

「光インターコネクト」産業チェーンの1万字に及ぶ解説:GPUの輝きに隠されたAIインフラのボトルネック
TechFlow厳選深潮セレクト
「光インターコネクト」産業チェーンの1万字に及ぶ解説:GPUの輝きに隠されたAIインフラのボトルネック
GPU の演算能力の爆発的向上により、光インターコネクトが AI インフラにおける新たなボトルネックへと押し上げられており、CPO(Co-Packaged Optics)技術がサプライチェーン全体の構造を再編している。この数千億人民元規模の市場機会は、上流の基板から下流のファウンドリに至るまで、全工程にわたって顕在化しつつある。
編集・翻訳:TechFlow
司会:ニコ
元タイトル:AI光インターコネクト:GPUの輝きに隠された、次の1兆ドル市場か?
ポッドキャスト元:ニコ・フロンティア・アルファ
放送日:2026年5月8日
編集者による解説
光インターコネクトは、もはやGPUの「付属部品」ではなく、AIデータセンターの核心的ボトルネックへと変化しつつあります。単一ラック、ラック間、さらにはスーパーノードレベルで数百~数千枚のGPUを協調動作させる必要が生じた際、実際の計算性能(算力)利用率を決定づけるのは、もはやチップそのものではなく、GPU間のデータ転送能力です。
本ポッドキャストでは、産業チェーン全体への投資・調査視点から、光トランシーバー(光モジュール)、シリコンフォトニクスPIC(光子集積回路)、CPO(共封装光学)、外部レーザー、InP基板、SOI基板、ファウンドリおよびパッケージング・テストといった要素を1枚の地図に統合し、AVGO、MRVL、GLWからCOHR、LITE、TSEM、さらにSIVE、AAOI、AXTI、IQE、Soitecに至るまで、階層別に整理したポートフォリオ構成フレームワークを提示します。
本回で最も注目すべき点は、特定の個別銘柄の推奨ではなく、「AIインフラ競争が『誰がより多くのGPUを保有しているか』という段階から、『誰がより希少な光インターコネクトサプライチェーンを確保できるか』という段階へと拡大しつつある」という判断です。この中で、CPO(共封装光学)は最大の成長変数となる可能性があります。
要点抜粋
なぜ光インターコネクトが突如として重要になったのか
- 「NVIDIAのGB300 GPUアクセラレータカード1枚の演算性能がどれほど高くても、それが他の数千枚のGPUと高速に通信できない限り、その大部分の性能は無駄になります。」
- 「インターコネクトの帯域幅が不足していれば、いくらGPUを大量購入しても、費用対効果は極めて低くなります。」
- 「訓練でも推論でも、複数GPUの協調処理が必要な場合は、GPU間で高速なデータ交換が不可欠であり、そのデータ伝送路こそがインターコネクトです。」
- 「光インターコネクトは単なる概念的なバブルではありません。AIデータセンターにおけるインターコネクト需要は、現実的かつ緊急・不可逆的です。」
銅線ケーブルの退場と光ファイバーの台頭
- 「銅線ケーブルの伝送速度はすでに物理的限界に近づいており、1本の銅線が実現可能な帯域幅は頭打ち状態です。」
- 「銅線ケーブルは数メートルを超えると信号減衰と干渉が顕著になり始めますが、AIデータセンターにおける接続距離は数十メートル~数百メートルにも及びます。」
- 「光ファイバーの帯域幅は銅線ケーブルの数十倍に達し、数キロメートルの距離でも問題なく伝送可能であり、消費電力は無視できるほど低いです。」
光モジュールの産業的本質
- 「光モジュールは、異なるラック間の通信を担っており、ラック内部のGPU間通信は担当しません。」
- 「光モジュール産業とGPU産業は独立した2つの市場ではなく、GPUの出荷台数が直接的に光モジュールの需要を牽引しています。」
- 「1つの光モジュールの製造には、2種類の全く異なる半導体プロセス技術体系が関与します。すなわち、光チップ(光学チップ)はInP化合物半導体で製造され、DSPチップ(デジタル信号処理チップ)はシリコンで製造されます。」
CPOの真の意味
- 「CPOが破壊するのは、光モジュール内の特定コンポーネントではなく、光モジュールという製品そのものの形態です。」
- 「CPOは既存製品の単なるアップグレードではなく、アーキテクチャレベルでの再構築です。」
- 「より正確に言えば、CPOは、従来のプラグアブル(着脱式)光モジュール市場を単純に置き換えるのではなく、それよりも遥かに大きな新規市場を開拓するものです。」
産業チェーン投資フレームワーク
- 「光インターコネクト産業チェーンは、GPUのようにNVIDIAが寡占するような市場ではなく、極めて細分化され、ボトルネックが分散化された構造です。」
- 「上流に進むほど企業規模は小さくなり、価格変動性(エラスティシティ)は高まりますが、確実性は低下します。下流に進むほど企業規模は大きくなり、確実性は高まりますが、価格変動性は低下します。」
- 「高いリスクと変動性を許容できる場合、投資の核心的ロジックは『ボトルネックの特定』です。各ボトルネック環節には、通常1~2社しか参入できません。」
GPU以外の、AIインフラで真に希少な『神経ネットワーク』
過去2~3年間、ほぼすべての人がGPUと計算性能(算力)について語ってきました。ChatGPT(OpenAIが提供する生成AI製品で、大規模言語モデルの実用化ブームを引き起こしました)の登場とAI技術革命の勃興以降、NVIDIA株価は3年間で15倍に跳ね上がり、計算性能はAI大規模モデルにとって避けられないキーワードとなりました。GPUを中心とする半導体産業チェーンも、景気循環を越えた全盛期を迎えました。
