correction », tout en conservant la traçabilité, en surveillant la sécurité et en ajustant les stratégies en fonction des informations révélées à chaque itération.
Aucun autre domaine n’appelle ces primaires avec une telle intensité. C’est pourquoi la science autonome est un « système » de pointe, et non une simple automatisation de laboratoire améliorée par des logiciels. Des entreprises comme Periodic Labs et Medra, respectivement dans les domaines des matériaux et des sciences de la vie, intègrent la capacité de raisonnement scientifique et la capacité de validation physique en un tout cohérent, permettant une itération scientifique continue tout en produisant en parallèle des données d’entraînement expérimentales.
La valeur de ces systèmes est intuitive. La découverte traditionnelle de nouveaux matériaux prend plusieurs années, du concept à la commercialisation ; l’accélération par l’IA de ce flux de travail pourrait théoriquement réduire drastiquement ce délai. La contrainte clé évolue désormais de la génération d’hypothèses (facilement assistée par les modèles fondamentaux) vers la fabrication et la validation (exigeant des instruments physiques, l’exécution robotique et l’optimisation en boucle fermée). Le SDL vise précisément ce goulot d’étranglement.
Une autre caractéristique importante de la science autonome — valable pour tous les systèmes du monde physique — est son rôle de moteur de données. Chaque expérience menée par un SDL produit non seulement un résultat scientifique, mais aussi un signal d’entraînement validé physiquement et empiriquement. Une mesure de la façon dont un polymère cristallise sous des conditions spécifiques enrichit la compréhension du modèle du monde concernant la dynamique des matériaux ; un chemin de synthèse vérifié devient une donnée d’entraînement pour le raisonnement physique ; une expérience ratée, correctement caractérisée, indique au système d’agents où ses prédictions échouent. Les données produites par un « scientifique IA » lors d’expériences réelles sont de nature différente des textes d’internet ou des sorties de simulation — elles sont structurées, causales et vérifiées empiriquement. Ce sont précisément les données dont les modèles de raisonnement physique ont le plus besoin, et qu’aucune autre source ne peut fournir. La science autonome constitue la voie directe transformant la réalité physique en connaissances structurées, améliorant ainsi l’ensemble de l’écosystème de la Physical AI.
Nouvelles interfaces
La robotique étend l’IA aux actions physiques, la science autonome l’étend à la recherche physique. Les nouvelles interfaces l’étendent au couplage direct entre l’intelligence artificielle et la perception humaine, l’expérience sensorielle et les signaux corporels — les dispositifs couvrant un spectre allant des lunettes de réalité augmentée (AR) aux bracelets EMG, jusqu’aux interfaces cerveau-machine implantables. Ce qui unit cette catégorie n’est pas une technologie unique, mais une fonction commune : étendre la bande passante et la modalité des canaux de communication entre l’intelligence humaine et les systèmes IA — et, ce faisant, générer directement des données d’interaction homme-monde utilisables pour construire la Physical AI.

Légende de l’illustration : Spectre des nouvelles interfaces, des lunettes AR aux interfaces cerveau-machine
La distance par rapport au paradigme dominant est à la fois le défi et le potentiel de ce domaine. Les modèles linguistiques connaissent conceptuellement ces modalités, mais ne sont pas naturellement familiers avec les motifs moteurs de la parole silencieuse, la géométrie de la liaison des récepteurs olfactifs, ou la dynamique temporelle des signaux EMG. Les représentations nécessaires pour décoder ces signaux doivent être apprises directement à partir des canaux sensoriels en expansion. Beaucoup de ces modalités ne disposent pas de corpus de pré-entraînement à l’échelle d’internet ; les données proviennent souvent exclusivement de l’interface elle-même — ce qui signifie que le système et ses données d’entraînement évoluent conjointement, un phénomène sans équivalent dans l’IA linguistique.
La performance récente de ce domaine est la montée fulgurante des dispositifs portables IA en tant que catégorie grand public. Les lunettes AR constituent peut-être l’exemple le plus visible de cette catégorie, tandis que d’autres dispositifs portables centrés sur la voix ou la vision apparaissent simultanément.
Cet écosystème de dispositifs grand public fournit non seulement une nouvelle plateforme matérielle pour étendre l’IA au monde physique, mais devient également une infrastructure de données du monde physique. Une personne portant des lunettes IA produit continuellement un flux vidéo à la première personne sur la façon dont les humains naviguent, manipulent des objets et interagissent avec leur environnement physique ; d’autres dispositifs portables capturent continuellement des données biométriques et de mouvement. Le parc installé de dispositifs IA portables se transforme en un réseau distribué de collecte de données du monde physique, enregistrant à une échelle sans précédent l’expérience physique humaine. Penser à l’ampleur des smartphones en tant que dispositif grand public — une nouvelle catégorie de dispositif grand public, à une échelle comparable, permet à l’ordinateur de percevoir le monde selon une nouvelle modalité, ouvrant ainsi une voie immense pour l’interaction entre l’IA et le monde physique.
