

Interview with FLock.io CEO: Why Can't Google Do True Federated Learning, but Blockchain Can?
TechFlow Selected TechFlow Selected
Interview with FLock.io CEO: Why Can't Google Do True Federated Learning, but Blockchain Can?
The world is utilitarian, and the algorithm is indeed this black-box algorithm; the outcome has truly produced a significant miracle.
Author: Sunny, TechFlow
Guest: Jiahao Sun, FLock
“Decentralized machine learning is gradually becoming less of a slogan and more of a viable engineering solution.”
– Jiahao Sun, CEO of FLock.io
Decentralized artificial intelligence (AI) is not a novel concept, but it is experiencing a resurgence due to the rise of cryptocurrency, offering potential for democratizing AI. However, for those unfamiliar with the field, the idea of democratized AI may seem vague.
Blockchain acts as a modern network backend that enables coordination and crowdsourcing of labor and resources.
AI broadly covers training and inference for prediction, relying on computing power, models, and data. Currently, control over these elements often lies in the hands of a few major tech companies. While widespread use is generally believed to be benign, there are no verifiable guarantees—necessitating a new approach to enable broader participation in AI development.
Google previously experimented with federated learning, where user devices locally contribute data and computational power, which are then aggregated into a global model. However, this model still maintains central control.
Blockchain provides a solution by enabling a private economic system where everyone can participate in providing data, computing power, and models through token economics and cryptocurrencies.
FLock (blockchain-based federated learning) introduces true federated learning via smart contracts and token economics, ensuring broader participation. Today, we welcome the CEO of FLock to discuss the concept of democratic AI and its relevance in fields such as global health—even recognizing that federated learning holds value beyond purely decentralized arguments.
From Traditional Finance AI Director to Smart Contract-Based Federated Learning
TechFlow: First, please introduce yourself briefly, and tell us what FLock—or decentralized federated learning—is?
Jiahao:
I spent ten years in the traditional Web2 fintech space. Right after graduation, I joined the Entrepreneur First incubator, where I launched my first startup—an AI-powered credit scoring system. Shortly after, I was headhunted by a top-tier financial institution to serve as Innovation Lead, eventually rising to become their Global AI Director over eight years. So, I’ve been deeply involved in AI research and applications throughout my career.
My interest in the Web3 industry began during the ICO spring of 2017. Seeing teams seemingly succeed with just an idea struck me as fascinating. However, the market at that time was clearly immature—or using today’s terms, felt too “shitcoin-y”—and lacked sophistication, so I didn’t consider seriously entering the space, though I found it intriguing to follow.
During the pandemic, time seemed to slow down. With remote work becoming the norm across Europe and North America, people suddenly had more free time. This extra time could be spent gaming all day or doing something meaningful. After a year of gaming, I realized it was too much of a waste, so I decided to pursue something impactful. Looking back at late 2021, despite being deep in a crypto bear market, I noticed many compelling projects emerging—teams with strong Web2 backgrounds making impressive strides in Web3. That inspired me and sparked my fascination with Web3’s development and truly meaningful technologies and narratives.
What ultimately convinced me to enter Web3 was a research paper our team won a top-tier conference award for—a deep exploration and reflection on the true essence of decentralized machine learning by our founding and research team. This marked the first public appearance of FLock (as a technical term: Federated Learning on the Blockchain), backed by peer review from leading academic institutions. This gave us tremendous confidence and support to fully launch the FLock project.
Paper link: https://scholar.google.com/citations?user=s0eOtD8AAAAJ&hl=en
Federated learning or decentralized machine learning has always existed within the industry.
For example, NVIDIA and AWS have invested heavily in distributed computing and distributed machine learning. But there's always one fundamental issue: suppose AWS claims, "All my cloud platforms and resources are decentralized—you own your own cloud platform." You wouldn't believe that, because you're still purchasing computing resources through AWS, which retains intermediary control and ultimate authority. You don’t truly own your AWS instance—you’re merely renting it. Similarly, users lack ownership of their data.
On the topic of privacy, Google introduced the concept of federated learning in 2017.
Federated learning is essentially a machine learning framework where computation is distributed across individual nodes, allowing data to remain local. Each participant performs local computation, and only the results are aggregated to form a final comprehensive model. This model reflects insights trained on all data while preventing raw data from being uploaded to any third-party server.
