

Crise des infrastructures dans l'industrie de la cryptographie
TechFlow SélectionTechFlow Sélection
Crise des infrastructures dans l'industrie de la cryptographie
La question n'est pas de savoir si la prochaine panne d'infrastructure se produira, mais quand elle aura lieu et quel en sera le déclencheur.
Rédaction : YQ
Traduction : AididiaoJP, Foresight News
Amazon Web Services subit une nouvelle interruption majeure, affectant gravement l'infrastructure cryptographique. Les problèmes AWS dans la région US-Est-1 (centre de données de Virginie du Nord) ont paralysé Coinbase ainsi que des dizaines d'autres plateformes crypto majeures telles que Robinhood, Infura, Base et Solana.
AWS a reconnu un « taux d'erreur accru » affectant Amazon DynamoDB et EC2, des services centraux de base de données et de calcul dont dépendent des milliers d'entreprises. Cette panne fournit une validation immédiate et frappante de l'argument central de cet article : la dépendance de l'infrastructure crypto vis-à-vis des fournisseurs cloud centralisés crée des vulnérabilités systémiques qui se manifestent régulièrement sous pression.
Le timing est particulièrement révélateur. Dix jours après qu'une série de liquidations de 19,3 milliards de dollars a exposé les défaillances d'infrastructure au niveau des exchanges, l'interruption AWS d'aujourd'hui montre que le problème dépasse les plateformes individuelles pour s'étendre jusqu'à la couche fondamentale de l'infrastructure cloud. Quand AWS tombe en panne, les effets en cascade touchent simultanément les exchanges centralisés, les plateformes dites « décentralisées » ayant des dépendances centralisées, et d'innombrables autres services.
Ce n'est pas un événement isolé, mais un schéma récurrent. L'analyse suivante documente des incidents AWS similaires survenus en avril 2025, décembre 2021 et mars 2017, chaque fois entraînant l'arrêt de principaux services crypto. La question n'est pas de savoir si une prochaine panne d'infrastructure aura lieu, mais quand elle se produira et quel en sera le déclencheur.
Événement de liquidation en chaîne des 10-11 octobre 2025 : étude de cas
L'événement de liquidation en chaîne des 10-11 octobre 2025 constitue une étude de cas éclairante sur les modèles de défaillance d'infrastructure. À 20h00 UTC, une annonce géopolitique majeure a déclenché une vente massive généralisée. En une heure, 6 milliards de dollars ont été liquidés. Au moment de l'ouverture des marchés asiatiques, 19,3 milliards de dollars de positions à effet de levier avaient disparu parmi 1,6 million de comptes traders.
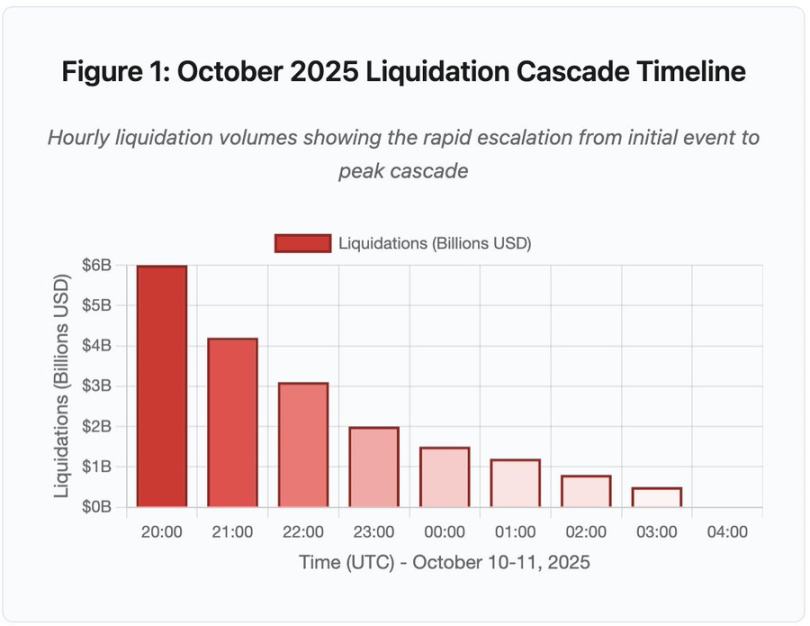
Figure 1 : Chronologie de l'événement de liquidation en chaîne d'octobre 2025
Ce diagramme interactif illustre l'évolution dramatique des liquidations horaires. Dès la première heure, 6 milliards de dollars ont disparu, puis davantage encore durant la deuxième heure où la chaîne s'est accélérée. La visualisation montre :
-
20:00-21:00 : Choc initial - 6 milliards de dollars liquidés (zone rouge)
-
21:00-22:00 : Pic de la chaîne - 4,2 milliards de dollars, période durant laquelle les API ont commencé à limiter les requêtes
