La « crise pétrolière » de l'explosion des données de l'IA, les entreprises de contenu peuvent désormais gagner de l'argent sans rien faire
TechFlow SélectionTechFlow Sélection
La « crise pétrolière » de l'explosion des données de l'IA, les entreprises de contenu peuvent désormais gagner de l'argent sans rien faire
Si l'on compare les grands modèles d'IA à des voitures, les données brutes sont le pétrole brut.
Rédaction : Jiang Jiang
Édition : Manman Zhou
L'apparition de ChatGPT et l'adoption fulgurante de Midjourney ont permis la première application à grande échelle de l'intelligence artificielle (IA), popularisant ainsi les grands modèles.
Par « grand modèle », on entend un modèle d'apprentissage automatique doté d'un nombre élevé de paramètres et d'une structure complexe, capable de traiter des volumes massifs de données et d'exécuter diverses tâches complexes.
01 Conflits liés aux droits d'auteur sur les données IA
Si l'on compare les grands modèles d'IA actuels à une automobile, alors les données brutes représentent le pétrole brut. Quoi qu'il en soit, les modèles d'IA ont avant tout besoin d'« essence » suffisante.
Les sources de données brutes pour les entreprises d'IA sont principalement les suivantes :
-
Données publiques gratuites disponibles en ligne, telles que Wikipédia, blogs, forums, actualités, etc. ;
-
Médias traditionnels et maisons d'édition historiques ;
-
Institutions universitaires et autres centres de recherche ;
-
Utilisateurs finaux (grand public) utilisant les modèles.
Dans le monde réel, la propriété du pétrole est encadrée par des normes juridiques bien établies. En revanche, dans le domaine encore flou de l'IA, le droit d'exploitation de ces « ressources premières » n'est pas clairement défini, ce qui génère de nombreux litiges.
Tout récemment, plusieurs majors du disque ont intenté une action en justice contre les sociétés d'IA musicales Suno et Udio, les accusant de violation de droits d'auteur. Cette poursuite rappelle celle engagée par le New York Times contre OpenAI en décembre dernier.

Source image : Billboard
En juillet 2023, plusieurs auteurs ont poursuivi OpenAI, affirmant que ChatGPT avait produit des résumés d’œuvres protégées par le droit d’auteur.
En décembre de la même année, le New York Times a lancé une procédure similaire contre Microsoft et OpenAI, les accusant d’avoir utilisé son contenu pour entraîner des robots conversationnels d’IA.
Par ailleurs, une action collective a été déposée en Californie contre OpenAI, l’accusant d’avoir collecté sans consentement des informations personnelles d’utilisateurs depuis Internet afin d’entraîner ChatGPT.
OpenAI n’a finalement pas assumé cette accusation. L’entreprise a rejeté les allégations du New York Times, affirmant ne pas pouvoir reproduire les problèmes mentionnés, et surtout, que les données fournies par le journal n’étaient pas significatives pour OpenAI.

Source :
https://openai.com/index/openai-and-journalism/
Pour OpenAI, la leçon principale tirée de cet épisode pourrait être la nécessité de bien gérer ses relations avec les fournisseurs de données, en clarifiant les responsabilités de chacun. Ainsi, au cours de l'année écoulée, nous avons vu OpenAI conclure des partenariats avec de nombreux fournisseurs de données, notamment The Atlantic, Vox Media, News Corp, Reddit, Financial Times, Le Monde, Prisa Media, Axel Springer et American Journalism Project, entre autres.
À l'avenir, OpenAI pourra légalement utiliser les données de ces médias, tandis que ces derniers intégreront la technologie OpenAI dans leurs propres produits.
02 L’IA stimule la monétisation des plateformes de contenu
Cependant, la raison fondamentale poussant OpenAI à nouer des partenariats avec des fournisseurs de données n’est pas la crainte des poursuites, mais plutôt la pénurie imminente de données pour l’apprentissage automatique. Des chercheurs du MIT ont estimé que les jeux de données d’apprentissage automatique pourraient épuiser toutes les « données linguistiques de haute qualité » d’ici 2026.
Ces « données de haute qualité » deviennent donc très prisées par des fabricants de modèles comme OpenAI ou Google. Les entreprises de contenu signent fréquemment des accords avec les concepteurs de modèles d’IA, adoptant ainsi un modèle rentable quasi passif.
