

Cryptoはお金の稼ぎ方やストーリーテリング以外に、AIのために何ができるのか?
TechFlow厳選深潮セレクト
Cryptoはお金の稼ぎ方やストーリーテリング以外に、AIのために何ができるのか?
AI分野には、暗号技術によって解決可能な根本的な問題が数多く存在する。
翻訳:TechFlow
Curve Financeの創設者@newmichwillは最近、暗号通貨の主な目的はDeFi(分散型金融)にあり、AI(人工知能)にはそもそも暗号通貨が必要ないとの見解をツイートしました。確かにDeFiが暗号分野において重要な構成要素であることに同意しますが、一方でAIに暗号通貨が不要だという主張には賛同できません。
AIエージェント(AI agents)の台頭とともに、多くのエージェントがトークンを付随させるため、人々はついつい暗号とAIの交差点とは単にこれらのAIエージェントのことだと誤解してしまいます。しかし、もう一つ注目すべき重要なテーマ、「分散型AI(Decentralized AI)」が見過ごされています。これはAIモデル自体のトレーニングと深く関係しています。
私がいくつかのナラティブに対して抱く不満は、大多数のユーザーが何かが流行っているからといって、それを必然的に重要かつ有用なものだと盲信してしまう点です。さらに悪いことに、彼らはこうしたナラティブの唯一の目的が可能な限り価値を搾取すること(つまり、お金を稼ぐこと)だと考えていることです。
分散型AIについて議論する際、まず自問すべきです。「なぜAIは分散化を必要とするのか?」「その結果として何がもたらされるのか?」
実際、分散化という概念はほぼ常に「インセンティブの一致(Incentive Alignment)」というアイデアと避けがたく結びついています。
AI分野には、暗号技術によって解決可能な根本的な課題が多数存在します。さらに、既存の問題を解決するだけでなく、AIにさらなる信頼性を与えるメカニズムさえあります。
では、なぜAIは暗号通貨を必要とするのでしょうか?
1. 高昂な計算コストが参加と革新を制限している
幸か不幸か、大規模なAIモデルは膨大な計算リソースを必要とし、これは自然と多くの潜在的利用者の参加を制限します。ほとんどの場合、AIモデルは大量のデータリソースと実際の計算能力を必要とし、個人にとってはこれらを負担するのは事実上不可能です。
この問題は特にオープンソース開発において顕著です。貢献者はモデルのトレーニングに時間を費やすだけでなく、計算リソースも投入しなければならず、これによりオープンソース開発の効率が低下します。
確かに、個人がAIモデルを動かすために大量のリソースを投入することは可能であり、ちょうどユーザーが自身のブロックチェーンノードを運営するために計算リソースを割り当てるのと同じです。
しかし、それでも根本的な解決にはなりません。なぜなら、その算力ではタスクを完了するには不十分だからです。
LLaMAのような大規模AIモデルの開発に独立系開発者や研究者が参加できないのは、モデルのトレーニングに必要な計算コスト(数千ものGPU、データセンター、追加のインフラなど)を負担できないからです。
以下は規模感を示すいくつかのデータです:
→ エロン・マスク氏は、最新のGrok 3モデルのトレーニングに10万枚のNvidia H100 GPUを使用したと述べています。
→ 各チップの価格は約3万ドル。
→ Grok 3のトレーニングに使用されたAIチップの総コストは約30億ドル。
この問題はスタートアップの立ち上げプロセスに似ており、個人は時間、技術力、実行プランを持っていても、最初にビジョンを実現するための十分なリソースを持っていないという状況です。
@dbarabanderが指摘したように、従来のオープンソースソフトウェアプロジェクトでは貢献者が時間だけを寄付すればよかったのに対し、オープンソースAIプロジェクトでは時間に加えて算力やデータといった大量のリソースが必要になります。
善意やボランティア精神だけでは、このような高額なリソースを提供する個人や団体を十分に動機づけることはできません。参加を促進するには、追加のインセンティブメカニズムが不可欠です。
2. 暗号技術はインセンティブの一致を実現する最適なツール
「インセンティブの一致」とは、システムへの貢献を通じて参加者が自身の利益も得られるようルールを設計することで、双方の利害を一致させる仕組みです。
異なるシステムにおけるインセンティブの一致を支援する上で、暗号技術には数え切れないほどの成功事例があります。特に顕著なのは、分散型物理インフラネットワーク(DePIN)業界で、この理念に完璧に適合しています。
たとえば、@heliumや@rendernetworkのようなプロジェクトは、分散ノードおよびGPUネットワークを通じてインセンティブの一致を達成し、模範例となっています。
それならば、なぜこのモデルをAI分野にも適用して、エコシステムをより開放的かつアクセス可能にできないのでしょうか?
