

Podcast Notes | Interview with Gensyn Founder: Maximizing Utilization of Idle Computing Resources via Decentralized Networks to Empower Machine Learning
TechFlow Selected TechFlow Selected
Podcast Notes | Interview with Gensyn Founder: Maximizing Utilization of Idle Computing Resources via Decentralized Networks to Empower Machine Learning
Blockchain provides a way to eliminate the need for a single decision-maker or arbitrator by enabling consensus among large groups.
Compiled & Translated by: Sunny, TechFlow
On June 12, Gensyn, a blockchain-based AI computing protocol, announced the completion of a $43 million Series A funding round led by a16z.
Gensyn's mission is to provide users with access to computational scale equivalent to owning private computing clusters, and crucially, to ensure fair access that cannot be controlled or shut down by any central entity. At the same time, Gensyn is a decentralized computing protocol focused on training machine learning models.
Reviewing a podcast from late last year featuring Gensyn founders Harry and Ben on Epicenter reveals an in-depth exploration of computational resource surveys—including AWS, on-premise infrastructure, and cloud infrastructure—to understand how to optimize and leverage these resources for AI application development.
They also discussed in detail Gensyn’s design philosophy, goals, market positioning, and the various constraints, assumptions, and execution strategies encountered during the design process.
The podcast introduced four main roles within Gensyn’s off-chain network, explored characteristics of Gensyn’s on-chain network, and emphasized the importance of Gensyn tokens and governance.
Additionally, Ben and Harry shared some interesting AI fundamentals, helping listeners gain deeper insights into the basic principles and applications of artificial intelligence.

Host: Dr. Friederike Ernst, Epicenter Podcast
Speakers: Ben Fielding & Harry Grieve, Co-founders of Gensyn
Original Title: "Ben Fielding & Harry Grieve: Gensyn – The Deep Learning Compute Protocol"
Air Date: November 24, 2022
Blockchain as a Trust Layer for Decentralized AI Infrastructure
The host asked Ben and Harry why they decided to combine their extensive experience in AI and deep learning with blockchain technology.
Ben explained that this decision wasn’t made overnight but evolved over a relatively long period. Gensyn aims to build large-scale AI infrastructure, and while researching how to achieve maximum scalability, they realized they needed a trustless layer.
They needed to integrate computing power without relying on centralized new suppliers, otherwise they would hit administrative scaling limits. To solve this, they began exploring verifiable computation research, but found it always required a trusted third party or judge to verify computations.
This limitation led them toward blockchain. Blockchain offers a way to eliminate the need for a single decision-maker or arbitrator by enabling consensus among large groups.
Harry also shared his perspective—he and Ben are strong advocates for free speech and concerned about censorship.
Before turning to blockchain, they were researching federated learning, a deep learning field where you train multiple models across distributed data sources and then combine them into a meta-model capable of learning from all sources. They worked with banks using this method. However, they quickly realized that the bigger challenge was acquiring the computational resources or processors needed to train these models.
To maximize integration of computing resources, they needed a decentralized coordination mechanism—this is where blockchain comes in.
Survey of Market Computing Resources: AWS, On-Premise, and Cloud Infrastructure
Harry explained different computing resource options for running AI models, depending on model size.
Students might use AWS or local machines; startups may opt for on-demand AWS or cheaper reserved instances.
However, for large-scale GPU demands, AWS can face cost and scalability limitations, leading many organizations to build internal infrastructure.
Research shows many organizations struggle to scale, with some even purchasing and managing GPUs themselves. Overall, buying GPUs is often more economical long-term than running on AWS.
Machine learning computing choices include cloud computing, running AI locally, or building your own cluster. Gensyn aims to provide access to computational scale equivalent to owning your own cluster, with the key being fair access that no central entity can control or shut down.

Table 1: All current computing resource options in the market
Exploring Gensyn’s Design Philosophy, Goals, and Market Positioning
The host asked how Gensyn differs from previous blockchain computing projects like Golem Network.
Harry explained that Gensyn’s design philosophy revolves around two axes:
-
Protocol specificity: Unlike general-purpose computing protocols like Golem, Gensyn is a specialized protocol focused specifically on training machine learning models.
