

Celer: Pantheon - ZKP Development Framework Evaluation Platform
TechFlow Selected TechFlow Selected
Celer: Pantheon - ZKP Development Framework Evaluation Platform
Performance test results of SHA-256 across various zk-SNARK and zk-STARK development frameworks.

Over the past few months, we have invested significant time and effort into developing cutting-edge infrastructure built on succinct zk-SNARK proofs. This next-generation innovation platform enables developers to build unprecedented blockchain application paradigms.
During our development process, we tested and used various zero-knowledge proof (ZKP) development frameworks. While this journey has been insightful, we also realized that the wide variety of ZKP frameworks often presents challenges for new developers trying to identify the most suitable framework for their specific use case and performance requirements. Recognizing this pain point, we believe there is a need for a community-driven evaluation platform that provides comprehensive performance benchmarking results—this would greatly accelerate the development of these new applications.
To address this need, we are launching Pantheon, a public-interest community initiative for benchmarking ZKP development frameworks. The first step of this initiative will encourage the community to share reproducible performance test results across various ZKP frameworks. Our ultimate goal is to collaboratively create and maintain a widely recognized benchmarking platform evaluating low-level circuit development frameworks, high-level zkVMs and compilers, and even hardware acceleration providers. We hope this effort will give developers better performance comparison references when selecting frameworks, thereby accelerating ZKP adoption. At the same time, by providing a set of universally referable performance benchmarks, we aim to drive improvements and iterations within the ZKP frameworks themselves. We will heavily invest in this initiative and invite all like-minded community members to join us in contributing to this work!
Step One: Performance Testing Circuit Frameworks Using SHA-256
In this article, we take the first step toward building ZKP Pantheon by providing a set of reproducible performance test results using SHA-256 across a series of low-level circuit development frameworks. While we acknowledge other performance test granularities and primitives might be viable, we chose SHA-256 because it applies to a broad range of ZKP use cases, including blockchain systems, digital signatures, zkDID, and more.
Also worth noting—we use SHA-256 extensively in our own systems too, so this was convenient for us! 😂
Our performance tests evaluate SHA-256 performance across various zk-SNARK and zk-STARK circuit development frameworks. Through comparative analysis, we aim to provide developers with insights into each framework’s efficiency and practicality. We hope these benchmarking results can guide developers in making informed decisions when choosing the optimal framework.
Proof Systems
In recent years, we've observed an explosion in zero-knowledge proof systems. Keeping up with all the exciting advancements in this field is challenging. We carefully selected the following proof systems based on maturity and developer adoption, aiming to provide representative samples across different frontend/backend combinations.
-
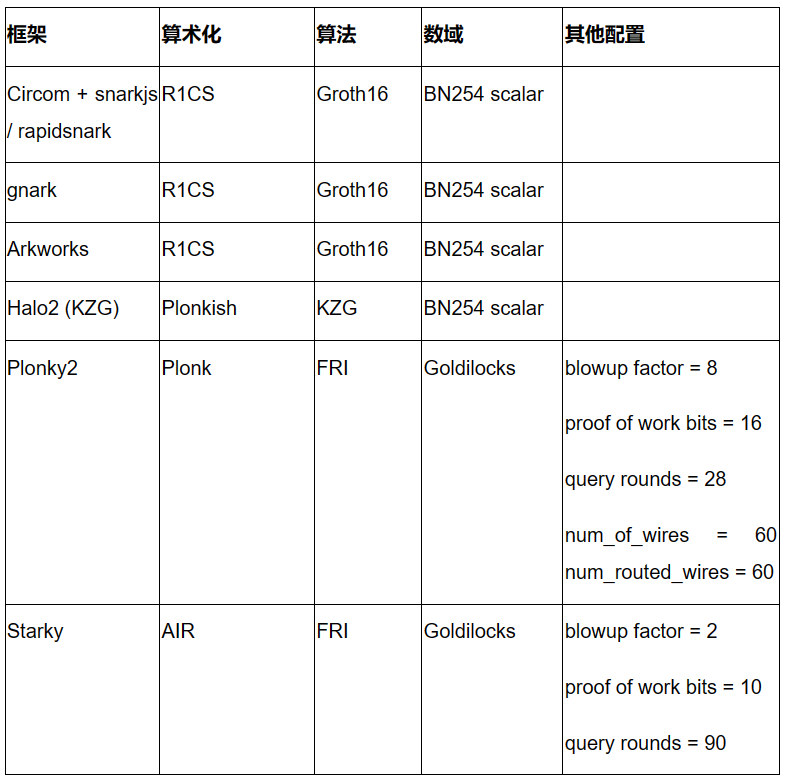
Circom + snarkjs / rapidsnark: Circom is a popular DSL for writing circuits and generating R1CS constraints, while snarkjs enables Groth16 or Plonk proof generation from Circom. Rapidsnark is another prover for Circom that generates Groth16 proofs and is typically much faster than snarkjs due to ADX extensions and aggressive parallelization of proof generation.
