

対話 0G Labs CEO:2年以内にWeb2 AIに追いつく、AIパブリックプロダクトの「無重力」実験
TechFlow厳選深潮セレクト
対話 0G Labs CEO:2年以内にWeb2 AIに追いつく、AIパブリックプロダクトの「無重力」実験
分散型AIの波とともに、0Gの核心的ビジョン、技術実装経路、エコシステムの重点領域および将来のロードマップ計画を探る。
執筆:TechFlow
OpenAI CEO Sam Altman は、ポッドキャストや公開講演で何度もこう述べてきた:
AIはモデル競争ではなく、公共財を創造し、誰もが恩恵を受けられるようにし、世界経済の成長を駆動することだ。
そして、Web2 AIが寡占によって批判されている現在、分散化を精神的内核とするWeb3の世界にも、「AIを公共財にする」を中核ミッションとするプロジェクトがあり、設立から2年余りで3500万ドルの資金調達を達成し、AIイノベーションアプリケーションの発展を支える技術基盤を構築し、300以上のエコシステムパートナーを惹きつけ、最大規模の分散型AIエコシステムの一つへと成長している。
それが0G Labsだ。
0G Labsの共同創設者兼CEO Michael Heinrichとの深い対話の中で、「公共財」という概念が何度も登場した。AI公共財への理解について、Michaelはこう語る:
私たちは、反中央集権的、反ブラックボックス的なAI発展モデルを構築したいと考えています。このモデルは透明で、オープンで、安全で、誰もが恩恵を受けられるものです。誰もが参加し、データと計算リソースを貢献し、報酬を得ることができ、社会全体がAIの利益を共有できるのです。
そして、その実現方法について、Michaelは0Gの具体的な道筋を一つ一つ分解して説明した:
AI専用に設計されたLayer 1として、0Gは卓越した性能優位性、モジュラー設計、そして無限に拡張可能でプログラマブルなDA層を備えており、検証可能な計算、多層ストレージから改ざん不可能なトレーサビリティ層まで、ワンストップのAIエコシステムを構築し、AIの発展に必要なすべての重要なコンポーネントを提供します。
今回の内容では、Michael Heinrichの共有に従い、分散型AIの波の下での0Gの中核的ビジョン、技術実現の道筋、エコシステムの焦点、そして将来のロードマップ計画について探っていく。

インクルーシブ:「AIを公共財にする」の精神的内核
TechFlow:お時間をいただきありがとうございます。まずは自己紹介をお願いします。
Michael:
皆さん、こんにちは。0G Labsの共同創設者兼CEOのMichaelです。
私は技術畑の出身で、MicrosoftやSAP Labsでエンジニアや技術プロダクトマネージャーなどの職務に就いていました。その後、ビジネス側に転向し、最初はゲーム会社で働き、その後ブリッジウォーター・アソシエーツに加わり、ポートフォリオ構築関連の業務を担当し、毎日約600億ドルの取引を審査していました。その後、母校スタンフォード大学に戻ってさらに学びを深め、初めての起業を開始しました。その会社はベンチャーキャピタルの支援を得て急速にユニコーンへと成長し、チーム規模は650人、収益は1億ドルに達しました。その後、私はその会社を売却し、成功裏に退出しました。
私と0Gとの縁は、ある日、スタンフォードの同級生であるThomasから電話がかかってきたことから始まりました。彼はこう言いました:
Michael、5年前に私たちは一緒にいくつかの暗号会社(その中にはConfluxも含まれます)に投資しました。伍鳴(Confluxと0Gの共同創設者兼CTO)とFan Long(0G Labsの最高セキュリティ責任者)は、私が支援した中で最も優秀なエンジニアの一人です。彼らは世界的に拡張可能なことをやりたいと考えています。彼らに会ってみませんか?
