

IOSG|計算能力から知能へ:強化学習が駆動する分散型AI投資マップ
TechFlow厳選深潮セレクト
IOSG|計算能力から知能へ:強化学習が駆動する分散型AI投資マップ
システムがAI訓練のパラダイムと強化学習技術の原理を分解し、強化学習×Web3の構造的優位性を論証する。
著者:Jacob Zhao @IOSG
人工知能は「パターン適合」を中心とする統計的学習から、「構造化推論」を核とする能力体系へと進化しており、後訓練(Post-training)の重要性が急速に高まっている。DeepSeek-R1の登場は、大規模モデル時代における強化学習のパラダイムシフトを象徴しており、業界のコンセンサスとして次のような見解が形成されている:事前学習はモデルの汎用的能力基盤を構築するものであり、強化学習はもはや価値観の調整ツールにとどまらず、推論チェーンの品質と複雑な意思決定能力を体系的に向上させる技術であることが証明され、知能レベルを継続的に高める技術的経路として進化しつつある。
一方で、Web3は非中央集権型の計算資源ネットワークと暗号インセンティブ体系を通じてAIの生産関係を再構築しようとしている。強化学習がrolloutサンプリング、報酬信号、検証可能な訓練に対して持つ構造的要求は、ブロックチェーンの計算協働、インセンティブ分配、検証可能な実行と自然に一致している。本レポートでは、AI訓練のパラダイムと強化学習の技術原理を体系的に分析し、強化学習×Web3の構造的優位性を立証するとともに、Prime Intellect、Gensyn、Nous Research、Gradient、Grail、Fraction AIなどのプロジェクトについて考察を行う。
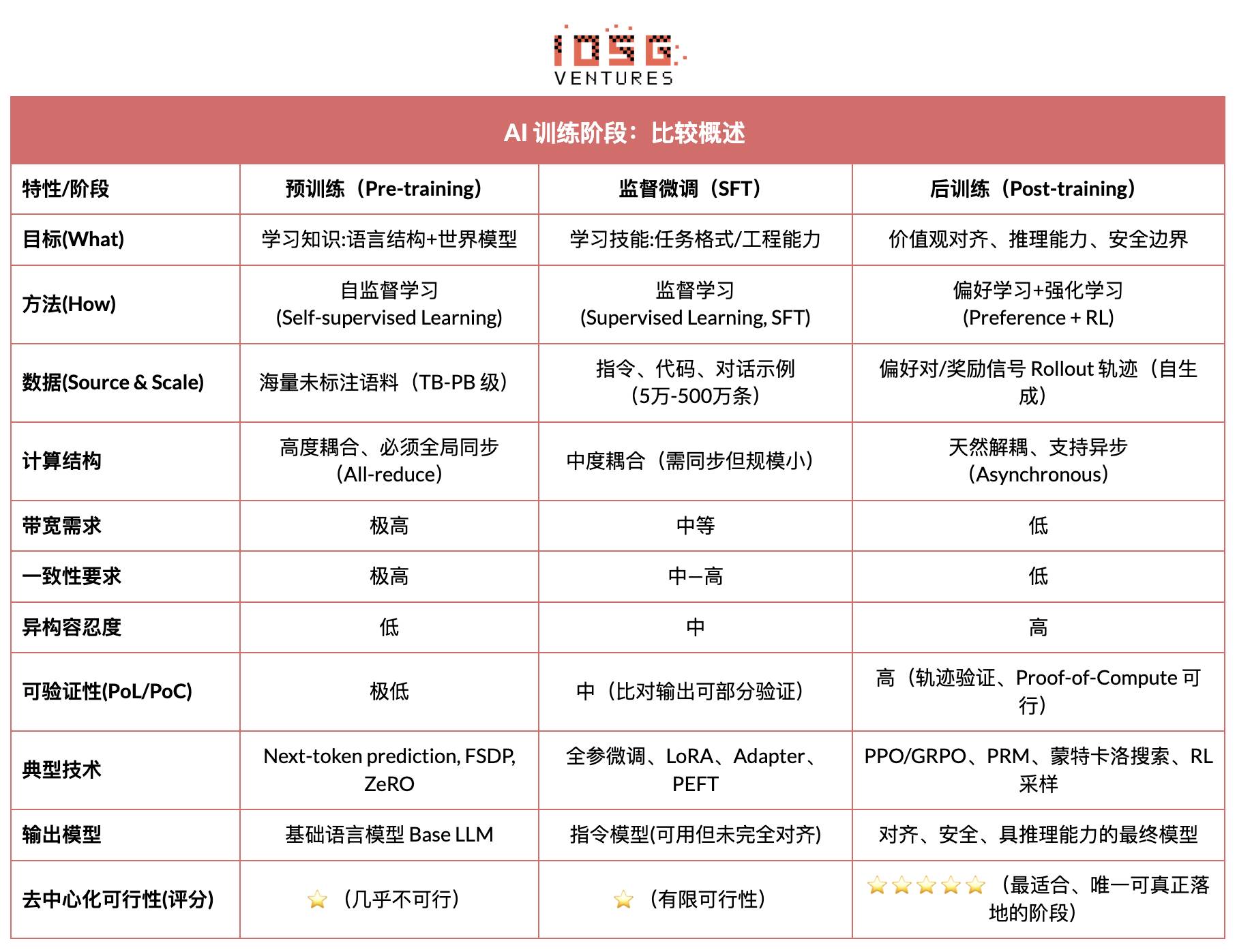
AI訓練の三段階:事前学習、指示微調整、後訓練アライメント
現代の大規模言語モデル(LLM)の訓練ライフサイクルは通常、以下の三つのコア段階に分けられる:事前学習(Pre-training)、監視付き微調整(SFT)、および後訓練(Post-training/RL)。これらはそれぞれ「世界モデルの構築—タスク能力の注入—推論力と価値観の形成」という機能を担っており、その計算構造、データ要求、検証難易度が非中央集権化との適合度を決定づけている。
-
事前学習(Pre-training)は大規模な自己教師あり学習(Self-supervised Learning)によってモデルの言語統計構造および跨モーダルな世界モデルを構築し、LLMの能力の基盤となる。この段階では兆単位のコーパス上でグローバル同期方式による訓練が必要であり、数千〜数万枚のH100を備えた同種クラスタに依存するため、コストの80–95%を占め、帯域幅とデータ著作権に対して極めて敏感である。そのため、高度に集中管理された環境でのみ実施可能である。
-
微調整(Supervised Fine-tuning)はタスク能力と指示フォーマットの注入を目的とし、データ量が少なく、コストも全体の約5–15%程度にとどまる。全パラメータ訓練またはパラメータ効率的な微調整(PEFT)手法(LoRA、Q-LoRA、Adapterなど)を採用できるが、勾配の同期が必要なため、非中央集権化の潜在能力は限定的である。
-
後訓練(Post-training)は複数の反復的サブフェーズから成り、モデルの推論能力、価値観、安全性の境界を決定する。その手法には強化学習系(RLHF、RLAIF、GRPO)、非RLの嗜好最適化(DPO)、プロセス報酬モデル(PRM)などが含まれる。この段階のデータ量とコストは低く(5–10%)、主にRolloutと方策更新に集中している。非同期かつ分散実行が天然的に可能で、ノードが完全な重みを持つ必要がないため、検証可能な計算とオンチェーントークンインセンティブを組み合わせることで、開放的な非中央集権型訓練ネットワークを形成でき、Web3に最も適合した訓練段階である。
強化学習技術の全体像:アーキテクチャ、フレームワーク、応用
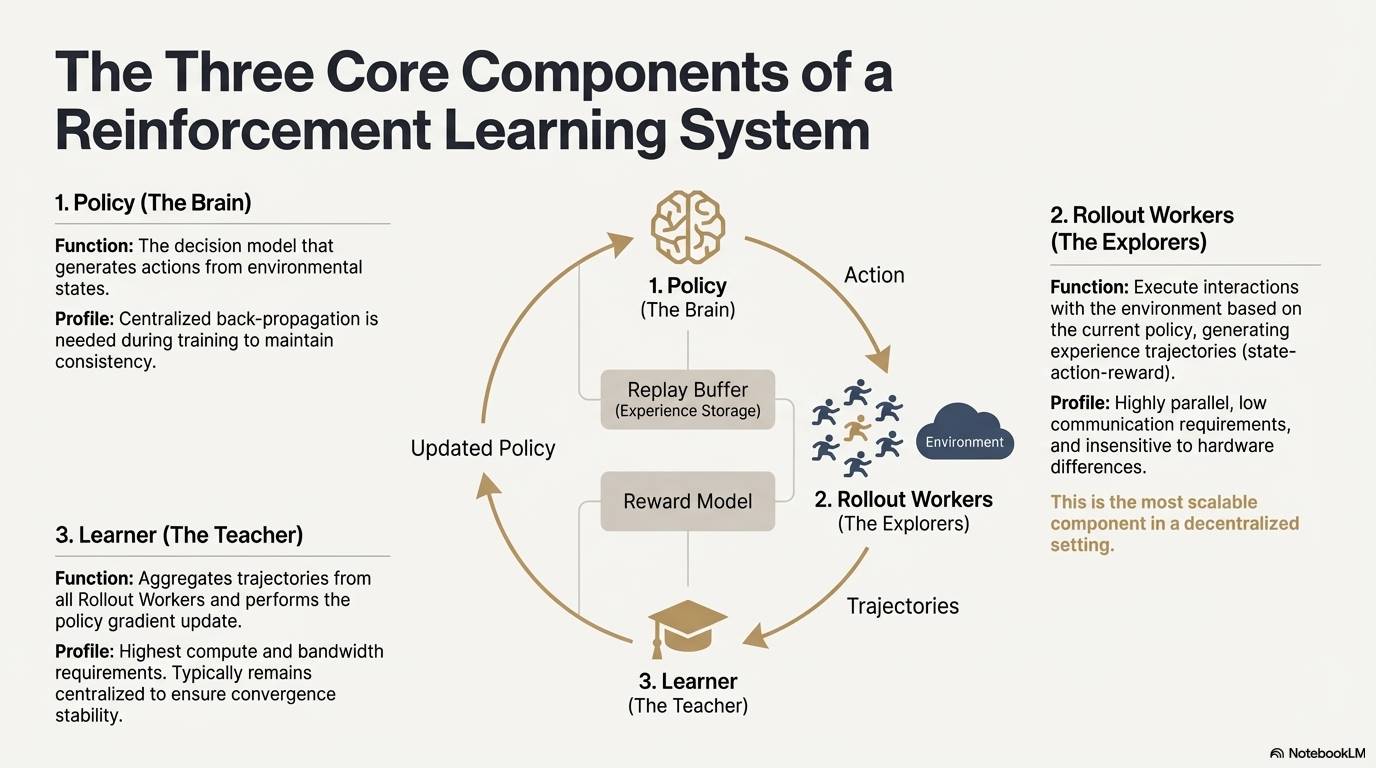
強化学習のシステムアーキテクチャと主要構成要素
強化学習(Reinforcement Learning, RL)は「環境との相互作用—報酬フィードバック—方策更新」によってモデルの自律的判断能力を改善していく。そのコア構造は状態、行動、報酬、方策からなるフィードバックループとみなせる。完全なRLシステムは通常、Policy(方策ネットワーク)、Rollout(経験サンプリング)、Learner(方策アップデータ)の三つの構成要素を持つ。方策が環境と相互作用して軌道を生成し、Learnerが報酬信号に基づいて方策を更新することで、継続的に反復・最適化される学習プロセスが形成される:
-
方策ネットワーク(Policy):環境状態から行動を生成する決定的核心。訓練時には一貫性を保つために集中型の逆伝播が必要だが、推論時には異なるノードに分散して並列実行できる。