-
gnark: gnark is a comprehensive Golang framework from Consensys supporting Groth16, Plonk, and many advanced features.
-
Arkworks: Arkworks is a comprehensive Rust framework for zk-SNARKs.
-
Halo2 (KZG): Halo2 is Zcash's zk-SNARK implementation combining Plonk with KZG commitments. It features highly flexible Plonkish arithmetic, supporting useful primitives such as custom gates and lookup tables. We used a fork of Halo2 supported by the Ethereum Foundation and Scroll, leveraging KZG commitments.
-
Plonky2: Plonky2 is a SNARK implementation based on PLONK and FRI technologies from Polygon Zero. Plonky2 uses a small Goldilocks field and supports efficient recursion. In our performance tests, we targeted ~100 bits of conjectured security and used parameters yielding the best proof times. Specifically, we used 28 Merkle queries, a blowup factor of 8, and a 16-bit proof-of-work challenge. Additionally, we set num_of_wires = 60 and num_routed_wires = 60.
-
Starky: Starky is Polygon Zero’s high-performance STARK framework. In our performance tests, we targeted ~100 bits of conjectured security and used parameters producing the best proof times. Specifically, we used 90 Merkle queries, a blowup factor of 2, and a 10-bit proof-of-work challenge.
The table below summarizes the above frameworks and their corresponding configurations used in our performance tests. This list is by no means exhaustive, and we plan to study many state-of-the-art frameworks/techniques in the future (e.g., Nova, GKR, Hyperplonk).
Note that these performance test results apply only to circuit development frameworks. We plan to publish a separate article in the future benchmarking different zkVMs (e.g., Scroll, Polygon zkEVM, Consensys zkEVM, zkSync, Risc Zero, zkWasm) and IR compiler frameworks (e.g., Noir, zkLLVM).
Performance Benchmarking Methodology
To benchmark these different proof systems, we computed the SHA-256 hash of N bytes of data, experimenting with N = 64, 128, ..., 64K (with the exception of Starky, where the circuit repeats SHA-256 computation on a fixed 64-byte input but maintains the same total number of message blocks). Performance code and SHA-256 circuit configurations are available in this repository.
Additionally, we evaluated each system using the following performance metrics:
-
Proof generation time (including witness generation time)
-
Peak memory usage during proof generation
-
Average CPU utilization percentage during proof generation. (This metric reflects the degree of parallelization during proof generation.)
Note that we are making some “casual” assumptions about proof size and verification cost, as these aspects can be mitigated by combining with Groth16 or KZG before going on-chain.
Machines
We conducted performance tests on two different machines:
-
Linux Server: 20 cores @2.3 GHz, 384GB RAM
-
MacBook M1 Pro: 10 cores @3.2GHz, 16GB RAM
The Linux server simulates a scenario with abundant CPU cores and memory. The MacBook M1 Pro, commonly used for development, has a more powerful CPU but fewer cores.
We enabled optional multithreading but did not use GPU acceleration in these performance tests. We plan to conduct GPU performance testing in the future.
Performance Test Results
Number of Constraints
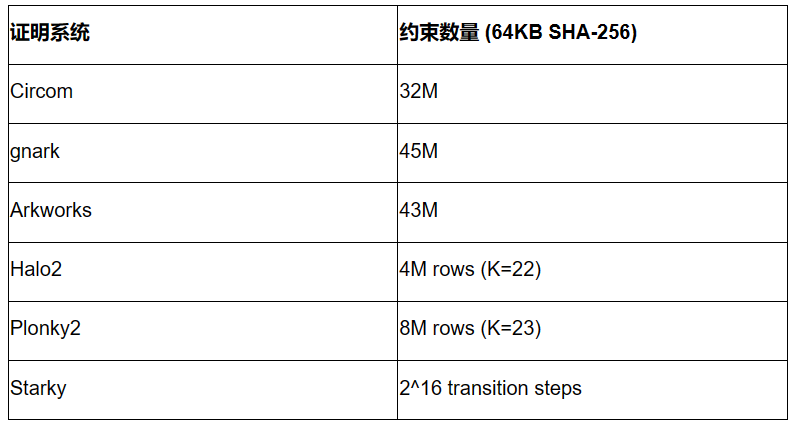
Before diving into detailed performance results, it is useful to understand the complexity of SHA-256 by examining the number of constraints in each proof system. Importantly, constraint counts across different arithmetization schemes cannot be directly compared.