This entire logic constitutes federated learning. When Google first proposed it, they applied the concept to keyboard prediction. Many early Pixel Phone users experienced federated learning firsthand—when typing with a Google phone, the system predicts the next word. This was federated learning’s earliest real-world application.
But as I mentioned earlier, Google controls the entire training process and could potentially act maliciously—they have access to all source code and original data—and cannot prove they haven’t seen it. A notable incident occurred when a Chinese keyboard app claimed to use federated learning to protect user privacy, but was later discovered to be sending all user input data directly back to centralized servers, completely bypassing federated learning.
These recent high-profile incidents have led the tech community to question: “If one entity controls all these resources, can we trust them not to act maliciously?” And even if they claim they won’t, should we believe them? Clearly, others don’t—if Apple and Google trusted each other, they would already have collaborated on a joint keyboard prediction model.
This is why we integrate blockchain and smart contract mechanisms into the traditional federated learning framework—eliminating the need for Google or any central coordinator. Each of us is an independent individual with our own node, computing only our portion. Smart contracts determine which uploaded gradients are valid and should be aggregated—all managed through on-chain consensus. This was the original research idea behind FLock.
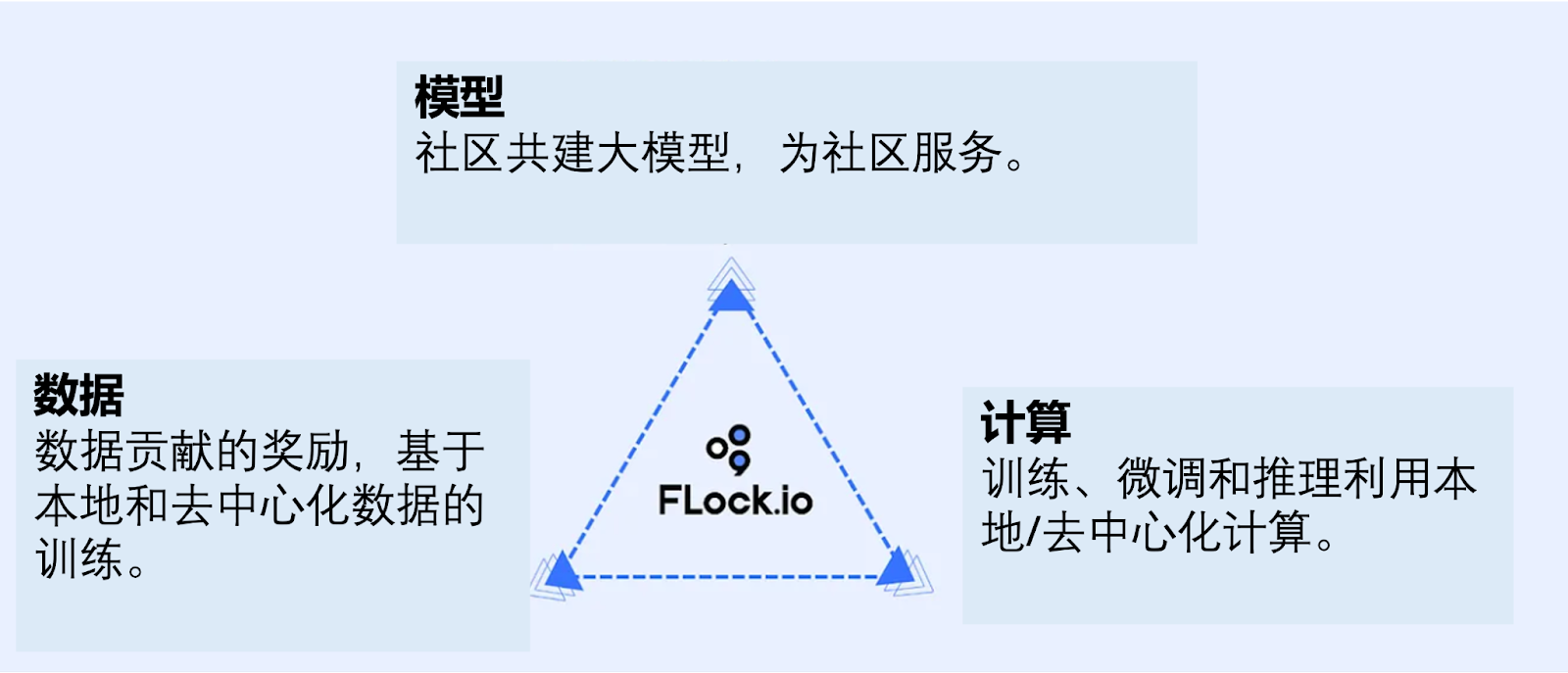
FLock coordinates community-driven collaboration on computation, models, and data via smart contracts
First Understand: Is Trained Data Still Your Data?
