

Foresight Ventures : Analyse et réflexion sur les réseaux de calcul décentralisés
TechFlow SélectionTechFlow Sélection
Foresight Ventures : Analyse et réflexion sur les réseaux de calcul décentralisés
Dans le contexte de l'évolution des grands modèles d'IA, les ressources en puissance de calcul deviendront le grand champ de bataille de la prochaine décennie et constitueront également l'élément le plus important de la société humaine future.
Rédaction : Yihan@Foresight Ventures
Résumé
-
Actuellement, l'intégration de l'IA et des cryptomonnaies se concentre principalement sur deux axes majeurs : le calcul distribué décentralisé et le ZKML ; pour le ZKML, vous pouvez consulter un précédent article que j'ai rédigé. Cet article s'appuiera sur une analyse critique du réseau de calcul distribué décentralisé.
-
Dans le contexte de l'évolution des grands modèles d'IA, la puissance de calcul sera le prochain grand champ de bataille de la décennie à venir, et constituera même l'élément le plus crucial de la société humaine future, allant au-delà de simples rivalités commerciales pour devenir une ressource stratégique dans les rapports de force entre grandes nations. À l'avenir, les investissements dans les infrastructures de calcul haute performance et les réserves de puissance de calcul augmenteront exponentiellement.
-
Les réseaux de calcul distribués décentralisés rencontrent leur demande maximale dans l'entraînement des grands modèles d'IA, mais font également face aux défis et goulots d'étranglement technologiques les plus importants. Cela inclut des problèmes complexes tels que la synchronisation des données et l'optimisation du réseau. En outre, la confidentialité et la sécurité des données constituent des facteurs limitants essentiels. Bien que certaines technologies existantes puissent offrir des solutions préliminaires, elles restent inapplicables dans les tâches d'entraînement distribué à grande échelle en raison des coûts élevés en calcul et communication.
-
Les réseaux de calcul distribués décentralisés ont davantage de chances de se concrétiser dans l'inférence des modèles, dont on peut anticiper un espace de croissance substantiel à l’avenir. Toutefois, ils doivent faire face à des obstacles liés à la latence de communication, à la confidentialité des données et à la sécurité des modèles. Comparée à l'entraînement, l'inférence implique une complexité de calcul moindre et moins d'interactions de données, ce qui la rend mieux adaptée à un environnement distribué.
-
À travers les cas des startups Together et Gensyn.ai, nous illustrons sous deux angles — optimisation technique et conception de la couche d'incitation — les orientations générales et approches concrètes des recherches menées autour des réseaux de calcul distribués décentralisés.
Calcul distribué — Entraînement des grands modèles
Lorsque nous discutons de l'application du calcul distribué à l'entraînement, nous nous concentrons généralement sur les grands modèles linguistiques, car l'entraînement de petits modèles ne requiert pas une puissance de calcul importante. Il serait peu rentable de mettre en œuvre une architecture distribuée face aux problèmes liés à la confidentialité des données et à la complexité ingénierie, alors qu'une solution centralisée suffit. En revanche, les grands modèles linguistiques exigent une puissance de calcul colossale. Actuellement, nous sommes au tout début d'une phase explosive : entre 2012 et 2018, la demande de puissance de calcul en IA doublait environ tous les quatre mois. Aujourd'hui, cette demande est particulièrement concentrée, et l'on peut anticiper une forte croissance sur les cinq à huit prochaines années.
Face à d'immenses opportunités, il est essentiel de bien identifier les difficultés. Tous reconnaissent le potentiel du marché, mais où se situent précisément les défis ? Ceux qui sauront cibler ces problèmes plutôt que de s'y engager aveuglément seront les véritables acteurs remarquables de ce secteur.
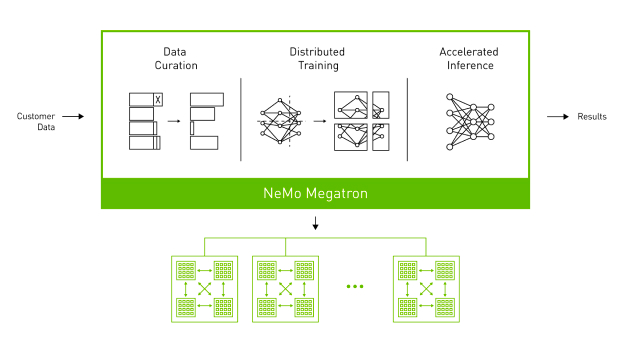
(NVIDIA NeMo Megatron Framework)
1. Flux global d'entraînement
Prenons l'exemple de l'entraînement d'un modèle de 175 milliards de paramètres. Étant donné la taille du modèle, un entraînement parallèle sur plusieurs GPU est nécessaire. Supposons un datacenter centralisé disposant de 100 GPU, chacun ayant 32 Go de mémoire.
