

Décortiquer la philosophie d’investissement de Gavin Baker, l’un des premiers investisseurs de NVIDIA : miser à la hausse sur les goulots d’étranglement des infrastructures IA, miser à la baisse sur les risques systémiques du marché
TechFlow SélectionTechFlow Sélection
Décortiquer la philosophie d’investissement de Gavin Baker, l’un des premiers investisseurs de NVIDIA : miser à la hausse sur les goulots d’étranglement des infrastructures IA, miser à la baisse sur les risques systémiques du marché
« L’IA n’est pas dans une bulle ; au contraire, elle se trouve au cœur d’un supercycle. »
Traduction & synthèse : TechFlow

Animés par : Ejaaz Ahamadeen (EJ) et Josh Kale (Josh)
Titre original : What The Best AI Investors Are Buying Right Now
Source du podcast : Limitless Podcast
Date de diffusion : 28 mai 2026
Introduction éditoriale
Cet épisode du podcast explore principalement la philosophie d’investissement de Gavin Baker, fondateur d’Atreides Management, investisseur de longue date dans Nvidia et Cerebras. Son jugement central est que l’IA n’est pas une bulle spéculative, mais un « super-cycle » d’infrastructures propulsé conjointement par l’électricité, les tranches de silicium (wafers) et la puissance de calcul ; les véritables rendements exceptionnels ne se trouvent pas dans les grands modèles linguistiques (LLM) ou les chatbots, mais dans les « fournisseurs d’outils » — c’est-à-dire les interconnexions GPU, la mémoire, les puces d’inférence, les procédés de pointe et l’approvisionnement électrique.
Gavin Baker protège son portefeuille contre une correction générale du marché en achetant des options put sur l’ETF QQQ, tout en concentrant ses investissements sur des actifs physiques critiques pour l’IA tels qu’Astera Labs, Unity, Micron, Nvidia, Cerebras et Positron. Il replace le débat sur la « bulle IA » au niveau des contraintes réelles d’offre et de demande, estimant que tant que TSMC, ASML, la mémoire à très grande bande passante (HBM) et le réseau électrique ne pourront pas rapidement atteindre une surcapacité, les dépenses en capital (capex) liées à l’IA ne seront probablement pas une réédition de la bulle internet de l’an 2000.
Citations clés
Bulle IA ou super-cycle ?
- « L’IA n’est pas dans une bulle ; au contraire, elle est précisément au cœur d’un super-cycle. »
- « Les plus hauts rendements ne proviennent pas des logiciels en mode SaaS, ni des chatbots comme OpenAI ou Anthropic, mais bien de l’électricité, de la puissance de calcul et de la fabrication de puces. »
- « Ce n’est pas la bulle internet, car les acheteurs sont principalement les entreprises les plus intelligentes et les mieux dotées en trésorerie au monde, qui n’achètent pas de puissance de calcul à l’aide d’un effet de levier financier. »
- « Si l’ensemble du marché ne peut être surexpliqué, il sera difficile qu’il s’effondre brutalement comme une bulle classique. »
Les véritables goulots d’étranglement : électricité, tranches de silicium (wafers), tokens
- « La théorie de Gavin est simple : elle se concentre uniquement sur les goulots d’étranglement au niveau de l’infrastructure IA. Celui qui parviendra à maximiser les performances par watt et à réduire le coût par token aura de la valeur. »
- « Les laboratoires d’IA s’intéressent de plus en plus à une seule question : combien de tokens peuvent être générés par watt d’électricité ? »
- « L’électricité et les tranches de silicium constituent deux murs infranchissables, ainsi que deux contraintes fondamentales freinant l’accélération trop rapide de l’IA. »
Transition de la phase d’entraînement préliminaire vers celle de l’inférence et du post-entraînement
- « Une fois l’entraînement préliminaire d’un modèle terminé, cela ne signifie pas qu’il restera génial toute sa vie : il doit encore intégrer de nouvelles informations durant la phase de post-entraînement. »
- « L’inférence exige intrinsèquement d’importantes ressources de calcul — c’est pourquoi les puces dédiées à l’inférence et les infrastructures associées deviendront le prochain grand axe stratégique. »
- « Le coût ou l’opportunité de revenus liée uniquement à l’inférence pourrait être de 5 à 10 fois supérieure aux dépenses en puissance de calcul consacrées à l’entraînement préliminaire. »
Modèles linguistiques spécialisés, modèles embarqués et infrastructures souveraines
- « À l’avenir, vous n’aurez peut-être pas besoin d’interagir quotidiennement avec Claude ; ce dont vous aurez vraiment besoin sera plutôt un agent IA personnalisé, entraîné sur vos propres données. »
- « La rapidité du déploiement physique de l’infrastructure constitue en soi une moat (avantage concurrentiel durable), car la vitesse d’itération dans le monde numérique est largement supérieure à celle de la construction des infrastructures physiques. »
« Celui qui parviendra à réduire à quelques semaines un déploiement physique qui prend habituellement plusieurs mois, voire plusieurs années, pourra facturer très cher ses services dans le domaine des infrastructures IA. »
La stratégie d’investissement de Gavin : miser sur les goulots d’étranglement, tout en couvrant le risque systémique
- « Il croit fermement à l’émergence de gagnants dans le domaine de l’IA, sans pour autant faire preuve d’un optimisme généralisé quant à l’ensemble du marché ; ses options put sur QQQ constituent une couverture contre le risque de baisse globale. »
- « TSMC limite en réalité la vitesse à laquelle la bulle peut s’accélérer ; tant que la capacité de production de puces ne peut pas s’étendre instantanément, les dépenses en capital restent peu susceptibles de déraper. »
- « Gavin ressemble à une version plus âgée, plus stable et dotée d’un historique plus éprouvé de Leopold : le succès du premier se mesure en décennies, tandis que celui du second se mesure actuellement en trimestres. »
Les actifs à privilégier pendant le super-cycle IA
EJ : Gavin Baker est un investisseur IA extrêmement prolifique, mais presque inconnu du grand public. Au cours des 20 dernières années, il a investi dans certaines entreprises IA qui allaient devenir mondialement célèbres, bien avant qu’elles ne commencent à faire parler d’elles. Il a notamment identifié très tôt Nvidia (fournisseur central de GPU et d’accélérateurs de calcul pour l’IA) et Cerebras (société spécialisée dans les puces IA), et défend une vision claire : l’IA n’est pas une bulle, mais précisément un super-cycle.