TechFlow: So how exactly are individual local data encrypted and incorporated into the global model during training, while still preserving the privacy of the original data once a result is obtained?
Jiahao:
Let me give an example: WorldCoin takes a photo of your iris, processes it through a neural network, and turns it into an embedding. That embedding is no longer your actual iris image, right? It depends on whether people accept this logic—
“That’s not my iris anymore—it’s a new embedding.”
Of course, some people reject this logic, arguing it’s still a derivative of their personal data.
Let’s break it down. For those who accept this premise, under federated learning, personal data never leaves the local device. What gets transmitted is the change in the local model after training—known as the gradient.
We only transmit this gradient to the next node. At no point is anything related to your raw data sent—so it remains fully confidential. In theory, no additional encryption is needed because the gradient itself isn’t your data.
However, if you don’t accept this—believing that even derivatives belong to you—even if the neural network transforms your iris into an embedding, and that embedding can still be linked back to your identity—we apply an additional layer of encryption on the transmission channel.
We also encrypt the transmission between nodes. There are multiple methods, including interesting ones like Deep Gradient Compression, which can compress node data transmissions to below 5%. This simultaneously accelerates transfer speed, addresses privacy concerns, and maintains model accuracy—a triple win.
Why does this work? First, in machine learning, to prevent overfitting, we intentionally drop some data during computation—known as Dropout—to improve overall accuracy. For example, even if we achieve 100% accuracy, we deliberately reduce it to around 70-80% before transmission, because pushing toward perfect scores risks converging on a local optimum rather than the global optimum. This method actually enhances the accuracy of our overall computation.
Second, in deep learning, we find that when gradients are compressed to extreme levels (e.g., below 5%), the information becomes irrecoverable—no one can reconstruct your original data. It’s like applying heavy mosaic blur to an image—no AI, no matter how advanced, can fully restore the original details. It might guess or hallucinate, but due to the scarcity of usable information, reconstruction is extremely limited. According to information theory, no one can recover your original data—making this a reliable layer of encryption.
Third, smaller data payloads naturally increase transmission efficiency. Even for large models measured in tens of billions of parameters, our optimizations allow decentralized fine-tuning across multiple consumer-grade machines to complete within hours.
Decentralized machine learning is gradually becoming less of a slogan and more of a viable engineering solution.
This is fundamentally not about blockchain or federated learning per se, but about secure encrypted transmission between nodes—as long as it’s safe, it works. The method I described is just one possible approach. Technologies like ZK, FHE, and TEE can also serve as encryption solutions. FLock is highly compatible with all of them—in fact, we even published a paper called zkFL.
Federated Learning + Smart Contracts = FLock
TechFlow: In federated learning, each node processes its own data and submits updates. What happens next? How would you explain Consensus to someone unfamiliar with AI?
Jiahao:
Think of these nodes as forming a ring. We use a Ring-all Reduce method, passing updates from one node to the next until a node receives the same data twice—completing the loop. This is called gradient accumulation. Once completed, every node updates its local model to the new version.
Consensus occurs in a system without centralized management. Why does Google need to manage a centralized federated learning system?
Because they fear malicious nodes—such as submitting fake data or random noise. This is why centralized oversight is deemed necessary. It’s also why in traditional Web2 federated learning, participants must sign legal agreements—you can only collaborate with trusted parties.
With FLock, we adopt a decentralized approach to prevent malicious nodes. We replace the central manager with smart contracts acting as Validators, using smart contracts to validate contributions.
Machine learning is outcome-oriented. As long as we verify that a submitted model improves accuracy, it passes validation.
If everyone else’s models are improving accuracy, but yours consistently degrades performance, you get slashed—not immediately, but gradually. If you continue deviating, you’ll eventually be removed from the network.
This is a game-theoretic mechanism managed by smart contracts.
Could extreme scenarios occur? That’s where Tokenomics comes in.
We’ve analyzed many edge cases in our papers. Here’s a simple example:
Suppose all data in the network comes from right-handed users, except one node with left-handed user data. His data genuinely differs, but is authentic. In the first round, all right-handed models shift slightly right, while his shifts left. Initially, our FLock consensus will slightly slash his contribution because it diverges. Over subsequent rounds, he may be slashed further. But after several epochs, because his data is genuine and contributes valuable signal, the model begins shifting toward accommodating left-handed patterns. Eventually, other nodes’ models start adjusting in that direction as well.