-
Préparation des données : Une base de données très volumineuse est requise, comprenant divers contenus tels que des informations internet, des actualités ou des livres. Avant l'entraînement, ces données doivent être prétraitées : nettoyage du texte, tokenisation (segmentation), construction du vocabulaire, etc.
-
Segmentation des données : Les données traitées sont divisées en plusieurs lots (batches) afin d'être traitées en parallèle sur plusieurs GPU. Si la taille du lot est fixée à 512, chaque lot contient 512 séquences textuelles. L'ensemble du jeu de données est ainsi découpé en une file de lots.
-
Transmission inter-appareils : Au début de chaque étape d'entraînement, le CPU extrait un lot depuis la file, puis transmet ces données via le bus PCIe vers les GPU. Si chaque séquence contient en moyenne 1024 tokens, la taille de chaque lot est approximativement de 512 * 1024 * 4 octets = 2 Mo (chaque token étant représenté par un nombre flottant simple précision de 4 octets). Cette transmission prend généralement quelques millisecondes.
-
Entraînement parallèle : Chaque GPU commence alors les calculs de propagation avant (forward pass) et arrière (backward pass), produisant les gradients de chaque paramètre. Comme la taille du modèle dépasse la mémoire d’un seul GPU, une technique de parallélisme de modèle est utilisée, répartissant les paramètres sur plusieurs GPU.
-
Agrégation des gradients et mise à jour des paramètres : Après la rétropropagation, chaque GPU possède une partie des gradients. Ces gradients doivent ensuite être agrégés entre tous les GPU afin d'obtenir le gradient global. Cette opération nécessite une transmission réseau. Par exemple, avec un réseau à 25 Gbps, le transfert de 700 Go de données (soit environ 700 Go pour 175 milliards de paramètres en simple précision) prend environ 224 secondes. Chaque GPU met ensuite à jour ses propres paramètres selon le gradient global.
-
Synchronisation : Après la mise à jour des paramètres, tous les GPU doivent se synchroniser pour garantir qu'ils utilisent des paramètres modèles cohérents lors de l'étape suivante. Ceci exige également une transmission réseau.
-
Répétition des étapes : Ce processus est répété jusqu’à ce que tous les lots aient été traités ou qu’un nombre prédéfini d’époques (epochs) soit atteint.
Ce processus implique de nombreuses transmissions de données et synchronisations, pouvant devenir un goulot d’étranglement affectant l’efficacité de l’entraînement. L’optimisation de la bande passante et de la latence réseau, ainsi que l’utilisation de stratégies efficaces de parallélisme et de synchronisation, sont donc cruciales pour l’entraînement de modèles à grande échelle.
2. Le goulot d’étranglement lié aux communications :
Il convient de noter que ce goulot de communication constitue précisément la raison pour laquelle les réseaux de calcul distribués décentralisés ne peuvent actuellement pas entraîner de grands modèles linguistiques.
Les différents nœuds doivent fréquemment échanger des informations pour coopérer, ce qui génère un coût de communication. Pour les grands modèles linguistiques, ce problème est particulièrement aigu en raison du nombre massif de paramètres. Ce coût de communication se manifeste de plusieurs façons :
-
Transmission des données : Pendant l'entraînement, les nœuds doivent fréquemment échanger des informations sur les paramètres du modèle et les gradients. Cela implique le transfert de volumes importants de données sur le réseau, consommant beaucoup de bande passante. Si les conditions réseau sont mauvaises ou si les distances entre les nœuds sont importantes, la latence de transmission augmente fortement, aggravant ainsi le coût de communication.
-
Problèmes de synchronisation : Les nœuds doivent collaborer pour assurer un entraînement correct, ce qui implique des opérations de synchronisation fréquentes, comme la mise à jour des paramètres du modèle ou le calcul du gradient global. Ces opérations nécessitent la transmission de grandes quantités de données sur le réseau et attendent que tous les nœuds aient terminé, entraînant ainsi un coût élevé en communication et des temps d’attente prolongés.
