

Ghi chú podcast | Đối thoại cùng người sáng lập Gensyn: Tận dụng mạng lưới phi tập trung để tối đa hóa tài nguyên tính toán nhàn rỗi, thúc đẩy học máy
Tuyển chọn TechFlowTuyển chọn TechFlow
Ghi chú podcast | Đối thoại cùng người sáng lập Gensyn: Tận dụng mạng lưới phi tập trung để tối đa hóa tài nguyên tính toán nhàn rỗi, thúc đẩy học máy
Blockchain cung cấp một cách thức để loại bỏ nhu cầu về một người ra quyết định duy nhất hoặc trọng tài, vì nó có khả năng đạt được sự đồng thuận giữa các nhóm lớn.
Thực hiện & Biên dịch: Sunny, TechFlow
Giao thức tính toán AI trên blockchain Gensyn ngày 12 tháng 6 đã công bố hoàn thành vòng gọi vốn Series A trị giá 43 triệu USD do a16z dẫn đầu.
Sứ mệnh của Gensyn là cung cấp cho người dùng quyền truy cập vào quy mô tính toán tương đương với việc sở hữu cụm máy tính riêng, và quan trọng nhất là đảm bảo quyền truy cập công bằng, tránh bị kiểm soát hoặc đóng cửa bởi bất kỳ thực thể trung tâm nào. Đồng thời, Gensyn là một giao thức tính toán phi tập trung tập trung vào việc huấn luyện các mô hình học máy.
Nhìn lại podcast cuối năm ngoái giữa các nhà sáng lập Gensyn Harry và Ben với Epicenter, có thể thấy họ đã đi sâu vào khảo sát nguồn lực tính toán, bao gồm AWS, cơ sở hạ tầng tại chỗ và cơ sở hạ tầng đám mây, nhằm tìm hiểu cách tối ưu hóa và tận dụng những nguồn lực này để hỗ trợ sự phát triển của các ứng dụng AI.
Họ cũng thảo luận chi tiết về triết lý thiết kế, mục tiêu và định vị thị trường của Gensyn, cũng như các ràng buộc, giả định và chiến lược thực thi khác nhau mà họ phải đối mặt trong quá trình thiết kế.
Trong podcast, họ giới thiệu bốn vai trò chính trong mạng lưới ngoài chuỗi của Gensyn, khám phá đặc điểm của mạng lưới trên chuỗi Gensyn, cũng như tầm quan trọng của token và quản trị Gensyn.
Ngoài ra, Ben và Harry cũng chia sẻ một số kiến thức thú vị về AI, giúp mọi người hiểu sâu hơn về các nguyên lý cơ bản và ứng dụng của trí tuệ nhân tạo.

Người dẫn chương trình: Dr. Friederike Ernst, podcast Epicenter
Diễn giả: Ben Fielding & Harry Grieve, đồng sáng lập Gensyn
Tiêu đề gốc: 《Ben Fielding & Harry Grieve: Gensyn – The Deep Learning Compute Protocol》
Ngày phát sóng: 24 tháng 11 năm 2022
Blockchain như lớp tin cậy cho cơ sở hạ tầng AI phi tập trung
Người dẫn chương trình hỏi Ben và Harry vì sao họ quyết định kết hợp kinh nghiệm sâu rộng về AI và học sâu của mình với blockchain?
Ben cho biết quyết định này không diễn ra ngay lập tức mà trải qua một khoảng thời gian khá dài. Mục tiêu của Gensyn là xây dựng cơ sở hạ tầng AI quy mô lớn, khi nghiên cứu cách đạt được khả năng mở rộng tối đa, họ nhận ra cần một lớp không cần tin cậy.
Họ cần có khả năng tích hợp năng lực tính toán mà không phụ thuộc vào việc tiếp cận nhà cung cấp tập trung mới, nếu không sẽ gặp giới hạn mở rộng hành chính. Để giải quyết vấn đề này, họ bắt đầu tìm hiểu nghiên cứu tính toán xác minh được, nhưng họ phát hiện điều này luôn đòi hỏi bên thứ ba đáng tin cậy hoặc một trọng tài để kiểm tra tính toán.
Giới hạn này khiến họ hướng tới blockchain. Blockchain cung cấp một cách thức phá vỡ nhu cầu về một người ra quyết định duy nhất hoặc trọng tài, vì nó cho phép đạt được sự đồng thuận giữa nhóm người lớn.
Harry cũng chia sẻ quan điểm của anh, anh và Ben rất ủng hộ tự do ngôn luận và lo ngại về kiểm duyệt.
Trước khi chuyển sang blockchain, họ đang nghiên cứu học liên kết (federated learning), một lĩnh vực học sâutrên các nguồn dữ liệu phân tán, nơi bạn huấn luyện nhiều mô hình rồi kết hợp chúng lại để tạo ra một mô hình tổng hợp có thể học từ tất cả các nguồn dữ liệu. Họ đã hợp tác với các ngân hàng theo phương pháp này. Tuy nhiên, họ nhanh chóng nhận ra rằng vấn đề lớn hơn là việc tiếp cận tài nguyên tính toán hoặc bộ xử lý cần thiết để huấn luyện các mô hình này.
Để tối đa hóa việc tích hợp tài nguyên tính toán, họ cần một cách phối hợp phi tập trung, và đây chính là lúc blockchain phát huy tác dụng.
Khảo sát tài nguyên tính toán thị trường: AWS, cơ sở hạ tầng tại chỗ và cơ sở hạ tầng đám mây
Harry giải thích các lựa chọn tài nguyên tính toán khác nhau để vận hành mô hình AI, tùy thuộc vào quy mô mô hình.
Sinh viên có thể sử dụng AWS hoặc máy tại chỗ, các startup có thể chọn AWS theo nhu cầu hoặc các lựa chọn rẻ hơn được đặt trước.
Tuy nhiên, đối với nhu cầu GPU quy mô lớn, AWS có thể bị giới hạn về chi phí và khả năng mở rộng, thường thì lựa chọn sẽ là xây dựng cơ sở hạ tầng nội bộ.
