

Pyth V2 Deep Dive: A Pivotal Shift in Price Feeding Model, Soaring Product Capabilities After Cross-chain and Multi-scenario Support
TechFlow Selected TechFlow Selected
Pyth V2 Deep Dive: A Pivotal Shift in Price Feeding Model, Soaring Product Capabilities After Cross-chain and Multi-scenario Support
As more DeFi use cases emerge, predicting future risks will become increasingly important.

Recently, attention seems to be heavily focused on L2s.
Coinbase has launched the Base testnet, Arbitrum has initiated its airdrop, zkSync Era announced mainnet launch, and Polygon rolled out zkEVM.... While we enjoy discussing valuations, technical architectures, and application ecosystems, let's not forget that they all share one common critical need:
Oracles.
All blockchain networks need to obtain prices for crypto assets—and even real-world assets—from various data sources to provide crucial inputs and references for on-chain applications.
If you observe closely, you’ll notice that almost immediately after any of the above L2s announces its launch, news follows that oracle project Pyth Network has already begun providing price feeds for it.
Not just L2s—whenever a new chain launches its mainnet or testnet, integrating an oracle usually requires technical coordination time. Given that “announce first, act later” has become the norm, how does Pyth achieve such rapid, seamless integration?
Oracles have traditionally remained invisible to end users, but with the surge of L2s, they now seem to have more opportunities to shine—mainly because:
High performance and low fees naturally foster more ecosystem applications and enable innovative financial Lego use cases, such as decentralized high-frequency trading contracts and derivatives based on real-world assets. This, in turn, increases demand for accuracy, quality, and update speed of financial/crypto asset pricing.
So, for developers building applications, is using Pyth a good choice?
For users, Pyth Network has yet to release its token. With strong partnership expectations across multiple blockchains, is it worth positioning early? And what participation methods are available?
Recently, Pyth Network also released its V2 version with numerous new features—its first major upgrade in over five months. What progress and changes have occurred? Beyond official announcements, in-depth analysis remains scarce.
Therefore, considering the explosive growth of L2s and Pyth’s own token anticipation, we’ve relaunched our research into this oracle project.
Whether you’re an investor/researcher in this sector or a developer considering oracle integration, this article will be helpful.
Data Performance: Usage Significantly Increased After V2 Upgrade
Before diving into specific mechanisms, let’s first look at Pyth Network’s current data performance.
First, regarding the overall oracle landscape, TVS (Total Value Secured) is a key metric. Unlike the commonly used TVL, TVS summarizes the total economic impact and adoption level of an oracle network, representing the “total secured value.”
For example, if Pyth’s TVS on Protocol A is $100, it means the total transaction value generated by Protocol A via Pyth’s price feeds amounts to $100. Additionally, these price feeds help prevent data manipulation and operational failures that could lead to user fund losses.
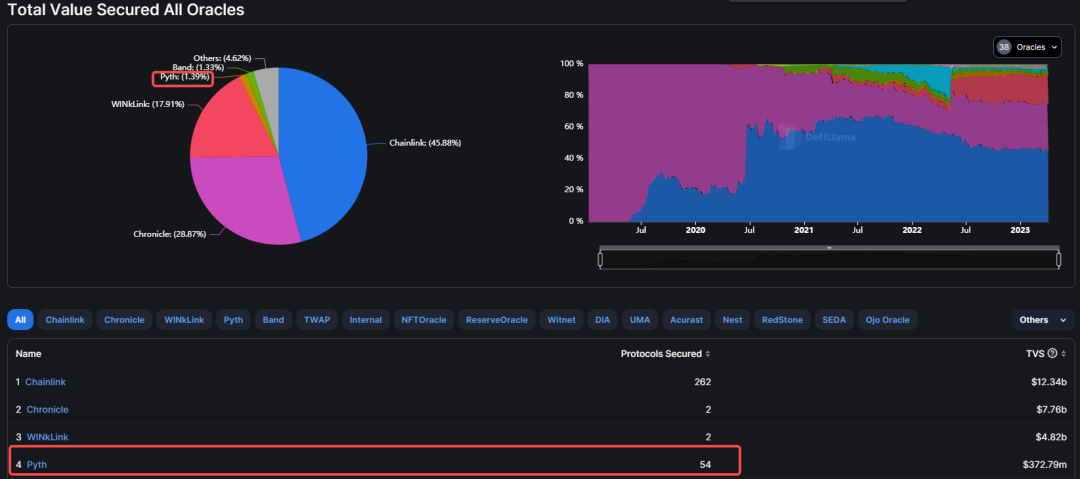
According to DefiLlama data, excluding two projects offering oracle services exclusively to single protocols, Pyth ranks second only to Chainlink—the leading oracle—in terms of TVS; it also ranks second in the number of supported projects (54).