-
Agrégation et mise à jour des gradients : Pendant l'entraînement, chaque nœud calcule ses propres gradients et les envoie aux autres nœuds pour agrégation et mise à jour. Cela nécessite la transmission de grandes quantités de données de gradients sur le réseau et attend que tous les nœuds aient terminé leurs calculs et transferts, contribuant largement au coût de communication.
-
Consistance des données : Il faut garantir que les paramètres du modèle soient identiques sur tous les nœuds. Cela implique des vérifications et synchronisations fréquentes entre les nœuds, générant un coût de communication élevé.
Bien que certaines méthodes permettent de réduire ce coût — comme la compression des paramètres et gradients ou l’utilisation de stratégies de parallélisme efficaces — celles-ci peuvent introduire une charge de calcul supplémentaire ou nuire à la qualité de l’entraînement. De plus, elles ne parviennent pas à résoudre complètement le problème, surtout lorsque les conditions réseau sont médiocres ou que les distances entre nœuds sont importantes.
Un exemple concret :
Réseau de calcul distribué décentralisé
Le modèle GPT-3 comporte 175 milliards de paramètres. En utilisant des nombres flottants simple précision (4 octets par paramètre), cela représente environ 700 Go de mémoire. Dans un entraînement distribué, ces paramètres doivent être fréquemment transférés et mis à jour entre les nœuds de calcul.
Supposons 100 nœuds de calcul, chacun devant mettre à jour tous les paramètres à chaque étape. Chaque étape nécessiterait alors un transfert d’environ 70 To (700 Go × 100) de données. Avec une hypothèse très optimiste d’une seconde par étape, cela représenterait un débit de 70 To/s. Une telle exigence dépasse largement les capacités de la plupart des réseaux, posant un problème de faisabilité fondamental.
En réalité, en raison des latences de communication et de la congestion du réseau, le temps de transfert pourrait largement dépasser la seconde. Les nœuds passeraient alors beaucoup de temps à attendre les données au lieu de calculer, ce qui réduirait drastiquement l’efficacité. Cette baisse n’est pas simplement une question de délai, mais une différence entre faisabilité et infaisabilité, rendant l’ensemble du processus d’entraînement impraticable.
Datacenter centralisé
Même dans un datacenter centralisé, l'entraînement de grands modèles nécessite des optimisations intensives de communication.
Dans un environnement centralisé, les équipements de calcul haute performance sont regroupés en cluster et reliés par un réseau rapide pour partager les tâches. Pourtant, même avec un tel réseau, le coût de communication reste un goulot d’étranglement, car les paramètres et gradients du modèle doivent être constamment transférés entre les dispositifs.
Comme mentionné précédemment, avec 100 nœuds de calcul et une bande passante réseau de 25 Gbps par serveur, le transfert de 700 Go de données par étape prendrait environ 224 secondes. Grâce aux avantages d’un datacenter centralisé, les développeurs peuvent optimiser la topologie réseau et utiliser des techniques comme le parallélisme de modèle pour réduire considérablement ce temps.
En revanche, dans un environnement distribué, avec 100 nœuds répartis mondialement et une bande passante moyenne de 1 Gbps par nœud, le transfert des mêmes 700 Go prendrait environ 5600 secondes — bien plus longtemps qu’en centralisé. La latence et la congestion réseau pourraient encore rallonger ce délai.
Par rapport à un réseau de calcul distribué, l’optimisation du coût de communication dans un datacenter centralisé est relativement aisée. En effet, les équipements y sont connectés à un même réseau haut débit, offrant une bande passante élevée et une latence faible. Dans un réseau décentralisé, les nœuds étant géographiquement dispersés, les conditions réseau sont souvent médiocres, aggravant ainsi le problème du coût de communication.
OpenAI a utilisé un cadre de parallélisme appelé « Megatron » pendant l'entraînement de GPT-3 pour atténuer ce coût. Megatron divise les paramètres du modèle et les traite en parallèle sur plusieurs GPU, chaque appareil ne stockant et mettant à jour qu’une partie des paramètres, réduisant ainsi le volume de données à transférer et le coût de communication. En parallèle, un réseau interconnecté haut débit a été utilisé, et la topologie réseau a été optimisée pour raccourcir les chemins de communication.