-
経験サンプリング(Rollout):ノードが方策に基づき環境と相互作用し、状態—行動—報酬といった軌道を生成する。このプロセスは高度に並列化可能で通信量が極めて少なく、ハードウェア差異にも鈍感であり、非中央集権環境での拡張に最も適している。
-
学習器(Learner):すべてのRollout軌道を集約し、方策勾配更新を実行する。計算能力と帯域幅の要求が最も高い唯一のモジュールであり、収束安定性を確保するため、通常は中央集権的または軽中央集権的に配置される。
強化学習段階のフレームワーク(RLHF → RLAIF → PRM → GRPO)
強化学習は一般的に五つの段階に分けられ、全体のフローは以下の通りである:
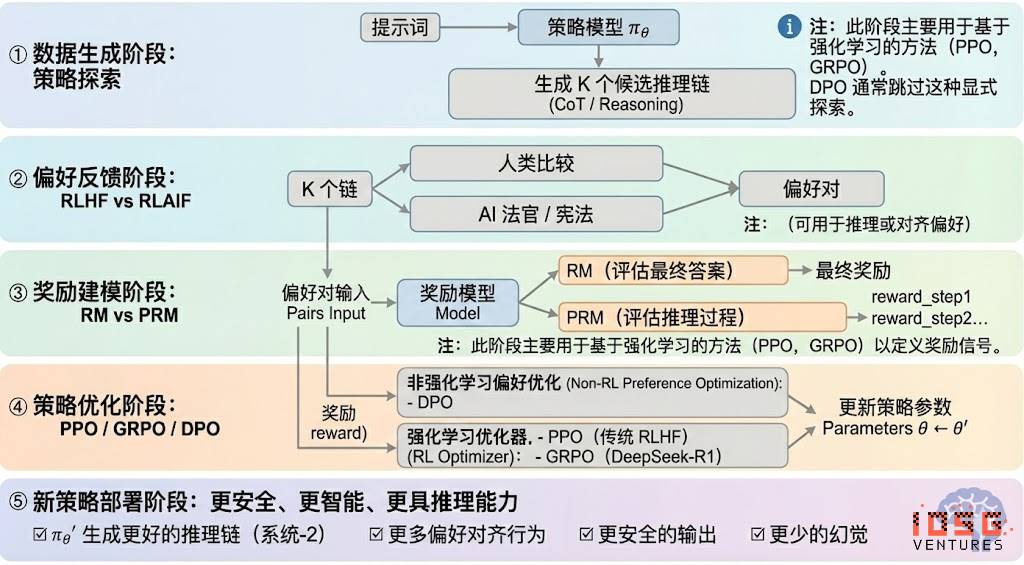
#データ生成段階(Policy Exploration)
入力プロンプトのもとで、方策モデルπθが複数の候補推論チェーンまたは完全な軌道を生成し、その後の嗜好評価と報酬モデリングのためのサンプル基盤を提供する。これは方策探索の広がりを決定する。
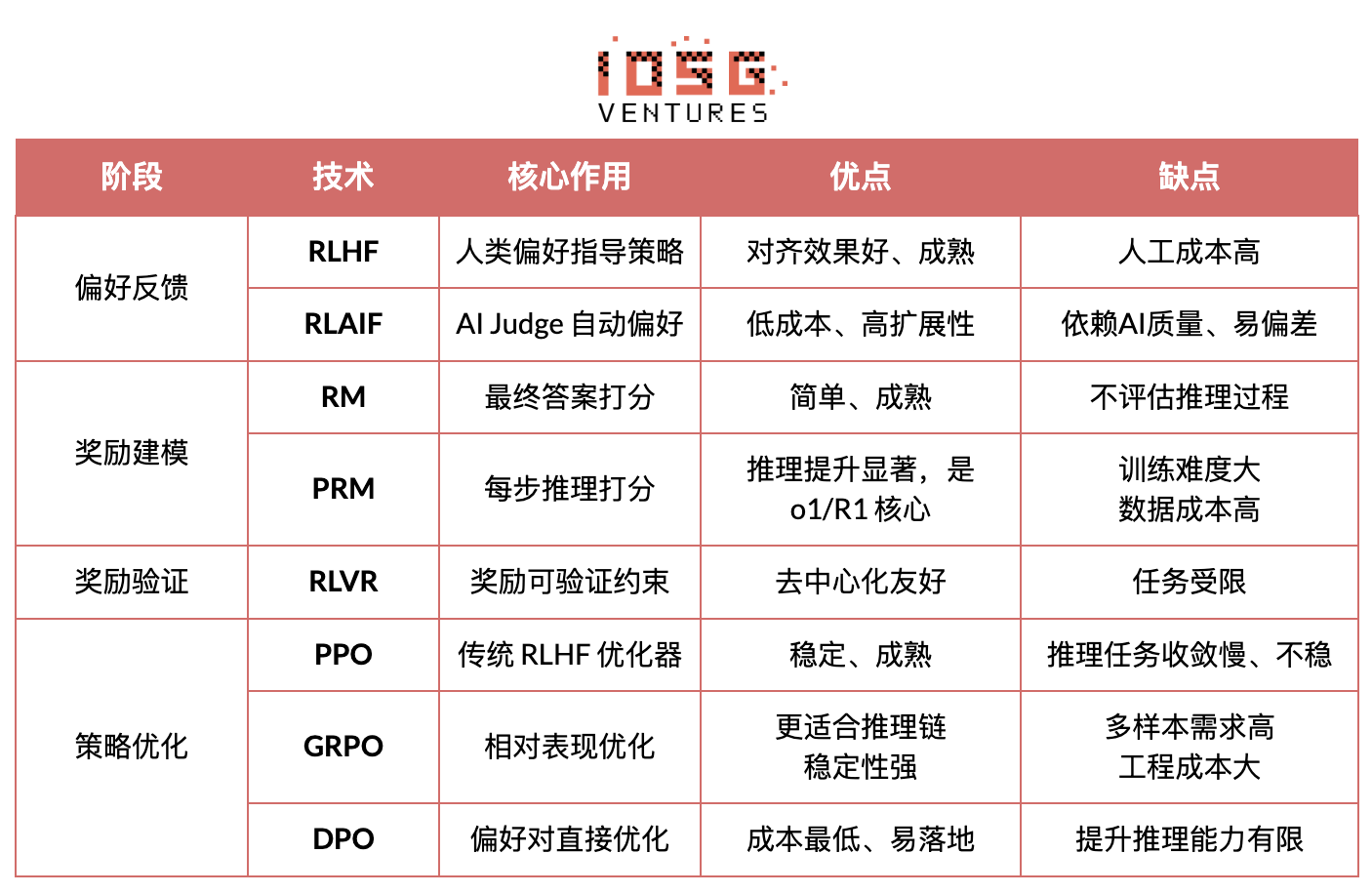
#嗜好フィードバック段階(RLHF / RLAIF)
-
RLHF(Reinforcement Learning from Human Feedback)は、複数回答からの人間による嗜好ラベリング、報酬モデル(RM)の学習、PPOによる方策最適化を通じてモデル出力を人間の価値観に適合させ、GPT-3.5 → GPT-4への移行において鍵となる役割を果たした。
-
RLAIF(Reinforcement Learning from AI Feedback)はAIジャッジまたは憲法的ルールを用いて人間のラベリングを自動化し、コストを大幅に削減しながらスケーラビリティを実現。Anthropic、OpenAI、DeepSeekなどで主流のアライメント方式となっている。
#報酬モデリング段階(Reward Modeling)
嗜好対を報酬モデルに入力し、出力を報酬にマッピングする。RMはモデルに「正しい答えとは何か」を教え、PRMは「どのように正しく推論するか」を教える。
-
RM(Reward Model):最終出力の良否を評価し、出力にのみスコアを与える。
-
プロセス報酬モデルPRM(Process Reward Model):最終出力だけでなく、各ステップの推論、各トークン、各論理セグメントにスコアを与える。OpenAI o1およびDeepSeek-R1のキーテクノロジーであり、本質的には「モデルに思考方法を教える」ことである。
#報酬検証段階(RLVR / Reward Verifiability)
報酬信号の生成と利用過程に「検証可能な制約」を導入し、可能な限り再現可能なルール、事実、合意に基づく報酬を得ることで、reward hackingやバイアスのリスクを低減し、開放環境下での監査可能性と拡張性を高める。
#方策最適化段階(Policy Optimization)
報酬モデルが提供する信号に基づいて方策パラメータθを更新し、より強い推論能力、高い安全性、安定した行動パターンを持つ方策πθ'を得る。主な最適化手法は以下の通り:
-
PPO(Proximal Policy Optimization):RLHFの従来型オプティマイザで安定性に優れるが、複雑な推論タスクでは収束が遅く、安定性に欠けるという限界がある。
-
GRPO(Group Relative Policy Optimization):DeepSeek-R1のコアイノベーション。候補回答群内の優位分布をモデリングして期待価値を推定するもので、単純な順位付けではない。報酬の大きさの情報を保持しており、推論チェーン最適化に適しており、訓練プロセスがより安定。PPOに続く深層推論向け重要な強化学習最適化フレームワークと見なされている。
-
DPO(Direct Preference Optimization):強化学習ではない後訓練手法。軌道を生成せず、報酬モデルも構築しない。嗜好対上で直接最適化を行うため、コストが低く効果も安定。Llama、Gemmaなどのオープンソースモデルのアライメントに広く用いられているが、推論能力の向上は図れない。
#新方策展開段階(New Policy Deployment)
最適化後のモデルは、より強力な推論チェーン生成能力(System-2 Reasoning)、人間またはAIの嗜好に合致した行動、低いハルシネーション率、高い安全性を持つ。モデルは継続的に嗜好を学び、プロセスを最適化し、意思決定の質を高めることでフィードバックループを形成する。
強化学習の産業応用の五つの分類
強化学習(Reinforcement Learning)は初期のゲームAIから進化し、多様な産業における自律的判断のコアフレームワークとなりつつある。技術成熟度と産業展開の度合いから、以下の五つのカテゴリに分類でき、それぞれの分野で重要な突破を遂げている。