実は、それは可能です。
Web3および暗号技術の発展を推進する中心にあるのは「所有権(Ownership)」です。
あなたは自分のデータを所有し、自分のインセンティブを所有し、特定のトークンを保有することでネットワークの一部を所有できます。リソース提供者に所有権を与えることで、彼らが資産をプロジェクトに提供するインセンティブが生まれ、ネットワークの成功からリターンを得ることを期待できるのです。
AIをより普及させるには、暗号技術が最適解です。開発者はプロジェクト間で自由にモデル設計を共有でき、計算およびデータ提供者はリソースの提供と引き換えに所有権の割合(インセンティブ)を得られます。
3. インセンティブの一致は検証可能性と密接に関連している
適切なインセンティブの一致を持つ分散型AIシステムを想定する場合、古典的なブロックチェーンメカニズムのいくつかの特性を継承すべきです:
-
ネットワーク効果(Network Effects)。
-
初期要件が低く、ノードは将来の収益によって報酬を得られる。
-
悪意ある行動者を罰するペナルティメカニズム(Slashing Mechanisms)。
特にペナルティメカニズムに関しては、検証可能性(Verifiability)が不可欠です。誰が悪意のある行動をしているかを検証できなければ、罰則を科せません。これは、特に複数チームが協力する状況下で、システムが詐欺行為に極めて脆弱になることを意味します。
分散型AIシステムでは、中央の信頼ポイントがないため、検証可能性が極めて重要です。代わりに、信頼不要だが検証可能なシステムを目指します。以下は検証可能性が求められる主要なコンポーネントです:
-
ベンチマーク段階(Benchmark Phase):特定の指標(x、y、zなど)において他のシステムよりも優れていること。
-
推論段階(Inference Phase):システムが正しく動作しているか、つまりAIの「思考」段階。
-
トレーニング段階(Training Phase):システムが正しくトレーニングまたはチューニングされているか。
-
データ段階(Data Phase):システムがデータを正しく収集しているか。
現在、数百のチームが@eigenlayer上でプロジェクトを構築していますが、最近特にAIに対する関心が高まっていることに気づきました。これが当初の再ステーキング(Restaking)のビジョンと合致しているかどうか、私も考えています。
インセンティブの一致を実現したいAIシステムはすべて、検証可能でなければなりません。
この文脈では、ペナルティメカニズムは検証可能性と等価です。分散型システムが悪意ある行動者を罰することができれば、それはその悪意ある行動を識別・検証できているということです。
システムが検証可能であれば、AIは暗号技術を利用して世界中の計算およびデータリソースにアクセスし、より大きく強力なモデルを構築できます。なぜなら、より多くのリソース(計算+データ)は通常、より良いモデルにつながるからです(少なくとも現在の技術環境では)。
@hyperbolic_labsは、共同計算リソースの可能性をすでに示しています。任意のユーザーがGPUをレンタルし、家庭で実行可能なよりも複雑なAIモデルをより低コストでトレーニングできます。
AIの検証を効率的かつ検証可能にするには?