-
Scalability of verification: Early projects typically relied on reputation systems or replication methods intolerant to Byzantine faults, which don't offer sufficient confidence for machine learning outcomes. Gensyn aims to apply lessons from cryptographic computation protocols specifically to machine learning, optimizing speed and cost while ensuring satisfactory verification levels.
Harry added that when considering the properties the network must have, it needs to be oriented toward machine learning engineers and researchers. It needs a verification component, but critically, in terms of allowing anyone to participate, it must be both censorship-resistant and hardware-agnostic.
Constraints, Assumptions, and Execution in the Design Process
During the platform design process, Ben emphasized the importance of system constraints and assumptions. Their goal is to create a network that turns the entire world into an AI supercomputer, requiring a balance between product assumptions, research hypotheses, and technical assumptions.
Regarding why Gensyn is built as its own Layer 1 blockchain, their rationale is to maintain greater flexibility and autonomy in critical areas such as consensus mechanisms. They want the freedom to prove their protocol in the future and avoid unnecessary constraints early in development. Additionally, they believe chains will eventually interact via widely accepted communication protocols, aligning their decision with this vision.
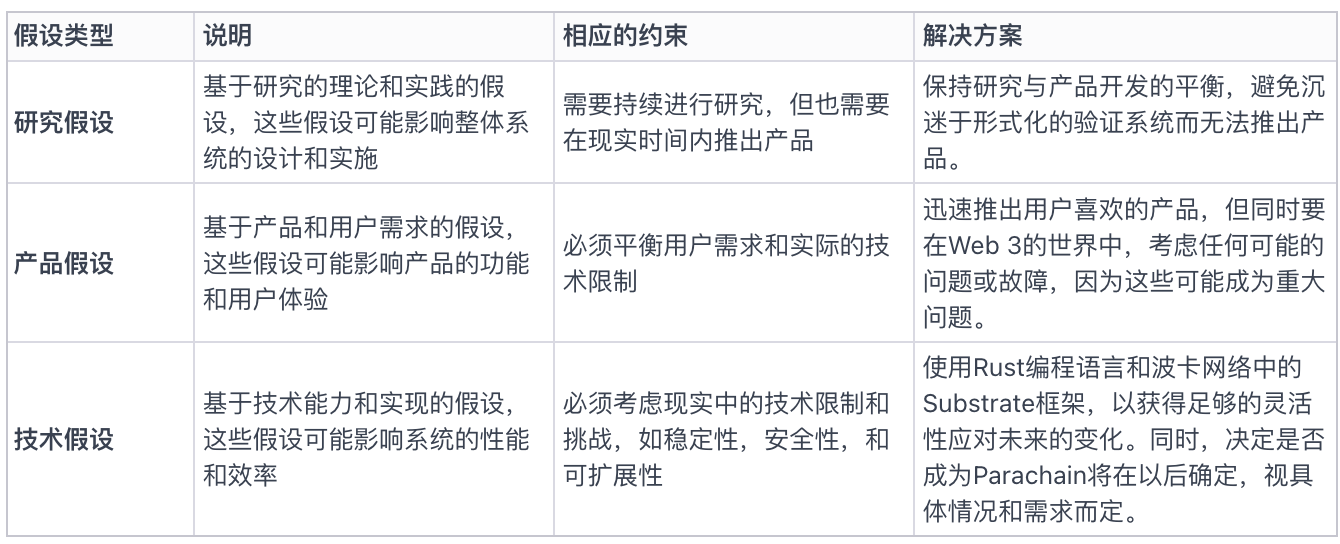
Figure 2: Product assumptions, research hypotheses, technical assumptions, constraints, and execution
Four Key Roles in Gensyn’s Off-Chain Network
In this discussion of Gensyn’s economy, four main roles were introduced: Submitter, Worker (Solver), Verifier, and Whistleblower. Submitters can submit various tasks to the Gensyn network, such as generating specific images or developing AI models for autonomous driving.
Submitter: Task Submission
Harry explained how to use Gensyn for model training. Users first define desired outcomes, such as generating images from text prompts, then build a model that takes text inputs and generates corresponding images. Training data is crucial for model learning and improvement. After preparing the model architecture and training data, users submit them along with hyperparameters such as learning rate schedules and training duration to the Gensyn network. The result of this training process is a trained model that users can host and utilize.