Nghiên cứu cho thấy nhiều tổ chức đang nỗ lực mở rộng quy mô, một số thậm chí chọn mua và tự quản lý GPU. Nhìn chung, mua GPU về lâu dài sẽ tiết kiệm hơn so với chạy trên AWS.
Các lựa chọn tài nguyên tính toán học máy bao gồm điện toán đám mây, chạy mô hình AI tại chỗ hoặc xây dựng cụm máy tính riêng. Mục tiêu của Gensyn là cung cấp quyền truy cập vào quy mô tính toán tương đương với việc sở hữu cụm máy riêng, và điều then chốt là đảm bảo quyền truy cập công bằng, không bị kiểm soát hay đóng cửa bởi bất kỳ thực thể trung tâm nào.

Bảng 1: Tất cả các lựa chọn tài nguyên tính toán hiện có trên thị trường
Thảo luận về triết lý thiết kế, mục tiêu và định vị thị trường của Gensyn
Người dẫn chương trình hỏi về sự khác biệt giữa Gensyn và các dự án tính toán blockchain trước đó như Golem Network.
Harry giải thích rằng triết lý thiết kế của Gensyn chủ yếu được xem xét theo hai trục:
-
Mức độ chuyên biệt của giao thức: Khác với các giao thức tính toán chung như Golem, Gensyn là một giao thức chuyên biệt tập trung vào việc huấn luyện mô hình học máy.
-
Khả năng mở rộng của việc xác minh: Các dự án trước đây thường dựa vào danh tiếng hoặc phương pháp sao chép dễ bị lỗi Byzantine, điều này không mang lại đủ độ tin cậy cho kết quả học máy. Mục tiêu của Gensyn là tận dụng kinh nghiệm từ các giao thức tính toán trong thế giới mã hóa và áp dụng đặc biệt cho học máy, nhằm tối ưu hóa tốc độ và chi phí, đồng thời đảm bảo mức độ xác minh thỏa đáng.
Harry bổ sung rằng khi xem xét các đặc tính mà mạng lưới phải có, nó cần được thiết kế cho các kỹ sư và nhà nghiên cứu học máy. Nó cần phần xác minh, nhưng điều then chốt là ở khía cạnh cho phép bất kỳ ai tham gia, nó cần vừa kháng kiểm duyệt, vừa trung lập với phần cứng.
Ràng buộc, giả định và thực thi trong quá trình thiết kế
Trong quá trình thiết kế nền tảng Gensyn, Ben nhấn mạnh tầm quan trọng của việc xem xét các ràng buộc và giả định hệ thống. Mục tiêu của họ là tạo ra một mạng lưới có thể biến toàn bộ thế giới thành siêu máy tính AI, vì vậy họ cần tìm sự cân bằng giữa các giả định sản phẩm, giả định nghiên cứu và giả định kỹ thuật.
Lý do họ xây dựng Gensyn thành blockchain lớp một riêng là để giữ được sự linh hoạt và tự do ra quyết định lớn hơn trong các lĩnh vực công nghệ then chốt như cơ chế đồng thuận. Họ muốn có thể chứng minh giao thức của mình trong tương lai, chứ không muốn áp đặt những giới hạn không cần thiết ngay từ giai đoạn đầu dự án. Ngoài ra, họ tin rằng trong tương lai, các chuỗi sẽ có thể tương tác thông qua một giao thức truyền thông được chấp nhận rộng rãi, nên quyết định của họ cũng phù hợp với viễn cảnh này.
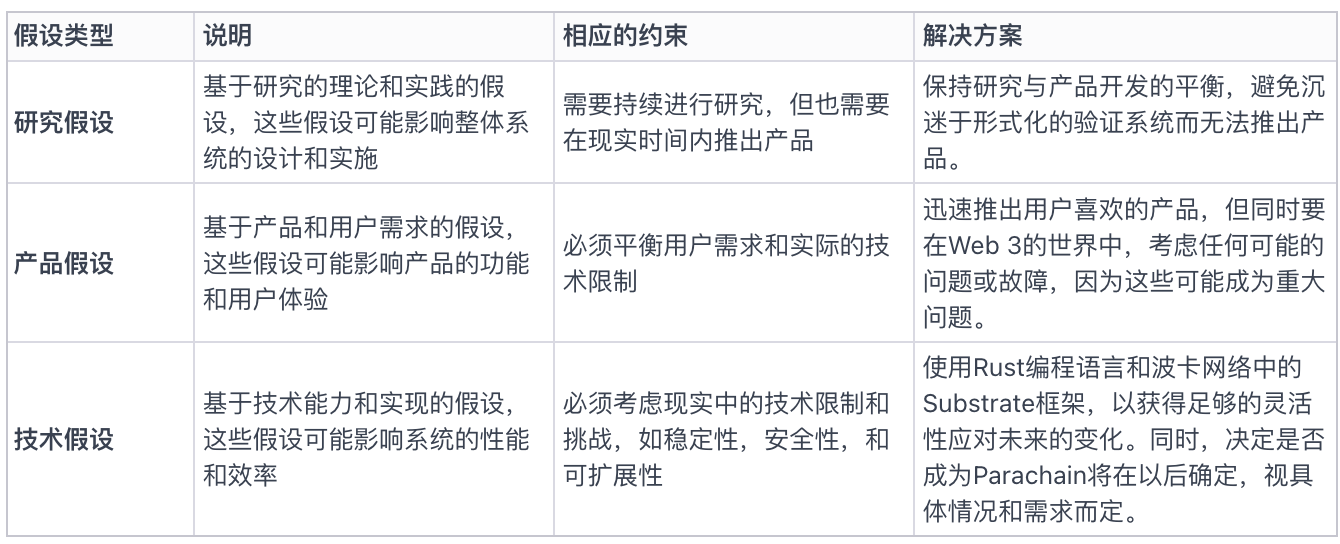
Hình 2: Giả định sản phẩm, giả định nghiên cứu, giả định kỹ thuật, ràng buộc và thực thi
Bốn vai trò chính trong mạng lưới ngoài chuỗi của Gensyn
Trong cuộc thảo luận kinh tế của Gensyn, bốn vai trò chính được giới thiệu: Người gửi (Submitter), Người làm (Worker), Người xác minh (Verifier) và Người tố giác (Whistleblower). Người gửi có thể gửi các bài toán khác nhau lên mạng lưới Gensyn, bao gồm tạo ảnh cụ thể hoặc phát triển mô hình AI có thể lái xe.
