

5兆元市場の前夜:エンボディッドAI × Web3の投資機会はどこにある?
TechFlow厳選深潮セレクト
5兆元市場の前夜:エンボディッドAI × Web3の投資機会はどこにある?
具身知能 x Web3、構造的ソリューションが投資機会を牽引。
著者:merakiki
翻訳:TechFlow
数十年にわたり、ロボット技術の応用範囲は非常に限定的であり、主に構造化された工場環境での反復作業に集中していた。しかし今日、人工知能(AI)がロボット分野を根本的に変革しており、ロボットにユーザーの指示を理解・実行させるとともに、動的に変化する環境に適応させることが可能になっている。
我々は今、急速な成長の新時代へと足を踏み入れようとしている。シティバンクの予測によれば、2035年までに世界中で13億台のロボットが導入され、その応用範囲は工場から家庭やサービス業界へと拡大するとされる。また、モルガン・スタンレーは、人間型ロボット市場単体で2050年までに5兆ドル規模に達する可能性があると予想している。
こうした拡大は巨大な市場ポテンシャルを解放する一方で、中央集権性、信頼性、プライバシー、スケーラビリティなどに関する重大な課題も伴っている。Web3技術は、分散化され、検証可能で、プライバシーを保護し、協働可能なロボットネットワークを支援することで、これらの問題に対する変革的な解決策を提供する。
本稿では、進化しつつあるAIロボットのバリューチェーン、特に人間型ロボットに焦点を当て、AIロボットとWeb3技術の融合によって生まれる魅力的な機会について深く探っていく。
AIロボットのバリューチェーン
AIロボットのバリューチェーンはハードウェア、インテリジェンス、データ、エージェントという4つの基本レイヤーから構成される。各レイヤーは他のレイヤーの上に構築され、複雑な現実環境においてロボットが認識・推論・行動できるようにする。
近年、Unitree や Figure AI といった業界の先駆者のリードにより、ハードウェア層では顕著な進展が見られた。しかし、非ハードウェア層では依然として多くの重要な課題が残っており、特に高品質なデータセットの不足、汎用基盤モデルの欠如、デバイス間の互換性の低さ、信頼できるエッジコンピューティングの必要性が挙げられる。そのため、現在最も大きな発展機会はインテリジェンス層、データ層、エージェント層にある。
1.1 ハードウェア層:「身体」
今日、現代の「ロボットの身体」の製造および展開は、これまで以上に容易になっている。現在の市場にはすでに100種類以上の異なるタイプの人間型ロボットが存在し、テスラのOptimus、UnitreeのG1、Agility RoboticsのDigit、Figure AIのFigure 02などが含まれる。

出典:モルガン・スタンレー、「人間型ロボット100:人間型ロボットバリューチェーンマップ」
この進歩は、以下の3つの主要コンポーネントにおける技術的ブレークスルーによるものである:
-
アクチュエータ(Actuators):ロボットの「筋肉」として機能し、デジタル指令を正確な動きに変換する。高性能モーターの革新により、ロボットは高速かつ精密な動作を実現でき、さらに電歪弾性体アクチュエータ(Dielectric Elastomer Actuators, DEAs)は微細なタスクに適している。これらの技術はロボットの柔軟性を大幅に向上させており、例えばテスラのOptimus Gen 2は22の自由度(DoF)を持ち、UnitreeのG1も人間に近い柔軟性と印象的な移動能力を示している。

