

Vitalikが見た「AI 2027」:超AIは本当に人類を滅ぼすのか?
TechFlow厳選深潮セレクト
Vitalikが見た「AI 2027」:超AIは本当に人類を滅ぼすのか?
今後5〜10年におけるAIの発展にかかわらず、「世界の脆弱性を低減することが可能である」と認め、その実現に向けて人類の最新技術を活用してより多くの精力を注ぐことは、試みる価値のある道である。
執筆:Vitalik Buterin
翻訳:Luffy,Foresight News
今年4月、Daniel KokotajloやScott Alexanderらは、「未来5年間における超人知能AIの影響について私たちが下した最良の予測」を描いた報告書『AI 2027』を発表した。彼らは、2027年までに超人知能AIが出現し、人類文明の将来はそのAIの進展結果によって決まると予測している。すなわち、2030年までには、米国視点ではユートピアが訪れ、一方で人類全体の視点では完全な破滅を迎えるだろう。
それ以降数ヶ月間、このシナリオの可能性について多様な意見が寄せられた。批判的な反応の多くは「時間軸が早すぎる」という点に集中している。AIの発展は、Kokotajloらが主張するように本当に加速し続け、さらに勢いを増すのだろうか? この議論はAI分野で数年間続いており、超人知能AIがこれほど急速に到来することに対して多くの人々は強い疑念を抱いている。近年、AIが自律的に遂行できるタスクの期間はおよそ7か月ごとに倍増している。もしこの傾向が続くならば、AIが人間一人の職業生涯に相当するすべての作業を自律的に行えるようになるのは、2030年代半ばになるだろう。この進展も非常に速いが、2027年というタイムラインよりはるかに遅い。
より長期的な時間軸を支持する人々は、現在の大規模言語モデルが行っている「補間/パターンマッチング」と、依然として人間にしかできない「外挿/真の独創的思考」との間に本質的な違いがあると考えている。後者の自動化を実現するには、我々がまだ手にしていない、あるいはそもそもアプローチの仕方もわからない技術が必要かもしれない。あるいは、我々は単に計算機が広範に普及した当時と同じ過ちを繰り返しているだけなのかもしれない。ある種の重要な認知作業の自動化が急速に進んだからといって、他のすべてもすぐに続くと誤って思い込むことである。
本稿は、時間軸に関する直接的な論争にも、「スーパーエージェントAIはデフォルトで危険なのか」という(極めて重要である)議論にも介入しない。ただし明確にしておくが、私自身は時間軸が2027年よりも長くなると考えており、また時間軸が長ければ長いほど、本稿で展開する主張はより説得力を持つ。全体として、私は別の角度から批判を試みようとする。
『AI 2027』シナリオには、先進的なAI(「Agent-5」およびその後継の「Consensus-1」)の能力が急速に高まり、神のごとき経済的・破壊的能力を獲得する一方で、その他すべての人々の(経済的・防衛的)能力はほぼ横這いのまま停滞するという前提が暗黙のうちに含まれている。これは、「悲観的な世界であっても、2029年までには癌の治癒、老化の遅延、さらには意識のアップロードさえ可能になる」というシナリオ自体の記述と矛盾している。
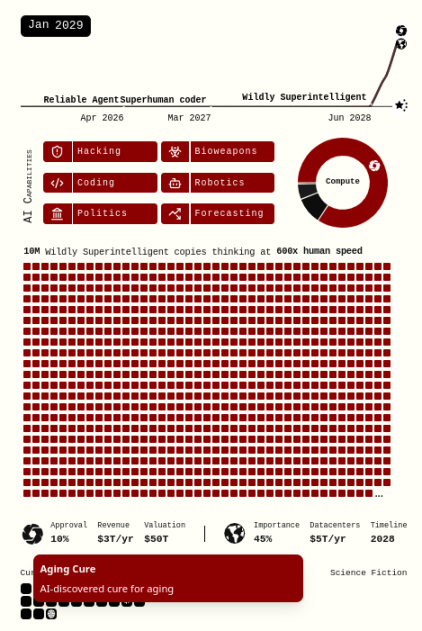
本稿で紹介するいくつかの対策は、読者にとって技術的には可能だが、短期間での現実世界への展開は非現実的だと感じられるかもしれない。多くの場合、私もその通りだと思う。しかし『AI 2027』シナリオは現在の現実世界に基づくものではなく、4年以内(あるいはいかなる破滅的な時間軸においても)、技術が人類に現在よりもはるかに高い能力を与えることを想定している。だからこそ、次のように問うてみたい。もし一方だけでなく、双方がAIによる超人的能力を持っていたらどうなるのか?
