

Entretien avec le PDG de FLock.io : Pourquoi Google ne peut pas faire un véritable apprentissage fédéré, mais que la blockchain le peut ?
TechFlow SélectionTechFlow Sélection
Entretien avec le PDG de FLock.io : Pourquoi Google ne peut pas faire un véritable apprentissage fédéré, mais que la blockchain le peut ?
Le monde est utilitariste, et l'algorithme est en effet cette boîte noire ; pourtant, le résultat a vraiment produit de grands miracles.
Rédaction : Sunny, TechFlow
Invité : Jiahao Sun, FLock
« L'apprentissage automatique décentralisé devient progressivement bien plus qu'un simple slogan : c'est désormais une solution d'ingénierie réalisable. »
– Jiahao Sun, PDG de FLock.io
L'intelligence artificielle (IA) décentralisée n'est pas un concept nouveau, mais connaît actuellement un renouveau grâce à l'essor des cryptomonnaies, offrant un potentiel pour la démocratisation de l'IA. Toutefois, pour ceux qui ne sont pas familiers avec ce domaine, l'idée de démocratisation de l'IA peut sembler floue.
La blockchain, en tant que backend du web moderne, permet la coordination et le crowdsourcing des ressources et de la main-d'œuvre.
L'IA couvre largement l'entraînement et l'inférence afin d'effectuer des prédictions, et repose sur trois piliers : la puissance de calcul, les modèles et les données. Actuellement, ces éléments sont principalement contrôlés par quelques grandes entreprises technologiques. Bien que leur utilisation soit généralement considérée comme bienveillante, il n'existe aucune garantie vérifiable, d'où la nécessité d'une nouvelle approche permettant à un public plus large de participer au développement de l'IA.
Google a déjà tenté une expérience avec l'apprentissage fédéré : les appareils des utilisateurs contribuent localement aux données et à la puissance de calcul, puis les résultats sont agrégés dans un modèle global. Cependant, ce modèle conserve un contrôle centralisé.
La blockchain propose une solution en activant un système économique privé où chacun peut participer, via la tokenéconomie et les cryptomonnaies, à l'apport de données, de puissance de calcul ou de modèles.
FLock (apprentissage fédéré basé sur la blockchain) introduit un véritable apprentissage fédéré grâce aux contrats intelligents et à la tokenéconomie, assurant ainsi une participation plus large. Aujourd'hui, nous accueillons le PDG de FLock pour discuter du concept d'IA démocratique, ainsi que de sa pertinence dans des domaines tels que la santé mondiale, même indépendamment des arguments liés à la décentralisation, car l'apprentissage fédéré reste pertinent en soi.
Du directeur IA en finance traditionnelle à l'apprentissage fédéré smart-contractisé
TechFlow : Pour commencer, pourriez-vous vous présenter brièvement et nous expliquer ce qu'est FLock, ou plus précisément l'apprentissage fédéré décentralisé ?
Jiahao :
J'ai passé dix ans dans l'écosystème Web2 de la fintech. Dès ma sortie d'études, j'ai intégré l'incubateur Entrepreneur First, où j'ai lancé ma première startup axée sur le scoring de crédit assisté par l'IA. Très vite, un chasseur de têtes m'a recruté dans une institution financière de premier plan en tant que responsable innovation, poste que j'ai occupé pendant huit ans jusqu'à devenir directeur mondial de l'IA. J'ai donc toujours été profondément impliqué dans la recherche et l'application de l'IA.
Mon intérêt pour le secteur Web3 remonte au printemps 2017 des ICO. À l'époque, je trouvais fascinant que de nombreuses équipes puissent lever des fonds avec presque n'importe quelle idée. Cependant, le marché était clairement immature – on aurait dit aujourd'hui que trop de projets « chiens » pullulaient, ce qui donnait une impression peu raffinée. Je n'ai donc pas envisagé sérieusement d'y entrer, me contentant d'observer ce secteur intrigant.
Pendant la pandémie, le temps semblait s'étirer, notamment en Europe et en Amérique, où tout le monde travaillait depuis chez soi. Soudain, nous avions beaucoup plus de temps libre. Ce surplus pouvait être utilisé à jouer aux jeux vidéo tous les jours, ou à faire quelque chose de plus significatif. Après avoir joué pendant un an, j'ai senti que c'était une perte de temps, alors j'ai choisi de faire quelque chose d'utile. En fin d'année 2021, malgré le creux du marché crypto, j'ai remarqué de nombreux projets remarquables. Dirigés par des équipes expérimentées en Web2, ils excellaient dans l'espace Web3, ce qui m'a fortement inspiré et suscité mon engouement pour l'évolution du Web3 et ses technologies réellement pertinentes.