現在、GPUをレンタルできるクラウドソリューションが多数存在しており、これで計算リソースの問題は解決していると考える人もいるでしょう。
しかし、AWSやGoogle Cloudのようなクラウドソリューションは高度に集中化されており、「待機リスト戦略(Waitlist Strategy)」を用いて人為的に需要が高いように見せかけ、価格を吊り上げています。この現象は、業界の寡占状態でよく見られます。
実際には、データセンター、マイニング施設、さらには個人の手元に、AIモデルのトレーニングに使えるはずの大量のGPUリソースが遊休状態で放置されています。
@getgrass_ioをご存知の方もいるでしょう。これは、ユーザーが未使用の帯域幅を企業に販売し、資源の無駄を防ぎながら報酬を得られるサービスです。
計算リソースが無限にあるとは言いませんが、どんなシステムでも最適化によってウィンウィンを実現できます。一方では、AIモデルのトレーニングにさらにリソースを必要とする人々に、より開放的な市場を提供し、他方では、そのリソースを提供する人々に見返りを与えます。
Hyperbolicチームは、オープンなGPU市場を開発しました。ここではユーザーがAIモデルのトレーニング用にGPUをレンタルでき、最大75%のコスト削減が可能で、GPU提供者は遊休リソースを貨幣化して収益を得られます。
その概要は以下の通りです:
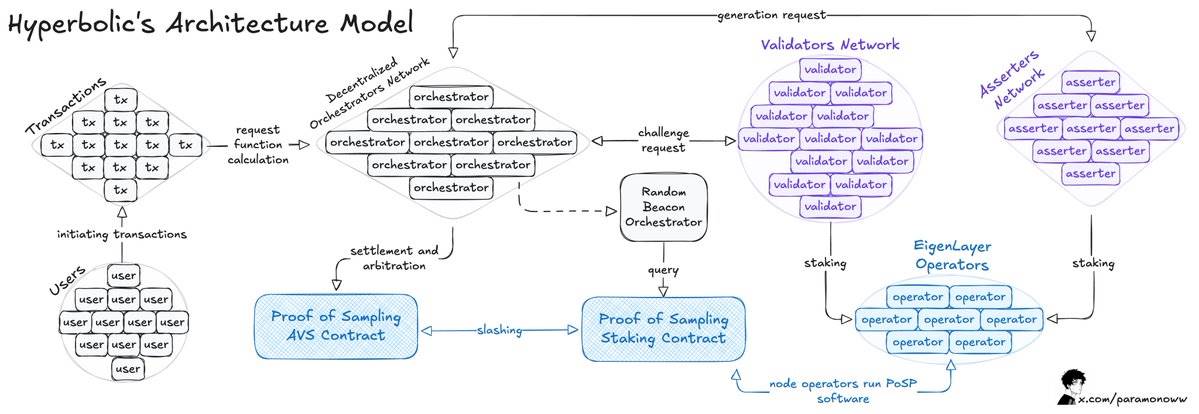
Hyperbolicは接続されたGPUをクラスタとノードに組織化し、需要に応じて計算能力をスケーラブルにします。
このアーキテクチャの核心は「サンプリングの証明(Proof of Sampling)」モデルで、トランザクションをサンプリング処理することで、ワークロードと計算要求を削減します。
大きな問題はAIの推論(Inference)プロセスに生じます。ネットワーク上で行われる各推論は検証されなければならず、他のメカニズムによる顕著な計算オーバーヘッドを避けたいものです。
前述したように、ある行為が検証可能であれば、それが規則違反と判明した場合、必ずペナルティ(Slashing)が科されるべきです。
HyperbolicがAVS(Adaptive Verification System:適応型検証システム)モデルを採用すると、システムにさらなる検証可能性が加わります。このモデルでは、検証者はランダムに選出され、出力結果を検証することで、インセンティブの一致を実現します。このメカニズムのもとでは、不正行為は利益にならないのです。
AIモデルをトレーニングし、より完成度を高めるには、主に二つのリソースが必要です:計算能力とデータ。計算能力のレンタルは一つの解決策ですが、依然としてどこかからデータを入手する必要があります。また、モデルの偏りを避けるためにも、多様なデータが必要です。
複数のソースからのAIデータを検証する
データが多いほどモデルは良くなりますが、通常は多様性のあるデータが必要です。これがAIモデルが直面する主要な課題です。
データプロトコルは数十年にわたり存在しています。データが公開か非公開かに関わらず、データブローカーはそのデータを何らかの形で収集し(支払いをする場合もしない場合もある)、利益を得るために販売しています。
AIモデルに適切なデータを供給する際に直面する問題には、単一障害点、検閲、そしてAIモデルに「供給」する真実で信頼できるデータを提供する信頼不要な方法の欠如があります。
では、誰がこのようなデータを必要としているのでしょうか?