Người gửi (Submitter) gửi nhiệm vụ
Harry giải thích cách sử dụng Gensyn để huấn luyện mô hình. Người dùng trước tiên xác định kết quả mong muốn, ví dụ như tạo ảnh từ gợi ý văn bản, sau đó xây dựng một mô hình lấy gợi ý văn bản làm đầu vào và tạo ảnh tương ứng. Dữ liệu huấn luyệnrất quan trọng đối với việc học và cải thiện mô hình. Sau khi chuẩn bị xong kiến trúc mô hình và dữ liệu huấn luyện, người dùng sẽ gửi chúng cùng với các siêu tham số như lịch học suất học (learning rate)và thời lượng huấn luyện lên mạng lưới Gensyn. Kết quả của quá trình huấn luyện này là mô hình đã được huấn luyện, người dùng có thể lưu trữ và sử dụng mô hình đó.
Khi được hỏi về cách chọn mô hình chưa được huấn luyện, Harry đưa ra hai phương pháp.
-
Phương pháp đầu tiên dựa trên khái niệm mô hình nền tảng phổ biến hiện nay, trong đó các công ty lớn như OpenAI hay Midjourney xây dựng mô hình nền tảng, sau đó người dùng có thể huấn luyện thêm mô hình nền tảng đó với dữ liệu cụ thể.
-
Lựa chọn thứ hai là xây dựng mô hình từ đầu, khác với phương pháp mô hình nền tảng.
Trong Gensyn, các nhà phát triển có thể sử dụng các phương pháp tương tự như tối ưu hóa tiến hóa để gửi các kiến trúc khác nhau nhằm huấn luyện và kiểm tra, liên tục tinh chỉnh để xây dựng mô hình mong muốn.
Ben chia sẻ cái nhìn sâu sắc về mô hình nền tảng, họ cho rằng đây là tương lai của lĩnh vực này.
Gensyn như một giao thức, chúng tôi hy vọng nó sẽ được các DApp sử dụng các kỹ thuật như tối ưu hóa tiến hóa hoặc các phương pháp tương tự. Các DApp này có thể gửi các kiến trúc riêng lẻ lên giao thức Gensyn để huấn luyện và kiểm tra, tinh chỉnh qua từng lần lặp để xây dựng mô hình lý tưởng.
Mục tiêu của Gensyn là cung cấp cơ sở tính toán học máy thuần túy, khuyến khích phát triển hệ sinh thái xung quanh nó.
Mặc dù mô hình được tiền huấn luyện có thể gây thiên lệch vì các tổ chức có thể sử dụng tập dữ liệu độc quyền hoặc che giấu thông tin về quá trình huấn luyện, giải pháp của Gensynlà mở quá trình huấn luyện, chứ không phải loại bỏ hộp đen hoặc phụ thuộc vào tính toàn xác định. Bằng cách cùng nhau thiết kế và huấn luyện mô hình nền tảng, chúng ta có thể tạo ra các mô hình toàn cầu mà không bị ảnh hưởng bởi tập dữ liệu của bất kỳ công ty cụ thể nào.
Người làm (Solver)
-
Về phân công nhiệm vụ, một nhiệm vụ tương ứng với một máy chủ. Nhưng một mô hình có thể được chia thành nhiều nhiệm vụ.
-
Các mô hình ngôn ngữ lớn được thiết kế để tận dụng tối đa dung lượng phần cứng lớn nhất sẵn có tại thời điểm đó. Khái niệm này có thể được mở rộng ra mạng lưới, xem xét tính dị cấu của thiết bị.
-
Đối với các nhiệm vụ cụ thể như người xác minh hoặc người làm, có thể chọn nhận từ Mempool. Trong số những người bày tỏ sẵn sàng nhận nhiệm vụ, một người làm sẽ được chọn ngẫu nhiên. Nếu mô hình và dữ liệu không phù hợp với thiết bị cụ thể, nhưng chủ sở hữu thiết bị tuyên bố có thể, có thể bị phạt do tắc nghẽn hệ thống.
-
Việc một nhiệm vụ có thể chạy trên một máy hay không được quyết định bởi một hàm ngẫu nhiên có thể xác minh, hàm này chọn một người làm từ tập con người làm sẵn có.
-
Về vấn đề xác minh năng lực người làm, nếu người làm không có năng lực tính toán như tuyên bố, họ sẽ không thể hoàn thành nhiệm vụ tính toán, điều này sẽ bị phát hiện khi nộp bằng chứng.
-
Tuy nhiên, kích thước nhiệm vụ là một vấn đề. Nếu nhiệm vụ đặt quá lớn, có thể gây ra các vấn đề hệ thống, ví dụ như tấn công từ chối dịch vụ (DoS), nơi người làm tuyên bố sẽ hoàn thành nhiệm vụ nhưng mãi không hoàn thành, làm lãng phí thời gian và tài nguyên.
-
Do đó, việc quyết định kích thước nhiệm vụ rất quan trọng, cần xem xét các yếu tố như song song hóa và tối ưu hóa cấu trúc nhiệm vụ. Các nhà nghiên cứu đang tích cực nghiên cứu và khám phá phương pháp tốt nhất dựa trên các ràng buộc khác nhau.
-
Một khi testnet khởi động, cũng sẽ xem xét tình hình thực tế, quan sát cách hệ thống hoạt động trong thế giới thực.