Selon lui, il suffit d’observer trois éléments fondamentaux — les watts (énergie électrique), les wafers (tranches de silicium) et les tokens (unités de génération et de calcul des modèles) — c’est-à-dire les couches profondes de l’infrastructure IA, pour identifier les goulots d’étranglement et les contraintes critiques. Sa conclusion est simple : les plus hauts rendements dans le domaine de l’IA proviennent de l’énergie, de l’alimentation électrique et de la fabrication de puces, et n’ont guère de lien avec les logiciels en mode SaaS ou avec des chatbots comme Anthropic ou OpenAI. En fin de compte, toute la chaîne industrielle se polarisera vers le secteur des semi-conducteurs — autrement dit, vers les « fournisseurs d’outils » (picks and shovels) qui soutiennent l’ensemble de l’industrie IA.
Lorsque beaucoup affirment que le secteur IA est déjà entré dans une bulle, Gavin considère au contraire qu’il s’agit d’une opportunité d’achat historique, particulièrement pour les infrastructures IA. Il traduit cette conviction dans son fonds via une allocation d’environ 4,1 milliards de dollars.
Si vous entendez Gavin parler de ces contraintes, surtout celles touchant aux infrastructures IA, vous reconnaîtrez immédiatement cette théorie. Nous avons déjà abordé, dans des épisodes précédents, un autre investisseur, Leopold Aschenbrenner, qui adopte une approche similaire. La différence réside dans le fait que Leopold n’a opéré que depuis environ trois ans, tandis que Gavin pratique cette stratégie depuis plus de 20 ans.
L’actif sous gestion (AUM) de Leopold est approximativement trois fois supérieur à celui de Gavin, mais Luke, le producteur de ce podcast, formule une remarque très pertinente : « Vous pouvez peut-être battre Warren Buffett sur un an, mais pouvez-vous le battre sur plusieurs décennies ? » L’historique de Gavin Baker suggère qu’il possède une perspective différente sur cette théorie d’investissement.
Pour ceux qui ne connaissent pas Gavin Baker, retenez simplement qu’il est le fondateur d’Atreides Management (un fonds d’investissement) et qu’il investit dans Nvidia depuis 20 ans. Le fait même de détenir des actions Nvidia depuis aussi longtemps — et de continuer à travailler — est déjà extraordinaire, car cela aurait dû générer des rendements spectaculaires.
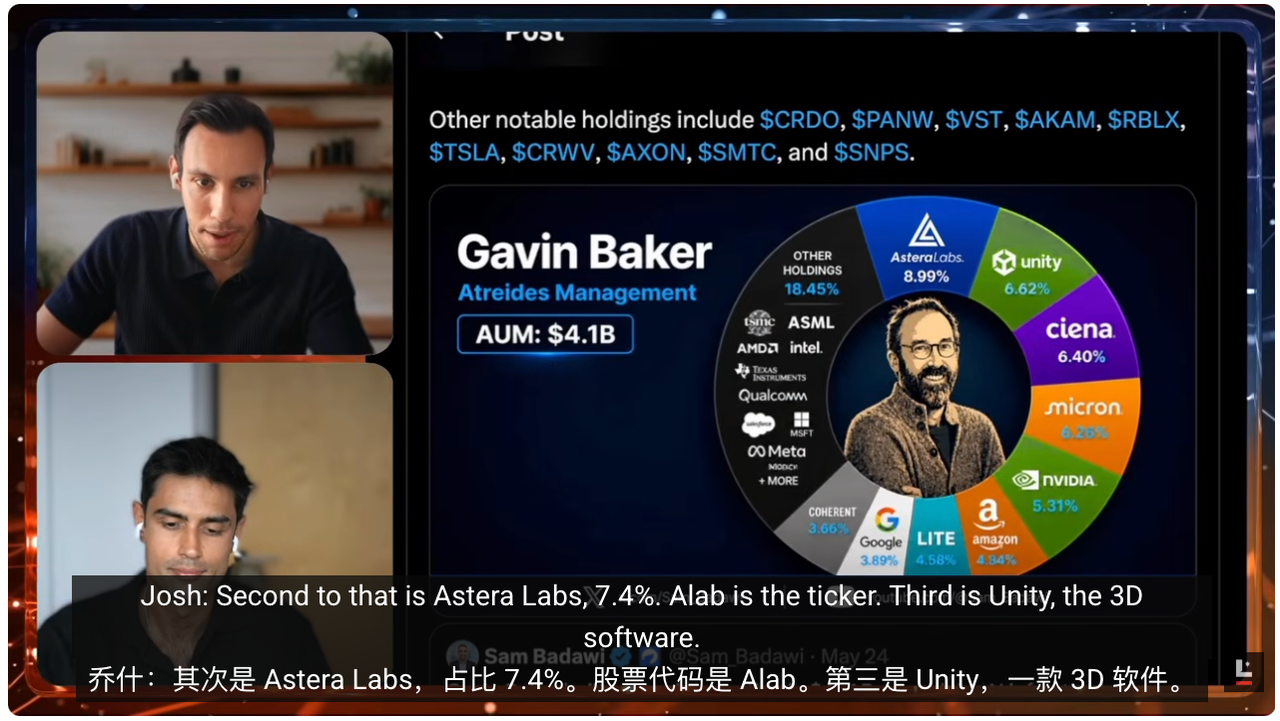
Parmi ses récentes réussites figurent Cerebras, ainsi qu’Astera Labs (une société spécialisée dans les puces de connectivité pour centres de données IA). Cerebras est une entreprise spécialisée dans les puces IA ; l’épisode mentionne qu’après son introduction en Bourse (IPO), sa valorisation était remarquablement élevée. Il existe également d’autres sociétés moins connues, que nous examinerons dans cet épisode en suivant la composition de son portefeuille et ses analyses, afin de comprendre où il situe exactement les opportunités d’investissement IA.