When asked about choosing untrained models, Harry proposed two approaches:
-
The first is based on the current popular foundation model concept, where large companies like OpenAI or Midjourney build foundation models, after which users fine-tune them on specific datasets.
-
The second option is building models from scratch, differing from the foundation model approach.
With Gensyn, developers can submit various architectures using evolutionary optimization-like methods for training and testing, continuously refining them to build desired models.
Ben offered an in-depth view on foundation models, believing they represent the future of the field.
As a protocol, Gensyn hopes to be used by DApps implementing evolutionary optimization or similar techniques. These DApps can submit individual architectures to the Gensyn protocol for training and testing, iteratively refining them to build ideal models.
Gensyn aims to provide pure machine learning computing infrastructure, encouraging ecosystem development around it.
While pre-trained models may introduce bias due to proprietary datasets or opaque training processes, Gensyn’s solution is to open up the training process rather than eliminating the black box or relying on full determinism. By collectively designing and training foundation models, we can create global models free from biases inherent in any single company’s dataset.
Worker (Solver)
-
For task assignment, one task corresponds to one server. However, a single model may be split into multiple tasks.
-
Large language models are designed to fully utilize the largest available hardware capacity at the time. This concept can be extended to networks, accounting for device heterogeneity.
-
For specific roles such as verifier or worker, participants can pick up tasks from the mempool. From those indicating willingness to take on a task, one worker is randomly selected. If a model and data cannot fit on a claimed device, the owner may face penalties due to system congestion.
-
Whether a task can run on a machine is determined by a verifiable random function selecting a worker from the available subset.
-
Regarding verification of worker capability: if a worker lacks the claimed computing power, they won’t complete the computation, which will be detected when submitting proofs.
-
However, task size is a concern. If set too large, it could cause system issues such as denial-of-service attacks (DoS), where workers claim tasks but never complete them, wasting time and resources.
-
Thus, determining task size is critical, requiring consideration of factors like parallelization and task structure optimization. Researchers are actively studying optimal methods under various constraints.
-
Once the testnet launches, real-world conditions will also be observed to evaluate system performance in practice.
-
Defining the perfect task size is challenging, and Gensyn is prepared to adjust and improve based on real-world feedback and experience.
Verification Mechanism and Checkpoints for Large-Scale On-Chain Computation
Harry and Ben highlighted that verifying computational correctness is a major challenge because, unlike hash functions, it isn't deterministic, so simple hash validation cannot confirm whether computation occurred. The ideal solution is to apply zero-knowledge proofs to the entire computation process. Currently, Gensyn is still working toward achieving this capability.
Currently, Gensyn uses a hybrid approach involving checkpoints, combining probabilistic mechanisms and checkpoints to verify machine learning computations. By integrating random auditing schemes with gradient space paths, a relatively robust checking mechanism is established. Additionally, zero-knowledge proofs are introduced to enhance verification, particularly applied to the global loss of models.
Verifier and Whistleblower
The host and Harry discussed two additional roles involved in verification: Verifier and Whistleblower. They detailed each role’s responsibilities and functions.
The Verifier ensures checkpoint correctness, while the Whistleblower ensures the Verifier performs accurately. The whistleblower resolves the verifier’s dilemma, ensuring the verifier’s work is correct and trustworthy. When verifiers intentionally introduce errors into their work, whistleblowers detect and expose these errors, thereby ensuring the integrity of the verification process.
Verifiers deliberately introduce errors to test whistleblower vigilance and ensure system effectiveness. If there is an error in the work, the verifier detects it and notifies the whistleblower. The error is then recorded on-chain and verified. Periodically, and at a rate tied to system security, verifiers intentionally introduce errors to maintain whistleblower engagement. If a whistleblower identifies an issue, they enter a "pinpoint protocol" game, narrowing down the computation to a specific point in a Merkle tree representing a region of the neural network. This information is submitted on-chain for arbitration. This is a simplified version of the verifier-whistleblower process, which will undergo further development and research following the seed round.
Gensyn’s On-Chain Network
Ben and Harry discussed in detail how Gensyn’s coordination protocol operates and is implemented on-chain. They first mentioned the process of building network blocks, involving staking tokens as part of the staked network. Then, they explained how these components relate to the Gensyn protocol.