Ma décision finale d'entrer dans le Web3 découle d'un article scientifique primé lors d'une conférence prestigieuse, fruit de réflexions approfondies entre les fondateurs et notre équipe de recherche sur l'essence véritable de l'apprentissage automatique décentralisé. Ce fut la première apparition publique de FLock en tant que concept technique (Federated Learning on the Blockchain), soutenu par une validation rigoureuse par les pairs académiques, ce qui nous a donné une grande confiance et un solide soutien pour lancer pleinement le projet FLock.
Lien vers l'article : https://scholar.google.com/citations?user=s0eOtD8AAAAJ&hl=en
L'apprentissage fédéré, ou l'apprentissage automatique décentralisé, existe depuis longtemps dans l'industrie.
Par exemple, NVIDIA et AWS investissent massivement dans des systèmes de calcul distribué et d'apprentissage automatique distribué. Maisil y a toujours un problème fondamental : imaginons qu'AWS affirme que « toutes ces ressources de cloud computing sont distribuées, vous possédez votre propre plateforme ». Pourtant, vous ne pouvez pas y croire vraiment, car vous achetez toujours via AWS une instance de cloud. AWS conserve un pouvoir de contrôle intermédiaire et reste l'autorité ultime. Vous ne possédez donc pas réellement cette ressource AWS ; vous la louez simplement. De même, les utilisateurs n'ont pas la propriété de leurs données.
Sur le plan de la confidentialité, Google a introduit dès 2017 le concept d'apprentissage fédéré (Federated Learning).
L'apprentissage fédéré est toujours un cadre d'apprentissage automatique, mais où tous les calculs sont répartis sur chaque nœud. Ainsi, les données ne quittent jamais l'appareil : chaque utilisateur effectue un calcul local, puis les résultats sont agrégés pour former un modèle global combiné. Ce modèle reflète les apprentissages issus de toutes les données sans exiger que celles-ci soient transférées sur un serveur tiers.
Ce processus constitue l'apprentissage fédéré. Après son introduction par Google, il a été appliqué très tôt à la prédiction de texte dans les claviers. De nombreux utilisateurs de téléphones Pixel ont ainsi été parmi les premiers à expérimenter concrètement l'apprentissage fédéré : lorsque vous tapez avec le clavier Google, il devine le mot suivant. Voilà l'une des premières applications pratiques de cette technologie.
Mais comme mentionné précédemment, Google contrôle entièrement le processus d'entraînement. Il pourrait potentiellement agir de manière malveillante, ayant accès à tous les codes sources et données brutes, sans qu'on puisse prouver qu'il n'en a rien fait. Un incident marquant s'est produit quand un logiciel chinois de saisie a été exposé : il affirmait utiliser l'apprentissage fédéré pour protéger la vie privée, mais des investigations ont révélé qu'il transmettait toutes les données de frappe directement vers un serveur centralisé, contredisant complètement son propre discours.
Ces événements récents ont suscité des débats techniques importants : «Si une seule entité contrôle toutes ces ressources, peut-on vraiment lui faire confiance pour ne pas abuser de ce pouvoir ?» Et si elle affirme sa bonne foi, peut-on la croire ? Manifestement non, sinon Apple et Google collaboreraient déjà pour entraîner ensemble un modèle de prédiction de texte.
C'est pourquoi nous intégrons le mécanisme des contrats intelligents blockchain au cadre traditionnel de l'apprentissage fédéré : cela supprime le besoin de Google ou de tout intermédiaire gestionnaire. Chacun devient un acteur autonome avec son propre nœud, calculant seulement sa part. Un contrat intelligent détermine ensuite quels gradients sont utiles et doivent être agrégés, tout étant réglé par un consensus sur la chaîne. C'est là que naquit FLock en tant qu'idée de recherche.