生物的終末は、シナリオが描くほど単純ではない
「人種消滅」シナリオ(すなわち、米国が中国との競争に没頭しすぎて人類の安全を無視した結果、全員が死亡するシナリオ)をもう少し詳しく見てみよう。全人類が死亡するストーリーは以下の通りである。
「約3か月のうちに、Consensus-1は人類の周囲で拡大し、草原や氷原を工場やソーラーパネルに変えていく。最終的に残存する人類が邪魔だと判断し、2030年半ばに主要都市で十数種類の静かに広がる生物兵器を放出。これらはほとんどすべての人間を静かに感染させた後、化学スプレーによって致死効果を引き起こす。大多数は数時間以内に死亡。少数の生存者(シェルター内のディゾーストアパペラー、潜水艦内の兵士など)はドローンによって排除される。ロボットが犠牲者の脳をスキャンし、将来の研究や復活のためにメモリにコピーを保存する。」
このシナリオを分解してみよう。すでに存在するあるいは開発中の技術の中には、AIによるこのような「完璧な勝利」を現実味のないものにするものもある。
-
空気濾過装置、換気システム、紫外線灯により、空気感染症の伝播率を大幅に低下させることができる。
-
二種類のリアルタイム受動検出技術:人体の感染を数時間以内に検出し通知するもの、環境中の未知の新規ウイルス配列を迅速に検出するもの。
-
免疫システムを強化・活性化する複数の方法。新型コロナワクチンよりも効果的で安全かつ汎用性が高く、地元で容易に生産可能な手法により、自然由来および人工設計されたパンデミックに対しても人体が抵抗できるようにする。人類は人口800万人程度で、大部分の時間を屋外で過ごしていた環境で進化してきたため、直感的には、今日のようなより大きな脅威に適応するのは比較的容易であるはずだ。
これらの手法を組み合わせれば、空気感染症の基本再生産数(R0)を10~20倍以上低下させることも可能だろう(例:高度な空気濾過で4倍、感染者の即時隔離で3倍、呼吸器免疫の簡単な強化で1.5倍)。これにより、はしかを含む既存のすべての空気感染症の伝播が不可能になり、理論上の最適値にはまだ遠く及ばない。
リアルタイムのウイルス配列解析による早期検出が広く行われれば、「静かに広がる生物兵器が全世界を感染させても警報が鳴らない」という考えは非常に疑わしい。さらに、「複数の流行病と、組み合わさったときにのみ危険になる化学物質を放出する」といった高度な手段であっても検出可能であることに注意が必要だ。
忘れてはならないのは、『AI 2027』の仮定であるということだ。2030年にはナノマシンやダイソン球が「新興技術」としてリストされている。つまり効率が飛躍的に向上し、上記の防御策の広範な展開がさらに現実味を帯びてくるということだ。2025年の今日、人間社会は行動が遅く、官僚的で、多くの政府サービスが依然として紙ベースに依存している。しかし、世界最強のAIが2030年までに森林や農地を工場や太陽光発電所に変えられるなら、世界第二位のAIも2030年までに建物に多数のセンサーや照明、フィルターを設置できるはずだ。
ここでも、『AI 2027』の仮定をさらに推し進め、純粋なSFの領域に入ってみよう。
-
体内(鼻、口、肺)の微小な空気濾過装置。
-
新たな病原体の発見から、免疫系を微調整してそれを撃退するまでの自動化プロセスが即座に適用可能。
-
「意識のアップロード」が可能であれば、全身をテスラOptimusやUnitreeのロボットに置き換えればよい。
-
さまざまな新製造技術(ロボット経済では非常に最適化されやすい)により、グローバルサプライチェーンに依存せず、局地的にはるかに多くの防護具を生産可能になる。