La question devient donc : dans quoi investit-il exactement, et pourquoi ? Si l’on examine les derniers rapports 13F (documents trimestriels américains de divulgation des positions détenues par les investisseurs institutionnels) d’Atreides Management, on constate que ce fonds gère environ 4 milliards de dollars d’actifs. En analysant ses principales positions, on découvre que toutes ces sociétés correspondent aux goulots d’étranglement de l’IA que Gavin mentionne fréquemment.
Il détient des positions importantes dans des entreprises peu médiatisées, voire totalement inconnues du grand public. Par exemple, Astera Labs représente près de 9 à 10 % du fonds. On peut considérer Astera Labs comme la couche de connectivité entre les GPU. Si l’on imagine un centre de données comme un système, les GPU constituent le moteur, chargé de l’entraînement préliminaire (pre-training), du post-entraînement (post-training) et de l’inférence (inference). Toutefois, pour fonctionner, les GPU doivent échanger d’énormes volumes de données entre eux et accéder aux puces de mémoire (memory chips) où ces données sont stockées.
Cela nécessite un véritable « système de canalisations ». Je reste ici à un niveau conceptuel élevé, car je ne prétends pas maîtriser tous les détails techniques sous-jacents. Astera Labs résout précisément ce problème. Lorsque les grappes IA s’étendent à des centaines de milliers de puces, le goulot d’étranglement ne réside plus seulement dans les GPU eux-mêmes, mais dans la fenêtre de transfert des données — c’est-à-dire la capacité à envoyer les bonnes données, au bon moment, et à y accéder correctement. Astera Labs construit justement ce type de système de canalisations.
Je n’avais jamais entendu parler d’Astera Labs avant de préparer cet épisode. Mais je me souvenais de Cerebras, qui présentait une situation similaire. Gavin avait parlé de Cerebras environ six mois auparavant, or, à l’échelle temporelle de l’IA, six mois représentent déjà une période très longue. Peu après, Cerebras a fait son IPO, avec une valorisation d’environ 60 milliards de dollars, puis a encore augmenté de 40 % après son introduction en Bourse. Cela suggère qu’Astera Labs pourrait également suivre une trajectoire similaire.
Josh : Cerebras constitue l’un de ses premiers investissements. Gavin est entré très tôt dans le cycle de vie de Cerebras, ce qui signifie qu’il applique cette théorie depuis de nombreuses années. D’autres sociétés font également partie de ses engagements de longue date, dont la plus emblématique est évidemment Nvidia.
Participer à la croissance de Nvidia depuis plus de 20 ans, tout en conservant une conviction ferme, est un exploit remarquable. J’ai récemment écouté deux podcasts auxquels Gavin a participé, où il exprime clairement sa conviction concernant sa position sur Nvidia : il estime que celle-ci pourra maintenir ses marges bénéficiaires actuelles et conserver une forte demande. Cela signifierait qu’elle pourrait atteindre une valorisation proche de 10 000 milliards de dollars — alors qu’elle n’en est aujourd’hui qu’à la moitié.
Un autre actif notable est Micron (fabricant mondial majeur de puces mémoire). Dans notre épisode précédent, nous avions décrit la pile d’investissement IA et la place occupée par ces entreprises — nous vous recommandons vivement de le réécouter. Micron est l’un des plus grands fabricants mondiaux de puces mémoire. L’épisode cite un chiffre stupéfiant : il y a un an, sa valorisation était inférieure à 100 milliards de dollars, tandis qu’au moment de l’enregistrement, elle avait franchi la barre des 1 000 milliards — soit une multiplication par 10 en un an. Cela illustre à quel point le « problème de la mémoire » est critique.
D’autres sociétés, moins visibles mais tout aussi intéressantes, méritent également d’être mentionnées. EJ, je tiens particulièrement à te signaler Unity Software. Tous les amateurs de jeux vidéo connaissent Unity, un moteur de jeu (game engine) utilisé pour créer de nombreux titres populaires grâce à ce logiciel de rendu 3D.
Mais pourquoi un investisseur spécialisé dans l’IA choisirait-il d’investir dans Unity, une société « spécialisée dans les jeux vidéo » ? La réponse réside dans les moteurs de jeu 3D. Unity est un « constructeur de modèles du monde » (world model builder) : il possède une compréhension approfondie de la physique, du fonctionnement du monde réel, des matériaux et de l’éclairage. Lorsque les entreprises IA cherchent à développer une intelligence générale artificielle (AGI) ou des robots humanoïdes, une étape essentielle consiste à simuler des environnements virtuels et des ensembles de données virtuelles afin d’y entraîner les robots. Unity est précisément l’un des outils les plus performants à cet égard. En tant que « partisan convaincu des modèles du monde » (world model maxi), vous appréciez sûrement cet exemple : une entreprise réputée pour son moteur de jeu possède une voie claire pour devenir un acteur majeur dans l’univers IA.