出典:Unitreeが2025年WAIC世界人工知能大会で最新の人間型ロボットによるボクシング対戦を披露
-
センサー(Sensors):高度なセンサーは視覚、LIDAR/RADAR、触覚、音声入力を通じて、ロボットが環境を認識・解釈することを可能にする。これらの技術は安全なナビゲーション、精密な操作、状況認識をサポートする。
-
組み込み計算(Embedded Computing):デバイス上のCPU、GPU、TPUやNPUなどのAIアクセラレータは、センサーデータをリアルタイムで処理し、AIモデルを実行することで自律的な意思決定を可能にする。信頼性の高い低遅延接続によりシームレスな協調が保たれ、ハイブリッドなエッジ-クラウドアーキテクチャにより、ロボットは必要に応じて計算負荷の高いタスクをオフロードできる。
1.2 インテリジェンス層:「脳」
ハードウェアが成熟するにつれ、業界の関心は「ロボットの脳」の構築――強力な基盤モデルと高度な制御戦略――へと移ってきている。
AI統合以前のロボットはルールベースの自動化に依存しており、あらかじめプログラムされた動作を実行するだけで、適応的な知能を持たなかった。
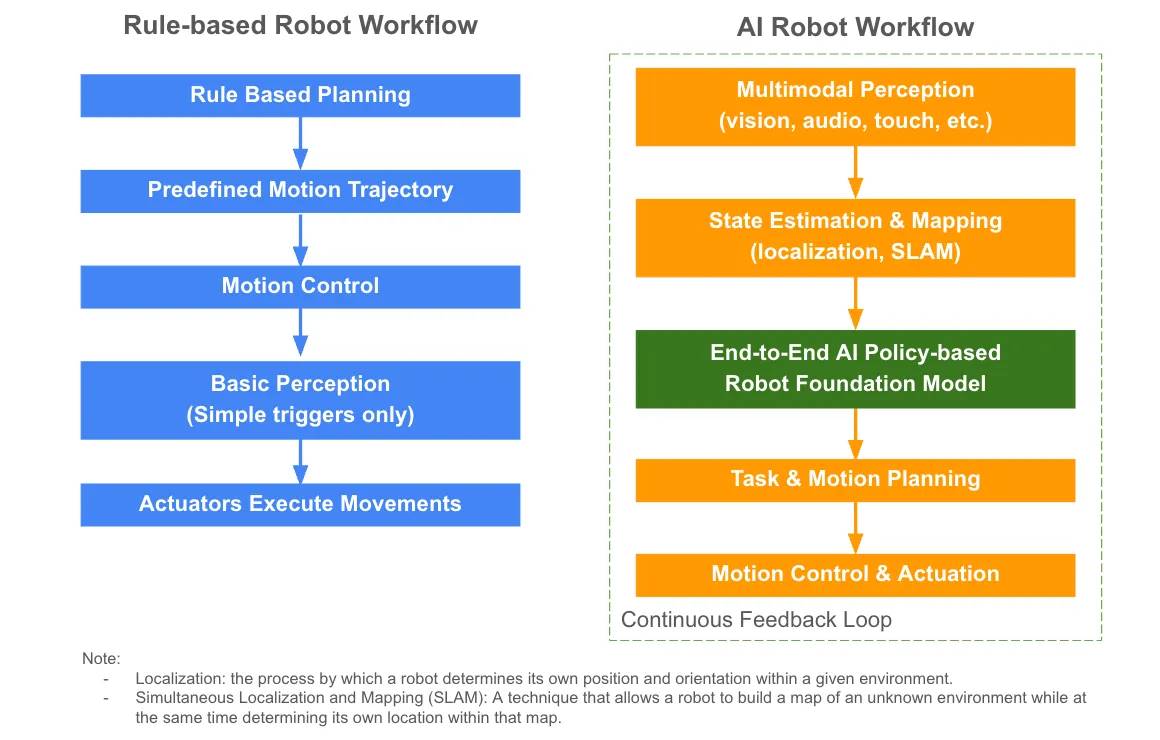
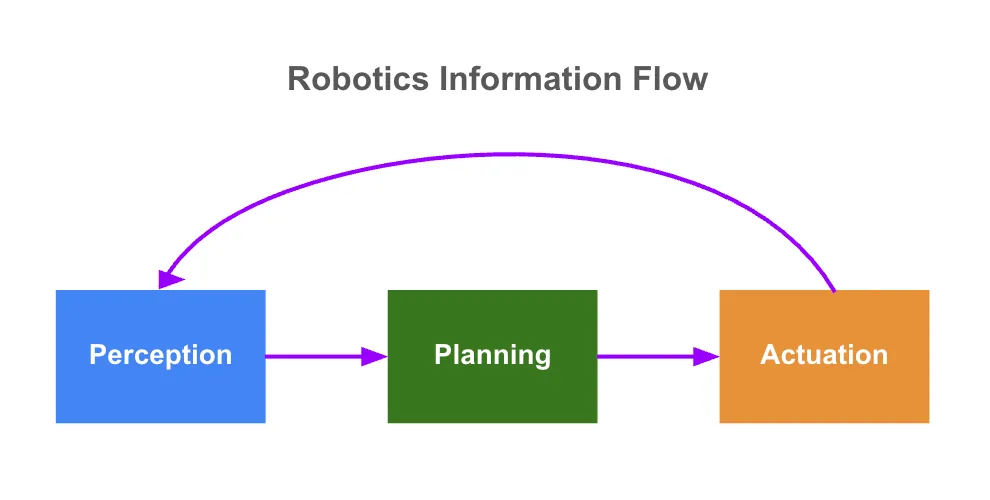
基盤モデルが徐々にロボット分野にも適用されつつある。しかし、汎用の大規模言語モデル(LLMs)だけでは不十分であり、ロボットは動的な物理環境で認識・推論・行動する必要がある。これらのニーズに対応するため、業界ではエンドツーエンドのロボット基盤モデルが開発されている。これらのモデルにより、ロボットは以下を行うことができる:
-
認識(Perceive):マルチモーダルなセンサーデータ(視覚、音声、触覚)を受け取る
-
計画(Plan):自らの状態を推定し、環境地図を作成し、複雑な命令を解釈し、認識結果を直接行動にマッピングすることで、手作業による工学的介入を減らす
-
行動(Act):運動計画を生成し、リアルタイム実行のための制御命令を出力する
これらのモデルは世界との相互作用に関する一般的な「戦略」を学習し、ロボットがさまざまなタスクに適応し、より高い知能と自律性を持って動作することを可能にする。高度なモデルは継続的なフィードバックを活用し、経験から学習することで、動的環境での適応能力をさらに高める。
VLAモデルは感覚入力(主に視覚データと自然言語命令)をロボットの行動に直接マッピングし、ロボットが「見る」「聞く」内容に基づいて適切な制御命令を発行できるようにする。注目すべき例としてはGoogleのRT-2、NVIDIAのIsaac GR00T N1、そしてPhysical Intelligence社のπ0がある。
これらのモデルを強化するために、通常は次のような複数の補完的手法が統合される:
-
ワールドモデル(World Models):物理的環境の内部シミュレーションを構築し、ロボットが複雑な行動を学び、結果を予測し、行動を計画できるようにする。例えば、Googleが最近発表したGenie 3は、前例のない多様なインタラクティブ環境を生成できる汎用ワールドモデルである。