まず第一に、AI研究者や開発者です。彼らは正確かつ適切な入力を通じてモデルのトレーニングと推論を行いたいと考えています。
たとえば、OpenLayerは誰でも許可なくシステムやAIモデルにデータストリームを追加でき、システムが利用可能なすべてのデータを検証可能な方法で記録できます。
OpenLayerはzkTLS(ゼロ知識トランスポート層セキュリティ)も使用しており、これは以前の私の記事で詳しく説明しています。このプロトコルにより、オペレーターが報告するデータが実際にソースから得られたものであることが保証されます(検証可能性)。
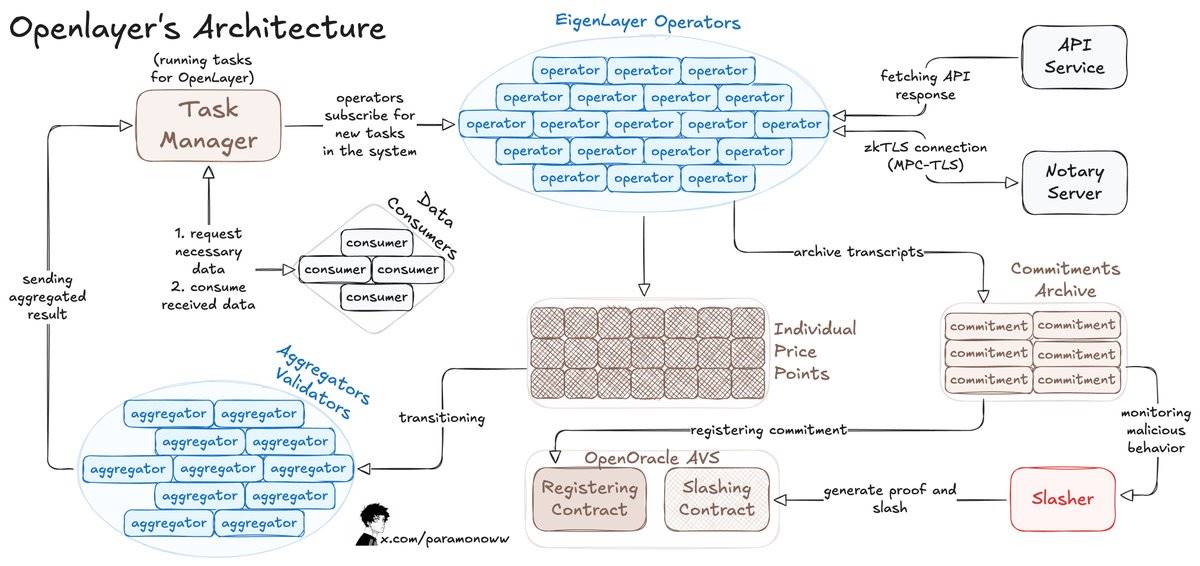
以下はOpenLayerの動作原理です:
-
データ利用者はOpenLayerのスマートコントラクトにデータ要求を投稿し、主要なデータオラクルに類似したAPIを使ってコントラクト(オンチェーンまたはオフチェーン)から結果を取得します。
-
オペレーターはEigenLayerに登録し、OpenLayer AVSのステークを担保として預け、AVSソフトウェアを実行します。
-
オペレーターはタスクをサブスクライブし、データをOpenLayerに処理・提出すると同時に、オリジナルのレスポンスと証明を分散型ストレージに保存します。
-
変動する結果については、アグリゲーター(特殊なオペレーター)が出力を標準化処理します。
開発者は任意のウェブサイトから最新データをリクエストし、それをネットワークに統合できます。AI関連プロジェクトを開発している場合、信頼できるリアルタイムデータを得ることが可能です。
AIの計算プロセスと検証可能なデータの取得方法について考察した後、次に注目すべきはAIモデルの二大核となる部分:計算そのものとその検証です。
AI計算は検証を通じて正しさを確保しなければならない
理想としては、ノードはその計算貢献を証明することで、システムの正常な動作を保証すべきです。
最も悪いケースでは、ノードが計算能力を提供したと虚偽に主張しながら、実際には何もしていない可能性があります。