L’interface cerveau-machine représente une frontière encore plus profonde. Neuralink a déjà implanté plusieurs patients, et ses robots chirurgicaux ainsi que ses logiciels de décodage évoluent rapidement. Le Stentrode vasculaire de Synchron est déjà utilisé pour permettre à des personnes paralysées de contrôler leur environnement numérique et physique. Echo Neurotechnologies développe un système BCI destiné à la restauration du langage, fondé sur ses recherches de pointe en décodage cortical de la parole à haute résolution. De nouvelles entreprises comme Nudge sont également créées pour rassembler talents et capitaux autour de nouvelles plateformes d’interfaces neuronales et d’interaction cérébrale. Des jalons technologiques au niveau de la recherche méritent également d’être notés : la puce BISC a démontré, sur une seule puce, un enregistrement neuronal sans fil à 65 536 électrodes ; l’équipe de BrainGate a directement décodé le langage interne à partir du cortex moteur.
La ligne directrice traversant les lunettes AR, les dispositifs portables IA, les interfaces de parole silencieuse et les BCI implantables n’est pas simplement « elles sont toutes des interfaces », mais qu’elles forment collectivement un spectre de bande passante croissante entre l’expérience physique humaine et les systèmes IA — chaque point de ce spectre soutenant les progrès continus des primaires sous-jacentes aux trois domaines présentés dans cet article. Un robot entraîné sur des millions de vidéos de première personne de haute qualité provenant d’utilisateurs de lunettes IA apprend des aprioris opérationnels radicalement différents de ceux appris par un robot entraîné sur un jeu de données de téléopération soigneusement filtré ; une IA de laboratoire répondant à des commandes sous-glottiques est, en termes de latence et de fluidité, dans un monde totalement différent d’un laboratoire contrôlé par clavier ; un décodeur neuronal entraîné sur des données BCI haute densité produit des représentations de la planification motrice inaccessibles par tout autre canal.
Les nouvelles interfaces constituent le mécanisme permettant d’élargir les canaux sensoriels eux-mêmes — elles ouvrent des canaux de données entre le monde physique et l’IA qui n’existaient pas auparavant. Et cette expansion est pilotée par des entreprises grand public cherchant le déploiement à grande échelle, ce qui signifie que le cercle vertueux des données s’accélère au rythme de l’adoption par les consommateurs.
Des systèmes du monde physique
Considérer la robotique, la science autonome et les nouvelles interfaces comme des instances différentes d’un même système de pointe, construit à partir des mêmes primaires, repose sur le fait qu’elles s’activent mutuellement et génèrent un rendement composé.
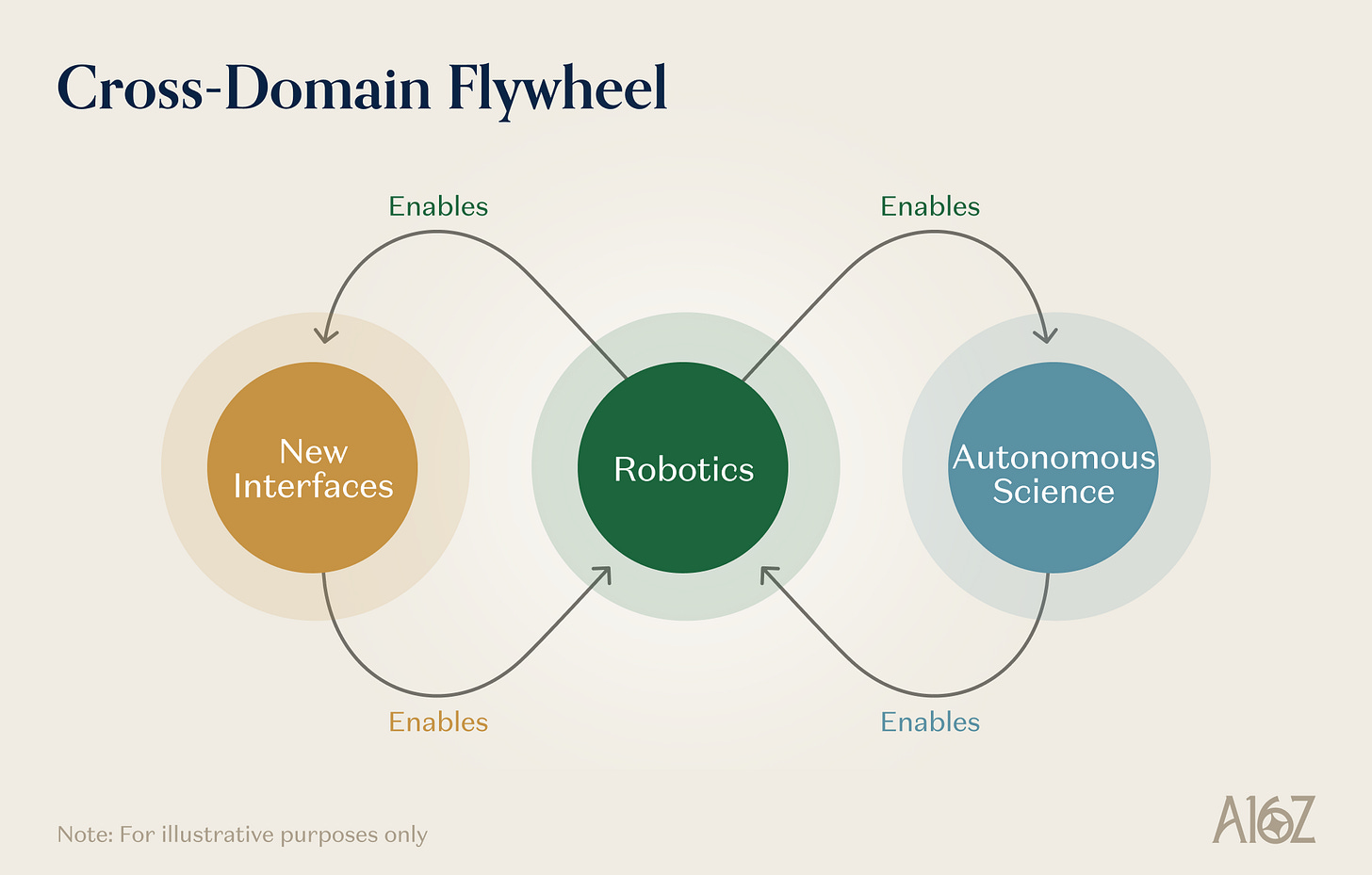
Légende de l’illustration : Le cercle vertueux de rétroaction entre robotique, science autonome et nouvelles interfaces
La robotique permet la science autonome. Un laboratoire automatisé est, en substance, un système robotique. Les capacités opérationnelles développées pour la robotique généraliste — préhension habile, manipulation de liquides, positionnement précis, exécution de tâches multi-étapes — sont directement transférables à l’automatisation des laboratoires. Chaque progrès du modèle robotique en termes de généralité et de robustesse élargit le spectre des protocoles expérimentaux que le SDL peut exécuter de manière autonome. Chaque avancée de l’apprentissage robotique réduit le coût des expériences autonomes et augmente leur débit.