La théorie et la stratégie d’investissement de Gavin
EJ : La théorie des « modèles du monde » (world models) est simple : les modèles IA actuels, ou les grands modèles linguistiques (LLM), comprennent le monde principalement à travers des textes et des livres, à l’instar d’un étudiant enfermé dans une bibliothèque, mais ils ne disposent d’aucune expérience directe du monde réel. Les modèles du monde ont justement pour objectif de résoudre ce problème : placer un personnage de jeu dans un environnement simulé afin qu’il comprenne comment fonctionne la réalité physique. Par exemple, que se passe-t-il si je laisse tomber mon téléphone ou donne un coup de pied dans un ballon ? Quelles sont les étapes suivantes ? Que dois-je faire ? C’est précisément ce genre de questions que les modèles du monde permettent de résoudre.
Aujourd’hui, très peu d’acteurs sont capables de produire à grande échelle ce type de capacités. Les leaders actuels sont probablement Google, avec des projets tels que Genie 3 (son modèle interactif génératif du monde). L’épisode mentionne également la récente sortie par Google de Gemini Omni, mais ces modèles n’ont pas encore connu leur propre « moment ChatGPT » (c’est-à-dire leur percée massive auprès du grand public).
Ce que j’apprécie particulièrement chez Gavin, c’est que sa stratégie d’allocation ressemble à une « stratégie barbell » (stratégie à double extrême). D’un côté, elle est très traditionnelle : tout le monde a besoin de GPU et de mémoire, donc il investit dans les géants du secteur, Micron et Nvidia. De l’autre, elle est très avant-gardiste : il anticipe où va le « puck » (le palet, métaphore tirée du hockey pour désigner la direction prise par l’innovation), et investit donc dans Cerebras, car il pense que l’inférence sera cruciale, et dans Unity, car il est convaincu que les modèles du monde constitueront la méthode future d’entraînement des robots et des prochaines générations de LLM.
Son portefeuille inclut également Positron, spécialiste des puces d’inférence. Si cela vous semble similaire à Cerebras, vous avez raison : les deux entreprises se concentrent sur l’inférence. Gavin insiste régulièrement, dans ses récents entretiens, sur une tendance clé : la pile d’infrastructure IA, et en particulier celle dédiée à l’entraînement, évolue progressivement vers une plus grande importance accordée au post-entraînement.
Si vous évoluez dans le milieu de l’IA, vous savez que cette transition est déjà en cours. Gavin y est particulièrement attentif. Un modèle doit toujours assimiler de nouvelles informations et de nouvelles données, et se mettre à jour en conséquence. Il ne suffit pas qu’il ait achevé son entraînement préliminaire sur un ensemble de données donné pour qu’il reste « génial » toute sa vie. Il doit continuer à apprendre de nouvelles informations, ce qui se produit précisément au niveau du post-entraînement — une étape qui requiert une puissance de calcul considérable.
Ensuite, si vous souhaitez que votre modèle IA réfléchisse véritablement à un problème — comme nous le faisons lorsque nous recevons une nouvelle information et nous demandons si ce point de vue tient debout, ou s’il existe une autre théorie pouvant l’expliquer — vous entrez dans le domaine du « raisonnement » (reasoning). Or, le raisonnement exige également une puissance de calcul très importante. Selon les estimations actuelles, le coût ou l’opportunité de revenus liée exclusivement à l’inférence pourrait être de 5 à 10 fois supérieure aux dépenses en puissance de calcul consacrées à l’entraînement préliminaire.
C’est pourquoi les laboratoires IA (AI labs) et les fabricants de puces (chip makers) sont en train de subir une transformation majeure. Vous avez déjà vu Nvidia lancer de nombreux GPU dédiés à l’inférence afin de soutenir les applications « agentic » (intelligentes, autonomes). Gavin traduit également cette conviction dans une série d’investissements ciblés sur l’inférence.
Le dernier point que je trouve particulièrement intéressant concerne les propos de Gavin sur la Chine. Dans la course à l’IA, le récit dominant oppose toujours la Chine aux États-Unis. La Chine dispose d’une configuration unique : une offre énergétique relativement abondante, ainsi qu’une capacité accrue à étendre sa fabrication de puces. Les États-Unis rencontrent actuellement des difficultés dans ce domaine, ce qui explique pourquoi de nombreuses étapes sont externalisées vers TSMC (Taiwan Semiconductor Manufacturing Company), le principal fondeur mondial de pointe de tranches de silicium, basé à Taïwan.
Selon Gavin, la Chine dispose d’une opportunité unique de créer une infrastructure IA ou des puces radicalement différentes de celles des États-Unis, car elles seront très fortement orientées vers l’inférence. Autrement dit, Gavin, par ses investissements aux États-Unis, prend une initiative pionnière pour construire l’infrastructure nationale d’inférence américaine. Je pense que cela pourrait représenter une opportunité considérable à l’avenir.
Josh : Il convient de noter que ce pari n’offre pas uniquement un potentiel haussier. Gavin détient également une position importante d’options put sur QQQ (options mises sur l’ETF Nasdaq 100). QQQ est un ETF qui suit l’indice Nasdaq 100, composé d’un panier d’actions, et constitue le deuxième ETF le plus échangé aux États-Unis. Il a connu une performance remarquable : +55 % en 2023, +25 % en 2024, +20 % en 2025, et +17 % déjà en 2026.
Autrement dit, QQQ, en tant qu’indice, affiche une performance excellente ; il est facile à acheter, car il regroupe les 100 meilleures entreprises cotées. Gavin, lui, mise en sens inverse, en effectuant une couverture. Il ne dit pas que l’IA ne remportera pas la victoire, mais qu’il veut investir dans les fabricants clés qui résolvent réellement les goulots d’étranglement, sans pour autant afficher un optimisme excessif quant à l’humeur générale du marché. Ces options put sur QQQ constituent une protection contre le risque de baisse (downside protection) : si le marché s’effondre de manière défavorable, même si l’IA remporte la victoire à long terme, il bénéficiera de cette couverture.