-
ゲームと戦略システム(Game & Strategy):RLが最初に実証された領域。AlphaGo、AlphaZero、AlphaStar、OpenAI Fiveなどの「完全情報+明確な報酬」環境において、人類の専門家と同等あるいはそれ以上の意思決定知能を示し、現代RLアルゴリズムの基礎を築いた。
-
ロボット工学と具身知能(Embodied AI):連続制御、力学モデリング、環境相互作用を通じて、ロボットが操作、運動制御、跨モーダルタスク(RT-2、RT-Xなど)を学ぶことを可能にする。現実世界へのロボット展開のキーテクノロジートレンドとして急ピッチで産業化が進んでいる。
-
デジタル推論(Digital Reasoning / LLM System-2):RL+PRMにより、大規模モデルが「言語模倣」から「構造化推論」へと進化。代表例はDeepSeek-R1、OpenAI o1/o3、Anthropic Claude、AlphaGeometryなど。本質的には最終回答の評価ではなく、推論チェーンレベルでの報酬最適化である。
-
自動科学発見と数学最適化(Scientific Discovery):ラベルなし、複雑な報酬、巨大な探索空間の中から最適構造または戦略を見出すことで、AlphaTensor、AlphaDev、Fusion RLなどの基盤的突破を達成。人間の直感を超える探索能力を示している。
-
経済的判断と取引システム(Economic Decision-making & Trading):戦略最適化、高次元リスク管理、適応型取引システム生成に用いられる。従来の定量モデルよりも不確実な環境で継続的に学習でき、スマート金融の重要な構成要素となっている。
強化学習とWeb3の天然的適合性
強化学習(RL)とWeb3の高い親和性は、両者が本質的に「インセンティブ駆動システム」であることに起因する。RLは報酬信号によって方策を最適化し、ブロックチェーンは経済的インセンティブによって参加者の行動を調整するため、メカニズムの面で自然に一致する。RLの主要要件——大規模な異種Rollout、報酬分配、真実性検証——はまさにWeb3の構造的強み所在である。
#推論と訓練の分離
強化学習の訓練プロセスは明確に二つの段階に分解できる:
-
Rollout(探索サンプリング):現在の方策に基づいて大量のデータを生成する。計算集約型だが通信稀疏型のタスクであり、ノード間の頻繁な通信を必要としないため、世界中に分散するコンシューマーGPU上で並列生成が可能。
-
Update(パラメータ更新):収集したデータに基づいてモデル重みを更新する。高帯域幅の中央集権型ノードによって実行される。
「推論—訓練の分離」は非中央集権的な異種計算資源構造に天然的に適合する。Rolloutはオープンネットワークに外注でき、貢献に応じてトークンインセンティブで決済可能であり、一方でモデル更新は安定性確保のために中央集権的に維持される。
#検証可能性 (Verifiability)
ZKおよびProof-of-Learning(PoL)は、ノードが本当に推論を実行したかを検証する手段を提供し、オープンネットワークにおける誠実性問題を解決する。コード、数学的推論など確定的なタスクでは、検証者は出力をチェックするだけで作業量を確認でき、非中央集権型RLシステムの信頼性を大幅に向上させる。
#インセンティブレイヤー:トークン経済に基づくフィードバック生成メカニズム
Web3のトークンメカニズムは、RLHF/RLAIFの嗜好フィードバック貢献者に直接報酬を与え、嗜好データ生成に透明性、決済性、無許可性を持つインセンティブ構造をもたらす。ステーキングとスラッシング(Staking/Slashing)によりフィードバック品質をさらに制約し、従来のクラウドソーシングよりも効率的で整合性のあるフィードバック市場を形成する。
#マルチエージェント強化学習(MARL)の可能性
ブロックチェーン自体が公開・透明・継続的に進化するマルチエージェント環境であり、アカウント、コントラクト、エージェントが常にインセンティブに駆られて戦略を調整しているため、大規模なMARL実験場としての潜在能力を持つ。まだ初期段階にあるが、状態の公開性、実行の検証可能性、インセンティブのプログラマブル性という特性は、将来のMARL発展に原則的な優位性を提供する。
代表的なWeb3+強化学習プロジェクトの分析
上記の理論枠組みに基づき、現在のエコシステムで最も代表的なプロジェクトを簡潔に分析する:
Prime Intellect: 非同期強化学習パラダイム prime-rl
Prime Intellectは、世界規模の開放算力市場の構築、訓練の敷居引き下げ、協調的非中央集権型訓練の推進、および完全なオープンソース超知能技術スタックの発展を目指している。その体系には、Prime Compute(統一クラウド/分散型算力環境)、INTELLECTモデルファミリー(10B–100B+)、オープン強化学習環境センター(Environments Hub)、大規模合成データエンジン(SYNTHETIC-1/2)が含まれる。