-
Việc xác định kích thước nhiệm vụ hoàn hảo là thách thức, Gensyn đã sẵn sàng điều chỉnh và cải tiến dựa trên phản hồi và kinh nghiệm thực tế.
Cơ chế xác minh và các điểm kiểm tra (Checkpoints) cho tính toán quy mô lớn trên chuỗi
Harry và Ben chỉ ra rằng việc xác minh tính đúng đắn của tính toán là một thách thức quan trọng, vì nó không mang tính xác định như hàm băm, do đó không thể đơn giản xác minh bằng băm để xác định liệu tính toán đã được thực hiện hay chưa. Để giải quyết vấn đề này, phương án lý tưởng là ứng dụng chứng minh kiến thức không (zero-knowledge proof) cho toàn bộ quá trình tính toán. Hiện tại, Gensyn vẫn đang nỗ lực đạt được khả năng này.
Hiện tại, Gensyn giới thiệu phương pháp hỗn hợp sử dụng các điểm kiểm tra, xác minh tính toán học máy thông qua cơ chế xác suất và các điểm kiểm tra. Bằng cách kết hợp sơ đồ kiểm toán ngẫu nhiên và đường đi trong không gian gradient, có thể xây dựng một hệ thống kiểm tra tương đối vững chắc. Ngoài ra, còn giới thiệu chứng minh kiến thức không để tăng cường quá trình xác minh, và đã áp dụng cho tổn thất toàn cục của mô hình.
Người xác minh (Verifier) và Người tố giác (Whistleblower)
Người dẫn chương trình và Harry thảo luận về hai vai trò bổ sung trong quá trình xác minh: Người xác minh (Verifier) và Người tố giác (whistleblower). Họ giải thích chi tiết nhiệm vụ và vai trò cụ thể của hai vai trò này.
Nhiệm vụ của người xác minh là đảm bảo tính đúng đắn của các điểm kiểm tra, trong khi nhiệm vụ của người tố giác là đảm bảo tính chính xác trong việc người xác minh thực hiện nhiệm vụ của họ. Người tố giác giải quyết vấn đề lưỡng nan của người xác minh, đảm bảo công việc của người xác minh là đúng và đáng tin cậy. Người xác minh cố ý đưa lỗi vào công việc, vai trò của người tố giác là nhận diện và phơi bày những lỗi này, từ đó đảm bảo tính toàn vẹn của quá trình xác minh.
Người xác minh cố ý đưa lỗi để kiểm tra sự cảnh giác của người tố giác và đảm bảo hiệu quả của hệ thống. Nếu công việc có lỗi, người xác minh sẽ phát hiện và thông báo cho người tố giác. Lỗi sau đó được ghi lại trên blockchain và được xác minh trên chuỗi. Định kỳ, và với tốc độ liên quan đến độ an toàn hệ thống, người xác minh cố ý đưa lỗi để duy trì mức độ tham gia của người tố giác. Nếu người tố giác phát hiện vấn đề, họ sẽ tham gia vào một trò chơi gọi là "giao thức xác định chính xác" (pinpoint protocol), qua đó họ có thể thu hẹp tính toán xuống một điểm cụ thể trong cây Merkle của khu vực cụ thể trong mạng nơ-ron. Thông tin này sau đó được gửi lên chuỗi để trọng tài. Đây là phiên bản đơn giản hóa của quá trình người xác minh và người tố giác, họ sẽ tiếp tục phát triển và nghiên cứu sâu hơn sau khi hoàn thành vòng hạt giống.
Mạng lưới trên chuỗi của Gensyn
Ben và Harry thảo luận chi tiết về cách thức hoạt động và chi tiết triển khai của giao thức phối hợp Gensyn trên chuỗi. Họ trước tiên đề cập đến quá trình xây dựng khối mạng lưới, liên quan đến việc đặt cược token như một phần của mạng lưới đặt cược. Sau đó, họ giải thích mối quan hệ giữa các thành phần này với giao thức Gensyn.
Ben giải thích rằng giao thức Gensyn chủ yếu là một giao thức mạng Polkadot dựa trên substrate cơ bản. Họ sử dụng cơ chế đồng thuận Grandpa Babe dựa trên Proof-of-Stake, các người xác minh hoạt động theo cách thông thường. Tuy nhiên, tất cả các thành phần học máy đã giới thiệu trước đó đều được thực hiện ngoài chuỗi, liên quan đến các bên tham gia ngoài chuỗi thực hiện nhiệm vụ riêng của họ.
Các bên tham gia này được khuyến khích thông qua việc đặt cược, có thể thông qua bảng đặt cược trong Substrate hoặc bằng cách gửi một lượng token cụ thể vào hợp đồng thông minh để đặt cược. Khi công việc của họ cuối cùng được xác minh, họ sẽ nhận được phần thưởng.
Ben và Harry đề cập đến thách thức trong việc đảm bảo sự cân bằng giữa số tiền đặt cược, số tiền giảm giá có thể xảy ra và số tiền thưởng, để ngăn chặn việc khuyến khích hành vi lười biếng hoặc ác ý.
Ngoài ra, họ cũng thảo luận về sự phức tạp do việc tăng số lượng người tố giác, nhưng do nhu cầu tính toán quy mô lớn, sự tồn tại của họ là then chốt để đảm bảo tính trung thực của người xác minh. Mặc dù họ liên tục tìm kiếm cách loại bỏ người tố giác thông qua công nghệ chứng minh kiến thức không. Họ cho biết hệ thống hiện tại phù hợp với mô tả trong lite paper, nhưng họ đang tích cực nỗ lực đơn giản hóa mọi khía cạnh.
Người dẫn chương trình hỏi liệu họ có giải pháp khả dụng dữ liệu nào không, Henry giải thích rằng họ đã giới thiệu một lớp gọi là proof of availability (POA) trên nền tảng substrate. Lớp này sử dụng các kỹ thuật như mã xóa bỏ (erasure code) để giải quyết các giới hạn họ gặp phải trên thị trường lưu trữ quy mô lớn. Họ rất quan tâm đến các nhà phát triển đã triển khai giải pháp như vậy.
