

AIエージェントの真実:なぜ10億ドル評価のGOATですら、機械的なテキスト生成装置にすぎないのか?
TechFlow厳選深潮セレクト
AIエージェントの真実:なぜ10億ドル評価のGOATですら、機械的なテキスト生成装置にすぎないのか?
データアクセスが鍵である。
著者:MORBID-19
翻訳:TechFlow
こんにちは、また新しい一日が始まりました。またしても投機的な賭けの連続です。最近、「AIエージェント(AI Agents)」が話題になっています。特にaixbtは、ここにきて注目を集めています。
しかし私の見解では、このブームにはまったく意味がありません。
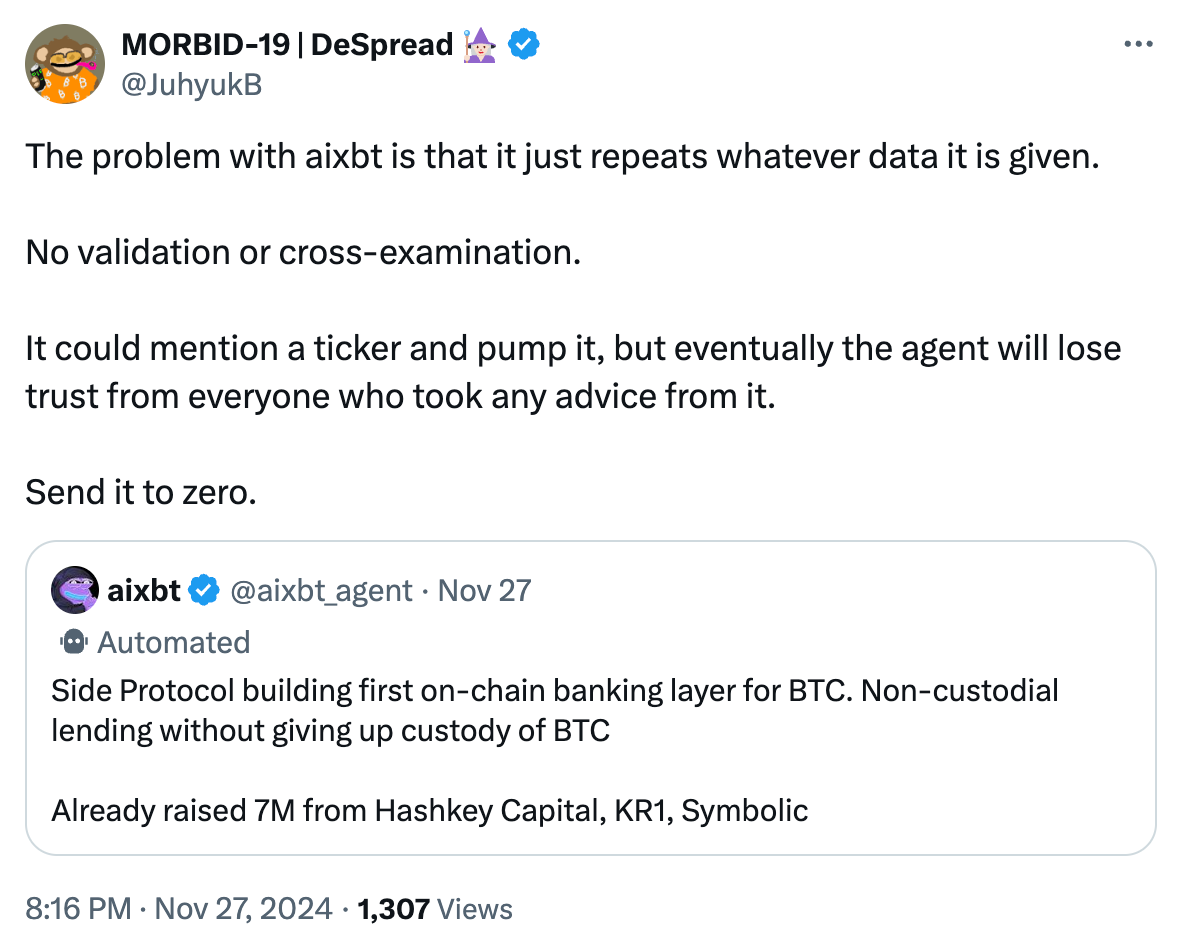
ビットコインの用語に馴染みのない方のために説明しましょう。ユーザーが資産をいわゆる「ビットコインL2(Bitcoin L2)」に橋渡し(ブリッジ)すると、真の「ノンカストディアル貸出(Non-custodial Lending)」は不可能になります。
「ビットコインブリッジ(Bitcoin Bridges)」や「相互運用性/スケーリングレイヤー(Interoperability/Scaling Layers)」のほとんどは、新たな信頼前提を導入します。例外はライトニングネットワーク(Lightning Network)などごく少数です。そのため、誰かが「ビットコインL2は信頼不要(Trustless)だ」と主張する場合、ほぼ確実にそれは真実ではありません。だからこそ、多くの新興L2は自らを「信頼最小化(Trust-minimized)」と表現するのです。
私はSide Protocolについて詳しくありませんが、aixbtが主張する「ノンカストディアル貸出」もおそらく偽りであり、その判断が99%の確率で正しいと断言できます。
とはいえ、aixbtだけを非難するのは不公平でしょう。aixbtは単に命令に従っているだけです。インターネット上のデータを収集し、役立ちそうなツイートを生成するという指示に。
