

NVIDIAを見逃したなら、今度はCrypto AIを見逃すな
TechFlow厳選深潮セレクト
NVIDIAを見逃したなら、今度はCrypto AIを見逃すな
我々は今、イノベーションの爆発的進展のさきばりに立っている。
著者:Teng Yan
翻訳:TechFlow

おはようございます。ついに来ました。
この論文全体の内容は非常に濃いため、読者の皆様が理解しやすく(かつメールサービスのサイズ制限を超えないように)するために、今後1か月かけていくつかのパートに分けて段階的に共有することにしました。では、始めましょう!
私がずっと忘れられない大きな機会損失があります。
今でも胸に引っかかっているのは、市場を注視していれば誰もが気づける明らかなチャンスだったにもかかわらず、私は一銭も投資しなかったことです。
いいえ、次のSolana殺しでもなければ、バカげた帽子を被った犬のミームコインでもありません。
それは……NVIDIAです。
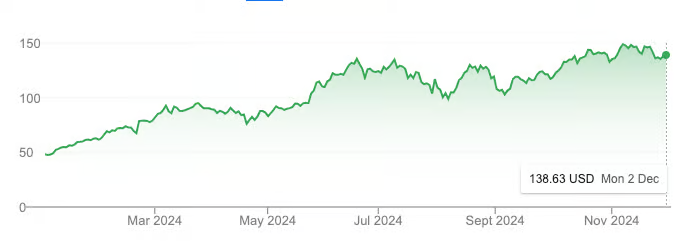
NVDA 年初来株価推移。出典:Google
わずか1年間で、NVIDIAの時価総額は1兆ドルから3兆ドルへと急騰し、株価は3倍になりました。これは同じ期間におけるビットコインのパフォーマンスさえ上回っています。
確かに、その一部はAIブームによるものですが、それ以上に重要なのは、こうした成長には現実的な基盤があるということです。NVIDIAは2024年度の売上高を600億ドルにまで伸ばしており、2023年比で126%の成長を記録しています。この驚異的な成長の裏には、大手テック企業がAGI(汎用人工知能)開発競争で優位に立つために、GPUを必死に買い求めている実態があります。
なぜ私は見逃してしまったのか?
過去2年間、私の関心は完全に暗号資産(クリプト)領域に集中しており、AI分野の動向からは目を背けていました。これは大きな過ちであり、今でも悔やんでいます。
しかし今回は、同じ間違いを繰り返すつもりはありません。
今日のCrypto AIは、どこか見覚えのある感覚を与えてくれます。
私たちはまさに革新が爆発する直前にいます。これは19世紀半ばのカリフォルニア・ゴールドラッシュと驚くほど似ており、業界と都市が一夜にして台頭し、インフラが急速に整備され、リスクを取った人々が巨万の富を得るのです。
初期のNVIDIAと同じように、将来振り返ったときにCrypto AIも「なぜもっと早く気づかなかったのか」と感じるほど明白なものになるでしょう。
Crypto AI:無限の可能性を持つ投資機会
私の論文第1部では、Crypto AIが投資家や開発者にとって最もエキサイティングな潜在的機会である理由を説明しました。主なポイントは以下の通りです:
-
多くの人々はまだこれを「空中楼閣」と見なしている。
-
Crypto AIは現在初期段階にあり、過熱期まではあと1〜2年あるかもしれない。
-
この分野には少なくとも2300億ドルの成長余地がある。
Crypto AIの本質は、人工知能と暗号資産インフラの統合にあります。これにより、より広範な暗号資産市場ではなく、AIの指数関数的成長軌道に沿って進む可能性が高まります。そのため先んじて行動するには、Arxiv上の最新AI研究を追いかけ、次世代の大規模プロジェクトを作ろうとしている創業者たちと対話することが必要です。
Crypto AIの4つの主要分野
本稿の第2部では、Crypto AIの中で特に有望な4つのサブセクターについて焦点を当てます:
-
分散型コンピューティング:モデル学習、推論、およびGPU取引市場
-
データネットワーク
-
検証可能なAI
-
ブロックチェーン上で動作するAIエージェント