Ben explained that the Gensyn protocol is largely based on the vanilla Substrate Polkadot network protocol. They adopted the Grandpa-Babe proof-of-stake consensus mechanism, with validators operating in the usual way. However, all previously mentioned machine learning components operate off-chain, involving various off-chain participants performing their respective tasks.
These participants are incentivized through staking, either via Substrate’s staking module or by submitting a specified amount of tokens in smart contracts. Once their work is validated, they receive rewards.
Ben and Harry noted the challenge lies in balancing stake amounts, potential slashing penalties, and reward levels to prevent incentives for lazy or malicious behavior.
Additionally, they discussed the complexity added by whistleblowers, yet their presence is essential for ensuring verifier honesty due to the scale of computational needs. While they are actively exploring ways to potentially eliminate whistleblowers using zero-knowledge proof technology, the current system aligns with what’s described in the lite paper, and they are continuously working to simplify every aspect.
When asked about data availability solutions, Harry explained they introduced a layer called Proof of Availability (PoA) atop Substrate. This layer leverages technologies like erasure coding to overcome limitations encountered in broad storage markets. They expressed strong interest in developers who have already implemented such solutions.
Ben added that their needs extend beyond storing training data to include intermediate proof data that doesn’t require long-term storage. For example, such data may only need to persist for about 20 seconds during a certain number of block productions. However, currently they pay Arweave fees covering centuries of storage, which is unnecessary for short-term needs. They are seeking a solution offering Arweave-level guarantees and functionality at lower costs suitable for temporary storage.
Gensyn Token and Governance
Ben explained the importance of the Gensyn token within the ecosystem, playing key roles in staking, penalties, rewards, and maintaining consensus. Its primary purpose is to ensure financial soundness and system integrity. Ben also mentioned cautious use of inflation to pay verifiers and leveraging game-theoretic mechanisms.
He emphasized the purely technical utility of the Gensyn token and stated they will technically ensure the timing and necessity of introducing the Gensyn token.
Harry noted they are part of a minority within the deep learning community, especially given widespread skepticism among AI scholars toward cryptocurrency. Nonetheless, they recognize the technological and ideological value of crypto.
