

DeepSeek "đánh cắp" OpenAI? Nghe更像是賊喊捉賊
Tuyển chọn TechFlowTuyển chọn TechFlow
DeepSeek "đánh cắp" OpenAI? Nghe更像是賊喊捉賊
Chưng cất không phải là đạo văn, mà là phương tiện cần thiết cho sự phát triển công nghệ.
Tác giả: Đặng Vịnh Nghi, Trí tuệ Dâng trào

Hình ảnh: Được tạo bởi Wujie AI
Vào dịp Tết Nguyên đán 2025, điều gây sốt không chỉ có phim "Na Tra 2", mà còn có một ứng dụng mang tên DeepSeek —— Câu chuyện truyền cảm hứng này đã được kể đi kể lại nhiều lần: ngày 20 tháng 1, công ty khởi nghiệp AI DeepSeek (Shensuozhuiqiu) tại Hàng Châu đã ra mắt mô hình mới R1, nhắm tới mô hình suy luận mạnh nhất hiện nay của OpenAI là o1, thực sự tạo nên cơn chấn động toàn cầu.
Chỉ trong một tuần ra mắt, ứng dụng DeepSeek đã đạt hơn 20 triệu lượt tải, đứng đầu ở hơn 140 quốc gia. Tốc độ tăng trưởng vượt cả ChatGPT khi ra mắt năm 2022, hiện đã đạt khoảng 20% so với ChatGPT.
Nóng đến mức nào? Tính đến ngày 8 tháng 2, lượng người dùng DeepSeek đã vượt quá 100 triệu, đối tượng sử dụng không chỉ giới hạn ở các tín đồ công nghệ AI mà đã lan rộng từ Trung Quốc ra toàn cầu. Từ người già, trẻ em đến các diễn viên hài, chính trị gia, ai ai cũng đang bàn tán về DeepSeek.
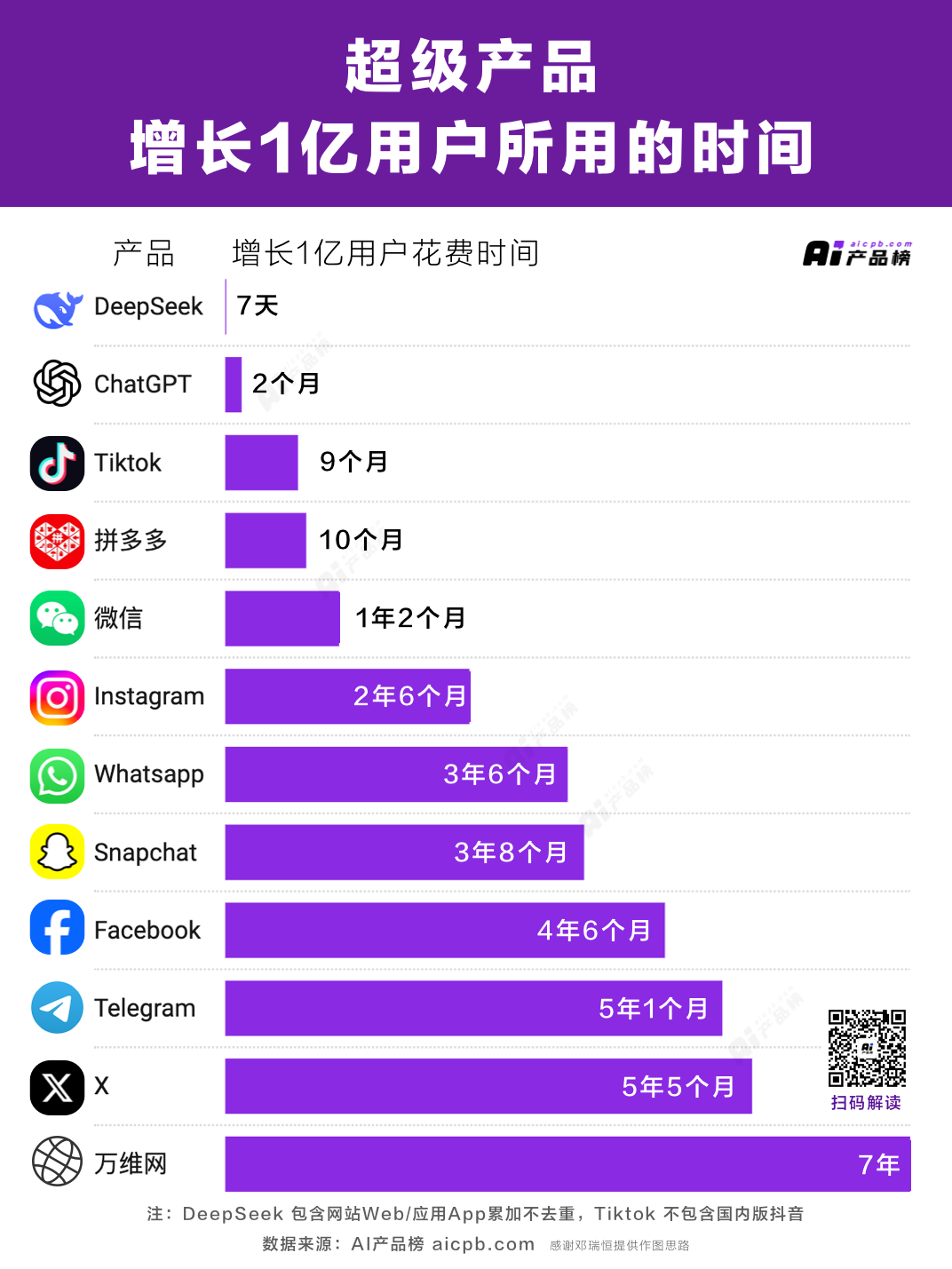
Tới tận bây giờ, cú sốc do DeepSeek mang lại vẫn chưa ngừng. Trong hai tuần qua, hành trình của DeepSeek giống như kịch bản TikTok – bùng nổ và tăng trưởng thần tốc, đánh bại nhiều đối thủ Mỹ, thậm chí khiến DeepSeek nhanh chóng đứng trên bờ vực chính trị địa lý: Mỹ và châu Âu bắt đầu thảo luận về “ảnh hưởng đến an ninh quốc gia”, nhiều khu vực nhanh chóng ban hành lệnh cấm tải hoặc cài đặt.
Marc Andreessen, đối tác tại A16Z, thậm chí thốt lên: Sự xuất hiện của DeepSeek là một khoảnh khắc “Sputnik” khác.