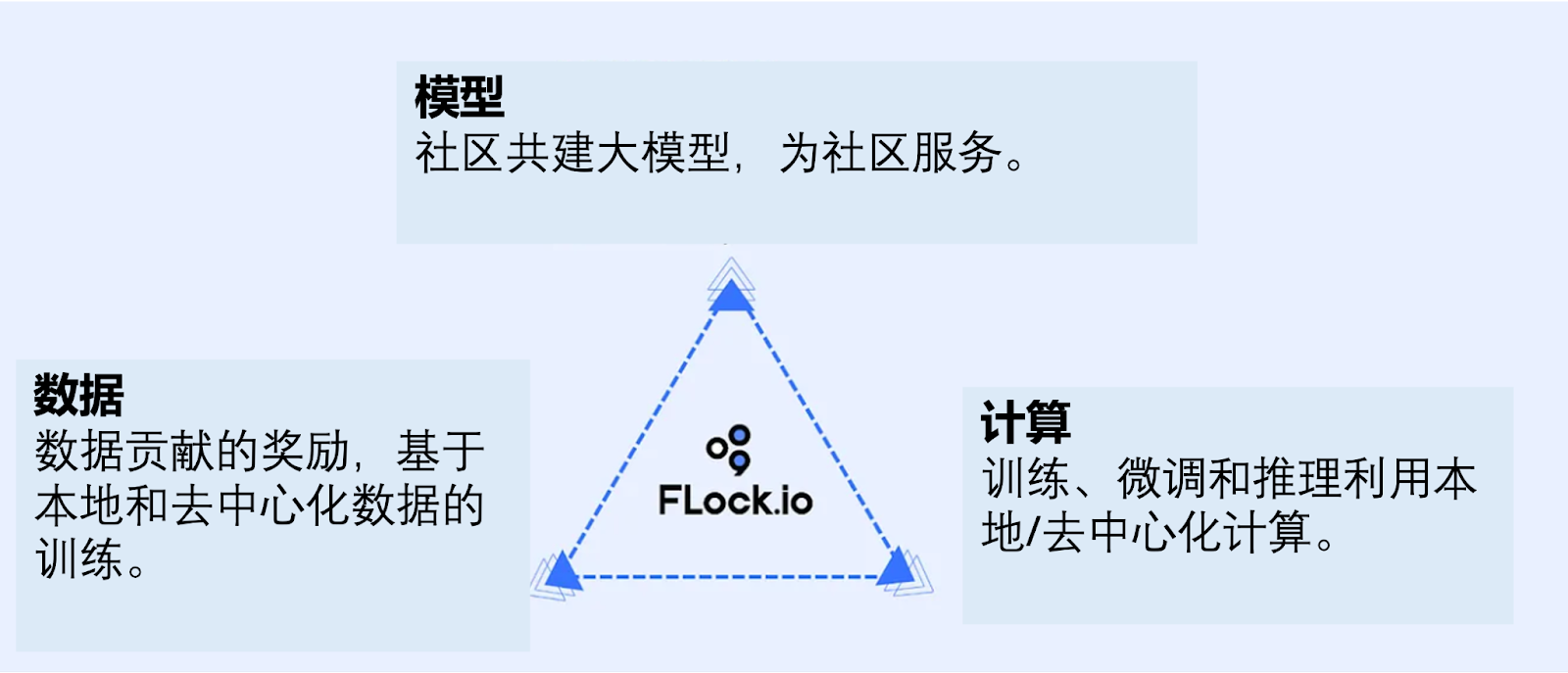
FLock coordonne via des contrats intelligents la coconstruction communautaire de calcul, de modèles et de données
Comprendre d’abord : les données entraînées sont-elles encore vos données ?
TechFlow : Alors, sur un nœud individuel, comment les données locales sont-elles chiffrées avant d'être intégrées au modèle global, et comment la confidentialité des données initiales est-elle préservée après l'obtention des résultats d'entraînement ?
Jiahao :
Prenons un exemple : WorldCoin. Vous prenez une photo de votre iris, puis celle-ci passe dans un réseau neuronal qui la transforme en un "embedding". Cet embedding n'est plus votre photo d'iris, n'est-ce pas ? Tout dépend si les gens acceptent ou non ce raisonnement.
– « Ce n'est plus mon iris, c'est un nouvel embedding. »
Certains rejettent ce raisonnement, estimant que c'est toujours un dérivé de leurs données.
Procédons étape par étape. Pour ceux qui acceptent ce principe, dans le cadre de l'apprentissage fédéré, les données personnelles ne quittent jamais le nœud local. Ce qui sort, c'est la variation du modèle local après entraînement sur vos données, appelée gradient.