However, at network launch, they expect most deep learning users will primarily transact in fiat currency, with conversion to tokens handled seamlessly behind the scenes.
On the supply side, workers and submitters will actively participate in token transactions, and they’ve already received interest from Ethereum miners who possess significant GPU resources and seek new opportunities.
Critically, it’s important to alleviate fears among deep learning and machine learning practitioners regarding crypto terminology (e.g., tokens), separating it from user interface experiences. Gensyn sees this as an exciting use case bridging Web 2 and Web 3 worlds, grounded in economic rationality and supported by necessary technology.
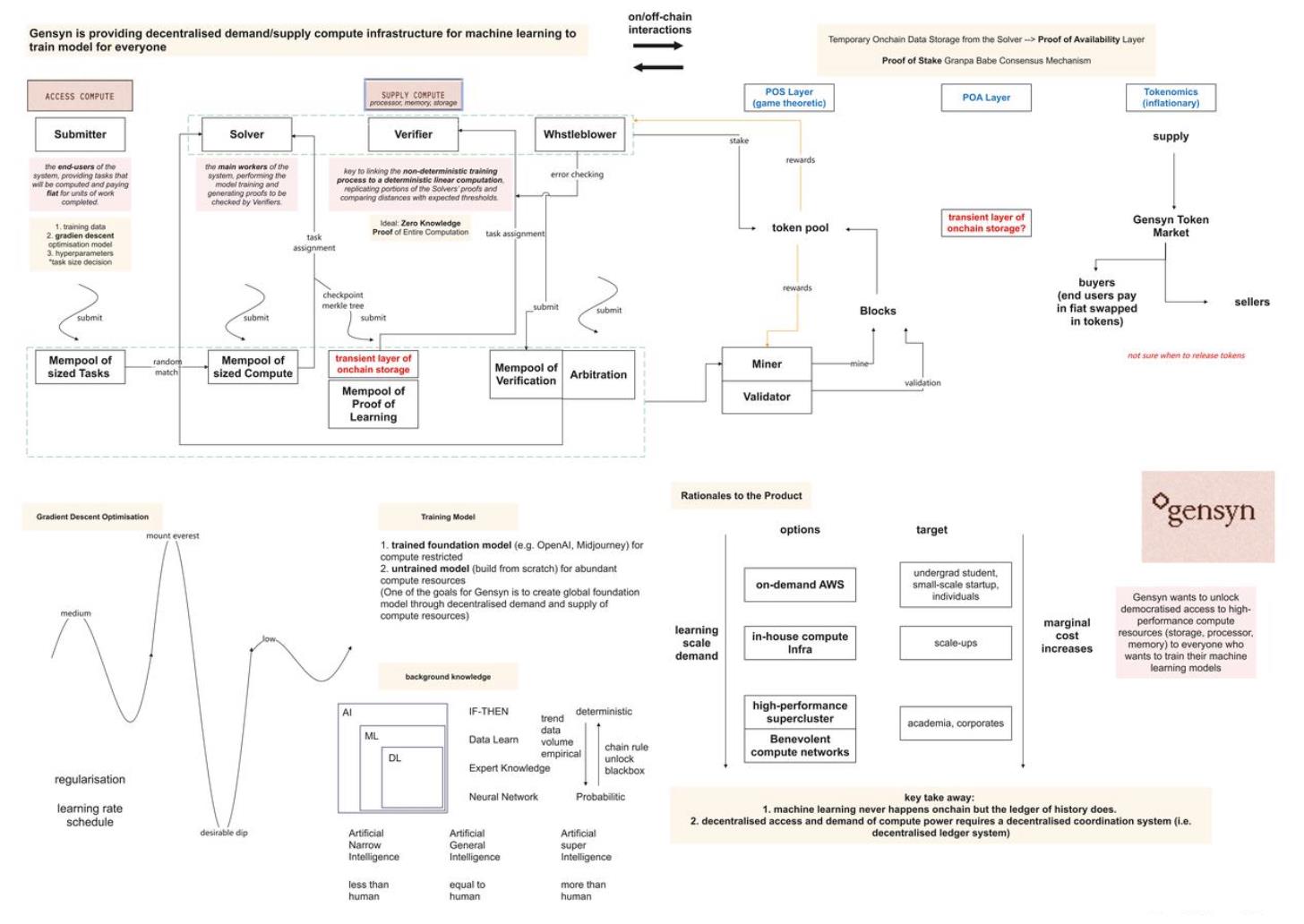
Figure 1: Gensyn’s on-chain and off-chain network operation model based on podcast content. Please notify us promptly if any operational mechanisms are inaccurately described. (Image source: TechFlow)
Demystifying Artificial Intelligence
AI, Deep Learning, and Machine Learning
Ben shared his views on recent developments in AI. He believes although the fields of AI and machine learning have seen a series of small breakthroughs over the past seven years, current advancements seem to be creating truly impactful and valuable applications that resonate with broader audiences. Deep learning is the fundamental driver behind these changes. Deep neural networks have demonstrated capabilities surpassing benchmarks set by traditional computer vision methods. Furthermore, models like GPT-3 have accelerated this progress.
Harry further clarified the distinctions between AI, machine learning, and deep learning. He noted these terms are often used interchangeably but have clear differences. He likened them to Russian nesting dolls, with AI being the outermost layer.
-
Broadly speaking, AI refers to programming machines to perform tasks.
-
Machine learning gained prominence in the 1990s and early 2000s, using data to determine probabilities of decisions rather than relying on expert systems with if-then rules.
-
Deep learning builds upon machine learning but allows for more complex models.

Figure 3: Differences between Artificial Intelligence, Machine Learning, and Deep Learning
Narrow AI, General AI, Superintelligent AI
In this section, the host and guests deeply explored three key areas of artificial intelligence: Artificial Narrow Intelligence (ANI), Artificial General Intelligence (AGI), and Artificial Superintelligence (ASI).
-
Artificial Narrow Intelligence (ANI): Current AI mainly exists at this stage—machines excel at specific tasks, such as detecting certain types of cancer in medical scans through pattern recognition.
