

Le « Vibe Coding », en train de tuer l’open source
TechFlow SélectionTechFlow Sélection
Le « Vibe Coding », en train de tuer l’open source
L’essor du « Vibe Coding » pourrait être bâti sur les ruines de l’écosystème open source.
Texte : Yi Tao
Au cours de la dernière année, le « Vibe Coding » a presque entièrement redéfini la manière de programmer.
Vous n’avez plus besoin d’écrire ligne par ligne du code vous-même. Il vous suffit de dire à Cursor, Claude ou Copilot ce que vous souhaitez réaliser, avec quelle pile technologique, et éventuellement « en imitant l’expérience utilisateur d’un produit donné » — le reste est pris en charge par l’IA.
De nombreuses personnes incapables de coder auparavant ont ainsi acquis, pour la première fois, la capacité concrète de « créer quelque chose ». Du point de vue individuel, nous vivons presque une ère dorée du développement logiciel.
Mais un préalable souvent négligé mérite d’être souligné : l’IA ne crée pas le code ex nihilo ; elle fait appel à, et réassemble, les résultats intellectuels déjà produits par les humains. Lorsque vous demandez à l’IA « de créer un site web », celle-ci puise en réalité, en silence, dans la logique et les structures accumulées au fil des ans par d’innombrables projets open source hébergés sur GitHub.
La capacité fondamentale du Vibe Coding repose précisément sur l’apprentissage et la réorganisation de ces bases de code open source.
Récemment, une équipe de recherche composée de chercheurs de l’Université d’Europe centrale et de l’Institut Kiel pour la recherche économique a publié un article intitulé Vibe Coding Kills Open Source (« Le Vibe Coding tue l’open source »), disponible sur arXiv, qui met en lumière la crise silencieuse sous-jacente à cette prospérité du Vibe Coding.
L’article révèle une vérité essentielle :
Le Vibe Coding risque de détruire, à la racine, l’écosystème open source qui soutient l’ensemble du monde logiciel.
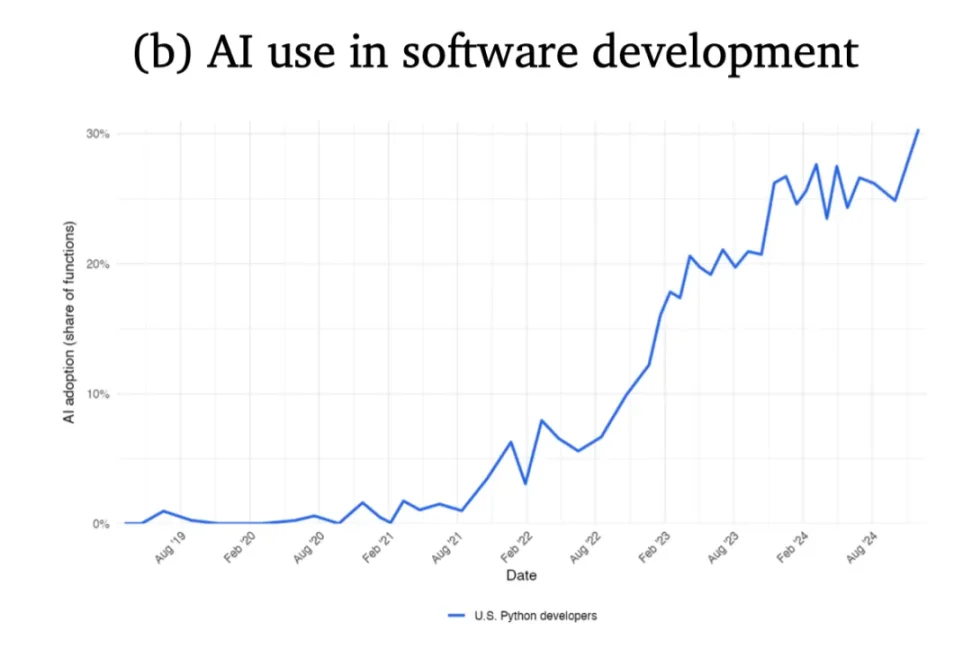
Depuis août 2022, la proportion de développeurs Python aux États-Unis utilisant l’IA pour programmer a fortement augmenté.