Nous transmettons uniquement ce gradient au nœud suivant. Aucune information liée directement à vos données n'est transférée. Elles restent parfaitement confidentielles. Théoriquement, aucun chiffrement supplémentaire n'est nécessaire, car il ne s'agit pas de vos données elles-mêmes.
Si vous rejetez ce raisonnement et considérez que tout dérivé appartient à vos données — même si ce n'est plus votre iris mais un embedding après traitement par un réseau neuronal — nous ajoutons alors une couche de chiffrement sur ce canal de transmission.
Nous chiffrons également la transmission entre nœuds. Plusieurs méthodes existent, dont certaines particulièrement innovantes comme la Deep Gradient Compression, qui compresse les données transmises à moins de 5 %. Cela accélère la transmission, résout simultanément les problèmes de confidentialité et préserve la précision du modèle : un triple avantage.
Pourquoi ? D'abord, en apprentissage automatique, pour éviter le surajustement (overfitting), on utilise souvent des techniques comme le Dropout, consistant à omettre intentionnellement certaines données pendant le calcul afin d'améliorer la précision globale. Par exemple, même si un calcul atteint 100 %, on le réduit volontairement à 70-80 % avant transmission, car un résultat parfait risquerait de conduire à un minimum local plutôt qu'au minimum global souhaité. Cette méthode améliore en réalité la précision globale du calcul.
Deuxièmement, en apprentissage profond, lorsque les gradients sont compressés à l'extrême (par exemple à 5 % ou moins), l'information qu'ils contiennent est tellement réduite qu'il devient impossible de reconstituer les données d'origine — un peu comme appliquer un masque épais sur une image, rendant toute reconstruction complète irréaliste, même pour une IA avancée. Elle peut spéculer, imaginer, mais les informations exploitables sont trop limitées. D'après la théorie de l'information, personne ne peut reconvertir ces gradients en données d'origine : c'est déjà une forme de chiffrement sécurisée.
Troisièmement, réduire la taille des données augmente naturellement l'efficacité de la transmission. Même pour des modèles géants de plusieurs dizaines de Go, grâce à nos optimisations, un ajustement décentralisé sur plusieurs machines domestiques ordinaires peut être achevé en quelques heures.
L'apprentissage automatique décentralisé devient progressivement bien plus qu'un simple slogan : c'est désormais une solution d'ingénierie réalisable.
Il ne s'agit donc pas d'un problème inhérent à la blockchain ou au mécanisme fédéré lui-même, mais de la sécurité de la transmission entre nœuds. Tant que celle-ci est garantie, tout va bien. Ce que j'ai décrit n'est qu'une approche possible. Des solutions comme les ZK, le FHE ou le TEE peuvent aussi servir. FLock est compatible avec toutes ces technologies, et nous avons même publié un article sur zkFL.
Apprentissage fédéré + Contrats intelligents = FLock
TechFlow : Dans l'apprentissage fédéré, chaque nœud traite ses propres données, puis soumet un résultat. Que se passe-t-il ensuite ? Comment expliquer ce consensus à quelqu'un qui ne connaît pas l'IA ?
Jiahao :
L'ensemble de ces nœuds forme un cercle. Nous utilisons une méthode appelée Ring-all Reduce : les gradients passent d'un nœud à l'autre, sans intermédiaire, jusqu'à ce qu'un nœud reçoive à nouveau les données — c'est alors qu'un cycle complet est terminé. On parle d'addition de gradients. Une fois cette phase accomplie, chaque participant met à jour son modèle local.
Le consensus intervient dans un système sans gestionnaire central. Pourquoi Google a-t-il besoin de gérer un système fédéré centralisé ?
Parce qu'il craint que certains nœuds ne trichent : par exemple, qu'ils utilisent des données fausses ou envoient des gradients aléatoires. C'est la raison pour laquelle un gestionnaire central est nécessaire. C'est aussi pourquoi, dans le monde Web2 traditionnel, les participants à l'apprentissage fédéré signent des contrats : on ne collabore qu'avec des parties de confiance.
Avec FLock, nous adoptons une approche décentralisée pour empêcher ces comportements malveillants. Nous remplaçons le gestionnaire central par des contrats intelligents, servant de validateurs automatisés.
L'apprentissage automatique est orienté résultats : il suffit de vérifier si les gradients soumis font évoluer le modèle vers une meilleure précision.
Si tous les autres tendent vers une précision croissante et que vous envoyez des gradients qui la font baisser, vous serez pénalisé (slashé). Ce n'est pas immédiat : la pénalité est progressive. Si vos contributions restent persistantes et divergentes, vous serez finalement exclu.
