

Web3 탈중앙화 데이터베이스 저장의 현재와 미래
글: Maggie
왜 탈중앙화 데이터베이스가 필요한가?
Web2 애플리케이션의 데이터 저장 방식은 기본적으로 파일 시스템(File System)과 데이터베이스(Database) 두 가지다. Web3에는 아직 데이터베이스 제품이 부족하기 때문에 대부분의 DApp은 소수의 중요한 데이터만 비싼 스마트 계약에 저장하고 나머지 구조화된 데이터는 여전히 중심화된 데이터베이스를 사용한다. IPFS 등의 탈중앙화 파일 시스템이 NFT 데이터 저장을 위해 점차 Web3 애플리케이션에서 활용되면서, 탈중앙화 파일 시스템은 Web3 커뮤니티로부터 인정받고 채택되기 시작했으며, 이와 함께 탈중앙화 데이터베이스 기술도 한 차례 진화를 거쳐 다양한 신규 제품들이 등장했다.
탈중앙화 데이터베이스는 전통적인 중심화 데이터베이스보다 독특한 장점을 지닌다. 단일 실패 지점(Single Point of Failure) 위험을 줄이고, DApp을 완전히 탈중앙화할 수 있다.
탈중앙화 데이터베이스는 접근 빈도가 높은 핫 데이터, 즉 DApp의 재무 관련이 아닌 데이터를 저장하는 데 적합하다. 예를 들어:
-
NFT 메타데이터
-
DAO 투표 데이터
-
DEX 오더북(Order book)
-
탈중앙화된 소셜 데이터, 블로그 데이터, 메일
-
DApp이 필요로 하는 복잡한 관계형 데이터베이스 데이터
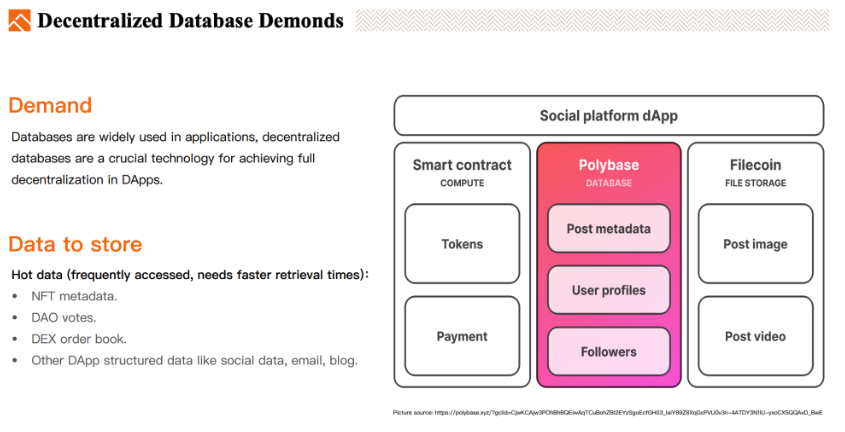
어떤 종류의 탈중앙화 데이터베이스 저장 시스템이 있는가?
최근 2년간 다수의 탈중앙화 데이터베이스 프로젝트가 등장했으며, 그 중 일부 혁신적인 프로젝트들은 큰 주목을 받았다.
-
Ceramic: 2019년에 시작된 프로젝트이다. 데이터는 스트림 형태로 저장 및 관리되며, 형식화된 이벤트 로그가 스트림에 추가된다. 로그는 파일로 만들어져 IPFS에 업로드된다. GraphQL API 쿼리를 제공한다. Ceramic은 IPFS처럼 인센티브 모델은 없으며, 데이터 생성, 읽기, 갱신(CRU)을 지원한다.
-
OrbitDB: Ceramic보다 이른 시기에 시작된 프로젝트로, IPFS 파일 시스템을 이용해 파일을 저장한다. NoSQL 데이터베이스와 파일 저장을 모두 지원한다.
-
Tableland: 2022년에 시작된 프로젝트로 현재 공개 테스트 단계에 있다. 정식 버전은 2023년 출시될 예정이다. 데이터 저장에는 스마트 계약이 필요하며, SQL 문을 정의하고 사용 권한을 설정한다. 데이터 읽기는 오프체인에서 이루어지며 비용이 들지 않는다. 현재 해당 계약은 ETH 및 OP 등 L2에 배포되어 있다.
-
Polybase: 현재 테스트넷에서 운영 중이다. CRUD 작업을 지원하는 NoSQL 데이터베이스로, 모든 작업에 수수료가 발생한다. 또한 Polybase는 로컬 디스크, IPFS, Filecoin, Polystore, 심지어 AWS S3까지 다양한 파일 시스템을 통해 데이터베이스 파일을 저장할 수 있다. 또한 데이터 조회 요금을 처리하기 위해 페이먼트 채널을 활용하여 체인상 트랜잭션 빈도를 낮추고, 결제로 인한 조회 지연을 방지한다.
-
Web3Q: 2022년에 시작된 프로젝트로 테스트넷이 이미 출시되었다. 데이터 접근을 위한 새로운 URL 형식(Web//access protocol)을 제안했다. 요금 체계가 특이하게도, 데이터 삭제 시 요금을 환불해 준다.
-
Kwill: Arweave 기반의 SQL 데이터베이스 시스템으로, 스마트 계약을 통한 결제를 사용한다.
