

DeepSeekを追跡する:なぜDeepSeekは職務経歴のない若者を好むのか?
TechFlow厳選深潮セレクト
DeepSeekを追跡する:なぜDeepSeekは職務経歴のない若者を好むのか?
職歴がなくても、DeepSeekが人材を選ぶ方法は?答えは、ポテンシャルを見るということだ。
著者:Sam Gao、ElizaOSの作者
0. はじめに
ここ最近、DeepSeek V3、R1が相次いで登場し、アメリカのAI研究者や起業家、投資家の間でFOMO(恐怖による過剰購入)が起きている。この盛り上がりは、2022年末にChatGPTが登場した時と同様に驚くべきものだ。

DeepSeek R1はHuggingFace上でモデルを無料ダウンロード可能という完全なオープンソース化と、極めて低価格なコスト(OpenAI o1の1/100)を武器に、わずか5日間で米国Apple AppStoreのランキング1位を獲得した。
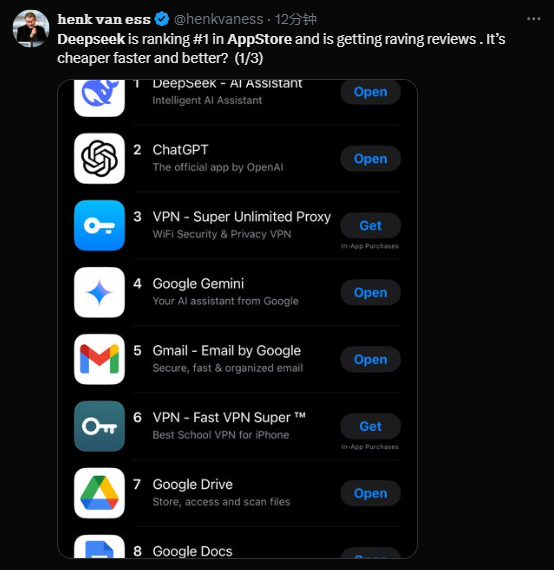
では、中国のクオンツ企業から生まれたこの謎めいたAI新興勢力「DeepSeek」は、一体どこから来たのだろうか?
1. DeepSeekの起源
私が初めてDeepSeekの存在を知ったのは2021年のことだった。当時、ダマオ院(アリババ傘下の研究所)に勤務していた私は、隣のチームにいた天才的な女性、北大修士課程出身で1年間に8本のACL(自然言語処理のトップカンファレンス)論文を発表した羅福莉さんが、幻方量化(High-Flyer Quant)へ移籍したと聞いていた。高収益を上げるクオンツ会社がなぜAI人材を採用するのか——皆、非常に疑問に思っていた。「まさか幻方も論文を出さなければならないのか?」と。
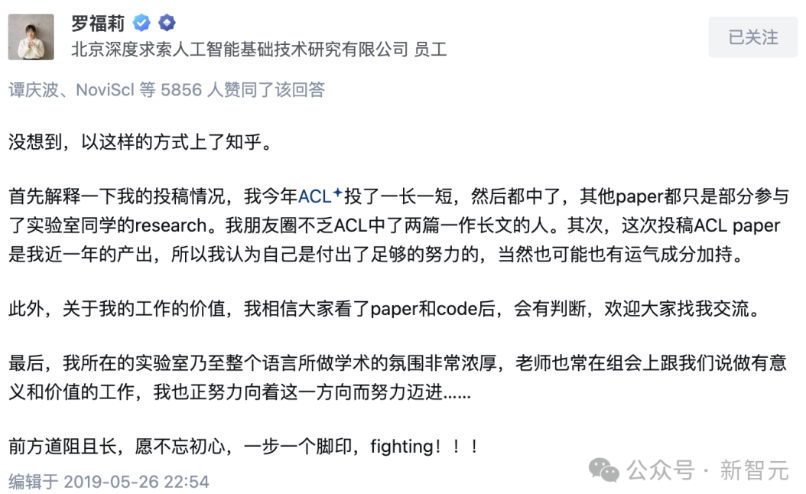
当時私の知る限り、幻方が採用したAI研究者はそれぞれ独自の最前線分野を探求しており、その中でも特に注力していたのが大規模言語モデル(LLM)およびテキストから画像を生成するモデル(当時のOpenAI DALL-Eなど)関連の研究だった。
時は流れ、2022年末になると、幻方はますます多くのトップクラスのAI人材(ほとんどが清華大学や北京大学の在学生)を吸収し始めた。ChatGPTの登場がきっかけとなり、長年にわたりAI分野で蓄積を重ねてきた幻方のCEO、梁文峰氏はついに決断する。「新しい会社を設立し、言語モデルから始め、その後には視覚モデルなども展開していく」と。
そう、その会社こそがDeepSeekである。2023年初頭、智譜、月之暗面、百川智能などいわゆる「六小龙」と呼ばれる企業たちが次々と注目を集める中、北京の中関村や五道口といった賑やかな地域の中で、DeepSeekの存在感はこれらの資金豊富なライバルたちに大きく覆い隠されてしまった。
そのため、2023年当時、スター創業者が不在の純粋な研究機関であったDeepSeek(例:李開復の零一万物、楊植麟の月之暗面、王小川の百川智能などとは異なり)は、市場から単独で資金調達を行うことが困難だった。そこで幻方は、DeepSeekを独立させ、全額出資して開発を支援することを決定した。2023年というバブル的時代において、VC(ベンチャーキャピタル)はDeepSeekへの投資を避けた。理由は二つある。第一に、DeepSeekのメンバーはほとんどが新卒の博士号取得者であり、著名なトップ研究者がいなかったこと。第二に、出口戦略(エグジット)が見通せない状況だったことだ。
騒がしく浮ついた環境の中、DeepSeekは着実にAI探求の物語を紡ぎ続けてきた。
-
2023年11月、670億パラメータを備えたDeepSeek LLMをリリース。その性能はGPT-4に迫るものだった。
-
2024年5月、DeepSeek-V2が正式にリリース。
-
2024年12月、DeepSeek-V3が発表。ベンチマークテストではLlama 3.1やQwen 2.5を上回り、GPT-4oおよびClaude 3.5 Sonnetと同等の性能を示し、業界の注目を一気に集めた。
-
2025年1月、初の推論能力を持つ大規模モデル「DeepSeek-R1」が登場。OpenAI o1の1/100以下の価格と卓越した性能により、世界中のテック業界に衝撃を与えた。「ようやく中国の力が本格的に現れたのだ… オープンソースこそが常に勝つ!」
2. 人材戦略
私は初期の段階からいくつかのDeepSeek研究員と知り合っており、特にAIGC分野の研究者たちだ。例えば2024年11月に発表されたJanusの作者やDreamCraft3Dの作者、また最新の論文の最適化を手伝ってくれた@xingchaoliu氏もいる。