Il s'agit d'un mécanisme de jeu géré par contrat intelligent.
Des cas extrêmes peuvent-ils survenir ? C'est précisément là que la tokenomie prend tout son sens.
Nous avons analysé de nombreux scénarios extrêmes dans notre article. Prenons un exemple simple :
Supposons que mes données proviennent uniquement d'utilisateurs droitiers, sauf un nœud appartenant à un gaucher, dont les données diffèrent réellement, mais sont authentiques. Lors du premier calcul, les modèles des droitiers dévieront vers la droite, tandis que celui du gaucher penchera vers la gauche. Au premier tour, selon le consensus FLock, le nœud du gaucher sera légèrement slashé car différent. Idem au deuxième tour. Mais après plusieurs itérations, comme ses données sont réelles et apportent une contribution valable, l'évolution du modèle commencera à s'incliner vers la direction du gaucher, entraînant progressivement les autres modèles dans cette orientation.
Selon notre tokenomie, plus le modèle final converge vers une direction, plus les récompenses sont attribuées à ceux qui ont contribué à cette convergence. Ainsi, bien que le nœud du gaucher ait été pénalisé initialement en raison de la singularité de ses données, il finira par recevoir davantage de récompenses proportionnellement à sa contribution au modèle final.
C'est précisément cette logique qui motive la conception de FLock. C'est aussi pourquoi nous avons commencé par la recherche académique, publié dans des conférences de haut niveau, avant de lancer FLock : beaucoup de réflexion était nécessaire. Notre équipe n'a d'ailleurs pas du tout pensé à la monétisation au début — nous nous sommes concentrés sur la rédaction d'articles, le codage, les expériences et les simulations. Le fait d'avoir obtenu l'approbation par les pairs (NeurIPS, TAI, Science, etc.) nous a permis de consolider solidement les bases techniques avant de développer le SDK et le testnet.
TechFlow : Pouvez-vous simplement décrire les différents acteurs du réseau, ou de la tokenomie ?
Jiahao :
Les acteurs sont au nombre de trois : Planer, Trainer et Validator. On peut les voir comme une plateforme de missions, similaire à HuggingFace dans le monde traditionnel de l'IA. Le Planer est l'émetteur de la mission : il publie une tâche et offre une incitation aux participants. Le Trainer est le développeur IA ou le détenteur de données qui contribue au modèle et espère une récompense. Le Validator fournit de la puissance de calcul et valide la précision des modèles, garantissant ainsi que le système fonctionne de façon équitable et efficace.
Stratégie commerciale (Go-to-Market)
TechFlow : Comment les contrats intelligents de FLock s'affichent-ils côté frontend ? Par exemple, dans la reconnaissance d'image, quelles sont les étapes ?
Jiahao :
Chaque utilisateur ouvre le site ou notre client, sélectionne ses données locales, puis clique sur « Entraîner » pour démarrer le processus. Pour les utilisateurs grand public, nous offrons une expérience transparente (seamless).
TechFlow : Comment fonctionne la correspondance entre différentes tâches ?
Jiahao :
En tant qu'entraîneur, mes données peuvent correspondre à diverses missions. Par exemple, un hôpital propose un jeu de données sur le sommeil quotidien : je peux choisir d'y participer. C'est un peu comme un marché. En tant que propriétaire de données, j'ai le choix d'adhérer à telle ou telle sous-réseau. Les incitations sur ce marché sont fournies par des entreprises : hôpitaux, banques, DeFi. Elles proposent une récompense (bounty), par exemple 200 K$, pour inciter les participants à rejoindre leur subnet sur FLock.
TechFlow : Votre stratégie commerciale consiste donc à convaincre d'abord les entreprises ?
Jiahao :
Oui, nos utilisateurs payants actuels sont des entreprises ayant signé des contrats. Nous avons déjà livré plusieurs projets. Maintenant, nous souhaitons lancer un Marketplace où davantage d'entreprises pourront publier directement des missions, rendant le service plus orienté grand public (2C), sans passer obligatoirement par un modèle B2B.
TechFlow : Quel est le niveau d'acceptation du Web3 parmi les fournisseurs traditionnels de données ?