しかし、過去1年間に、GPUと同様に重要であり、それ以上に希少な環節が静かに爆発しつつあります。大規模データセンターの展開において、たとえNVIDIA GB300 GPUアクセラレータカード1枚の計算性能がどれほど高くても、それが他の数千枚のGPUと高速に通信できない限り、その大部分の性能は無駄になります。インターコネクトの帯域幅が不足していれば、いくらGPUを大量購入しても、費用対効果は極めて低くなります。この数千枚のGPUを高速に相互接続する役割を担うのが、光インターコネクトです。
光通信分野の調査機関LightCountingのデータによると、2024年の世界光モジュール市場規模は前年比100%増の154億ドルに達しました。2025年も55%増加し、238億ドルに達すると予測されています。楽観シナリオでは、LightCountingは2030年までに光インターコネクト産業チェーン全体の市場規模が1,100億ドルを突破すると予測しています。

しかし、この産業チェーン上の企業の多くは、一般投資家にとって名前すら聞いたことがないかもしれません。SIVE/SIVEEの年間売上高は約3,000万ドルで、2026年初頭からの上昇率は10倍に達しています。TSEM(Tower Semiconductor、イスラエルの特殊ファウンドリ)は市場から「光インターコネクト分野のTSMC」と称され、その70%の生産能力が2028年まですでに契約済みです。COHR(Coherent、光学・材料分野の垂直統合企業)の年間売上高は約58億ドルで、NVIDIAから20億ドルの戦略的投資を受けています。
本日の内容では、光インターコネクト産業チェーンを最初から最後まで徹底的に解剖します。光インターコネクトとは何か、光モジュールの構成要素は何か、次世代技術の方向性は何か、産業チェーンのキーボトルネックはどこにあるのか、各企業の位置付けは何か、そして投資家が自身のリスク許容度に応じてこの分野にどのようにポートフォリオを構築すべきか、を明確にお伝えします。
訓練・推論とインターコネクト:なぜGPU間で高速通信が必要なのか
具体的な企業分析に入る前に、まず「なぜ光インターコネクトが突如としてAIインフラの中で最も重要かつ希少な環節の一つとなったのか?」という問いに答える必要があります。これは、AIがどのように機能するかという基本から説明する必要があります。AIの処理は大きく2つのフェーズに分けられます:訓練(トレーニング)と推論(インファレンス)です。
訓練とは、大量のテキスト、画像、コードをモデルに入力し、既存のコンテンツに基づいてモデルが継続的に学習・進化していくプロセスです。大規模言語モデルのパラメーター数は兆単位に達することがあり、単一GPUでは到底収容できません。そのため、これを数千分割し、数千枚のGPU上で並列計算する必要があります。各GPUが自らの担当部分の計算を終えた後、中間結果を他のGPUに送信し、協調して全体のタスクを完了させなければなりません。
推論とは、既に学習済みの知識を活用して回答を生成するプロセスです。あなたがChatGPTに質問すれば、数十秒後に回答が返ってくるのが推論です。多くの人は推論は単一GPUが1つの質問に答えるだけだと考えがちですが、2023年頃までは概ねその通りでした。しかし、2026年には状況は全く異なります。
AIは単純な一問一答から、深層推論やAgentic AI(エージェント型AI)へと進化しています。ユーザーとのインタラクション対象は、単なるチャットボットではなく、タスク計画、多段階推論、複数データソースへの照会などを行う複雑なエージェント(AIエージェント)へと変化しています。1回のインタラクションの裏側には、数百~数千枚のGPUが協調して稼働している可能性があります。訓練でも推論でも、協調処理が関わる限り、GPU間で高速なデータ交換が必須であり、そのデータ通路こそがインターコネクトです。
なぜ銅線ケーブルでは不十分なのか
これまでのインターコネクトは主に銅線ケーブル(電気信号)で行われていましたが、現在この通路は徐々に光ファイバー(光信号)へと置き換えられつつあります。銅線ケーブルが不十分な理由は主に3つあります。
第一に、銅線ケーブルの伝送速度はすでに物理的限界に達しています。材料やプロセスをいかに最適化しても、1本の銅線が実現可能な帯域幅は頭打ちです。まるで2車線の道路が混雑していても、同時に走れる車は2台しかいないのと同じです。第二に、距離が長くなるほど信号品質が劣化します。銅線ケーブルは数メートルを超えると信号減衰と干渉が始まりますが、AIデータセンター内の接続距離は数十メートル~数百メートルにも及び、銅線ケーブルでは耐えられません。第三に、銅線ケーブルは消費電力が大きいことです。GPUは世代ごとに消費電力が増加しており、H100は700ワット、B200は1,000ワット、GB300ではさらに高くなります。このような高消費電力レベルにおいて、GPU間の銅線ケーブル接続自体が莫大な電力を消費する可能性があります。
一方、光ファイバーは全く異なります。1本の光ファイバーの帯域幅は銅線ケーブルの数十倍に達し、数キロメートルの距離でも問題なく伝送可能です。また、消費電力は無視できるほど低く、さらに複数の異なる波長の光信号を同時伝送できます。まるで1本の高速道路を8車線に分け、それぞれ異なる色の光が干渉せずに走行するようなものです。1本の光ファイバーは、数十本の銅線ケーブルに相当します。
光インターコネクトの3つの段階
光をデータセンター内で使用するというアイデアは、突然現れた新技術ではなく、非常に明確な3つの段階を経て進化してきました。各段階において、光の適用範囲はチップに近づいていっています。
