

DeepSeek « vole » OpenAI ? Plutôt un cas de voleur qui crie au voleur
TechFlow SélectionTechFlow Sélection
DeepSeek « vole » OpenAI ? Plutôt un cas de voleur qui crie au voleur
La distillation n'est pas du plagiat, mais un moyen nécessaire pour l'évolution technologique.
Auteur : Deng Yongyi, TechFlow

Image : générée par WuJie AI
Pendant le Festival du Printemps 2025, ce n’était pas seulement Ne Zha 2 qui a fait sensation, mais aussi une application nommée DeepSeek. Cette histoire inspirante a été maintes fois racontée : le 20 janvier, DeepSeek (Deep Thinking), une startup d’intelligence artificielle basée à Hangzhou, a publié son nouveau modèle R1, rivalisant avec o1, le modèle de raisonnement le plus puissant actuel d’OpenAI, provoquant véritablement une onde de choc mondiale.
En seulement une semaine après son lancement, l’application DeepSeek a dépassé les 20 millions de téléchargements et s’est classée première dans plus de 140 pays. Sa vitesse de croissance dépasse celle de ChatGPT lors de son lancement en 2022 et représente désormais environ 20 % de ce dernier.
Jusqu’à quel point est-il populaire ? Au 8 février, le nombre d’utilisateurs de DeepSeek a dépassé 100 millions, touchant bien au-delà des passionnés d’IA, s’étendant de la Chine au monde entier. Des personnes âgées aux enfants, en passant par des humoristes et des politiciens, tout le monde parle de DeepSeek.
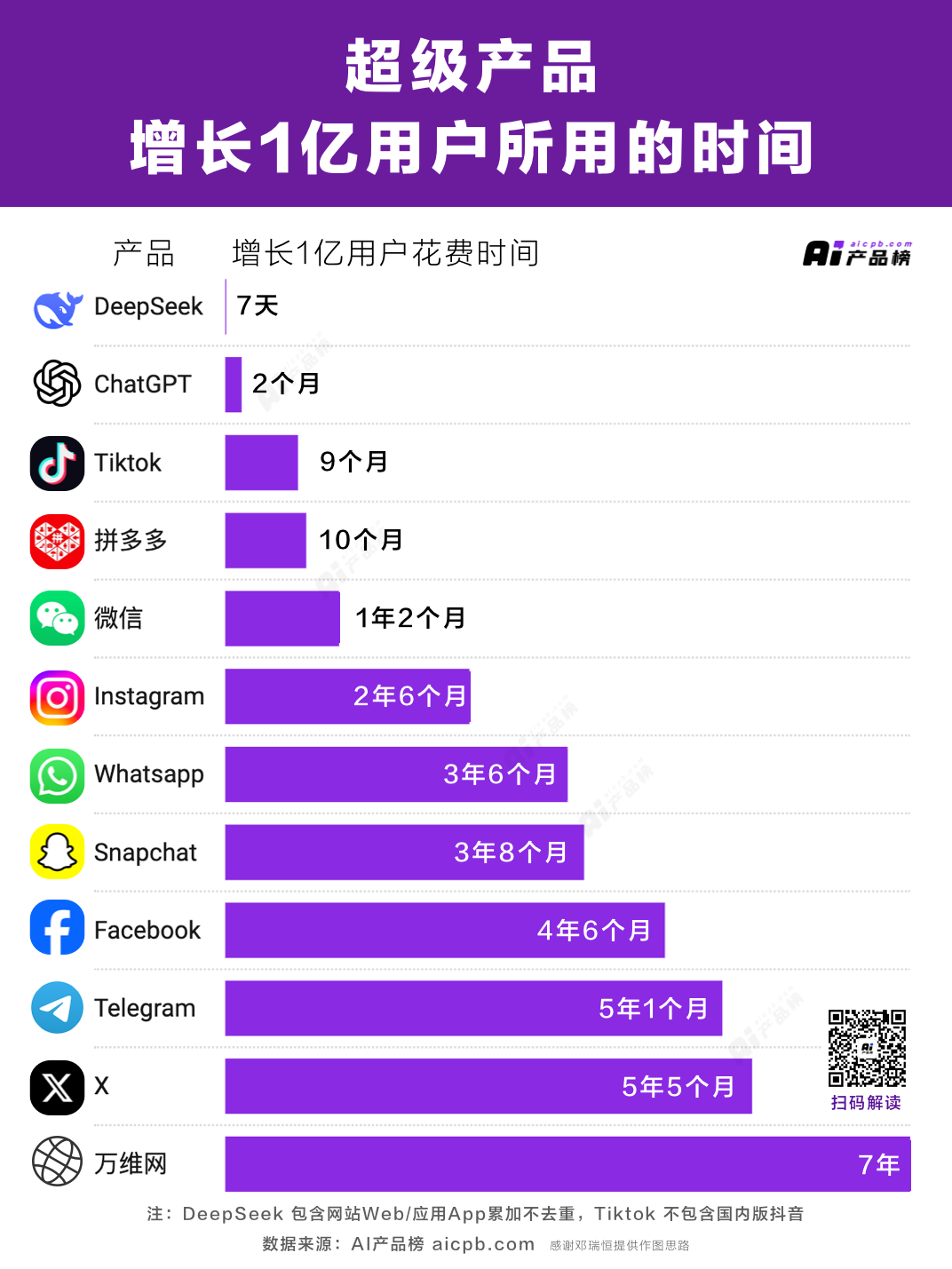
À ce jour, l’impact de DeepSeek continue de se faire sentir. Au cours des deux dernières semaines, DeepSeek a enchaîné les événements dignes d’un scénario TikTok : succès fulgurant, croissance explosive, surpassant de nombreux concurrents américains, et se retrouvant rapidement au bord du précipice géopolitique. Les États-Unis et l’Europe discutent désormais de « menaces sur la sécurité nationale », et de nombreuses régions ont rapidement émis des ordres interdisant le téléchargement ou l’installation.
Marc Andreessen, associé chez A16Z, s’est exclamé : l’apparition de DeepSeek constitue un autre « moment Spoutnik » (Sputnik Moment).
(Une expression datant de la guerre froide, lorsque l’URSS a lancé avec succès le premier satellite artificiel au monde, « Spoutnik 1 », en 1957, provoquant la panique dans la société américaine, qui prenait conscience que sa suprématie était menacée et que son avantage technologique pouvait être renversé.)
Mais plus on est célèbre, plus on attire les controverses. Dans la communauté technologique, DeepSeek est également impliqué dans des débats autour de la « distillation » et du « vol de données ».