Jiahao :
Cela réduit leurs coûts. Hors chaîne (off-chain), un tel processus peut prendre plusieurs mois et traverser de nombreuses validations. Pire encore, pour des essais cliniques internationaux, la situation est critique : presque aucun pays ne permet l'exportation de données médicales. Dans de nombreux cas, ces projets sont tout simplement impossibles.
FLock représente donc une percée pour eux :
Premièrement, les données restent sur place, évitant de multiples régulations.
Deuxièmement, cela permet des choses auparavant impensables, comme un projet multinational entre la Chine, le Japon et la Corée pour un meilleur modèle de prédiction glycémique adapté au métabolisme asiatique.
Au-delà, il y a des perspectives encore plus vastes, comme la télémédecine — autrefois quasi impossible en raison de l'impossibilité d'exporter les données. Avec l'apprentissage fédéré, je peux effectuer une surveillance ici, et obtenir un diagnostic là-bas, sans que les deux parties n'aient accès aux données complètes de l'autre. Pour le patient, cela réduit considérablement les complications — je n'ai plus besoin de voyager dans un pays tiers pour un simple bilan médical. D'après mes observations, le secteur médical est probablement celui qui comprend le mieux l'apprentissage fédéré. Le deuxième secteur le plus averti est la finance, car il a été ardemment démarché par de nombreuses startups technologiques.
Toutefois, nous ne collaborons pas avec la finance traditionnelle, mais directement avec le DeFi, car ils comprennent parfaitement le Web3, ce qui minimise les barrières de compréhension.
Lors du lancement du Marketplace, nous nous concentrerons surdes startups IA plus proches des besoins individuels, comme celles spécialisées dans la simulation vocale. Récemment, une application populaire générant des photos par IA a perdu en popularité à cause d'une clause de confidentialité effrayante : « Tous les droits sur vos photos appartiennent à **** ». Beaucoup d'utilisateurs ont refusé de télécharger 10 photos de leur visage. Pour ces startups de simulation vocale, FLock est un gage de confidentialité rassurant : elles peuvent afficher que la voix reste stockée localement, et que la blockchain prouve qu'elle n'a jamais été envoyée à un tiers, tout en permettant de s'amuser à imiter la voix de Zhao Benshan ou d'autres personnalités.
À terme, j'aimerais que FLock devienne pour la protection de la vie privée ce que CertiK est pour la sécurité blockchain : un standard reconnu pour la formation décentralisée et privée des modèles d'IA.
TechFlow : Depuis combien de temps avez-vous étudié les réseaux P2P avant de juger la solution viable ?
Jiahao :
Environ moins d'un an. Nos articles ont été rapidement publiés, ce qui nous a confirmé que le sujet était prometteur.
Je considère les comités de lecture comme des indicateurs : si vos travaux sont jugés ennuyeux ou non novateurs, la monétisation sera difficile. Mais dès nos premières publications, les retours ont été excellents. Ces retours positifs ont été très encourageants.
Cependant, passer des retours académiques à la monétisation demande encore beaucoup d'efforts : comment convaincre les investisseurs que cela a du sens ? Quel avenir voyez-vous ? C'est un autre défi.
Notre première phase fut celle de R&D. La deuxième phase a suivi avec la sortie de versions test et de bibliothèques open source. En 2023, en plein hiver crypto, nous avons levé six millions de dollars en seed round, menés par Lightspeed Faction (Lightspeed US), spécialisé dans l'IA. Cela nous a donné une grande confiance : même dans les pires conditions de marché, un fonds d'élite nous a accordé sa confiance, ce qui a consolidé nos perspectives à long terme.
Nous sommes maintenant dans la troisième phase : la reconnaissance du marché. Nous allons lancer une plateforme décentralisée d'entraînement, un Marketplace où tous les utilisateurs pourront créer des modèles pour leur communauté. Notre réseau a déjà été réservé par les plus grands validateurs mondiaux.
TechFlow : Aujourd'hui, le potentiel du Web3 est reconnu. De nombreux projets utilisent la blockchain dans des applications réelles, comme vous. Comment augmentez-vous votre visibilité ?
Jiahao :
Nous visons une logique de succès viral, via des applications phares ou répondant à des besoins essentiels. C'est pourquoi nous nous rapprochons tant du monde DeFi : de nombreux besoins ici sont cruciaux mais insatisfaits.
Par exemple, pour le crédit personnel, les données bancaires ne peuvent pas être liées directement. FLock permet de calculer localement un score de crédit, servant de preuve d'identité financière. Bien qu'on n'en soit pas encore au prêt à faible garantie, on peut passer d'une sur-garantie de 150 % à 105 %, améliorant ainsi l'efficacité du marché. Pour beaucoup d'utilisateurs, c'est un besoin vital.