Looking at its own growth trajectory, Pyth’s TVS has shown clear upward momentum since December last year—a trend that aligns with the timing of its V2 launch at the end of 2022.
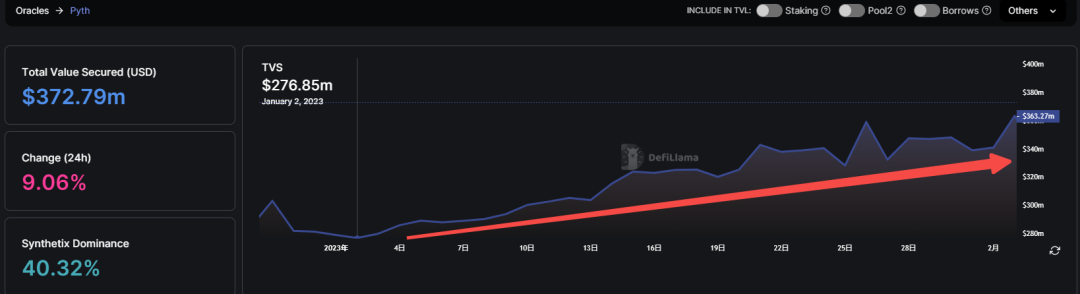
To clarify: when Pyth launched its V1 two years ago, it initially supported only Solana-based ecosystem projects; the V2 version adopted a multi-chain strategy, offering oracle services to both EVM and non-EVM blockchains. Today, the TVS of its cross-chain service projects has already surpassed Solana’s total TVL.
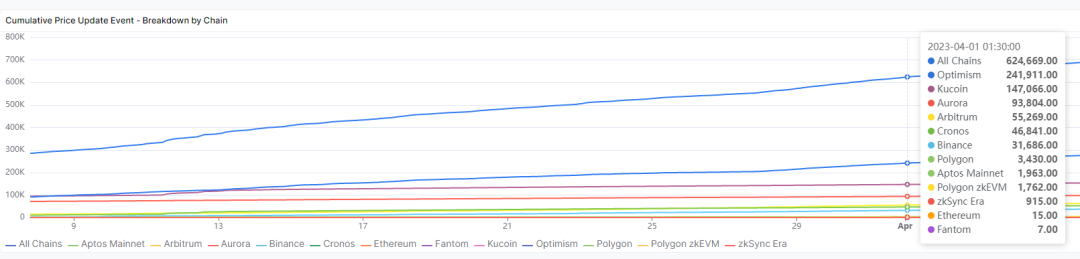
The chart below more clearly illustrates Pyth’s usage across multiple chains. As of April 1, Pyth delivered over 600,000 price update events across various chains—meaning numerous DeFi protocols across different chains rely on Pyth’s price feeds to execute operations (e.g., users trading BTC at real-time prices via a DeFi protocol).
Which protocols are currently using Pyth’s services? We found Synthetix accounts for over 40% of TVS, making it Pyth’s largest client. Other notable DeFi protocols across various chains and L2s—including Mango Finance, Drift, CAP, ZETA, Perpy, and Cypher—also leverage Pyth’s oracle services.

What advantages do these protocols see in Pyth? Or from another angle: what aspects should we focus on when evaluating an oracle project?
Basic Logic for Analyzing Oracles
To answer the previous question, first understand: Why doesn’t Web2 need oracles, but Web3 absolutely does?
Many readers often wonder: Binance, CoinMarketCap, and others already provide crypto price data—why can’t DeFi protocols simply use them directly instead of relying on oracles?
The key lies in the closed nature of on-chain environments.