À ce jour, DeepSeek n’a publié aucune déclaration officielle. Ces débats se sont ainsi polarisés entre deux extrêmes : des partisans enthousiastes qui élèvent DeepSeek-R1 au rang d’innovation « stratégique pour la nation », et des professionnels de la tech qui remettent en question son coût d’entraînement extrêmement bas et sa méthode de formation par distillation, jugeant que ces innovations sont surestimées.
Deepseek aurait-il « volé » OpenAI ? Plutôt un cas de voleur criant au voleur
Dès le début de la popularité de DeepSeek, des géants américains comme OpenAI et Microsoft ont publiquement exprimé leurs critiques, ciblant principalement les données utilisées par DeepSeek. David Sacks, responsable de l’IA et du chiffrement au sein du gouvernement américain, a déclaré publiquement que DeepSeek avait « absorbé » les connaissances de ChatGPT via une technique appelée distillation.
Dans un article du Financial Times britannique, OpenAI affirme avoir détecté des signes de « distillation » de ChatGPT par DeepSeek, affirmant que cela violerait les conditions d’utilisation de ses modèles. Toutefois, OpenAI n’a fourni aucune preuve concrète.
En réalité, cette accusation ne tient pas debout.
La distillation est une technique normale d'entraînement des grands modèles. Elle intervient généralement pendant la phase d'entraînement : en utilisant les sorties d'un modèle plus grand et plus puissant (modèle professeur) pour entraîner un modèle plus petit (modèle étudiant) à améliorer ses performances. Sur certaines tâches spécifiques, le modèle plus petit peut atteindre des résultats similaires à moindre coût.
La distillation n'est pas un plagiat. En termes simples, c’est comme si un professeur résolvait tous les problèmes difficiles et rédigeait des notes parfaites — ces notes ne contiennent pas seulement les réponses, mais aussi les meilleures méthodes de résolution ; un élève ordinaire (petit modèle) n’a qu’à apprendre directement ces notes, produire ses propres réponses, puis les comparer aux démarches logiques contenues dans les notes du professeur.
L’apport majeur de DeepSeek réside surtout dans l’utilisation accrue de l’apprentissage non supervisé — permettant à la machine de s’auto-corriger davantage, réduisant ainsi le besoin de feedback humain (RLHF). Le résultat immédiat est une baisse drastique du coût d’entraînement — ce qui explique aussi bon nombre des critiques.