Ben bổ sung rằng nhu cầu của họ không chỉ liên quan đến việc lưu trữ dữ liệu huấn luyện, mà còn bao gồm dữ liệu bằng chứng trung gian, những dữ liệu này không cần lưu trữ lâu dài. Ví dụ, khi họ hoàn thành việc phát hành một số lượng khối cụ thể, có thể chỉ cần giữ khoảng 20 giây. Tuy nhiên, hiện tại họ đang trả phí lưu trữ trên Arweave cho phạm vi hàng trăm năm, điều này là không cần thiết cho các nhu cầu ngắn hạn này. Họ đang tìm kiếm một giải pháp vừa có được sự đảm bảo và chức năng của Arweave, vừa có thể đáp ứng nhu cầu lưu trữ ngắn hạn với chi phí thấp hơn.
Token và quản trị Gensyn
Ben giải thích tầm quan trọng của token gensyn trong hệ sinh thái, nó đóng vai trò then chốt trong việc đặt cược, phạt, cung cấp phần thưởng và duy trì đồng thuận. Mục đích chính là đảm bảo tính hợp lý về tài chính và tính toàn vẹn của hệ thống. Ben cũng đề cập đến việc thận trọng sử dụng tỷ lệ lạm phát để trả cho người xác minh, và tận dụng cơ chế lý thuyết trò chơi.
Anh nhấn mạnh mục đích kỹ thuật thuần túy của token Gensyn và cho biết họ sẽ đảm bảo về mặt kỹ thuật thời điểm và sự cần thiết khi giới thiệu token Gensyn.
Harry cho biết họ thuộc thiểu số trong cộng đồng học sâu, đặc biệt là các học giả AI nghi ngờ rộng rãi về tiền mã hóa. Tuy nhiên, họ nhận ra giá trị về mặt công nghệ và ý thức hệ của tiền mã hóa.
Tuy nhiên, khi mạng lưới khởi động, họ dự đoán phần lớn người dùng học sâu sẽ chủ yếu sử dụng tiền pháp định để giao dịch, việc chuyển đổi sang token sẽ diễn ra liền mạch phía sau hậu trường.
Về nguồn cung, người làm và người gửi sẽ tích cực tham gia giao dịch token, và họ đã nhận được sự quan tâm từ các thợ đào Ethereum, những người sở hữu lượng lớn tài nguyên GPU và đang tìm kiếm cơ hội mới.
Ở đây, điều quan trọng là loại bỏ nỗi sợ của các chuyên gia học sâu và học máy về các thuật ngữ tiền mã hóa (như token), tách biệt chúng khỏi giao diện trải nghiệm người dùng. Gensyn cho biết đây là một trường hợp sử dụng thú vị, kết nối thế giới Web 2 và Web 3, vì nó có tính hợp lý về kinh tế và công nghệ cần thiết để tồn tại.
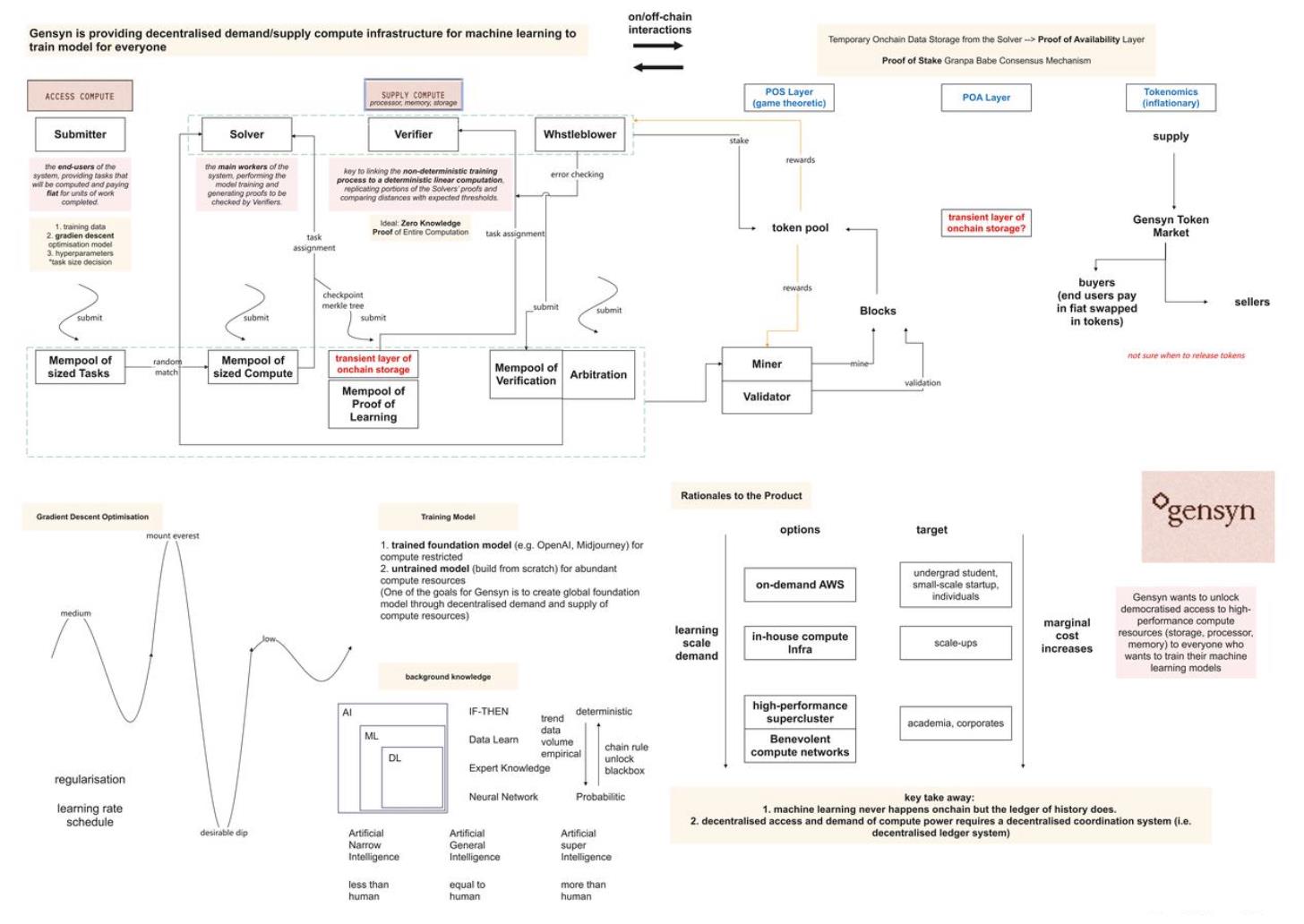
Hình 1: Mô hình hoạt động mạng lưới trên và ngoài chuỗi Gensyn được tổng hợp từ podcast, nếu có sai sót về cơ chế vận hành, kính mong quý độc giả góp ý kịp thời (Nguồn ảnh: TechFlow)
Giáo dục về trí tuệ nhân tạo
AI, học sâu và học máy
Ben chia sẻ quan điểm của anh về sự phát triển của lĩnh vực AI trong những năm gần đây. Anh cho rằng, mặc dù lĩnh vực AI và học máy đã trải qua một loạt các bước phát triển nhỏ trong bảy năm qua, nhưng những tiến bộ hiện tại dường như đang tạo ra tác động thực sự và các ứng dụng có giá trị, những ứng dụng này có thể tạo được tiếng vang với đông đảo khán giả hơn. Học sâu là động lực cơ bản đằng sau những thay đổi này. Các mạng nơ-ron sâuđã thể hiện khả năng vượt qua các tiêu chuẩn được thiết lập bởi các phương pháp truyền thống trong lĩnh vựcthị giác máy tính. Ngoài ra, các mô hình như GPT-3 cũng đẩy nhanh tiến trình này.