第1段階は2020年以前です。当時、光は主にデータセンター間の接続に使われていました。例えば、クラウド事業者が北京と上海にそれぞれデータセンターを保有し、その距離が1,000キロメートル以上離れている場合、光ファイバーで接続する必要がありました。しかし、データセンター内部では、サーバー間の接続は依然として銅線ケーブルが主流でした。
第2段階は2023年から2024年にかけてです。ChatGPTが2022年末にAI技術革命を引き起こし、翌年にはGPUの販売が爆発的に伸びましたが、当初の光モジュール市場は顕著な活性化を見せませんでした。その理由は、当時のNVIDIA GPUクラスターが主に銅線ケーブルを使用しており、光モジュールはコアコンポーネントではなかったためです。さらに悪いことに、2023年初頭には景気後退への懸念からクラウド事業者が資本支出を削減し、Meta(Facebookの親会社、世界主要なクラウドおよびAIインフラの調達先の一つ)は光モジュール導入計画の半分以上をキャンセルしました。
真の転換点は2024年に訪れました。クラウド事業者のGPUクラスターは数百台から数千台、さらには1万台以上へと拡大し、銅線ケーブルの数メートル級の伝送距離では到底対応できなくなりました。NVIDIAは参考アーキテクチャにおいて、銅線ケーブルをプラグアブル光モジュールに置き換えました。このアーキテクチャレベルでの切り替えが市場を刺激し、2024年の光モジュール市場規模は前年比100%増加しました。
第3段階は2025年から現在に至ります。NVIDIA Blackwell(NVIDIAの最新AI GPUアーキテクチャ)が本格的に展開され、消費電力がさらに高まり、インターコネクトの帯域幅要求も増大し、光モジュール需要がさらに急増しました。同時に、世界五大クラウド事業者の前9カ月間の資本支出合計は3,000億ドルを超え、過去最高を記録しました。光モジュール需要は供給を2倍以上上回り、深刻な需給不均衡が発生しました。今年3月、NVIDIAはLumentumおよびCoherentに対し、それぞれ20億ドルの投資を表明しました。GTC 2026(NVIDIA年次開発者カンファレンス)では、NVIDIAがCPOソリューションおよび次世代Rubinアーキテクチャにおける光インターコネクト設計を披露し、光インターコネクトがマイナーな市場からAIインフラのメインストーリーへと昇格したことを宣言しました。
光モジュールとは:電気信号と光信号の『翻訳機』
投資・調査の本論に入る前に、いくつかの基礎概念を説明します。まず第1に光モジュールです。GPUチップ自体は電気信号のみを認識しますが、光ファイバー内を流れるのは光信号です。両者は言語が異なるため、電気信号を光信号に翻訳して送信し、光信号を受信したら再び電気信号に翻訳する「翻訳機」が必要です。この翻訳機こそがプラグアブル光モジュールです。
光モジュールはUSBメモリ程度のサイズで、片方はサーバーのネットワークカードに差し込み、もう片方は光ファイバーに接続します。大規模AIデータセンターでは、数万~十数万個のこうした「小さな箱」が存在します。ここでよく誤解される概念があります。「光モジュールは異なるラック間の通信を担当しており、ラック内部のGPU間通信は担当しない」という点です。
例として、NVIDIA GB300 NVL72(NVIDIAのラック単位GPUシステム)を取り上げます。1つのラック内には72枚のGPUが搭載されており、GPU間の接続はNVIDIAの高速GPUインターコネクト技術であるNVLinkおよびNVSwitch(NVスイッチ)を用いて、すべて銅線による電気信号で行われます。その距離は数十センチメートル~1~2メートル程度であり、光は不要です。データが1つのラックから別のラックへと移動する際、距離が十数メートル~数十メートル、あるいはそれ以上になる場合にのみ、光モジュールが必要になります。
完全なAIクラスターにおいて、光モジュールは通常2箇所に設置されます:サーバーのネットワークカード上とスイッチ上です。1本の光ファイバーの両端にはそれぞれ1個の光モジュールが接続されます。GPUの枚数が増え、ラックの数が増え、ラック間の接続需要が高まれば、光モジュールの需要も高まります。光モジュール産業チェーンとGPU産業チェーンは独立した市場ではなく、GPUの出荷台数が直接的に光モジュールの需要を牽引しています。
光モジュールの5つのコアコンポーネント
USBメモリサイズの光モジュールには、通常5つのコアコンポーネントが含まれています:レーザーチップ、変調器チップ、検出器チップ、DSPチップ、およびレンズと光ファイバー結合コンポーネントです。
第1にレーザーチップです。その機能は光を発することであり、安定したレーザー光を連続的に発することで光信号の媒体となります。レーザーはマイクロサイズの懐中電灯のようなもので、爪の先より小さく、しかし発する光は極めて正確かつ純粋です。レーザーの最も重要な要素は材料です。GPUやCPOではシリコンが使われますが、レーザーではリン化インジウム(InP)またはヒ素化ガリウム(GaAs)が使われます。シリコンは光を発することに先天的に不向きであり、InPやGaAsなどの化合物半導体の原子構造は光子の生成に適しています。これが、レーザーチップの製造をTSMCのようなシリコン基盤ファウンドリが担当していない理由です。
第2に変調器チップです。レーザーが発する光自体には情報が含まれておらず、単なる「空白の光」です。変調器の機能は、電気信号を光に書き込むことです。GPUから送られてくるのは0と1のバイナリ電気信号ですが、変調器はレーザーの点灯・消灯や強度の変化を制御し、光によって0と1を表現します。前述の例えを続けますと、レーザーは常に点灯している懐中電灯であり、変調器はそのスイッチを操作する手です。1秒間に数百億回の高速でスイッチを操作します。場合によっては、変調器とレーザーが同一チップ上に集積され、EML(Electro-absorption Modulated Laser:電吸収変調レーザー)と呼ばれます。これは懐中電灯とスイッチを1つの部品に統合したものです。