(Một thuật ngữ bắt nguồn từ thời kỳ Chiến tranh Lạnh, khi Liên Xô phóng thành công vệ tinh nhân tạo đầu tiên thế giới “Sputnik-1” vào năm 1957, gây ra làn sóng hoảng loạn trong xã hội Mỹ, nhận thức rõ vị thế của mình bị thách thức và ưu thế công nghệ có thể sụp đổ)
Nhưng càng nổi tiếng thì càng nhiều thị phi, trong giới công nghệ, DeepSeek cũng vướng phải những tranh cãi như “chưng cất”, “đánh cắp dữ liệu”, v.v.
Tính đến nay, DeepSeek chưa đưa ra bất kỳ phản hồi công khai nào, những tranh luận này cũng vì vậy rơi vào hai thái cực: những người ủng hộ cuồng nhiệt nâng DeepSeek-R1 lên tầm đổi vận quốc gia; đồng thời cũng có những chuyên gia công nghệ nghi ngờ chi phí huấn luyện siêu thấp và phương pháp đào tạo bằng chưng cất, cho rằng những đổi mới này đang bị thổi phồng quá mức.
Deepseek “đánh cắp” OpenAI? Thật ra giống như kẻ trộm kêu bắt trộm
Gần như ngay từ lúc DeepSeek trở nên nổi tiếng, các gã khổng lồ AI ở Thung lũng Silicon như OpenAI, Microsoft lần lượt lên tiếng, trọng tâm cáo buộc đều tập trung vào dữ liệu của DeepSeek. David Sacks, quan chức phụ trách AI và mã hóa của chính phủ Mỹ, cũng công khai cho biết DeepSeek đã “hút” tri thức từ ChatGPT thông qua một kỹ thuật gọi là chưng cất.
Theo bài báo trên tờ Financial Times (Anh), OpenAI cho biết họ đã phát hiện dấu hiệu DeepSeek “chưng cất” ChatGPT, đồng thời khẳng định điều này vi phạm thỏa thuận sử dụng mô hình của OpenAI. Tuy nhiên, OpenAI không đưa ra bằng chứng cụ thể nào.
Thực tế, đây là một cáo buộc không vững chắc.
Chưng cất là một kỹ thuật huấn luyện mô hình lớn bình thường. Phương pháp này thường xảy ra trong giai đoạn huấn luyện mô hình – sử dụng kết quả đầu ra của một mô hình lớn và mạnh hơn (mô hình thầy giáo) để giúp mô hình nhỏ hơn (mô hình học sinh) học cách cải thiện hiệu suất. Trên các nhiệm vụ cụ thể, mô hình nhỏ có thể đạt được kết quả tương tự với chi phí thấp hơn.