私の観察によると、私が知る研究員たちは非常に若く、ほとんどが在学中の博士課程学生か、卒業後3年以内の人たちだ。


彼らの多くは北京で修士または博士課程を修めており、学術的に非常に優れた実績を持っている。特に、3〜5本のトップカンファレンス論文を発表している研究者が多数を占める。
私はDeepSeekの関係者に、「なぜ梁文峰氏は若手ばかりを採用するのか?」と尋ねたことがある。
すると、彼らは幻方CEO・梁文峰氏の言葉を教えてくれた。
DeepSeekチームの正体は未解明のままだが、その秘密兵器とは何か?海外メディアはこう報じている。「その秘密兵器とは『若い天才』であり、彼らこそが財力に恵まれたアメリカの大手企業と肩を並べて競争できる存在なのだ」
AI業界では経験豊富なベテランを起用することが一般的であり、多くの中国国内AIスタートアップも海外博士号保持者や资深研究者を好んで採用している。しかし、DeepSeekは逆を行き、職歴のない若手を積極的に採用している。
かつてDeepSeekと協力したヘッドハンターによれば、「DeepSeekは資深技術者を採用しない。3〜5年の経験が上限で、8年以上の経験者はほぼ確実に不採用になる」とのこと。梁文峰氏自身も2023年5月に36Krのインタビューで、「DeepSeekの開発者の多くは新卒か、AI業界でのキャリアを始めたばかりの人物だ」と述べており、「当社のコア技術ポジションの多くは、新卒あるいは1〜2年の経験しかない人材が担っている」と強調している。
職歴がない若手をどうやって選んでいるのか?答えは「潜在能力」を見るということだ。
梁文峰氏はこう語っている。「長期的なプロジェクトにおいては、経験よりも基礎的能力、創造性、情熱の方がはるかに重要だ」。彼は言う。「現在、世界トップ50のAI人材が中国にいないかもしれない。だが、我々は自らそれらの人材を育てることができる」。
この戦略は、OpenAIの初期戦略を彷彿とさせる。OpenAIが2015年末に設立された際、Sam Altmanの核心的考えは「野心ある若手研究者を集める」ことだった。そのため、代表のGreg BrockmanとチーフサイエンティストのIlya Sutskever以外の4人の主要技術創設メンバー(Andrew Karpathy、Durk Kingma、John Schulman、Wojciech Zaremba)はすべて新卒の博士号取得者であり、それぞれスタンフォード大学、アムステルダム大学、カリフォルニア大学バークレー校、ニューヨーク大学出身だった。