Harry tiếp tục giải thích sự khác biệt giữa AI, học máy và học sâu. Anh cho rằng ba thuật ngữ này thường bị dùng lẫn lộn, nhưng chúng có sự khác biệt rõ rệt. Anh ví von rằng, AI, học máy và học sâu giống như những chiếc hộp Nga xếp lồng vào nhau, AI là chiếc hộp ngoài cùng.
-
Theo nghĩa rộng, AI là việc lập trình cho máy móc thực hiện nhiệm vụ.
-
Học máy bắt đầu phổ biến vào những năm 90 và đầu những năm 2000, nó sử dụng dữ liệu để xác định xác suất ra quyết định, thay vì dựa vào các hệ thống chuyên gia với các quy tắc if-then.
-
Học sâu được xây dựng trên nền tảng học máy nhưng cho phép các mô hình phức tạp hơn.

Hình 3: Sự khác biệt giữa trí tuệ nhân tạo, học máy và học sâu
Trí tuệ nhân tạo hẹp, trí tuệ nhân tạo tổng quát, trí tuệ nhân tạo siêu việt
Trong phần này, người dẫn chương trình và khách mời đi sâu vào ba lĩnh vực then chốt của trí tuệ nhân tạo: Trí tuệ nhân tạo hẹp (ANI), Trí tuệ nhân tạo tổng quát (AGI), và Trí tuệ nhân tạo siêu việt (ASI).
-
Trí tuệ nhân tạo hẹp (Artificial Narrow Intelligence, ANI): AI hiện tại chủ yếu đang ở giai đoạn này, tức là máy móc rất giỏi thực hiện các nhiệm vụ cụ thể, ví dụ như phát hiện một loại ung thư cụ thể từ hình ảnh y khoa thông qua nhận dạng mẫu.
-
Trí tuệ nhân tạo tổng quát (Artificial General Intelligence, AGI): AGI là khả năng của máy móc thực hiện các nhiệm vụ mà con người làm tương đối dễ dàng nhưng lại rất thách thức khi phản ánh trong hệ thống tính toán. Ví dụ, để máy móc có thể di chuyển thuận lợi trong môi trường đông đúc, đồng thời đưa ra các giả định rời rạc về mọi đầu vào xung quanh, đây là một ví dụ về AGI. AGI ám chỉ mô hình hoặc hệ thống có thể thực hiện các nhiệm vụ hàng ngày như con người.
-
Trí tuệ nhân tạo siêu việt (Artificial Super Intelligence, ASI): Sau khi đạt được trí tuệ nhân tạo tổng quát, máy móc có thể tiếp tục phát triển thành trí tuệ nhân tạo siêu việt. Điều này ám chỉ việc máy móc vượt qua khả năng của con người nhờ độ phức tạp của mô hình, năng lực tính toán tăng lên, tuổi thọ vô hạn và trí nhớ hoàn hảo. Khái niệm này thường được khai thác trong các phim khoa học viễn tưởng và kinh dị.
Ngoài ra, khách mời cũng đề cập rằng việc kết hợp não người với máy móc, ví dụ như qua giao diện não - máy (brain-machine interface), có thể là một con đường để đạt được AGI, nhưng điều này cũng đặt ra một loạt vấn đề đạo đức và luân lý.
Tháo gỡ hộp đen học sâu: Tính xác định và tính xác suất
Ben giải thích rằng, bản chất hộp đen của các mô hình học sâu là do kích thước tuyệt đối của chúng. Bạn vẫn có thể theo dõi đường đi qua chuỗi các điểm ra quyết định trong mạng. Chỉ là đường đi này rất lớn, khó liên kết trọng số hoặc tham số bên trong mô hình với giá trị cụ thể của chúng, vì những giá trị này được rút ra sau khi đưa vào hàng triệu mẫu. Bạn có thể làm điều này một cách xác định, bạn có thể theo dõi từng cập nhật, nhưng cuối cùng lượng dữ liệu bạn tạo ra sẽ rất lớn.