The results below correspond to a 64KB preimage size. While results may vary with other preimage sizes, they roughly scale linearly.
-
Circom, gnark, and Arkworks all use the same R1CS arithmetization, resulting in approximately 30M to 45M R1CS constraints for computing SHA-256 on 64KB inputs. Differences among Circom, gnark, and Arkworks may stem from configuration variations.
-
Halo2 and Plonky2 both use Plonkish arithmetic, with row counts ranging from 2^22 to 2^23. Due to the use of lookup tables, Halo2’s SHA-256 implementation is significantly more efficient than Plonky2’s.
-
Starky uses AIR arithmetization, where the execution trace table requires 2^16 transition steps.
Proof Generation Time
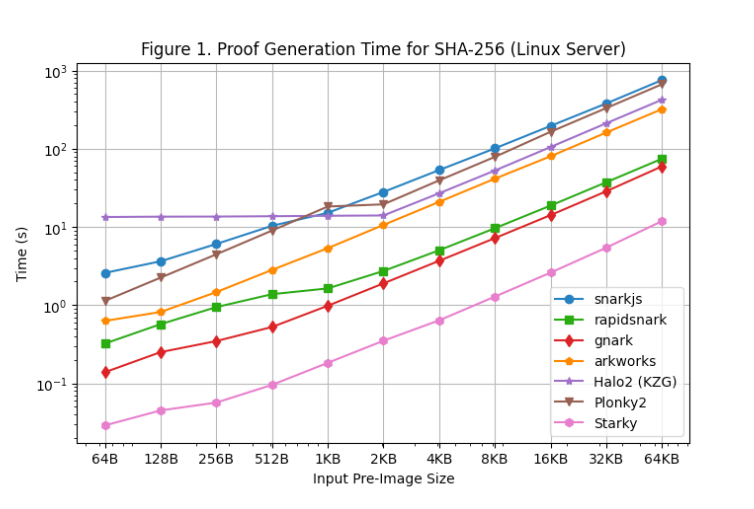
[Figure 1] shows proof generation times across each framework for various preimage sizes on the Linux server. Key findings include:
-
For SHA-256, Groth16 frameworks (rapidsnark, gnark, and Arkworks) generate proofs faster than Plonk frameworks (Halo2 and Plonky2). This is because SHA-256 primarily consists of bit operations, where wire values are 0 or 1. For Groth16, this reduces much of the computation from elliptic curve scalar multiplication to point addition. However, wire values are not directly used in Plonk computations, so the special wiring structure in SHA-256 does not reduce computational load in Plonk frameworks.
-
Among all Groth16 frameworks, gnark and rapidsnark are 5–10x faster than Arkworks and snarkjs, thanks to their superior ability to parallelize proof generation across multiple cores. Gnark is 25% faster than rapidsnark.
-
For Plonk frameworks, when using larger preimage sizes (≥4KB), Plonky2’s SHA-256 is 50% slower than Halo2’s. This is because Halo2’s implementation leverages lookup tables to accelerate bitwise operations, requiring half as many rows as Plonky2. However, if we compare Plonky2 and Halo2 with the same number of rows (e.g., Halo2 SHA-256 >2KB vs. Plonky2 SHA-256 >4KB), Plonky2 is 50% faster. If we implemented SHA-256 using lookup tables in Plonky2, we would expect it to outperform Halo2, despite having larger proof sizes.
-
On the other hand, when input preimage sizes are small (≤512 bytes), Halo2 is slower than Plonky2 (and others) due to the fixed setup cost of lookup tables dominating the constraint count. However, as preimage size increases, Halo2 becomes increasingly competitive, maintaining nearly constant proof generation time up to 2KB preimages, showing almost linear scalability as shown in the graph.
-
As expected, Starky’s proof generation time is significantly shorter (5x–50x) than any SNARK framework, albeit at the cost of much larger proof sizes.
-
It should also be noted that although circuit size scales linearly with preimage size, proof generation for SNARKs grows super-linearly due to O(n log n) FFTs (though this is not visibly apparent on the graph due to logarithmic scaling).