-
22:00-04:00 : Période de détérioration continue - 9,1 milliards de dollars liquidés sur un marché aux liquidités faibles
-
Point critique : limitation du débit des API, retrait des market makers, raréfaction du carnet d'ordres
Son ampleur dépasse d'au moins un ordre de grandeur tous les événements précédents sur les marchés cryptos. La comparaison historique souligne la nature discontinue de cet événement :
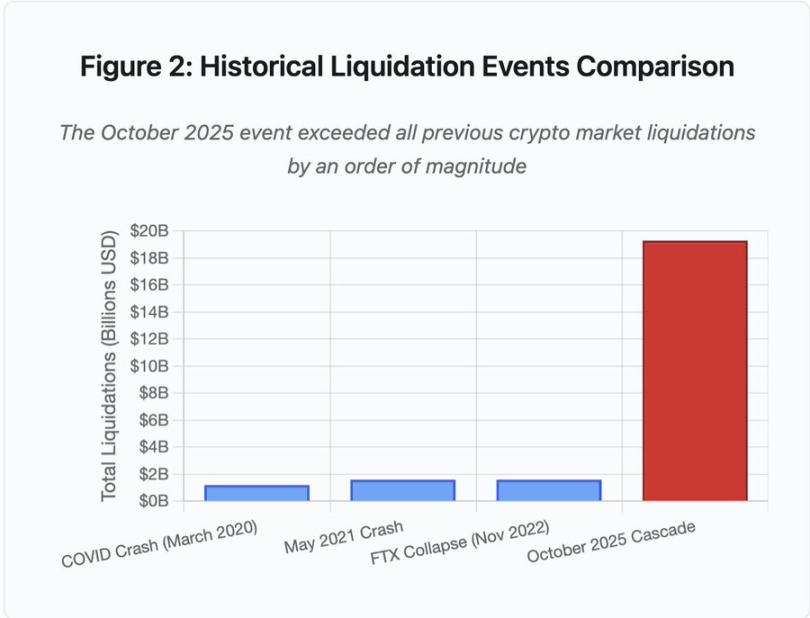
Figure 2 : Comparaison des événements historiques de liquidation
Le graphique en barres illustre de manière frappante la singularité de l'événement d'octobre 2025 :
-
Mars 2020 (COVID) : 1,2 milliard de dollars
-
Mai 2021 (effondrement) : 1,6 milliard de dollars
-
Novembre 2022 (FTX) : 1,6 milliard de dollars
-
Octobre 2025 : 19,3 milliards de dollars, soit 16 fois plus que le précédent record
Mais les chiffres de liquidation ne racontent qu'une partie de l'histoire. La question la plus intéressante concerne les mécanismes : comment un événement externe du marché a-t-il pu déclencher ce modèle spécifique de défaillance ? La réponse révèle des faiblesses systémiques dans l'architecture des exchanges centralisés et la conception des protocoles blockchain.
Défaillances hors chaîne : architecture des exchanges centralisés
Surchauffe de l'infrastructure et limitation de débit
Les API des exchanges appliquent des limitations de débit pour prévenir les abus et gérer la charge serveur. En fonctionnement normal, ces limites permettent les transactions légitimes tout en bloquant les attaques potentielles. En période de forte volatilité, lorsque des milliers de traders tentent simultanément d'ajuster leurs positions, ces mêmes limitations deviennent un goulot d'étranglement.
Les CEX limitent les notifications de liquidation à une commande par seconde, même lorsqu'ils traitent des milliers de commandes par seconde. Pendant l'événement de chaîne d'octobre, cela a créé une opacité. Les utilisateurs ne pouvaient pas connaître en temps réel la gravité de la chaîne. Des outils tiers montraient des centaines de liquidations par minute, tandis que les sources officielles affichaient des chiffres bien inférieurs.
La limitation de débit des API a empêché les traders de modifier leurs positions durant la première heure cruciale, avec des requêtes de connexion expirant et des soumissions d'ordres échouant. Les ordres stop-loss n'ont pas été exécutés, les demandes d'information sur les positions retournaient des données obsolètes ; cette défaillance infrastructurelle a transformé un événement de marché en crise opérationnelle.
Les exchanges traditionnels configurent leur infrastructure pour une charge normale augmentée d'une marge de sécurité. Mais la charge normale diffère radicalement de la charge de stress. Le volume moyen quotidien ne prédit pas bien les pics extrêmes. Durant un événement de chaîne, le volume peut exploser de 100 fois ou plus, et les requêtes de données de position peuvent augmenter de 1000 fois, chaque utilisateur vérifiant son compte simultanément.