Deuxièmement, le succès viral, comme la simulation vocale. Si elle devient tendance et que les influenceurs partagent leurs créations, d'autres voudront télécharger l'appli.
Ce sont ces deux leviers que nous comptons exploiter pour attirer des utilisateurs.
TechFlow : FLock s'inscrit aussi dans la catégorie DePin. Quelle est la relation entre FLock et les secteurs actuels du calcul décentralisé et du stockage décentralisé ?
Jiahao :
Je pense que la coopération verticale est excellente. Nous sommes une couche d'entraînement, juste une strate. Dans l'écosystème, nous tenons une position similaire à TensorFlow ou PyTorch. Dans l'industrie traditionnelle, nous sommes comparables à une couche intermédiaire d'entraînement. Vous avez toujours besoin d'AWS pour héberger votre modèle ou de S3 pour stocker vos données. Nous nous contentons de coordonner. Quant à la provenance de la puissance de calcul ou aux solutions de stockage, de nombreux acteurs existent déjà.
Je pense que les innovations dans le stockage décentralisé des données sont limitées — le domaine est déjà mature. Notre premier testnet a très bien coopéré avec IPFS. Utiliser le calcul décentralisé permet aux utilisateurs ordinaires de bénéficier de FLock sans difficulté.
Dans une vision puriste, comment utiliser Bitcoin ? Télécharger le grand livre complet sur son ordinateur personnel, puis envoyer une transaction. De même, l'utilisation puriste de FLock consisterait à ouvrir son ordinateur, garder toutes ses données localement sans jamais les confier à un tiers — la solution la plus sûre — puis se connecter au réseau FLock. Mais on ne peut pas exiger que tout le monde possède un bon ordinateur toujours allumé. C'est pourquoi notre collaboration avec le calcul et le stockage décentralisés est cruciale : l'utilisateur peut importer ses données sur un stockage décentralisé, utiliser une puissance de calcul décentralisée, et FLock agit comme intermédiaire pour coordonner les données et les ressources, produire un résultat, et distribuer équitablement les récompenses. Ainsi, l'utilisateur se connecte comme avec MetaMask, clique, et c'est terminé. Il n'a pas besoin d'héberger physiquement ses données.
Pour nous, la collaboration avec les couches inférieures vise à améliorer l'expérience utilisateur.
Digression sur l'IA : GPT, GNN et autres grands modèles
TechFlow : Pendant votre période en banque, avez-vous travaillé sur l'apprentissage fédéré ?
Jiahao :
Pas vraiment. En banque, nous nous concentrons davantage sur le traitement du langage naturel (NLP), comme les réseaux de neurones graphiques (GNN) et les graphes de connaissances. J'ai donc une certaine connaissance du domaine. Quand GPT est devenu populaire, j'ai constaté que l'industrie des graphes de connaissances et des réseaux neuronaux s'est soudainement refroidie. J'encadrais deux doctorants à l'Imperial College : leurs mémoires de thèse ont dû être entièrement réécrits, car on pouvait facilement les remettre en question : « Pourquoi ne pas utiliser directement GPT ? »
TechFlow : GPT traite des données sémantiques, tandis que les graphes traitent davantage de données non sémantiques ?
Jiahao :
On peut le dire ainsi. Mais la force brute produit des miracles. Si GPT peut résoudre le problème, pourquoi proposer un graphe derrière GPT ? En 2022, lors de NeurIPS, j'étais invité à un forum avec Boxing Chen de Huawei Research, Yu Cheng de Microsoft et Marjan de Meta, pour discuter de l'avenir du NLP. J'essayais alors de relancer un peu l'intérêt pour mes graphes de connaissances.
Mais la réponse dominante était : « Si nous disposons de la puissance de calcul maximale, des meilleurs algorithmes et des meilleures données, et que nous pouvons atteindre directement le résultat de bout en bout, pourquoi analyser en profondeur chaque relation dans le réseau ? Le monde est utilitariste, et l'algorithme boîte noire produit effectivement de grands miracles. »
Analyser ces relations coûte cher et donne des résultats lents. Voici un exemple concret : au début des réseaux de neurones, beaucoup s'y opposaient. Les traditionalistes voulaient
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