-
深層強化学習(Deep Reinforcement Learning):試行錯誤を通じてロボットが行動を学ぶのを助ける。
-
遠隔操作(Teleoperation):遠隔からの操作を可能にし、トレーニングデータを提供する。
-
デモンストレーション学習(LfD)/模倣学習(Imitation Learning):人間の動作を模倣することで、ロボットに新しいスキルを教える。
以下の図は、これらの手法がロボット基盤モデル内でどのように機能するかを示している。
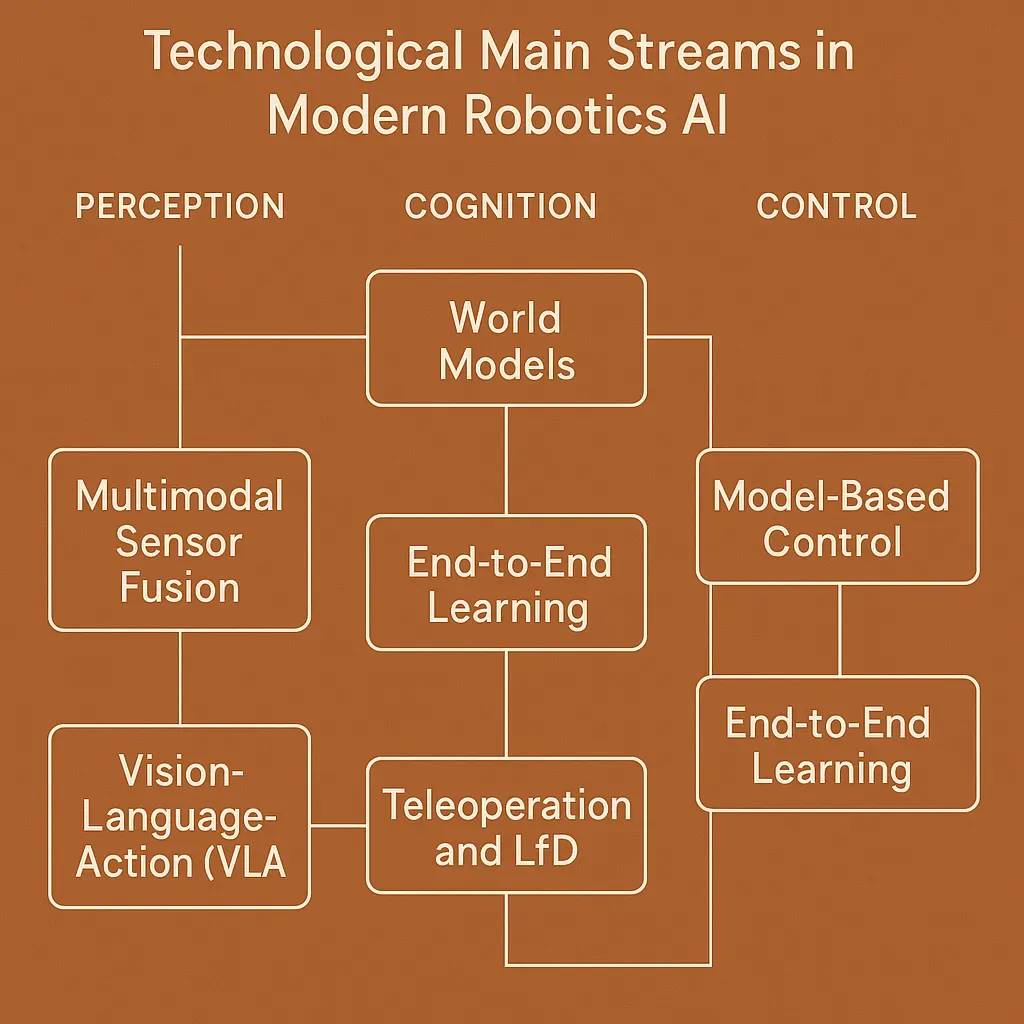
出典:ワールドモデル:AGIへの道を進める物理的知能の核(World models: the physical intelligence core driving us toward AGI)
最近のいくつかのオープンソースのブレークスルー、例えばPhysical Intelligence社のπ0やNVIDIAのIsaac GR00T N1は、この分野における重要な進展を示している。しかし、ほとんどのロボット基盤モデルは依然として中央集権的でクローズドソースである。CovariantやTeslaなどの企業は、開放的なインセンティブメカニズムの欠如により、引き続き独自のコードとデータセットを保持している。
このような透明性の欠如は、ロボットプラットフォーム間の協働性と相互運用性を制限し、安全で透明なモデル共有、チェーン上でのコミュニティガバナンス、デバイス横断的な相互運用性レイヤーの必要性を浮き彫りにしている。このようなアプローチは信頼と協働を促進し、この分野のより強力な発展を推進するだろう。
1.3 データ層:脳の「知識」
強力なロボットデータセットは量、質、多様性という3つの柱に依存している。
業界はデータ蓄積に取り組んでいるものの、既存のロボットデータセットの規模は依然として不十分である。例えば、OpenAIのGPT-3は3000億トークンのデータで訓練されているが、最大のオープンソースロボットデータセットであるOpen X-Embodimentは22種類のロボットを含む100万以上の実際のロボット軌跡しか持たない。これは強力な汎化能力を得るために必要なデータ規模と比べて、極めて小さい。
専有型のアプローチ、例えばテスラが「データファクトリー」で従業員にモーションキャプチャスーツを着せてトレーニングデータを収集する方法は、確かに実際の運動データの収集を助けている。しかし、こうした方法はコストが高く、データの多様性が限られ、スケールしにくい。
これらの課題に対処するため、ロボット分野では以下の3つの主なデータ源を利用している:
-
インターネットデータ:インターネットデータは規模が大きくスケーラブルだが、主に観察データであり、センサーと運動信号が欠けている。インターネットデータ上で大規模な視覚言語モデル(GPT-4VやGeminiなど)を事前学習することで、貴重な意味的・視覚的先行情報を得ることができる。また、動画に運動学的ラベルを付けることで、生の映像を操作可能なトレーニングデータに変換できる。
-