(Données utilisées pour entraîner les modèles LLM)
3. Pourquoi les réseaux de calcul distribués ne peuvent-ils pas réaliser ces optimisations ?
C'est techniquement possible, mais comparé à un datacenter centralisé, l'efficacité de ces optimisations est fortement limitée.
1. Optimisation de la topologie réseau : Dans un datacenter centralisé, on contrôle directement le matériel et la disposition réseau, permettant une conception et optimisation libre de la topologie. Dans un environnement distribué, les nœuds sont géographiquement dispersés — l’un en Chine, l’autre aux États-Unis — rendant impossible le contrôle direct des connexions entre eux. Bien que des logiciels puissent optimiser les chemins de transmission, cela reste moins efficace que l’optimisation matérielle. De plus, les variations géographiques induisent des différences importantes de latence et de bande passante, limitant davantage l’efficacité de l’optimisation.
2. Parallélisme de modèle : Le parallélisme de modèle consiste à répartir les paramètres du modèle sur plusieurs nœuds de calcul pour accélérer l'entraînement. Toutefois, cette méthode nécessite des échanges fréquents de données entre nœuds, exigeant une bande passante élevée et une faible latence. Dans un datacenter centralisé, ces conditions sont remplies, rendant le parallélisme très efficace. En revanche, dans un environnement distribué aux performances réseau médiocres, cette approche est fortement limitée.
4. Défis liés à la sécurité et à la confidentialité des données
Presque tous les aspects impliquant le traitement et le transfert de données peuvent compromettre la sécurité et la confidentialité :
1. Répartition des données : Les données d'entraînement doivent être distribuées aux différents nœuds participants. À ce stade, les données risquent d’être mal utilisées ou divulguées sur les nœuds distribués.
2. Entraînement du modèle : Pendant l'entraînement, chaque nœud utilise ses données attribuées pour effectuer des calculs, puis renvoie des mises à jour de paramètres ou des gradients. Si le processus de calcul est intercepté ou les résultats analysés malveillamment, des fuites de données peuvent survenir.
3. Agrégation des paramètres et gradients : Les sorties des différents nœuds doivent être agrégées pour mettre à jour le modèle global. Cette communication d’agrégation peut elle-même révéler des informations sur les données d'entraînement.
Quelles solutions existent pour la confidentialité des données ?
-
Calcul sécurisé multipartite (SMC) : Le SMC a déjà été appliqué avec succès à certaines tâches spécifiques et à petite échelle. Mais pour des tâches d'entraînement distribué à grande échelle, son coût élevé en calcul et communication limite encore son utilisation généralisée.
-
Confidentialité différentielle (DP) : Appliquée à certaines tâches de collecte et d’analyse de données (comme les statistiques utilisateur de Chrome), la DP affecte toutefois la précision du modèle dans les tâches profondes d’apprentissage. Concevoir des mécanismes appropriés d’ajout de bruit reste également un défi.
-
Apprentissage fédéré (FL) : Utilisé pour l'entraînement de modèles sur des appareils périphériques (par exemple, la prédiction de mots pour le clavier Android), le FL fait face à des problèmes de coût de communication élevé et de coordination complexe dans des tâches plus vastes.
-
Chiffrement homomorphe : Déjà utilisé avec succès pour des tâches à faible complexité, il reste peu applicable à grande échelle en raison de son coût computationnel élevé.
Bilan
Chacune de ces méthodes présente des cas d’usage et des limitations. Aucune ne permet actuellement de résoudre entièrement le problème de confidentialité des données dans l’entraînement de grands modèles sur un réseau de calcul distribué.
L’espoir placé dans le ZK peut-il résoudre la confidentialité des données lors de l'entraînement de grands modèles ?
Théoriquement, les preuves à connaissance nulle (ZKP) peuvent garantir la confidentialité des données dans un calcul distribué : un nœud peut prouver qu’il a bien effectué un calcul sans révéler les données d’entrée ni de sortie.