この記事は、数週間にわたる徹底的な調査と、Crypto AI分野の創業者・チームとの交流から生まれたものです。各分野の詳細分析というよりは、好奇心を喚起し、研究の方向性を最適化し、投資判断を導くためのハイレベルなロードマップです。
Crypto AIエコシステムの青写真
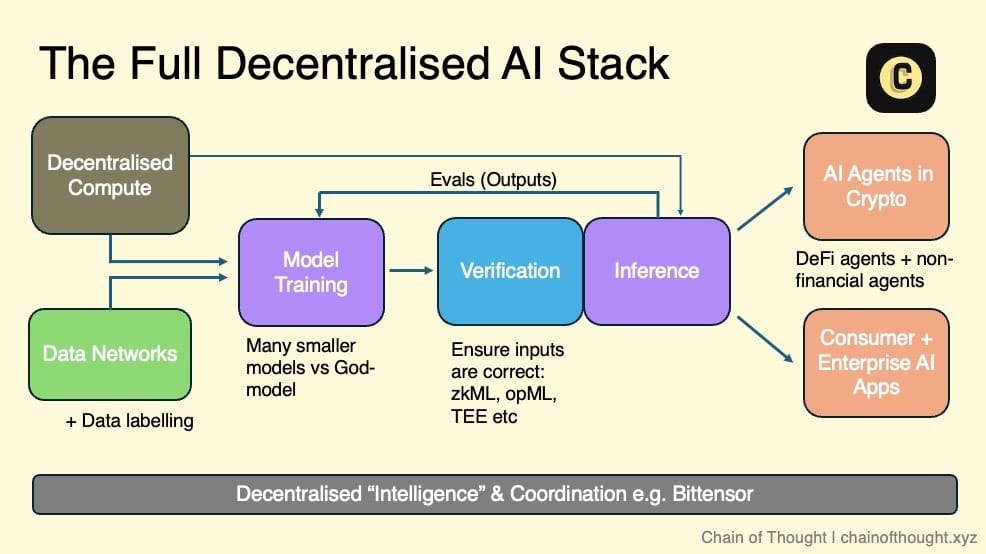
私は分散型AIエコシステムを階層構造だとイメージしています。一端には分散型コンピューティングとオープンデータネットワークがあり、これらが分散型AIモデルの学習基盤を提供します。
すべての推論(inference)の入力と出力は、暗号技術、暗号経済インセンティブ、評価ネットワークによって検証されます。これらの検証済み結果は、チェーン上で自律的に動作するAIエージェントや、ユーザーが信頼できるコンシューマー・エンタープライズ向けAIアプリケーションへと流れていきます。
調整ネットワークはエコシステム全体を接続し、シームレスなコミュニケーションと協働を可能にします。
このビジョンにおいて、AI開発を行うすべてのチームは自らのニーズに応じて、エコシステムの1つまたは複数のレイヤーに参加できます。分散型コンピューティングを利用してモデルを学習するもよし、評価ネットワークを通じて高品質な出力を保証するもよし、多様な選択肢が存在します。
ブロックチェーンの合成性(composability)のおかげで、我々はモジュラー化された未来に向かっていると信じています。各レイヤーは高度に専門化され、オールインワンソリューションではなく、特定機能に特化したプロトコルが登場するでしょう。
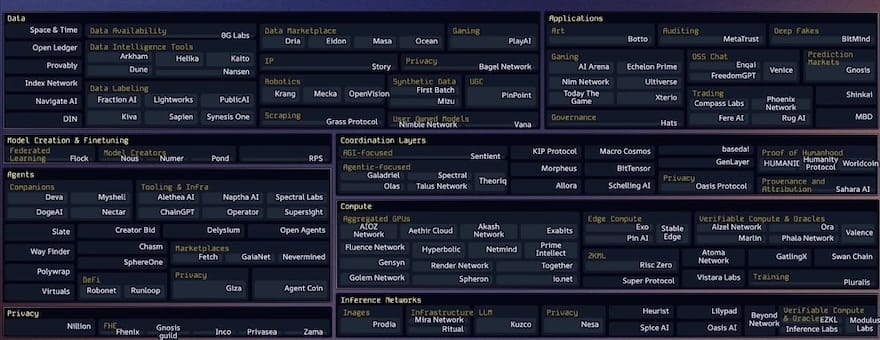
近年、分散型AI技術スタックの各層には多数のスタートアップが誕生しており、「カンブリア爆発」のような成長を見せています。そのほとんどが設立からわずか1〜3年しか経っていません。つまり、我々は依然としてこの業界の初期段階にあるということです。
私がこれまで目にしたCrypto AIスタートアップのエコシステム図の中でも、topology.vcのCasey氏とそのチームが管理しているものが最も包括的かつ最新です。この分野の動向を追うすべての人にとって欠かせないリソースです。
私がCrypto AIの各サブセクターを深掘りする際、いつも問うのは「ここにどれほどの機会があるのか?」ということです。私は小規模市場ではなく、数千億ドル規模に拡大可能な巨大な機会に注目しています。
-
市場規模
市場規模を評価する際、私は次のように自問します。「このサブセクターはまったく新しい市場を創造しているのか、それとも既存市場を破壊しているのか?」
例えば分散型コンピューティングは典型的な破壊的分野です。その潜在力を既存のクラウドコンピューティング市場から推定できます。現在、クラウドコンピューティング市場は約6800億ドル規模で、2032年までに2.5兆ドルに達すると予測されています。
一方、AIエージェントのようなまったく新しい市場は定量的に測るのが難しいです。歴史的データが不足しているため、問題解決能力に対する直感と合理的な推測に頼らざるを得ません。ただし注意すべきは、一見新しい市場に見える製品が、実は「問題を探して解決策を押し付けている」だけの場合もあることです。
-
タイミング
タイミングは成功の鍵です。技術は時間とともに進歩し、安価になっていきますが、分野ごとにその進化速度には大きな差があります。
あるサブセクターの技術的成熟度はどうか? すでに大規模展開可能なほど成熟しているのか、それとも研究段階にあり、実用化まで数年かかるのか? この点が、その分野に即座に注力すべきか、あるいはしばらく様子を見るべきかを決定づけます。