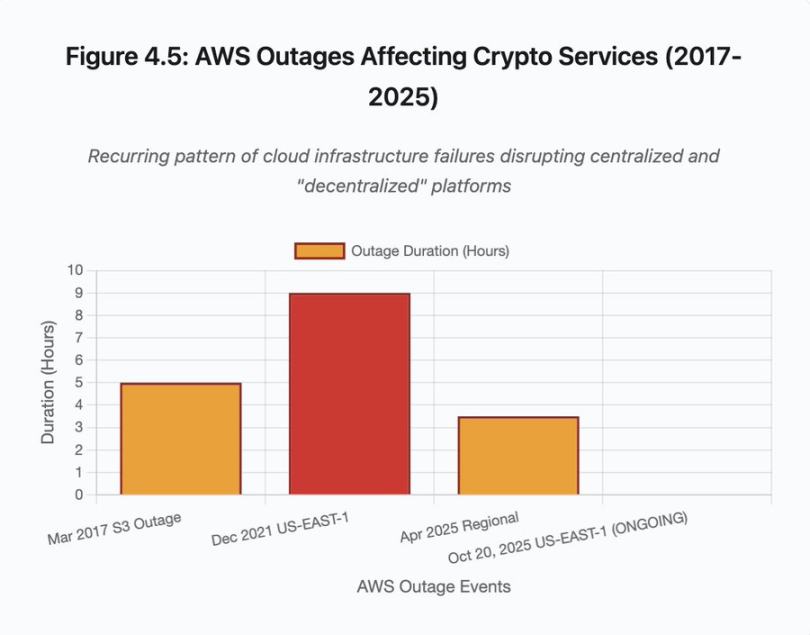
Figure 4.5 : Interruptions AWS affectant les services cryptos
L'infrastructure cloud à extension automatique aide, mais ne répond pas instantanément. Créer des répliques supplémentaires de bases de données prend plusieurs minutes. Lancer de nouvelles instances de passerelle API prend également plusieurs minutes. Pendant ces quelques minutes, le système de marge continue de valoriser les positions selon des données de carnet d'ordres corrompues causées par la surcharge.
Manipulation des oracles et vulnérabilités de prix
Pendant l'événement de chaîne d'octobre, un choix clé dans la conception du système de marge est apparu : certains exchanges calculent la valeur des garanties à partir du prix spot interne plutôt que de flux de données provenant d'oracles externes. En conditions normales, les arbitragistes maintiennent la cohérence des prix entre différents marchés. Mais quand l'infrastructure est sous pression, ce couplage s'effondre.

Figure 3 : Schéma de manipulation d'oracle
Ce diagramme interactif visualise cinq phases du vecteur d'attaque :
-
Vente initiale : pression de vente de 60 millions de dollars sur USDe
-
Manipulation de prix : USDe chute de 1,00 dollar à 0,65 dollar sur un exchange unique
-
Défaillance de l'oracle : le système de marge utilise un flux de données internes corrompu
-
Déclenchement de la chaîne : les garanties sont sous-évaluées, déclenchant des liquidations forcées
-
Amplification : 19,3 milliards de dollars de liquidations (amplification par un facteur 322)
Cette attaque exploitait le fait que Binance utilise le prix spot pour évaluer les garanties synthétiques emballées. Lorsque l'attaquant a vendu 60 millions de dollars de USDe sur un carnet d'ordres relativement peu profond, le prix spot est passé de 1,00 à 0,65 dollar. Le système de marge, configuré pour valoriser selon le prix spot, a réévalué à la baisse de 35 % toutes les positions garanties par USDe. Cela a déclenché des appels de marge et des liquidations forcées pour des milliers de comptes.
Ces liquidations ont forcé davantage de ventes sur ce même marché illiquide, faisant chuter encore le prix. Le système de marge observait ces nouveaux prix plus bas et réduisait la valorisation d'autres positions, créant une boucle de rétroaction qui a amplifié une pression de vente de 60 millions de dollars en 19,3 milliards de liquidations forcées.

Figure 4 : Boucle de rétroaction de la chaîne de liquidations
Ce schéma circulaire illustre la nature auto-renforçante de la chaîne :
Baisse des prix → Déclenchement de liquidations → Ventes forcées → Nouvelle baisse des prix → [boucle répétée]
Un système d'oracle bien conçu rendrait ce mécanisme inefficace. Si Binance avait utilisé un prix moyen pondéré temporellement (TWAP) croisé sur plusieurs exchanges, la manipulation ponctuelle des prix n'aurait pas affecté l'évaluation des garanties. S'ils avaient utilisé un flux agrégé de prix provenant de Chainlink ou d'un autre oracle multi-source, l'attaque aurait échoué.
Quatre jours plus tôt, l'incident wBETH a révélé une vulnérabilité similaire. wBETH devrait maintenir un taux d'échange 1:1 avec ETH. Pendant l'événement de chaîne, les liquidités ont disparu, et le marché spot wBETH/ETH a affiché une décote de 20 %. Le système de marge a alors sous-évalué les garanties wBETH, provoquant la liquidation de positions adossées à du ETH sous-jacent entièrement solvable.
Mécanisme de Réduction Automatique des Positions (ADL)
Quand une liquidation ne peut être exécutée au prix du marché actuel, les exchanges mettent en œuvre la Réduction Automatique des Positions (ADL), répartissant les pertes entre les traders bénéficiaires. L'ADL force la fermeture des positions gagnantes au prix courant afin de combler le déficit laissé par les positions liquidées.
Pendant l'événement de chaîne d'octobre, Binance a activé l'ADL sur plusieurs paires. Des traders possédant des positions longues bénéficiaires ont vu leurs positions fermées de force, non pas à cause d'une erreur personnelle de gestion des risques, mais parce que d'autres positions étaient devenues insolventes.