Under our Tokenomics design, rewards are allocated based on whose data influences the final model direction. Although the left-handed user may face initial slashing due to data uniqueness, his eventual contribution leads to greater reward allocation—resulting in higher net earnings.
This is precisely why we designed the FLock mechanism this way. That’s also why we started with academic research, publishing at top conferences, because many aspects required deep thought. Our early team focused entirely on R&D—writing papers, coding, running experiments, simulations—earning peer recognition (NeurIPS, TAI, Science, etc.) to ensure a solid foundation before launching SDKs and testnets.
TechFlow: Can you briefly describe the players in this Tokenomics ecosystem—the different participants in the network?
Jiahao:
There are three main roles: Planer, Trainer, and Validator. Think of it abstractly as a task platform, similar to HuggingFace in the traditional AI world. The Planer is the task publisher who issues tasks and provides incentives. The Trainer represents AI developers and data owners who contribute models or data and expect rewards. The Validator ensures fairness and efficiency by verifying computational accuracy and contributing computing power.
Go-to-Market
TechFlow: How does the FLock smart contract appear on the frontend? For example, in image recognition, what are the steps involved?
Jiahao:
Each user opens our website or client, locates their local data, clicks “Train,” and enters the training process. For retail users, we offer a seamless experience.
TechFlow: How is matching between different tasks handled?
Jiahao:
As a trainer, my data can match various tasks. For instance, if a hospital runs a sleep study with daily sleep datasets, I can choose to join it—like a marketplace. As a data owner, I have the right to decide which subnetwork (subnet) to join. The incentives in this marketplace come from business sponsors—hospitals, banks, DeFi protocols—who post bounties (e.g., $200K) to incentivize participation in their FLock-hosted subnet.
TechFlow: So in your go-to-market strategy, do you first target the business side?
Jiahao:
Yes, our current paying customers are all enterprise clients under contract. We’ve delivered several projects and now aim to launch a public Marketplace, allowing more businesses to directly post tasks—shifting toward a more consumer-facing model instead of relying solely on B2B onboarding.
TechFlow: How receptive are traditional data providers to Web3?
Jiahao:
It reduces their costs significantly. Off-chain processes could take months and require extensive audits. Moreover, conducting cross-border clinical trials is nearly impossible because almost no country allows medical data to leave its borders.
Thus, FLock offers a breakthrough:
First, data stays local—bypassing complex regulatory hurdles.
Second, it enables previously impossible collaborations—such as joint blood glucose prediction models across China, Japan, and Korea, tailored for East Asian physiology.
Beyond that, there are even bigger possibilities—remote diagnostics, for instance. Previously impractical due to data sovereignty laws, federated learning now allows monitoring here and diagnosis there—neither party sees the full dataset. For patients, this eliminates the need to travel internationally for checkups. From what I’ve seen, healthcare is perhaps the industry that best understands federated learning. The second most informed is finance, having been pitched countless times by tech startups.
We’re not targeting traditional finance—we’re partnering directly with DeFi, since they fully understand Web3, minimizing mutual learning curves.
When our Marketplace launches, we’ll focus on AI startups with strong individual-use cases, like voice simulation apps. Remember when an AI-generated selfie app lost popularity because its privacy policy stated, “You grant us full copyright to all photos”? People hesitated to upload 10 facial images. Startups in voice synthesis want to use FLock as a privacy assurance—proving their product keeps your voice strictly local, with on-chain proof it never leaves your device, while still letting you simulate voices like Zhao Benshan’s.
Ultimately, I hope FLock becomes like CertiK for privacy—a standard-setter for privacy-preserving and decentralized model training.
TechFlow: How long did you study P2P networks before concluding they were feasible?
Jiahao:
Less than a year. Our papers were accepted quickly, signaling strong interest.
Peer reviewers serve as a barometer—if your work is seen as unoriginal or boring, monetization is unlikely. But our submissions received overwhelmingly positive feedback, which was incredibly encouraging.
Still, transitioning from academic validation to monetization requires significant effort—convincing investors this makes sense, showing them the potential. That’s another challenge altogether.
Our first phase was R&D. The second phase began after releasing test versions and open-sourcing our codebase. During the 2023 crypto bear market, we closed a $6 million seed round led by Lightspeed Faction (US), giving us immense confidence—top-tier, AI-focused VCs backing us at the market low signaled strong long-term prospects.