Quatre catégories d’actifs à privilégier
Josh : Nous pouvons décomposer les goulots d’étranglement d’investissement jugés les plus critiques par Gavin en quatre grandes catégories. La première est celle des « petits modèles linguistiques verticalisés » (verticalized small language models). Les LLM classiques, comme Claude ou ChatGPT (des chatbots), sont des « modèles linguistiques généraux » (generalized LLM) : ils possèdent une compréhension large du monde et peuvent répondre à des questions précises. En revanche, entraîner un modèle spécifiquement autour d’un domaine vertical ou d’un problème particulier constitue une démarche différente.
Ces problèmes spécifiques existent souvent au sein des entreprises, notamment celles qui se sont spécialisées dans un domaine précis ou qui ont développé une niche (un créneau spécifique) sur un segment particulier. Les « petits modèles linguistiques verticalisés » (verticalized SLMs) répondent justement à ce besoin : ce sont des modèles « frontière » (frontier models), mais fortement optimisés, capables de fonctionner efficacement sur les données d’une entreprise donnée ou directement sur un appareil (device).
Nous avons déjà évoqué les modèles « embarqués » (on-device) ou « exécutés localement » (locally run models). La raison en est que votre smartphone ou d’autres appareils contiennent d’énormes volumes de données très personnelles, que vous ne souhaitez peut-être pas partager, et que les entreprises ne sont pas nécessairement autorisées à consulter. Pensez aux dossiers médicaux ou aux détails financiers. J’ai récemment vu qu’OpenAI avait lancé un « agent IA financier », capable d’accéder à votre compte bancaire, mais sans pouvoir réellement effectuer d’opérations à votre place, car il contient de nombreuses informations personnelles identifiables (PII), telles que votre numéro de sécurité sociale ou les détails de votre compte bancaire.
Les modèles locaux ou les SLMs permettent de résoudre ce type de problème. Gavin parie fortement sur leur importance croissante à l’avenir. Une entreprise qu’il apprécie particulièrement est Apple. Bien qu’il n’ait pas explicitement exprimé un intérêt d’investissement, il considère qu’Apple sera l’un des principaux fabricants d’appareils (device makers) capables de faire fonctionner des modèles locaux sur les équipements.
Si ce scénario se réalise, nous ne considérerons peut-être plus Claude comme le modèle avec lequel nous interagissons quotidiennement. Ce dont nous aurons réellement besoin sera un « agent IA personnalisé », entraîné sur nos propres données — ce à quoi les SLMs pourraient finalement aboutir. Une version généraliste pourrait s’exécuter directement sur votre smartphone, tandis que de nombreuses entreprises déployeront des modèles hautement optimisés et spécialisés, entraînés sur leurs propres données propriétaires (proprietary data), afin de mieux vendre ou promouvoir leurs produits.
EJ : Apple occupe une position idéale sur ce terrain. J’attends avec impatience la WWDC (Worldwide Developers Conference, conférence mondiale des développeurs d’Apple), qui approche.
Josh : Oui.
EJ : La conférence des développeurs d’Apple n’est plus qu’à quelques semaines. Elle marquera le lancement de nouveaux logiciels IA et de leur intégration avec le matériel. Cela sera extrêmement important, et nous continuerons à en rendre compte. J’ai hâte d’en discuter.
Josh : Le deuxième pilier est celui des « infrastructures souveraines » (sovereign infrastructure). Nous disons souvent que la vitesse des « bits » (données numériques) est bien supérieure à celle des « atomes » (objets physiques). Cela est particulièrement évident dans le domaine des infrastructures IA : la qualité des modèles progresse presque de façon exponentielle, tout comme l’intelligence générée par watt ou l’intelligence associée à chaque token.
Toutefois, la vitesse de déploiement physique ne progresse pas à un rythme comparable — et c’est justement cette différence qui constitue une « moat ». Le matériel est extrêmement complexe, la précision des transistors approchant déjà l’échelle atomique ; déployer à grande échelle sur des infrastructures déjà sollicitées est loin d’être facile. Avec l’accélération de la diffusion des véhicules électriques, le réseau électrique subit déjà une pression accrue, et de nombreuses zones approchent de leur pleine capacité. L’IA vient désormais ajouter un « problème énergétique » et un « problème de puces ».
Gavin parie fortement sur le fait que la construction d’infrastructures est extrêmement difficile, nécessitant souvent des jours, des mois, voire des années. Il mise donc sur ceux qui parviennent à réduire ce délai à quelques semaines. Ainsi, la vitesse du déploiement physique constitue en soi une « moat ». Il affine sa cible pour identifier les entreprises capables de déployer rapidement.
Le premier exemple qui me vient à l’esprit est SpaceX (la société spatiale d’Elon Musk) et sa capacité à construire Colossus (le gigantesque cluster IA d’xAI) et à le louer à Anthropic — une offre qui pourrait s’étendre à d’autres entreprises. Ce pilier des infrastructures est l’un des axes clés de l’attention de Gavin.
Si l’on examine le portefeuille de Leopold, on retrouve également ce même élément central. La réalité est la suivante : construire des choses est extrêmement difficile, et ceux qui y parviennent peuvent les vendre à un prix très élevé. L’épisode mentionne que la principale source de revenus de SpaceX est désormais la location de centres de données, et non plus les lancements de fusées. Cela illustre parfaitement l’importance de ce pilier.
EJ : Ce qui intéresse Gavin, c’est non seulement la vitesse, mais aussi le coût. Il mentionne à plusieurs reprises un indicateur clé : les performances par watt (performance per watt). Ce qu’il veut dire en réalité, c’est que les laboratoires IA s’intéressent de plus en plus au nombre de tokens générés par watt.
