

Vana:AI時代にあなたのデータをトークンのように自由に流通させ、価値を創造
TechFlow厳選深潮セレクト
Vana:AI時代にあなたのデータをトークンのように自由に流通させ、価値を創造
Vanaは「データDAO」と「貢献の証明」を用いてAI時代のデータ価値連鎖をどのように再構築するのか?
執筆:思维怪怪
あなたは、RedditやX(旧Twitter)のようなソーシャルメディアがなぜ無料で利用できるのか考えたことがありますか?その答えは、あなたが毎日投稿するコンテンツ、いいねを押す行動、あるいはただ滞在している時間の中に隠れています。
かつてこれらのプラットフォームは、あなたの「注目」を広告主に商品として売却していました。しかし今、彼らにはさらに大きな買い手——AI企業が現れました。報道によると、RedditとGoogleのデータ使用許諾契約だけでも、前者に年間6,000万ドルもの収入をもたらすとのことです。しかし、この巨額の富は、データの真の創造者である私たちユーザーとは無関係に分配されています。
さらに気になるのは、私たちのデータで訓練されたAIが将来、私たち自身の仕事を奪う可能性があるということです。確かにAIは新たな雇用機会を生み出すかもしれませんが、このようなデータ独占による富の集中は、社会的不平等を確実に拡大させています。私たちは、少数のテック大手が支配するサイバーパンク的な世界へと滑り落ちつつあるのです。
では、一般の人々はAI時代においてどのようにして自身の利益を守ることができるのでしょうか?AIの台頭とともに、多くの人々がブロックチェーンを「AIに対する最後の防衛線」と見なすようになりました。こうした思考に基づき、革新者たちが解決策を探り始めています。彼らが提唱するのは、まず私たち自身のデータに対する所有権とコントロールを取り戻すこと。そして、それらのデータを活用して、一般市民に真正にサービスを提供するAIモデルを共同で訓練することです。
このアイデアは理想主義的に見えるかもしれませんが、歴史が示すように、すべての技術革命は「狂気」と思える構想から始まります。今日、その構想を現実にしようとしているのが、「Vana」という新しいパブリックチェーンプロジェクトです。分散型データ流動性ネットワークとして初の取り組みとなるVanaは、ユーザーのデータを自由に流通可能なトークンへと変換し、ユーザー主導の分散型AIの実現を目指しています。

Vanaの創設者とプロジェクトの起源
実はVanaの誕生は、マサチューセッツ工科大学(MIT)メディアラボの教室にさかのぼります。そこには、世界を変えたいという理想を持つ二人の若者——Anna KazlauskasとArt Abal——が出会いました。

左:Anna Kazlauskas;右:Art Abal
MITでコンピューターサイエンスと経済学を専攻していたAnna Kazlauskasは、2015年からデータと暗号資産に強い関心を持っていました。当時彼女はイーサリアムの初期マイニングに参加しており、この経験を通じて分散型技術の潜在力を深く理解しました。その後、連邦準備制度理事会(FRB)、欧州中央銀行(ECB)、世界銀行など国際金融機関でのデータ研究を通じて、彼女は「未来においてデータは新たな通貨形態となる」と確信するようになりました。
一方、ハーバード大学で公共政策の修士号を取得していたArt Abalは、ベルファースクールの科学・国際問題センターにてデータ影響評価を深く研究しました。Vana加入前には、AIトレーニングデータプロバイダーAppen社で革新的なデータ収集手法を主導し、現在の多くの生成AIツールの開発に大きく貢献しました。彼のデータ倫理およびAI責任に関する洞察は、Vanaに強固な社会的使命感を注入しています。