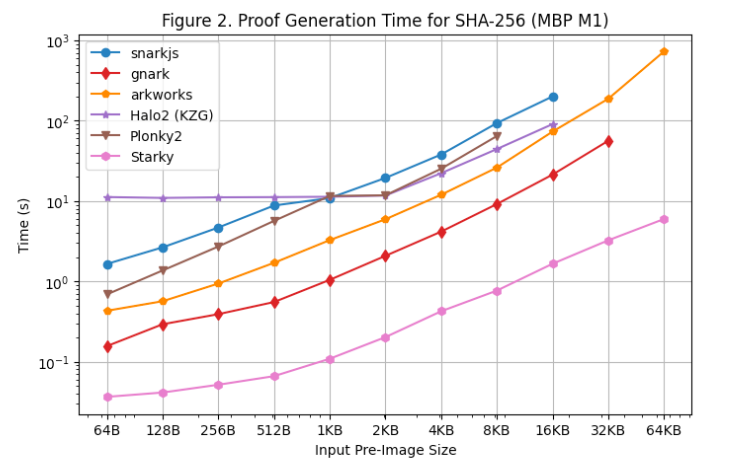
We also conducted proof generation time tests on the MacBook M1 Pro, as shown in [Figure 2]. Note, however, that rapidsnark was excluded from this test due to lack of arm64 support. To run snarkjs on arm64, we had to use WebAssembly for witness generation, which is slower than the C++ witness generation used on the Linux server.
Additional observations from running tests on the MacBook M1 Pro:
-
All SNARK frameworks except Starky encountered out-of-memory (OOM) errors or began swapping memory (slowing proof times) as preimage size increased. Specifically, Groth16 frameworks (snarkjs, gnark, Arkworks) started swapping at preimage sizes ≥8KB, with gnark encountering OOM at ≥64KB. Halo2 hit memory limits at ≥32KB. Plonky2 began swapping at ≥8KB.
-
FRI-based frameworks (Starky and Plonky2) were about 60% faster on the MacBook M1 Pro than on the Linux server, while other frameworks showed similar proof times across both machines. As a result, even without lookup tables, Plonky2 achieved nearly identical proof times to Halo2 on the MacBook M1 Pro. The main reason is that the MacBook M1 Pro has a more powerful CPU but fewer cores. FRI involves mostly hashing, which is sensitive to CPU clock cycles but less parallelizable than KZG or Groth16.
Peak Memory Usage
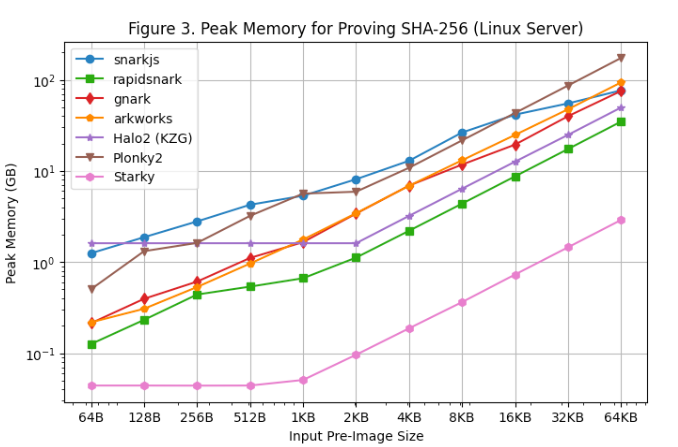
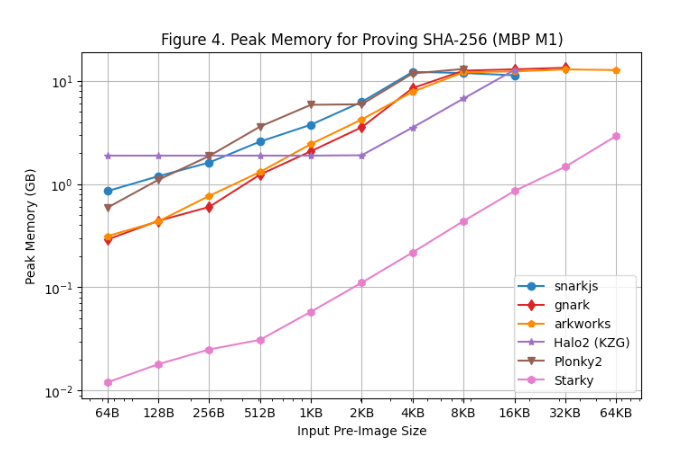
[Figure 3] and [Figure 4] show peak memory usage during proof generation on the Linux Server and MacBook M1 Pro, respectively. Key observations:
-
Among all SNARK frameworks, rapidsnark is the most memory-efficient. We also observe that Halo2 uses more memory for small preimages due to the fixed setup cost of lookup tables, but consumes less overall memory for large preimages.