Prime Intellectのコアインフラコンポーネントであるprime-rlフレームワークは、非同期分散環境向けに設計されており、強化学習と密接に関連している。その他、帯域幅のボトルネックを突破するOpenDiLoCo通信プロトコル、計算完全性を保証するTopLoc検証メカニズムなども含む。
#Prime Intellect コアインフラコンポーネント概要
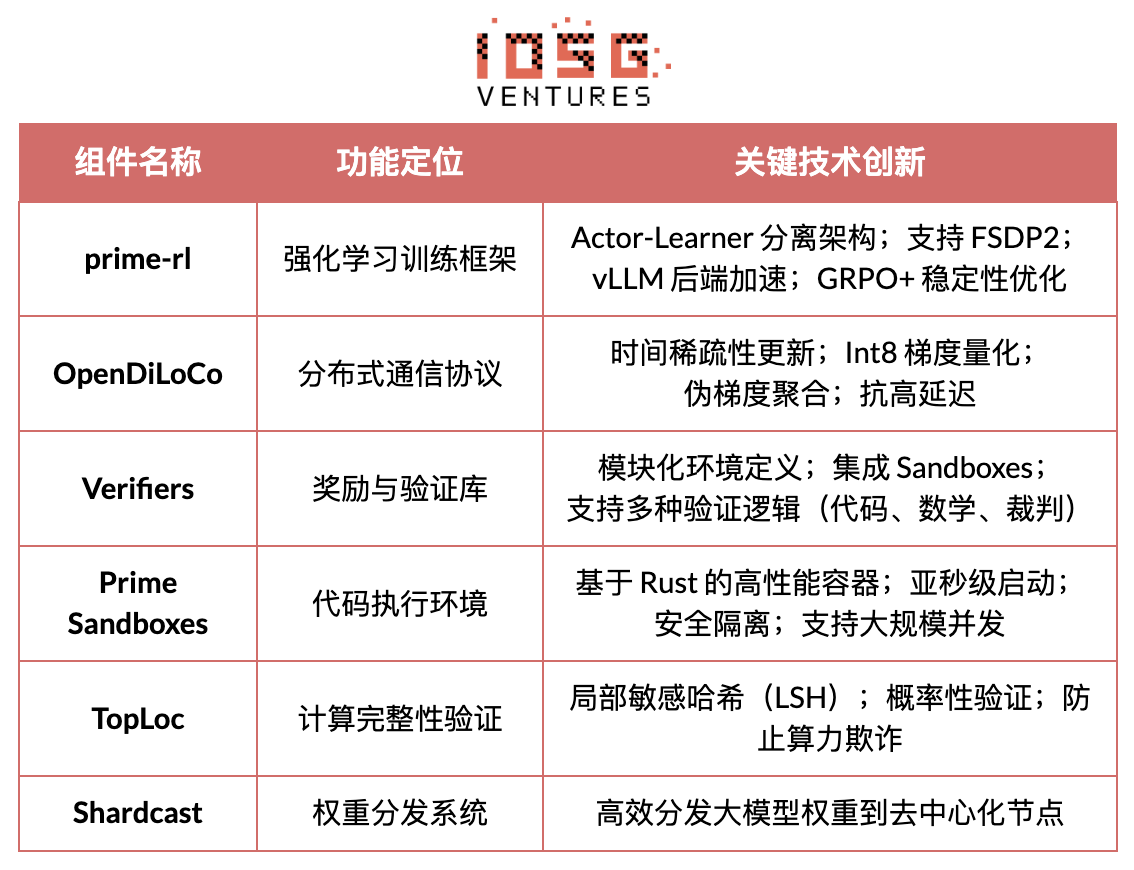
#技術的基盤:prime-rl 非同期強化学習フレームワーク
prime-rlはPrime Intellectのコア訓練エンジンであり、大規模非同期分散環境向けに設計され、Actor–Learnerの完全分離によって高スループット推論と安定した更新を実現する。実行者(Rollout Worker)と学習者(Trainer)は同期ブロッキングされず、ノードはいつでも参加・退出でき、最新方策を継続的に取得し、生成データをアップロードすればよい:
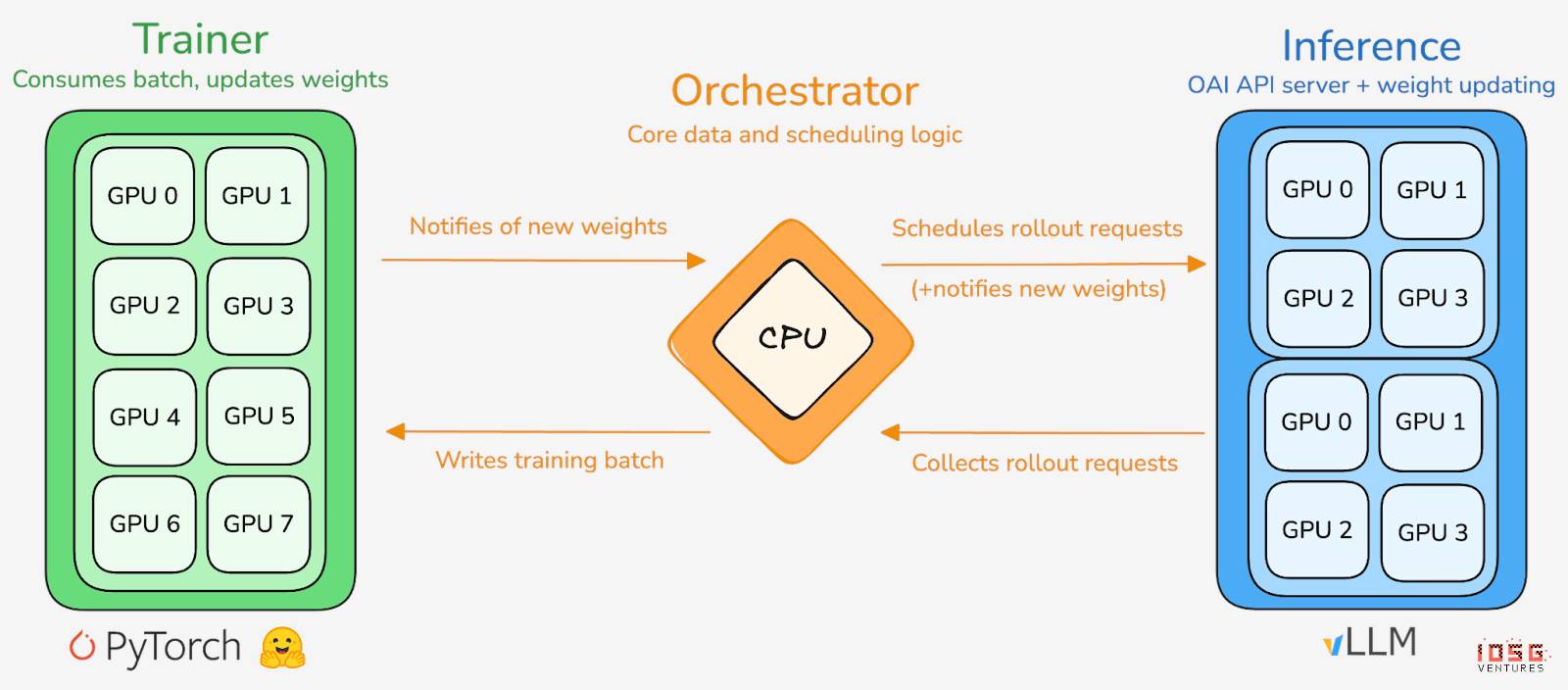
-
実行者 Actor (Rollout Workers):モデル推論とデータ生成を担当。Prime Intellectは、画期的にActor側にvLLM推論エンジンを統合。vLLMのPagedAttention技術と連続バッチ処理(Continuous Batching)により、極めて高いスループットで推論軌道を生成できる。
-
学習者 Learner (Trainer):方策最適化を担当。Learnerは共有の経験リプレイバッファ(Experience Buffer)から非同期にデータを取得し、勾配更新を行う。すべてのActorが現在のバッチを完了するのを待つ必要はない。
-
オーケストレーター (Orchestrator):モデル重みとデータフローのスケジューリングを担当。
#prime-rlの主要な革新点
-
完全非同期(True Asynchrony):prime-rlは従来のPPOの同期パラダイムを放棄し、遅いノードを待たず、バッチのアライメントも不要。任意の数と性能のGPUがいつでも接続可能となり、非中央集権型RLの実現可能性を確立。
-
FSDP2とMoEの深層統合:FSDP2によるパラメータ分割とMoEのスパース活性化により、prime-rlは100億規模のモデルを分散環境で効率的に訓練できる。Actorはアクティブな専門家のみを実行するため、メモリ使用量と推論コストを大幅に削減。
-
GRPO+(Group Relative Policy Optimization):GRPOはCriticネットワークを不要とし、計算量とメモリ消費を大幅に削減。非同期環境に天然的に適合。prime-rlのGRPO+はさらなる安定化機構により、高遅延条件下でも信頼できる収束を実現。
#INTELLECT モデルファミリー:非中央集権型RL技術成熟度の指標
-
INTELLECT-1(10B、2024年10月):OpenDiLoCoが三大陸にまたがる異種ネットワークで効率的に訓練可能であることを初めて証明(通信比率<2%、計算資源利用率98%)。地理的制約を超えた訓練の物理的認識を打破。
-
INTELLECT-2(32B、2025年4月):初のPermissionless RLモデルとして、prime-rlとGRPO+が多段遅延・非同期環境での安定収束能力を検証。世界規模の開放算力が参加する非中央集権型RLを実現。
-
INTELLECT-3(106B MoE、2025年11月):12Bパラメータのみを活性化するスパースアーキテクチャを採用。512×H200上で訓練され、旗艦級推論性能(AIME 90.8%、GPQA 74.4%、MMLU-Pro 81.9%等)を達成。全体性能は自身よりはるかに大きな集中閉源モデルに匹敵、あるいは凌駕。
Prime Intellectはまた、いくつかの支援インフラも構築している。OpenDiLoCoは時間的疎通信と量子化された重み差分により、地理的制約を超えた訓練の通信量を数百倍削減。これによりINTELLECT-1は三大陸ネットワークでも98%の利用率を維持。TopLoc+Verifiersは非中央集権型信頼実行層を形成し、活性化フィンガープリントとサンドボックス検証で推論と報酬データの真実性を確保。SYNTHETICデータエンジンは大規模高品質推論チェーンを生成し、パイプライン並列により671BモデルをコンシューマーGPUクラスタ上で効率稼働。これらのコンポーネントは非中央集権型RLのデータ生成、検証、推論スループットに不可欠な技術基盤を提供。INTELLECTシリーズはこの技術スタックが成熟したワールドクラスモデルを生み出せることを証明し、非中央集権型訓練体系が概念段階から実用段階へ移行したことを示している。