Mais en pratique, l'utilisation des ZKP pour l'entraînement de grands modèles sur un réseau de calcul distribué fait face à plusieurs goulots d’étranglement :
-
Augmentation des coûts de calcul et communication : Générer et vérifier une preuve à connaissance nulle nécessite une puissance de calcul considérable. De plus, la preuve elle-même doit être transmise, ce qui alourdit la communication. Dans le cas de l'entraînement de grands modèles, ces coûts deviennent particulièrement significatifs. Par exemple, si une preuve doit être générée pour chaque mini-lot, le temps et le coût totaux d’entraînement augmentent fortement.
-
Complexité du protocole ZK : Concevoir et implémenter un protocole ZKP adapté à l'entraînement de grands modèles est extrêmement complexe. Il doit gérer de grandes quantités de données et des calculs sophistiqués, tout en traitant les erreurs éventuelles.
-
Compatibilité matérielle et logicielle : L'utilisation des ZKP nécessite un support spécifique, qui peut ne pas être disponible sur tous les dispositifs du réseau distribué.
Bilan
Appliquer les ZKP à l'entraînement de grands modèles sur un réseau de calcul distribué à grande échelle nécessitera encore plusieurs années de recherche et développement, ainsi qu’un engagement accru de la communauté académique sur ce sujet.
Calcul distribué — Inférence de modèles
Un autre domaine important pour le calcul distribué est l’inférence de modèles. Selon notre vision de l’évolution des grands modèles, la demande d’entraînement atteindra un pic puis diminuera progressivement avec la maturité des grands modèles, tandis que la demande d’inférence augmentera exponentiellement avec la montée en puissance des grands modèles et de l’AIGC.
Comparées aux tâches d’entraînement, les tâches d’inférence présentent généralement une complexité de calcul moindre et moins d’interactions de données, ce qui les rend mieux adaptées à un environnement distribué.
(Accélérer l'inférence LLM avec NVIDIA Triton)
1. Défis
Latence de communication :
Dans un environnement distribué, la communication entre nœuds est incontournable. Dans un réseau de calcul décentralisé, les nœuds pouvant être répartis mondialement, la latence réseau devient un problème, surtout pour les tâches d’inférence nécessitant une réponse en temps réel.
Déploiement et mise à jour du modèle :
Le modèle doit être déployé sur chaque nœud. En cas de mise à jour, chaque nœud doit être mis à jour, ce qui consomme beaucoup de bande passante et de temps.
Confidentialité des données :
Bien que l’inférence nécessite généralement seulement les données d’entrée et le modèle, sans retour de données intermédiaires ou de paramètres, les données d’entrée peuvent toujours contenir des informations sensibles, comme des données personnelles.
Sécurité du modèle :
Dans un réseau décentralisé, le modèle est déployé sur des nœuds non approuvés, ce qui expose à des risques de fuite du modèle, portant atteinte aux droits de propriété et entraînant des abus. Des problèmes de sécurité et de confidentialité peuvent aussi survenir si un nœud analyse le comportement du modèle pour en déduire des informations sensibles.
Contrôle de qualité :
Les nœuds d’un réseau de calcul distribué décentralisé peuvent avoir des capacités de calcul et des ressources différentes, ce qui rend difficile la garantie de performance et de qualité uniformes pour les tâches d’inférence.
2. Faisabilité
Complexité de calcul :
Durant l'entraînement, le modèle subit de nombreuses itérations, impliquant à chaque fois des propagations avant et arrière, y compris le calcul des fonctions d’activation, de la fonction de perte, des gradients et la mise à jour des poids. La complexité de calcul est donc élevée.
Durant l'inférence, seule une propagation avant est nécessaire pour obtenir le résultat. Par exemple, dans GPT-3, le texte d’entrée est converti en vecteur, puis propagé à travers les couches du modèle (généralement des couches Transformer), produisant une distribution de probabilités à partir de laquelle le mot suivant est généré. Dans les GANs, un vecteur de bruit est transformé en image. Ces opérations ne nécessitent pas de calcul de gradients ni de mise à jour de paramètres, rendant la complexité de calcul bien plus faible.
Interopérabilité des données :
Durant l'inférence, le modèle traite généralement une entrée isolée, contrairement aux grands lots d’entraînement. Chaque résultat d’inférence dépend uniquement de l’entrée courante, sans lien avec d’autres entrées ou sorties, évitant ainsi de nombreux échanges de données et réduisant la pression de communication.
Prenons l’exemple d’un modèle génératif d’images : avec un GAN, il suffit d’entrer un vecteur de bruit pour générer une image correspondante. Chaque entrée produit une sortie indépendante, sans dépendance entre elles, donc aucune interaction de données n’est requise.