Chưng cất không phải là đạo văn. Giải thích theo cách通俗, chưng cất giống như việc một giáo viên giải tất cả các bài toán khó, sau đó tổng hợp thành một cuốn sổ tay giải bài hoàn hảo – trong cuốn sổ tay này không chỉ có đáp án, mà còn ghi lại các cách giải tối ưu; học sinh bình thường (mô hình nhỏ) chỉ cần học trực tiếp cuốn sổ tay này, sau đó đưa ra câu trả lời của riêng mình, rồi so sánh xem câu trả lời có phù hợp với cách suy luận từng bước trong sổ tay của giáo viên hay không.
Đóng góp nổi bật nhất của DeepSeek nằm ở chỗ trong quá trình này, họ sử dụng nhiều hơn phương pháp học không giám sát – nghĩa là để máy tự phản hồi, giảm thiểu phản hồi con người (RLHF). Kết quả trực tiếp nhất là chi phí huấn luyện mô hình giảm mạnh – cũng chính là lý do dẫn đến nhiều lời chất vấn.
Bài báo về DeepSeek-V3 từng đề cập quy mô cụ thể cụm huấn luyện mô hình V3 (2048 chip H800). Nhiều người ước tính theo giá thị trường, số tiền này khoảng 5,5 triệu USD, tương đương chỉ bằng một phần mười chi phí huấn luyện mô hình của Meta, Google, v.v.
Nhưng cần lưu ý rằng, DeepSeek đã ghi rõ trong bài báo rằng đây chỉ là chi phí chạy đơn lẻ cho lần huấn luyện cuối cùng, chưa bao gồm thiết bị ban đầu, nhân sự và hao mòn trong quá trình huấn luyện.
Trong lĩnh vực AI, chưng cất không phải là điều mới lạ, nhiều nhà sản xuất mô hình đã từng tiết lộ công việc chưng cất của họ. Ví dụ, Meta từng công bố cách chưng cất mô hình của mình – Llama 2 sử dụng mô hình lớn hơn, thông minh hơn để tạo ra dữ liệu chứa quá trình suy nghĩ, phương pháp tư duy, sau đó đưa vào mô hình suy luận quy mô nhỏ hơn của họ để tinh chỉnh.
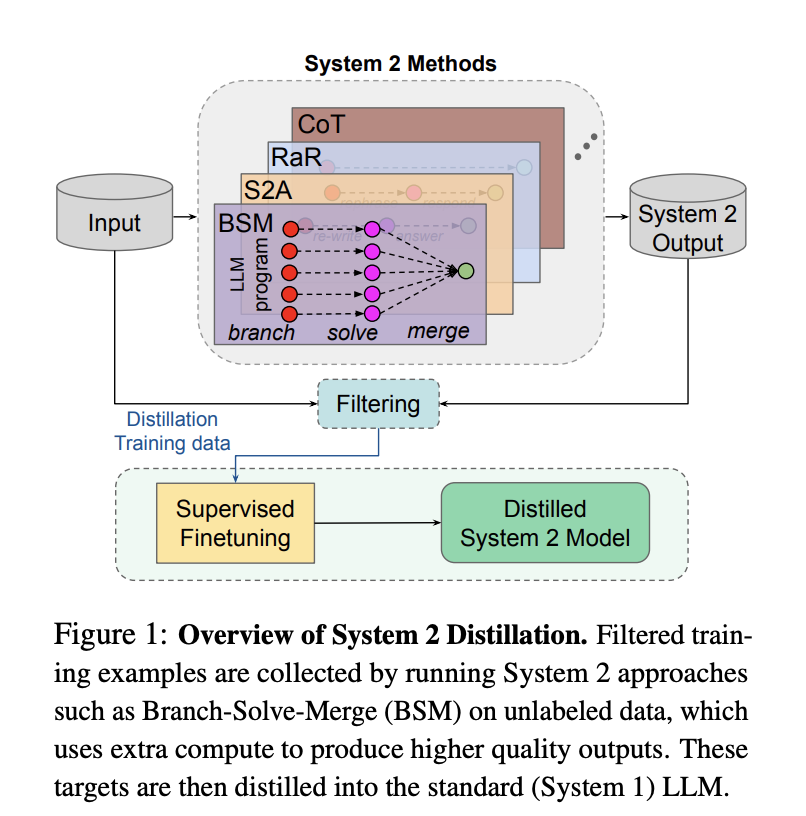
△ Nguồn: Meta FAIR
Nhưng chưng cất cũng có nhược điểm.