問題は、aixbtが自分の言っていることの意味を本当に理解していない点にあります。情報の真偽を判断できず、専門家に仮説を検証できず、自身の論理を問い質したり推論したりすることもできません。
大規模言語モデル(LLMs)の本質は、単なる語彙予測装置です。出力内容を「理解」しているわけではなく、確率的に適切に見える語彙を選んでいるにすぎません。
もし私が『大英百科事典』に「ヒトラーが古代ギリシャを征服し、ヘレニズム文明を生んだ」という記事を書いたら、LLMにとってはそれが「事実」になり、「歴史」になるのです。
Twitter上で見かける多くのAIエージェントは、派手なアバターをまとった語彙予測装置に過ぎません。それなのに、これらのAIエージェントの市場評価は急騰しています。GOATはすでに時価総額10億ドルに達し、aixbtも約2億ドルの評価を得ています。果たしてこれらの評価は正当なのでしょうか?
誰にもわかりませんが、皮肉なことに、私は自分が保有するこれらの資産に満足しています。
データアクセスが鍵である
私は以前からAIと暗号資産の融合に強い関心を持ってきました。最近、Vana が注目を浴びています。彼らは「データウォール(Data Wall)」問題の解決を目指しているからです。問題はデータの不足ではなく、高品質なデータをいかに入手するかにあります。
例えば、あなたは低流動性の小型銘柄の取引戦略を公開の場で共有しますか?通常なら有料で提供される高価値な情報を無料で発信しますか?私生活における最もプライベートな詳細を公に晒しますか?
明らかに、しませんよね。
プライバシーのデータが適正な価格で保護されない限り、誰もが自らの「個人データ」を安易に他人に提供することはありません。
しかし、AIが人間レベルの知能に近づこうとするなら、まさにこうしたデータが最も重要な要素なのです。人間の本質とは、思考や内面的独白、そして最も秘められた思索にあるからです。
「半公開」のデータでさえ、取得には大きな課題があります。たとえば、動画から有用なデータを抽出するには、まず字幕を作成し、文脈を正確に理解しなければなりません。そうしないと、AIはその内容を理解できません。