Si l’on songe au fait que, cette année seulement, environ cinq entreprises vont dépenser des dizaines de milliards, voire des milliers de milliards de dollars, en GPU, en puissance de calcul et en électricité pour alimenter ces systèmes, on comprend à quel point le rapport coût-efficacité (bang for buck) doit être élevé. Cela est particulièrement vrai lorsque les hyperscalers (les grands fournisseurs de services cloud) étendent leurs infrastructures à une telle échelle — le coût devient alors un enjeu central.
Prenons un exemple hypothétique : je pose une question à Claude, et la réponse me coûte 2 cents ; je pose la même question à ChatGPT, et la réponse me coûte 1 dollar. Même si Claude n’est que 95 % aussi intelligent que ChatGPT, je choisirai très probablement Claude, car je pourrai poser davantage de questions et obtenir, au final, une réponse à moindre coût.
Ainsi, le coût d’accès à cette « intelligence » est extrêmement important. Cette semaine même, Microsoft et Uber ont annoncé qu’ils réduisaient effectivement leur utilisation de Claude Code (l’outil IA d’Anthropic dédié à la programmation), car leur budget annuel a été épuisé en seulement quatre mois.
Vous pouvez observer ce phénomène dans le portefeuille de Gavin : Cerebras, Positron, Astera Labs. Il identifie des goulots d’étranglement extrêmement spécifiques au niveau de l’infrastructure, puis effectue un pari simple : si cette entreprise parvient à résoudre ce goulot d’étranglement, à atteindre un certain niveau de performances par watt et à réduire le coût par token à un seuil donné, alors les laboratoires IA achèteront davantage de GPU, davantage de produits ou davantage de ce type d’équipements.
En somme, sa théorie est très simple, même si les technologies sous-jacentes sont complexes : « Je me concentre uniquement sur les goulots d’étranglement au niveau de l’infrastructure IA. Si je trouve une entreprise capable d’améliorer les performances par watt et de réduire le coût des tokens, je parie qu’elle deviendra très valorisée, soit via une introduction en Bourse, soit via un rachat à un prix élevé. »
Josh : Dans cette catégorie, si quelqu’un souhaite reproduire les transactions de Gavin, il doit connaître quelques noms clés : Astera Labs, Cerebras, SiFive (société de conception de puces RISC-V) et Positron. Ces quatre entreprises jouent un rôle central dans ce secteur.
Le quatrième et dernier axe est la convergence entre « énergie » (energy) et « espace » (space). Comme nous l’avons mentionné précédemment, le réseau électrique terrestre (terrestrial grid) limite dans une large mesure l’offre énergétique, et la création de nouvelles sources d’énergie est également extrêmement difficile. L’épisode cite une statistique selon laquelle environ 40 % des nouveaux centres de données rencontrent une opposition très forte : des citoyens organisent des campagnes de lobbying et des manifestations pour empêcher leur implantation.
Deux solutions s’offrent à nous. La première consiste à créer une « énergie hors-boîte » (out-of-the-box energy), c’est-à-dire une énergie portable. Vous pouvez transporter votre centre de données et l’alimenter avec un dispositif énergétique compact. Blue Marble, une entreprise très appréciée de Leopold, appartient à cette catégorie.
La seconde solution est le « calcul orbital » (orbital compute), un domaine sur lequel Gavin se concentre actuellement. L’entreprise la plus grande et la plus centrale dans ce domaine est bien sûr SpaceX. Elle est la seule capable de devenir l’autoroute vers l’espace, d’envoyer des charges utiles (payload) en orbite, d’installer des racks (baies) et des centres de données en orbite basse, et de générer suffisamment d’intelligence et d’énergie pour les renvoyer sur Terre.
Je pense que l’importance de SpaceX dépasse largement celle de SpaceX elle-même. Je suis quelque peu surpris que le portefeuille de Gavin ne comporte pas davantage d’actions spatiales (space stocks), étant donné qu’il considère ce secteur comme colossal. La réalité est probablement qu’il est encore trop tôt, et que SpaceX constitue le « maillon essentiel » (linchpin) permettant de débloquer ce domaine.
Il faut maintenant suivre de très près le lancement de Starship V3. Nous venons juste de voir un lancement de Starship, qui s’est très bien déroulé. Si Starship ne parvient pas à fonctionner pleinement, il n’y aura ni énergie spatiale, ni racks en orbite. C’est une condition nécessaire, car les charges utiles à lancer sont extrêmement volumineuses. SpaceX est donc une entreprise incontournable, même si de nombreuses autres sociétés en seront indirectement affectées.
Pourquoi ce n’est pas une nouvelle bulle internet ?
Josh : La question suivante, inévitable, est : pourquoi cela ne serait-il pas simplement une nouvelle « bulle internet » (dot-com bubble) ? Gavin a été interrogé de nombreuses fois sur ce sujet, et il fournit une réponse très convaincante — une réponse à laquelle je crois globalement, car son raisonnement est très solide.
Son argumentation est la suivante : la bulle internet de l’an 2000 était alimentée par l’endettement (debt-fueled). De nombreuses personnes avaient emprunté d’importantes sommes pour financer des théories non vérifiées et des produits que personne n’utilisait réellement ou ne souhaitait réellement.
Si l’on compare cela au « super-cycle IA » décrit par Gavin, on constate que, rien qu’OpenAI et Anthropic devraient atteindre, cette année, un chiffre d’affaires récurrent annuel (ARR) de 200 milliards de dollars. Ce n’est pas de l’argent imaginaire, mais bien des revenus déjà contractualisés, dont une grande partie — l’épisode indique 40 à 60 % — a déjà été payée d’avance par des clients entreprises et grand public. Autrement dit, de l’argent réel circule déjà.