Dans l'article scientifique sur DeepSeek-V3, la taille exacte du cluster d'entraînement utilisé (2048 puces H800) a été précisée. De nombreuses estimations basées sur les prix du marché situent ce coût à environ 5,5 millions de dollars, soit une fraction des coûts d'entraînement des modèles de Meta ou Google.
Cependant, il est important de noter que DeepSeek a clairement indiqué dans son article que ce montant correspond uniquement au coût d'une seule exécution finale, sans inclure les coûts initiaux liés au matériel, au personnel ou aux pertes durant l'entraînement.
Dans le domaine de l’IA, la distillation n’est pas une nouveauté, et plusieurs fabricants de modèles ont déjà révélé leurs travaux de distillation. Par exemple, Meta a déjà publié comment ses modèles ont été distillés : Llama 2 a utilisé un modèle plus grand et plus intelligent pour générer des données comprenant processus de pensée et méthodes de raisonnement, puis a affiné ses propres modèles de raisonnement plus petits grâce à ces données.
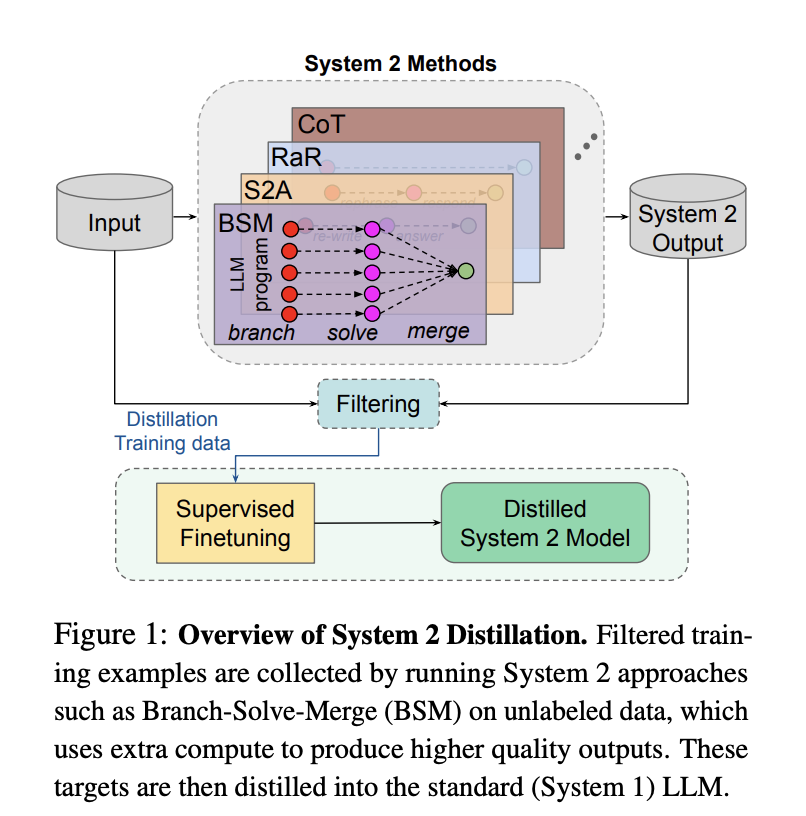
△ Source : Meta FAIR
Mais la distillation comporte aussi des inconvénients.
Un professionnel de l’IA dans une grande entreprise a déclaré à TechFlow que la distillation permet certes d’améliorer rapidement les capacités d’un modèle, mais présente l’inconvénient que les données générées par le « modèle professeur » sont trop propres, manquant de diversité. Apprendre à partir de telles données rend le modèle comparable à un « plat préparé standardisé », dont les capacités ne peuvent jamais dépasser celles du modèle professeur.
La qualité des données détermine largement l’efficacité de l’entraînement. Si la distillation couvre la majorité du processus d’entraînement, cela conduit à une forte homogénéisation des modèles. Aujourd’hui, alors que les grands modèles pullulent à travers le monde, chacun proposant sa « version premium », distiller un modèle identique n’a plus grand intérêt.
Un problème encore plus critique est que les hallucinations pourraient empirer. En effet, le petit modèle imite souvent seulement la « surface » du grand modèle, sans comprendre en profondeur la logique sous-jacente, ce qui nuit à ses performances sur de nouvelles tâches.
Ainsi, pour que le modèle développe sa propre personnalité, les ingénieurs IA doivent intervenir dès la phase des données — le choix des données, leur proportion, ainsi que la méthode d’entraînement, influencent fortement les caractéristiques finales du modèle.
Les cas typiques sont aujourd’hui OpenAI et Anthropic. Ces deux entreprises californiennes ont été parmi les premières à développer des grands modèles, sans disposer de modèle préexistant à distiller, et ont donc directement extrait et appris à partir d’Internet public et de jeux de données.