第3に検出器チップです。変調器は電気信号を光信号に変換する送信工程を担当しますが、受信側では光信号を再び電気信号に変換する必要があります。それが検出器の役割です。これは受信側の「耳」のようなもので、光を検知すると1を出力し、光を検知しなければ0を出力します。検出器も通常InPまたはGaAs材料系で製造されます。
第4にDSPチップ(Digital Signal Processor:デジタル信号処理チップ)です。これは光モジュール内の「脳」に相当し、エラー訂正、符号化、信号品質の均等化を担当します。光信号の伝送過程ではノイズや歪みが発生します。これは、交通量の多い大通りで電話をかけているような状態で、相手の話が聞き取れないことがあります。DSPは送信側で特殊な方法で符号化を行い、受信側でノイズを除去して、復元された0と1が元のデータと一致することを保証します。DSPはシリコン基盤チップであり、GPUやCPOと同じ半導体プロセス体系で製造され、通常はTSMCなどのシリコン基盤ファウンドリで製造されます。
800Gおよび1.6Tは光モジュールの伝送速度を示します。800Gは毎秒800ギガビット、1.6Tは毎秒1.6テラビットのデータを伝送できることを意味し、速度は2倍になります。光モジュールは400Gから現在主流の800G、さらに展開中の1.6Tへと進化しており、速度が上がるにつれ、チップ設計の難易度も高まり、DSPのコストと設計難易度も高まり、時にはレーザーチップよりも高価になることがあります。
第5にレンズと光ファイバー結合コンポーネントです。これはレーザーから発せられた光を、光ファイバーの入口に正確に合わせる役割を果たします。レーザーが発する光束は非常に細く、光ファイバーのコアも非常に細く、髪の毛の10分の1程度の太さです。そのため、ミクロン単位の精度が求められます。これは、針の穴に別の針を通すような作業を、工場のライン上で何百万回も自動で行うようなものです。
以上の5つのコンポーネントを順に追うと、光モジュールの動作プロセスは明確になります。GPUから電気信号が送られ、まずDSPで符号化・エラー訂正が行われ、その後変調器へと送られます。変調器は、レーザーが発する光に電気信号を書き込みます。その光はレンズを通過して光ファイバーに入り、数十メートル~数百メートルを伝送します。到着地点では、光が光ファイバーから出てレンズを通過し、検出器に正確に照射されます。検出器は光を再び電気信号に変換し、それを別のDSPがデコード・エラー訂正してから、別のGPUへと送られます。
光モジュールの製造:2つの半導体プロセスの併存
多くの人は無意識のうちに「チップといえばTSMCが製造するものだ」と考えがちですが、光モジュールのチップは全く異なります。1つの光モジュールには、2種類の全く異なるチップが存在し、それぞれ異なる材料で構成され、異なる工場で製造されます。
第1にDSPチップです。これは光モジュールの「脳」であり、エラー訂正・符号化を担当します。シリコン基盤チップであり、GPUやCPOと同様の製造プロセスで製造され、TSMCなどのシリコン基盤ファウンドリで製造されます。DSPチップの設計会社としては、AVGO(Broadcom:ブロードコム、通信チップおよびカスタムAIチップの大手)、MRVL(Marvell Technology:マーベル・テクノロジー、データセンターおよびネットワークチップ企業)、CRDO(Credo:データインターコネクトチップ企業)などが挙げられます。
第2に光学チップです。これにはレーザー、変調器、検出器が含まれ、これらはInPなどの化合物半導体材料で製造されます。一部の企業は設計から製造まで一貫して行っています。例えばLITE(Lumentum:光通信デバイスおよびレーザー企業)、COHR(Coherent:光学材料およびデバイス企業)、AAOI(Applied Optoelectronics:米国の光モジュールおよび光デバイス企業)などです。また、レーザー設計に特化した小規模企業もあり、例えばSIVE/SIVEEは最も困難なレーザー設計に特化し、それをファウンドリに委託して製造しています。
光学チップはTSMCに直接製造を依頼することはできません。TSMCの全製造ライン、設備、化学薬品、プロセスパラメーターは全てシリコン向けに設計されています。一方、InPは全く異なる材料であり、ウェハーのサイズ、エッチング用化学薬品、結晶成長温度など全てが異なり、TSMCのラインではそもそも稼働できません。そのため、光学チップには独自の製造システムが存在します。
基板とエピタキシャル成長:光学チップ製造の2つの土台
光学チップの製造を理解するには、まず「基板」と「エピタキシャル成長」という2つの概念を理解する必要があります。基板はすべての光チップ製造の出発点であり、その上にすべての機能構造が形成される特殊な薄板です。例えるならば、光を発する「レーザーの木」を育てるには、普通の砂地に種をまくのではなく、種の分子構造とマッチした特殊な土壌が必要です。普通のシリコンは砂地であり、光を発するには不向きです。InPこそがその特殊な土壌なのです。
基板の品質は、その上に形成されるすべての構造の品質を直接的に左右します。基板に原子レベルの欠陥があれば、その欠陥は亀裂のように上層へと伝わり、レーザーチップが仕様を満たさなくなり、光モジュールの量産が不可能になります。高純度InP基板の製造は極めて困難であり、世界でこの水準を安定して実現できる工場はごく少数に過ぎません。