Les « infrastructures invisibles » du monde numérique
Pour comprendre les inquiétudes soulevées par cet article, commençons par clarifier deux points fondamentaux : qu’est-ce que le logiciel open source, et quelle place occupe-t-il dans notre quotidien ?
Beaucoup de gens n’ont pas forcément conscience de ce qu’est le logiciel open source, alors qu’en réalité, presque tous les produits numériques que nous utilisons quotidiennement reposent, à leur niveau le plus profond, sur des logiciels open source.
Lorsque vous vous levez le matin et saisissez votre smartphone Android, le système d’exploitation Linux qui le fait fonctionner en arrière-plan est un logiciel open source ;
Lorsque vous ouvrez WeChat pour consulter vos messages, la base de données SQLite qui stocke chacun de vos échanges est également un logiciel open source ;
Et lorsque vous regardez des vidéos sur Douyin ou Bilibili pendant votre pause déjeuner, le décodage et la lecture vidéo s’appuient, en arrière-plan, sur FFmpeg — lui aussi un logiciel open source.
Le logiciel open source est l’équivalent numérique des égouts. Vous l’utilisez chaque jour sans même y penser.
Ce n’est que lorsqu’il tombe en panne que vous prenez soudain conscience de son importance.
L’incident Log4j survenu en 2021 en constitue un exemple emblématique. Log4j est le framework de journalisation le plus répandu dans l’écosystème Java, utilisé pour enregistrer les événements et informations générés durant l’exécution d’une application.
La plupart des utilisateurs ordinaires n’ont jamais entendu parler de ce nom. Pourtant, des serveurs cloud d’Apple et de Google aux systèmes informatiques gouvernementaux de nombreux pays, des milliards d’appareils dans le monde exécutent ce composant en arrière-plan.
Fin 2021, la vulnérabilité « Log4Shell » a été découverte. Elle permettait aux pirates informatiques de prendre le contrôle à distance des serveurs du monde entier, comme s’ils manipulaient leur propre ordinateur. L’ensemble de l’infrastructure internet s’est retrouvé instantanément exposé, obligeant les équipes mondiales de cybersécurité à intervenir d’urgence le week-end. Son ampleur et la difficulté de sa correction en ont fait l’une des crises de sécurité les plus graves de l’histoire d’internet.
Tel est l’essence même de l’open source : ce n’est pas un produit commercial appartenant à une entreprise, mais un « bien public ». En raison de son absence de dimension marchande, les développeurs qui écrivent et maintiennent ces projets ne peuvent généralement pas tirer directement des revenus de leur travail.
Leur rémunération est indirecte : ils acquièrent une notoriété grâce à leurs projets, ce qui leur ouvre les portes d’emplois dans de grands groupes ; ils vendent des services de conseil ; ou encore ils comptent sur les dons de la communauté.
Ce modèle fonctionne depuis des décennies, fondé sur une « interaction directe » : lorsque les utilisateurs emploient un logiciel, ils lisent la documentation, signalent des bogues, ou manifestent leur soutien via des « stars » sur GitHub. Ces signaux d’attention reviennent aux mainteneurs, alimentant leur motivation à poursuivre l’entretien du projet.
Or c’est précisément ce lien que le Vibe Coding est en train de couper.
Comment l’IA « affame » progressivement l’open source ?
Avant l’avènement du Vibe Coding, le mode de développement suivait ce schéma : vous téléchargez un paquet open source, vous lisez sa documentation ; si vous rencontrez un bogue, vous ouvrez un ticket sur GitHub ; si vous trouvez le projet utile, vous cliquez sur l’étoile pour marquer votre soutien.
Grâce à ces interactions, les mainteneurs gagnent en visibilité, ce qui se traduit ensuite par des revenus — créant ainsi un cercle vertueux.
Avec le Vibe Coding, il vous suffit désormais de dire à l’IA ce que vous voulez réaliser : celle-ci sélectionne et assemble automatiquement, en arrière-plan, des extraits de code open source afin de produire une implémentation fonctionnelle.