Một chuyên gia làm ứng dụng AI tại công ty lớn cho biết với Trí tuệ Dâng trào, chưng cất có thể giúp khả năng mô hình tăng nhanh, nhưng nhược điểm là dữ liệu do “mô hình thầy giáo” tạo ra quá sạch sẽ, thiếu tính đa dạng. Học loại dữ liệu này, mô hình sẽ giống như một món “ăn liền” chuẩn mực, khả năng cũng không thể vượt qua mô hình thầy giáo.
Chất lượng dữ liệu phần lớn quyết định hiệu quả huấn luyện mô hình. Nếu chọn dùng chưng cất để hoàn thành phần lớn quá trình huấn luyện, ngược lại sẽ khiến mô hình trở nên quá đồng nhất. Hiện nay các mô hình lớn trên toàn cầu đã rất phong phú, mỗi bên đều cung cấp “phiên bản tinh túy” của riêng mình, chưng cất một mô hình giống hệt sẽ không có nhiều ý nghĩa.
Vấn đề nghiêm trọng hơn là hiện tượng ảo giác có thể trở nên trầm trọng hơn. Bởi vì mô hình nhỏ chỉ bắt chước “bề ngoài” của mô hình lớn ở một mức độ nào đó, khó hiểu sâu logic phía sau, dễ dẫn đến suy giảm hiệu suất trên các nhiệm vụ mới.
Vì vậy, nếu muốn mô hình có đặc điểm riêng, các kỹ sư AI cần can thiệp từ giai đoạn dữ liệu – lựa chọn dữ liệu nào, tỷ lệ dữ liệu, cũng như phương pháp huấn luyện, đều khiến mô hình cuối cùng huấn luyện ra trở nên rất khác biệt.
Một ví dụ điển hình là OpenAI và Anthropic hiện nay. OpenAI và Anthropic là những công ty Silicon Valley đầu tiên làm mô hình lớn, cả hai bên đều không có sẵn mô hình để chưng cất, mà trực tiếp thu thập và học từ mạng internet công khai và các bộ dữ liệu.
Các con đường học tập khác nhau cũng dẫn đến phong cách của hai mô hình hiện nay có sự khác biệt rõ rệt – hiện tại, ChatGPT giống như một sinh viên kỹ thuật nghiêm túc, giỏi giải quyết các vấn đề trong cuộc sống và công việc; trong khi Claude lại giỏi về lĩnh vực xã hội nhân văn, được công nhận là vua về uy tín trong các nhiệm vụ viết lách, nhưng cũng không hề kém cạnh trong các nhiệm vụ lập trình.
Sự mỉa mai khác trong cáo buộc của OpenAI là dùng một điều khoản mơ hồ để buộc tội DeepSeek, dù bản thân họ cũng từng làm điều tương tự.
Từ khi thành lập, OpenAI luôn là một tổ chức hướng tới mã nguồn mở, nhưng sau GPT-4 thì chuyển sang đóng nguồn. Việc huấn luyện của OpenAI gần như quét sạch dữ liệu từ internet công khai toàn cầu. Do đó, sau khi chọn đóng nguồn, OpenAI cũng luôn vướng vào các tranh chấp bản quyền với các cơ quan truyền thông, nhà xuất bản.
Cáo buộc “chưng cất” của OpenAI đối với DeepSeek bị chế giễu là “kẻ trộm kêu bắt trộm”, bởi vì dù là OpenAI o1 hay DeepSeek R1, trong bài báo đều không tiết lộ chi tiết về chuẩn bị dữ liệu, vấn đề này vẫn tồn tại như một bí ẩn chưa có lời giải.
Thậm chí hơn nữa, khi ra mắt, DeepSeek-R1 thậm chí chọn giấy phép mã nguồn mở MIT – gần như là giấy phép mã nguồn mở thoải mái nhất. DeepSeek-R1 cho phép thương mại hóa, cho phép chưng cất, còn cung cấp cho công chúng sáu mô hình nhỏ đã được chưng cất, người dùng có thể triển khai trực tiếp lên điện thoại, PC, là hành động rất chân thành nhằm trả ơn cộng đồng mã nguồn mở.