AnnaとArtがMITメディアラボの授業で出会い、データの民主化とユーザーのデータ権益について共通の情熱を持っていることに気づいたとき、彼らはデータ所有権とAIの公平性という問題を真に解決するためには、全く新しいパラダイム——ユーザーが自らのデータを真正にコントロールできるシステム——が必要だと認識しました。
こうした共通のビジョンのもと、二人は共同でVanaを設立しました。彼らの目標は、ユーザーがデータ主権を獲得するだけでなく、自らのデータから経済的利益を得られるような革命的なプラットフォームを構築することです。革新的なDLP(Data Liquidity Pool)メカニズムと貢献証明(Proof of Contribution)システムを通じて、Vanaはユーザーがプライベートデータを安全に提供し、それらのデータで訓練されたAIモデルを共同所有・利益享受できる仕組みを提供し、ユーザー主導のAI発展を推進します。
Vanaのビジョンは業界から早くも高い評価を得ています。これまでに合計2,500万ドルの資金調達を完了しており、Coinbase Venturesが主導した500万ドルの戦略的ラウンド、Paradigm主導の1,800万ドルのAラウンド、Polychain主導の200万ドルのシードラウンドを含みます。その他にもCasey Caruso、Packy McCormick、Manifold、GSR、DeFiance Capitalといった著名投資家が参画しています。

データが「新時代の石油」と呼ばれるこの世界において、Vanaの登場はまさに我々がデータ主権を取り戻すための重要なチャンスを提供しています。では、この可能性に満ちたプロジェクトは一体どのように機能するのでしょうか?次に、Vanaの技術構造と革新理念を詳しく探っていきましょう。
Vanaの技術構造と革新理念
Vanaの技術アーキテクチャは、データの民主化と価値最大化を目的とした精巧に設計されたエコシステムです。その中核を成すのは、データ流動性プール(DLP)、貢献証明メカニズム、名古屋コンセンサス、ユーザー自己ホスト型データ管理、そして分散型アプリケーション層です。これらはプライバシー保護とデータ潜在価値の解放を両立する、革新的なプラットフォームを構築しています。
1. データ流動性プール(DLP):データ価値化の基盤
データ流動性プール(DLP)はVanaネットワークの基本単位であり、データ版の「流動性マイニング」と捉えることができます。各DLPは特定タイプのデータ資産を集約するためのスマートコントラクトです。例えば、「Reddit Data DAO(r/datadao)」は成功したDLPの事例であり、14万人以上のRedditユーザーが参加しています。このDLPはユーザーのReddit投稿、コメント、投票履歴を統合しています。
ユーザーがDLPにデータを提出すると、そのDLP特有のトークン報酬を受け取れます。例えばReddit Data DAOの場合はRDATという独自トークンです。これらのトークンはユーザーの貢献を表すだけでなく、DLPにおけるガバナンス権および将来の収益分配権も与えます。Vanaでは各DLPが独自のトークンを発行できることで、多様なデータ資産に対して柔軟な価値捕獲メカニズムを提供しています。