On-chain applications execute operations and produce results according to smart contract logic, but the triggers for execution come from external conditions—external data must be brought into the contract.
Crypto asset prices from websites remain external data independent of the blockchain world. Even though readily available, they aren’t necessarily usable: we still need an intermediary to deliver price data to on-chain protocols—that’s exactly why oracles exist.
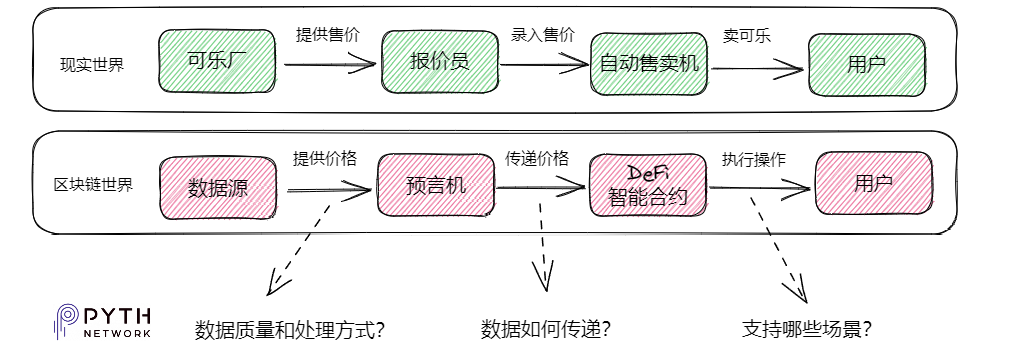
In the blockchain world, when you purchase a crypto asset at market price through a DeFi platform, the process generally involves:
- Data sources provide asset prices to the oracle;
- The oracle delivers prices to DeFi and other applications;
- Users buy assets at the price displayed in the DeFi app.

Thus, the oracle acts as a “quotation agent”—fetching prices from upstream sources and delivering them downstream to support application use cases. In connecting these three stages, we can naturally ask questions about each key step:
- Data source quality: Since prices are being fetched, are the sources themselves accurate and trustworthy? How is the data processed?
- Data delivery method: Including efficiency and cost—can applications easily integrate and use the service?
- Supported use cases: Can it offer customization to meet the specific needs of different DeFi applications?
These aspects serve as important benchmarks for assessing an oracle’s fundamentals—and form the core framework for analyzing Pyth Network’s latest developments.
New Data Source Developments: Aggregating Price Confidence Intervals, Dedicated Application Chain
A key reason Pyth Network holds a strong position in the oracle space is its robust roster of data providers.
Back at its initial launch, Pyth announced over 40 top-tier financial market and crypto industry price data providers—including GTS, one of the largest NYSE market makers, and Jump Trading, the clearing unit of CME Group. In the crypto space, it included major centralized exchanges like Binance, OKX, and Coinbase, as well as market makers such as DWF Labs.
By April this year, the number of public data providers had grown to over 80. In crypto markets, beyond mainstream assets like BTC and ETH, Pyth now includes many long-tail assets. In traditional finance, it has uniquely incorporated prices for commodities, precious metals, and forex—real-world assets increasingly integrated into its offerings.
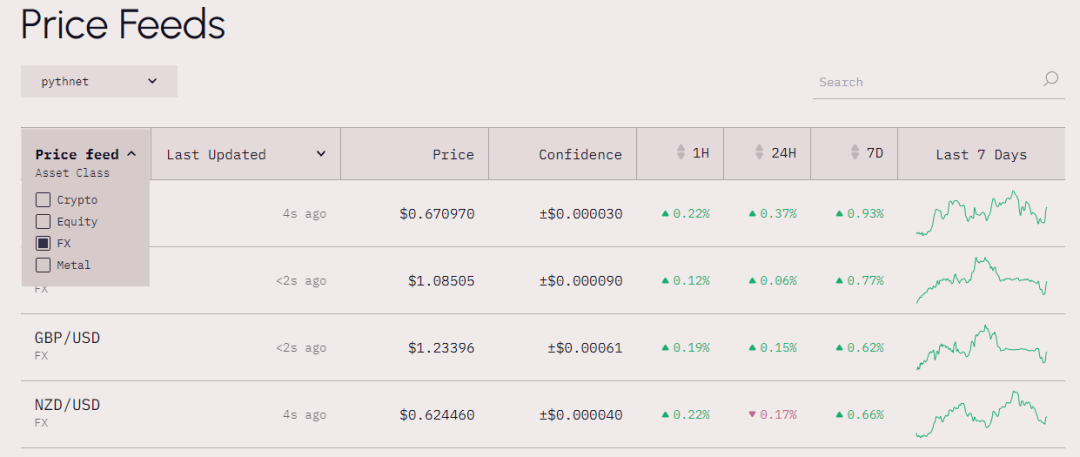
Figure: Financial asset price quotes offered on the Pyth Network official website
However, as the number of data sources grows, a natural question arises: Whose price should we trust, and how do we ensure the correctness of prices provided by so many sources?