Anh thấy có hai điều đang xảy ra:
-
Khi chúng ta hiểu ngày càng nhiều về các mô hình đang xây dựng, bản chất hộp đen đang dần biến mất. Học sâu là một lĩnh vực nghiên cứu, trải qua một giai đoạn nhanh chóng thú vị với lượng lớn thí nghiệm, những thí nghiệm này không được thúc đẩy bởi nền tảng nghiên cứu. Mà nhiều hơn là xem chúng ta có thể thu được gì từ đó. Vì vậy, chúng ta đưa vào nhiều dữ liệu hơn, thử các kiến trúc mới, chỉ để xem chuyện gì xảy ra, thay vì xuất phát từ các nguyên lý cơ bản, thiết kế thứ này, và biết chính xác cách nó hoạt động. Vì vậy, có một giai đoạn hào hứng khi mọi thứ đều là hộp đen. Nhưng anh cho rằng sự tăng trưởng nhanh chóng này đang bắt đầu chậm lại, chúng ta đang thấy mọi người xem xét lại các kiến trúc này, kiểm tra và nói: "Tại sao cái này hiệu quả đến thế? Hãy đi sâu vào, chứng minh điều đó." Vì vậy, ở một mức độ nào đó, bức màn đang được vén lên.
-
Điều thứ hai có thể gây tranh cãi hơn là sự thay đổi trong quan điểm về việc hệ thống tính toán có cần hoàn toàn xác định hay không, hay chúng ta có thể sống trong một thế giới xác suất. Chúng ta là con người sống trong một thế giới xác suất. Ví dụ về xe tự lái có lẽ rõ ràng nhất, khi chúng ta lái xe, chúng ta chấp nhận sẽ có các sự kiện ngẫu nhiên, có thể có tai nạn nhỏ, có thể hệ thống xe tự lái gặp vấn đề. Nhưng chúng ta hoàn toàn không thể chấp nhận điều này, chúng ta nói điều này phải là một quá trình hoàn toàn xác định. Một trong những thách thức của ngành công nghiệp xe tự lái là họ giả định mọi người sẽ chấp nhận cơ chế xác suất áp dụng cho xe tự lái, nhưng thực tế mọi người không chấp nhận. Anh nghĩ tình trạng này sẽ thay đổi, có thể gây tranh cãi là, liệu chúng ta như một xã hội có cho phép các hệ thống tính toán xác suất cùng tồn tại với chúng ta hay không? Anh không chắc con đường này sẽ suôn sẻ, nhưng anh nghĩ điều này sẽ xảy ra.
Phương pháp tối ưu hóa gradient: Phương pháp tối ưu hóa cốt lõi của học sâu
Tối ưu hóa gradient là một trong những phương pháp cốt lõi của học sâu, đóng vai trò then chốt trong việc huấn luyện mạng nơ-ron. Trong mạng nơ-ron, một chuỗi các tham số về cơ bản là các số thực. Việc huấn luyện mạng liên quan đến việc thiết lập các tham số này thành các giá trị thực tế cho phép dữ liệu truyền đúng và kích hoạt đầu ra mong muốn ở giai đoạn cuối của mạng.
Phương pháp tối ưu hóa dựa trên gradient đã mang lại sự thay đổi to lớn trong lĩnh vực mạng nơ-ron và học sâu. Phương pháp này sử dụng gradient, tức là đạo hàm của các tham số ở mỗi tầng mạng đối với lỗi. Bằng cách áp dụng quy tắc chuỗi, gradient có thể được lan truyền ngược qua toàn bộ mạng phân tầng. Trong quá trình này, bạn có thể xác định vị trí của mình trên bề mặt lỗi. Lỗi có thể được mô hình hóa như một bề mặt trong không gian Euclide, bề mặt này trông giống một khu vực đầy gò đống và thung lũng. Mục tiêu tối ưu hóa là tìm ra khu vực có thể làm giảm lỗi tối thiểu.
Gradient cho mỗi tầng cho biết vị trí của bạn trên bề mặt này và hướng bạn nên cập nhật tham số. Bạn có thể sử dụng gradient để điều hướng trên bề mặt gồ ghề này, tìm ra hướng có thể giảm lỗi. Kích thước bước nhảy phụ thuộc vào độ dốc của bề mặt. Nếu độ dốc cao, bạn sẽ nhảy xa hơn; nếu độ dốc nhỏ, bạn sẽ nhảy ngắn hơn. Về cơ bản, bạn chỉ đang điều hướng trên bề mặt này, tìm một rãnh, và gradient có thể giúp bạn xác định vị trí và hướng đi.
Phương pháp này là một bước đột phá lớn, vì gradient cung cấp một tín hiệu rõ ràng và hướng đi hữu ích, so với việc nhảy ngẫu nhiên trong không gian tham số, nó có thể hiệu quả hơn nhiều trong việc hướng dẫn bạn biết mình đang ở đâu trên bề mặt, đang ở đỉnh núi, trong hẻm núi hay trong vùng bằng phẳng.
Mặc dù trong học sâu có nhiều kỹ thuật có thể giải quyết vấn đề tìm ra giải pháp tối ưu, nhưng tình hình thực tế thường phức tạp hơn. Có rất nhiều kỹ thuật chính quy hóa (regularization)được sử dụng trong huấn luyện học sâu khiến nó trở thành một nghệ thuật chứ không phải khoa học. Và đây là lý do tại sao việc tối ưu hóa dựa trên gradient trong ứng dụng thực tế giống nghệ thuật hơn là một khoa học chính xác.