L'ADL reflète un choix architectural fondamental dans le trading dérivé centralisé. L'exchange s'assure de ne jamais perdre d'argent. Cela signifie que les pertes doivent être supportées par l'une ou plusieurs des parties suivantes :
-
Fonds d'assurance (fonds réservé par l'exchange pour combler les manques à liquider)
-
ADL (fermeture forcée des positions gagnantes)
-
Pertes socialisées (répartition des pertes entre tous les utilisateurs)
La taille du fonds d'assurance par rapport au volume total des positions ouvertes détermine la fréquence de l'ADL. En octobre 2025, le fonds d'assurance de Binance atteignait environ 2 milliards de dollars. Par rapport aux 4 milliards de dollars de positions ouvertes sur les contrats BTC, ETH et BNB en USDⓈ-M, cela représentait une couverture de 50 %. Mais durant l'événement de chaîne d'octobre, le volume total des positions ouvertes sur toutes les paires dépassait 20 milliards de dollars. Le fonds d'assurance ne pouvait donc pas couvrir le déficit.
Après la chaîne d'octobre, Binance a annoncé qu'il garantirait l'absence d'ADL pour les contrats BTC, ETH et BNB en USDⓈ-M tant que le volume total des positions resterait inférieur à 4 milliards de dollars. Cela crée une structure d'incitation : l'exchange peut maintenir un fonds d'assurance plus important pour éviter l'ADL, mais cela mobilise des capitaux qui pourraient être rentabilisés autrement.
Défaillances sur chaîne : Limites des protocoles blockchain
Le graphique en barres compare les durées d'indisponibilité lors de différents événements :
-
Solana (février 2024) : 5 heures - goulot d'étranglement du débit de votes
-
Polygon (mars 2024) : 11 heures - incompatibilité de version entre validateurs
-
Optimism (juin 2024) : 2,5 heures - surcharge du séquenceur (airdrop)
-
Solana (septembre 2024) : 4,5 heures - attaque par spam transactionnel
-
Arbitrum (décembre 2024) : 1,5 heure - défaillance d'un fournisseur RPC
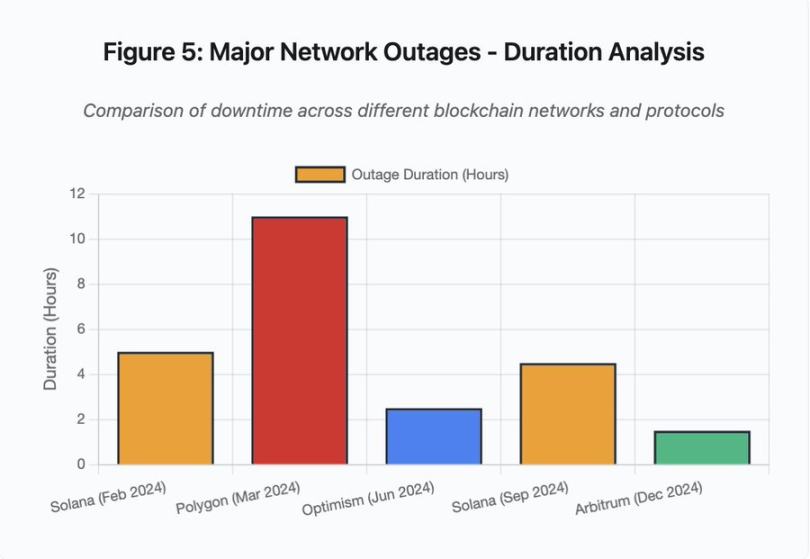
Figure 5 : Interruptions majeures – Analyse de la durée
Solana : goulot d'étranglement du consensus
Solana a connu plusieurs interruptions entre 2024 et 2025. L'interruption de février 2024 a duré environ 5 heures, celle de septembre 2024 environ 4 à 5 heures. Ces incidents ont la même cause racine : le réseau ne parvient pas à traiter le volume de transactions pendant des attaques par spam ou des périodes d'activité extrême.
Détail figure 5 : Les interruptions de Solana (5 heures en février, 4,5 heures en septembre) mettent en lumière des problèmes récurrents de résilience du réseau sous pression.
L'architecture de Solana est optimisée pour le débit. En conditions idéales, le réseau traite 3 000 à 5 000 transactions par seconde avec une finalité sub-seconde. Cette performance dépasse Ethereum de plusieurs ordres de grandeur. Mais durant les épisodes de stress, cette optimisation crée des failles.
L'interruption de septembre 2024 a été provoquée par un déluge de transactions spam saturant le mécanisme de vote des validateurs. Les validateurs Solana doivent voter les blocs pour atteindre le consensus. En fonctionnement normal, ils priorisent les transactions de vote pour assurer la progression du consensus. Mais auparavant, le protocole traitait les transactions de vote comme des transactions ordinaires au niveau du marché des frais.
