

État actuel et avenir du stockage de bases de données décentralisées Web3
TechFlow SélectionTechFlow Sélection
État actuel et avenir du stockage de bases de données décentralisées Web3
Pourquoi a-t-on besoin d'une base de données centralisée ? Comment évaluer la qualité d'une base de données décentralisée ?
Rédaction : Maggie
Pourquoi a-t-on besoin de bases de données décentralisées ?
Les applications Web2 disposent de deux méthodes fondamentales pour stocker les données : le système de fichiers (File System) et la base de données (Database). En raison du manque de produits de base de données dans Web3, la plupart des DApp, outre le stockage d'une petite quantité de données critiques dans des contrats intelligents coûteux, utilisent encore des bases de données centralisées pour stocker les données structurées. Avec l'émergence progressive de systèmes de fichiers décentralisés comme IPFS, utilisés pour stocker les données NFT des applications Web3, ces systèmes gagnent en reconnaissance et acceptation au sein de l'écosystème Web3. Parallèlement, la technologie des bases de données décentralisées a connu une nouvelle itération, donnant naissance à plusieurs nouveaux produits.
Par rapport aux bases de données centralisées traditionnelles, les bases de données décentralisées offrent des avantages uniques : elles réduisent le risque de panne unique pour les projets Web3 et permettent une décentralisation complète des DApps.
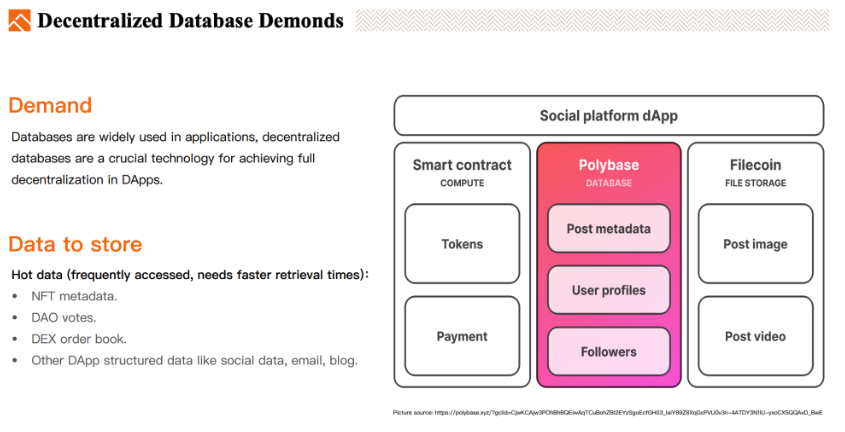
Les bases de données décentralisées conviennent particulièrement au stockage des données chaudes à accès fréquent, notamment les données non financières des DApp, telles que :
-
Les métadonnées NFT
-
Les données de vote DAO
-
Le carnet d'ordres des DEX
-
Les données sociales décentralisées, les blogs, les courriels.
-
Les données complexes nécessitant une base de données relationnelle pour les DApp.
Quels types de systèmes de stockage de bases de données décentralisées existent-il ?
Ces deux dernières années, de nombreux projets de bases de données décentralisées sont apparus, dont certains, innovants, ont attiré une attention particulière.
-
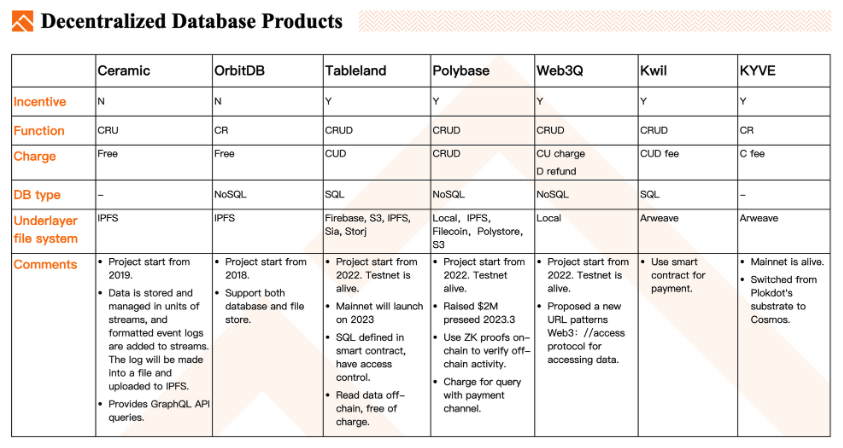
Ceramic : Lancé en 2019, Ceramic stocke et gère les données sous forme de flux, ajoutant des journaux d'événements formatés à ces flux. Ces journaux sont transformés en fichiers puis envoyés sur IPFS. L'accès aux données se fait via une API GraphQL. Sans modèle incitatif similaire à celui d'IPFS, Ceramic prend en charge la création, la lecture et la mise à jour des données (CRU).