-
KYVE: Arweave 기반의 데이터베이스 시스템이다.
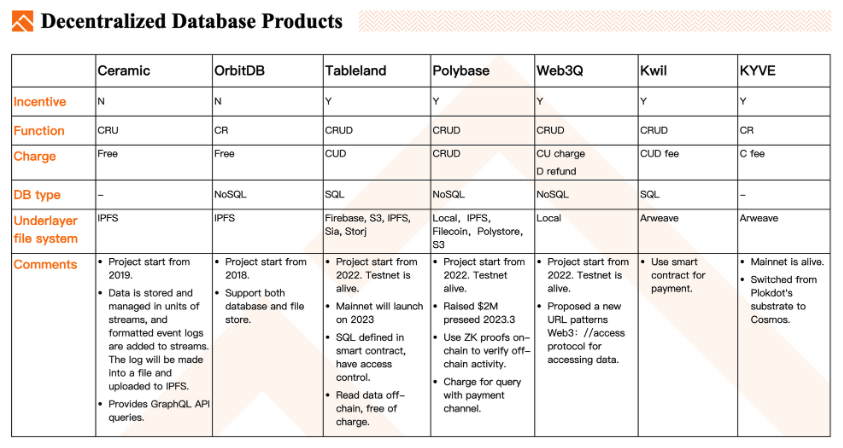
기술적 측면
-
SQL과 NoSQL 모두 데이터베이스로 사용 가능하며, SQL은 더 성숙하고 효율적이며, NoSQL은 더 풍부하고 유연하다. SQL은 데이터 구조 일관성이 높아야 하며 조인 쿼리 능력이 강하고, 성숙도와 효율성이 뛰어나다. 반면 NoSQL의 키-값(KV) 형식은 이더리움 설계 패턴에 더 잘 맞으며, 다양한 데이터 유형을 지원하고 유연성과 확장성이 뛰어나다.
-
기능적으로 CRUD를 모두 지원하는 것이 이상적이지만, UD(업데이트 및 삭제)를 지원하면 시스템 복잡성이 증가한다. 로컬 저장을 채택할 경우 과거 값 조회가 불가능할 수 있으며, IPFS나 Arweave를 사용할 경우 데이터베이스는 append-only여야 한다. 그렇지 않으면 하나의 데이터에 여러 버전이 생겨 저장 비용이 급격히 증가한다.
-
하부 파일 시스템 선택은 두 가지 방식이 있다.
-
로컬에 파일을 저장하는 것은 더 유연하며 검색 로직을 자유롭게 정의할 수 있고 효율성이 높다. 또한 Arweave 등의 탈중앙화 파일 시스템 사용으로 인한 불안정성과 복잡성을 피할 수 있다. 예를 들어, 사용자가 토큰A로 데이터베이스 마이너에게 요금을 지불하고, 마이너는 데이터 저장을 위해 Arweave 코인을 지불해야 하는 이중 네트워크 구조는 복잡성을 증가시킨다.
-
데이터베이스 파일을 IPFS 및 Arweave 등의 탈중앙화 파일 시스템에 저장하는 방식;
-
노드 로컬 또는 S3 클라우드에 저장하는 방식.
-
-
탈중앙화 스토리지와 마찬가지로, 데이터 검색 속도 개선, 인센티브 모델과 토큰 경제학 설계, 그리고 데이터 가용성을 보장하기 위한 알고리즘은 프로토콜이 널리 쓰일 수 있는 핵심 요소다.
-
좋은 인센티브 모델과 토큰 모델은 노드 참여를 유도할 뿐 아니라 올바른 행동을 장려한다. 예를 들어 단순히 저장만 하고 보상을 받는 것이 아니라, 효과적인 검색 기능을 제공하도록 유도하는 것이다.
-
데이터 가용성 보장 알고리즘은 일정 주기로 노드의 데이터 저장 상태를 점검하며, 노드는 데이터 가용성 증명을 제출해야 한다. 이 증명은 인센티브와 연동되어 데이터 유실을 방지한다.
-
데이터 검색 속도는 사용자 경험에 직접 영향을 미치며, DApp의 사용 편의성과 원활함에 매우 중요하다.
-
결론
-
탈중앙화 데이터베이스 분야는 높은 관심과 절박한 수요를 지니고 있지만, 아직 널리 채택되고 사용되는 제품은 없다.
-
탈중앙화 데이터베이스 기술의 성숙도는 탈중앙화 파일 저장 시스템보다 낮다. 왜냐하면 탈중앙화 데이터베이스 기술은 분산 파일 시스템을 기반으로 하기 때문이다. 많은 프로젝트들이 2022년에 시작되었다.
-
데이터 검색 속도 향상, 인센티브 모델 및 토큰 경제학 설계, 데이터 가용성 보장을 위한 보장 알고리즘은 프로토콜이 널리 사용될 수 있는 결정적 요소다. 특히 DApp의 사용 편의성과 원활함을 위해서는 검색 시간 단축이 핵심 과제가 될 것이다.

TechFlow 공식 커뮤니티에 오신 것을 환영합니다
Telegram 구독 그룹:https://t.me/TechFlowDaily
트위터 공식 계정:https://x.com/TechFlowPost
트위터 영어 계정:https://x.com/BlockFlow_News