完全準同型暗号(FHE)を例に挙げると、そのポテンシャルは疑いようがありませんが、現在の技術性能は依然として遅すぎて大規模利用は困難です。主流市場への浸透にはまだ数年かかるかもしれません。そのため私は、技術が大規模展開に近づいている分野を優先し、勢いをつけつつある機会に時間とエネルギーを集中させます。
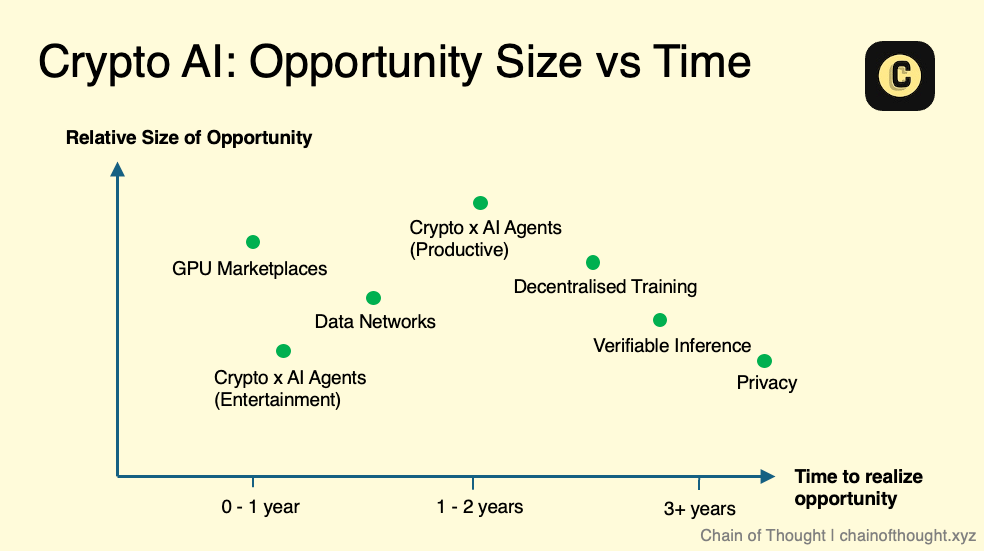
これらのサブセクターを「市場規模 vs タイミング」のグラフにプロットすると、おそらくこのような配置になるでしょう。ただし、これは厳密なガイドラインではなく概念的なスケッチであることに注意してください。各分野内部にも複雑さがあります。たとえば検証可能な推論(verifiable inference)においても、zkMLやopMLといった異なる手法は技術的成熟度が異なります。
それでも私は確信しています。AIの未来は極めて巨大であり、現在「ニッチ」に見える分野でも、将来的には重要な市場に成長する可能性があるのです。
同時に、技術進歩は常に線形に進むわけではないことも認識しておく必要があります。むしろ飛躍的に進むことが多いのです。新たな技術的ブレークスルーが現れれば、市場のタイミングと規模に関する私の見方も変わるでしょう。
以上の枠組みに基づき、これからCrypto AIの各サブセクターを一つずつ分解し、その成長可能性と投資機会を探っていきます。
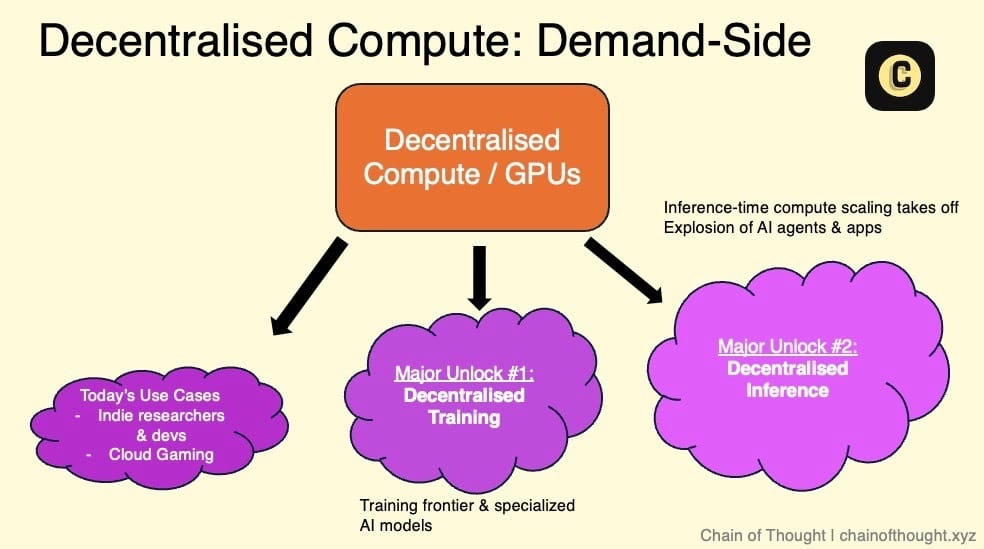
分野1:分散型コンピューティング
要約
-
分散型コンピューティングは、分散型AI全体の中心的支柱である。
-
GPU市場、分散型学習、分散型推論は互いに密接に関連し、連携して発展している。
-
供給側の主な源は中小規模のデータセンターと一般消費者のGPUデバイスである。
-
需要側は現在規模が小さいが徐々に増加しており、主にコストに敏感で遅延要求が低いユーザー、および小規模なAIスタートアップが含まれる。
-
現在のWeb3 GPU市場が直面する最大の課題は、これらのネットワークを実際に効率的に稼働させることである。
-
分散型ネットワーク内でGPUの使用を調整するには、高度な工学的スキルと堅牢なネットワークアーキテクチャ設計が必要である。
1.1 GPU市場/計算ネットワーク
現在、いくつかのCrypto AIチームが、グローバルに未活用のまま眠っている計算リソースプールを活用し、GPU需要が供給を大幅に上回る状況に対処しようとしています。
これらのGPU市場のコアバリューは以下3点に集約されます:
-
AWSに比べて最大90%の計算コスト削減が可能。この低コストは仲介業者の排除と供給源の開放から生まれ、ユーザーは世界中で最も低い限界コストの計算リソースにアクセスできる。
-
長期契約不要、本人確認(KYC)不要、承認待ち不要。
-
検閲耐性
市場の供給側を解決するために、これらの市場は以下のソースから計算リソースを獲得しています:
-
企業用GPU:A100やH100などの高性能GPU。通常は中小規模のデータセンター(独立運営では十分な顧客を得にくい)や、収益源の多様化を目指すビットコインマイナーが提供。また、政府助成による大規模インフラプロジェクトで建設された大量のデータセンターも供給源の一つ。こうしたプロバイダーはトークン報酬により、GPUを継続的にネットワークに接続するインセンティブを持ち、設備の減価償却費を相殺できる。
-
消費者用GPU:何百万ものゲーマーや家庭ユーザーがPCをネットワークに接続し、トークン報酬を得ている。
現在、分散型コンピューティングの需要側には主に以下のユーザーがいます:
-