基板があっても、すぐにチップを製造できるわけではなく、基板の上に機能層を1層ずつ積み重ねていく必要があります。このプロセスを「エピタキシャル成長」と呼びます。レーザーが光を発する理由は、基板そのものが光を発するのではなく、基板上に成長させた特殊構造が光を発するためです。電流がエピタキシャル層を通過すると、電子と正孔が再結合して光子を放出し、これがレーザー光の起源です。
エピタキシャル層は1層あたり数ナノメートルの厚さで、数十層が重なり合って「千層餅」のような構造を形成します。各層の成分、厚さ、ドーピング濃度は極めて高い精度が要求され、1層の原子の数が1つ違えば光の波長がずれ、レーザーは使用不能になります。
InP基板はAXTI(米国化合物半導体基板サプライヤー)が提供し、エピタキシャル成長はIQE/IQEE(英国化合物半導体エピタキシャルウェハー・サプライヤー)が担当します。エピタキシャル成長が完了した後、レーザーチップの製造には2つのルートがあります。1つはFabless(設計・製造分離)方式で、例えばスウェーデンのSIVE/SIVEEがレーザー設計を行い、台湾のWin Semi(Winstar Semiconductor:化合物半導体ファウンドリ)に製造を委託するものです。もう1つはIDM(Integrated Device Manufacturer:設計・製造一貫型)方式で、例えばLITE、COHR、AAOIはエピタキシャル成長、レーザー、変調器、検出器、光モジュール組立まで全て自社で行っています。
したがって、1つの光モジュールの製造は、InP化合物半導体による光学チップ製造と、シリコンによるDSPチップ製造という、全く異なる2つの半導体プロセス体系を横断します。これら2つは互換性がなく、同一の製造ラインで製造することはできません。いずれかの環節で生産能力が足りなくなると、光モジュール全体の出荷が止まってしまいます。
これが、光学企業がDSPを簡単に手がけず、デジタルチップ企業がレーザーを簡単に手がけない理由です。光学チップ設計とデジタルチップ設計は全く異なる専門分野です。光学エンジニアはレーザー物理学、光波導理論、量子井戸構造を理解しています。一方、デジタルチップエンジニアは論理回路およびデジタル信号処理アルゴリズムを理解しています。両者のスキルセットは重複せず、心臓外科医と脳外科医がどちらも外科医ではあるものの、手術を互いに代行できないのと同じです。
光インターコネクト産業チェーンの最も興味深い点はここにあります。それは、GPUのようにNVIDIAが独占する市場ではなく、極めて細分化され、ボトルネックが分散化された産業チェーンです。この分散化ゆえに、一般投資家も見過ごされがちな小規模企業を発掘するチャンスがあるのです。
CPO:光学部品をサーバー背面からチップの隣へと移動させる
プラグアブル光モジュールはあくまで現行のソリューションです。さらに注目すべきは、この産業チェーンが根本的な再構築を目前にしていることです。CPO(共封装光学)と呼ばれる次世代技術が、光インターコネクト全体のアーキテクチャを一から作り直そうとしています。
CPOの正式名称はCo-Packaged Opticsで、日本語では「共封装光学」です。CPOが解決しようとしている課題は、「光モジュールがGPUから遠すぎる」という点です。現行の標準的なソリューションでは、光モジュールはサーバー背面に差し込まれるプラグアブルな小さな箱であり、GPUが生成した電気信号はまず数十センチメートルの銅線を経由してサーバー背面へと送られ、そこで光信号に変換されます。この数十センチメートルの銅線はエネルギー損失、遅延、発熱を引き起こします。AIクラスターの密度が高まるにつれ、このわずかな損失が数十万倍に拡大し、重大な問題となります。
CPOの発想は、光学部品をサーバー背面からチップのパッケージ内部へと移動させ、GPUやスイッチチップに極めて近接させるものです。これにより、電気-光変換の距離を数十センチメートルから数ミリメートルへと短縮します。例えるならば、現行のソリューションは「ご飯」と「汁物」を別々の容器に入れ、GPUがご飯の容器に、光モジュールが別個のコップに入っている状態です。CPOは、汁物をご飯の容器の独立した仕切りに注ぐことで、「ご飯」と「汁物」は別々ではあるものの、同じ容器の中に収まり、距離は数ミリメートルに短縮されるのです。

しかし、光学部品をチップのパッケージ内部に移動させるには、大きな障壁があります。従来の光モジュール内の光学チップはInPで作られていますが、GPUはシリコンで作られています。InPとシリコンのパッケージングプロセスは互換性がなく、InPチップとシリコン基盤GPUを単純に同一パッケージ内に収めることはできません。この課題に対する解決策は、光学チップをシリコンで作ることです。これがシリコンフォトニクスPIC(光子集積回路)の登場を意味します。
PICはPhotonic Integrated Circuitの略で、日本語では「光子集積回路」です。我々がよく知るIC(集積回路)は数十億個のトランジスタを1つのチップ上に集積して計算を行いますが、PICは同様の発想で、トランジスタではなく光学部品(変調器、光波導、検出器など)を1つのシリコン基盤チップ上に集積します。シリコン基盤であるため、GPUと同じパッケージング技術で集積可能であり、これはInP光学チップでは実現できないことです。