合成データ:シミュレーションで生成される合成データは、大規模な実験を迅速に行い、多様なシナリオをカバーできるが、現実世界の複雑さを完全に反映できないという限界がある(「シミュレーションから現実へのギャップ(sim-to-real gap)」)。研究者らはドメイン適応(データ拡張、ドメインランダム化、敵対的学習など)やシミュレーションから現実への移行によってこの問題に対処し、モデルを繰り返し最適化し、現実環境でテスト・微調整を行う。
-
現実世界のデータ:稀少で高価であるが、モデルの実用化やシミュレーションと実際の展開のギャップを埋めるために不可欠である。高品質な現実データには、通常、第一人称視点(egocentric views)でロボットがタスク中に「見る」内容や、正確な動作を記録する運動データが含まれる。運動データは、通常、人間のデモンストレーションや遠隔操作によって収集され、VR、モーションキャプチャ装置、または触覚指導を通じて、モデルが正確な実例から学習できるようにする。
研究によれば、インターネットデータ、現実世界データ、合成データを組み合わせてロボットを訓練することは、いずれか一つのデータソースに依存する場合よりも、訓練効率とモデルのロバスト性(注:異常や危険な状況下でも健全で強靭な特性を保つ能力)を大幅に向上させる。
同時に、データ量の増加は助けになるが、特に新しいタスクやロボット形態への汎化を実現するためには、データの多様性の方が重要である。このような多様性を実現するには、オープンなデータプラットフォームと共同的なデータ共有が必要であり、複数のロボット形態をサポートするクロスインスタンスデータセットの作成を通じて、より強力な基盤モデルの発展を推進する。
1.4 エージェント層:「物理的AIエージェント」
物理的AIエージェントへの傾向は加速しており、これらの自律型ロボットは現実世界で独立して行動できるようになる。エージェント層の進歩は、モデルの微調整、継続的学習、および各ロボットのユニークな形態に特化した実際の適合に依存している。
物理的AIエージェントの発展を加速する新たな機会は以下の通り:
-
継続的学習と適応型インフラ:リアルタイムのフィードバックループと展開中の共有経験により、ロボットが継続的に改善できるようにする。
-
自律エージェント経済:ロボットが独立した経済主体として動作し、ロボット間市場で計算能力やセンサーデータなどのリソースを取引し、トークン化されたサービスで収益を生み出す。
-
マルチエージェントシステム:次世代のプラットフォームとアルゴリズムにより、ロボット群が協調・協働し、集団的行動を最適化できる。
AIロボットとWeb3の融合:巨大な市場ポテンシャルの解放
AIロボットが研究段階から現実世界での実用展開へと移行する中で、長年の課題がイノベーションを妨げ、ロボットエコシステムのスケーラビリティ、ロバスト性、経済的実現可能性を制限している。これらには、データとモデルの中央集権的孤島、信頼性とトレーサビリティの欠如、プライバシーとコンプライアンスの制限、相互運用性の不足が含まれる。
2.1 AIロボットが直面する課題
-
中央集権的なデータとモデルの孤島
ロボットモデルには大量で多様なデータセットが必要である。しかし、現在のデータとモデルの開発は高度に中央集権的で分散化されており、コストが高い。これによりシステムが分断され、適応性が低下している。動的な現実環境に展開されたロボットは、しばしばデータの多様性不足やモデルのロバスト性の限界により、パフォーマンスが劣る。