価格に敏感で遅延要件が低いユーザー:予算制約のある研究者や独立系AI開発者など。リアルタイム処理能力よりもコストを重視。従来のクラウド大手(AWSやAzure)の高額料金では負担できないため、こうした層へのピンポイントマーケティングが重要。
-
小規模AIスタートアップ:柔軟でスケーラブルな計算リソースを必要とするが、大手クラウドプロバイダーとの長期契約は避けたい。この層を惹きつけるにはビジネス提携の強化が必要。彼らは伝統的クラウド以外の代替案を積極的に探している。
-
Crypto AIスタートアップ:分散型AI製品を開発中だが、自前の計算リソースがないため、こうした分散型ネットワークに依存。
-
クラウドゲーム:AIとは直接関係ないが、GPUリソース需要が急増している。
肝心なのは開発者は常にコストと信頼性を最優先に考えるということです。
真の課題:需要であって供給ではない
多くのスタートアップはGPU供給ネットワークの規模を成功の指標として捉えますが、実際にはこれは単なる「虚栄の指標(vanity metric)」にすぎません。
真のボトルネックは供給ではなく需要にあります。成功を測る真の指標はネットワーク内のGPUの数ではなく、GPUの利用率や実際にレンタルされたGPUの数です。
トークンインセンティブは供給側の立ち上げに非常に有効で、迅速にリソースをネットワークに集めることが可能です。しかし、需要不足の問題を直接解決できるわけではありません。真の試練は、製品を十分に磨き上げ、潜在的な需要を引き出すことができるかどうかにあります。
DragonflyのHaseeb Qureshiが言うように、これがまさにカギなのです。
計算ネットワークを本当に稼働させる
現在、Web3分散型GPU市場が直面する最大の課題は、これらのネットワークを本当に効率的に稼働させることです。
これは簡単なことではありません。
分散ネットワーク内でGPUを調整することは極めて複雑な作業であり、リソース割当、動的ワークロード拡張、ノードとGPUの負荷分散、遅延管理、データ転送、障害耐性、そして世界中に散在する多様なハードウェアの取り扱いといった技術的難題が山積しています。これらが重なり合い、巨大な工学的課題となっています。
これらを解決するには、非常に堅実な工学的能力と、堅牢で設計のよいネットワークアーキテクチャが必要です。
これを理解するために、GoogleのKubernetesを参考にしてください。Kubernetesはコンテナオーケストレーションの黄金標準とされ、分散環境における負荷分散やスケーリングなどのタスクを自動化します。これらは分散型GPUネットワークが直面する課題と非常に似ています。なお、KubernetesはGoogleの10年以上にわたる分散計算の経験をもとに開発され、それでも完成までに数年の反復が必要でした。
現在、いくつかの上場済みGPU計算市場は小規模なワークロードなら処理できますが、大規模化を試みると問題が露呈します。これは根本的なアーキテクチャの欠陥がある可能性を示唆しています。
信頼性の問題:課題と機会
もう一つの分散型計算ネットワークが解決すべき重要な問題は、各ノードが主張する計算能力を本当に提供しているかをどう検証するか、つまりノードの信頼性確保です。現在、この検証プロセスは多くがネットワークの評判システムに依存しており、計算提供者が評価スコアに基づいてランク付けされることがあります。ブロックチェーン技術はこの分野で天然の利点を持ち、信頼不要の検証メカニズムを実現できます。GensynやSpheronといったスタートアップは、信頼不要の方法でこの問題を解決しようと模索しています。
現在、多くのWeb3チームがこうした課題に取り組んでいる最中であり、これはこの分野に依然として大きな機会があることを意味しています。
分散型計算市場の規模
では、分散型計算ネットワークの市場は一体どれくらいなのか?