This question affects the normal operation of all DeFi applications and underpins the stability of the entire crypto ecosystem.
To address this, Pyth Network designed a confidence interval mechanism to ensure price accuracy and stability.
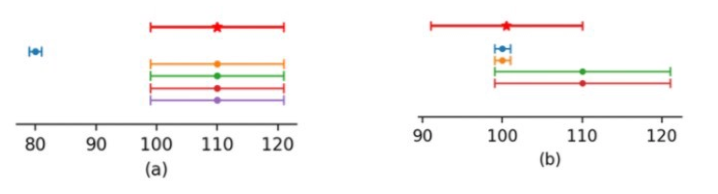
Figure: Confidence interval design ensures price correctness
According to information TechFlow obtained from Pyth’s product team, each identical quote issued by Pyth requires input from at least five data sources.
For example, four sources report the real-time price of asset A between $100–120, while one reports around $80. Under normal circumstances, Pyth sets the confidence interval for asset A at approximately $100–120, meaning the price within this range is considered more reliable, ensuring published data isn't skewed by outlier sources (Figure a).
When different sources provide slightly varying but non-extreme prices, Pyth applies weighted aggregation based on their precision, forming a composite confidence interval (Figure b). For instance, if two sources quote asset B at $100–101 and two others at $100–120, Pyth might generate a final confidence interval of $100–110 after weighting.
From these examples, it’s clear that Pyth aggregates prices from multiple sources, reflecting discrepancies while mathematically ensuring correct synthesis.
Understanding this design naturally leads to another question: How do we verify that price aggregation actually occurred? Is there proof? Pyth’s answer is surprising yet logical—by building its own blockchain.
Surprising because in Pyth’s earlier V1 version, its tight coupling with Solana was evident—the oracle relied entirely on the Solana network for price submission, validation, and execution.
Logical because although price aggregation could be verified on Solana, if Solana went down or became congested due to resource-heavy applications (e.g., an NFT minting frenzy), Pyth’s oracle service would suffer collateral damage—causing delayed or failed price updates.
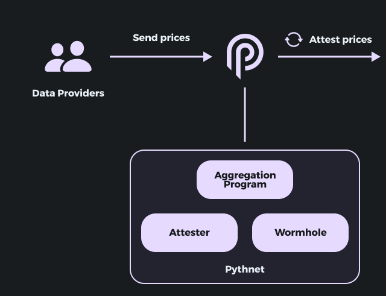
Figure: Pythnet architecture and role overview
In the newly released V2 version, Pyth now operates its own dedicated application chain: Pythnet. Pythnet is a fork of Solana—leveraging Solana’s high performance while remaining unaffected by Solana outages or congestion.
The basic operation of this chain involves aggregating price data submitted by providers, computing a composite price, and recording it on-chain. The entire calculation process is also performed on-chain, enabling easy verification of both process and outcome via blockchain—ensuring final price accuracy.
Additionally, data providers stake Pyth tokens to act as validators on this chain, responsible for verifying data authenticity and transactions. It remains unclear whether ordinary users can delegate their Pyth tokens to these nodes for rewards, but the dedicated chain design certainly expands potential utility for the token.
More importantly, Pythnet’s independent operation ensures oracle services remain unaffected by issues on other chains. Even during periods of high resource usage on target chains, Pyth can continue delivering price updates—its “dedicated chain for dedicated tasks” design strongly enhances service stability.