La plateforme traditionnelle de médias Shutterstock a successivement noué des collaborations avec des entreprises d’IA telles que Meta, Alphabet, Amazon, Apple, OpenAI et Reka. Grâce à la licence de contenus accordée aux modèles d’IA, elle a porté son chiffre d’affaires annuel à 104 millions de dollars en 2023, et prévoit un revenu de 250 millions de dollars en 2027. Reddit percevrait jusqu’à 60 millions de dollars par an pour avoir autorisé Google à utiliser son contenu. Apple, quant à lui, cherche à collaborer avec les principaux médias d’information, proposant des frais de licence annuels d’au moins 50 millions de dollars. Les redevances perçues par les entreprises de contenu auprès des sociétés d’IA augmentent frénétiquement à un rythme annuel de 450 %.

Source image : CX Scoop
Durant les dernières années, en dehors du streaming, il était difficile de monétiser les contenus — un véritable point douloureux pour l’industrie du contenu. Comparé à l’ère de la création d’entreprises internet, l’émergence de l’IA offre aujourd’hui une plus grande marge de manœuvre aux acteurs du secteur, ainsi qu’une forte attente en termes de revenus.
03 La rareté persistante des données de haute qualité
Bien entendu, tous les types de contenu ne répondent pas aux besoins de l’IA.
Concernant la controverse entre OpenAI et le New York Times mentionnée précédemment, un autre aspect saillant concerne la qualité des données. Tout comme le raffinage du pétrole exige à la fois une matière première de bonne qualité et une technologie de purification efficace.
OpenAI a insisté sur le fait que le contenu du New York Times n’avait apporté aucune contribution significative à l’entraînement de ses modèles. Contrairement à Shutterstock, dont les services coûtent à OpenAI plusieurs dizaines de millions de dollars par an, les médias textuels comme le New York Times, fondés sur l’actualité, ne sont pas les chouchous de l’ère de l’IA. Ce dernier privilégie des données profondes et uniques.
Face à la rareté des données de haute qualité, les entreprises d’IA concentrent désormais leurs efforts sur les « technologies de purification » et les applications « tout-en-un ».
Le 25 juin, OpenAI a acquis Rockset, une entreprise spécialisée dans les bases de données analytiques en temps réel. Cette société propose principalement des fonctionnalités d'indexation et d'interrogation en temps réel des données. OpenAI intègrera la technologie de Rockset à ses produits afin d'améliorer la valeur d'utilisation immédiate des données.

Source image : DePIN Scan
Grâce à cette acquisition, OpenAI entend améliorer l’utilisation et l’accès de l’IA aux données en temps réel. Cela permettra à ses produits de prendre en charge des applications plus complexes, telles que des systèmes de recommandation en temps réel, des chatbots pilotés par des données dynamiques ou encore des systèmes de surveillance et d’alerte instantanés.
Rockset constitue le « département pétrolier intégré » d’OpenAI, transformant directement des données ordinaires en données de haute qualité prêtes à l’emploi.
04 L’attribution des droits sur les données des créateurs est-elle une utopie ?
Les données des plateformes de médias en ligne (Facebook, Reddit, etc.) proviennent largement des contenus générés par les utilisateurs (UGC). Alors que nombre de ces plateformes facturent cher leur accès aux données aux entreprises d’IA, elles ajoutent discrètement à leurs conditions d’utilisation une clause stipulant que « la plateforme détient le droit d’utiliser les données des utilisateurs pour entraîner des modèles d’IA ».
Bien que les conditions d’utilisation mentionnent explicitement ce droit, de nombreux créateurs ignorent quelles œuvres produites ont été utilisées par quels modèles, s’il s’agit d’un usage payant ou non, et ne peuvent donc percevoir les retombées financières auxquelles ils auraient pu prétendre.
Lors de la conférence trimestrielle de Meta en février dernier, Mark Zuckerberg a clairement indiqué qu’il utiliserait les images provenant de Facebook et Instagram pour entraîner ses outils de génération d’IA.
Selon des rapports, Tumblr aurait également conclu secrètement des accords de licence avec OpenAI et Midjourney, sans toutefois révéler les détails précis de ces contrats.