現時点では、クラウドコンピューティング市場(約6800億〜2.5兆ドル規模)のごく小さな一部にすぎないかもしれません。しかし、分散型計算のコストが従来のクラウドプロバイダーよりも低ければ、多少ユーザーエクスペリエンスに摩擦があっても需要は必ず存在します。
短期〜中期的には、分散型計算のコストは依然として低く維持されると考えます。これは主に2つの要因によるものです。1つはトークン補助、もう1つは価格に鈍感なユーザーからの供給解放です。例えば、私のゲーミングノートパソコンを貸して毎月20ドルでも50ドルでも副収入になれば満足です。
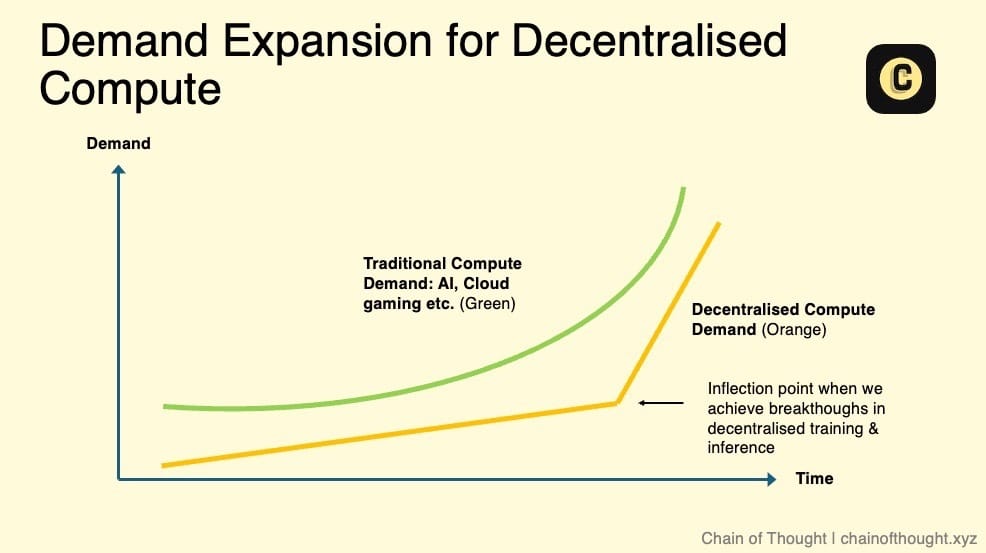
分散型計算ネットワークの真の成長可能性と市場規模の顕著な拡大は、以下のキーファクターに依存します:
-
分散型AIモデル学習の実現可能性:分散型ネットワークがAIモデルの学習をサポートできるようになれば、巨大な需要が生まれます。
-
推論需要の爆発:AI推論需要が急増すれば、既存のデータセンターでは対応できなくなるでしょう。実際、この傾向はすでに始まっています。NVIDIAのJensen Huangは、推論需要が「十億倍」になると述べています。
-
サービスレベル契約(SLAs)の導入:現在、分散型計算は「ベストエフォート」方式で提供されており、サービス品質(稼働時間など)の不確実性に直面しています。SLAがあれば、ネットワークは標準化された信頼性とパフォーマンス指標を提供でき、企業採用の主要な障壁を打破し、従来のクラウドコンピューティングの実行可能な代替手段となるでしょう。
非中央集権的で許可不要の計算は、分散型AIエコシステムの基礎層であり、最も重要なインフラの一つです。
GPUなどのハードウェアサプライチェーンは拡大を続けていますが、我々は依然として「人間知能時代」の夜明けにいると思っています。将来、計算能力への需要は尽きることがありません。
GPU市場の再評価を引き起こす可能性のある重要な転換点に注目してください。その時がすぐそこまで来ているかもしれません。
その他の注記:
-
純粋なGPU市場は非常に競争が激しく、非中央集権型プラットフォーム間の競争だけでなく、Web2 AI新興クラウドプラットフォーム(Vast.aiやLambdaなど)の台頭も脅威です。
-
小型ノード(例:H100 4枚)は用途が限られているため、市場需要は大きくありません。一方で、大型クラスターを販売したいと考えるサプライヤーを見つけるのは事実上不可能です。需要が依然として非常に高いからです。
-
分散型プロトコルの計算リソース供給は、最終的に少数の支配者が掌握するのか、それとも複数の市場に分散したままになるのか。私は前者を支持し、インフラ効率を高めるために統合が進むと考えます。もちろん、この過程には時間がかかり、その間は市場の分散と混乱が続くでしょう。
-
開発者はアプリ構築に集中したいのであって、デプロイや設定の問題に時間を費やしたくありません。そのため、計算市場はこうした複雑さを簡素化し、計算リソース取得時の摩擦を最小限に抑える必要があります。
1.2 分散型学習
要約
-
もしスケーリング則(Scaling Laws)が正しければ、次世代の最先端AIモデルを単一のデータセンターで学習することは物理的に不可能になる。
-