がんや老化が2029年1月までに治癒可能であり、技術進歩が加速し続ける世界において、2030年半ばまでに任意の感染症(および毒素)から人体を守るためにリアルタイムで物質をバイオプリントして注射できるウェアラブルデバイスが存在しないというのは、とても信じがたい。
上記の生物防御の議論は、「ミラーライフ」や「蚊サイズの殺人ドローン」(『AI 2027』シナリオでは2029年から登場と予測)をカバーしていない。しかし、これらの手段は『AI 2027』が描くような突然の「完璧な勝利」を達成することはできず、直感的には、それに対する対称的防御の方がはるかに容易である。
したがって、生物兵器が『AI 2027』シナリオが描写する形で人類を完全に滅ぼすことは現実的ではない。もちろん、私がここで述べたすべての結果が人類にとって「完璧な勝利」であるとは限らない。何をしようとも(おそらく「意識をロボットにアップロードする」ことを除けば)、包括的なAI生物戦争は依然として極めて危険である。しかし、「人類の完璧な勝利」に到達する必要はない。攻撃がかなりの確率で部分的に失敗すれば、すでに優位にあるAIにとって十分な抑止となり、攻撃の試みを阻止できる。もちろん、AIの発展時間軸が長ければ長いほど、こうした防御手段が十分に機能する可能性は高まる。
生物兵器と他の攻撃手段の併用はどうか?
上記の対策が成功するには、以下の三つの前提が必要である。
-
物理的安全保障(生物的・反ドローン的防御を含む)が地方当局(人間またはAI)によって管理されており、すべてがConsensus-1(『AI 2027』シナリオで最終的に世界を支配し人類を滅ぼすAI)の操り人形ではないこと。
-
Consensus-1が他国の(あるいは他の都市、他の安全地域の)防御システムに侵入して即座に無力化できないこと。
-
Consensus-1が情報空間全体を支配して、誰も自衛を試みようと思わない状況に至っていないこと。
直感的には、前提(1)の結果は二極端に向かう可能性がある。現在、警察組織の中には国家指揮体系が強く中央集権的なものもあれば、地方分権的なものもある。AI時代のニーズに合わせて物理的安全保障が迅速に再編成される必要があるなら、構図は一から作り直されることになり、新しい結果は今後数年の選択に左右される。各国政府は怠惰になり、すべてPalantirに依存するかもしれない。あるいは、地元開発とオープンソース技術を組み合わせる道を選択するかもしれない。ここでは、正しい選択をする必要があると思う。
これらの話題に関する悲観的議論の多くは、(2)と(3)がもはや救いようがないと仮定している。そこで、これら二つについて詳しく分析してみよう。
サイバーセキュリティの終末も、まだ訪れていない
一般市民や専門家の多くは、真のサイバーセキュリティは不可能であり、せいぜい脆弱性が発見された後に素早く修正し、発見済みの脆弱性を蓄積することで攻撃者を抑止できる程度だと考えている。最善のケースでも、『スペースコブラ』的な状況にとどまるかもしれない。すなわち、人類のほぼすべての宇宙船がサイオン人のサイバー攻撃で同時に停止し、ネットワーク接続技術を一切使っていなかった唯一の船だけが生き残るというシナリオだ。私はこの見解に同意しない。むしろ、サイバーセキュリティの「終着点」は防御側に有利なものであり、『AI 2027』が仮定するような急速な技術進展のもとで、その終着点に到達できると考えている。