-
OrbitDB : Projet antérieur à Ceramic, OrbitDB utilise également le système de fichiers IPFS pour le stockage. Il prend en charge le stockage NoSQL ainsi que celui des fichiers.
-
Tableland : Lancé en 2022, ce projet est actuellement en phase de test public. La version finale devrait être publiée en 2023. Le stockage des données s'appuie sur des contrats intelligents définissant les instructions SQL et les permissions d'utilisation. La lecture des données s'effectue hors chaîne, sans frais. À ce jour, le contrat est déployé sur ETH et sur des solutions L2 comme OP.
-
Polybase : Actuellement disponible sur son réseau de test, il s'agit d'une base de données NoSQL prenant en charge les opérations CRUD, chacune entraînant des frais. Polybase supporte divers systèmes de fichiers pour le stockage, y compris le disque local, IPFS, Filecoin, Polystore, voire AWS S3. Il utilise aussi des canaux de paiement pour les requêtes, réduisant ainsi la fréquence des transactions sur chaîne et évitant les retards liés au paiement.
-
Web3Q : Lancé en 2022, le testnet est déjà opérationnel. Il propose un nouveau mode d’URL, « Web//access protocol », pour accéder aux données. Son modèle économique est original : la suppression de données permet un remboursement partiel.
-
Kwil : Système de base de données SQL basé sur Arweave, utilisant des contrats intelligents pour les paiements.
-
KYVE : Système de base de données fondé sur Arweave.
Du point de vue technique
-
Les bases SQL et NoSQL peuvent toutes deux servir de bases de données. SQL est plus mature et efficace, tandis que NoSQL est plus riche et flexible. La structure des données SQL exige une forte cohérence et offre une meilleure capacité de jointure, ce qui la rend mature et performante. Le format clé-valeur (KV) de NoSQL correspond mieux au modèle de conception d'Ethereum, prend en charge davantage de types de données et offre souplesse et extensibilité.
-
Sur le plan fonctionnel, prendre en charge CRUD est idéal, mais intégrer les opérations Update et Delete (UD) ajoute de la complexité au système. Si le système repose sur un stockage local, il pourrait ne pas permettre l'interrogation des valeurs historiques. En revanche, avec IPFS ou Arweave, la base doit être append-only ; sinon, chaque donnée ayant plusieurs versions, le coût de stockage doublerait.
-
Deux choix s'offrent pour le système de fichiers sous-jacent :
-
Stocker les fichiers localement est plus souple, permet une logique de recherche personnalisée, une efficacité accrue, tout en évitant les inconvénients et la complexité liés à l'utilisation de systèmes de fichiers décentralisés comme Arweave. Par exemple : un utilisateur paie un mineur de base de données en TokenA, qui doit ensuite payer en jeton Arweave pour stocker les données — cette superposition de deux couches réseau complique le système.
-
Stockage des fichiers de base de données dans des systèmes décentralisés tels qu’IPFS ou Arweave ;
-
Stockage local sur les nœuds ou sur le cloud S3.
-
-
Comme pour le stockage décentralisé, la rapidité de récupération des données, le modèle d'incitation et l'économie des jetons, ainsi que les algorithmes garantissant la disponibilité des données, sont des facteurs clés déterminant l'adoption massive d'un protocole.
-
Un bon modèle d'incitation et un design équilibré des jetons encouragent non seulement la participation des nœuds, mais aussi leur comportement correct : fournir une fonction de recherche efficace plutôt que simplement stocker des données pour percevoir une récompense.
-
L'algorithme de garantie de disponibilité des données vérifie périodiquement que les nœuds conservent bien les données, en exigeant des preuves de disponibilité. Cette preuve est liée aux incitations pour prévenir toute perte de données.
-
La rapidité de récupération des données affecte directement l'expérience utilisateur et est cruciale pour la commodité et la fluidité d'utilisation des DApps.
-
Conclusion
-
Le domaine des bases de données décentralisées suscite un vif intérêt et répond à un besoin urgent, mais aucun produit n'est encore largement adopté à ce jour.
-
La maturité technologique des bases de données décentralisées reste inférieure à celle des systèmes de stockage de fichiers décentralisés, car ces bases reposent précisément sur les systèmes de fichiers distribués. De nombreux projets ont été lancés en 2022.
-
L'amélioration de la vitesse de récupération des données, des modèles incitatifs et économiques des jetons, ainsi que des algorithmes garantissant la disponibilité des données, sont des facteurs décisifs pour l'adoption généralisée d’un protocole. L'accent sera mis sur la réduction du temps de récupération, essentiel pour la facilité d'utilisation et la fluidité des DApps.

Bienvenue dans la communauté officielle TechFlow
Groupe Telegram :https://t.me/TechFlowDaily
Compte Twitter officiel :https://x.com/TechFlowPost
Compte Twitter anglais :https://x.com/BlockFlow_News