Pour GPT-3, la génération du mot suivant dépend uniquement du texte d’entrée et de l’état du modèle, sans interaction avec d’autres entrées ou sorties, ce qui réduit aussi les besoins en interopérabilité des données.
Bilan
Que ce soient les grands modèles linguistiques ou les modèles génératifs d’images, les tâches d’inférence ont une complexité de calcul et une interdépendance de données faibles, les rendant particulièrement adaptées aux réseaux de calcul distribués décentralisés. C’est d’ailleurs la direction vers laquelle se tournent aujourd’hui la majorité des projets.
Projets
Les réseaux de calcul distribués décentralisés présentent des seuils techniques élevés et nécessitent un soutien matériel conséquent, ce qui explique qu’on observe encore peu d’initiatives. Prenons les exemples de Together et Gensyn.ai :
1. Together

(RedPajama de Together)
Together est une entreprise axée sur l’open source des grands modèles, visant des solutions de calcul IA décentralisées, permettant à toute personne, partout dans le monde, d’accéder et d’utiliser l’IA. Together vient de lever 20 millions USD en financement de départ, conduit par Lux Capital.
Fondée par Chris, Percy et Ce, l’entreprise a vu le jour face à la nécessité de clusters GPU haut de gamme et de coûts élevés pour l’entraînement des grands modèles, ressources et compétences aujourd’hui concentrées entre quelques grandes entreprises.
De mon point de vue, un plan entrepreneurial raisonnable pour le calcul distribué serait :
Étape 1. Modèle open source
Pour exécuter l’inférence d’un modèle sur un réseau de calcul distribué décentralisé, il faut que les nœuds puissent accéder facilement au modèle. Autrement dit, le modèle utilisé doit être open source (si une licence restrictive s’applique, cela ajoute complexité et coût). Un modèle comme ChatGPT, non open source, n’est donc pas adapté à un tel réseau.
On peut donc supposer qu’un avantage concurrentiel caché d’une entreprise fournissant un réseau de calcul décentralisé réside dans sa capacité à développer et maintenir de puissants modèles. Créer et publier un solide modèle de base en open source réduit la dépendance aux modèles tiers et résout un problème fondamental du réseau. Cela démontre aussi plus facilement que le réseau peut effectivement entraîner et exécuter des grands modèles.
C’est exactement ce que fait Together. Le projet RedPajama, basé sur LLaMA et lancé récemment par Together, Ontocord.ai, ETH DS 3 Lab, Stanford CRFM et Hazy Research, vise à développer une série de grands modèles linguistiques entièrement open source.
Étape 2. Mise en œuvre du calcul distribué pour l’inférence
Comme expliqué précédemment, l’inférence, avec sa faible complexité et ses interactions de données limitées, est bien plus adaptée à un environnement distribué décentralisé que l’entraînement.
Sur la base de son modèle open source, l’équipe de Together a apporté plusieurs améliorations au modèle RedPajama-INCITE-3B, notamment l’utilisation de LoRA pour un ajustement fin à faible coût, permettant une exécution fluide sur processeur (notamment sur MacBook Pro équipé de processeur M2 Pro). Bien que de taille modeste, ce modèle surpasse d'autres modèles similaires en performance et est déjà utilisé dans des applications pratiques, notamment juridiques et sociales.