Now we’re in the third phase—market validation. We’re launching FLock’s decentralized training platform as a Marketplace, enabling anyone to build AI models for their communities. Our network has already been pre-committed by the largest global validators.
TechFlow: Now that people see Web3’s potential, many projects apply blockchain to real-world problems—you’re one of them. How do you boost market visibility?
Jiahao:
We’re aiming for breakout applications—either solving urgent needs or creating viral appeal. Our close ties with DeFi stem from the fact that many critical needs exist there but remain unmet.
For example, in personal lending, credit data cannot be linked to physical bank cards. FLock enables on-device computation to generate a credit score used as verification. While we can’t yet enable low-collateral loans, we might allow 105% collateral versus others’ 150%, significantly boosting lending efficiency. For many users, this is a real pain point.
The second path is virality—like the voice simulation app going viral again, with influencers sharing it widely, prompting others to download it.
These two strategies form our core user acquisition channels.
TechFlow: FLock is also part of the DePIN sector. How does FLock relate to existing Decentralized Compute and Decentralized Storage projects?
Jiahao:
We view ourselves as complementary partners in the ecosystem. We operate at the Training Layer—a single layer in the stack, analogous to TensorFlow or PyTorch in traditional AI. We don’t replace AWS—you still use AWS S3 for storage or other compute providers. We coordinate the workflow: where compute comes from, how storage integrates.
I think innovation in decentralized data storage may be limited—many players already dominate. Our first testnet integrated well with IPFS. Partnering with decentralized compute allows regular users to seamlessly experience FLock without technical barriers.
Ideally, Bitcoin should be run by downloading the full ledger onto your home computer and signing transactions locally. Similarly, purist FLock usage would involve running everything locally—your data never leaves your machine, maximizing security. But we can’t expect everyone to have powerful always-online PCs. That’s why integration with decentralized compute and storage is crucial: users can log into FLock, store data on decentralized storage, leverage decentralized compute, and let FLock coordinate data and computation—delivering results with fair, transparent reward distribution. Like MetaMask, users simply log in, click, and leave—no need to host data themselves.
For us, upstream and downstream partnerships exist to enhance user experience.
Side Note on AI: GPT, GNN, and Other Large Models
TechFlow: Did you work on federated learning during your time in banking?
Jiahao:
Not really. In banking, it was mostly NLP—Graph Neural Networks, Knowledge Graphs, etc.—so I’m somewhat familiar. When GPT exploded, I noticed the knowledge graph and neural network fields suddenly cooled down. I supervise two PhD students at Imperial College—their thesis topics had to be rewritten, otherwise examiners would easily challenge them: “Why not just use GPT?”
TechFlow: Is GPT semantic data, while graphs deal more with non-semantic data?
Jiahao:
You could say that. But brute force produces miracles—if GPT solves the problem, why propose a graph underneath? At NeurIPS 2022, I participated in a panel with Huawei Research’s Boxing Chen, Microsoft’s Yu Cheng, and Meta’s Marjan discussing the future of NLP. I tried hard to revive interest in Knowledge Graphs.
But the prevailing view was: if we have maximum compute, best algorithms, and best data, and can achieve end-to-end results directly, why analyze every internal relationship? The world is utilitarian. Black-box algorithms deliver astonishing results through sheer scale.
Doing causal analysis is too costly and slow. Let me give a clear example: when neural networks first emerged, traditional academics opposed them, insisting on statistical methods and knowing causality—how A leads to B, deriving formulas. That was considered real machine learning.
But neural network proponents asked: why bother? A leads to B—we build a network that transforms A to B. If it fails, make the network larger. Keep iterating until it works. Today, who questions neural networks for lack of transparency? Industries that once demanded causal analysis—like high-frequency trading funds—have changed their audit practices, now relying on end-to-end testing to justify strategies, abandoning causal reports altogether.
From a consumer market perspective, I suspect Graph’s future may follow the same path. Once large models advance far enough, in the next cycle, people may forget why graphs were ever needed. They might be seen by the next generation as outdated academic pursuits in statistical algorithms.
Still, I must emphasize: fundamental scientific research is always essential, and I will continue supporting it where I can. Graphs still have a long and promising road ahead in research. After all, this is the field I dedicated ten years to. Ha ha.
Further Reading
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News