-
信頼性、トレーサビリティ、信頼性
データの出所、モデルの学習プロセス、ロボットの運用履歴などを含む透明で監査可能な記録が欠如しているため、信頼性と責任の所在が損なわれる。これはユーザー、規制当局、企業がロボットを採用する際の主要な障壁となっている。
-
プライバシー、セキュリティ、コンプライアンス
医療や家庭用ロボットなどのセンシティブな用途では、プライバシー保護が極めて重要であり、欧州のGDPR(一般データ保護規則)など厳格な地域規制に準拠しなければならない。中央集権的なインフラは、安全でプライバシー保護されたAI協働を支援するのが難しく、データ共有を制限し、規制対象やセンシティブな分野でのイノベーションを抑制する。
-
スケーラビリティと相互運用性
ロボットシステムは、リソース共有、協同学習、複数のプラットフォームや形態にわたる統合において大きな課題に直面している。これらはネットワーク効果の分断を招き、異なるロボットタイプ間での能力の迅速な移転を妨げる。
2.2 AIロボット × Web3:投資機会を牽引する構造的解決策
Web3技術は、分散化され、検証可能で、プライバシーを保護し、協働可能なロボットネットワークを通じて、上記の課題を根本的に解決する。この融合は新たな投資機会を開拓している:
-
分散型の協働開発:インセンティブ駆動型ネットワークにより、ロボットがデータを共有し、共同でモデルやインテリジェントエージェントを開発できる。
-
検証可能なトレーサビリティと責任:ブロックチェーン技術により、データとモデルの出所、ロボットの身元、運用履歴が改ざん不可能な形で記録され、信頼性とコンプライアンスにとって不可欠となる。
-
プライバシー保護型協働:高度な暗号技術により、ロボットは独自の情報やセンシティブなデータを公開せずに、モデルの共同学習や知見の共有が可能になる。
-
コミュニティ主導のガバナンス:分散型自治組織(DAO)がチェーン上での透明かつ包括的なルールとポリシーを通じて、ロボットの運用を指導・監督する。
-
クロスモーフィック相互運用性:ブロックチェーンベースのオープンフレームワークが、異なるロボットプラットフォーム間のシームレスな協働を促進し、開発コストを削減し、能力の移転を加速する。
-
自律エージェント経済:Web3インフラはロボットに独立した経済エージェントとしてのアイデンティティを与え、人間の介在なしにP2P取引、交渉、トークン化市場への参加を可能にする。
-
分散型物理インフラネットワーク(DePIN):ブロックチェーンベースのP2P計算、センシング、ストレージ、接続の共有により、ロボットネットワークのスケーラビリティと弾力性が強化される。
以下は、この分野の発展を推進している革新的なプロジェクトの一例であり、AIロボットとWeb3の融合の可能性とトレンドを示している。もちろん、これは参考情報であり、投資勧誘を意図したものではない。
分散型データとモデル開発
Web3駆動型プラットフォームは、貢献者(モーションキャプチャスーツ、センサー共有、視覚データアップロード、データアノテーション、さらには合成データ生成など)へのインセンティブ付与を通じて、データとモデル開発の民主化を実現する。このアプローチにより、単一企業が達成できる範囲を遥かに超える、より豊かで多様かつ代表的なデータセットとモデルを構築できる。分散型フレームワークは、予測不能な環境で動作するロボットにとって極めて重要な、エッジケースへのカバレッジも向上させる。