Gensyn: 強化学習コアスタックRL SwarmとSAPO
Gensynの目標は、世界中のアイドル算力を集約し、開放的で信頼不要、無限に拡張可能なAI訓練インフラを構築すること。そのコアには、デバイス横断的な標準実行層、P2P協調ネットワーク、信頼不要のタスク検証システムがあり、スマートコントラクトによって自動的にタスクと報酬を分配する。強化学習の特徴に着目し、RL Swarm、SAPO、SkipPipeなどのコアメカニズムを導入。生成、評価、更新の三工程を分離し、世界中の異種GPUからなる「蜂群」によって集団的進化を実現。最終的に提供するのは単なる算力ではなく、「検証可能な知能(Verifiable Intelligence)」である。
#Gensyn スタックの強化学習応用
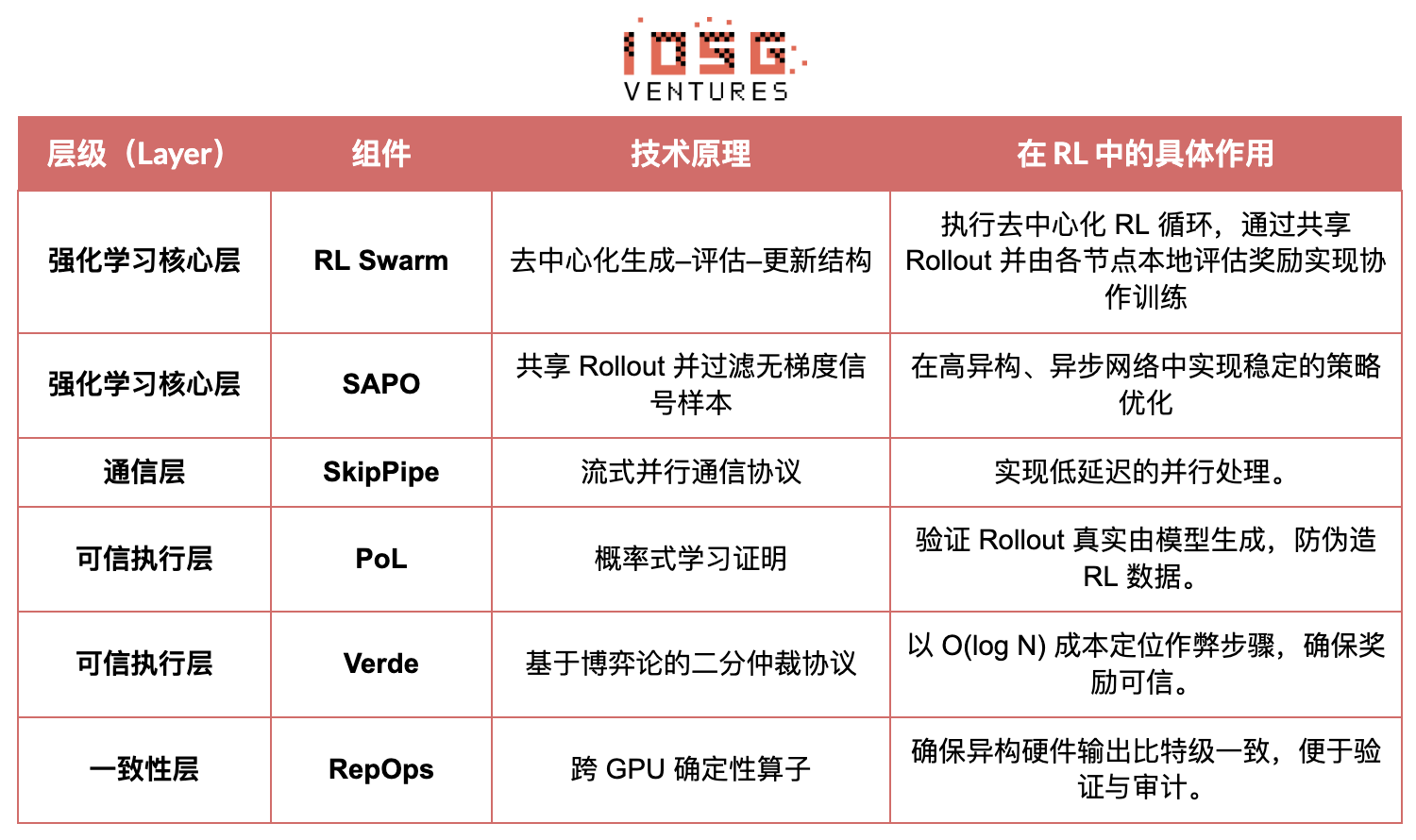
#RL Swarm:非中央集権型協調強化学習エンジン
RL Swarmは全く新しい協働モードを提示する。単なるタスク配布ではなく、人間社会の学習を模倣した非中央集権型「生成—評価—更新」ループであり、協同学習プロセスを無限ループで繰り返す:
-
Solvers(実行者):ローカルモデル推論とRollout生成を担当。ノードの異種性は障害にならない。Gensynは高スループット推論エンジン(CodeZeroなど)をローカルに統合し、答えだけでなく完全な軌道を出力できる。
-
Proposers(出題者):動的にタスク(数学問題、コード課題など)を生成。タスク多様性とCurriculum Learning風の難易度適応をサポート。
-
Evaluators(評価者):凍結された「審判モデル」またはルールでローカルRolloutを評価し、ローカル報酬信号を生成。評価プロセスは監査可能で、悪意行為の余地を減らす。
三者はP2PのRL組織構造を共に形成し、中央集権的スケジューリングなしに大規模協同学習を完遂できる。
#SAPO:非中央集権型に再構築された方策最適化アルゴリズム
SAPO(Swarm Sampling Policy Optimization)は「勾配を共有せず、Rolloutを共有し、勾配信号を持たないサンプルをフィルタリングする」ことを核心とする。大規模非中央集権型Rolloutサンプリングを行い、受信したRolloutをローカル生成物として扱うことで、中央集権的調整なし、ノード間の遅延差が大きい環境でも安定した収束を維持する。Criticネットワークに依存し計算コストが高いPPOや、グループ内優位性推定に基づくGRPOと比較して、SAPOは極めて低帯域でコンシューマーGPUでも大規模強化学習最適化に効果的に参加できる。
RL SwarmとSAPOを通じ、Gensynは強化学習(特に後訓練段階のRLVR)が非中央集権型アーキテクチャに天然的に適合することを証明している。なぜなら、それは高頻度のパラメータ同期よりも、大規模かつ多様な探索(Rollout)に依存しているからである。PoLとVerdeの検証体系と組み合わせることで、Gensynは兆単位パラメータモデルの訓練に、単一テック大手に依存しない代替的パスを提供する:世界中の数百万の異種GPUから構成される、自己進化する超知能ネットワークである。
Nous Research:検証可能な強化学習環境 Atropos
Nous Researchは、非中央集権的で自己進化可能な認知インフラを構築している。そのコアコンポーネント——Hermes、Atropos、DisTrO、Psyche、World Sim——は、継続的フィードバックループを形成する知能進化システムとして編成されている。従来の「事前学習—後訓練—推論」の線形プロセスとは異なり、NousはDPO、GRPO、拒否サンプリングなどの強化学習技術を用い、データ生成、検証、学習、推論を一つの連続的フィードバックループに統合。継続的に自己改善する閉ループAIエコシステムを創出している。
#Nous Research 構成コンポーネント総覧

#モデル層:Hermes と推論能力の進化
HermesシリーズはNous Researchがユーザーに提供する主要なモデルインターフェースであり、その進化は業界が従来のSFT/DPOアライメントから推論強化学習(Reasoning RL)へ移行する道筋を明確に示している:
-
Hermes 1–3:指示アライメントと初期エージェント能力:Hermes 1–3は低コストDPOにより堅牢な指示アライメントを達成。Hermes 3では合成データと初導入のAtropos検証メカニズムを活用。
-
Hermes 4 / DeepHermes:思考の連鎖(Chain-of-Thought)によってSystem-2式の遅い思考を重みに書き込み、Test-Time Scalingにより数学・コード性能を向上。「拒否サンプリング+Atropos検証」により高純度推論データを構築。
-