New Developments in Data Delivery: Cross-Chain Support, From “Push” to “Pull-on-Demand”
After securing abundant data sources and ensuring accuracy, we turn to how Pyth delivers these prices to applications in need.
Ultimately, oracle products are functionally similar—all aim to feed price data to applications. Differences in delivery methods, however, can create significant advantages in feed efficiency and cost.
So, what stands out about Pyth Network’s V2 data delivery approach?
We can break this down further: Who receives the data, and how is it delivered?
Regarding recipients, the most obvious advancement is cross-chain support. In Pyth’s original design, built on Solana, its price feeds primarily served Solana-based projects.
Binding an oracle to a single blockchain is no longer a viable long-term strategy in today’s rapidly evolving crypto landscape. The emergence of new L1s and L2s has driven demand for cross-chain DeFi deployments, posing challenges to oracle coverage.
Figure: Blockchains supported on Pyth’s official website
Thus, Pyth has actively embraced cross-chain functionality, now supporting not only Solana but also 12 major L1s and L2s—including recently popular ones like Arbitrum and zkSync Era.
But each chain has different technical characteristics and requirements—how does Pyth quickly deliver price data across diverse chains?
This is crucial—it touches on oracle feed model design and represents a key competitive edge for Pyth.
Traditional oracles typically use a “push” model:
- Data sources send data to the oracle;
- The oracle continuously pushes price updates to various blockchains at fixed intervals;
- On-chain DeFi protocols receive prices and execute accordingly.
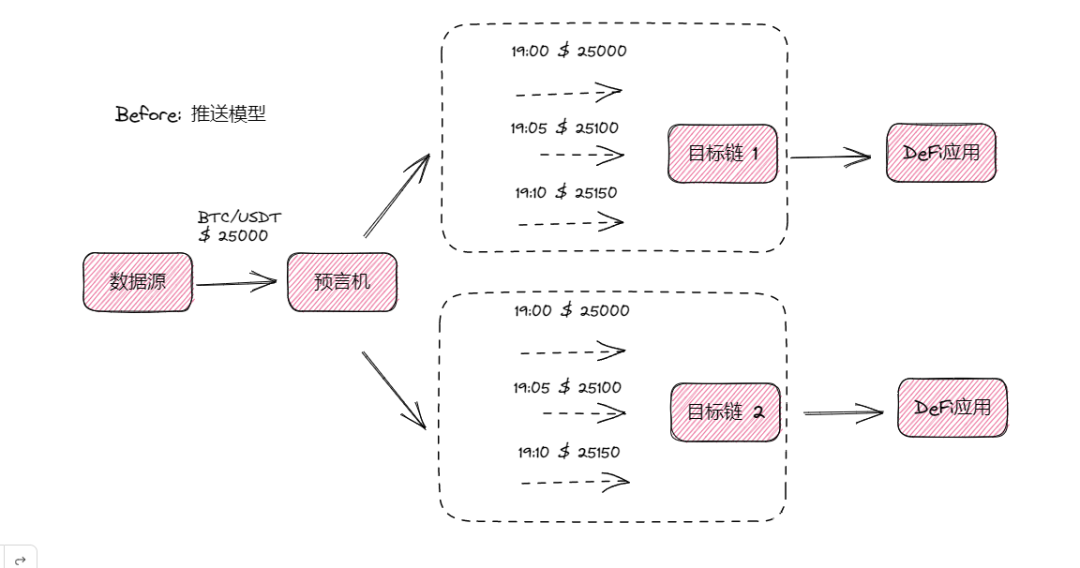
While intuitive, this model faces scalability and cost challenges:
Each price update requires gas fees, as pushing data on-chain incurs transaction costs.
Increasing update frequency raises costs proportionally. For example, if you need BTC/USDT, ETH/USDT, and DOGE/USDT prices on three chains, you’d pay nine separate fees per update cycle (one fee per pair per chain).
As DeFi protocols expand cross-chain or add more trading pairs, oracle costs grow exponentially. Moreover, network congestion increases the risk of delayed price feeds.