事例:
-
Frodobots:ロボットゲームを通じて現実世界のデータセットをクラウドソーシングするプロトコル。「Earth Rovers」プロジェクト――歩道用ロボットとグローバル「Drive to Earn」ゲーム――を展開し、FrodoBots 2K Datasetデータセットを成功裏に作成した。このデータセットにはカメラ映像、GPSデータ、音声記録、人間操作データが含まれ、10都市以上をカバーし、約2000時間のリモート操作ロボット走行データが累計されている。
-
BitRobot:FrodoBots LabとProtocol Labsが共同開発した暗号インセンティブプラットフォーム。Solanaブロックチェーンおよびサブネットアーキテクチャに基づいている。各サブネットは公開チャレンジとして設定され、貢献者はモデルやデータの提出に対してトークン報酬を得ることで、グローバルな協働とオープンソースのイノベーションを促進する。
-
Reborn Network:AGIロボットのオープンエコシステムの基盤層。複雑な人間型ロボットデータセットのオープン化を支援するために、Rebocapモーションキャプチャスーツを提供し、誰もが自身の実際の運動データを記録して収益化できるようにする。
-
PrismaX:グローバルなコミュニティ貢献者の力を活用し、分散型インフラでデータの多様性と真正性を確保し、強力な検証とインセンティブメカニズムを実施することで、ロボットデータセットの大規模化を推進する。
トレーサビリティと信頼性の証明
ブロックチェーン技術は、ロボットエコシステムにエンドツーエンドの透明性と責任の所在を提供する。データとモデルの検証可能なトレーサビリティを保証し、ロボットの身元と物理的位置を認証し、運用履歴と貢献者の関与を明確に記録する。さらに、協働型検証、チェーン上の評判システム、ステークに基づく検証メカニズムにより、データとモデルの品質が守られ、低品質または詐欺的な入力がエコシステムを損なうことを防ぐ。
事例:
-
OpenLedger:コミュニティ所有のデータセットを利用して専用モデルを訓練・展開するAIブロックチェーンインフラ。“Proof of Attribution”(帰属の証明)メカニズムを通じて、高品質なデータ貢献者が公正な報酬を得られるようにする。
トークン化された所有権、ライセンス、マネタイズ
Web3ネイティブの知的財産ツールは、専用データセット、ロボット能力、モデル、インテリジェントエージェントのトークン化ライセンスを支援する。貢献者はスマートコントラクトを用いてライセンス条件を資産に直接埋め込み、データやモデルが再利用またはマネタイズされた際に自動的にロイヤリティを受け取れるようにする。このアプローチは透明で許可不要のアクセスを促進し、ロボットデータとモデルのためのオープンで公平な市場を創出する。
事例:
-
Poseidon:IP中心のStoryプロトコルに基づくフルスタック分散型データ層。法的許諾されたAIトレーニングデータを提供する。
プライバシー保護ソリューション