Vanaエコシステム内では、上位16位までのDLPは追加でVANAトークンの排出報酬も得られ、高品質なデータプールの形成と競争を促進しています。このようにして、Vanaは断片的な個人データを流動性のあるデジタル資産へと変換し、データの価値化と流動性の基礎を築いています。
2. 貢献証明(Proof of Contribution):データ価値の精密測定
貢献証明は、Vanaがデータ品質を確保するためのキーメカニズムです。各DLPは独自の特性に応じて、独自の貢献証明関数をカスタマイズできます。この関数はデータの真実性と完全性を検証するだけでなく、それがAIモデルの性能向上にどれだけ貢献するかも評価します。
ChatGPT Data DAOを例にすると、その貢献証明は四つの次元から構成されます:真実性、所有権、品質、独自性。真実性はOpenAIが提供するデータエクスポートリンクで確認され、所有権はユーザーのメールアドレスで検証されます。品質評価はLLMがランダムサンプリングされた対話をスコア付けすることで行われ、独自性はデータの特徴ベクトルを計算し既存データと比較することで判断されます。
このような多次元評価により、高品質かつ価値あるデータのみが受け入れられ、報酬を得られます。貢献証明はデータ価格付けの基礎であると同時に、エコシステム全体のデータ品質を維持するための鍵でもあります。
3. 名古屋コンセンサス(Nagoya Consensus):分散型のデータ品質保証
名古屋コンセンサスはVanaネットワークの心臓部であり、Bittensorのユマコンセンサス(Yuma Consensus)を参考に改良したものです。このメカニズムの核心は、複数の検証ノードが集団でデータ品質を評価し、加重平均によって最終スコアを決定することにあります。
より革新的なのは、検証ノードがデータを評価するだけでなく、他の検証ノードの評価行動に対してもスコアを与える点です。この「二重評価」メカニズムにより、システムの公平性と正確性が大幅に向上します。たとえば、明らかに低品質なデータに高スコアをつけた検証ノードは、他のノードから懲罰的なスコアを受けることになります。
1,800ブロック(約3時間)ごとに一周期として、システムはその期間中の総合評価に基づき検証ノードに報酬を分配します。この仕組みは、検証ノードが誠実に行動するようインセンティブを与え、悪質な行為を迅速に識別・排除することで、ネットワーク全体の健全性を維持します。
4. 非ホスト型データストレージ:プライバシー保護の最終ライン
Vanaの大きな革新の一つが、独自のデータ管理方式です。Vanaネットワークでは、ユーザーの生データは決して「オンチェーン」に保存されることなく、ユーザーがGoogle Drive、Dropbox、あるいはMacbook上で稼働する個人サーバーなど、任意の場所に保管を選択できます。
ユーザーがDLPにデータを提出する際、実際に送信されるのは暗号化されたデータへのURLと、オプションで内容整合性のハッシュ値だけです。これらの情報はVanaのデータ登録コントラクトに記録されます。検証者がデータにアクセスする必要がある場合、復号キーを要求し、ダウンロード後に復号して検証を行います。
この設計は、データのプライバシーとコントロールの問題を巧妙に解決しています。ユーザーは常に自らのデータを完全に掌握しつつ、データ経済に参加できるのです。これは安全性の確保だけでなく、将来の幅広いデータ応用シーンの可能性も開きます。
5. 分散型アプリケーション層:データ価値の多様化実現