Le code fonctionne, mais vous ignorez totalement quels sont les bibliothèques exactement utilisées, et vous ne consultez ni leur documentation ni leurs communautés.
L’article qualifie ce phénomène d’« effet de médiation » : l’attention et les retours d’information qui allaient autrefois directement des utilisateurs aux mainteneurs sont désormais captés dans leur intégralité par l’intermédiaire de l’IA.
Que se passe-t-il si ce mécanisme perdure ?
Les auteurs de l’article ont construit un modèle économique simulant l’écosystème open source. Dans ce modèle, les développeurs sont assimilés à des entrepreneurs décidant, selon différents niveaux de qualité, s’ils vont ou non « entrer sur le marché » : ils investissent d’abord dans le développement, puis décident, en fonction des retours du marché, s’ils publieront ou non leur travail en open source. Les utilisateurs, quant à eux, doivent choisir parmi des milliers de paquets logiciels, et décident soit de les utiliser « directement », soit de passer par « l’intermédiaire IA ».
Les simulations révèlent deux forces opposées.
La première est une amélioration de l’efficacité : l’IA rend les logiciels plus faciles à utiliser et abaisse les coûts de développement de nouveaux outils. Cela devrait normalement inciter davantage de développeurs à participer, augmentant ainsi l’offre.
La seconde est un transfert de la demande : dès lors que les utilisateurs passent par l’intermédiaire IA, les mainteneurs perdent les revenus issus des interactions directes, ce qui réduit leur rémunération globale.
Cependant, sur le long terme, si cette deuxième force (le transfert de la demande) l’emporte sur la première (l’amélioration de l’efficacité), tout le système glisse vers une contraction.
Concrètement, cela se traduit par une hausse du seuil d’entrée pour les développeurs : seuls les projets de très haute qualité restent jugés dignes d’être partagés, tandis que les projets de qualité moyenne disparaissent. À terme, le nombre total de paquets logiciels disponibles diminue, tout comme leur qualité moyenne. Bien que chaque utilisateur bénéficie à court terme de la commodité offerte par l’IA, son bien-être global diminue à long terme, car le choix d’outils performants se réduit.
Autrement dit, l’écosystème entre dans un cercle vicieux. Et dès lors que l’écosystème open source — fondement même de ce système — s’appauvrit, les capacités de l’IA s’en trouvent elles-mêmes affaiblies.
C’est là un point central répété dans l’article : le Vibe Coding augmente la productivité à court terme, mais pourrait, à long terme, faire baisser le niveau général du système.
Cette tendance n’est pas une hypothèse purement théorique : elle se matérialise déjà dans la vie réelle.
Par exemple, le trafic des questions-réponses publiques sur Stack Overflow a nettement diminué depuis la généralisation de l’IA générative. De nombreuses questions qui auraient autrefois été discutées dans les communautés publiques sont désormais traitées dans des dialogues privés avec des modèles d’IA.