ノードに貢献の証明を求めることは、正当な参加者だけが認められ、悪意ある行動が防止されることを意味します。このメカニズムは従来のプルーフ・オブ・ワーク(PoW)と非常に似ており、違いはノードが実行する作業の種類だけです。
適切なインセンティブの一致メカニズムをシステムに導入しても、ノードが自身の作業を許可なしに証明できない場合、実際の貢献と合わない報酬を得る可能性があり、報酬の不公平配分を招くかもしれません。
ネットワークが計算貢献を評価できなければ、あるノードに能力を超えるタスクが割り当てられ、他のノードはアイドル状態になるなど、非効率やシステム障害につながる可能性があります。
計算貢献を証明することで、ネットワークはFLOPS(1秒あたりの浮動小数点演算回数)などの標準化された指標で各ノードの努力を定量化できます。これにより、単にネットワークに存在しているかどうかではなく、実際に完了した作業に基づいて報酬を分配できます。
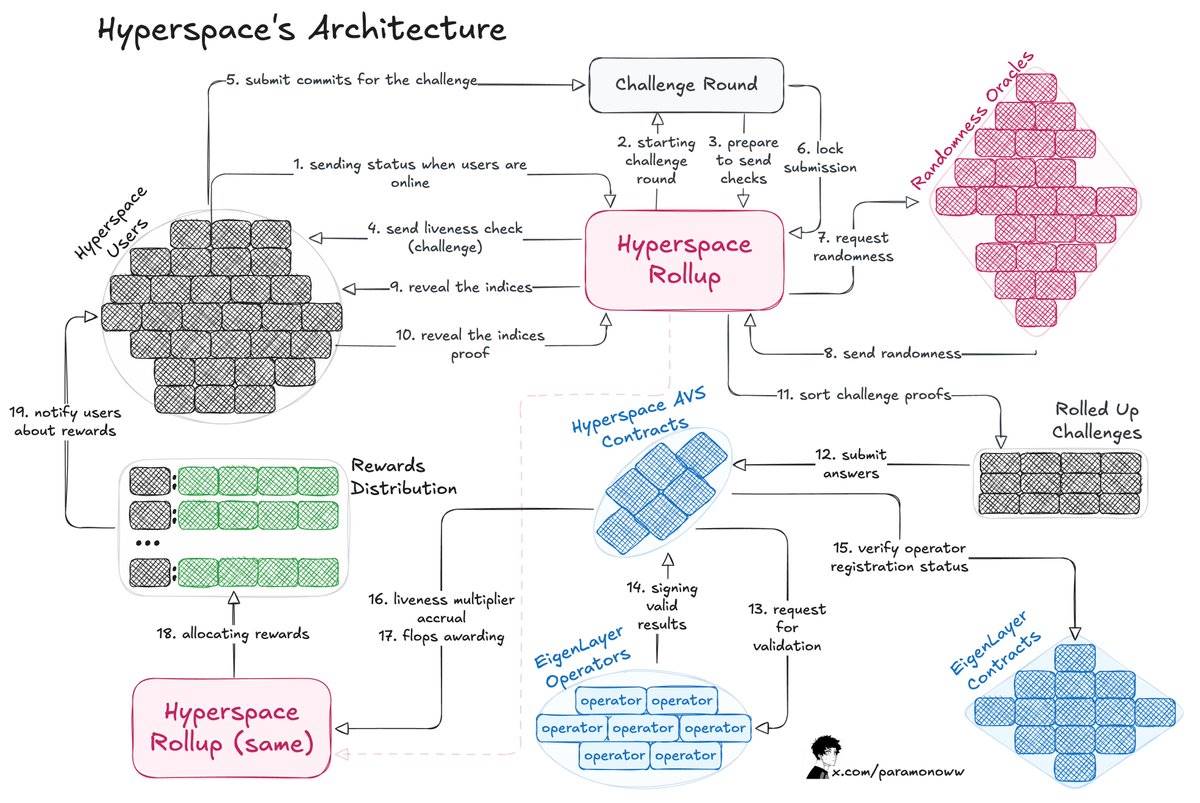
@HyperspaceAIのチームは、「FLOPSの証明(Proof-of-FLOPS)」システムを開発し、未使用の計算能力をレンタルできるようにしました。その見返りとして、「flops」というポイントを受け取り、これがネットワーク内の共通通貨となります。
このアーキテクチャの動作原理は以下の通りです:
-
プロセスはユーザーへのチャレンジ発行から始まり、ユーザーはチャレンジに対するコミットメントを提出して応答します。
-
Hyperspace Rollupがプロセスを管理し、提出の安全性を確保し、オラクルから乱数を取得します。
-
ユーザーがインデックスを公開し、チャレンジプロセスが完了します。
-
オペレーターがレスポンスをチェックし、有効な結果をHyperspace AVSコントラクトに通知し、その後EigenLayerコントラクトで結果を確認します。
-
活性乗数(Liveness Multipliers)を計算し、ユーザーにflopsポイントを付与します。