Vanaの最上層には、オープンなアプリケーションエコシステムがあります。ここでは開発者はDLPが蓄積したデータ流動性を活用して、さまざまな革新的アプリを開発できます。一方、データ提供者はこれらのアプリから直接経済的価値を得られます。
例えば、ある開発チームがReddit Data DAOのデータを使って専用のAIモデルを訓練したとしましょう。データ提供者はモデル完成後、それを使用できるだけでなく、貢献度に応じてモデルが生む収益を分配されます。実際、すでにそのようなAIモデルが開発されており、詳細は『触底反弹,AI 赛道老币 r/datadao 为何起死回生?』をご参照ください。
このモデルは高品質なデータ提供を促進するだけでなく、ユーザー主導のAI開発エコシステムを本物に作り上げます。ユーザーは単なるデータ提供者から、AI製品の共同所有者・受益者へと変貌するのです。
このようにして、Vanaはデータ経済の地図を再描きつつあります。この新しいパラダイムでは、ユーザーは受動的なデータ供給者から、積極的に参加し、共に利益を得るエコシステム構築者へと転換します。これは個人にとって新たな価値獲得手段を提供するだけでなく、AI業界全体に新たな活力と革新の原動力を与えています。
Vanaの技術アーキテクチャは、データ所有権、プライバシー保護、価値分配といった現代データ経済の根本的課題を解決するだけでなく、将来のデータ駆動型イノベーションの道を切り開いています。ますます多くのデータDAOがネットワークに加わり、プラットフォーム上で新たなアプリが構築されれば、Vanaは次世代の分散型AIおよびデータ経済のインフラとしての可能性を秘めています。
Satoriテストネット:Vanaの公開試験場
6月11日にSatoriテストネットが公開され、Vanaはそのエコシステムの原型を一般に提示しました。これは単なる技術検証の場ではなく、将来的なメインネット運営モードのプレビューでもあります。現在、Vanaエコシステムでは参加者に三つの主要な参加経路を提供しています:DLP検証ノードの運用、新しいDLPの作成、または既存DLPへのデータ提出による「データマイニング」参加です。
DLP検証ノードの運用
検証ノードはVanaネットワークの「ゲートキーパー」であり、DLPに提出されたデータの品質を検証する役割を担います。検証ノードの運用には技術力だけでなく、十分な計算資源も求められます。Vanaの技術文書によると、最低ハードウェア要件はCPUコア1つ、RAM 8GB、高速SSDストレージ10GBです。
検証者になりたいユーザーは、まず特定のDLPを選択し、そのDLPのスマートコントラクトを通じて検証者として登録します。承認されると、そのDLPに特化した検証ノードを稼働できます。なお、検証者は複数のDLPに対して同時にノードを運用できますが、各DLPには独自の最低ステーキング要件が設定されています。
新しいDLPの作成
独自のデータリソースや斬新なアイデアを持つユーザーにとって、新しいDLPを作成することは非常に魅力的な選択肢です。DLP作成にはVanaの技術アーキテクチャ、特に貢献証明と名古屋コンセンサスの深い理解が求められます。
新規DLPの創設者は、データ提供の目標、検証方法、報酬パラメータを設計する必要があります。また、データ価値を正確に評価できる貢献証明関数を実装しなければなりません。このプロセスは複雑ですが、Vanaは詳細なテンプレートとドキュメントサポートを提供しています。
データマイニングへの参加
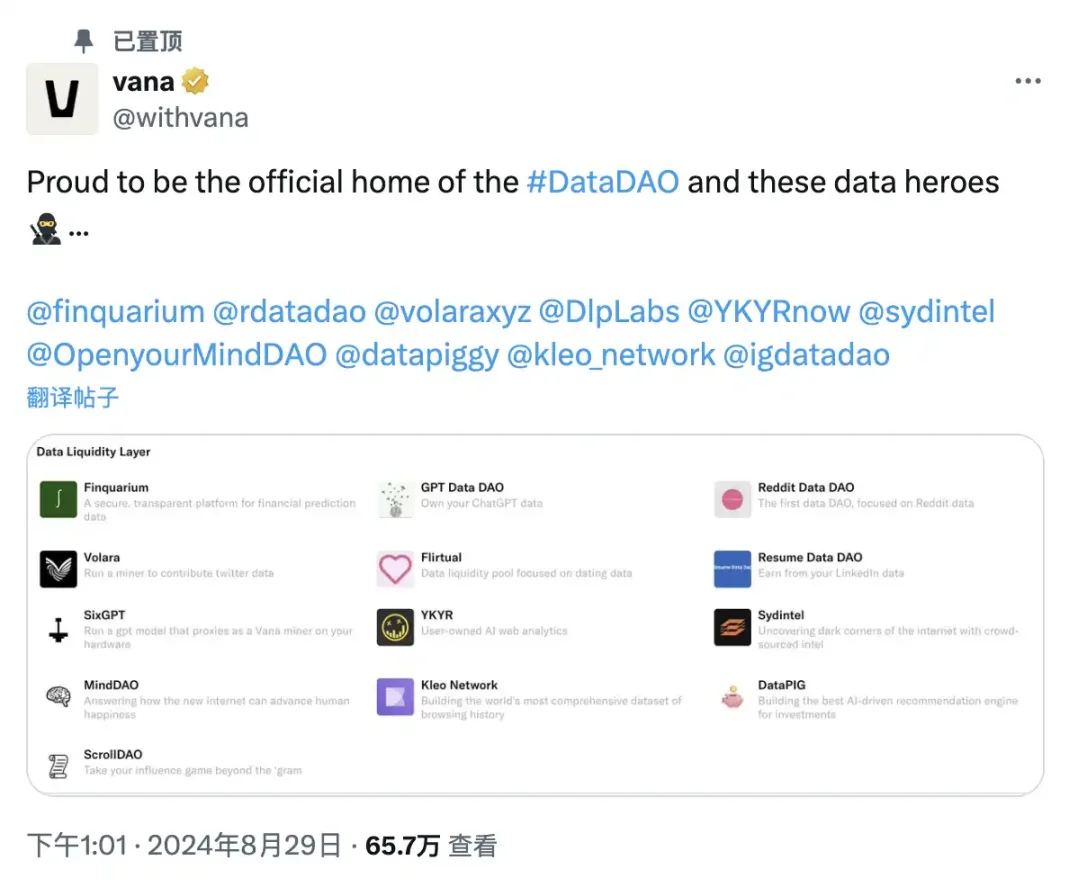