-
Artificial General Intelligence (AGI): AGI refers to machines performing tasks that are easy for humans but computationally challenging. For example, navigating smoothly through a crowded environment while making discrete assumptions about all surrounding inputs exemplifies AGI. AGI means models or systems capable of performing everyday human tasks.
-
Artificial Superintelligence (ASI): After achieving AGI, machines might evolve into ASI—where due to model complexity, increased computing power, infinite lifespan, and perfect memory, they surpass human abilities. This concept is frequently explored in science fiction and horror films.
Additionally, the guests mentioned brain-machine fusion, such as brain-computer interfaces, as a possible path to AGI, though it raises numerous ethical and moral questions.
Unpacking the Deep Learning Black Box: Determinism vs. Probabilism
Ben explained that the black-box nature of deep learning models stems from their sheer size. You can still trace paths through decision points in the network, but the path is so vast that linking internal weights or parameters to specific values becomes extremely difficult—these values emerge after processing millions of samples. You can track everything deterministically, updating each step, but the resulting data volume would be enormous.
He observes two trends emerging:
-
As our understanding of constructed models grows, the black-box nature is gradually fading. Deep learning has undergone a fascinating rapid phase filled with extensive experimentation not driven by foundational research, but rather exploratory—seeing what emerges. We feed more data, try new architectures, just to observe outcomes, rather than designing from first principles with full understanding. So there was an exciting era where everything was a black box. But he believes this rapid growth is slowing, and people are revisiting architectures, asking, “Why does this work so well?” and conducting deeper analyses. In this sense, the curtain is beginning to lift.
-
The second trend may be more controversial: a shift in perception about whether computing systems need to be fully deterministic, or whether we can live in a probabilistic world. Humans live in a probabilistic world. The autonomous vehicle example illustrates this best—we accept random events while driving, minor accidents, or system glitches. Yet we completely reject this uncertainty, demanding fully deterministic processes. One challenge facing the autonomous vehicle industry is assuming people will accept probabilistic mechanisms, but in reality, they don’t. He thinks this will change, though controversially: Will society allow probabilistic computing systems to coexist with us? He’s unsure the path will be smooth, but believes it will happen.
Gradient Optimization: Core Method in Deep Learning
Gradient optimization is one of the core methods in deep learning, playing a pivotal role in neural network training. In neural networks, layer parameters are essentially real numbers. Training involves setting these parameters to actual values that allow data to pass correctly through the network and trigger the desired output at the final stage.
Gradient-based optimization has brought transformative change to neural networks and deep learning. This method uses gradients—the partial derivatives of each layer’s parameters with respect to error. By applying the chain rule, gradients can be backpropagated throughout the layered network. This allows you to determine your position on the error surface. Error can be modeled as a surface in Euclidean space, resembling a landscape of peaks and valleys. The goal of optimization is to find regions that minimize error.
Gradients indicate your position on this surface and the direction in which you should update parameters. You navigate this rugged terrain using gradients to find directions that reduce error. Step size depends on the slope: steeper slopes mean larger steps; gentler slopes mean smaller ones. Essentially, you’re navigating this surface, searching for a trough, and gradients help determine location and direction.
This method was a massive breakthrough because gradients provide a clear signal and useful direction—compared to randomly jumping in parameter space, gradients more effectively guide you in knowing whether you're on a peak, in a valley, or on flat ground.
Although many techniques exist in deep learning to address finding optimal solutions, real-world scenarios are often more complex. Numerous regularization techniques used in deep learning training make it more of an art than a science. This is why gradient-based optimization in practice feels more like art than precise science.