Étape 3. Mise en œuvre du calcul distribué pour l’entraînement
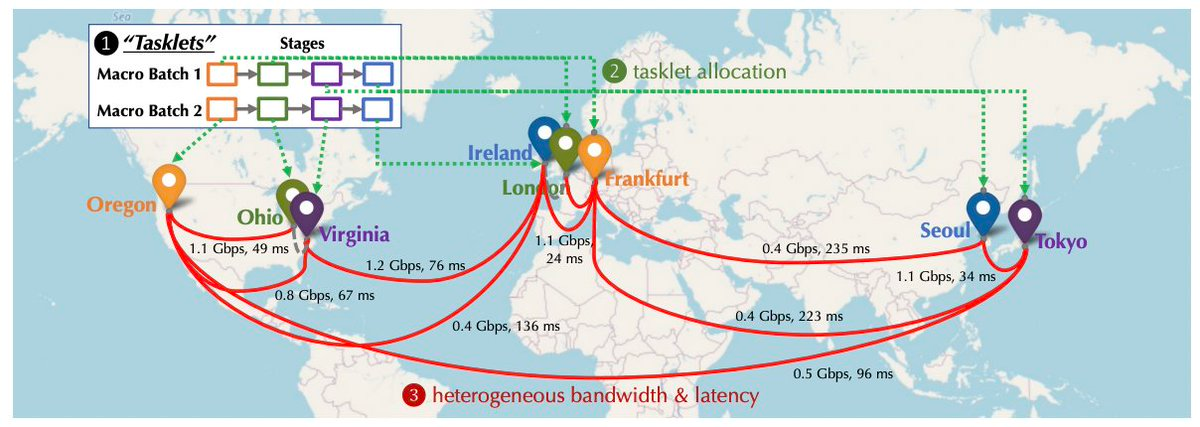
(Schéma du réseau de calcul dans « Overcoming Communication Bottlenecks for Decentralized Training »)
À moyen et long terme, malgré les défis techniques, répondre à la demande de calcul pour l’entraînement des grands modèles d’IA reste l’objectif le plus attractif. Dès sa création, Together a commencé à travailler sur la levée des goulots d’étranglement de communication dans l’entraînement décentralisé. Elle a publié un article à NeurIPS 2022 intitulé « Overcoming Communication Bottlenecks for Decentralized Training ». On peut en extraire les directions suivantes :
Optimisation de l’ordonnancement
Dans un environnement décentralisé, les connexions entre nœuds varient en latence et bande passante. Il est donc crucial d’affecter les tâches nécessitant beaucoup de communication aux nœuds dotés de liaisons rapides. Together modélise le coût de différentes stratégies d’ordonnancement pour mieux les optimiser, minimisant ainsi le coût de communication et maximisant le débit d’entraînement. L’équipe a observé que même avec un réseau 100 fois plus lent, le débit d’entraînement bout-en-bout n’était que 1,7 à 2,3 fois plus lent. L’optimisation de l’ordonnancement permet donc de combler efficacement l’écart entre réseaux distribués et clusters centralisés.
Optimisation par compression de communication
Together propose de compresser les activations avant et les gradients arrière, introduisant l’algorithme AQ-SGD, qui garantit rigoureusement la convergence de la descente de gradient stochastique. AQ-SGD permet d’ajuster finement de grands modèles de base sur des réseaux lents (par exemple 500 Mbps), avec seulement 31 % de retard par rapport à un entraînement sans compression sur un réseau centralisé rapide (10 Gbps). AQ-SGD peut aussi être combiné avec des techniques avancées de compression de gradients (comme QuantizedAdam), offrant un gain de 10 % en vitesse bout-en-bout.
Bilan du projet
L’équipe de Together est exceptionnellement complète, rassemblant des experts académiques de haut niveau dans les domaines des grands modèles, du cloud computing et de l’optimisation matérielle. Son feuille de route reflète une stratégie patiente et à long terme : du développement de grands modèles open source, en passant par les tests d’inférence sur du calcul inutilisé (comme des Mac), jusqu’à la préparation de l’entraînement décentralisé. Cela sent vraiment la réussite après une longue préparation :)
Toutefois, Together n’a pas encore montré de résultats marquants sur la couche d’incitation, un aspect que je juge tout aussi crucial que le développement technique pour assurer la pérennité d’un réseau de calcul décentralisé.
2. Gensyn.ai

(Gensyn.ai)
À travers la stratégie technique de Together, on comprend mieux le processus de mise en œuvre du calcul décentralisé pour l’entraînement et l’inférence, ainsi que les priorités de recherche associées.
Un autre aspect essentiel, souvent négligé, est la conception de la couche d’incitation / algorithme de consensus. Un bon réseau doit notamment :
1. Offrir des revenus suffisamment attractifs ;
2. Garantir que chaque mineur reçoive une rémunération équitable, avec prévention des tricheries et principe « plus tu travailles, plus tu gagnes » ;
3. Assurer une répartition et une planification raisonnables des tâches entre les nœuds, évitant à la fois les nœuds inactifs et la surcharge de certains nœuds ;
4. Que l’algorithme d’incitation soit simple et efficace, sans surcharger le système ni créer de latence excessive.
Voyons comment Gensyn.ai procède :
Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