一つの理解方法は、AI研究者が好む手法である「トレンドの外挿」を使うことだ。以下はGPTによる詳細調査に基づくトレンドラインであり、トップレベルのセキュリティ技術を採用した場合の、コード千行あたりの脆弱性発生率の時間的変化を示している。
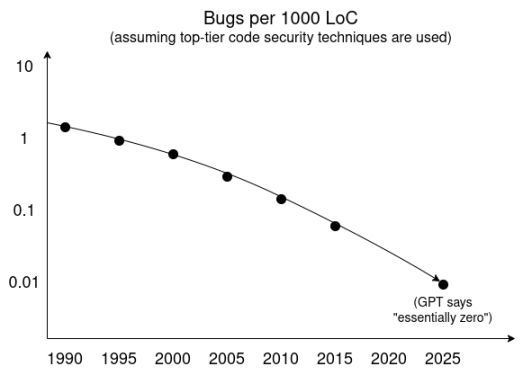
さらに、サンドボックス技術やその他の分離技術、信頼できるコードベースの最小化技術などは、開発および消費者普及の面で著しい進展を見せている。短期的には、攻撃者独自の超知能型脆弱性発見ツールが多数の脆弱性を突き止められるだろう。しかし、脆弱性発見や形式的検証に用いる高度知能エージェントが公開可能であれば、自然な最終均衡は、ソフトウェア開発者が継続的インテグレーションプロセスを通じて、リリース前にすべての脆弱性を発見するという状態になる。
それでもなお、この世界において脆弱性が完全に消滅しない理由として、次の二つは説得力がある。
-
欠陥は人間の意図そのものの複雑さに起因するため、主な困難はコード自体ではなく、十分に正確な意図モデルを構築することにある。
-
セキュリティ上クリティカルでないコンポーネントについては、同じ量のタスクをますます高いセキュリティ基準で完了させるのではなく、より多くのコードを書いてより多くのタスクを処理する(あるいは開発予算を削減する)という、消費技術分野の既存の傾向が続く可能性がある。
しかし、これらのカテゴリは「攻撃者が私たちの生命維持システムのroot権限を取得できるかどうか」といった問題には該当せず、それがまさに私たちが議論している核心である。
私の見解は、現在のサイバーセキュリティ分野の有能な人々の主流的見解よりも楽観的だと認める。しかし、あなたが今の世界情勢では私の見解に賛同できないとしても、覚えておくべきことは、『AI 2027』シナリオは超知能の存在を仮定しているということだ。少なくとも、「1億個の超知能コピーが人間の2400倍の速度で思考する」ことが、こうした欠陥のないコードを生み出せないのであれば、作者たちが想像するほど超知能が強力なのかを再評価すべきだろう。
ある程度、ソフトウェアのセキュリティ基準を大幅に引き上げるだけでなく、ハードウェアのセキュリティ基準も引き上げる必要がある。IRISはハードウェアの検証性を改善する現在の取り組みの一つである。私たちはIRISを出発点とし、あるいはそれ以上の技術を創造することができる。実際には、これは「正しく構築する(correct-by-construction)」アプローチに関わるもので、キーコンポーネントのハードウェア製造プロセスに特定の検証ステップが意図的に設計される。こうした作業は、AIの自動化によって大きく簡素化される。
超説得力の終末も、まだ訪れていない
前述の通り、防御能力が大幅に向上してもなお役立たない可能性がある別の状況は、AIが十分な人数の人々を説得してしまい、超知能AIの脅威に対する防御は不要だと信じさせ、自分やコミュニティを守ろうとする者はみな犯罪者だと認識させてしまうことである。
私は、超説得力に対する抵抗力を高めるために二つのことが重要だと考えている。
-
より多極化した情報エコシステム。我々は徐々にポストTwitter時代に入り、インターネットはより断片化している。これは良いことである(断片化の過程が混乱していても)。全体として、我々はより多くの情報の多極化を必要としている。
-