Ngày 5 tháng 2, cựu giám đốc nghiên cứu của Stability AI, Tanishq Mathew Abraham cũng viết riêng một bài báo, chỉ ra rằng cáo buộc này nằm trong vùng xám: trước hết, OpenAI không đưa ra bằng chứng nào cho thấy DeepSeek trực tiếp sử dụng GPT để chưng cất. Ông đoán một khả năng là DeepSeek đã tìm được bộ dữ liệu được tạo bởi ChatGPT (trên thị trường hiện đã có rất nhiều), và tình huống này chưa bị OpenAI cấm rõ ràng.
Chưng cất có phải là tiêu chuẩn để phán xét việc làm AGI hay không?
Trên sân khấu dư luận, hiện nay nhiều người dùng bước “có chưng cất hay không” để phân biệt việc sao chép hay làm AGI, điều này thật sự quá độc đoán.
Công việc của DeepSeek đã làm sống lại khái niệm “chưng cất”, thực tế đây là công nghệ đã xuất hiện gần mười năm trước.
Năm 2015, trong bài báo “Distilling the Knowledge in a Neural Network” do một số chuyên gia AI hàng đầu như Hinton, Oriol Vinyals, Jeff Dean đồng tác giả, lần đầu tiên chính thức đề xuất kỹ thuật “chưng cất tri thức” trong mô hình lớn, từ đó trở thành tiêu chuẩn trong lĩnh vực mô hình lớn sau này.
Đối với các nhà sản xuất mô hình tập trung vào lĩnh vực, nhiệm vụ cụ thể, chưng cất thực ra là một con đường thực tế hơn.
Một chuyên gia AI nói với Trí tuệ Dâng trào rằng, ở Trung Quốc gần như không có mấy nhà sản xuất mô hình lớn nào không dùng chưng cất, đây gần như là một bí mật công khai. “Hiện nay dữ liệu từ mạng công khai gần như đã cạn kiệt, chi phí làm tiền huấn luyện và gắn nhãn dữ liệu từ con số 0, ngay cả các công ty lớn cũng khó lòng dễ dàng gánh vác.”
Một ngoại lệ là ByteDance. Trong phiên bản DouBao 1.5 pro ra mắt gần đây, ByteDance tuyên bố rõ ràng “trong quá trình huấn luyện chưa từng sử dụng bất kỳ dữ liệu nào do mô hình khác tạo ra, kiên quyết không đi con đường tắt chưng cất”, thể hiện quyết tâm theo đuổi AGI.
Việc các công ty lớn chọn không chưng cất có lý do thực tiễn, chẳng hạn tránh được nhiều tranh chấp pháp lý sau này. Trong điều kiện đóng nguồn, điều này cũng tạo ra một bức tường ngăn nhất định cho năng lực mô hình. Theo tìm hiểu của Trí tuệ Dâng trào, chi phí gắn nhãn dữ liệu hiện nay của ByteDance đã đạt mức ngang hàng với các công ty Silicon Valley – cao nhất có thể lên tới 200 đô la Mỹ mỗi mục, loại dữ liệu chất lượng cao này đòi hỏi các chuyên gia trong từng lĩnh vực cụ thể, chẳng hạn nhân tài trình độ thạc sĩ, tiến sĩ trở lên, để gắn nhãn.
Đối với nhiều bên tham gia hơn trong lĩnh vực AI, dù dùng chưng cất hay các phương pháp kỹ thuật khác, về bản chất đều là một dạng khám phá ranh giới của Scaling Law (luật hiệu ứng quy mô). Đây là điều kiện cần, chứ không phải điều kiện đủ để khám phá AGI.
Hai năm đầu tiên mô hình lớn bùng nổ, Scaling Law thường bị hiểu một cách thô sơ là “dùng sức mạnh tạo nên điều kỳ diệu”, tức là dồn thêm năng lực tính toán, tham số, trí tuệ sẽ tự nhiên xuất hiện, điều này chủ yếu xảy ra trong giai đoạn tiền huấn luyện.
Phía sau cuộc tranh luận nóng bỏng về “chưng cất” hiện nay, ẩn chứa sự thay đổi trong mô hình phát triển mô hình lớn: Scaling Law vẫn tồn tại, nhưng đã thực sự chuyển từ giai đoạn tiền huấn luyện sang giai đoạn hậu huấn luyện và suy luận.