左から右へ:Ilya Sutskever(元チーフサイエンティスト)、Greg Brockman(元代表)、Andrej Karpathy(元技術責任者)、Durk Kingma(元研究員)、John Schulman(元強化学習チームリーダー)、Wojciech Zaremba(現技術責任者)
この「幼狼戦略(young wolf strategy)」によって、OpenAIは大きな成果を得た。GPTの父と称されるAlec Radford(いわゆる三流大学卒)、文生画像モデルDALL-Eの父Aditya Ramesh(NYU学部生)、そしてGPT-4oのマルチモーダル担当で三度のオリンピック金メダリストPrafulla Dhariwalなどが育ち、当初は目標も曖昧だったOpenAIが、若手たちの突進によって新たな道を切り拓き、DeepMindの影にいた無名の存在から巨象へと成長したのである。
梁文峰氏は、まさにSam Altmanのこの成功事例を見て、自らもこの道を歩むことを決めた。ただし、OpenAIがChatGPTの登場まで7年待ったのに対し、梁文峰氏の投資は2年余りで実を結び、まさに「中国スピード」と呼ぶにふさわしい成果をあげた。
3. DeepSeekを擁護して
DeepSeek R1に関する論文では、その指標が驚異的なまでの優秀さを見せている。しかしそれゆえに、懐疑の声も上がっている。主に二つの疑問点がある。
-
① 採用しているExpert-Mixture(MoE)技術は訓練負荷とデータ量の要求が非常に高い。このため、一部ではDeepSeekがOpenAIのデータを使って訓練しているのではないかという疑念が提起されている。
-
② 強化学習(RL)による強化学習技術を用いているが、これはハードウェア要件が高く、MetaやOpenAIの万枚GPUクラスタと比較すると、DeepSeekはわずか2048枚のH800を使用しただけである。
計算リソースの制限とMoEの複雑性を考えると、500万ドルで一発成功したというDeepSeek R1の話は確かに怪しく見える。しかし、あなたがR1に対して「低コストの奇跡」と崇拝しようとも、「実用性に乏しい」と疑問視しようとも、その機能的革新性の輝きを否定することはできない。
BitMEX共同設立者Arthur Hayes氏は投稿でこう述べている:「DeepSeekの台頭は、グローバル投資家がアメリカ例外主義を見直すきっかけになるだろうか? アメリカ資産の価値は過大評価されていないか?」
スタンフォード大学教授の呉恩達(Andrew Ng)氏は、今年のダボス会議で公にこう語った。「DeepSeekの進展には非常に感銘を受けました。彼らは非常に経済的な方法でモデルを訓練できている。最新の推論モデルは非常に優れている……『頑張れ!』」
A16zの創設者Marc Andreessen氏は、「Deepseek R1は私がこれまでに見た中で最も驚嘆すべき、最も印象的なブレイクスルーの一つだ。そしてそれがオープンソースとして公開されたことは、世界への深い贈り物である」と称賛した。
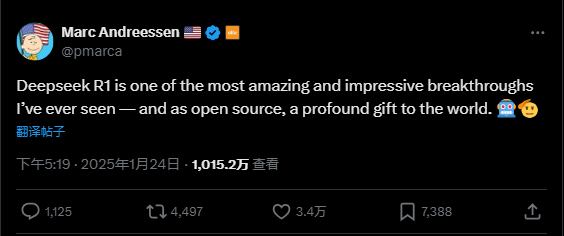
2023年、舞台の隅に控えていたDeepSeekは、ついに2025年、旧正月を前にして、世界AIの頂点に立った。
4. ArgoとDeepSeek
Argoの技術開発者兼AIGC研究者として、私はArgoの重要な機能をDeepSeek化している。ワークフロー(workflow)システムにおいて、粗い初期段階のワークフロー生成はすでにDeepSeek R1によって行われている。さらに、ArgoはLLMを標準としてDeepSeek R1を内蔵し、高価でクローズドソースなOpenAIモデルの使用をあえて放棄した。理由は、ワークフローシステムは通常大量のトークン消費とコンテキスト情報(平均>=10kトークン)を伴うため、高価なOpenAIやClaude 3.5を利用すると実行コストが非常に高くなる。Web3ユーザーが真の価値を享受する以前にこのような先行支出を行うことは、製品にとって害悪であると考えたからだ。
今後、DeepSeekの性能がさらに向上するにつれ、ArgoはDeepSeekを代表とする中国勢との連携をより緊密にしていく予定だ。これには、Text2Image/Videoインターフェースの中国化、LLMの中国化などが含まれる。
協力面では、今後ArgoはDeepSeekの研究員を招いて技術成果の共有セッションを開催し、トップAI研究者に対してgrants(助成金)を提供することで、Web3投資家やユーザーがAIの進展を理解するサポートを行っていく。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