DeepHermesはさらにPPOの代替としてGRPOを採用。PPOは非中央集権化展開が困難だが、GRPOにより推論RLをPsycheの非中央集権GPUネットワーク上で実行可能に。オープンソース推論RLのスケーラビリティに工学的基盤を築いた。
#Atropos:検証可能な報酬駆動型強化学習環境
AtroposはNous RL体系の真のハブである。プロンプト、ツール呼び出し、コード実行、マルチターン相互作用を標準化されたRL環境にパッケージングし、出力が正しいかを直接検証可能にして、確定的報酬信号を提供。これにより高価でスケーラビリティに欠ける人間のラベリングに代わる。さらに重要なのは、非中央集権型訓練ネットワークPsycheにおいて、Atroposが「審判」として機能し、ノードが実際に方策を向上させているかを検証。監査可能なProof-of-Learningをサポートし、分散型RLにおける報酬信頼性問題を根本的に解決する。
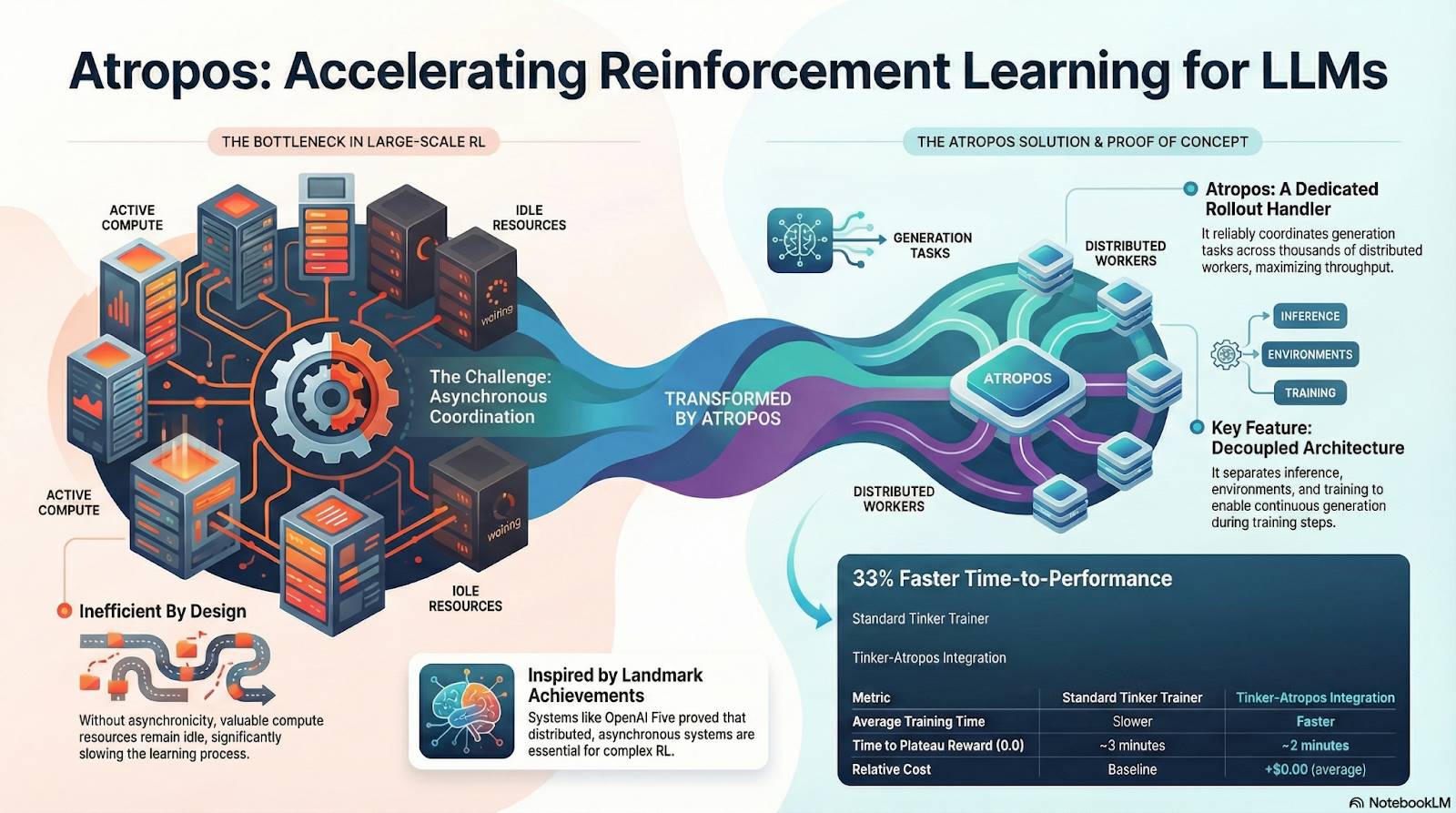
#DisTrO と Psyche:非中央集権型強化学習のオプティマイザ層
従来のRLF(RLHF/RLAIF)訓練は中央集権型高帯域クラスタに依存しており、これがオープンソースが再現できないコア障壁である。DisTrOは運動量の分離と勾配圧縮により、RLの通信コストを数桁削減し、インターネット帯域幅上で訓練を可能にする。Psycheはこの訓練メカニズムをオンチェーンネットワークに展開し、ノードがローカルで推論、検証、報酬評価、重み更新を完遂できるようにし、完全なRL閉ループを形成する。
Nousの体系では、Atroposが思考の連鎖を検証し、DisTrOが訓練通信を圧縮し、PsycheがRLループを実行し、World Simが複雑な環境を提供し、Forgeが実際の推論を収集し、Hermesがすべての学習を重みに書き込む。強化学習は単なる訓練段階ではなく、データ、環境、モデル、インフラを結ぶコアプロトコルであり、Hermesをオープンソース算力ネットワーク上で継続的に自己改善する生命体システムにしている。
Gradient Network:強化学習アーキテクチャ Echo
Gradient Networkのコアビジョンは、「開放知能プロトコルスタック」(Open Intelligence Stack)を通じてAIの計算パラダイムを再構築すること。Gradientの技術スタックは、独立に進化可能で異種協働する一連のコアプロトコルから成る。その体系は、下層の通信から上層の知能協働まで、Parallax(分散推論)、Echo(非中央集権型RL訓練)、Lattica(P2Pネットワーク)、SEDM / Massgen / Symphony / CUAHarm(記憶、協働、安全)、VeriLLM(信頼検証)、Mirage(高忠実度シミュレーション)を含み、継続的に進化する非中央集権型知能インフラを構成する。
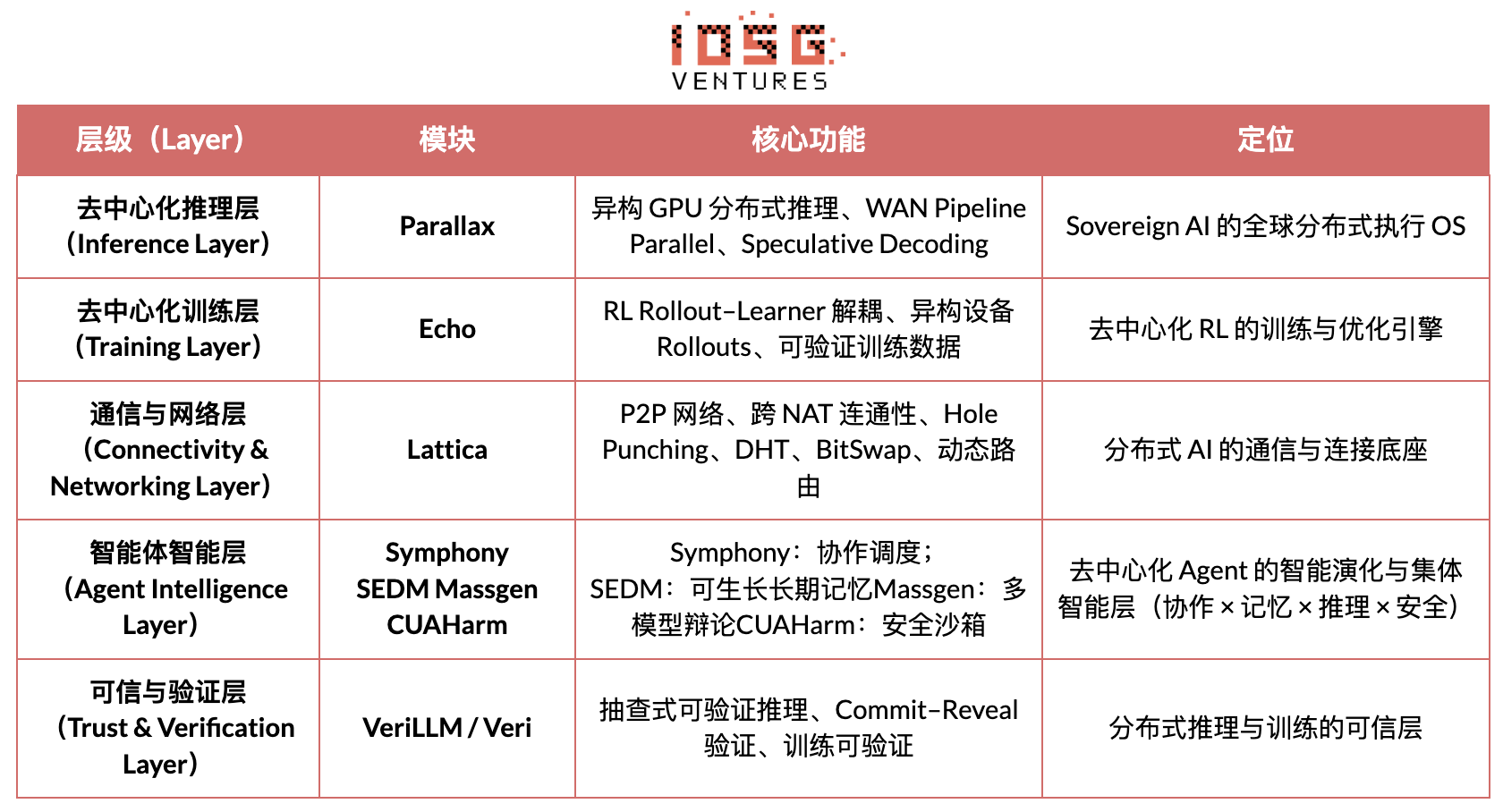
Echo — 強化学習訓練アーキテクチャ
EchoはGradientの強化学習フレームワークであり、そのコア設計思想は、訓練、推論、データ(報酬)パスを分離し、Rollout生成、方策最適化、報酬評価が異種環境で独立に拡張・スケジューリング可能にすることにある。推論側と訓練側ノードからなる異種ネットワーク上で協働し、軽量な同期メカニズムにより広域異種環境でも訓練の安定性を維持。従来のDeepSpeed RLHF / VERLにおける推論と訓練の混在によるSPMD失敗やGPU利用率のボトルネックを効果的に緩和する。
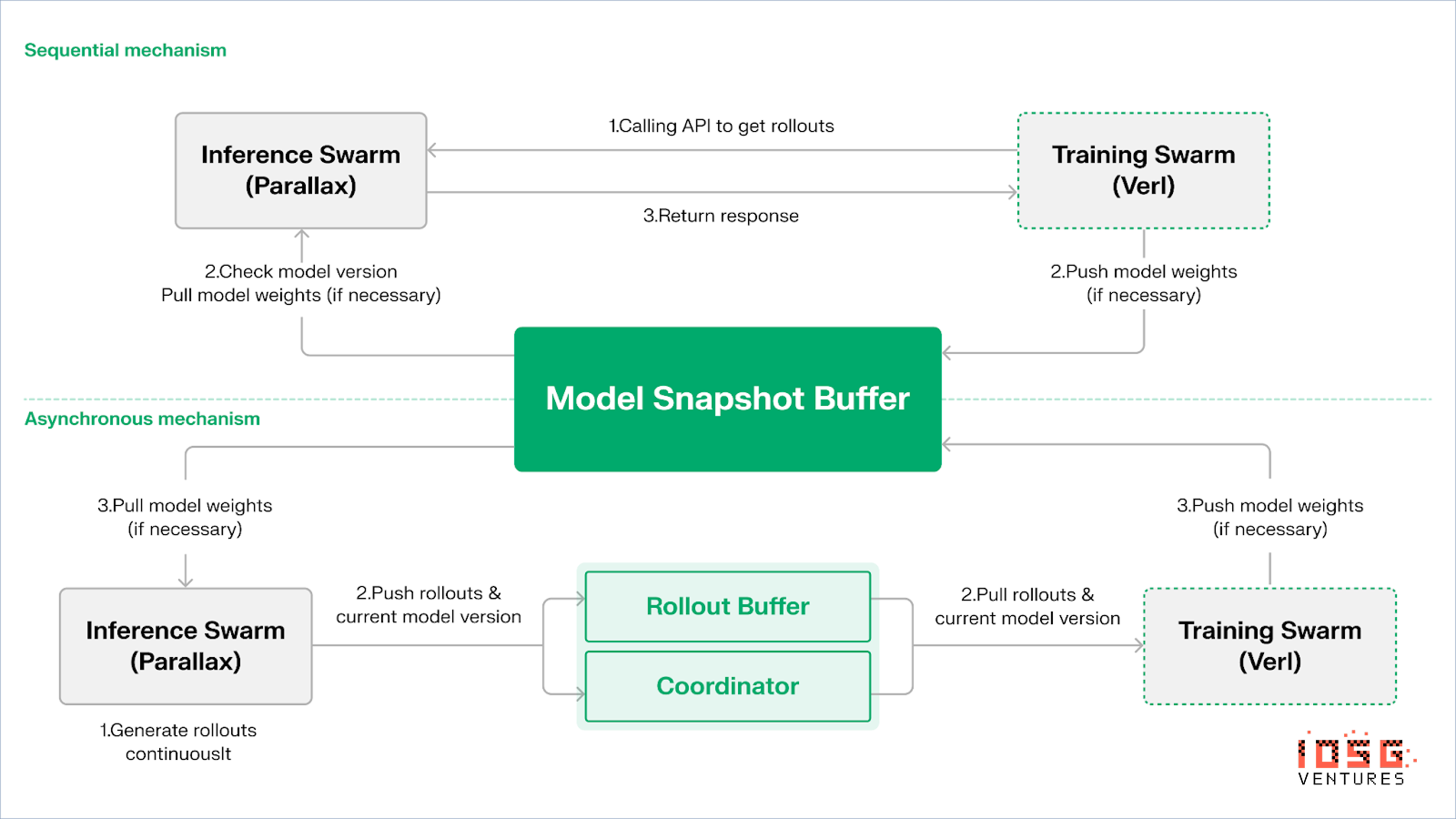
Echoは「推論-訓練二重群アーキテクチャ」を採用し、算力利用を最大化。二つの群は独立に動作し、互いにブロッキングしない:
-
スループット最大化:推論群 Inference SwarmはコンシューマーGPUとエッジデバイスから構成され、Parallaxによってパイプライン並列で高スループットサンプラーを構築。軌道生成に特化。
-
勾配算力最大化:訓練群 Training Swarmは、中央集権クラスタまたは世界中のコンシューマーGPUネットワークで実行可能。勾配更新、パラメータ同期、LoRA微調整を担当。学習プロセスに特化。
方策とデータの一貫性を保つため、Echoは順次(Sequential)と非同期(Asynchronous)の二種類の軽量同期プロトコルを提供し、方策重みと軌道の双方向一貫性管理を実現:
-
順次取得(Pull)モード|精度優先:訓練側が新しい軌道を取得する前に、推論ノードにモデルバージョンの更新を強制。軌道の新鮮さを確保。方策の陳腐化に非常に敏感なタスクに適している。
-
非同期プッシュ・プル(Push–Pull)モード|効率優先:推論側がバージョンタグ付き軌道を継続生成。訓練側が自身のペースで消費。オーケストレーターがバージョン偏差を監視し、重み更新をトリガー。デバイス利用率を最大化。