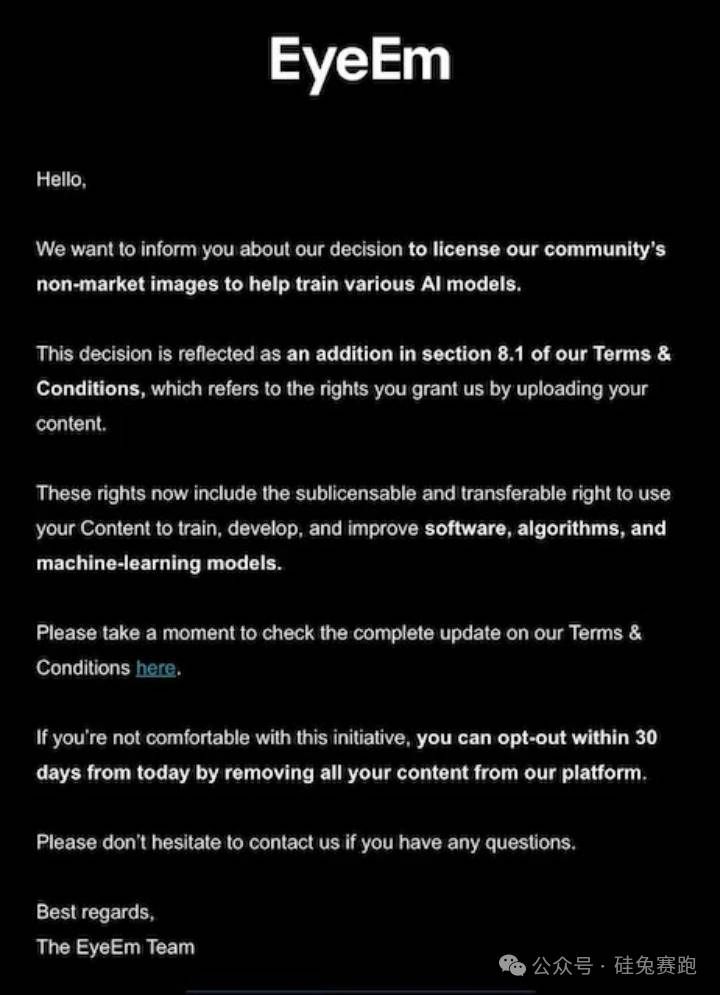
Les créateurs de la plateforme de banque d’images EyeEm ont récemment reçu une notification les informant que leurs photos publiées seraient utilisées pour entraîner des modèles d’IA. Bien que les utilisateurs puissent choisir de ne plus utiliser le service en conséquence, aucune politique de compensation n’a encore été annoncée. La maison mère de EyeEm, Freepik, a confié à Reuters avoir signé des accords avec deux grandes entreprises technologiques, cédant la majorité de ses 200 millions d’images à environ trois cents par image. Le PDG Joaquin Cuenca Abela a indiqué que cinq transactions similaires étaient en cours, mais a refusé de divulguer l’identité des acheteurs.
Des plateformes dominées par du contenu UGC comme Getty Images, Adobe, Photobucket, Flickr et Reddit font face à des problèmes similaires. Face à l’attrait considérable de la monétisation des données, ces plateformes choisissent d’ignorer la propriété intellectuelle des utilisateurs, regroupant et vendant massivement les données aux entreprises de modèles d’IA.
Tout ce processus se déroule dans l’ombre, et les créateurs n’ont aucune possibilité de résistance. Beaucoup d’entre eux ne découvriront peut-être qu’un jour lointain, en reconnaissant une œuvre semblable à la leur dans un modèle d’IA, que leurs créations ont été vendues par une plateforme à une entreprise d’IA sans leur consentement.
Pour résoudre les difficultés d’attribution des droits et de protection des revenus des créateurs, le Web3 pourrait offrir une solution intéressante. Alors que les entreprises d’IA atteignent des sommets boursiers sur le marché américain, les cryptomonnaies liées au concept d’IA dans l’écosystème Web3 connaissent également une envolée spectaculaire. Grâce à ses caractéristiques de décentralisation et d’immutabilité, la blockchain dispose d’un avantage naturel pour protéger les droits des créateurs.
Les contenus multimédias tels que les images et vidéos ont déjà connu une adoption massive sur la blockchain durant le boom de 2021. Désormais, l’enregistrement des contenus UGC issus des réseaux sociaux sur la blockchain se développe silencieusement. Par ailleurs, de nombreuses plateformes Web3 combinant IA récompensent déjà les utilisateurs ordinaires ayant contribué à l’entraînement des modèles, qu’ils soient propriétaires de données ou participants à l’entraînement.
Le développement exponentiel des modèles d’IA renforce davantage le besoin d’attribution des droits sur les données. Les créateurs doivent se poser les questions suivantes : pourquoi mes œuvres ont-elles été vendues à une entreprise d’IA à 5 cents pièce sans mon accord ? Pourquoi n’ai-je aucun contrôle sur ce processus, ni aucun bénéfice à en tirer ?
Les plateformes médias exploiteront leurs ressources jusqu’à épuisement sans réussir à apaiser l’anxiété des entreprises d’IA face à la pénurie de données. La condition préalable à une production abondante de données de haute qualité réside dans l’attribution claire des droits et dans une répartition équitable des intérêts entre les créateurs, les plateformes et les entreprises de modèles d’IA.
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News