Leurs parcours différents ont conduit à des styles très distincts : aujourd’hui, ChatGPT ressemble davantage à un étudiant sérieux en sciences, excellent pour résoudre divers problèmes de la vie quotidienne ou professionnelle ; tandis que Claude excelle en lettres, reconnu comme champion incontesté des tâches d’écriture, sans être en reste pour les tâches de codage.
Un autre aspect ironique des accusations d’OpenAI réside dans le fait qu’il utilise une clause floue pour accuser DeepSeek, alors qu’il a lui-même fait des choses similaires.
Au départ, OpenAI était une organisation axée sur l’open source, mais elle est passée au closed source à partir de GPT-4. Son entraînement a presque exploité toutes les données publiques disponibles sur Internet. Depuis son passage au closed source, OpenAI est constamment impliqué dans des litiges de droits d’auteur avec des médias et des éditeurs.
L’accusation d’« apprentissage par distillation » portée par OpenAI contre DeepSeek est ironiquement qualifiée de « voleur criant au voleur », car ni OpenAI o1 ni DeepSeek R1 n’ont divulgué dans leurs articles les détails de leurs préparations de données — cette question reste donc un mystère complet.
Encore plus important, DeepSeek-R1 a été publié sous licence MIT — l’une des licences open source les plus permissives. DeepSeek-R1 autorise l’usage commercial, permet la distillation, et met à disposition du public six petits modèles déjà distillés, pouvant être directement déployés sur smartphones ou PC, une démarche sincère et engageante envers la communauté open source.
Le 5 février, Tanishq Mathew Abraham, ancien responsable recherche chez Stability AI, a rédigé un article spécifique indiquant que cette accusation touche un terrain gris : premièrement, OpenAI n’a fourni aucune preuve que DeepSeek ait directement utilisé GPT pour la distillation. Il suppose qu’il est possible que DeepSeek ait utilisé un jeu de données généré par ChatGPT (déjà largement disponible sur le marché), ce qui n’est pas explicitement interdit par OpenAI.
La distillation est-elle un critère pour juger si l’on fait de l’AGI ?
Dans le débat public, beaucoup utilisent désormais l’étape de « distillation ou non » pour juger du plagiat ou de l’engagement en faveur de l’AGI, ce qui est excessivement arbitraire.
Les travaux de DeepSeek ont relancé la popularité du concept de « distillation », une technique qui existe en réalité depuis près de dix ans.
En 2015, dans un article conjoint de plusieurs grands spécialistes de l’IA — Hinton, Oriol Vinyals et Jeff Dean — intitulé « Distilling the Knowledge in a Neural Network », la technique de « distillation des connaissances » dans les grands modèles a été officiellement introduite, devenant depuis un standard dans le domaine.
Pour les fabricants de modèles spécialisés dans des domaines ou tâches spécifiques, la distillation constitue une voie plus réaliste.
Un professionnel de l’IA a déclaré à TechFlow qu’en Chine, pratiquement aucun grand fabricant de modèles ne s’abstient de la distillation — c’est un secret de polichinelle. « Actuellement, les données disponibles sur Internet sont presque épuisées. Le coût de la pré-formation et de l’annotation des données, même pour les grandes entreprises, est difficile à supporter aisément. »
Une exception notable est ByteDance. Dans la version récemment publiée de DouBao 1.5 Pro, ByteDance a clairement affirmé « n’avoir jamais utilisé de données générées par un autre modèle durant l’entraînement, refusant catégoriquement de prendre le raccourci de la distillation », montrant ainsi sa détermination à poursuivre l’AGI.
Le choix de ne pas utiliser la distillation par les grandes entreprises repose sur des considérations pragmatiques, notamment éviter de futures controverses juridiques. Dans un cadre closed source, cela crée également une certaine barrière aux capacités du modèle. Selon TechFlow, le coût actuel d’annotation des données chez ByteDance est désormais comparable à celui des entreprises de la Silicon Valley — allant jusqu’à 200 dollars par donnée annotée, nécessitant des experts hautement qualifiés dans des domaines spécifiques, tels que des diplômés de niveau master ou doctorat.
Pour la plupart des acteurs du secteur de l’IA, que ce soit par distillation ou d’autres moyens techniques, il s’agit fondamentalement d’explorer les limites de la loi d’échelle (Scaling Law). C’est une condition nécessaire, mais non suffisante, pour explorer l’AGI.