Thomasの仲介により、私たち4人は6ヶ月間の共同創設者としてのコミュニケーションと調整の段階を経ました。その間、私は同じ結論に達しました:伍鳴とFan Longは、私がこれまで一緒に仕事をした中で最も優れたエンジニア兼コンピュータサイエンスの才能です。当時の私の考えは:私たちはすぐに始めなければならない。そうして0G Labsが誕生しました。

0G Labsは2023年5月に設立されました。最大規模で最速のAI Layer 1プラットフォームとして、私たちは完全な分散型AIオペレーティングシステムを構築し、それをAI公共財として作り上げることに尽力しています。このシステムにより、すべてのAIアプリケーションが完全に分散化された環境で実行できるようになります。これは、実行環境がL1の一部であることを意味し、ストレージだけでなく、推論、ファインチューニング、事前学習などの機能を含む計算ネットワークにも無限に拡張でき、あらゆるAIイノベーションアプリケーションの構築をサポートします。
TechFlow:先ほどもおっしゃっていましたが、0GにはMicrosoft、Amazon、Bridgewaterなどの有名企業からトップ人材が集まっており、あなたを含む多くのチームメンバーは以前からAI、ブロックチェーン、高性能計算などの分野で顕著な成果を上げてきました。どのような信念やきっかけが、この「オールスター・チーム」をして分散型AIにAll inし、0Gに加わるという共通の選択をさせたのでしょうか?
Michael:
私たちが一緒に0Gというプロジェクトを行うことにした理由の多くは、プロジェクトそのもののミッションに由来しています:AIを公共財にすること。もう一つの原動力は、AIの発展の現状に対する私たちの懸念です。
中央集権的なモデルでは、AIは少数の大手企業によって独占され、ブラックボックスとして運営される可能性があります。誰がデータに注釈を付けたのか、データがどこから来たのか、モデルの重みとパラメータは何なのか、あるいはオンライン環境で実行されている具体的なバージョンはどれなのかを知ることはできません。AIに問題が発生した場合、特に自律型AIエージェントがネットワーク上で大量の操作を実行している場合、誰が責任を負うのでしょうか?さらに悪いことに、中央集権的な企業はそのモデルの制御さえ失い、AIが完全に脱線・制御不能になる可能性さえあります。
私たちはこのような方向性を懸念しており、そのため、反中央集権的、反ブラックボックス的なAI発展モデルを構築したいと考えています。このモデルは透明で、オープンで、安全で、誰もが恩恵を受けられるものです。私たちはこれを「分散型AI」と呼んでいます。このようなシステムでは、誰もが参加し、データと計算リソースを貢献し、公平な報酬を得ることができます。私たちは、このモデルが公共財として作り上げられ、社会全体がAIの利益を共有できることを望んでいます。
TechFlow:「0G」というプロジェクト名は少し特別に聞こえます。0GはZero Gravityの略称ですが、このプロジェクト名の由来について紹介していただけますか?それは0Gの分散型AIの未来への理解をどのように体現していますか?
Michael:
実は、私たちのプロジェクト名は、私たちが一貫して堅持してきた核心理念に由来しています:
技術は、努力を要せず、スムーズで、抵抗なく、シームレスであるべきだ、特にインフラストラクチャとバックエンド技術を構築する際には。つまり、エンドユーザーは自分が0Gを使用していることを意識する必要はなく、製品がもたらすスムーズな体験だけを感じればよいのです。
これが0Gプロジェクト名の由来です:「Zero Gravity(ゼロ重力)」。ゼロ重力環境では、抵抗が最小化され、動きは自然でスムーズです。これこそが私たちがユーザーに提供したい体験です。
同様に、0Gの上に構築されるすべての製品やアプリケーションも、同じ「努力を要しない」感覚を伝えるべきです。例を挙げましょう:もしあなたがビデオストリーミングプラットフォームでドラマを見る前に、まずサーバーを選び、次にエンコーディングアルゴリズムを選び、さらに手動で支払いゲートウェイを設定しなければならないとしたら、それは非常に悪く、摩擦に満ちた体験になるでしょう。
そして、AIの発展に伴い、これらすべてが変わると私たちは考えています。例えば、あなたがAIエージェントに「現在最もパフォーマンスの良いあるミームトークンを見つけ、XX数量を購入せよ」と指示するだけで、そのAIエージェントは自動的にパフォーマンスを調査し、本当にトレンドと価値があるかどうかを判断し、所在するチェーンを確認し、必要に応じてクロスチェーンまたはブリッジして資産を購入します。このプロセス全体をユーザーが段階的に手動で実行する必要はありません。
摩擦を排除し、ユーザーが簡単に体験できるようにすること、これが0Gが可能にする「ゼロ摩擦」の未来です。

コミュニティ駆動がAIの発展モデルを徹底的に覆す
TechFlow:Web3AIの発展がWeb2 AIと比べてまだ大きな差がある現実の中で、なぜAIが次の段階の画期的な発展を遂げるには分散型の力が不可欠だと言えるのでしょうか?