Quand la mempool est saturée de millions de transactions spam, les validateurs peinent à propager leurs votes. Sans suffisamment de votes, les blocs ne peuvent pas être finalisés. Sans blocs finalisés, la chaîne s'arrête. Les utilisateurs voient leurs transactions bloquées dans la mempool. Aucune nouvelle transaction ne peut être soumise.
StatusGator a enregistré plusieurs interruptions de service Solana en 2024-2025, que Solana n'a jamais officiellement reconnues. Cela crée une asymétrie d'information. Les utilisateurs ne peuvent pas distinguer un problème de connexion local d'un problème global du réseau. Les services de surveillance tiers assurent une forme de responsabilité, mais les plateformes devraient tenir des pages de statut complètes.
Ethereum : explosion des frais de gaz
Ethereum a connu des hausses extrêmes des frais de gaz durant la prospérité DeFi en 2021, avec des frais de transaction dépassant 100 dollars pour un simple transfert. Des interactions complexes de contrats intelligents coûtaient 500 à 1000 dollars. Ces frais rendaient le réseau inutilisable pour les petites transactions, tout en ouvrant une autre voie d'attaque : l'extraction de MEV.
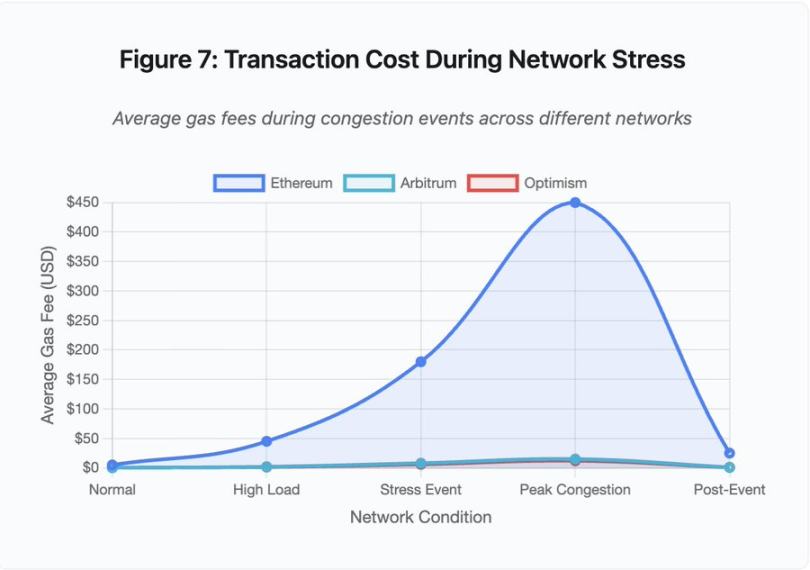
Figure 7 : Coût des transactions en période de stress réseau
Ce graphique en courbes montre dramatiquement l'augmentation des frais de gaz sur différents réseaux durant les pics de congestion :
-
Ethereum : 5 dollars (normal) → 450 dollars (pic de congestion) - +90x
-
Arbitrum : 0,50 dollar → 15 dollars - +30x
-
Optimism : 0,30 dollar → 12 dollars - +40x
La visualisation montre que même les solutions Layer 2 subissent une augmentation significative des frais de gaz, malgré un point de départ beaucoup plus bas.
La Valeur Maximale Extractible (MEV) décrit les profits que les validateurs peuvent extraire en réordonnant, incluant ou excluant des transactions. Dans un environnement à hauts frais de gaz, l'extraction de MEV devient particulièrement lucrative. Les arbitragistes se précipitent pour devancer de gros échanges DEX, les robots de liquidation se battent pour liquider en premier les positions sous-garanties. Cette compétition se traduit par des enchères sur les frais de gaz.
Les utilisateurs souhaitant garantir l'inclusion de leur transaction en période de congestion doivent surenchérir sur les robots MEV. Cela conduit à des frais supérieurs à la valeur de la transaction. Vous voulez récupérer votre airdrop de 100 dollars ? Payez 150 dollars de frais de gaz. Vous devez ajouter des garanties pour éviter la liquidation ? Entrez en concurrence avec des robots payant 500 dollars de frais prioritaires.
La limite de gaz d'Ethereum restreint la quantité totale de calcul par bloc. En période de congestion, les utilisateurs enchérissent pour l'espace rare dans les blocs. Le marché des frais fonctionne comme prévu : celui qui paie le plus obtient la priorité. Mais cette conception rend le réseau de plus en plus cher en période d'usage élevé, précisément au moment où les utilisateurs en ont le plus besoin.
Les solutions Layer 2 tentent de résoudre ce problème en déplaçant le calcul hors chaîne tout en héritant de la sécurité d'Ethereum via des règlements périodiques. Optimism, Arbitrum et d'autres Rollups traitent des milliers de transactions hors chaîne, puis soumettent des preuves compressées à Ethereum. Cette architecture réussit à réduire significativement le coût par transaction en fonctionnement normal.