シリコンフォトニクスPICで使われるシリコンウェハーは、通常のシリコンウェハーではなく、SOI(Silicon-On-Insulator:絶縁体上シリコン)と呼ばれる特殊な三層構造のシリコンウェハーです。基板と上層シリコンの間に絶縁層を挟むことで、光信号を上層の薄いシリコン層内に閉じ込め、下層へ漏れ出さないようにします。通常のシリコンウェハーは実心の塊であり、光が入ると四方八方に広がって制御できなくなりますが、SOIの中間の絶縁層は鏡のように働き、光を上層へと反射させ、設計通りの経路に沿って光を導きます。
SOI基板という細分化された分野では、フランスのSoitec(フランスのSOI基板サプライヤー)が中心的なサプライヤーの1つであり、市場での地位はほぼ独占的です。シリコンフォトニクスPICのファウンドリは主にTSEM、つまりTower Semiconductorです。TSEMはSOI基板上にシリコンフォトニクスチップを加工し、改良されたCMOSプロセスを用いています。このプロセスはTSMCには馴染みがなく、TSEMはこの細分化された分野でシェアが最も高いファウンドリです。
しかし、シリコンには天然の欠点があります。それは光を発しないことです。したがって、シリコンフォトニクスPICは光を操ることはできますが、光を発生させることはできず、光源は依然としてInPレーザーが必要です。これにより、CPOのコア構造が形成されます。パッケージ内部には、変調・伝送・検出などの光を操る機能を担うシリコンフォトニクスPICを配置し、それを先進パッケージング技術でGPUやスイッチチップと同一パッケージ基板上に並べ、距離を数ミリメートルに短縮します。これは、HBMメモリがGPUの隣に配置されるのと同様です。
シリコンフォトニクスPICの隣には、GPUの電気信号とシリコンフォトニクスPICの光信号の間で変換を行うドライバーチップも配置されます。これはシリコン基盤チップであり、本質的には従来の光モジュールにおけるDSPの大幅に簡略化されたバージョンです。CPOでは電気-光変換距離が数ミリメートルしかないため、DSPのような複雑なエラー訂正・符号化は不要で、シンプルなドライバーで十分です。
パッケージ外部には、外部光源(External Laser Source:ELS)としてレーザーを配置します。レーザーは光ファイバーを通じて光をパッケージ内部のシリコンフォトニクスPICへと送ります。レーザーをパッケージ内部に直接組み込まない理由は2つあります。1つは、InPレーザーは発熱量が大きく、GPUやシリコンフォトニクスPICと密接に配置すると問題が生じるためです。もう1つは、レーザーの寿命は有限であり、パッケージ内部に組み込んだ場合、故障時に数万ドル相当の高価なチップ全体を廃棄しなければならなくなるためです。レーザーを外部着脱式の形で設計すれば、故障時に簡単に交換でき、チップそのものには影響を与えません。
CPOが真に破壊しているのは、光モジュール内の特定コンポーネントではなく、光モジュールという製品そのものの形態です。現在のプラグアブル光モジュールは、レーザー、変調器、検出器、DSPを内蔵した独立した小さな箱です。CPOはこの箱を分解し、シリコンフォトニクスPICをチップ内部に直接パッケージングし、レーザーを独立した外部光源とし、DSPは大幅に簡略化あるいは省略し、サーバー背面の小さな箱を不要にします。これは既存製品の単なるアップグレードではなく、アーキテクチャレベルでの再構築です。
CPOが2026年に投資テーマとなった理由
CPOという概念は長年にわたり存在していましたが、なぜ2026年に突然注目を集める投資テーマとなったのでしょうか?ゴールドマン・サックスが発表したレポートによると、光インターコネクトの潜在市場規模は、現在の約150億ドルから2028年には1,540億ドルへと約9倍に拡大し、そのうちCPOが910億ドルを占めると予測されています。その核心的理由はただ1つ、NVIDIAの次世代アーキテクチャがCPOを「選択肢」から「必須要件」へと変えたことです。

現在のGB300 NVL72システムでは、72枚のGPUが1つのラックを構成し、ラック内部のGPU間接続は依然として銅線ケーブルで行われています。しかし、AIクラスターの規模が数百~数千枚のGPUへと拡大するにつれ、ラック間のネットワーク接続がボトルネックとなります。NVIDIAは次世代Rubin(NVIDIAの後続AIプラットフォームのコードネーム)プラットフォームにおいて、ラック間のネットワークスイッチにCPOソリューションを導入し、従来のプラグアブル光モジュールを置き換えます。これはNVIDIAが自社プラットフォームでCPOを正式に採用した初めての事例です。
さらにその次のフェインマン(NVIDIAの更に後続のAIプラットフォームのコードネーム)では、CPOがラック内部のGPU間接続へとまで進展する可能性があります。つまり、光はラック間からGPU間へと、一歩一歩近づいているのです。LumentumのCEOは最新決算発表の電話会議で、CPOは大規模な需給不均衡を引き起こすと確認し、CPOがLumentum最大の単一成長ドライバーであり、なおかつ非常に初期段階にあるとも述べています。
業界データによると、CPO市場の実際の出荷量はまだ極めて少なく、2026年は約1.6億ドルで、主に試作および小ロット出荷に留まっています。しかし、ゴールドマン・サックスの予測が実現すれば、2028年には910億ドルへと膨張し、ゼロから千億ドルへの爆発的成長曲線を描くことになります。NVIDIAは2026年初頭からCPOスイッチの量産を開始しており、ブロードコムは2025年10月に顧客へCPO関連製品を納品しています。TSMCもCOUPE(TSMCのCPO向け先進パッケージングソリューション)を発表しています。NVIDIAとブロードコムがCPOを採用していることは、それが将来の概念ではなく、現実化しつつあることを示しています。