病院、ホテルの客室、家庭などで生成される高価値データは、公共チャネルでは取得が難しいものの、豊かな文脈情報を持つため、基盤モデルの性能を大幅に向上させることができる。暗号化ソリューションにより、プライベートデータをチェーン上の資産に変換し、追跡可能・組み合わせ可能・収益化可能にしながら、プライバシーを保護する。TEE(Trusted Execution Environment)やゼロ知識証明(ZKPs)などの技術は、元のデータを公開せずに安全な計算と結果の検証を可能にする。これらのツールにより、組織は分散されたセンシティブデータ上でAIモデルを訓練しつつ、プライバシーとコンプライアンスを維持できる。
事例:
-
Phala Network:開発者がアプリケーションを安全なTEEにデプロイし、機密AIおよびデータ処理を可能にする。
オープンで監査可能なガバナンス
ロボットの訓練は、通常、透明性や適応性に欠ける独占的ブラックボックスシステムに依存している。リスクを低減し、ユーザー、規制当局、企業の信頼を高めるには、透明で検証可能なガバナンスが極めて重要である。Web3技術はチェーン上でのコミュニティ主導の監視を通じて、オープンソースのロボットインテリジェンスの協働開発を実現する。
事例:
-
Openmind:ロボットが考え、学び、協働するのを支援するオープンなAIネイティブソフトウェアスタック。人間とロボットの社会のためのERC7777標準を提唱し、検証可能なルールに基づくロボットエコシステムの構築を目指している。安全性、透明性、スケーラビリティに重点を置き、人間とロボットの身元管理、社会的ルールセットの実行、参加者の登録・除外のための標準化インターフェースを定義し、関連する権利と責任を明確にする。
最後に
AIロボットとWeb3技術の融合により、自律システムが大規模に協働し、適応する全新时代へと進んでいる。今後3〜5年が鍵となる期間であり、ハードウェアの急速な進化が、より豊かな現実世界のデータセットと分散型協働メカニズムに基づいたより強力なAIモデルの誕生を促すだろう。専用AIエージェントがホテル業界、物流など複数の業界で登場し、巨大な新市場機会を創出すると予想される。
しかし、AIロボットと暗号技術の融合には課題もある。バランスの取れた効果的なインセンティブ設計は依然として複雑で進化途中であり、貢献者を公正に報酬する一方で悪用を防ぐ必要がある。技術的複雑性も大きな課題であり、複数のロボットタイプのシームレスな統合を実現する堅牢でスケーラブルなソリューションの開発が急務である。また、プライバシー保護技術は十分に信頼できるものでなければならず、特にセンシティブデータを扱う際にはステークホルダーの信頼を得る必要がある。急速に変化する規制環境にも慎重に対応し、各国管轄区域でのコンプライアンスを確保しなければならない。これらのリスクを解決し、持続可能なリターンを実現することが、技術進歩と広範な普及を推進する鍵となる。
我々はこの分野の進展に注目し、協働を通じて進歩を促し、急速に拡大する市場に現れる機会を捉えていくべきである。
ロボット技術の革新は、共に歩むのが最良の旅路である :)
最後に、私の研究に貴重な支援を提供してくれたChain of Thoughtの『ロボティクスと物理的AIの時代』(Robotics & The Age of Physical AI)に感謝したい。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