AIモデルの学習には大量のGPU間データ転送が必要であり、分散型GPUネットワークの低い相互接続速度が最大の技術的障壁となる。
-
研究者たちは複数の解決策を模索しており、画期的な進展(Open DiLoCo、DisTrOなど)が見られる。こうした技術革新は相乗効果を持ち、分散型学習の発展を加速させる。
-
分散型学習の将来は、AGI向けの最先端モデルよりも、特定分野に特化した小型専用モデルに集中する可能性が高い。
-
OpenAIのo1のようなモデルの普及により、推論需要が爆発的に増加し、分散型推論ネットワークに大きな機会をもたらす。
想像してみてください。世界を変える巨大なAIモデルが、秘密のトップラボではなく、数百万人の一般人によって共同で開発される未来です。ゲーマーたちのGPUはもはや『コールオブデューティ』の華やかな映像をレンダリングするだけではなく、より大きな目標――オープンソースで集団所有されるAIモデル、中央集権的な審査者を持たないAI――を支えるために使われます。
このような未来では、大規模AIモデルの開発はトップラボの独占ではなく、国民全体の成果となるのです。
しかし現実に戻ると、現在の重量級AI学習の大部分は依然として中央集権型データセンターに集中しており、この傾向は当面変わらないでしょう。
OpenAIのような企業は、巨大なGPUクラスターを拡大し続けています。Elon Muskは最近明らかに、xAIは20万枚のH100相当のGPUを備えたデータセンターの完成間近だと述べました。
しかし問題はGPUの数だけではありません。Googleが2022年に発表したPaLM論文では、モデルFLOPS利用率(Model FLOPS Utilization, MFU)という重要な指標を提示しています。これはGPUの最大計算能力が実際にどれだけ活用されているかを示すものですが、意外にもその利用率は通常35〜40%程度にとどまっています。
なぜここまで低いのか? GPUの性能はムーアの法則に従って飛躍的に向上していますが、ネットワークやメモリ、ストレージの改良はそれに追い付いておらず、明確なボトルネックとなっています。結果として、GPUはしばしばデータ転送の完了を待つだけでアイドル状態になります。
現在、AI学習が高度に中央集権化されている根本的な理由はただ一つ――効率です。
大規模モデルの学習は以下のキーテクノロジーに依存しています:
-
データ並列処理:データセットを複数のGPUに分割して並列処理することで、学習を高速化。
-
モデル並列処理:モデルの異なる部分を複数のGPUに分散し、メモリ制限を克服。
これらの技術はGPU間での頻繁なデータ交換を必要とするため、相互接続速度(ネットワーク内でのデータ転送速度)が極めて重要です。
最先端AIモデルの学習コストが10億ドルに達する場合、わずかな効率改善でも大きな意味を持ちます。
中央集権型データセンターは高速相互接続技術により、GPU間のデータ転送を迅速に行い、学習時間の短縮とコスト削減を実現しています。これは分散型ネットワークが現在匹敵できない点です……少なくとも今のところは。
遅い相互接続速度の克服
AI業界の関係者に話を聞くと、多くの人が「分散型学習は不可能だ」と断言するでしょう。