In contrast, Pyth Network’s V2 replaces passive “constant pushing” with active “pull-on-demand”:
- Data sources send data to the oracle;
- Price updates occur not on target chains, but on Pythnet;
- Blockchain mechanisms ensure these updates are authentic and valid;
- DeFi protocols pull prices from the target chain when needed;
- They receive prices and proceed with execution.
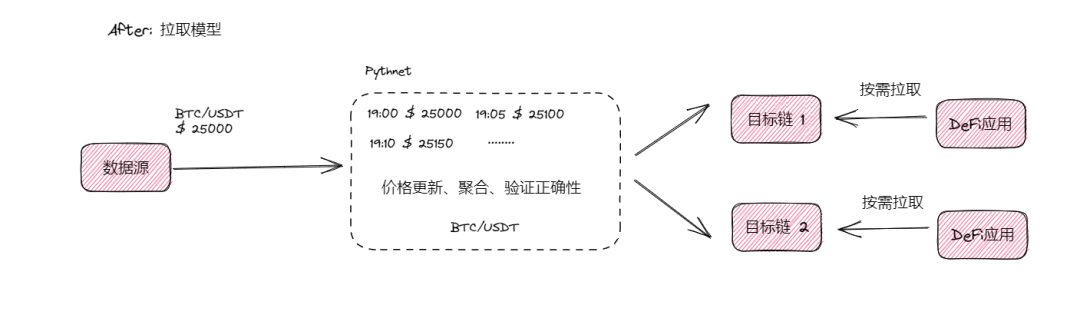
With pull-on-demand, fees are incurred only when a feed is used—eliminating continuous on-chain pushes. Delving deeper into Pyth’s actual implementation reveals significant scalability improvements:
- Prices aggregated and verified on Pythnet can be bridged across chains via Wormhole (a cross-chain messaging protocol);
- For the same type of price data, a single Wormhole bridge deployment suffices—even across different chains—requiring only one receiving smart contract per chain;
- Whenever a downstream app requests data, it sends a query to Wormhole, which then pulls the data from Pythnet and delivers it.
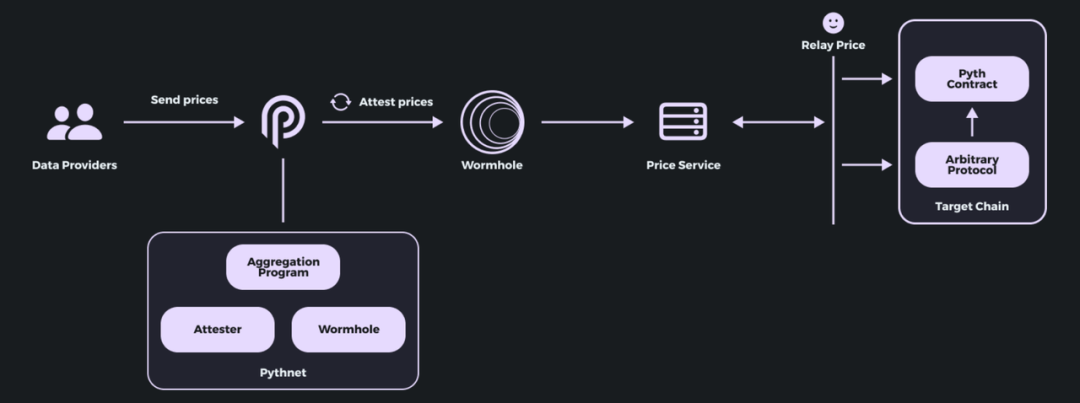
Figure: On-demand “pull”-based price feed workflow
As a result, any chain using Pyth’s price feeds only needs to deploy a compatible receiving contract—development and deployment costs are extremely low. These contracts essentially require only minor variations of a standardized data storage and cross-chain message handling model (especially for EVM chains), making deployment quick and easy (according to Pyth team members, typically under two weeks). Meanwhile, core feed logic—including performance optimizations and deep data integrations—remains centralized on Pythnet.
With on-demand access becoming reality, Pyth becomes highly attractive to downstream DeFi protocols. Developers naturally prefer focusing energy and resources on refining their own products rather than complex oracle integrations.