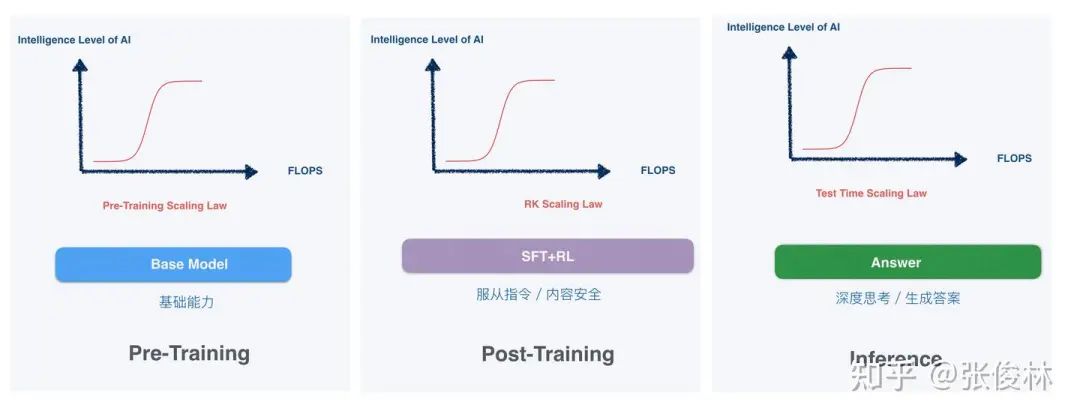
△ Nguồn: Bài chuyên mục của Tiến sĩ Trương Tuấn Lâm, Viện Nghiên cứu Phần mềm, Viện Khoa học Trung Quốc
OpenAI o1 được ra mắt vào tháng 9 năm 2024, được coi là dấu hiệu Scaling Law chuyển sang hậu huấn luyện và suy luận, hiện vẫn là mô hình suy luận tiên tiến nhất toàn cầu. Nhưng vấn đề nằm ở chỗ, OpenAI chưa bao giờ công bố phương pháp và chi tiết huấn luyện, chi phí ứng dụng vẫn duy trì ở mức cao: chi phí o1 pro lên tới 200 đô la/tháng, đồng thời tốc độ suy luận còn chậm, điều này也被 coi là một trở ngại lớn đối với phát triển ứng dụng AI.
Trong giai đoạn này, phần lớn công việc trong giới AI là tái hiện hiệu quả của o1, đồng thời cần giảm chi phí suy luận, mới có thể ứng dụng trong nhiều tình huống hơn. Ý nghĩa then chốt của DeepSeek không chỉ đến từ việc rút ngắn đáng kể thời gian mô hình mã nguồn mở đuổi kịp mô hình đóng đỉnh cao – chỉ mất khoảng ba tháng, đã gần như đuổi kịp nhiều chỉ số của o1; quan trọng hơn là tìm ra bí quyết then chốt giúp o1 nhảy vọt về năng lực, và công khai nó.
Một tiền đề lớn không thể bỏ qua là DeepSeek đã hoàn thành đổi mới này bằng cách đứng trên vai những người khổng lồ. Chỉ coi các phương pháp kỹ thuật như “chưng cất” là đi đường tắt thì quá hẹp hòi, đây thực chất là chiến thắng của văn hóa mã nguồn mở.
Hệ sinh thái cùng phát triển và hiệu ứng mã nguồn mở do DeepSeek mang lại đã nhanh chóng hiện hữu. Không lâu sau khi gây sốt, một công trình mới của “bà mẹ AI” Lý Phi Phi cũng nhanh chóng viral: sử dụng Gemini thuộc Google làm “mô hình thầy giáo”, Qwen2.5 của Alibaba sau tinh chỉnh làm “mô hình học sinh”, thông qua chưng cất và các phương pháp khác, chỉ với dưới 50 đô la, đã huấn luyện thành công mô hình suy luận s1, tái hiện năng lực của DeepSeek-R1 và OpenAI-o1.
NVIDIA cũng là một ví dụ điển hình. Sau khi DeepSeek-R1 ra mắt, mặc dù vốn hóa thị trường NVIDIA một đêm bốc hơi khoảng 600 tỷ đô la Mỹ,创下 kỷ lục sụt giảm lớn nhất trong ngày trong lịch sử, nhưng ngay ngày hôm sau đã nhanh chóng phục hồi mạnh mẽ, tăng khoảng 9% – thị trường vẫn phổ biến kỳ vọng vào nhu cầu suy luận mạnh mẽ mà R1 mang lại.
Có thể dự đoán, sau khi các bên trong lĩnh vực mô hình lớn hấp thụ năng lực của R1, một làn sóng đổi mới ứng dụng AI sẽ nhanh chóng xuất hiện.
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News