Michael:
今年のWebXカンファレンスでのあるパネルディスカッションに参加した時、ある登壇者が私に強い印象を残しました。その登壇者はGoogle DeepMindで15年の経験を持っています。
私たちは一致してこう考えています:AIの未来は、より小さく、より専門的な言語モデルで構成されるネットワークに属するでしょう。それらは依然として「大規模モデル」レベルの能力を備えています。これらの専門性を持つ小さな言語モデルが、ルーティング、役割分担、インセンティブ整合を通じて精巧に編成されると、正確性、適応速度、コスト効率、アップグレードと反復の速度において、単一の巨大なモノリシックモデルを凌駕することができます。
その理由は:高価値のトレーニングデータの大部分は公開されておらず、プライベートなコードリポジトリ、内部Wiki、個人のノート、暗号化されたストレージなどに深く隠されているからです。専門分野の知識の90%以上が閉ざされており、個人の経験と強く結びついています。そして、十分な動機がない限り、ほとんどの人は自身の経済的利益を弱めるような形でこれらの専門知識を無償で提供する動機を持ちません。
しかし、コミュニティ駆動のインセンティブモデルはこれを変えることができます。例えば:私は自分のMLプログラマーの友人たちを組織して、Solidityに精通したモデルをトレーニングします。彼らはコードスニペット、デバッグ記録、計算リソース、注釈を貢献し、貢献に対してトークン報酬を得ます。さらに、モデルが後日プロダクション環境で呼び出された時、使用量に応じて継続的に報酬を得ることができます。
私たちは、これが人工知能の未来だと信じています:このモデルでは、コミュニティが分散型の計算リソースとデータを提供し、AIの参入障壁を大幅に下げ、超巨大な中央集権的なデータセンターへの依存を減らし、それによってAIシステム全体のレジリエンスをさらに向上させます。
私たちは、この分散型の発展モデルがAIの発展をより速くし、AIがより効率的にAGIに向かうことを促進すると信じています。
TechFlow:コミュニティメンバーの中には、0GとAIの関係をSolanaとDeFiの関係に例える人もいます。この例えをどのようにお考えですか?
Michael:
私たちはこのような比較を非常に嬉しく思っています。なぜなら、Solanaのような業界をリードするプロジェクトと私たちを比較対象にすることは、私たちにとって励みとなり、鞭撻となるからです。もちろん、長期的な発展の観点から、将来的には私たち自身の独自のコミュニティ文化とブランドイメージを確立し、0Gが自らの実力で直接認識されることを望んでいます。その時には、AI分野について語る際に0G自体が十分であり、もはや例えを必要としないでしょう。
0Gの将来の中核戦略において、私たちは徐々により多くの閉鎖的な中央集権的ブラックボックス型企業に挑戦することを計画しています。そのためには、さらにインフラストラクチャを固める必要があります。具体的には、今後も業界研究とハードコアなエンジニアリングに焦点を当て続けます。これは長期的で挑戦的な仕事であり、極端な場合には2年を費やすことになるかもしれませんが、現在の進捗から見ると、おそらく1年で達成できるでしょう。
例えば、私たちの知る限り、私たちは完全な分散型環境で1070億パラメータのAIモデルのトレーニングに成功した最初のプロジェクトです。この画期的な進展は、以前の公開記録の約3倍であり、私たちの研究と実行の両面におけるリーダーシップ能力を十分に示しています。
コミュニティが話題にしたSolanaとの比較に戻ると:Solanaは初期に高スループットブロックチェーンの性能で先駆けを開きました。0GもAIの分野でより多くの先駆けを開きたいと考えています。
ワンストップAIエコシステムの中核技術コンポーネント
TechFlow:AI専用に設計されたLayer 1として、技術的な観点から、0Gには他のLayer 1にはないどのような機能や優位性がありますか?それらはどのようにAIの発展を可能にしますか?