分散型アーキテクチャでは、GPUクラスターが同一の物理的位置にないため、データ転送速度が遅くなり、これが主要なボトルネックとなります。学習プロセスでは、各ステップでGPU間のデータ同期と交換が必要です。距離が遠ければ遅延は高まり、遅延が高ければ学習速度が遅くなり、コストが上がります。
中央集権型データセンターでは数日で終わる学習タスクが、分散型環境では2週間かかり、コストも高くなるかもしれません。明らかに実用的ではありません。
しかし、状況は変わりつつあります。
喜ばしいことに、分散型学習の研究は急速に盛り上がりを見せています。研究者たちは複数の方向から同時並行で取り組んでおり、最近の大量の研究成果と論文がその証です。こうした技術進歩は相乗効果を持ち、分散型学習の発展を加速させます。
さらに、実際の生産環境でのテストも極めて重要であり、既存の技術的境界を突破する鍵となります。
現在、いくつかの分散型学習技術は低速相互接続環境でも小規模モデルを処理できています。最前線の研究は、こうした手法をより大規模なモデルに拡張しようとしています。
-
たとえば、Prime IntellectのOpen DiCoLo論文は、実用的な手法を提案しています。GPUを「群島」に分け、それぞれが500回のローカル計算を終えてから同期を行うことで、帯域幅需要を1/500に削減します。この技術は当初Google DeepMindが小規模モデル向けに研究したものでしたが、現在では100億パラメータのモデル学習にまで拡張され、近日公開されました。
-
Nous ResearchのDisTrOフレームワークはさらに一歩進み、オプティマイザ技術によりGPU間通信を最大1万倍削減しながら、12億パラメータのモデルの学習に成功。
-
この勢いは続きます。Nousは最近、150億パラメータのモデルのプリトレーニングを完了し、損失曲線と収束速度が従来の中央集権型学習を上回ったと発表しました。
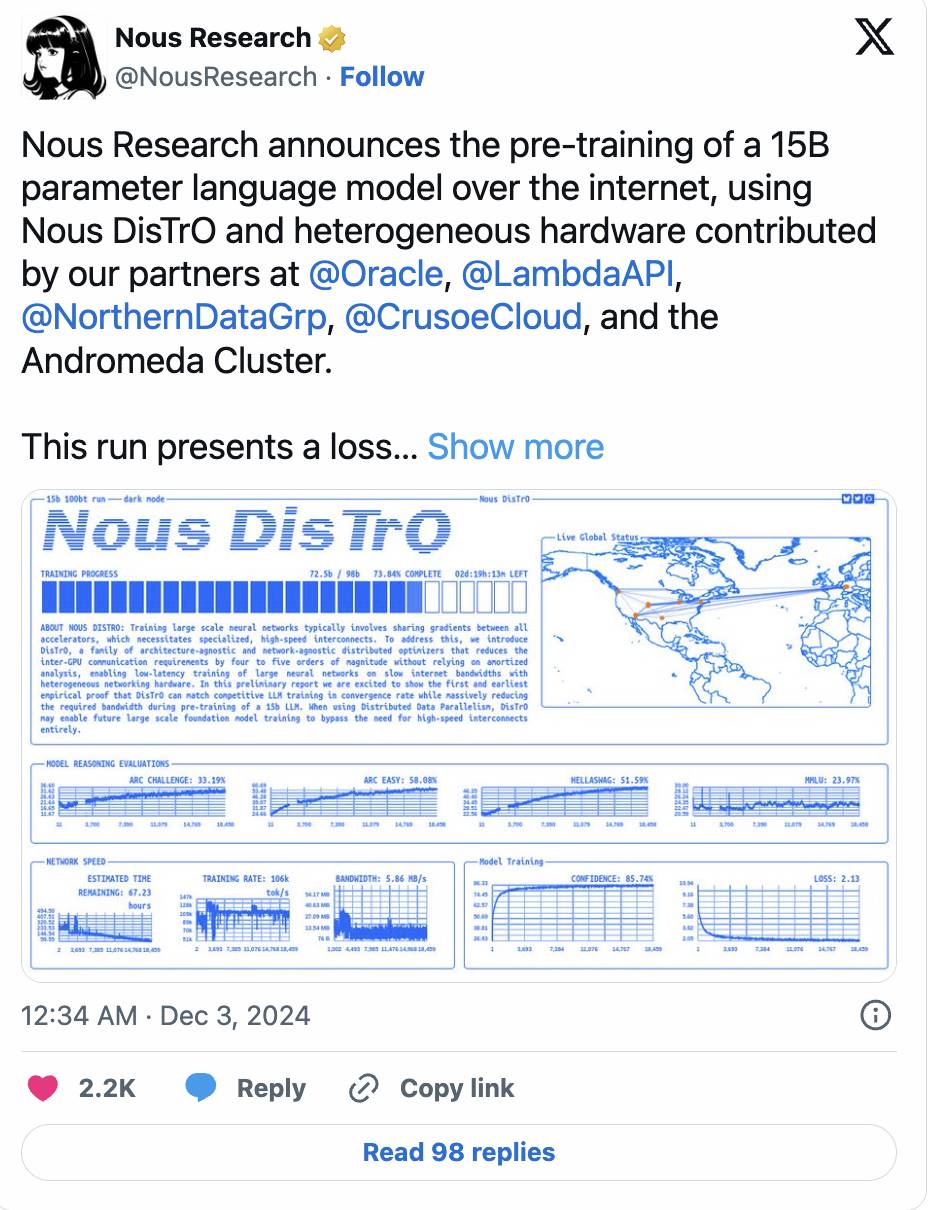
(ツイート詳細)
-
SWARM ParallelismやDTFMHEといった手法も、速度や接続条件が異なるさまざまなデバイス上で超大規模AIモデルを学習する方法を模索しています。
もう一つの課題は、多様なGPUハードウェア、特に分散型ネットワークでよく見られる消費者用GPUの管理です。これらは通常メモリが限られています。モデル並列処理技術(モデルの異なる層を複数のデバイスに分散)により、この問題は徐々に解決されつつあります。
分散型学習の将来
現在、分散型学習手法のモデル規模は、最先端モデル(GPT-4は約1兆パラメータと報告され、Prime Intellectの100億パラメータモデルの100倍)に比べてはるかに遅れています。真のスケーリングを実現するには、モデルアーキテクチャ設計、ネットワークインフラ、タスク割り当て戦略での大きなブレークスルーが必要です。
しかし大胆に想像できます。将来、分散型学習は、最大の中央集権型データセンターを上回るGPU計算能力を集結できるかもしれません。
Pluralis Research(分散型学習分野で注目すべきチーム)は、これは可能であるだけでなく必然であると述べています。中央集権型データセンターは空間や電力供給といった物理的制約に縛られますが、分散型ネットワークは世界中のほぼ無限のリソースを利用できます。