Moreover, this shift in feed model is expected to drive a transformation in business models:
Under traditional push models, DeFi protocols may sign subscription contracts with oracles, paying periodically for continuous data delivery—an off-chain negotiation process involving time and overhead.
In contrast, Pyth’s pull-on-demand model enables a truly Web3-native experience: you don’t need to contact Pyth’s sales team at all. Simply follow documentation and deploy a contract—you can start pulling price data automatically. The entire flow—contract trigger, gas payment, data retrieval, and usage—is fully automated, embodying a “permissionless” and “on-chain-first” philosophy.

Expanding Use Cases: Balancing Breadth and Depth, Focusing on Long-Tail DeFi Scenarios
Commonly, oracles are seen as solving the “availability” of price data. When evaluating oracles, “breadth” is often a key benchmark.
If an oracle serves many protocols, we consider it successful.
However, as competition intensifies, differentiation increasingly depends on “depth”:
Solving data availability defines the floor; the ceiling lies in adapting to more verticalized use cases.
Today’s DeFi protocols demand more than just raw prices—they want “data tailored to my specific use case.” In response, Pyth Network has been exploring deeper scenario adaptation.
In February this year, Pyth launched a new oracle product targeting DeFi liquidity risk forecasting and management: Liquidity Oracle V1.

Simply put, crypto asset prices in certain DeFi products can be significantly impacted by liquidity. If an asset has low liquidity, a large buy order could cause sharp price swings, potentially disrupting sensitive operations like high-frequency trading or perpetual contracts.
While standard oracles solve the “existence” of price data, liquidity oracles address the “existence” of risk alerts.
Pyth’s Liquidity Oracle provides liquidity metrics for various crypto assets, serving as a reference for DeFi products highly sensitive to liquidity shifts. When liquidity changes are anticipated, Pyth issues early warnings estimating the potential impact.
We won’t dive into technical details here—the more meaningful insight lies in risk management: as more DeFi use cases emerge, predicting future risks will become increasingly important.
In March, Pyth launched another product: Benchmarks.
Benchmarks functions as a historical data solution, allowing on- and off-chain apps to retrieve past Pyth price data.
With Pyth Benchmarks, Pyth Network created a database storing historical prices for over 200 assets and opened APIs for searching and retrieving this data.
This means DeFi projects using Pyth can access not only real-time data but also historical data via API—valuable for use cases requiring historical price references.
For example, Ribbon Finance, an options-focused platform, often needs historical prices for settlement. Suppose settlement occurs at 8:00 AM, but the oracle delays price delivery until 8:10 AM. Any price movement during those 10 minutes could introduce settlement errors.
Using Benchmarks solves this: Pyth updates prices at second-level granularity, with all historical data stored in the Benchmarks database. To settle at 8:00 AM, the protocol can request data seconds after 8:00, quickly retrieve the exact price, and initiate settlement—eliminating timing-related discrepancies.
Additionally, we learned that Pyth is currently collaborating with Synthetix to develop solutions addressing frontrunning and MEV issues caused by oracle latency.
Overall, by offering tailored price feeds for specialized data needs and targeting long-tail markets, Pyth demonstrates where its future growth potential truly lies.
Conclusion
Partnerships with top DeFi protocols, cross-chain service expansion, and multi-scenario adaptability all reflect Pyth Network’s growing ecosystem reach. By decoupling from Solana and building its own Pythnet, the project gains greater flexibility.
Considering Pyth is not yet the #1 oracle, it will likely employ incentives to encourage broader adoption. DeFi protocols and data providers may benefit from early collaboration, potentially accessing subsidies and incentive programs.
For end users, all these improvements in product capabilities, expanding partnerships, and future plans ultimately converge on Pyth’s token.
Public information indicates the Pyth token will primarily be used for gas fee payments, revenue sharing, and governance rights.
Given strong token expectations and positive fundamentals, users can consider joining its Discord community early and engaging in typical activities—building reputation, participating in events—to increase chances of potential airdrops and privileges.
In the last bull cycle, we witnessed LINK’s rapid rise. In this new cycle, infrastructure builders like oracles may stay behind the scenes, but we have every reason to believe these enablers of DeFi will eventually step into their own spotlight.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