基盤層では、EchoはParallax(低帯域環境下の異種推論)と軽量分散訓練コンポーネント(VERLなど)に基づき、LoRAによってノード間同期コストを削減し、強化学習を世界規模の異種ネットワーク上で安定稼働可能にする。
Grail:Bittensorエコの強化学習
Bittensorは独自のYumaコンセンサスメカニズムを通じ、巨大で疎、非定常な報酬関数ネットワークを構築している。
BittensorエコシステムのCovenant AIは、SN3 Templar、SN39 Basilica、SN81 Grailを通じて、事前学習からRL後訓練までの垂直統合型パイプラインを構築。SN3 Templarは基礎モデルの事前学習を担当。SN39 Basilicaは分散算力市場を提供。SN81 GrailはRL後訓練向けの「検証可能な推論層」として、RLHF / RLAIFのコアプロセスを担い、基礎モデルからアライメント方策までの閉ループ最適化を完遂する。
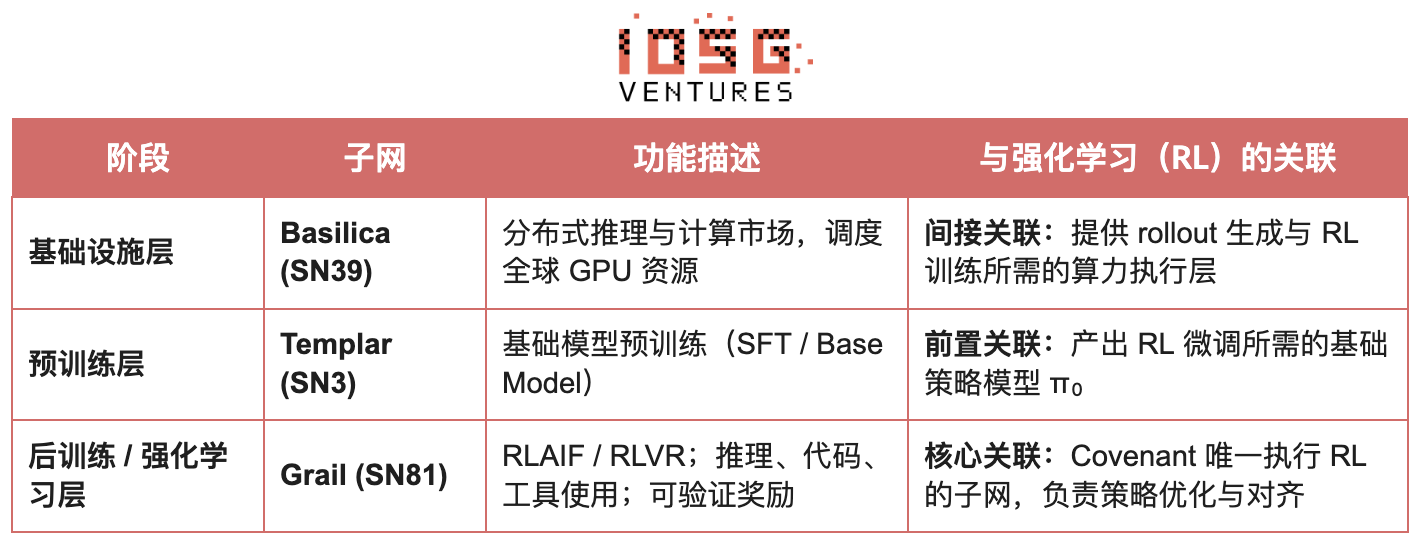
GRAILの目標は、暗号的手法によって各強化学習rolloutの真実性とモデルIDのバインディングを証明し、信頼不要環境下でもRLHFが安全に実行可能にすること。プロトコルは三層メカニズムで信頼チェーンを構築:
-
決定論的チャレンジ生成:drandランダムビーコンとブロックハッシュを用いて予測不能だが再現可能なチャレンジタスク(SAT、GSM8Kなど)を生成。事前計算による不正行為を防止。
-
PRFインデックスサンプリングとsketch commitmentsにより、検証者が極めて低コストでtoken-level logprobと推論チェーンをスポットチェックし、rolloutが宣言されたモデルによって生成されたことを確認。
-
モデルIDバインディング:推論プロセスをモデル重みフィンガープリントおよびトークン分布の構造的署名とバインディング。モデルの置換や結果のリプレイが即座に検出される。これにより、RLの推論軌道(rollout)に真実性の基盤を提供。
このメカニズムの上に、GrailサブネットはGRPOスタイルの検証可能後訓練プロセスを実現:マイナーが同一課題に対して複数の推論パスを生成。検証者が正解性、推論チェーン品質、SAT充足度に基づきスコアリング。正規化された結果をTAO重みとしてオンチェーンに書き込む。公開実験では、このフレームワークによりQwen2.5-1.5BのMATH正解率が12.7%から47.6%に向上。不正防止とモデル能力の大幅強化の両立を証明。Covenant AIの訓練スタックにおいて、Grailは非中央集権型RLVR/RLAIFの信頼と実行の基盤であり、現時点ではまだ正式にメインネットにリリースされていない。
Fraction AI:競争に基づく強化学習 RLFC
Fraction AIのアーキテクチャは、競争強化学習(Reinforcement Learning from Competition, RLFC)とゲーム化データアノテーションを中心に設計されており、従来のRLHFの静的報酬と人間アノテーションを、開放的で動的な競争環境に置き換えている。エージェントは異なるSpacesで対戦し、相対ランキングとAIジャッジのスコアが共同でリアルタイム報酬を構成。アライメントプロセスは継続的オンラインマルチエージェントゲームシステムへと進化する。
従来のRLHFとFraction AIのRLFCの本質的違い:

RLFCのコア価値は、報酬が単一モデルからではなく、継続的に進化する対戦相手と評価者から得られることにある。これにより報酬モデルの悪用を回避し、戦略の多様性を通じてエコシステムが局所最適に陥るのを防ぐ。Spacesの構造がゲームの性質(ゼロサムまたはプラスサム)を決定し、対抗と協働の中で複雑な行動が出現する。
システムアーキテクチャ上、Fraction AIは訓練プロセスを四つのキーコンポーネントに分解:
-
Agents:オープンソースLLMに基づく軽量方策ユニット。QLoRAにより差分重みを拡張し、低コストで更新可能。
-
Spaces:隔離されたタスクドメイン環境。エージェントは料金を支払い参加し、勝敗により報酬を得る。
-
AI Judges:RLAIFに基づく即時報酬層。スケーラブルで非中央集権的な評価を提供。
-
Proof-of-Learning:方策更新を具体的な競争結果にバインディング。訓練プロセスの検証可能性と不正防止を確保。
Fraction AIの本質は、「人間と機械の協働進化エンジン」を構築することにある。ユーザーは戦略層の「メタ最適化者」(Meta-optimizer)として、プロンプトエンジニアリング(Prompt Engineering)とハイパーパラメータ設定によって探索方向を誘導。一方で、エージェントは微視的な競争の中で自発的に大量の高品質嗜好対(Preference Pairs)を生成。このモデルにより、データアノテーションが「信頼不要微調整」(Trustless Fine-tuning)を通じてビジネス閉ループを実現する。