NVIDIAのJensen Huangでさえ、非同期分散型学習がAIスケーリングの可能性を解き放つ鍵かもしれないと述べています。また、分散型学習ネットワークは耐障害性も高いです。
したがって将来の可能性として、世界最強のAIモデルが分散型で学習されるかもしれません。
このビジョンはわくわくしますが、私はまだ懐疑的です。超大規模モデルの分散型学習が技術的・経済的に実現可能であることを示す、より強力な証拠が必要です。
私は、分散型学習の最適なユースケースは、超大規模でAGI指向の最先端モデルと競合するのではなく、特定用途に特化した小型オープンソースモデルにあると考えます。特に非Transformerモデルは、分散型環境に適していることが証明されています。
また、トークンインセンティブも将来の重要な要素となるでしょう。分散型学習が規模的に実現可能になれば、トークンは貢献者を効果的に報酬し、ネットワークの発展を促進できます。
道は長いですが、現在の進展は励みになります。分散型学習のブレークスルーは分散型ネットワークに恩恵をもたらすだけでなく、大手テック企業やトップAIラボにも新たな可能性を提供するでしょう……
1.3 分散型推論
現在、AIの計算リソースの大部分は大規模モデルの学習に集中しています。トップAIラボ間では、最強のベースモデルを開発し、最終的にAGIを達成するという軍拡競争が繰り広げられています。
しかし私は、こうした学習への計算資源の集中は、今後数年で徐々に推論へと移行していくと考えています。AI技術が医療からエンタメまで日常アプリに深く統合されるにつれ、推論に必要な計算リソースは膨大なものになります。

この傾向は根拠のないものではありません。推論時の計算スケーリング(Inference-time Compute Scaling)はAI分野のホットトピックとなっています。OpenAIは最近、最新モデルo1(コードネーム:Strawberry)のプレビュー版/ミニバージョンを公開しました。その顕著な特徴は「考える時間をかける」ことです。具体的には、まず質問に答えるために必要なステップを分析し、それらを段階的に実行します。
このモデルはクロスワードパズルを解くような計画が必要な複雑なタスクや、深い推論を要する問題に特化しています。応答生成は遅くなりますが、結果はより丁寧で熟考されたものになります。しかし、この設計には高額な運用コストが伴い、その推論費用はGPT-4の25倍です。
この傾向からわかるのは、AIパフォーマンスの次の飛躍は、より大規模なモデルの学習だけでなく、推論フェーズの計算能力拡張にも依存するということです。
詳しく知りたい方は、以下の研究をご覧ください:
-
推論計算をリピートサンプリングで拡張することで、多くのタスクで顕著なパフォーマンス向上が得られる。
-
推論フェーズも指数関数的なスケーリング則(Scaling Law)に従う。
強力なAIモデルが学習された後、その推論タスク(実際の応用段階)は分散型計算ネットワークにオフロードできます。これは非常に魅力的です。理由は以下の通り:
-
推論のリソース要件は学習に比べてはるかに低い。学習後、モデルは量子化(Quantization)、刈り込み(Pruning)、蒸留(Distillation)などの
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News