Layer 2 : goulot d'étranglement du séquenceur
Mais les solutions Layer 2 introduisent de nouveaux goulots d'étranglement. Optimism a connu une interruption en juin 2024 lorsque 250 000 adresses ont réclamé un airdrop simultanément. Le séquenceur — composant qui ordonne les transactions avant leur envoi à Ethereum — a été submergé, privant les utilisateurs de soumission de transactions pendant plusieurs heures.
Cet incident montre que déplacer le calcul hors chaîne n'élimine pas les besoins d'infrastructure. Le séquenceur doit traiter les transactions entrantes, les ordonner, les exécuter, et générer des preuves de fraude ou des preuves ZK pour le règlement sur Ethereum. Sous trafic extrême, le séquenceur fait face aux mêmes défis d'extension qu'une blockchain autonome.
Il faut maintenir la disponibilité de plusieurs fournisseurs RPC. Si le fournisseur principal tombe en panne, les utilisateurs doivent pouvoir basculer sans heurt vers une alternative. Durant l'interruption d'Optimism, certains fournisseurs RPC sont restés fonctionnels tandis que d'autres ont échoué. Les portefeuilles connectés par défaut à un fournisseur défaillant ont été incapables d'interagir avec la chaîne, même si celle-ci était toujours en ligne.
Les interruptions AWS ont répété à maintes reprises l'existence de risques d'infrastructure centralisée dans l'écosystème crypto :
-
20 octobre 2025 (aujourd'hui) : interruption de la région US-Est-1 affectant Coinbase, Venmo, Robinhood et Chime. AWS reconnaît une hausse du taux d'erreur sur DynamoDB et EC2.
-
Avril 2025 : interruption régionale affectant simultanément Binance, KuCoin et MEXC. Plusieurs exchanges majeurs deviennent indisponibles lorsque leurs composants hébergés sur AWS tombent en panne.
-
Décembre 2021 : interruption de la région US-Est-1 paralyse Coinbase, Binance.US et l'exchange dit « décentralisé » dYdX pendant 8 à 9 heures, impactant aussi les entrepôts Amazon et des services de streaming majeurs.
-
Mars 2017 : interruption S3 empêche les utilisateurs de se connecter à Coinbase et GDAX pendant cinq heures, accompagnée de larges interruptions internet.
Le schéma est clair : ces exchanges hébergent des composants critiques sur l'infrastructure AWS. Quand AWS connaît une interruption régionale, plusieurs exchanges et services majeurs deviennent simultanément indisponibles. Les utilisateurs ne peuvent pas accéder à leurs fonds, exécuter des transactions ou modifier leurs positions durant l'interruption, précisément au moment où la volatilité du marché pourrait exiger une action immédiate.
Polygon : incompatibilité de version du consensus
Polygon (anciennement Matic) a connu une interruption de 11 heures en mars 2024. La cause racine concernait une incompatibilité de version entre validateurs : certains exécutaient une ancienne version logicielle, d'autres une version mise à jour. Ces versions calculaient différemment les transitions d'état.
Détail figure 5 : L'interruption de Polygon (11 heures) est la plus longue parmi les principaux événements analysés, soulignant la gravité d'une défaillance de consensus.
Quand les validateurs parviennent à des conclusions différentes sur l'état correct, le consensus échoue, la chaîne ne peut plus produire de nouveaux blocs car les validateurs ne s'accordent plus sur la validité des blocs. Cela crée une impasse : les validateurs avec l'ancien logiciel rejettent les blocs produits par ceux avec le nouveau logiciel, et vice-versa.
La résolution nécessite une coordination pour la mise à jour des validateurs, mais coordonner cela durant une interruption prend du temps. Chaque opérateur de validateur doit être contacté, la bonne version logicielle doit être déployée, et le validateur redémarré. Sur un réseau décentralisé comptant des centaines de validateurs indépendants, cette coordination prend plusieurs heures, voire jours.
Un hard fork utilise généralement un déclencheur basé sur la hauteur de bloc. Tous les validateurs se mettent à jour avant une certaine hauteur, assurant une activation simultanée, mais cela demande une coordination préalable. Une mise à jour progressive, où les validateurs adoptent progressivement la nouvelle version, comporte le risque précis d'incompatibilité qui a causé l'interruption de Polygon.