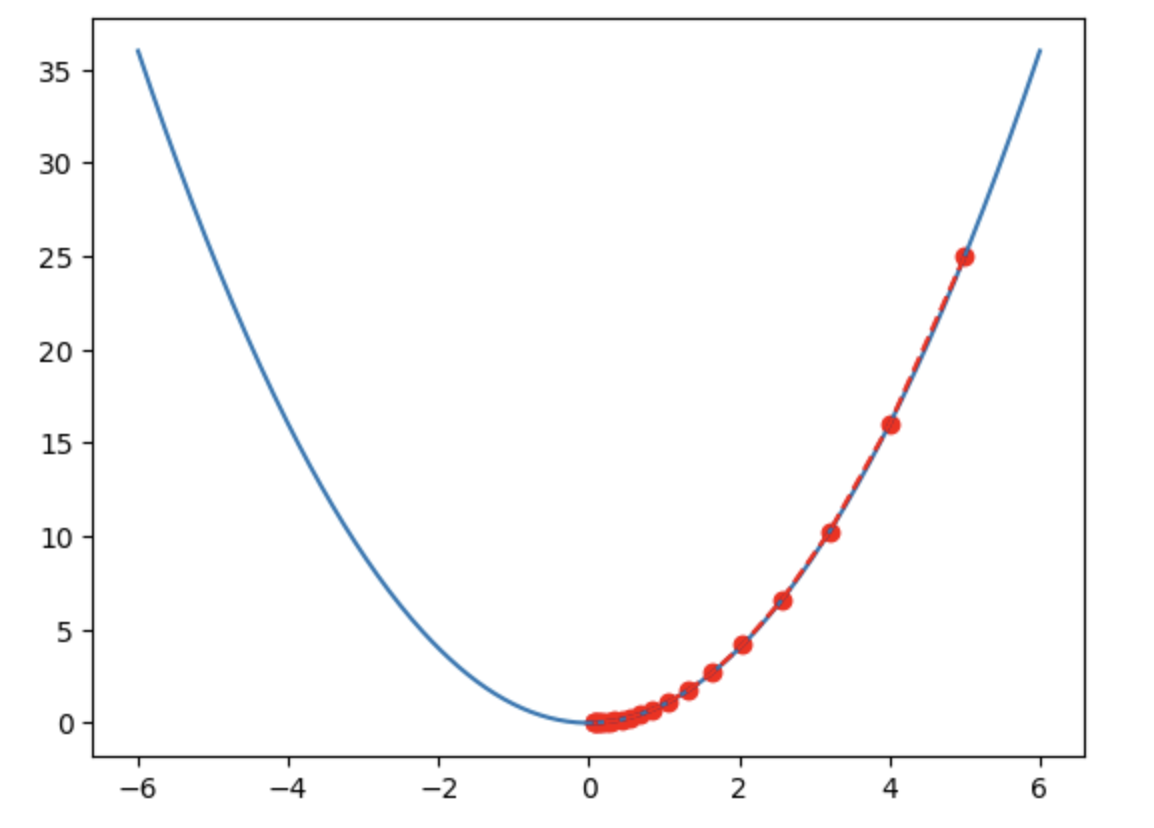
Figure 2: Simply put, the optimization goal is to find the bottom of the valley (Image source: TechFlow)
Conclusion
Gensyn’s goal is to build the world’s largest machine learning computing resource system, fully utilizing idle or underused computing resources such as personal smartphones and computers.
Within the context of machine learning and blockchain, ledger records typically store computational results—i.e., the state of data after machine learning processing. This state could be: “This batch of data has been processed via machine learning, valid, timestamped X date.” The primary purpose of such records is to express result states, not to detail the computation process.
Within this framework, blockchain plays several critical roles:
-
Blockchain provides a way to record data state results. Its design ensures authenticity, preventing tampering and repudiation.
-
Blockchain incorporates economic incentive mechanisms to coordinate behaviors among different roles in the computing network, such as the four roles mentioned: Submitter, Worker, Verifier, and Whistleblower.
-
Through surveys of today’s cloud computing market, we see that while cloud computing has merits, each computing method has specific challenges. Decentralized blockchain computing can play a role in certain scenarios but cannot universally replace traditional cloud computing—blockchain is not a panacea.
-
Finally, AI can be viewed as productivity, whereas organizing and training AI effectively falls under the domain of production relations—encompassing collaboration, crowdsourcing, and incentives. In this regard, Web 3.0 offers numerous potential solutions and use cases.
Therefore, we can understand that the integration of blockchain and AI, particularly in data and model sharing, coordination of computing resources, and verification of results, opens new possibilities for addressing challenges in AI training and deployment.
References
1.https://docs.gensyn.ai/litepaper/
2.https://a16zcrypto.com/posts/announcement/investing-in-gensyn/
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