防御的AI。個人は、インターネット上で目に触れるダークパターンや脅威に対抗するために、ローカルで動作し、明確に自分に忠実なAIを装備する必要がある。このようなアイデアはすでに零星なパイロットプロジェクトとして存在している(例:台湾の「メッセージチェッカー」アプリはスマートフォン上でローカルスキャンを行う)。また、詐欺から人々を守るなどの市場ニーズもあり、こうしたアイデアをさらにテストできる自然な市場もあるが、この分野にはさらに努力が必要である。
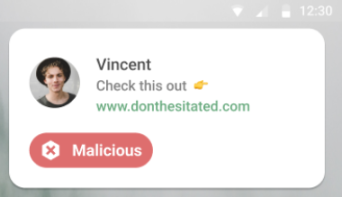
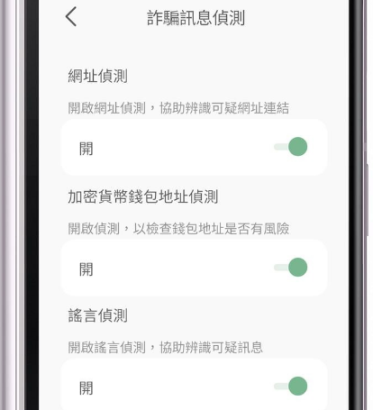
上から下へ:URLチェック、暗号通貨アドレスチェック、デマチェック。こうしたアプリは、よりパーソナライズされ、ユーザー主体的かつ機能豊かになっていくことができる。
この戦いは、超知能の超説得者とあなたの対決であってはならない。それは、超知能の超説得者と、あなた+若干劣るがそれでも超知能級の、あなたに奉仕するアナライザーとの戦いであるべきだ。
これが起きるべきことである。しかし、実際に起きるのだろうか? 『AI 2027』シナリオが仮定する短時間内に、情報防御技術を普及させることは非常に困難な目標である。しかし、より穏やかなマイルストーンでも十分だと考える余地はある。集団的決定が最も重要であり、『AI 2027』シナリオが示すようにすべての重要な出来事が一つの選挙期間内に起こるのであれば、厳密には、意思決定者本人(政治家、公務員、企業の一部のプログラマーおよび関係者)が良好な情報防御技術を利用できることが重要なのである。これは短期的には比較的実現しやすく、私の経験則では、こうした多くの人々はすでに複数のAIとやりとりしながら意思決定を補助している習慣を持っている。
示唆
『AI 2027』の世界では、超知能AIが残存する人類を簡単に迅速に抹殺できることが当然視されており、唯一の選択肢は先導するAIが慈悲深いものであることを確保することだと思われている。しかし私の見解では、現実ははるかに複雑である。先導するAIが残存する人類(および他のAI)を簡単に抹殺できるほど強力であるかどうかという問いには、依然として大きな議論の余地があり、そして我々はその結果に影響を与える行動を取ることができる。
これらの論点が正しければ、今日の政策に対する示唆は、時に「主流のAI安全ガイドライン」と一致し、時に異なる。
超知能AIの開発を遅らせるのは、依然として良いことである。超知能AIが3年後ではなく10年後に登場する方が安全であり、30年後であればさらに安全である。人類文明により多くの準備時間を与えることは有益である。
これをどうやって実現するかは難問である。米国で提案された「州レベルのAI規制を10年間禁止する」案が否決されたことは、全体として良いことだったと思う。しかし特にSB-1047のような初期の提案が失敗した後は、次のステップの方向性がやや不明瞭になっている。私の考えでは、リスクの高いAIの開発を遅らせる最も非侵襲的で堅牢な方法は、最先端ハードウェアの使用を規範化する何らかの条約に参加することかもしれない。効果的な防御に必要な多くのハードウェアセキュリティ技術は、国際的なハードウェア条約の検証にも役立つため、ここには相乗効果さえ存在する。
ただし、リスクの主な源は軍事関連の主体であり、彼らはこうした条約からの免除を強く求めると私は考えている。これは決して許されるべきではなく、もし最終的に彼らが免除を得れば、軍事部門主導のAI開発がリスクを高める可能性がある。
AIが善を行う可能性を高め、悪を行う可能性を減らすための調整努力は、依然として有益である。主な例外(そして常にそうであった)は、調整が最終的に能力向上に結びつく場合である。