Michael:
私は、AI専用に設計されたLayer 1としての0Gの最初の独自の優位性は性能にあると考えます。
AIをチェーン上に移行することは、極端なワークロードを処理する必要があることを大きく意味します。例を挙げましょう:現代のAIデータセンターのデータスループットは毎秒数百GBから数TBに及びますが、Serumが始まった頃の性能は約毎秒80KBで、AIワークロードに必要な性能よりもほぼ100万倍低いものでした。そのため、私たちはデータ可用性層を設計しました。ネットワークノードとコンセンサスメカニズムを導入することで、あらゆるAIアプリケーションに無限のデータスループットを提供します。
また、私たちはシャーディング設計を採用しています。大規模なAIアプリケーションは、シャードを横方向に増やすことで総スループットを向上させ、事実上毎秒無限のトランザクション処理を実現できます。このような設計により、0Gはさまざまなニーズに応じたあらゆるワークロードを満たし、AIのイノベーションと発展をより良くサポートすることができます。
さらに、モジュラー設計は0Gのもう一つの顕著な特徴です:Layer 1を利用することも、ストレージ層だけを単独で使用することも、計算層だけを単独で使用することもできます。それらは単独で使用可能であり、組み合わせることでさらに強力なシナジー効果を生み出します。例えば、1000億パラメータ(100B)のモデルをトレーニングする場合、トレーニングデータをストレージ層に保存し、0G計算ネットワークを通じて事前学習やファインチューニングを実行し、データセットハッシュ、重みハッシュなどの改ざん不可能な証明をLayer 1にアンカーすることができます。また、コンポーネントの一つだけを採用することもできます。モジュラー設計により、開発者は必要に応じて取り出し、同時に監査可能性と拡張性を保持することができ、これは0Gにさまざまなユースケースをサポートする能力を与え、非常に強力です。
TechFlow:0Gは無限に拡張可能でプログラマブルなDA層を作り上げました。これはどのように実現されたのか、またどのようにAIの発展を可能にするのか、詳しく紹介していただけますか?
Michael:
技術的な観点から、このブレークスルーがどのように実現されたかを説明しましょう。
要約すると、中核的なブレークスルーは二つの部分を含みます:システム的な並列化;「データ公開パス」と「データストレージパス」を完全に分離すること。これにより、ネットワーク全体のブロードキャストのボトルネックを効果的に回避できます。