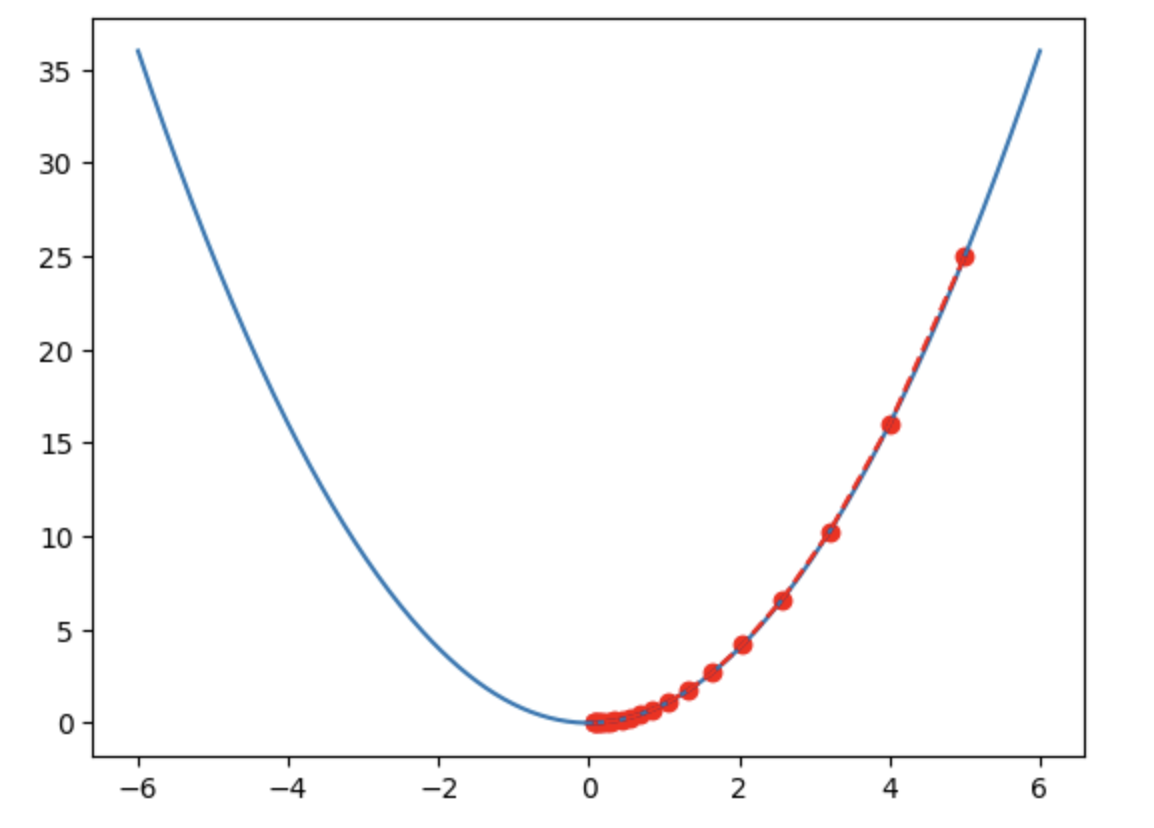
Hình 2: Nói đơn giản, mục tiêu tối ưu hóa là tìm đáy thung lũng (Nguồn ảnh: TechFlow)
Tổng kết
Mục tiêu của Gensyn là xây dựng hệ thống tài nguyên tính toán học máy lớn nhất toàn cầu, tận dụng tối đa các tài nguyên tính toán bị bỏ không hoặc chưa được sử dụng đầy đủ, chẳng hạn như điện thoại thông minh, máy tính cá nhân.
Trong bối cảnh học máy và blockchain, bản ghi sổ cái thường lưu giữ kết quả tính toán, tức là trạng thái dữ liệu đã được xử lý bằng học máy. Trạng thái này có thể là: “Dữ liệu này đã được xử lý bằng học máy, hợp lệ, thời gian xảy ra là X tháng X năm”. Mục tiêu chính của bản ghi này là biểu thị trạng thái kết quả, chứ không phải mô tả chi tiết quá trình tính toán.
Và trong khuôn khổ này, blockchain đóng vai trò quan trọng:
-
Blockchain cung cấp một cách thức ghi lại kết quả trạng thái dữ liệu. Thiết kế của nó đảm bảo tính xác thực dữ liệu, ngăn chặn việc sửa đổi và chối bỏ.
-
Blockchain có cơ chế khuyến khích kinh tế bên trong, thông qua đó có thể điều phối hành vi của các vai trò khác nhau trong mạng lưới tính toán, ví dụ như bốn vai trò đã đề cập: Người gửi, Người làm, Người xác minh và Người tố giác.
-
Thông qua khảo sát thị trường điện toán đám mây hiện tại, chúng ta thấy điện toán đám mây không phải hoàn toàn không có điểm tốt, mà mỗi cách tính toán đều có vấn đề riêng. Cách tính toán phi tập trung của blockchain có thể phát huy tác dụng trong một số tình huống, nhưng không thể thay thế hoàn toàn điện toán đám mây truyền thống, nghĩa là blockchain không phải là giải pháp vạn năng.
-
Cuối cùng, AI có thể được coi là một lực lượng sản xuất, tuy nhiên, việc tổ chức và huấn luyện AI hiệu quả thuộc về phạm trù quan hệ sản xuất. Điều này bao gồm các yếu tố như hợp tác, cộng tác và khuyến khích. Trong lĩnh vực này, Web 3.0 cung cấp rất nhiều giải pháp và kịch bản tiềm năng.
Do đó, chúng ta có thể hiểu rằng, sự kết hợp giữa blockchain và AI, đặc biệt trong việc chia sẻ dữ liệu và mô hình, phối hợp tài nguyên tính toán và xác minh kết quả, đã mở ra những khả năng mới để giải quyết một số vấn đề trong quá trình huấn luyện và sử dụng AI.
Trích dẫn
1.https://docs.gensyn.ai/litepaper/
2.https://a16zcrypto.com/posts/announcement/investing-in-gensyn/
Chào mừng tham gia cộng đồng chính thức TechFlow
Nhóm Telegram:https://t.me/TechFlowDaily
Tài khoản Twitter chính thức:https://x.com/TechFlowPost
Tài khoản Twitter tiếng Anh:https://x.com/BlockFlow_News