ただし、CPOが短期間でプラグアブル光モジュールを完全に置き換えることはありません。CPOは主に超高密度AIクラスター内部の接続需要、例えばNVIDIAスーパーノード内部のGPU間接続を解決します。一方、データセンターにはラックからスイッチ、スイッチからスイッチ、データセンターからデータセンターなど、多数の他の接続シナリオが存在し、これらのシナリオでは、予見可能な将来にわたってプラグアブル光モジュールが引き続き使用されます。したがって、より正確には、CPOはプラグアブル光モジュール市場を単純に置き換えるのではなく、それよりも遥かに大きな新規市場を開拓するものであり、両者は異なるシナリオで共存します。
CPO爆発後の5つの恩恵を受ける環節
もしCPOが今後本当に爆発し、スーパーサイクルを迎えるとすれば、最も恩恵を受ける産業チェーンの環節はおおよそ5つあります。
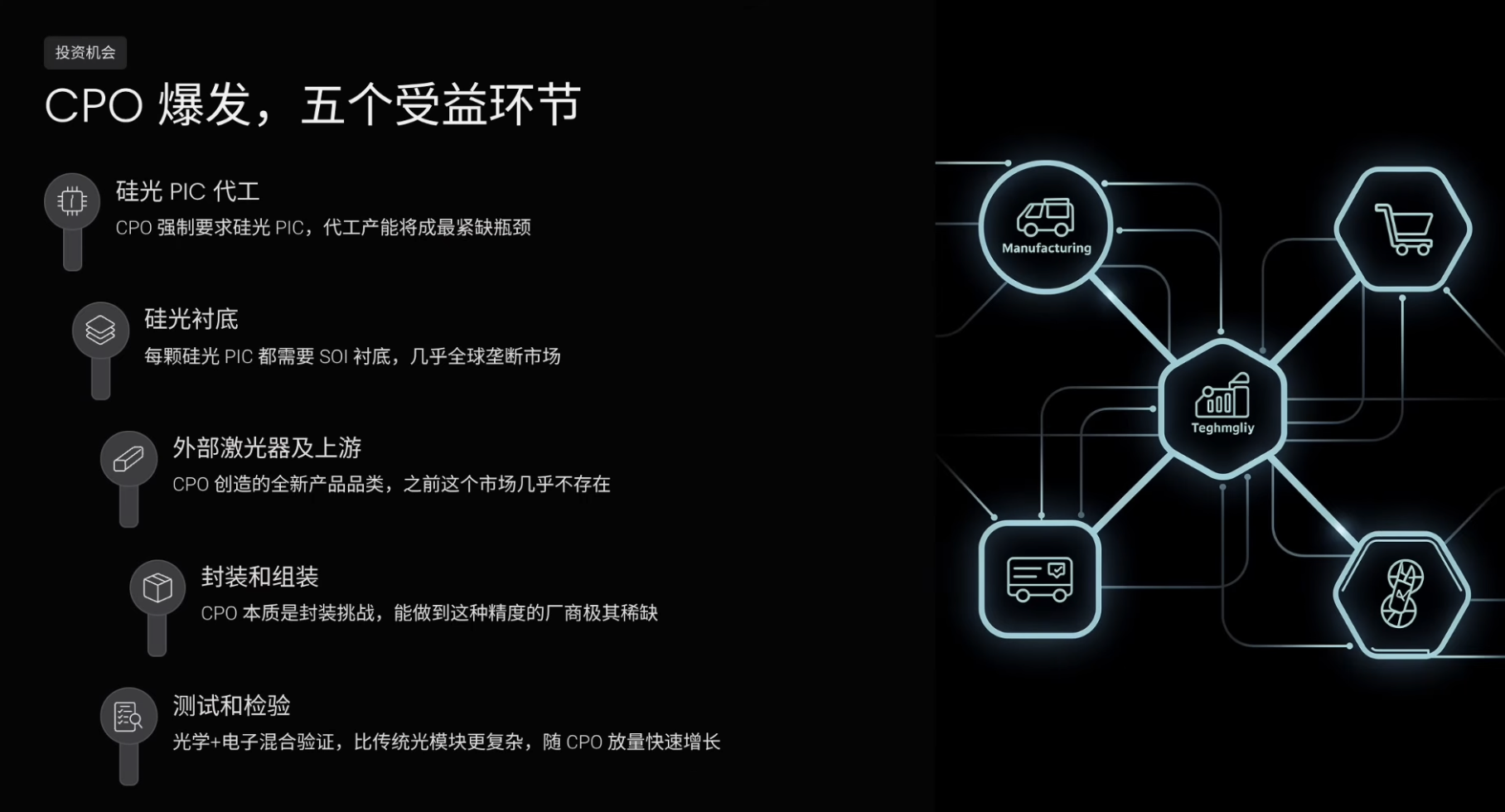
第1に、シリコンフォトニクスPICのファウンドリです。CPOアーキテクチャではシリコンフォトニクスPICの使用が強制され、これはGPUとの先進パッケージングを可能にする唯一の手段だからです。シリコンフォトニクスPICのファウンドリを提供できるメーカーは極めて少なく、その生産能力は最も逼迫したボトルネックの1つとなるでしょう。
第2に、シリコンフォトニクス基板です。1つのシリコンフォトニクスPICには必ずSOI基板が必要であり、CPOの普及に伴いシリコンフォトニクスPICの需要が爆発的に増加すれば、SOI基板の需要も同様に爆発的に増加します。SOI基板市場はほぼ世界的な独占状態です。
第3に、外部レーザーおよびその上流サプライチェーンです。CPOは新しい製品カテゴリーを創出します。従来のプラグアブル光モジュールではレーザーを箱の内部に統合していましたが、CPOアーキテクチャではレーザーを独立した外部光源として分離する必要があります。この市場はこれまでほとんど存在していませんでした。
ここにはさらに重要な工程のミスマッチがあります。大手レーザー企業の既存生産能力は、主にEML(電吸収変調レーザー)という従来型レーザーの製造に集中しており、これは光の発生と変調を1つのチップに集積したもので、プラグアブル光モジュール向けであり、その受注契約は2027~2028年まで締結されています。しかし、CPOには変調を担当しない、単に光を発するだけのシンプルなレーザーが必要です。変調はパッケージ内部のシリコンフォトニクスPICが担当します。2種類のレーザーはどちらもInPを使いますが、設計も生産ラインも異なり、シームレスな切り替えは不可能です。大手企業の生産能力は従来型レーザーの契約でロックされているため、Lumentum自身もCPO向けレーザーを公開市場から調達せざるを得ず、余剰需要は独立系レーザー企業へと流れることになります。
レーザー需要の爆発は、さらに上流へと波及します。より多くのレーザーは、より多くのInP基板およびより多くのエピタキシャルウェハーを意味します。ゴールドマン・サックスのレポートは、InP基板の供給逼迫が2027年まで続く可能性を警告しています。
第4に、パッケージングおよび組立です。CPOは本質的にパッケージングの課題であり、シリコンフォトニクスPICと電子チップを精密に統合する必要があります。その精度要件は極めて高く、CPOレベルのパッケージングおよび組立を実現できるメーカーは将来的に極めて希少なものとなります。
第5に、テストおよび検査です。各シリコンフォトニクスPICは出荷前に光性能テストおよび信頼性検証を受ける必要があります。CPOのテストは従来の光モジュールよりも複雑であり、光学と電子の混合検証を含むため、この環節もCPOの量産拡大に伴って急速に成長します。
まとめると、CPO需要の爆発後、最も恩恵を受けるのは、シリコンフォトニクスファウンドリ、シリコンフォトニクス基板、外部レーザー、InP基板およびエピタキシャル成長、パッケージング・組立、テスト・検査といったボトルネック環節です。

上流基板:AXTIとSoitec
上流から下流へと見ていきますと、基板分野で最も重要な2社はAXTIとSoitecです。両社は異なる技術ルートを担当しており、競合関係ではなく、補完関係です。AXTIはレーザー産業チェーン(光の発生)を担当し、Soitecはシリコンフォトニクス産業チェーン(光の制御)を担当します。光インターコネクトには両者の協調が不可欠です。
AXTIは、米国に本拠を置くInPおよびGaAs基板メーカーです。その業務は、インジウム、リン、ガリウム、ヒ素などの希少元素を精製・合成し、単結晶インゴットを引き、それを薄板に切断することです。AXTIの代替不能性は、高品質InP基板を製造できる企業が世界でごく少数しか存在しないことにあります。AXTIに加えて、日本の住友電工やドイツのFreibergerなど、ごく少数のメーカーのみが該当します。AXTIの護城河(モアット)は、材料の純度に関するプロセス技術の蓄積、数十年にわたるノウハウ、および長い顧客認証期間にあります。下流企業がサプライヤーを変更する場合、製品ライン全体を再検証する必要があり、切り替えコストは非常に高くなります。
CPOはInP基板を回避せず、むしろその需要を拡大します。CPOアーキテクチャでは、各GPUに外部レーザーが必要であり、レーザーの数はGPUの数と直接的に連動します。より多くのレーザーは、より多くのInP基板を意味します。したがって、CPOはAXTIにとって明確な追い風です。AXTIの投資属性は、時価総額が小さく、価格変動性が高く、需要の伝播にはタイムラグがあるものの、一旦注文に反映されれば、株価の価格変動性(エラスティシティ)は非常に大きくなる可能性があります。