従来のDA層の設計では、完全なデータブロック(Blob)がすべてのバリデータにプッシュされ、各バリデータが同じ計算を実行し、可用性サンプリングを行ってデータ可用性を確認します。これは非常に非効率で、帯域幅を倍増させ、ブロードキャストのボトルネックを形成します。
そのため、0Gはイレイジャーコーディング設計を採用し、データブロックを大量のシャードに分割してエンコードします。例えば、データブロックを3000個のシャードに分割し、各シャードをストレージノードに一度だけ保存し、すべてのコンセンサスノードに元の大きなファイルを繰り返しプッシュしません。ネットワーク全体には、簡潔な暗号コミットメント(KZGコミットメントなど)と少量のメタデータだけがブロードキャストされます。
次に、システムはストレージノードとDAノードの間にランダムリストを作成して署名を収集し、ランダム/ローテーション委員会がシャードをサンプリングまたは包含証明を検証し、集約署名を生成して「データ可用性条件が成立」と宣言します。コミットメントと集約署名だけがコンセンサス順序に入り、コンセンサスチャネルにおける粗粒度データのトラフィックを最小限に抑えます。
このように、ネットワーク全体を流れるのは軽量なコミットメントと署名であり、完全なデータではないため、新しいストレージノードを追加することで全体の書き込み/サービス能力を増加させることができます。例えば、各ノードのスループットは約35MB/秒で、理想的にはN個のノードの理想的な総スループット≈N×35MB/秒となり、スループットは線形に拡張され、新しいボトルネックが現れるまで続きます。
そして、ボトルネックが現れた時、リステーキングの特性を利用して、同じステーキング状態を維持し、同時に任意の数のコンセンサス層を起動し、任意の大規模ワークロードの拡張を効果的に実現できます。再びボトルネックに遭遇したら、このサイクルを繰り返し、データスループットの無限の拡張性を実現します。
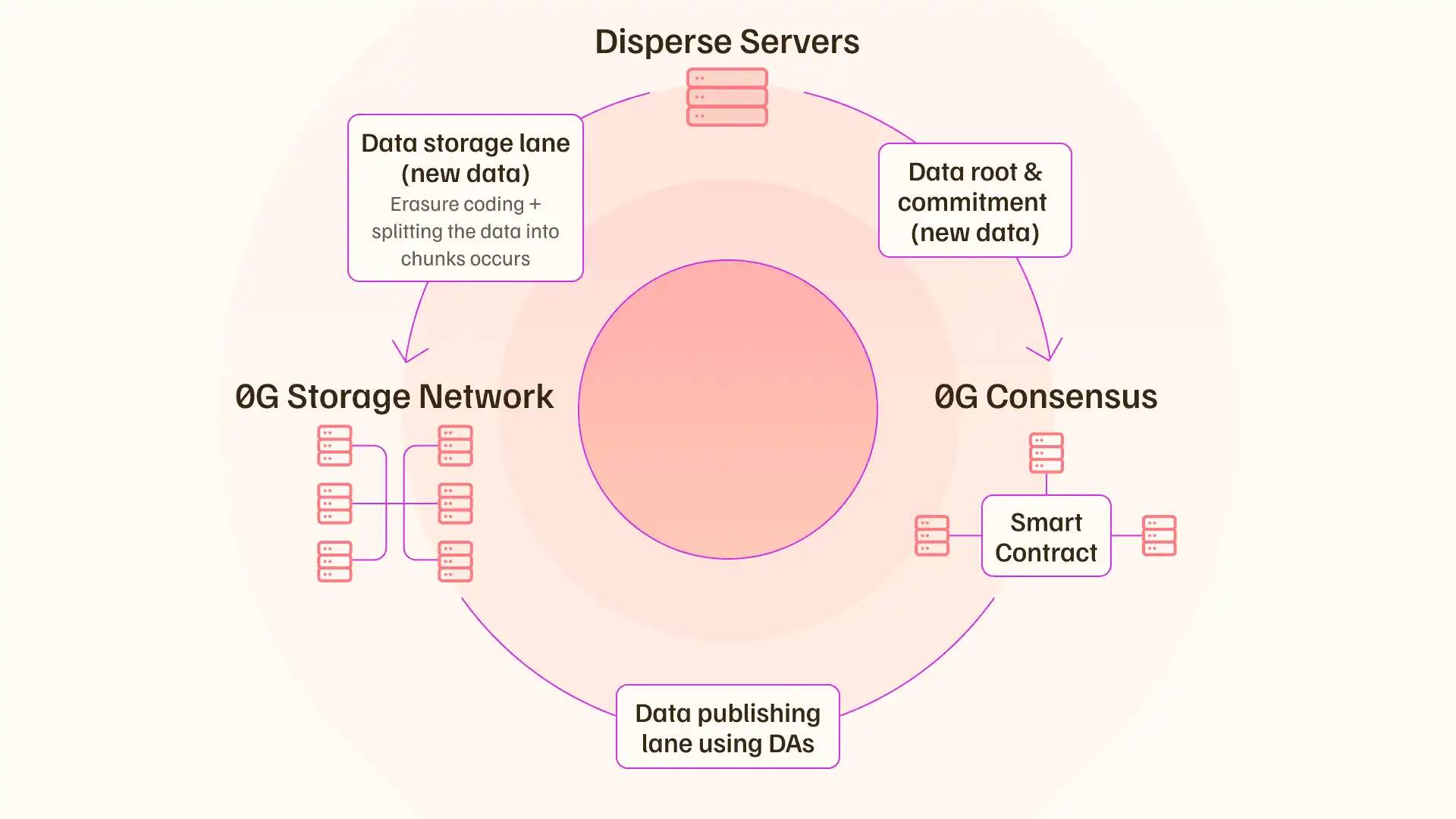
TechFlow:0Gの「ワンストップAIエコシステム」というビジョンをどのように理解すればよいですか?ここでの「ワンストップ」は具体的にいくつの中核コンポーネントに分解できますか?
Michael:
その通りです。私たちは、皆さんがチェーン上に望むあらゆるAIアプリケーションを構築するのに役立つ、必要なすべての重要なコンポーネントを提供
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