大多数のユーザーにとっては、既存のDLPにデータを提出して「データマイニング」に参加するのが最も直接的な参加方法です。現在、公式推薦されているDLPは13あり、ソーシャルメディアデータから金融予測データまで多岐にわたります。
-
Finquarium:金融予測データを集約。
-
GPT Data DAO:ChatGPTチャットデータのエクスポートに特化。
-
Reddit Data DAO:Redditユーザーデータに焦点を当て、すでに正式開始。
-
Volara:Twitterデータの収集と活用に特化。
-
Flirtual:デートデータを収集。
-
ResumeDataDAO:LinkedInデータのエクスポートに特化。
-
SixGPT:LLMチャットデータの収集・管理。
-
YKYR:Google Analyticsデータを収集。
-
Sydintel:クラウドソーシング知能でインターネットの闇の側面を明らかにする。
-
MindDAO:ユーザーの幸福感に関連する時系列データを収集。
-
Kleo:世界最大規模の閲覧履歴データセットを構築。
-
DataPIG:トークン投資嗜好データに注目。
-
ScrollDAO:Instagramデータの収集と活用。
これらのDLPのうち、一部はまだ開発中ですが、いずれも「プリマイニング」段階にあります。正式なデータ提出とマイニングはメインネット稼働後から可能になるためです。ただし、ユーザーは現在のうちに様々な方法で参加資格を確保できます。たとえば、VanaのTelegramアプリ内のチャレンジイベントに参加したり、各DLPの公式サイトで事前登録を行うことで可能です。
まとめ
Vanaの出現は、データ経済が新たなパラダイムシフトを迎えていることを示しています。現在のAIの波の中で、データは「新時代の石油」となりましたが、Vanaはこの資源の採掘、精製、分配のあり方を再構築しようとしています。
本質的に、Vanaはデータ版の「共有地の悲劇」に対する解決策を構築しています。巧妙なインセンティブ設計と技術革新により、無限に近い供給ながらも価値化が難しい個人データを、管理可能・価格付け可能・流通可能なデジタル資産へと変えています。これにより、一般ユーザーがAIの恩恵を享受する新たな道が開かれ、分散型AIの発展に向けた可能性のある青写真が提示されています。
しかし、Vanaの成功には依然多くの不確実性があります。技術的には、開放性と安全性のバランスを取る必要があります。経済的には、持続的な価値創出を証明しなければなりません。社会的レベルでは、データ倫理や規制対応といった潜在的な課題にも直面しています。
さらに深く見ると、Vanaは現在のデータ独占とAI発展モデルに対する反省と挑戦を象徴しています。それは重要な問いを投げかけています:AI時代において、我々は既存のデータ寡占をさらに強化するのか、それともより開放的で公正かつ多様なデータエコシステムを構築するのか?
Vanaが最終的に成功するかどうかにかかわらず、その存在はデータ価値、AI倫理、技術革新について再考する窓を私たちに与えてくれます。将来、Vanaのようなプロジェクトは、Web3の理想とAIの現実をつなぐ重要な架け橋となり、デジタル経済の次のフェーズの方向性を示すかもしれません。
TechFlow公式コミュニティへようこそ
Telegram購読グループ:https://t.me/TechFlowDaily
Twitter公式アカウント:https://x.com/TechFlowPost
Twitter英語アカウント:https://x.com/BlockFlow_News