Pendant les deux premières années de popularité des grands modèles, la loi d’échelle était souvent grossièrement comprise comme « la puissance brute engendre des miracles » — accumuler de la puissance de calcul et des paramètres suffisait à faire émerger l’intelligence, surtout lors de la phase de pré-entraînement.
Aujourd’hui, derrière le regain d’intérêt pour la « distillation », se dessine en filigrane une évolution du paradigme de développement des grands modèles : la loi d’échelle persiste, mais s’est progressivement déplacée de la phase de pré-entraînement vers les phases d’entraînement postérieur et de raisonnement.
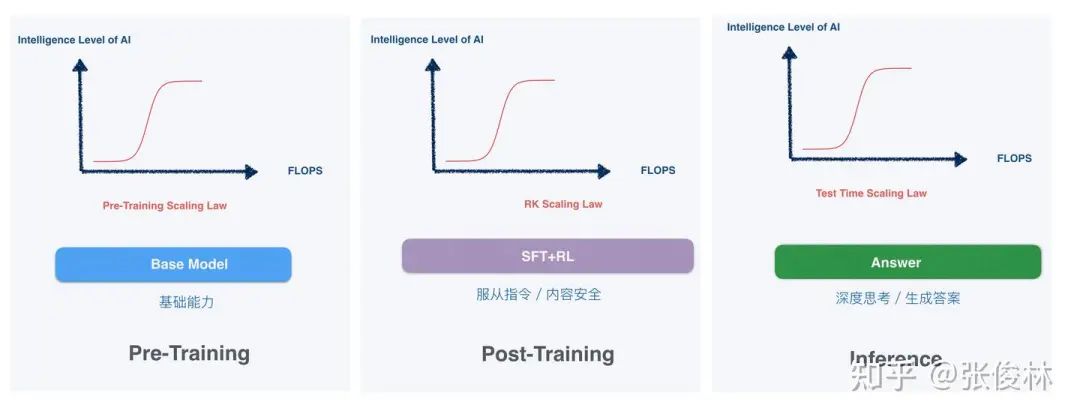
△ Source : article de Zhang Junlin, doctorant à l'Institut des logiciels de l'Académie des sciences de Chine
Le modèle o1 d’OpenAI, publié en septembre 2024, est considéré comme le symbole de ce virage vers l’entraînement postérieur et le raisonnement, restant à ce jour le modèle de raisonnement le plus avancé au monde. Cependant, OpenAI n’a jamais révélé publiquement sa méthode ni ses détails d’entraînement, et son coût d’application reste élevé : o1 pro coûte jusqu’à 200 dollars par mois, avec une vitesse de raisonnement encore lente, ce qui constitue un frein majeur pour le développement d’applications IA.
Actuellement, la plupart des travaux dans la communauté IA visent à reproduire les performances d’o1 tout en réduisant les coûts de raisonnement, afin de permettre des applications plus larges. La signification historique de DeepSeek réside non seulement dans le fait qu’il a considérablement raccourci le temps nécessaire aux modèles open source pour rattraper les meilleurs modèles closed source — en seulement environ trois mois, il a presque égalé plusieurs indicateurs d’o1 — mais surtout dans le fait qu’il a identifié et publié ouvertement la clé essentielle de la percée d’o1.
Il ne faut pas négliger un grand présupposé : DeepSeek a accompli cette innovation en s’appuyant sur les épaules des géants. Considérer les méthodes techniques comme la « distillation » comme de simples raccourcis serait trop réducteur. Il s’agit davantage d’une victoire de la culture open source.
L’effet de synergie écologique et open source de DeepSeek s’est rapidement manifesté. Peu après son succès, un nouveau travail de « la marraine de l’IA », Li Feifei, a rapidement fait le buzz : en utilisant Gemini de Google comme « modèle professeur » et Qwen2.5 d’Alibaba affiné comme « modèle étudiant », grâce à la distillation et autres méthodes, un modèle de raisonnement s1 a été entraîné pour moins de 50 dollars, reproduisant les capacités des modèles DeepSeek-R1 et OpenAI-o1.
NVIDIA est un autre cas emblématique. Bien que sa capitalisation boursière ait chuté d’environ 600 milliards de dollars en une nuit après la sortie de DeepSeek-R1 — la plus grande perte quotidienne de l’histoire — elle a rapidement rebondi le lendemain, grimpant d’environ 9 %. Le marché continue d’anticiper une forte demande en capacités de raisonnement induite par R1.
On peut prévoir qu’après l’intégration des capacités de R1 par les différents acteurs du domaine des grands modèles, une vague d’innovation dans les applications IA suivra naturellement.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News