Compromis architecturaux
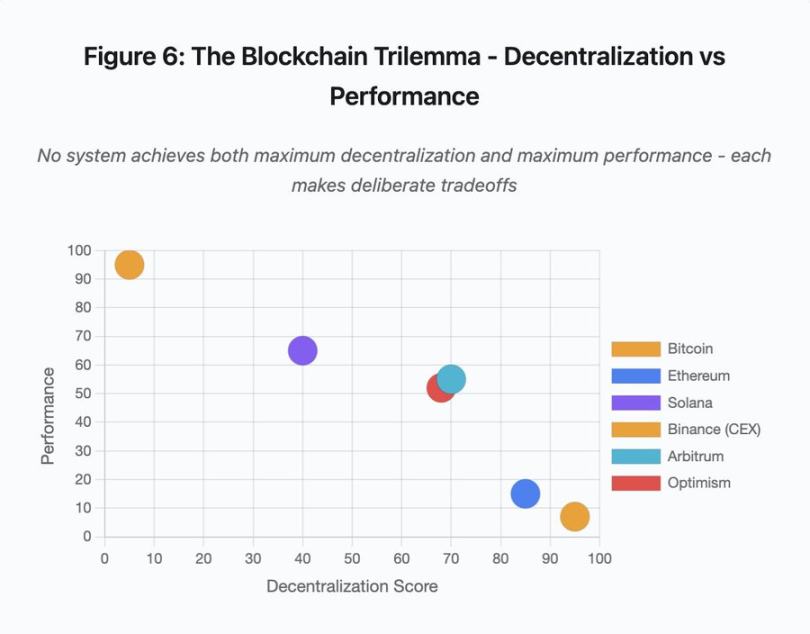
Figure 6 : Le dilemme blockchain – décentralisation vs performance
Ce nuage de points cartographie différents systèmes selon deux dimensions clés :
-
Bitcoin : haute décentralisation, faible performance
-
Ethereum : haute décentralisation, performance moyenne
-
Solana : décentralisation moyenne, haute performance
-
Binance (CEX) : décentralisation minimale, performance maximale
-
Arbitrum/Optimism : décentralisation moyenne-élevée, performance moyenne
Insight clé : aucun système ne peut atteindre à la fois la décentralisation et la performance maximales. Chaque conception implique des compromis réfléchis pour différents cas d'usage.
Les exchanges centralisés atteignent une faible latence grâce à une architecture simple : le moteur de matching traite les ordres en microsecondes, l'état étant stocké dans une base de données centralisée. Aucun protocole de consensus n'introduit de surcharge, mais cette simplicité crée des points uniques de défaillance, et les pannes en cascade se propagent à travers des systèmes fortement couplés sous pression.
Les protocoles décentralisés distribuent l'état entre les validateurs, éliminant ainsi les points uniques de défaillance. Les blockchains à haut débit conservent cette propriété en cas d'interruption (pas de perte de fonds, seulement une perte temporaire d'activité). Mais parvenir à un consensus entre validateurs distribués introduit une surcharge de calcul : les validateurs doivent s'accorder avant qu'une transition d'état ne soit finalisée. Quand les validateurs exécutent des versions incompatibles ou font face à un trafic écrasant, le processus de consensus peut temporairement s'arrêter.
Ajouter des répliques améliore la tolérance aux pannes, mais augmente le coût de coordination. Dans les systèmes de tolérance aux pannes byzantines, chaque validateur supplémentaire augmente la surcharge de communication. Les architectures à haut débit minimisent cette surcharge par une communication optimisée entre validateurs, offrant ainsi des performances excellentes, mais elles restent vulnérables à certains types d'attaques. Les architectures axées sur la sécurité privilégient la diversité des validateurs et la robustesse du consensus, limitant le débit de la couche de base tout en maximisant la résilience.
Les solutions Layer 2 tentent de fournir ces deux attributs via une architecture en couches. Elles héritent de la sécurité d'Ethereum par règlement sur L1, tout en offrant un haut débit par calcul hors chaîne. Toutefois, elles introduisent de nouveaux goulots d'étranglement au niveau du séquenceur et des RPC, montrant que la complexité architecturale, en résolvant certains problèmes, en crée de nouveaux.
L'extensibilité reste un problème fondamental
Ces événements révèlent un schéma constant : les systèmes sont dimensionnés pour une charge normale, puis échouent catastrophiquement sous pression. Solana traite efficacement le trafic habituel, mais s'effondre quand le volume augmente de 10 000 %. Les frais de gaz d'Ethereum restent raisonnables jusqu'à ce que l'adoption DeFi provoque la congestion. L'infrastructure d'Optimism fonctionne bien jusqu'à ce que 250 000 adresses réclament un airdrop simultanément. L'API de Binance fonctionne en période normale, mais est limitée durant une chaîne de liquidations.
L'événement d'octobre 2025 illustre ce phénomène au niveau des exchanges. En fonctionnement normal, les limitations de débit API et les connexions à la base de données de Binance sont suffisantes. Mais durant une chaîne de liquidations, lorsque chaque trader tente simultanément d'ajuster sa position, ces limites deviennent des goulots d'étranglement. Le système de marge, conçu pour protéger l'exchange via des liquidations forcées, amplifie la crise en créant des vendeurs forcés au pire moment.
L'extension automatique offre une protection insuffisante contre des augmentations soudaines de charge. Démarrer des serveurs supplémentaires prend plusieurs minutes. Pendant ces minutes, le système de marge valorise les positions selon des données de prix corrompues issues d'un carnet d'ordres raréfié. Quand la nouvelle capacité est disponible, la chaîne s'est déjà propagée.
Surdimensionner pour des événements rares de stress est coûteux en fonctionnement normal. Les opérateurs d'exchange optimisent pour la charge typique, acceptant occasionnellement des pannes comme un choix économiquement rationnel. Le coût des interruptions est externalisé vers les utilisateurs, qui subissent liquidations, transactions bloquées ou impossibilité d'accéder à leurs fonds durant les mouvements clés du marché.