-
Starky is over 10x more memory-efficient than SNARK frameworks, partly due to using fewer rows.
-
Note that due to memory swapping, peak memory usage on the MacBook M1 Pro remains relatively flat as preimage size increases.
CPU Utilization
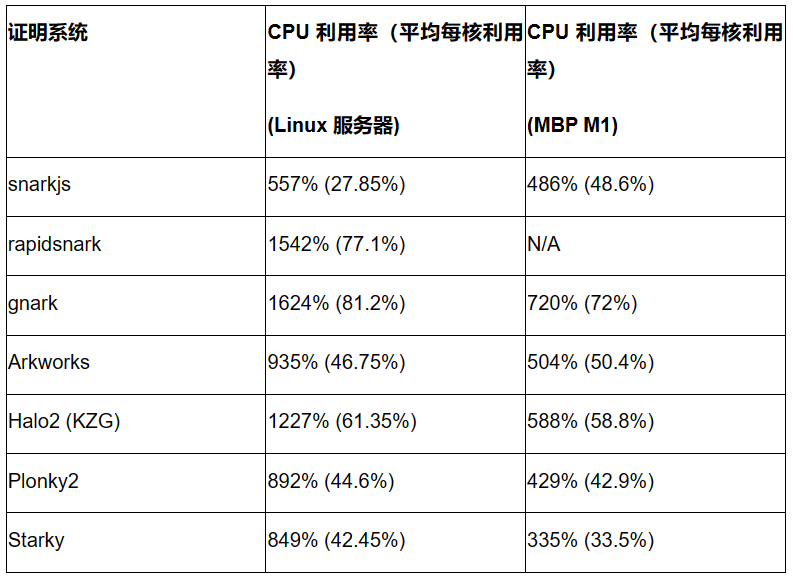
We assessed the degree of parallelization in each proof system by measuring average CPU utilization during proof generation for a 4KB preimage input. The table below shows average CPU utilization on the Linux Server (20 cores) and MacBook M1 Pro (10 cores) (with per-core average utilization in parentheses).
Key observations:
-
Gnark and rapidsnark show the highest CPU utilization on the Linux server, indicating effective multi-core usage and parallelized proof generation. Halo2 also demonstrates strong parallelization performance.
-
Most frameworks achieve roughly double the CPU utilization on the Linux server compared to the MacBook M1 Pro, with the exception of snarkjs.
-
Although FRI-based frameworks (Plonky2 and Starky) were initially expected to struggle with efficient multi-core utilization, they performed comparably to certain Groth16 or KZG frameworks in our tests. Whether CPU utilization differs on machines with more cores (e.g., 100 cores) remains to be seen.
Conclusion and Future Work
This article presents a comprehensive comparison of performance test results for SHA-256 across various zk-SNARK and zk-STARK development frameworks. Through this comparison, we gain insights into the efficiency and practicality of each framework, aiming to assist developers who need to generate succinct proofs for SHA-256 operations.
We found that Groth16 frameworks (e.g., rapidsnark, gnark) are faster in proof generation than Plonk frameworks (e.g., Halo2, Plonky2). Lookup tables in Plonkish arithmetization significantly reduce constraints and proof time for SHA-256 with large preimage sizes. Moreover, gnark and rapidsnark demonstrate excellent capability in leveraging multiple cores for parallelized operations. On the other hand, Starky achieves much shorter proof generation times at the cost of significantly larger proof sizes. In terms of memory efficiency, rapidsnark and Starky outperform other frameworks.
As the first step toward building the zero-knowledge proof benchmarking platform "Pantheon," we acknowledge that these performance test results are far from being the final comprehensive platform we envision. We welcome and appreciate feedback and criticism, and invite everyone to contribute to this initiative, making zero-knowledge proofs easier and more accessible to developers. We are also willing to provide funding support to individual contributors to cover computational resource costs for large-scale performance testing. We hope to collectively enhance the efficiency and practicality of ZKPs and benefit the broader community.
Finally, we extend our gratitude to the Polygon Zero team, the gnark team at Consensys, Pado Labs, and the Delphinus Lab team for their valuable reviews and feedback on our performance test results.
Join TechFlow official community to stay tuned
Telegram:https://t.me/TechFlowDaily
X (Twitter):https://x.com/TechFlowPost
X (Twitter) EN:https://x.com/BlockFlow_News