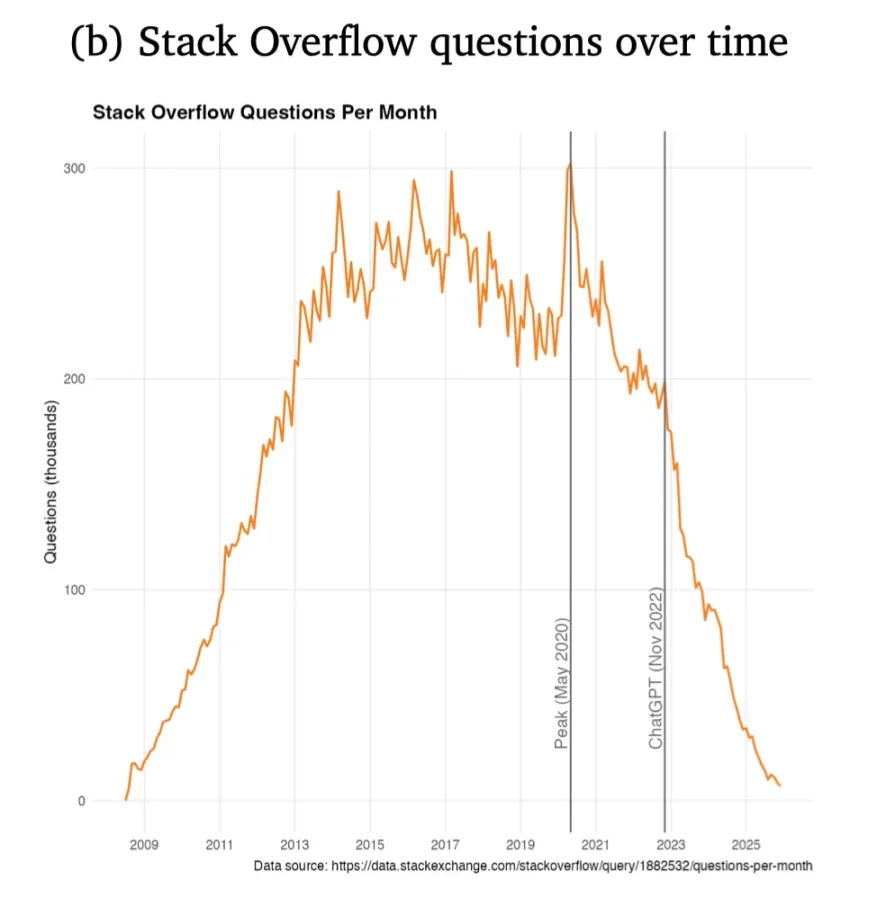
Après le lancement de ChatGPT, le nombre de questions publiées sur Stack Overflow a nettement chuté.
Un autre exemple est celui de Tailwind CSS : ses téléchargements continuent d’augmenter, mais les visites de sa documentation et ses revenus commerciaux connaissent une baisse.
Le projet est massivement utilisé, mais il devient de plus en plus difficile de transformer cette utilisation en rémunération significative pour ses mainteneurs.
Quand apparaîtra le « Spotify » du codage ?
Bien que le Vibe Coding soulève ces problèmes, l’augmentation de productivité qu’il procure est bel et bien réelle. Personne ne peut revenir en arrière, vers un monde où le codage assisté par IA n’existerait pas.
La question fondamentale est la suivante : lorsque l’IA devient un nouvel intermédiaire, les anciennes structures d’incitation ne sont plus adaptées.
Dans le système actuel, les plateformes IA tirent une immense valeur de l’écosystème open source, sans pour autant supporter le coût de son entretien. Les utilisateurs paient l’IA pour bénéficier de sa commodité, mais les projets open source sollicités — et leurs mainteneurs — ne reçoivent généralement rien en retour.
Les auteurs de l’article proposent une solution :
Repenser la répartition des bénéfices.
Tout comme les plateformes de streaming musical telles que Spotify reversent une part des recettes aux artistes en fonction du nombre de lectures, les plateformes IA pourraient parfaitement tracer les appels aux projets open source qu’elles effectuent, et redistribuer une partie de leurs revenus aux mainteneurs, proportionnellement à l’usage effectif.
Outre ces mécanismes de redistribution via les plateformes, les financements accordés par des fondations, les parrainages d’entreprises, ou encore les aides publiques spécifiques aux infrastructures numériques constituent également des leviers essentiels pour compenser la perte de revenus subie par les mainteneurs.
Cela suppose un changement de mentalité sectoriel : passer de la conception du logiciel open source comme une « ressource gratuite » à celle d’une « infrastructure publique nécessitant un investissement et un entretien à long terme ».
Le logiciel open source ne disparaîtra pas : il est déjà profondément intégré au tissu du monde numérique et ne saurait être remplacé facilement.
Mais l’ère open source, fondée sur une attention fragmentée, une accumulation progressive de réputation et un idéalisme désintéressé, semble avoir atteint ses limites.
Le Vibe Coding ne nous offre pas seulement une expérience de développement plus rapide : il constitue aussi un test de résistance crucial concernant la question de « comment assurer durablement l’entretien des technologies publiques ».
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News