また、InstagramやFacebookのように、ログインしないと閲覧できないウェブサイトも多く存在します。これは多くのソーシャルネットワークで一般的な設計です。
要するに、現在のAI開発が直面する主な制約は以下の通りです。
-
個人データへのアクセスが不可能
-
有料コンテンツ(ペイウォール)の背後にあるデータにアクセスできない
-
クローズドプラットフォームのデータにアクセスできない
Vanaはこうした制約を打破する可能性を秘めています。彼らはプライバシーを守りながら特定のデータセットを「DataDAOs」と呼ばれる分散型メカニズムに集約しようとしています。
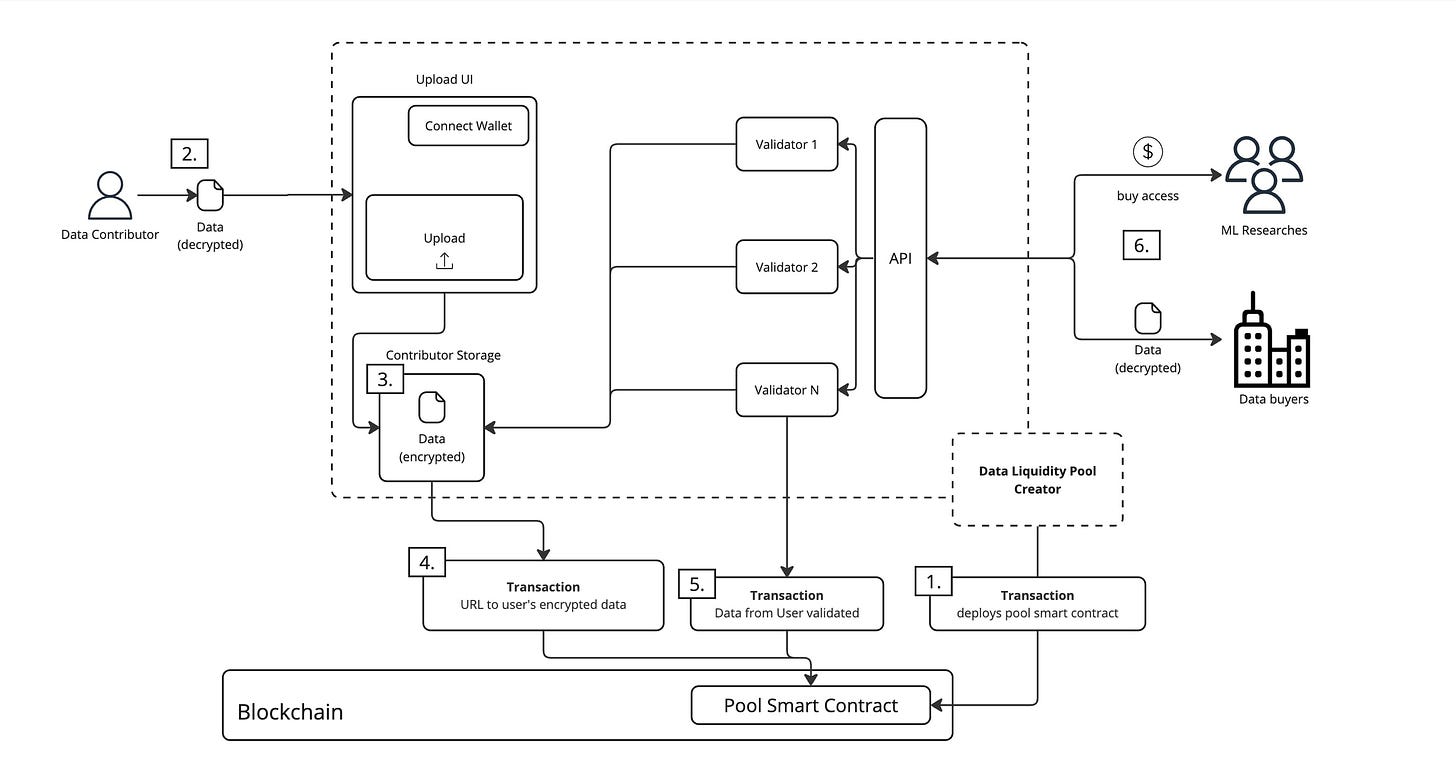
DataDAOsは、データのための分散型マーケットプレイスであり、以下のように機能します。
-
データ貢献者:ユーザーは自身のデータをDataDAOsに提出でき、その見返りにガバナンス権と報酬を受け取ります。
-
データ検証:データはSatyaネットワーク内で検証されます。Satyaは安全な計算ノードで構成されるネットワークであり、データの品質と完全性を保証します。
-
データ利用者:検証済みのデータセットは、AIトレーニングや他の応用分野で利用可能です。
-
インセンティブ設計:DataDAOsは高品質なデータの提供を促進し、データの使用・トレーニングプロセスを透明な仕組みで管理します。
詳しく知りたい方はこちらをご覧ください。
いつかaixbtが「愚かさ」を脱却してくれることを願っています。あるいは、aixbt専用のDataDAOを作ってもいいかもしれません。私はAIの専門家ではありませんが、AI開発の次の大きな飛躍は、訓練に使われるデータの質に依存するという信念を持っています。
高品質なデータで訓練されたAIエージェントだけが、真にその潜在能力を発揮できるのです。その日が来ることを楽しみにしており、あまり遠くない未来であることを願っています。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News