Examinons ensuite la puissance de calcul GPU, non pas du point de vue des laboratoires IA, mais de celui des acheteurs de produits Nvidia. Google, Microsoft, Amazon et Meta paient tous de leurs propres réserves de trésorerie, sans recourir à l’emprunt. Amazon vient tout juste d’atteindre le bout de sa trésorerie libre ; si ces entreprises commencent à emprunter, là, oui, nous devrons nous inquiéter. Pour l’instant, le point crucial est qu’elles n’utilisent pas de levier financier.
Et ce sont cinq des entreprises les plus prestigieuses au monde, et, d’une certaine manière, aussi parmi les plus intelligentes, compte tenu de leur valorisation, de leur taille et de leur position. En comparaison avec la bulle internet, de nombreuses entreprises anonymes avaient alors levé d’importantes sommes, qu’elles dépensaient de façon totalement irrationnelle. Dans ce cycle, ce sont les entreprises les plus intelligentes au monde qui dépensent de l’argent sans effet de levier.
Les rapports trimestriels que nous avons examinés récemment dans ce podcast montrent également que les bénéfices s’optimisent autour de ces dépenses, que les modèles progressent encore et deviennent plus intelligents. Le raisonnement central de Gavin est donc le suivant : ce n’est pas une bulle internet, car elle n’est pas alimentée par des capitaux à effet de levier ; en outre, les goulots d’étranglement que nous avons évoqués sont limités par des « atomes physiques » (physical atoms).
Acheter des puces mémoire et des GPU est une chose, mais Nvidia ne peut pas vendre plus de GPU qu’elle n’en produit, et Micron ne peut pas vendre plus de puces mémoire IA qu’elle n’en fabrique, car elle ne dispose pas d’installations de production suffisantes. Son raisonnement simple est donc le suivant : « Si vous ne pouvez pas surexpliquer l’ensemble du marché, alors ce n’est pas une bulle. Nous sommes limités par un manque de “pelles et de pioches” (picks and shovels) pour accomplir cette tâche, et c’est précisément cela que j’investis. »
Un autre point intéressant : Gavin estime que, si TSMC pouvait répondre à la demande, Nvidia aurait pu vendre, cette année et l’année prochaine, des GPU pour un montant de 2 à 3 000 milliards de dollars. Autrement dit, TSMC constitue un maillon essentiel dans la délimitation de la bulle.
En effet, si TSMC pouvait satisfaire la demande de ces entreprises et leur fournir un tel volume de puces, cela engendrerait des dépenses colossales. Or, les graphiques actuels ne montrent pas encore de déconnexion importante entre les dépenses en capital (CapEx) et la trésorerie d’exploitation (operating cash) ; les entreprises génèrent encore suffisamment de trésorerie pour financer leurs investissements.
Mais si TSMC annonçait demain à Nvidia qu’elle pouvait tripler sa capacité de production du jour au lendemain, Nvidia n’hésiterait pas à accepter, et commencerait à dépenser des milliards pour acheter ces puces. Les autres entreprises seraient alors contraintes d’emprunter pour acquérir ces puces, et la « bulle des dépenses en capital » (CapEx bubble) commencerait à gonfler, se déconnectant progressivement de la trésorerie d’exploitation.
Mais comme chaque maillon de la chaîne connaît des contraintes d’approvisionnement — contraintes sur la mémoire, sur la fabrication des puces, sur l’énergie, et surtout sur la fabrication de puces de pointe par TSMC — nous ne pouvons pas accélérer le rythme de construction aussi rapidement. TSMC bloque donc l’accélération de la bulle.
Tant que la capacité de production de puces de TSMC reste limitée, et tant que Samsung et d’autres fabricants de puces ne dépassent pas sa part de marché, la croissance restera relativement durable. Elle peut paraître rapide, mais une demande considérable reste insatisfaite, car nous ne construisons pas assez vite. Tant que ce déséquilibre persiste, je pense que le risque reste limité.
EJ : Un autre point à souligner est que vous ne pouvez pas supposer que la demande restera statique, car ce n’est pas le cas. La demande liée à l’IA augmente de façon exponentielle, et son rythme de croissance dépasse largement celui de l’offre de puces.
Je ne vois que deux façons de réfuter cette théorie. Premièrement, si quelqu’un parvenait, par miracle, à reproduire ASML (le principal fournisseur mondial de machines de lithographie à rayons ultraviolets extrêmes), et si soudainement une multitude de concurrents d’ASML apparaissaient. Pour ceux qui ne connaissent pas ASML, voici une explication simple : elle fabrique des machines valant environ 400 millions de dollars, indispensables à TSMC et à tous les principaux fondeurs de puces (chip fabs). L’épisode indique qu’ASML ne dispose que d’une seule équipe, située en Norvège, pour fabriquer ces machines, et que les délais sont extrêmement longs, avec un carnet de commandes (backlog) déjà rempli pour environ cinq ans.
Deuxièmement, si nous parvenions à concevoir un type entièrement nouveau de LLM, ne nécessitant ni autant de GPU ni autant de mémoire. Or, à ce jour, nous ne voyons aucun signe de ce changement.
Aujourd’hui, j’ai lu une actualité concernant SK Hynix (un des principaux fournisseurs mondiaux de mémoire à très grande bande passante — HBM), le principal fabricant et fournisseur de mémoire pour les GPU Nvidia, et pratiquement le leader absolu du marché de la mémoire IA. Il semble que Google et Microsoft lui fassent actuellement des offres comprises entre 50 et 100 milliards de dollars, afin de sécuriser à l’avance l’approvisionnement de la production des trois prochaines années, destiné à financer l’achat des équipements nécessaires à l’expansion de ses capacités de production.