Soitecはフランス・パリに上場するSOIシリコンフォトニクス基板メーカーです。Soitecはシリコンフォトニクス専用SOI基板分野で圧倒的な市場地位を有しており、Smart Cut(SoitecのSOIウェハー製造技術)という特許技術を発明しました。CPOの核はシリコンフォトニクスPICであり、各シリコンフォトニクスPICにはSOI基板が必要です。したがって、SoitecはCPOスーパーサイクルにおいて、確実性の高い恩恵を受ける企業の1つです。当時の評価額は帳簿価額の約1.4倍であり、世界的な独占企業としては低めの水準でした。注意点として、Soitecはパリ証券取引所に上場しており、米国市場には上場していません。
エピタキシャル層:IQE/IQEE
次にエピタキシャル層です。世界で重要な独立系エピタキシャルサプライヤーは、ロンドンに上場するIQE/IQEEです。IQEの護城河は、エピタキシャルプロセスそのものの難しさにあります。エピタキシャル成長は、基板上に「千層餅」のように機能層を1層ずつ積み重ねるプロセスであり、各層は数ナノメートルの厚さで、材料・温度・成長時間のわずかなずれもレーザーの不良につながります。こうしたパラメーターの組み合わせは「エピタキシャル・レシピ」と呼ばれ、IQEはこのレシピに関して数十年にわたる蓄積があり、単に資金を投入しても短期間で模倣することはできません。
CPOの爆発に伴い、IQEとAXTIのロジックは同様です。CPOはレーザー需要を拡大し、より多くのレーザーはより多くのエピタキシャルウェハーを必要とします。IQEのリスクは、顧客集中度が高く、LITEがその主要顧客の1つである点です。もしLITEが今後自社でエピタキシャル成長を手がけ、垂直統合を推進する場合、IQEの最大の収益源が打撃を受ける可能性があり、これは投資前に留意すべき単一ポイントリスクです。
レーザー層:SIVE/SIVEE、LITE、COHR、AAOI
さらに下流へと進み、チップ層に入ります。この層で最も希少な環節はレーザーです。主要企業にはSIVE/SIVEE、LITE、COHR、AAOIが含まれます。
SIVE/SIVEEは、過去1年間で光インターコネクト分野で最も急騰した銘柄の1つです。これはスウェーデンに上場する小規模企業で、時価総額は約15億ドル、年間売上高は約3,000万ドルです。同社はFabless寄りのルートを採用しており、独自のInP100プラットフォームと英国グラスゴーの小型ウェハー工場を有し、一定の製造能力を有しています。同時に、台湾のWin Semiと提携し、レーザー設計を成熟したファウンドリに委託することで、高出力レーザーの量産を拡大しています。
SIVE/SIVEEには5つのコア優位性があります。第1に、InP100標準化プラットフォームで、レーザーのコアモジュールを標準化し、ブロックのようにさまざまな仕様の製品を迅速に組み立てられる点です。第2に、ウェハー単位でのテストで、ウェハーを切り出してから1個ずつテストするのではなく、ウェハーのまま各チップを直接テストするため、歩留まり向上とコスト削減が可能です。第3に、現行および次世代技術の両方をカバーしており、プラグアブル光モジュール向けレーザーとCPO向け外部光源の両方の製品を有しています。第4に、AIデータセンター光インターコネクトに加え、LiDAR(ライダー)、衛星通信、防衛分野など、複数の市場で並行展開し、単一市場リスクを分散させています。第5に、軽資産型の拡張モデルで、小規模工場でコア検証および小ロット生産を行い、大規模量産はWin Semiの生産能力を活用することで、重資産の工場建設を回避しつつ、コア製造能力を維持しています。
SIVE/SIVEEは、CPOスーパーサイクルにおいて価格変動性(エラスティシティ)が非常に大きい銘柄です。その理由の1つは、大手企業の生産能力が従来型レーザーの注文でロックされており、CPO向け外部光源の余剰需要を独立系レーザー企業が受け止めなければならない点です。もう1つの理由は、同社が既に複数のCPOプロジェクトのサプライチェーンに組み込まれている点です。AMDのCPOソリューションはGlobalFoundries(グローバルファウンドリーズ:世界のウェハー製造企業)のプラットフォームを通じて推進されており、SIVEはそのエコシステム内で数少ないレーザー・サプライヤーの1つです。また、Marvell傘下のCelestial AI(シリコンフォトニクスインターコネクトのスタートアップ)、Ayar Labs(CPO/シリコンフォトニクスインターコネクトのスタートアップ)なども同社の顧客です。
ただし、SIVE/SIVEEのリスクも明確です。売上高が極めて低く、顧客の多くはまだ開発・検証段階にあり、正式な大量生産には至っていません。任意の2~3社の顧客が実績を上げれば、株価はさらに上昇する可能性がありますが、顧客が遅延またはキャンセルした場合には、株価が大幅に下落する可能性もあります。これは、高配当率の宝くじと捉えることができます。
LITE、すなわちLumentumは、レーザー分野におけるIDM(設計・製造一貫型)の代表企業です。同社はレーザー設計から製造、さらには完成光モジュールの組立まで一貫して行っています。LITEの最も重要な注目点は、NVIDIAから20億ドルの戦略的投資および数十億ドル規模の調達約束を獲得し、その生産能力を直接確保した点です。さらに、LITEはGoogle TPU(グーグルが自社開発したAIアクセラレータチップのエコシステム)と深く連携しており、GoogleのAIデータセンターではLITEの光路
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