La science autonome permet la robotique. Les données scientifiques produites par le laboratoire automatisé — mesures physiques validées, résultats expérimentaux causaux, bases de données de propriétés des matériaux — fournissent exactement le type de données structurées et concrètes dont ont le plus besoin le modèle du monde et le moteur de raisonnement physique. Plus encore, les matériaux et composants dont auront besoin les prochaines générations de robots (actionneurs améliorés, capteurs tactiles plus sensibles, batteries à plus haute densité, etc.) sont eux-mêmes des produits de la science des matériaux. Les plateformes de découverte autonome accélérant l’innovation des matériaux améliorent directement la couche matérielle sous-jacente sur laquelle les robots apprennent et fonctionnent.
Les nouvelles interfaces permettent la robotique. Les dispositifs AR constituent un moyen évoluable à grande échelle de collecter des données sur « la façon dont les humains perçoivent et interagissent avec l’environnement physique ». Les interfaces neuronales produisent des données sur les intentions motrices humaines, la planification cognitive et le traitement sensoriel. Ces données sont extrêmement précieuses pour l’entraînement des systèmes d’apprentissage robotique, en particulier pour les tâches impliquant la collaboration homme-robot ou la téléopération.
Il existe ici une observation plus profonde sur la nature même des progrès de pointe de l’IA. Le paradigme du langage/code a produit des résultats remarquables et continue de monter en puissance de manière vigoureuse à l’ère de l’échelle. Mais le monde physique offre de nouveaux problèmes, de nouveaux types de données, de nouveaux signaux de rétroaction et de nouveaux critères d’évaluation quasi infinis. Ancrer les systèmes IA dans la réalité physique — à travers des robots manipulant des objets, des laboratoires synthétisant des matériaux, ou des interfaces reliant les mondes biologique et physique — nous ouvre un nouvel axe d’échelle complémentaire à la frontière numérique actuelle — et très probablement capable de s’améliorer mutuellement.
Légende de l’illustration : Interaction et émergence des différents axes d’échelle de la Physical AI
Il est difficile de prédire avec précision quels comportements émergeront de ces systèmes — la définition même de l’émergence est l’interaction de capacités compréhensibles individuellement, mais produisant ensemble des résultats inédits. Toutefois, l’histoire offre un motif optimiste. Chaque fois qu’un système IA acquiert une nouvelle modalité d’interaction avec le monde — voir (vision par ordinateur), parler (reconnaissance vocale), lire et écrire (modèles linguistiques) — le saut de capacité obtenu dépasse largement la somme des améliorations individuelles. La transition vers les systèmes du monde physique représente la prochaine de ces transitions de phase. En ce sens, les primaires discutées dans cet article sont actuellement en cours de construction, et pourraient permettre aux systèmes IA de pointe de percevoir, raisonner et agir sur le monde physique, libérant ainsi une immense valeur et de nombreux progrès dans ce domaine.
Avertissement : Le présent article est fourni uniquement à titre d’information et ne constitue en aucun cas un conseil en matière d’investissement. Il ne doit pas être utilisé comme base pour des conseils juridiques, commerciaux, d’investissement ou fiscaux.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