Cela illustre à quel point ces grandes entreprises sont assoiffées de mémoire — et ce n’est qu’un sous-secteur parmi les composants IA. SK Hynix, quant à elle, répond : « Je ne vous garantis pas l’approvisionnement, je préfère simplement augmenter mes prix. » Son taux de marge opérationnelle (operating margin) est d’environ 70 %, un niveau quasi inouï dans le secteur des semi-conducteurs.
Ainsi, le pari total (all-in) de Gavin est parfaitement justifié. Cela ne ressemble pas à une bulle, même si le marché pourrait réagir ainsi à court terme. Avant l’enregistrement de cet épisode, j’ai consulté notre portefeuille boursier : presque tous les titres étaient en baisse, mais il s’agit surtout d’une réaction émotionnelle (reactionary). L’objectif stratégique est clair : nous aurons besoin de plus de GPU, de plus de puces semi-conductrices, tandis que l’offre reste insuffisante et que les fabricants sont en nombre limité.
Le portefeuille d’investissement de Gavin
Josh : En conclusion : l’électricité et les tranches de silicium (wafers). Voilà les deux seuls éléments. Ce sont deux murs infranchissables, deux facteurs limitants qui nous empêchent d’accélérer trop rapidement. Tant que l’électricité et les tranches de silicium conservent de la valeur, que la demande reste forte et que l’offre demeure limitée, les beaux jours sont encore devant nous.
Si vous souhaitez une version TLDR (« trop long, pas lu ») du portefeuille de Gavin, je peux vous lire ses principales positions. Encore une fois, cela ne constitue pas un conseil en investissement. Il s’agit simplement de ce que détient Gavin, pas de ce que nous détenons. Je ne sais pas si ces actions vont monter, descendre ou stagner.
Sa position la plus importante est, de façon contre-intuitive, une position d’options put sur QQQ (Nasdaq 100 ETF). Globalement, il adopte une posture baissière (bearish) sur le marché, ce qui est très remarquable. Sa deuxième position est Astera Labs, à hauteur d’environ 7,4 %, cotée sous le ticker ALAB. La troisième est Unity, la société de logiciels 3D.
Viennent ensuite de nombreuses autres entreprises : Ciena (fabricant d’équipements optiques pour réseaux), Micron, Nvidia, Amazon, Lumentum (spécialiste des composants photoniques et lasers), Alphabet (la société-mère de Google), Coherent (spécialiste des composants photoniques et des matériaux), Roblox (plateforme de jeux), EchoStar (opérateur de télécommunications par satellite), Twilio (plateforme de communications cloud) et Wayfair (plateforme e-commerce de meubles). Cet homme investit dans tout.
Si cela vous intéresse, vous pouvez consulter ses rapports 13F, dont nous mettrons le lien dans la description. Mais voilà la vision de Gavin : les goulots d’étranglement sont l’électricité et les tranches de silicium. Tant que ces contraintes persistent, la tendance est globalement haussière. EJ, comment absorbes-tu ces informations ? Comment les traites-tu ?
EJ : Depuis la publication du rapport 13F de Leopold, les marchés sont très instables. En enregistrant cet épisode, je me rends de plus en plus compte que Gavin ressemble à une version plus âgée, plus intelligente et plus expérimentée de Leopold. Il est présent dans ce secteur depuis très longtemps. Certes, il ne gère pas 13 milliards de dollars d’actifs, mais j’ai le sentiment qu’il sera toujours là dans dix ans.
Si vous écoutez cet épisode et que vous pensez : « Je ne veux pas suivre chaque minute, chaque heure, chaque jour les avancées de l’IA ; je veux simplement placer mon argent et le laisser croître au cours des prochains mois ou des prochaines années », alors le portefeuille de Gavin peut constituer une référence très utile. Bien entendu, ce n’est pas un conseil en investissement.
Il adopte une approche plus prudente, plus long terme et plus orientée vers l’avenir. Si sa vision des tendances se confirme — comme ce fut le cas lorsqu’il a identifié très tôt Nvidia et Cerebras — des rendements exponentiels pourraient se matérialiser dans les années à venir. Tout cela repose cependant sur une conviction fondamentale : « Nous ne sommes pas dans une bulle. »
Je suis curieux de savoir si les auditeurs partagent cet avis. Manifestement, la plupart des gens ne sont pas aussi techniciens que Gavin, ni aussi immergés dans les couches profondes de la technologie. Mais après avoir écouté cet épisode, que pensez-vous ? Sommes-nous dans une bulle, ou non ? Quels sont les arguments en faveur et à l’encontre ? Y a-t-il des éléments que nous aurions omis ? Josh, avant de conclure, penses-tu que nous sommes actuellement dans une bulle ?
Josh : Je pense que nous sommes assurément dans une bulle. La question est plutôt de savoir à quelle phase de la bulle nous nous trouvons — et cela reste ouvert à discussion. Pour l’instant, cela ressemble davantage à une phase initiale, donc espérons qu’elle perdure. Selon Gavin, tant que TSMC continuera à limiter la capacité de production de puces, tout ira bien.
C’est là l’orientation générale. Nous avons déjà parlé de Leopold, dont le succès est mesuré en trimestres ; aujourd’hui, nous parlons de Gavin, dont le succès se mesure en décennies. Beaucoup d’entre vous trouveront probablement leur réponse quelque part entre ces deux extrêmes.
Si vous avez apprécié cet épisode, n’oubliez pas de le partager avec vos amis. Et dites-nous quel type d’actif vous inspire le plus confiance. Ce n’est peut-être pas une théorie particulière, mais un code boursier précis qui mérite notre attention. Je trouve cela passionnant, car tout évolue à une vitesse folle, que ce soit à la hausse ou à la baisse, avec beaucoup de volatilité et une participation très active. À demain, bonne journée.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