計算貢献の証明により、各ノードの能力が明確に可視化され、システムはタスクを賢く割り振れます。高性能ノードには複雑なAI計算タスクを、能力の低いノードには軽量なタスクを割り当てられます。
最も興味深いのは、このシステムをいかに検証可能にし、誰もが作業の正しさを証明できるようにするかという点です。HyperspaceのAVSシステムは、上述のアーキテクチャ図のように、継続的にチャレンジと乱数要求を送信し、多層的な検証プロセスを実行します。
オペレーターは結果が検証され、報酬が公正に分配されるため、安心してシステムに参加できます。結果が正しくなければ、悪意ある行動者には疑いなくペナルティ(Slashing)が科されます。
AI計算結果の検証には多くの重要な理由があります:
-
ノードが参加し、リソースを貢献するよう促進する。
-
努力に応じて報酬を公平に分配する。
-
貢献が特定のAIモデルを直接支援していることを保証する。
-
ノードの検証能力に基づいてタスクを効果的に割り当てる。
AIの分散化と検証可能性
@yb_effectが指摘したように、「分散型(Decentralized)」と「分散(Distributed)」はまったく異なる概念です。後者はハードウェアが異なる場所に配置されていることを意味しますが、依然として中心的な接続点が存在します。
一方、「分散型」とは単一のマスターノードがなく、トレーニングプロセスが障害を処理できることを意味し、これは今日の多くのブロックチェーンの動作方式と似ています。
AIネットワークが真に分散化されるためには、複数のソリューションが必要ですが、ほぼ確実に言えるのは、あらゆるものを検証する必要があるということです。
AIモデルやエージェントを構築する場合は、すべてのコンポーネントおよび依存関係が検証されていることを確認する必要があります。
推論、トレーニング、データ、オラクル――これらすべてを検証可能にすることで、インセンティブと整合した暗号報酬をAIシステムに導入できるだけでなく、システムをより公平かつ効率的にすることができます。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News