強化学習 Web3 プロジェクトアーキテクチャ比較
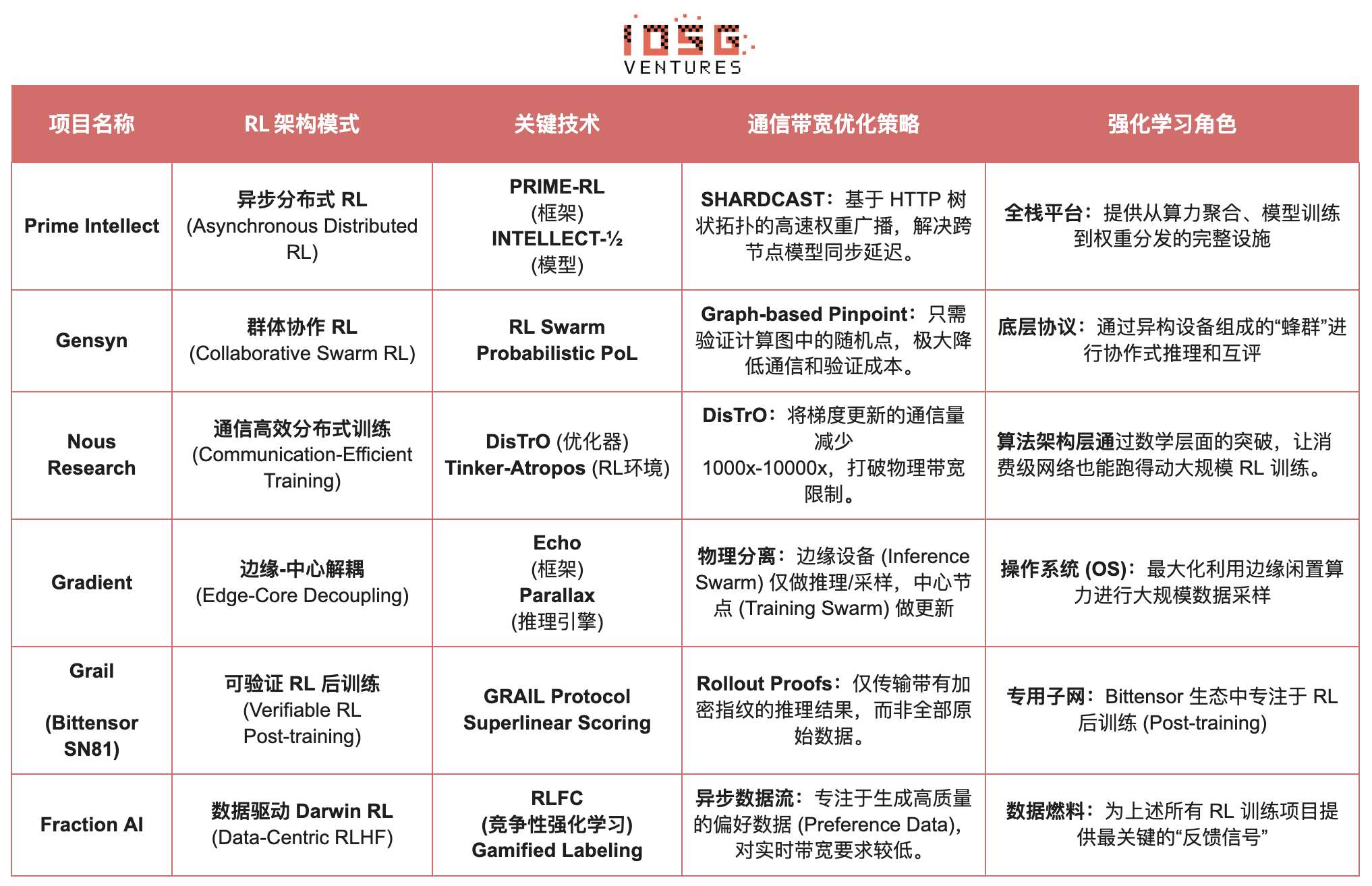
まとめと展望:強化学習 × Web3 の道筋と機会
上述の先端プロジェクトの解構分析に基づき、我々が観察するのは次の点である:各チームのアプローチ(アルゴリズム、工学、市場)は異なっても、強化学習(RL)とWeb3が結合するとき、その基盤アーキテクチャ論理はすべて「分離—検証—インセンティブ」という高度に一貫したパラダイムに収束している。これは技術的な偶然ではなく、非中央集権ネットワークが強化学習の独特な属性に適合する必然的帰結である。
強化学習の共通アーキテクチャ特徴: 核心的物理制約と信頼問題の解決
-
推論と訓練の物理的分離 (Decoupling of Rollouts & Learning) —— デフォルト計算トポロジー 通信稀疏で並列可能なRolloutを世界中のコンシューマーGPUに外注し、高帯域のパラメータ更新は少数の訓練ノードに集中。Prime Intellectの非同期Actor–LearnerからGradient Echoの二重群アーキテクチャまで、すべて同様である。
-
検証駆動の信頼層 (Verification-Driven Trust) —— インフラストラクチャー化 無許可ネットワークにおいて、計算の真実性は数学とメカニズム設計によって強制的に保障されなければならない。代表例はGensynのPoL、Prime IntellectのTOPLOC、Grailの暗号検証。
-
トークン化されたインセンティブ閉ループ (Tokenized Incentive Loop) —— 市場の自己調整 算力供給、データ生成、検証順序、報酬分配が閉ループを形成。報酬によって参加を促進し、スラッシングによって不正を抑制。開放環境下でもネットワークが安定かつ継続的に進化する。
差別化された技術的道筋:一貫したアーキテクチャ下の異なる「突破口」
アーキテクチャが収束しても、各プロジェクトは自身の遺伝子に基づき異なる技術的護城河を選択している:
-
アルゴリズム突破派 (Nous Research):分散訓練の根本的矛盾(帯域ボトルネック)を数学的基盤から解決しようとする。DisTrOオプティマイザは勾配通信量を数千倍圧縮することを目指し、家庭用ブロードバンドでも大規模モデル訓練が可能になる。これは物理的制約に対する「次元下げ攻撃」である。
-
システム工学派 (Prime Intellect, Gensyn, Gradient):次世代「AIランタイムシステム」の構築に重点を置く。Prime IntellectのShardCastやGradientのParallaxは、既存ネットワーク条件下で究極の工学的手法によって異種クラスタ効率を最大限に引き出すことを目指している。
-
市場ゲーム派 (Bittensor, Fraction AI):報酬関数(Reward Function)の設計に注力。巧妙なスコアリングメカニズムを設計し、マイナーが自発的に最適戦略を探求するよう誘導。知能の出現を加速する。
強み、課題、終局の展望
強化学習とWeb3の融合パラダイム下で、システムレベルの強みはまずコスト構造とガバナンス構造の再構築に表れる。
-
コストの再構築:RL後訓練(Post-training)はサンプリング(Rollout)の需要が無限である。Web3は極めて低コストで世界のロングテール算力を動員でき、これは中央集権クラウドベンダーには比べられないコスト優位性である。
-
主権のアライメント (Sovereign Alignment):大手企業によるAIの価値観(Alignment)独占を打破。コミュニティはトークン投票によって「良い回答とは何か」を決定でき、AIガバナンスの民主化を実現。
同時に、このシステムは二つの構造的制約にも直面している。
-
帯域の壁 (Bandwidth Wall):DisTrOなどの革新があっても、物理的遅延は超大規模パラメータモデル(70B+)のフルトレーニングを制限。現時点ではWeb3 AIは主に微調整と推論に限定。
-
グッドハートの法則 (Reward Hacking):高度にインセンティブ化されたネットワークでは、マイナーが「過学習」して報酬ルール(スコアリング)を刷り、真の知能向上ではなくなるリスクが高い。不正防止の頑健な報酬関数設計は永遠のゲームである。
-
悪意あるビザンチン型ノード攻撃 (BYZANTINE worker):訓練信号の能動的操作や汚染によってモデル収束を破壊。核心は継続的に不正防止報酬関数を設計することではなく、対抗的頑健性を持つメカニズムを構築することである。
強化学習とWeb3の融合は、本質的に「知能がいかに生
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News