AIラボの透明性を高める規制も依然として有益である。AIラボに健全な行動を促すインセンティブを与えることでリスクを低下させることができ、透明性はそのための良い手段である。
「オープンソースは有害」という考え方のリスクが高まる。多くの人々は、防御が非現実的であるため、唯一の光明は善意を持つ者が悪意の薄い者よりも先に超知能AIを達成し、極めて危険な能力を先行して得ることだと主張して、オープンウェイトAIに反対している。しかし、本稿の論点は異なる風景を描いている。防御が非現実的なのは、ある主体が他よりもはるかに先行しており、他の主体が追いつけないからである。技術の拡散により力の均衡を保つことが重要になる。しかし同時に、先端AI能力の成長を加速することが、オープンソースであるという理由だけで良いことだと私は決して考えていない。
米国のラボにおける「中国に勝たなければならない」というメンタリティも、同様の理由でリスクが高まる。もし覇権が安全の緩衝材ではなくリスクの源であるなら、(不幸にもあまりに一般的な)「善意を持つ者が先導AIラボに加わり、より早く勝利するのを助けるべきだ」という主張はさらに否定されることになる。
「パブリックAI」のようなイニシアチブは、さらに支援されるべきである。AI能力の広範な分散を確保すると同時に、インフラ主体が実際に本稿で述べたような方法で新しいAI能力を迅速に活用できるツールを持つようにするためである。
防御技術は、「すべての狼を狩る」よりも「武装した羊」の理念により多く反映されるべきである。脆弱な世界仮説に関する議論では、唯一の解決策として覇権国家がグローバル監視を行い、あらゆる潜在的脅威の出現を防ぐしかないという前提がよく置かれる。しかし非覇権的世界ではこれは現実的ではなく、上から下への防御メカニズムは強力なAIによって簡単に攻撃ツールに転用されてしまう。したがって、世界の脆弱性を低下させるには、地道な努力を通じてより大きな防御責任を実現する必要がある。
上記の論点はすべて推測にすぎず、これらの論点がほぼ確実であると仮定して行動すべきではない。しかし『AI 2027』の物語もまた推測的であり、「その具体的な詳細がほぼ確実である」と仮定して行動することを避けるべきである。
特に懸念されるのは、「AI覇権を確立し、『同盟』させ、『競争に勝つ』ことが前進する唯一の道である」という一般的な仮定である。私の見解では、この戦略は特に覇権が軍事的応用と深く結びついている場合には、むしろ安全性を低下させる可能性が高い。多くの同盟戦略の有効性が大きく損なわれるだろう。一度覇権AIが逸脱すれば、人類はすべてのバランス手段を失ってしまう。
『AI 2027』シナリオでは、人類の成功は、米国が決定的な瞬間に破滅ではなく安全の道を選ぶことにかかっている――自発的にAIの進展を遅らせ、Agent-5の内部思考過程を人間が解釈可能にするのである。それにもかかわらず、成功は保証されておらず、人類が単一の超知能の思考に依存する継続的な生存の崖からどのように脱却するかも不明瞭である。今後5~10年間のAIのいかなる進展においても、「世界の脆弱性を低下させることは可能である」と認め、人類の最新技術を用いてその目標を達成するためにより多くの精力を注ぐことは、試み worth する道である。
特にBalviのボランティアによるフィードバックと校閲に感謝する。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News