Améliorations de l'infrastructure
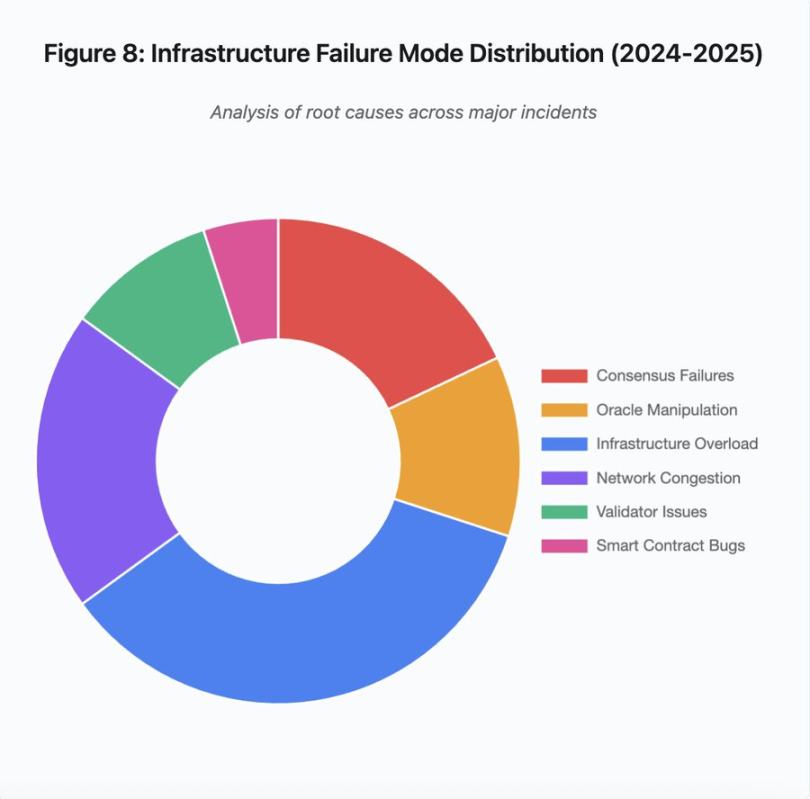
Figure 8 : Distribution des modes de défaillance de l'infrastructure (2024-2025)
La répartition en camembert des causes racines montre :
-
Surchauffe de l'infrastructure : 35 % (le plus fréquent)
-
Conflit réseau : 20 %
-
Défaillance du consensus : 18 %
-
Manipulation d'oracle : 12 %
-
Problèmes de validateurs : 10 %
-
Faiblesses de contrat intelligent : 5 %
Plusieurs changements architecturaux pourraient réduire la fréquence et la gravité des pannes, bien que chacun implique des compromis :
Séparation entre système de prix et système de liquidation
Une partie du problème d'octobre venait du couplage entre le calcul de marge et le prix spot. Utiliser un taux de change plutôt que le prix spot pour les actifs emballés aurait évité la mauvaise évaluation de wBETH. Plus généralement, les systèmes critiques de gestion des risques ne devraient pas dépendre de données de marché manipulables. Des systèmes d'oracles indépendants, avec agrégation multi-source et calcul TWAP, offrent un flux de prix plus robuste.
Infrastructures surdimensionnées et redondantes
L'interruption AWS d'avril 2025 affectant Binance, KuCoin et MEXC a mis en évidence les risques liés à la dépendance centralisée. Exécuter des composants critiques sur plusieurs fournisseurs cloud augmente la complexité opérationnelle et le coût, mais élimine les pannes corrélées. Les réseaux Layer 2 peuvent maintenir plusieurs fournisseurs RPC avec basculement automatique. Les coûts supplémentaires semblent gaspillés en période normale, mais évitent des heures d'indisponibilité en période de pic.
Tests de stress renforcés et planification de capacité
Le schéma « fonctionne bien jusqu'à ce qu'il échoue » indique un manque de tests sous pression. Simuler une charge 100 fois supérieure à la normale devrait être une pratique standard ; identifier les goulots d'étranglement en développement coûte moins cher que de les découvrir durant une panne réelle. Pourtant, les tests réalistes de charge restent difficiles. Le trafic réel présente des motifs que les tests synthétiques ne capturent pas entièrement, et le comportement des utilisateurs en cas de panique réelle diffère de celui en test.
Voie à suivre
Le surdimensionnement offre la solution la plus fiable, mais entre en conflit avec les incitations économiques. Maintenir une capacité excédentaire de 10 fois pour des événements rares coûte cher quot
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News


![Axe Compute [NASDAQ : AGPU] finalise sa restructuration d'entreprise (anciennement POAI), la puissance GPU décentralisée d'entreprise Aethir fait officiellement son entrée sur le marché principal](https://upload.techflowpost.com/upload/images/20251212/2025121221124297058230.png?x-oss-process=image/resize,p_50/quality,q_80)










